AWSが投じた一手 ― ニューヨーク・サミットでの発表
発表の舞台は、2026年6月17日にニューヨーク市で開かれた「AWS Summit New York City」である。AWSでエージェンティックAI担当バイスプレジデントを務めるスワミ・シヴァスブラマニアン(Swami Sivasubramanian)氏のキーノートで、Amazon Bedrock Managed Knowledge Base が一般提供(GA)に達したことが明らかにされた。AWSの公式ブログ「Introducing Amazon Bedrock Managed Knowledge Base」と「What's New」告知(いずれも初出6月17日、一部6月19日に更新)が同日付で公開されている。
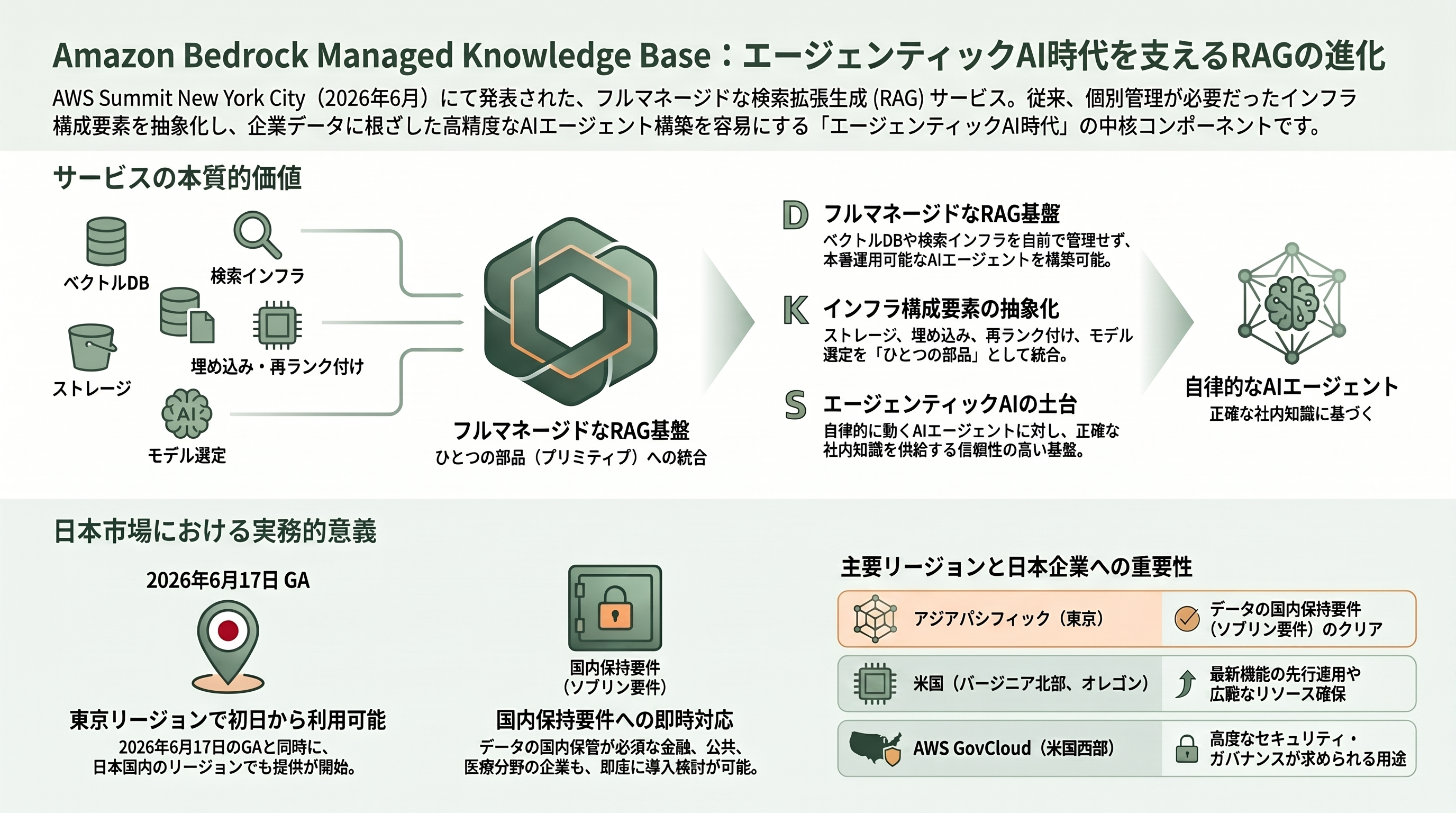
AWSによる位置づけは明快だ。Amazon Bedrock Managed Knowledge Base は「フルマネージドの検索拡張生成(RAG)サービス」であり、「ベクトルデータベース、データパイプライン、検索インフラを自前で管理することなく、企業データに根ざした本番運用可能なAIエージェントを構築できる」とされる。公式ブログは、開発者が従来は個別に組み上げ保守してきた「ストレージ、検索(リトリーバル)、埋め込み(エンベディング)、再ランク付け(リランキング)、基盤モデルの選定」という複数のインフラ構成要素を、ひとつのマネージドな部品(プリミティブ)へと抽象化した、と説明する。
提供リージョンは、米国東部(バージニア北部)、米国西部(オレゴン)、アジアパシフィック(シドニー、東京)、欧州(ダブリン、フランクフルト、ロンドン)、そして AWS GovCloud(米国西部)。東京リージョンが初日から含まれている点は、日本企業にとって実務上の意味が大きい。データの国内保持要件を抱える金融・公共・医療分野でも、リージョン選択だけで対応の出発点に立てるためだ。
この発表は単発のものではなく、AWSが繰り返し掲げる「エージェンティックAIの時代(the Agentic AI era)」という大きな文脈の一部に置かれている。同じニューヨーク・サミット前後では、Bedrock上での新モデル提供や価格改定なども併せてアナウンスされており、Managed Knowledge Base は「AIエージェントに正確な社内知識を与える土台」として、その中心に据えられた格好だ。
ここで一点、名称の整理をしておきたい。AWSには2023年から提供されてきた「Amazon Bedrock Knowledge Bases(ナレッジベース)」が既に存在する。今回GAとなったのは、それをさらに押し進めた「Managed Knowledge Base(マネージド型)」という新しい区分である。両者の違いは後段で詳述するが、まずは「RAGとは何か」から順を追って解説する。
そもそもRAGとは何か ― 大規模言語モデルの「外付け記憶」
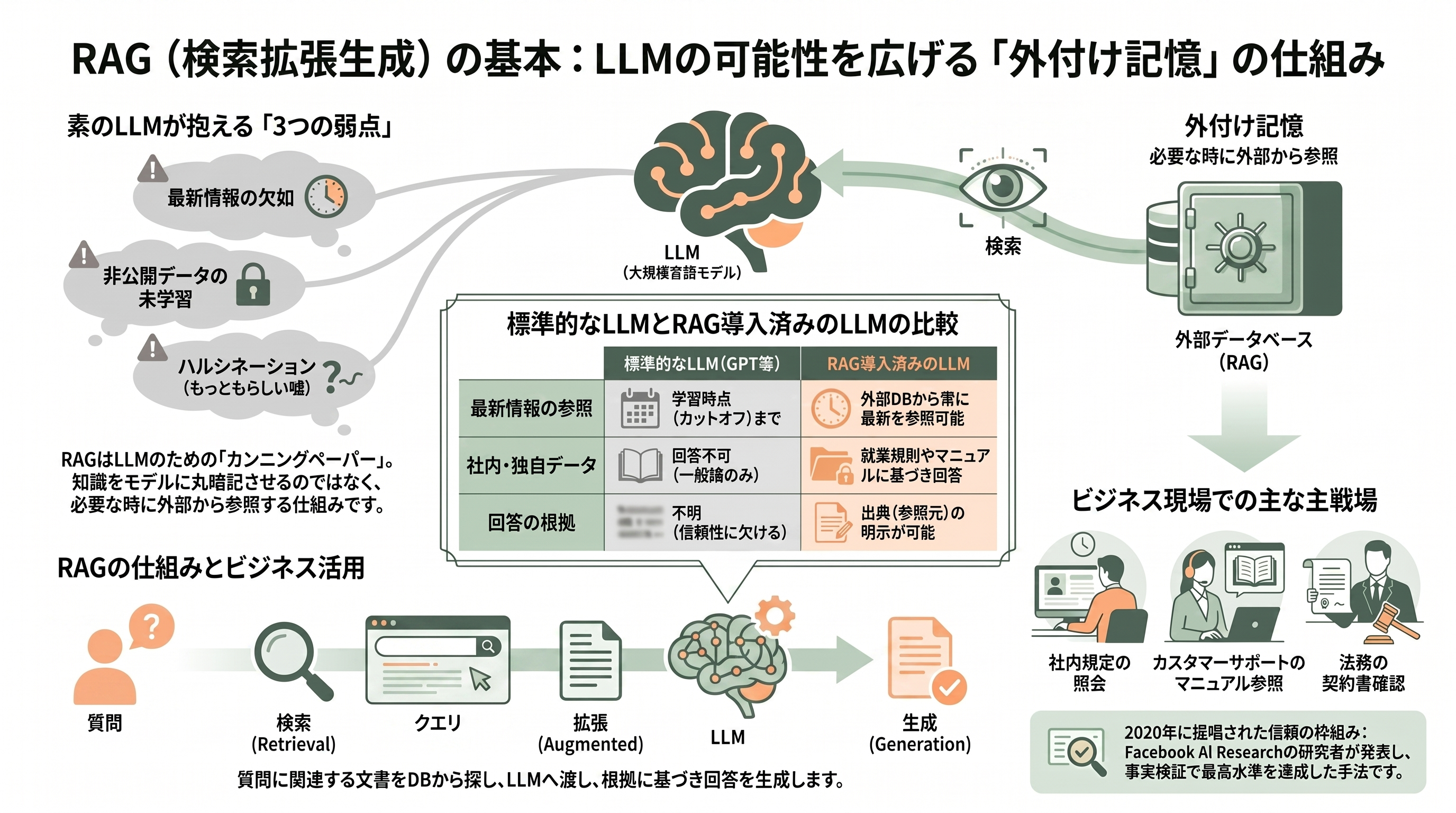
RAG(Retrieval-Augmented Generation、検索拡張生成)を理解する出発点は、大規模言語モデル(LLM)の根本的な制約にある。ChatGPTやClaudeのようなLLMは、学習時に取り込んだ膨大なテキストから知識を「パラメータ(重み)」の中に固定的に焼き付けている。この知識には三つの弱点がある。第一に、学習データのカットオフ時点で時間が止まっており、最新情報を知らない。第二に、企業の社内規程・契約書・製品マニュアル・顧客データといった非公開情報は、そもそも学習に含まれていないため答えようがない。第三に、知らないことを問われたとき、それらしく聞こえる誤答(ハルシネーション)を生成してしまう。
RAGはこの三つを一挙に緩和する設計思想である。仕組みを一言で言えば、「質問に答える前に、関連する社外・社内の文書をデータベースから検索(Retrieval)して取り出し、その文書を質問文と一緒にLLMへ渡し(Augmented)、根拠に基づいた回答を生成(Generation)させる」というものだ。LLMに記憶を丸暗記させ直すのではなく、必要なときに参照する「外付けの記憶(カンニングペーパー)」を与える、と考えると直感的にわかりやすい。
具体例で考えてみよう。ある製造業の社員が「私の有給休暇は何日繰り越せるか」と社内チャットボットに尋ねたとする。素のLLMは一般論しか返せないが、RAGを組み込んだシステムは、まず社内の就業規則PDFから「有給休暇の繰り越し」に関する条項を検索して抜き出し、その実際の条文をLLMに読ませたうえで「貴社規程では最大20日まで翌年度に繰り越せます(就業規則第15条)」と、出典付きで答える。カスタマーサポートで製品マニュアルを横断して回答する、コールセンターで過去の問い合わせ履歴を参照する、法務が契約書群を根拠に質問へ答える――こうした「自社の事実に基づいて答えてほしい」あらゆる場面がRAGの主戦場だ。
RAGという概念自体は新しいものではない。起源は、当時Facebook AI Research(FAIR、現Meta AI)のロンドン拠点に在籍し、ユニバーシティ・カレッジ・ロンドン(UCL)で博士課程に取り組んでいたパトリック・ルイス(Patrick Lewis)氏らが2020年に発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」(NeurIPS 2020収録)にさかのぼる。この論文は、モデル内部に固定された「パラメトリックな記憶」と、Wikipediaのような外部データを指す「非パラメトリックな記憶」を組み合わせるという枠組みを提示し、オープンドメインの質問応答や事実検証で当時の最高水準を達成した。後述するが、この論文の共著者の一人は、のちにRAG専業スタートアップを起業することになる。
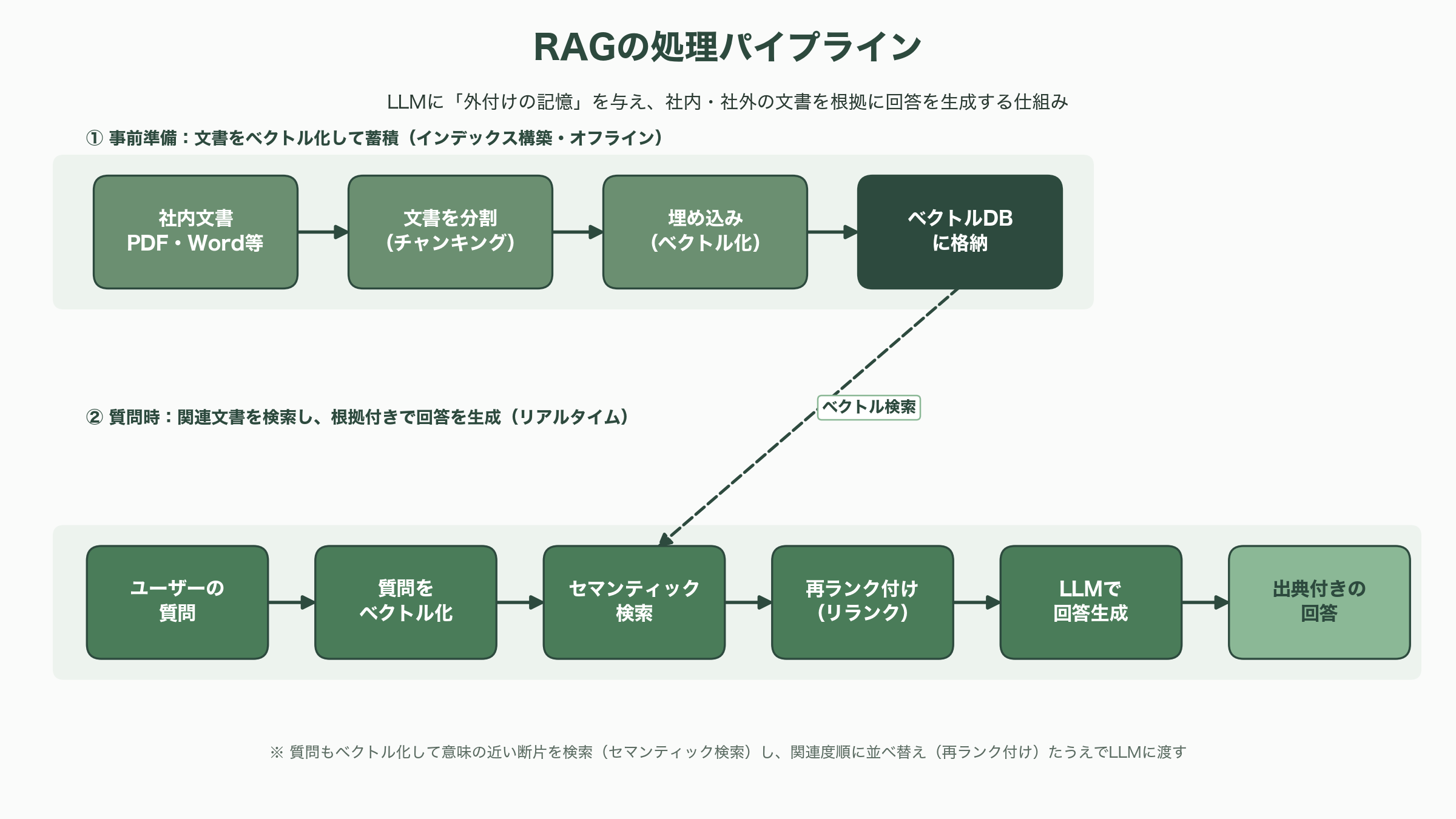
実装面では、RAGは複数の工程の連鎖でできている。文書を適切な長さの断片に分割し(チャンキング)、各断片を意味を表す数値ベクトルへ変換し(埋め込み)、それをベクトルデータベースに格納する。質問が来たら質問もベクトル化し、意味的に近い断片を検索(セマンティック検索)し、必要なら関連度の高い順に並べ替え(再ランク付け)、最終的にそれらをLLMへ渡して出典付きの回答を生成する。問題は、この一見シンプルな流れを「本番品質」で安定運用するのが、想像以上に難しいという点にある。
「フルマネージドRAG」という考え方 ― 何が"丸ごと"任せられるのか
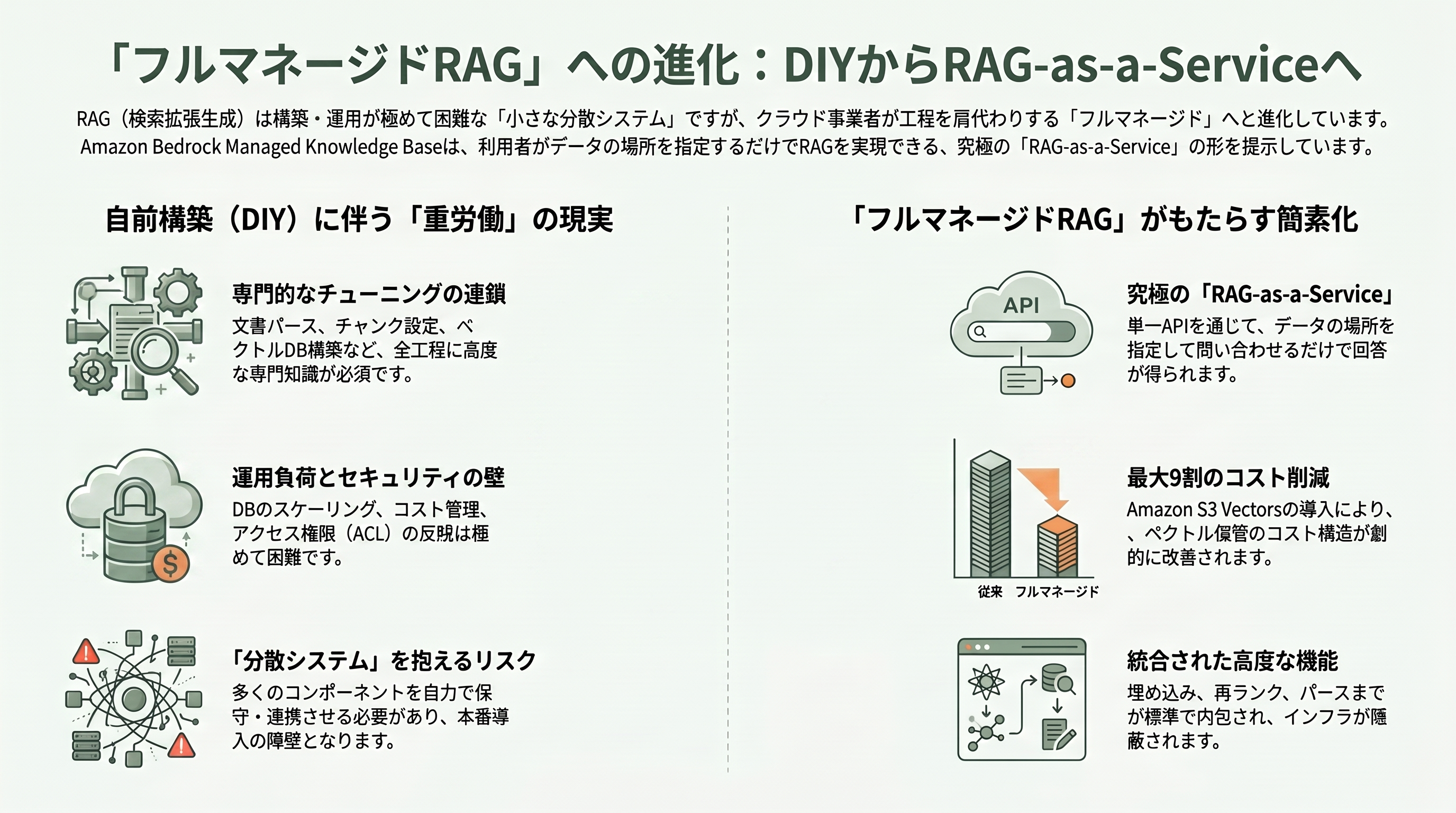
RAGは「デモを作るのは簡単だが、本番に載せるのは難しい」技術の代表格とされてきた。前節で挙げた工程のひとつひとつが、それぞれ専門的なチューニングと運用負荷を伴うからだ。文書のパースは、PDFの表・画像・スキャン文書になると途端に難航する。チャンクの長さや重なりの設定次第で検索精度が大きく揺れる。埋め込みモデルの選定、ベクトルデータベース(Pinecone、OpenSearch、PostgreSQLのpgvectorなど)の構築・スケーリング・コスト管理、LangChainやLlamaIndexといったオーケストレーション・フレームワークの保守、検索結果をどうプロンプトに組み込むか――どれも一筋縄ではいかない。さらに、誰がどの文書を見てよいかというアクセス権限(ACL)を検索結果に正しく反映させる仕組みまで含めると、自前構築(DIY)のRAGは小さな分散システムをまるごと運用するに等しい。
「フルマネージドRAGサービス」とは、この一連の重労働をクラウド事業者側が肩代わりし、利用者は「データのありかを指定して、問い合わせを投げるだけ」で根拠付き回答を得られるようにしたものを指す。RAGの提供形態は、大きく三段階のグラデーションで捉えると整理しやすい。最も手前にあるのが、すべてを自分で組む自己ホスト型のDIY。中間が、ベクトル検索や埋め込みなど一部を managed コンポーネントとして借りつつ、組み合わせは自分で設計するパターン。最も奥が、取り込みから検索・生成までを単一APIに封じ込めた完全な「RAG-as-a-Service」である。今回の Amazon Bedrock Managed Knowledge Base は、この最も奥のカテゴリを、ハイパースケーラーが本気で取りに来た事例と言える。
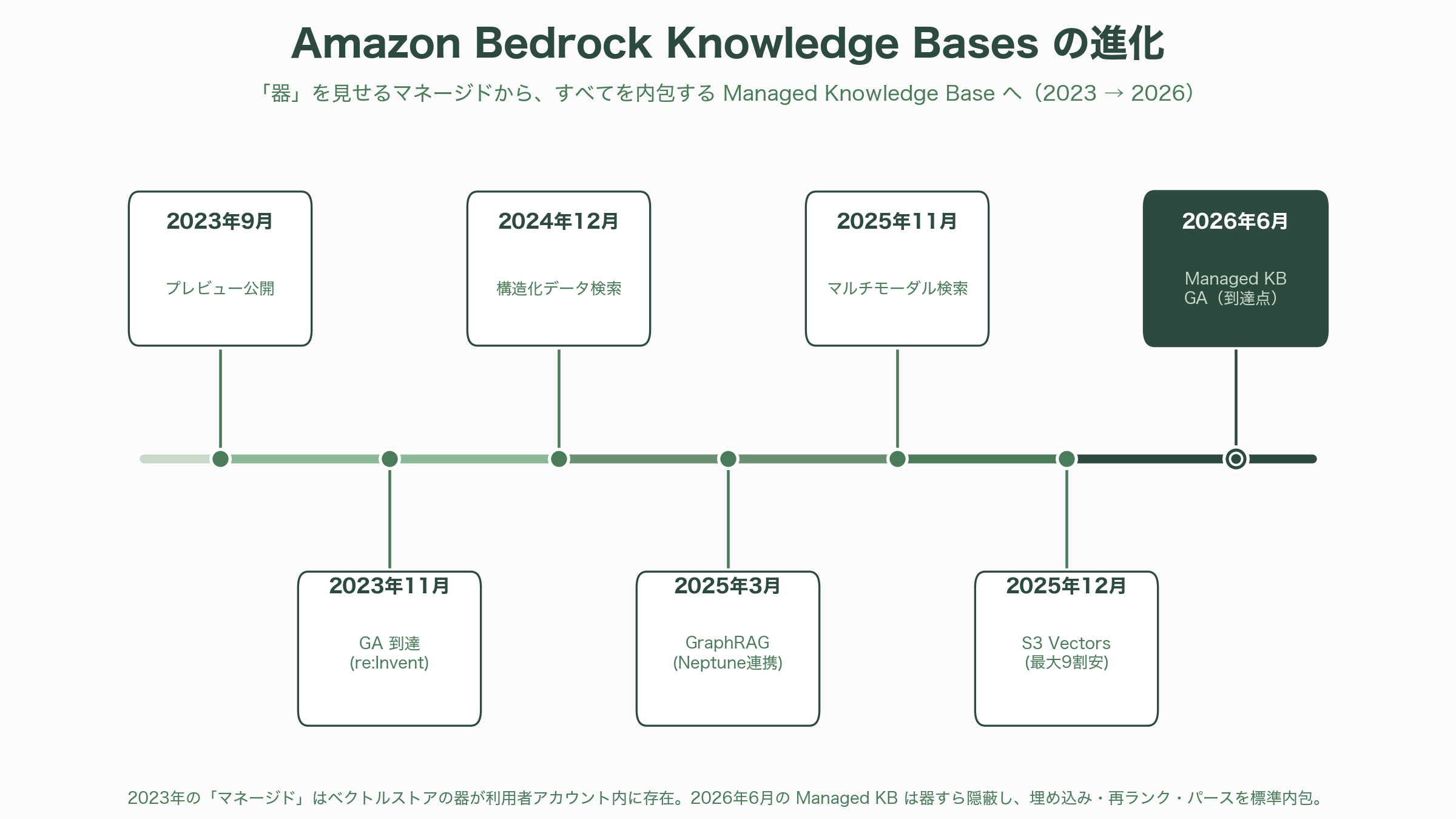
ここで、AWS自身の歩みを振り返ると進化の方向性がよく見える。前身の Amazon Bedrock Knowledge Bases は2023年9月にプレビュー、同年11月の re:Invent でGAに達したが、当時の「マネージド」は、AWSが利用者のアカウント内に Amazon OpenSearch Serverless のベクトルインデックスを自動作成して埋め込みと検索を肩代わりする、というレベルだった。つまり、ベクトルストアの「器」は依然として利用者のアカウントに存在し、埋め込みモデルの選択も利用者側に残っていた。その後も構造化データ検索(2024年12月)、GraphRAG(2025年3月、Amazon Neptune Analytics連携)、マルチモーダル検索(2025年11月)と段階的に機能を重ね、2025年12月には OpenSearch Serverless 比で最大9割安いとされる「Amazon S3 Vectors」を投入して、ベクトル保管のコスト構造そのものを書き換えにかかった。今回の Managed Knowledge Base は、その延長線上で「器」すら利用者から見えなくし、埋め込み・再ランク・パースまで標準で内包した、到達点としての一手である。
Amazon Bedrock Managed Knowledge Base の中身
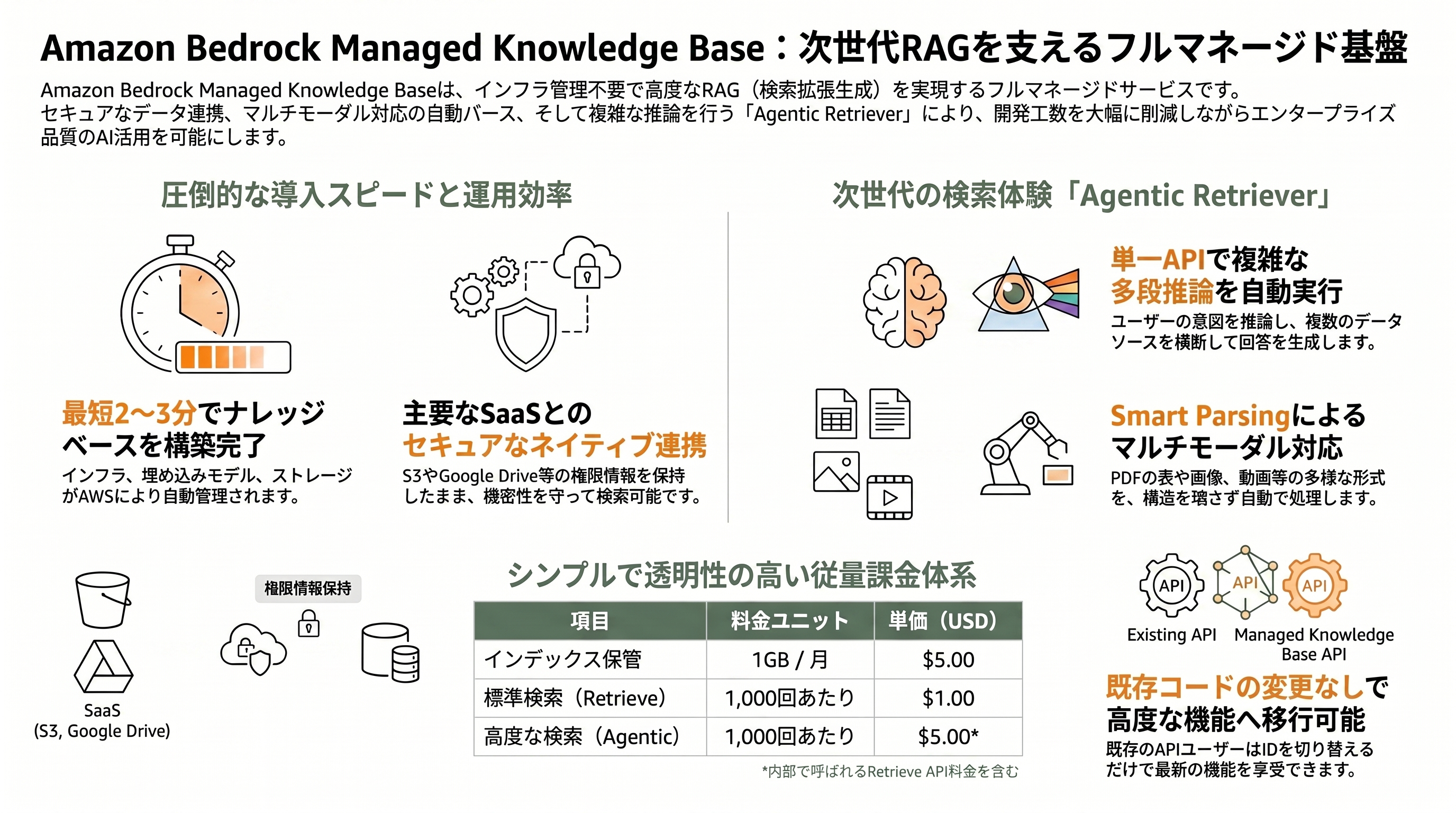
新サービスは、利用者の関与度に応じて二つの型を持つ。AWSがインフラを全面的に管理する「Managed Knowledge Base(MANAGED型)」と、自前のベクトルストアを接続して制御権を保持する「Custom Knowledge Base」である。今回GAの主役は前者で、埋め込みと再ランクには標準でサービス管理モデルが使われ(自前モデルの指定も可能)、ストレージも自動管理される。Classmethodの技術ブログ「DevelopersIO」の検証では、S3をデータソースに指定した場合、Bedrockコンソールからのナレッジベース作成が「2〜3分で完了した」と報告されており、運用の軽さが具体的な手触りとして示されている。
6つのネイティブコネクタとSmart Parsing
データの取り込み口として、Amazon S3、SharePoint、Confluence、Google Drive、OneDrive、Web Crawler の6種類のネイティブコネクタが用意される。これらは単にファイルを引き込むだけでなく、SaaSアプリ側の「アクセス権限(permissions)」も併せて取り込む点が、エンタープライズ用途では決定的に重要だ。誰がどの文書を閲覧できるかという情報を保持したまま検索に反映できれば、「権限のないユーザーに機密文書の内容が漏れる」という、社内RAG最大の事故を構造的に防ぎやすくなる。
取り込んだデータは「Smart Parsing」が処理する。これは、データ種別とコネクタごとに最適なパース戦略を自動判定する機能で、コネクタ固有のデータモデルによってメタデータ・埋め込み画像・スレッドの文脈を保持し、テキスト・画像・音声・動画・多言語といったマルチモーダルなコンテンツを、抽出とキャプション付けによって扱う。チャンキングも基盤モデルに文書構造を理解させて最適化する。従来は開発者が頭を悩ませてきた「PDFの表や画像をどう壊さずに取り込むか」という難所を、サービス側が肩代わりする設計だ。
Agentic Retriever ― 単一APIで多段検索をこなす
機能面で最も新しいのが「Agentic Retriever(エージェンティック・リトリーバー)」である。従来の素朴なRAGは「質問に意味的に近い断片を一発で引く」だけだったが、Agentic Retriever は利用者の意図を推論し、どのデータソースを引くべきかを判断し、複数のナレッジベースをまたいでクエリを計画し、途中結果を評価しながら再ランク付けを行い、必要な深さと広さの情報が揃うまで反復する。しかもこれらを、オーケストレーション用のコードを一切書かずに単一のAPI呼び出しで完結させる。
AWSが挙げる例がわかりやすい。「機械学習プラットフォームチームのクラウドインフラ予算はいくらか」という問いと、「当社の経費規程では年間契約の前払いは認められているか」という問いを組み合わせて答えるには、予算管理文書と経費規程という別々の文書群を横断し、複数のホップ(多段推論)をこなす必要がある。Agentic Retriever はこの種の複合質問を、利用者から複雑さを隠したまま処理する。冒頭で触れた「エージェンティックAIの時代」という旗印が、ここで具体的な製品機能として結実している。
料金体系と既存資産との互換性
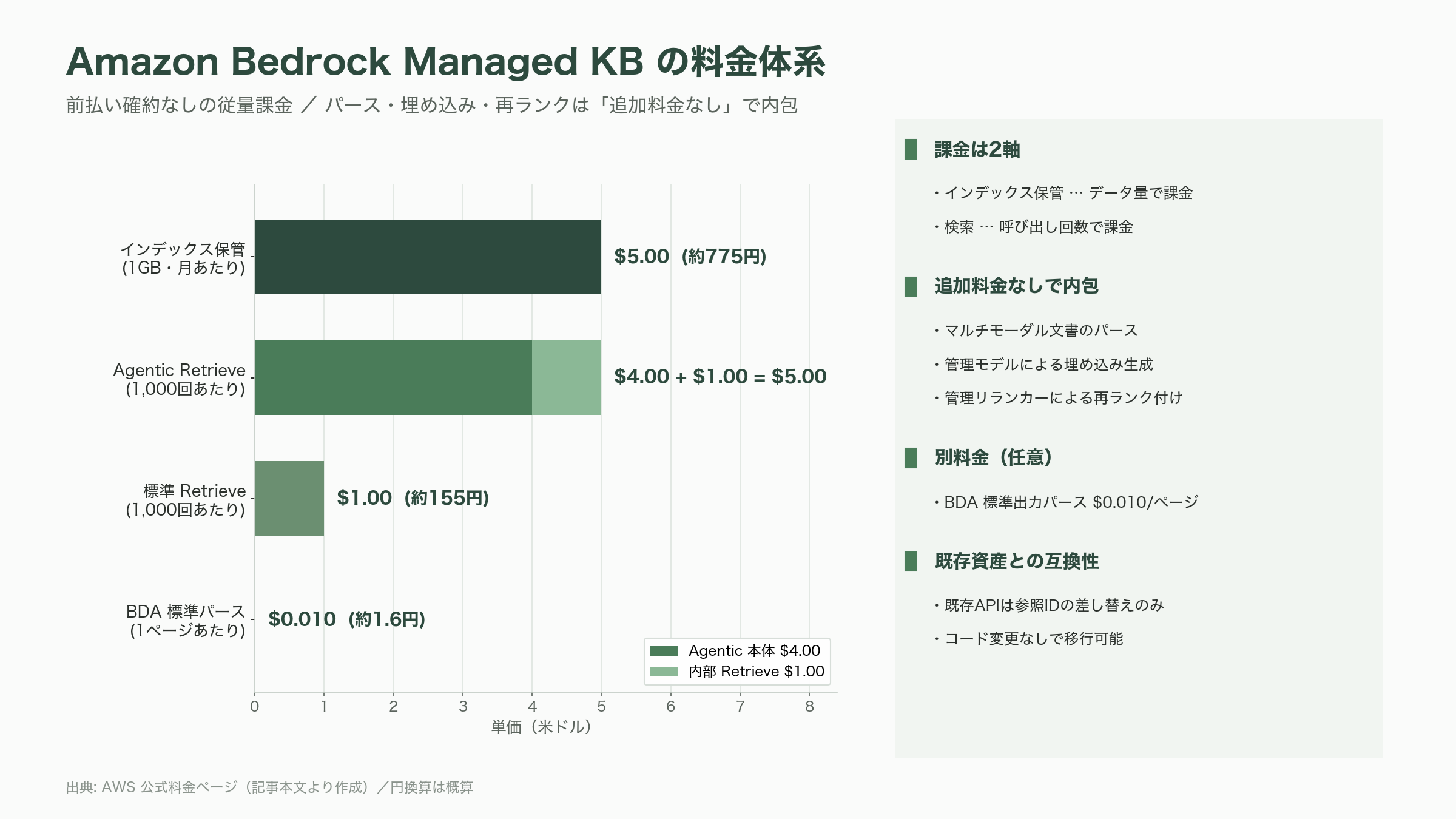
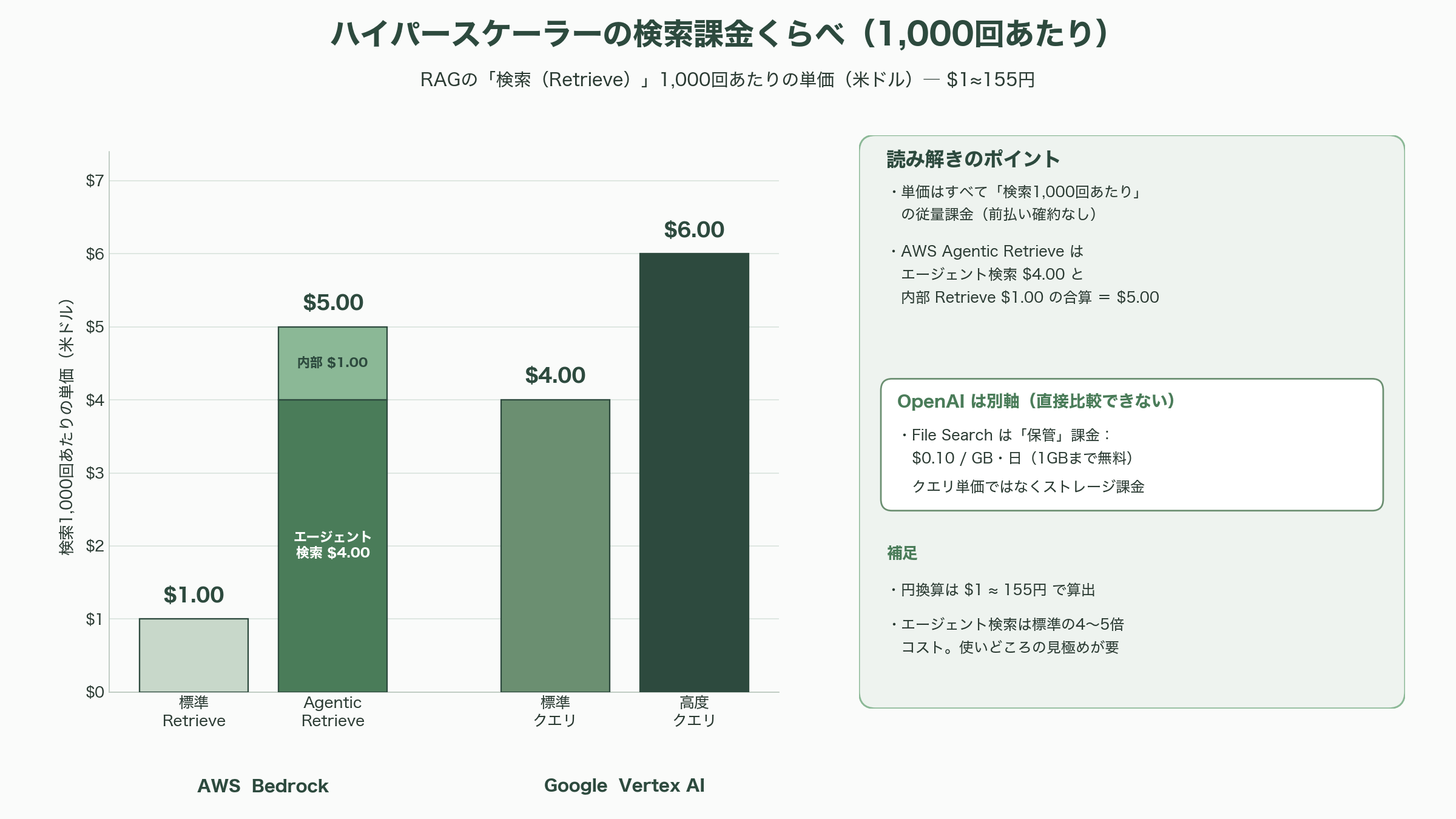
料金は前払いの確約なしの従量課金で、AWS公式の料金ページによれば二つの軸で構成される。第一にインデックス保管で、生データ1GBあたり月額5.00ドル(約775円)。第二に検索で、標準のRetrieve APIが1,000回あたり1.00ドル(約155円)、Agentic Retrieve APIは1,000回あたり4.00ドル(約620円)に、内部で呼ばれる基礎的なRetrieve API分の1,000回あたり1.00ドル(約155円)が加算される。注目すべきは、マルチモーダル文書のパース、管理モデルによる埋め込み生成、管理リランカーによる再ランク付けが「追加料金なし」で含まれる点だ。なお、Knowledge Bases経由で Bedrock Data Automation の標準出力パースを使う場合は1ページあたり0.010ドル(約1.6円)が別途かかる。
既存ユーザーへの配慮も周到だ。すでに Bedrock Knowledge Bases のAPI(Retrieve、StartIngest、StopIngest、IngestKnowledgeBaseDocuments)を使っている開発者は、参照先を新しいナレッジベースのIDに切り替えるだけで、コード変更なしに移行できる。さらに Managed Knowledge Base は、AWSのエージェント基盤「AgentCore」のゲートウェイにネイティブのターゲットとして統合され、標準のモデルコンテキストプロトコル(MCP)を公開する。これにより、Strands Agents、LangChain、CrewAI、LlamaIndex、LangGraph といったMCP対応フレームワークのクライアントから、ナレッジベースが「ツール」として自動的に発見・利用される。RAGを単体の検索機能ではなく、エージェントが呼び出す部品として標準化した点に、AWSの狙いが透けて見える。
導入ユースケースとベストプラクティス

AWSが想定する代表的なユースケースは、社員向けアシスタント(人事・情報システムのヘルプデスク)、カスタマーサポートの自動化、そしてテキスト・動画・音声・画像にまたがるマルチモーダルなナレッジベースである。いずれも「散在する社内知識を、権限を保ったまま、根拠付きで引き出す」という共通項を持つ。たとえば、就業規則・福利厚生・IT手順書を横断する社内ヘルプデスク、製品マニュアルと過去チケットを束ねたサポートボット、設計図面や検査動画まで含めた製造現場のナレッジ検索――こうした用途が、最小限のコードで立ち上がる。
もっとも、「丸ごと任せられる」ことと「何も考えなくてよい」ことは同義ではない。本番品質を狙うなら、いくつかの定石を踏まえる必要がある。まず大前提として、入力データの品質が回答品質の天井を決める。古い文書・重複・矛盾を放置すれば、どれほど高度な検索でも「ゴミを入れればゴミが出る」だけだ。次に、純粋なベクトル検索だけに頼らず、キーワード検索を併用する「ハイブリッド検索」が有効な場面が多い。Microsoftが自社のAzure AI Searchについて指摘するとおり、業務文書には製品コード・法的識別子・口座番号・日付・略語・完全一致句が頻出し、これらは埋め込みベクトルでは正確に保持しきれないことがあるためだ。Managed Knowledge Base はハイブリッド検索と再ランク付けを標準で備えるが、その挙動を理解して使うかどうかで結果は変わる。
運用前にもっとも投資すべきは、評価(エバリュエーション)の仕組みである。正解の出典がひも付いたテスト質問集をあらかじめ用意し、どの種類の問いで検索やプロンプトが失敗しているかを継続的に検知できるようにしておくこと――この基盤をデプロイ前に作っておく方が、ユーザーからの苦情で失敗に気づくよりはるかに安上がりだ、というのが研究者・実務家に共通する助言である。加えて、前述のアクセス権限の伝播を必ず検証すること、まずは管理デフォルトで始めて指標が要求したときだけカスタマイズすること、そして後述するコスト構造を踏まえてエージェンティック検索の使いどころを見極めることが、現実的なベストプラクティスとなる。
精度・課題・コスト感 ― 「丸ごと任せる」ことの裏側
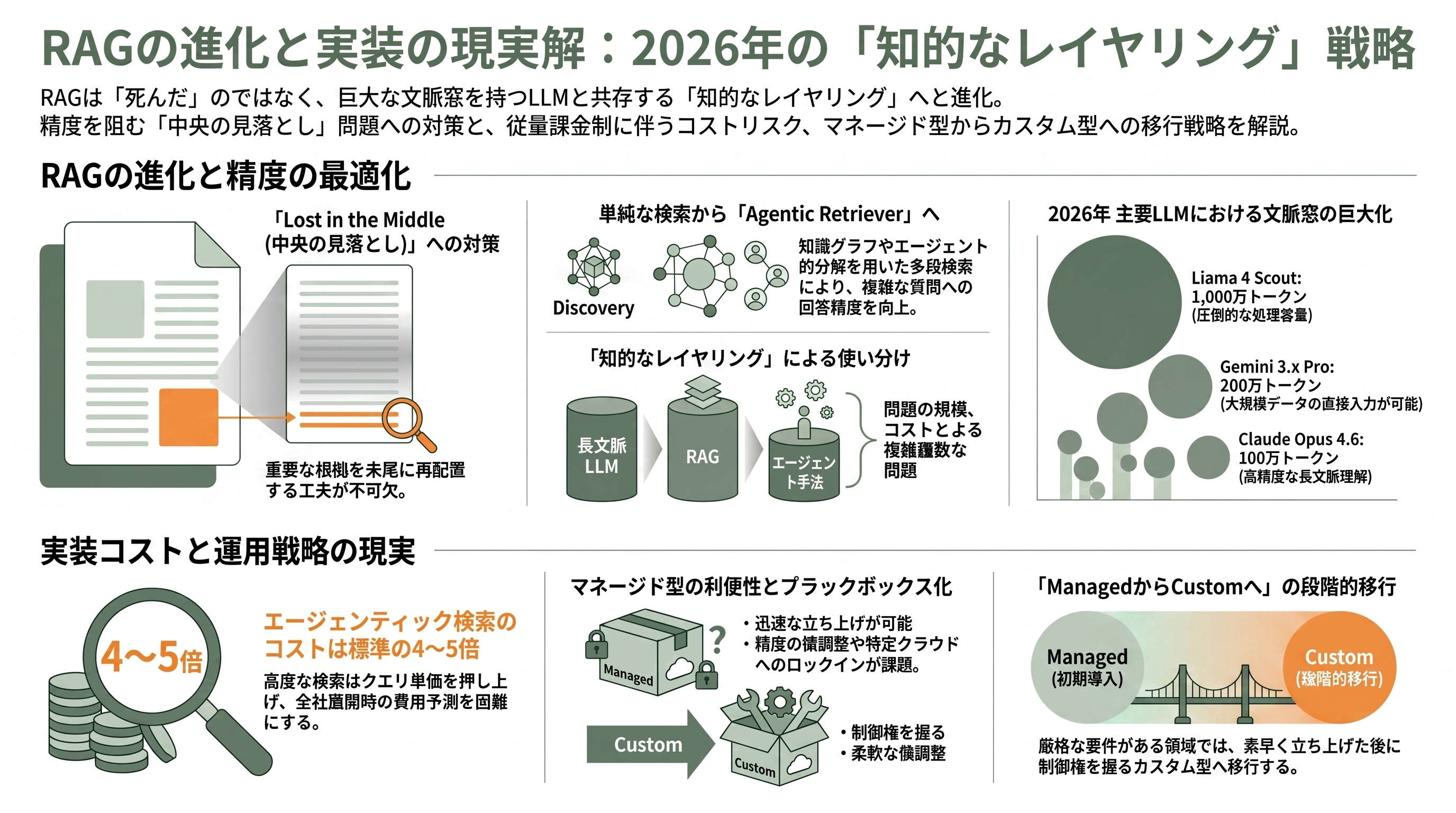
RAGはハルシネーションを「減らす」技術であって「ゼロにする」技術ではない。回答の正確さは、結局のところ検索フェーズで正しい根拠を引けたかどうかに律速される。誤った断片を引けば、LLMはその誤りに「忠実に」誤答を生成してしまう。さらに、長い文脈をLLMに渡す際には「Lost in the Middle(中央の見落とし)」と呼ばれる現象が立ちはだかる。スタンフォード大学とワシントン大学の研究が示したとおり、LLMは入力の冒頭と末尾の情報を重視し、中央に置かれた情報への注意が薄れるU字型の性能曲線を描く。検索した断片をただ大量に詰め込めば精度が上がるわけではなく、むしろ情報の希釈や位置バイアスで劣化しうる。重要な断片を末尾に再配置するといった工夫が効くのはこのためだ。
ここで避けて通れないのが、2026年に何度も再燃した「RAGは死んだのか(RAG is dead)」論争である。論拠は単純で、文脈窓(コンテキストウィンドウ)が巨大化した今、関連文書を全部プロンプトに詰め込めばRAGなど要らない、というものだ。実際、2026年時点の主要モデルの文脈窓は桁違いに広い――Claude Opus 4.6 / Sonnet 4.6 がいずれも100万トークン、Gemini 3.x Pro が200万トークン、Llama 4 Scout に至っては1,000万トークンに達するとされる。だが「死んだ」論への反証も明確だ。第一にコストで、巨大な文脈窓に毎回コーパス全体を流し込めば、検索で数千トークンの関連部分だけを渡すRAGに比べ、クエリあたりの費用は桁違いに膨らむ。第二に前述の位置バイアスとレイテンシ(遅延)。第三に、そもそも数百万トークンに収まらない規模の社内データには長文脈だけでは対処できない。2026年の実務家の合意は「RAGは死んだのではなく進化した」であり、長文脈・RAG・エージェント的手法を問題に応じて使い分ける『知的なレイヤリング』へと収束しつつある。Agentic Retriever のような多段検索は、まさにこの進化形の中核だ。実務家の報告では、知識グラフやエージェント的分解を取り入れたRAGは、素朴なチャンク検索に比べて多段質問でのハルシネーションを大きく削減できるとされ、AWSが Agentic Retriever を前面に押し出したのもこの流れに沿っている。
コスト感については、二面で捉える必要がある。表面上の単価――保管1GBあたり月5ドル(約775円)、検索1,000回あたり1〜5ドル(約155〜775円)――は安価に見える。しかし、これは利用量に正比例して積み上がる従量制であり、全社展開で問い合わせが数千万回規模に達すれば、特にエージェンティック検索(標準の4〜5倍)を多用する設計では費用が読みにくくなる。業界では「クラウドネイティブなRAGはクエリ単位・トークン単位の課金のため、本番ボリュームが見えるまで総額を見積もりにくい」という指摘が共通している。そして「フルマネージド」の最大のトレードオフは、利便性と引き換えに制御権とブラックボックス性を受け入れる点にある。埋め込みモデルやチャンキング、リランカーの細かな挙動を自分で握れない分、精度が出ないときの原因切り分けが難しく、特定クラウドへのロックインも進む。要件が厳しい領域ほど、Managed型で素早く立ち上げてから、必要に応じて Custom型へ降りていく――という現実的な使い分けが求められる。

群雄割拠のRAG市場 ― ハイパースケーラーと専業勢
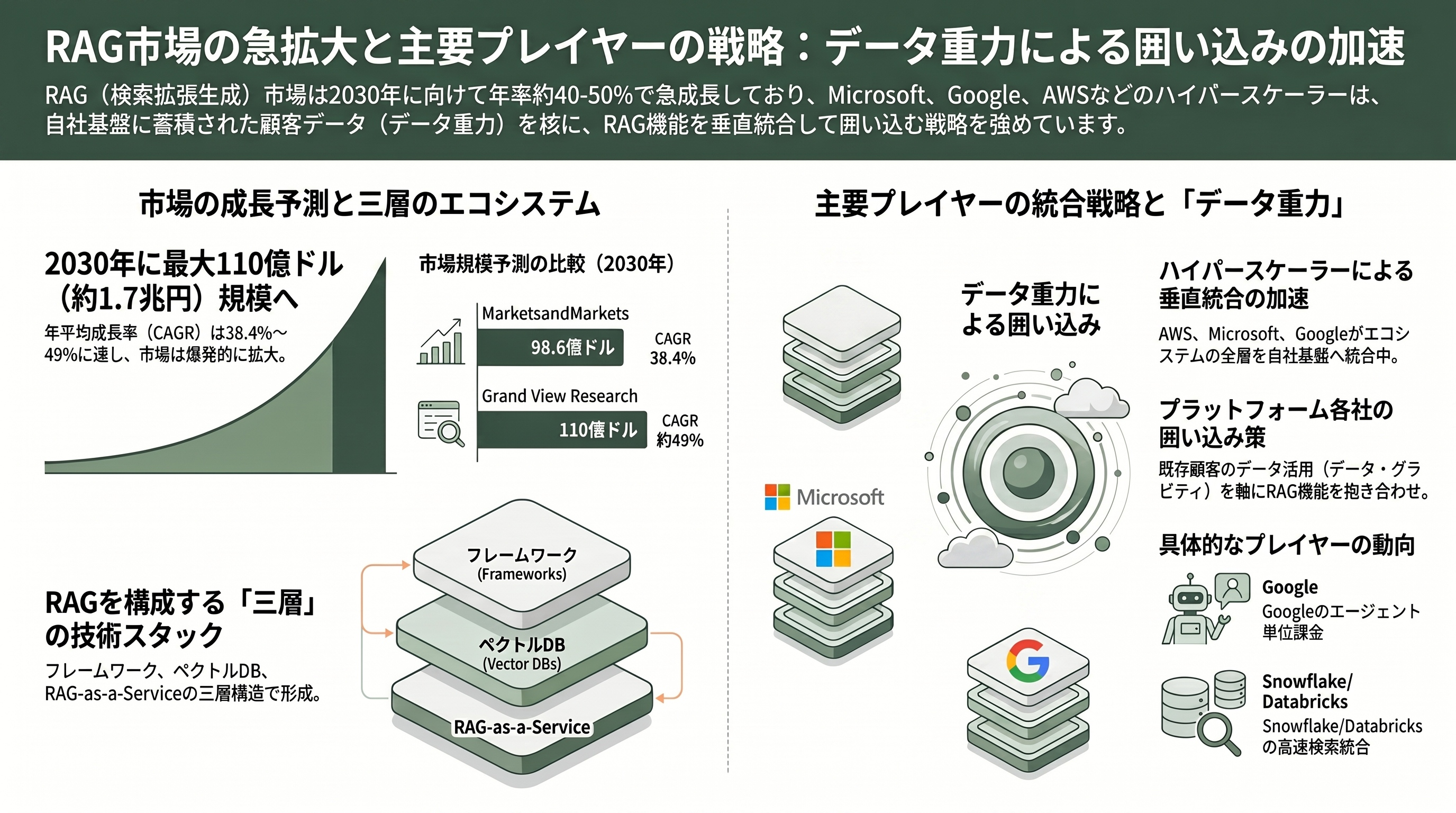
RAG市場の規模感について、アナリストの推計には幅がある。MarketsandMarketsは2025年の19.4億ドル(約3,010億円)から2030年に98.6億ドル(約1兆5,280億円)へ、年平均成長率(CAGR)38.4%で拡大すると見込む。Grand View Researchは2025〜2030年にCAGR約49%で2030年に110億ドル(約1兆7,050億円)規模に達すると予測し、2026年単年の市場規模については各社の推計が27億〜33億ドル(約4,200億〜5,100億円)あたりに分布する。MarketsandMarketsはこの市場を主導するプレイヤーとしてMicrosoft、AWS、Anthropicを挙げている。
エコシステムは三層で捉えると見通しがよい。第一層がLangChain、LlamaIndex、Haystackといったオーケストレーション・フレームワーク、第二層がPinecone、Weaviate、Vespaなどのベクトルデータベース、第三層がVectaraやRagieのような「RAG-as-a-Service」である。今回のAWSの一手は、この三層をハイパースケーラーが垂直統合して飲み込みにかかる動きにほかならない。
ハイパースケーラー勢の布陣を見渡すと、競争の激しさが浮かび上がる。Microsoftは Azure AI Search を中核に据え、ベクトル検索・キーワード検索・トランスフォーマーベースのセマンティック・ランキングを単一のマネージド基盤で統合し、Azure OpenAI と組み合わせて提供する。Googleは2026年の「Cloud Next」で Vertex AI を「Gemini Enterprise(Gemini Enterprise Agent Platform)」へと再編し、旧Vertex AI・Agentspace・Gemini Code Assist Enterprise を統合、エージェント単位の課金とノーコードのビルダーを打ち出した。Vertex AI Searchの検索課金は標準クエリ1,000回あたり4.00ドル(約620円)、高度クエリで6.00ドル(約930円)とされる。OpenAIは Responses API の File Search を通じて、ベクトルストア保管を1GB・1日あたり0.10ドル(約16円、1GBまで無料)で提供する。さらにデータ基盤勢として、Snowflakeは「Cortex Search」でベクトル検索とキーワード検索を倉庫内で統合し200〜300ミリ秒の応答を謳い、Databricksは「Mosaic AI Vector Search」と既にGA済みの「Mosaic AI Agent Framework」で、データとMLパイプラインに密結合したRAGを提供する。各社に共通するのは「自社プラットフォームに蓄積された顧客データという重力(データ・グラビティ)を、RAGの抱き合わせで囲い込む」という戦略だ。
シリコンバレーVCの視点 ― 価値はどこへ移るのか
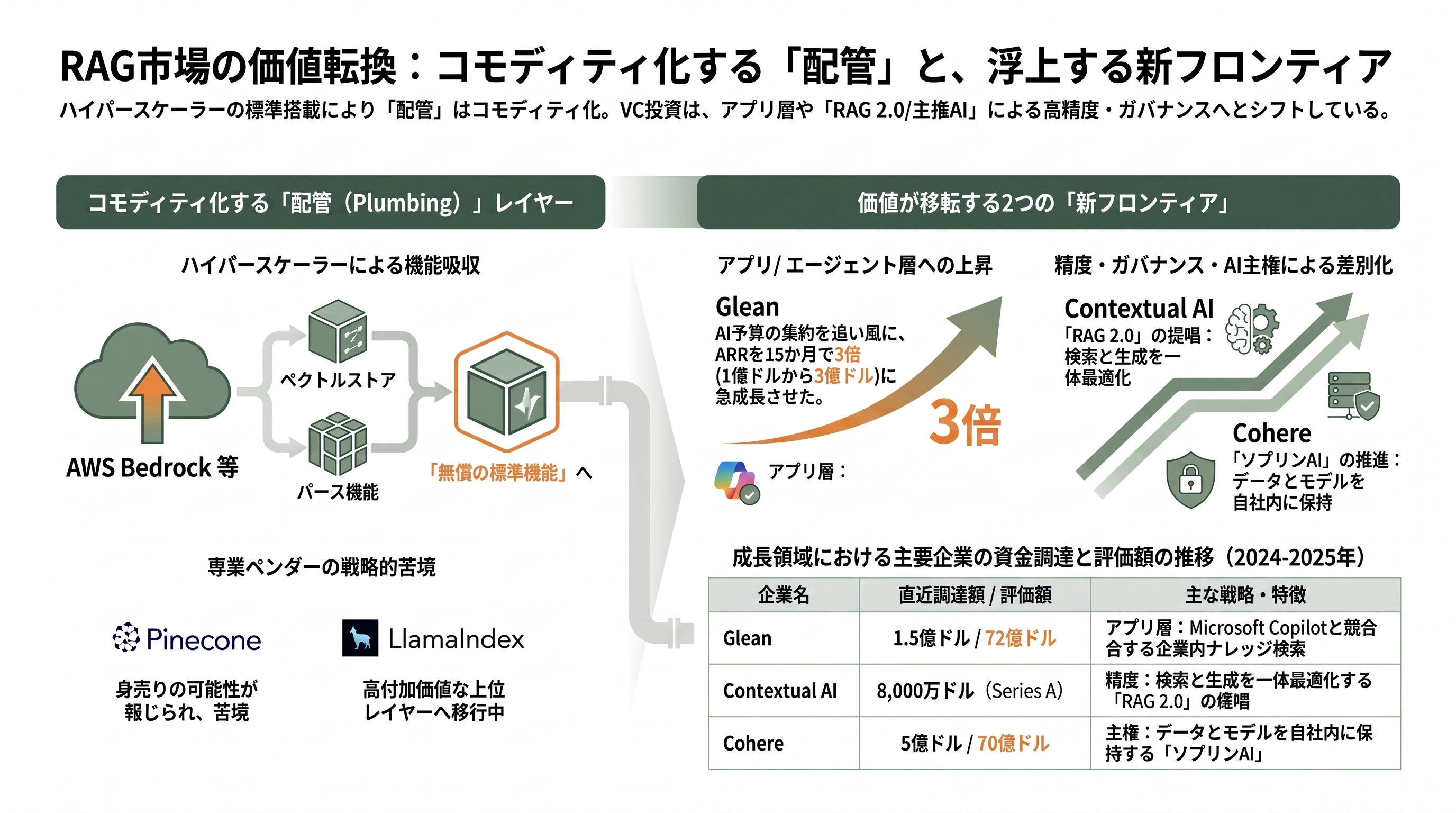
ベンチャーキャピタルの目線でこの発表を読み解くと、見えてくるのは「コモディティ化のフロンティアが一段上がった」という構図である。Bedrock Managed Knowledge Base がパース・埋め込み・再ランクを標準で無償内包し、ベクトルストアの存在すら隠蔽したということは、これまで独立したスタートアップが価値を主張してきた「RAGの配管(plumbing)」レイヤーが、ハイパースケーラーの基本機能へと吸収されつつあることを意味する。
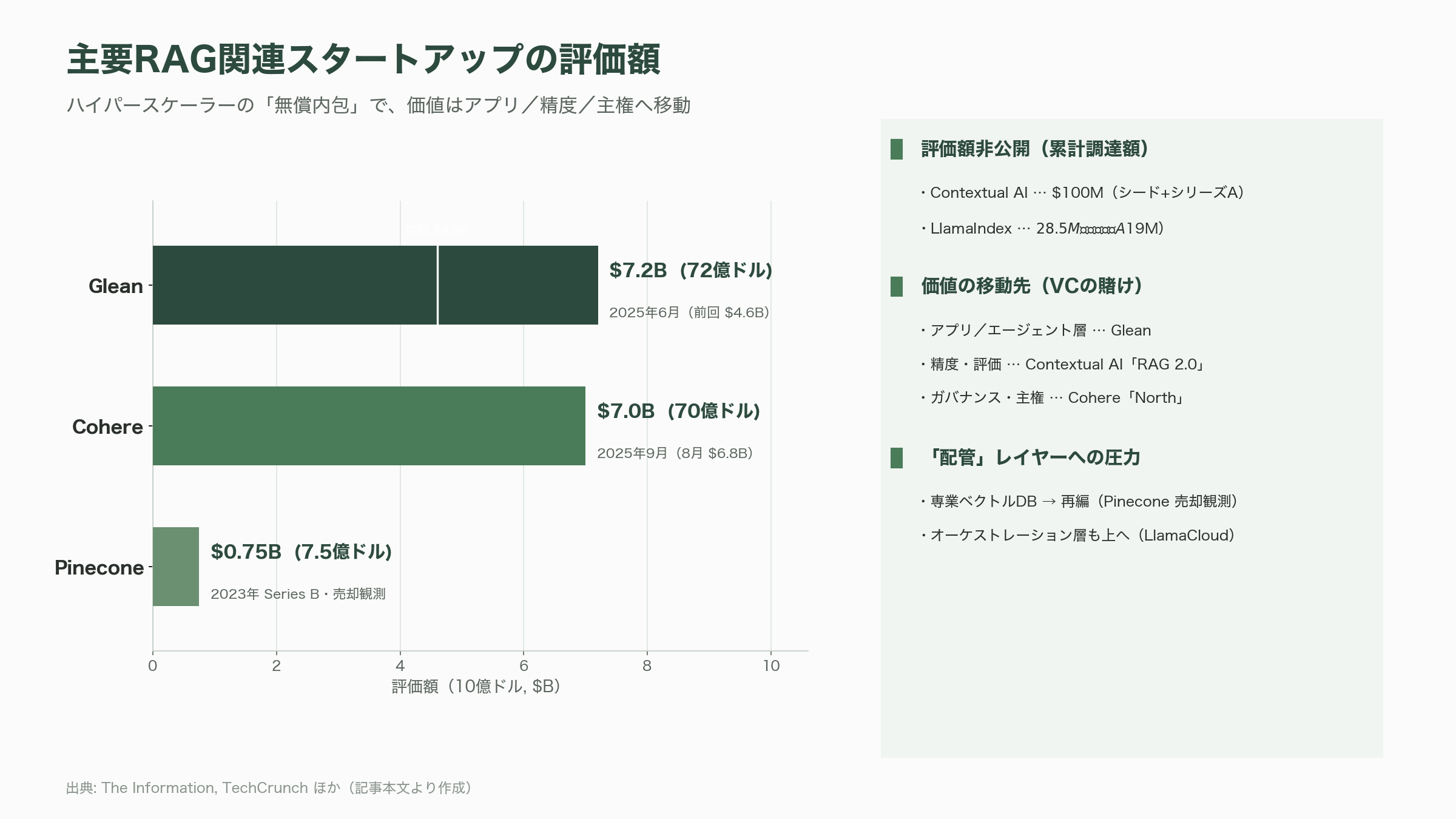
その圧力を最も直接に受けるのが、専業ベクトルデータベースだ。象徴的なのがPineconeである。同社は2023年にAndreessen Horowitz(a16z)主導で1億ドル(約155億円)のシリーズBを評価額7.5億ドル(約1,160億円)で調達し、累計調達額は1.38億ドル(約214億円)とされるが、The Informationの報道によれば、競争激化のなか身売り(売却)の可能性を探っているという。創業者エド・リバティ(Edo Liberty)氏が会長格に退きアッシュ・アシュトシュ(Ash Ashutosh)氏をCEOに迎えた経営体制の刷新も、単独での成長から次の局面への移行を示唆する動きと読める。オーケストレーション層のLlamaIndexも、2025年3月にNorwest Venture PartnersとGreylock主導で1,900万ドル(約29億円、累計2,850万ドル=約44億円)のシリーズAを調達し、自らもマネージドサービス「LlamaCloud」(月額50ドル=約7,800円から)やPDFパーサー「LlamaParse」へと事業の重心を上へ動かしている。配管そのものでは戦えない、という危機感の表れだ。
では価値はどこへ移るのか。VCの賭けは大きく二方向に向かっている。ひとつはアプリケーション/エージェント層への上昇だ。その筆頭がGleanで、同社は2025年6月にWellington Management主導で1.5億ドル(約233億円)を評価額72億ドル(約1兆1,160億円)で調達した(前回2024年9月は46億ドル=約7,130億円)。同社のARR(年間経常収益)は2025年初頭の1億ドル(約155億円)から同年12月に2億ドル(約310億円)、そして2026年5月下旬に3億ドル(約465億円)へと約15か月で3倍に伸び、TechCrunchはこの急成長の背景に「AI予算の削減(複数ツールの置き換え)」という訴求力があると報じている。Microsoft Copilotと正面から競合する企業内ナレッジ・アシスタントという、最も上位のレイヤーで価値を握る賭けである。
もうひとつは精度・ガバナンス・主権による差別化だ。ここで象徴的なのがContextual AIである。共同創業者のドゥエ・キーラ(Douwe Kiela)氏は、まさに前述の2020年RAG論文の共著者であり、「RAGの発明者の一人がRAG専業企業を率いる」という構図そのものが投資家の関心を引いた。同社は2023年6月にBain Capital Ventures主導で2,000万ドル(約31億円)のシードを、2024年8月にはGreycroft主導で8,000万ドル(約124億円)のシリーズAを調達。後者にはNVIDIAのNVentures、Snowflake Ventures、HSBC Ventures、Bezos Expeditionsといった事業会社系・著名投資家が名を連ねた。同社が掲げる「RAG 2.0」は、検索器と生成器を一体で最適化し、ハルシネーションを抑えて高精度な企業向け回答を出すという思想で、ハイパースケーラーの汎用マネージドRAGとは別軸の価値を主張する。基盤モデル側からもCohereが、Rerank・Embedといった「他社のRAGを精度面で支える」モデル群と、企業向けワークスペース「North」を武器に、データとモデルを自国・自社内に保持する『AI主権(ソブリンAI)』を前面に押し出す。同社は2025年8月に評価額68億ドル(約1兆540億円)で5億ドル(約775億円)を調達し、9月の1億ドル(約155億円)の追加クローズで評価額は70億ドル(約1兆850億円)に達した。2025年のARRは約2.4億ドル(約372億円)で目標の2億ドルを上回ったとされる。
総じてVCの読み筋はこうだ――RAGの『配管』レイヤーは利益率の圧縮と業界再編(M&A)に向かい、価値は「アプリ/エージェント」「精度・評価」「ガバナンス・主権」へと染み出す。ハイパースケーラーによる『無償化』の一手は、導入障壁を下げて市場全体(TAM)を膨らませる追い風であると同時に、中間レイヤーをコモディティ化させる逆風でもある、という二面性を持つ。
今後の展望 ― いつ、何が起きるのか
短期的に最大の節目となるのは、例年11月末から12月初頭に開催されるAWSの年次イベント「re:Invent」だろう。2023年と同様、サミットでGAした機能群を re:Invent でさらに拡張するのがAWSの定石であり、コネクタの追加、対応リージョンの拡大、GraphRAGや構造化データ検索といった既存機能のManaged型への統合、AgentCoreとの一層の密結合などが、2026年末に向けて重ねられる可能性が高い。Managed Knowledge Base がMCP経由でエージェントのツールとして標準化された以上、次の主戦場は「エージェントがどれだけ賢く社内知識を使い回せるか」へ移る。
技術トレンドとしては、Agentic RAGが事実上の標準になっていく。素朴な一発検索から、計画・反復・自己評価を伴う多段検索へ――この移行は2026年を通じて加速し、知識グラフ(GraphRAG)やマルチモーダルとの組み合わせが企業導入の本流になると見込まれる。同時に、インフラ層では価格下落圧力が続き、差別化の軸は「いかに正確で、ガバナンス可能で、説明責任を果たせるか」という評価・運用の質へとさらに移る。
市場構造の面では、専業ベクトルDBや中間ミドルウェアの再編(Pineconeの売却観測がその試金石)と、アプリケーション層の高成長(Gleanの3億ドルARR)という二極化が一段と鮮明になる公算が大きい。注視すべきは、Googleの「Gemini Enterprise」のエージェント単位課金がどこまで企業に浸透するか、MicrosoftがCopilotとAzureの組み合わせでどう応戦するか、そしてOpenAIがエンタープライズ向けにどこまで踏み込むかである。RAGはもはや一機能ではなく「エンタープライズAIのインフラ」へと位置づけが変わった。Amazon Bedrock Managed Knowledge Base のGAは、その地殻変動を象徴する2026年前半の一里塚として記憶されることになるだろう。