TPUとは何か
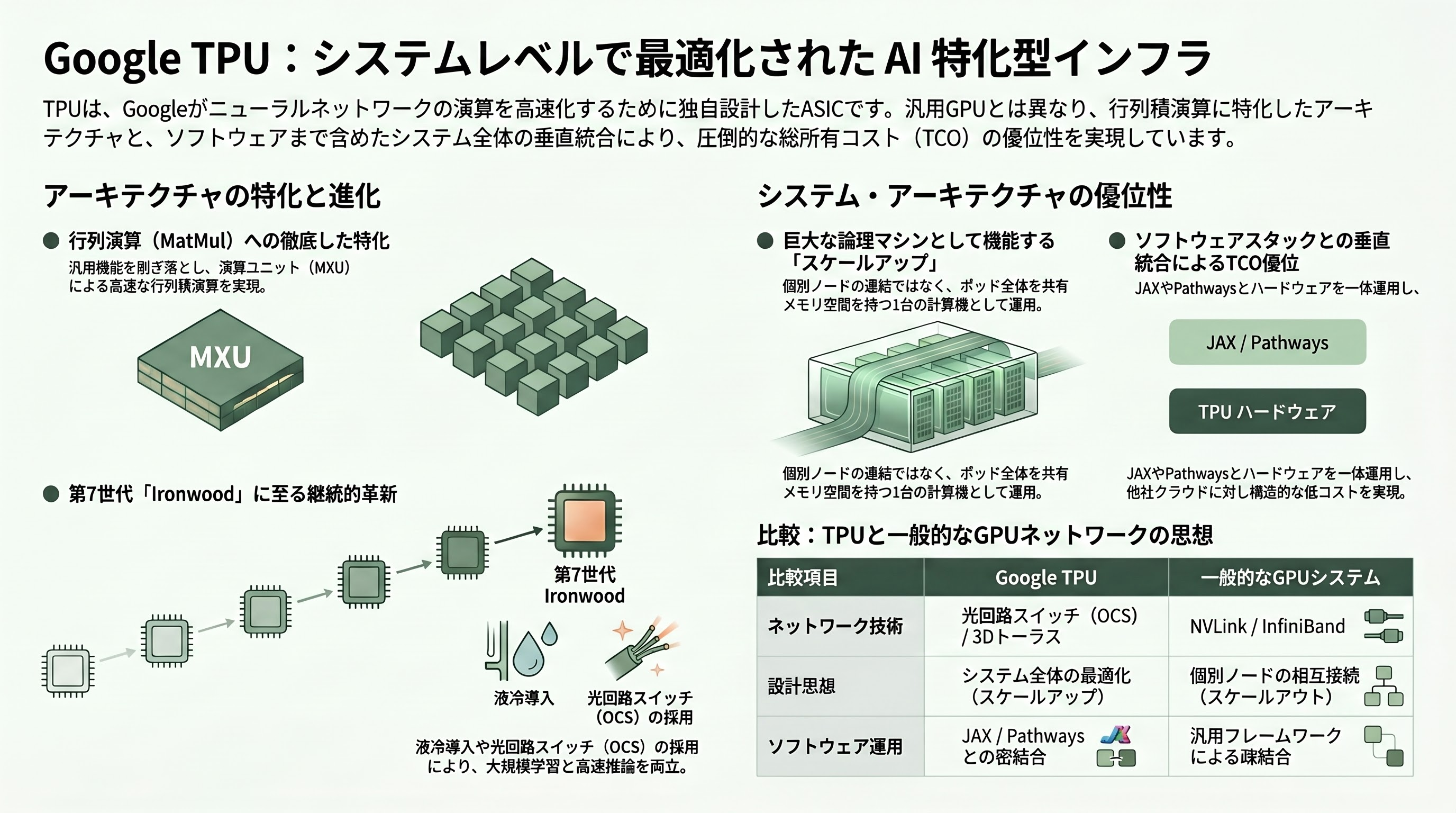
TPU(Tensor Processing Unit)は、Googleが自社のニューラルネットワーク推論と学習を高速化するために設計した独自のASIC(特定用途向け集積回路)で、汎用GPUが備える可変パイプラインやレイトレーシングのような無関係な機能を削ぎ落として行列積演算(MatMul)と縮約演算に振り切ったアーキテクチャを持つ。初代TPUは2015年に社内導入され、当時のCEOサンダー・ピチャイは2016年のGoogle I/Oでその存在を初めて公にした。以降、GoogleはTPU v2でHBMを搭載して学習用に拡張し、v3で液冷を導入、v4とv5で光回路スイッチ(OCS)による3Dトーラス・ファブリックを確立、第6世代「Trillium」と第7世代「Ironwood」で大規模学習と高速推論の両立を目指してきた。
設計面の特徴は、行列演算ユニット(MXU)と呼ばれるシストリックアレイ、HBMによる超広帯域メモリ、そしてポッド全体を1台の論理マシンに見立てる「スケールアップ・ファブリック」にある。Nvidia GPUがNVLinkとInfiniBandを介して個別ノードを束ねるのに対し、TPUはハードウェア・コヒーレントな共有メモリ空間を巨大化させて1ジョブを丸ごと格納する思想で、JAXとPathwaysといったGoogle製ソフトウェアスタックと一体運用される点が他社ASICとの最大の違いである。SemiAnalysisのダイラン・パテルはこれを「マイクロアーキテクチャではなくシステム・アーキテクチャでの優位」と表現し、Microsoft AzureやAmazon EC2に対するGoogle Cloudの構造的な総所有コスト優位の源泉だと位置付けている。
TPU 8t、TPU 8i の衝撃 ― 8世代目で訪れた「分岐点」
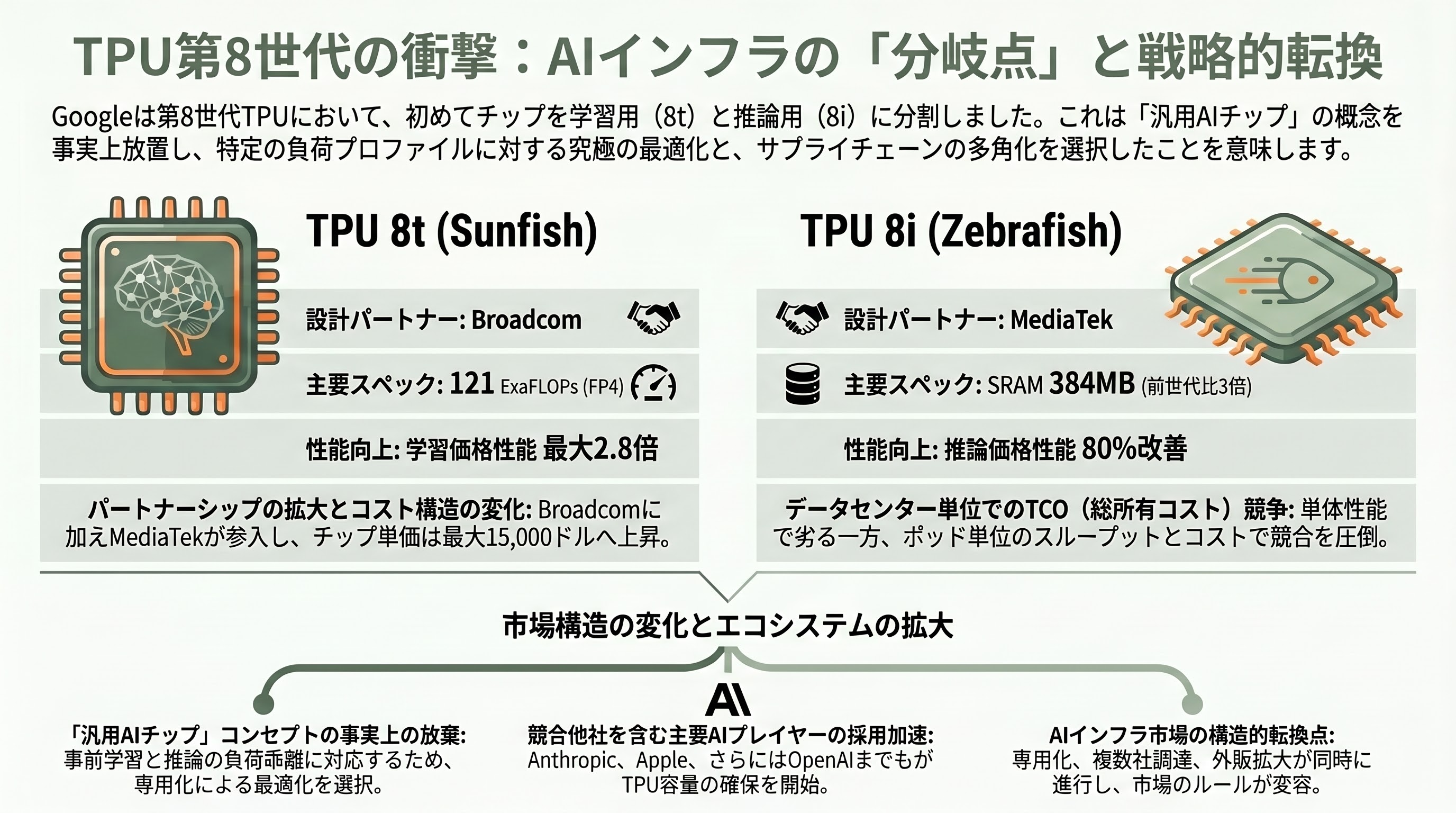
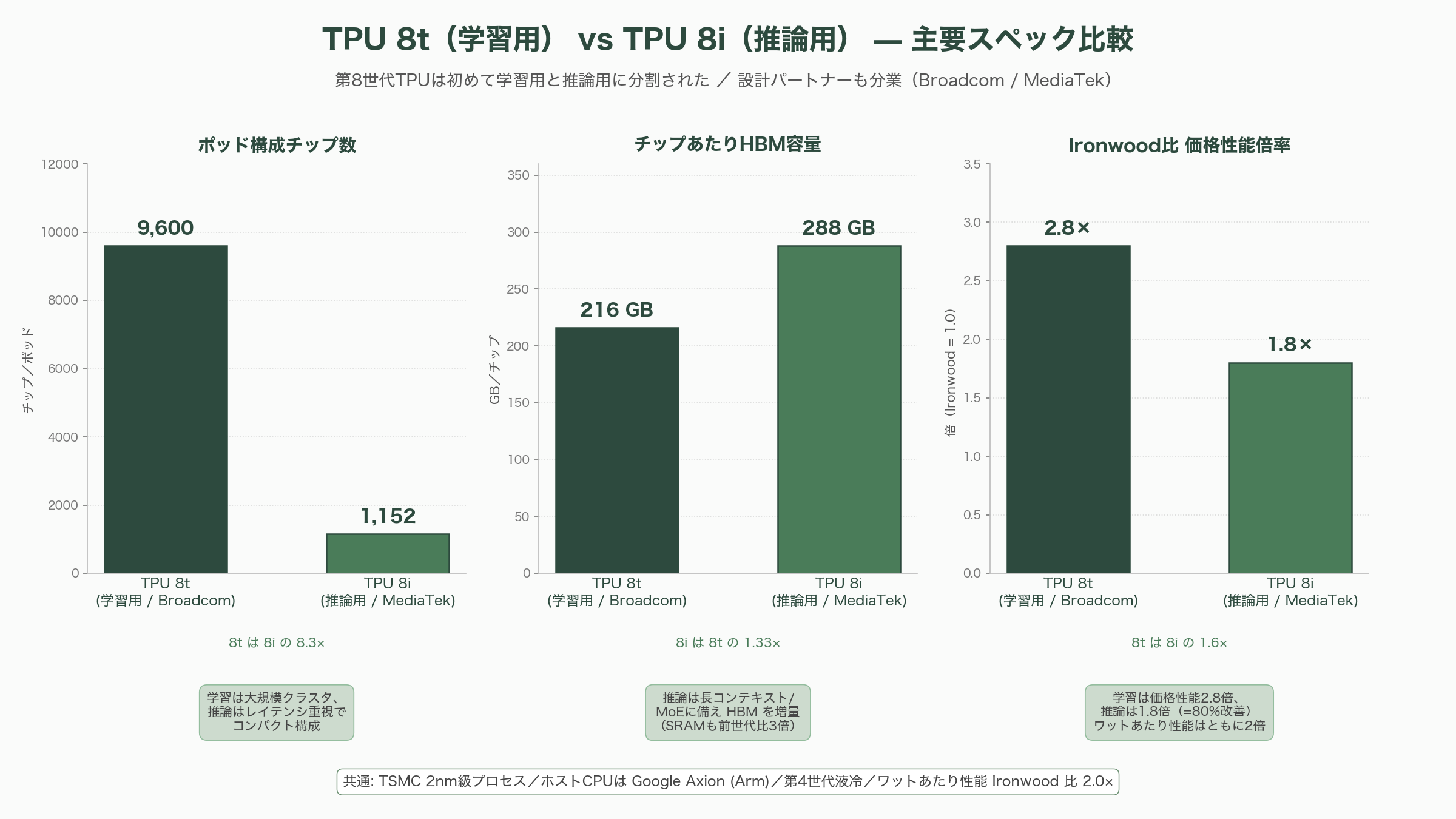
第8世代の最大の論点は、Googleが初めてTPUを1ライン2チップに分割したことにある。学習用の「TPU 8t」(社内コードネーム Sunfish)はBroadcomが設計を主導し、9,600チップで構成されるスーパーポッドが2ペタバイトの共有HBMと121 ExaFLOPs(FP4)を搭載、Ironwood比で学習価格性能を最大2.8倍に引き上げる。一方、推論・推論時推論(リーズニング)用の「TPU 8i」(コードネーム Zebrafish)は新規パートナーMediaTekが設計を担い、1,152チップで構成されるポッドにHBM 288GBとオンチップSRAM 384MB(前世代比3倍)を載せ、Ironwood比で推論価格性能を80%改善した。いずれもチップあたりの絶対演算性能ではNvidia Vera Rubin R200やAMD MI455Xに対しなお3対1のレンジで劣るとされるが、ポッド単位、ひいてはデータセンター単位での総所有コストとスループットでは互角以上に張り合えるとGoogleは主張する。
衝撃の核心は三つある。第一に、Googleが「汎用AIチップ」というコンセプトを実質的に放棄した点である。HyperFRAME Researchはこれを「事前学習とエージェント大量並列推論の負荷プロファイルが乖離し過ぎたことに対する暗黙の自白」と評し、Googleがハイブリッド最適化ではなく専用化に舵を切ったと指摘した。第二に、Broadcomの独占体制が崩れMediaTekが参入した点で、Bank of AmericaのVivek Aryaを筆頭にしたアナリスト陣は、これによりTPU 1個あたりのASPは従来の5,000〜6,000ドル(約77万〜93万円)から12,000〜15,000ドル(約186万〜232万円)へ上振れすると推計している。第三に、Anthropicが最大100万チップを使う最大顧客に位置付けられ、Meta、Apple経由のSiri推論、Citadel Securities、米エネルギー省17国立研究所、そしてOpenAIまでもがTPU容量を確保し始めたことだ。専用化、二社調達、そして外販拡大という三つの動きが同時進行している点が、Cloud Next 2026を「単なる年次イベント」から「AIインフラ市場の構造変化点」へと押し上げている。
技術の掘り下げ ― Boardflyとファブリック設計の革新
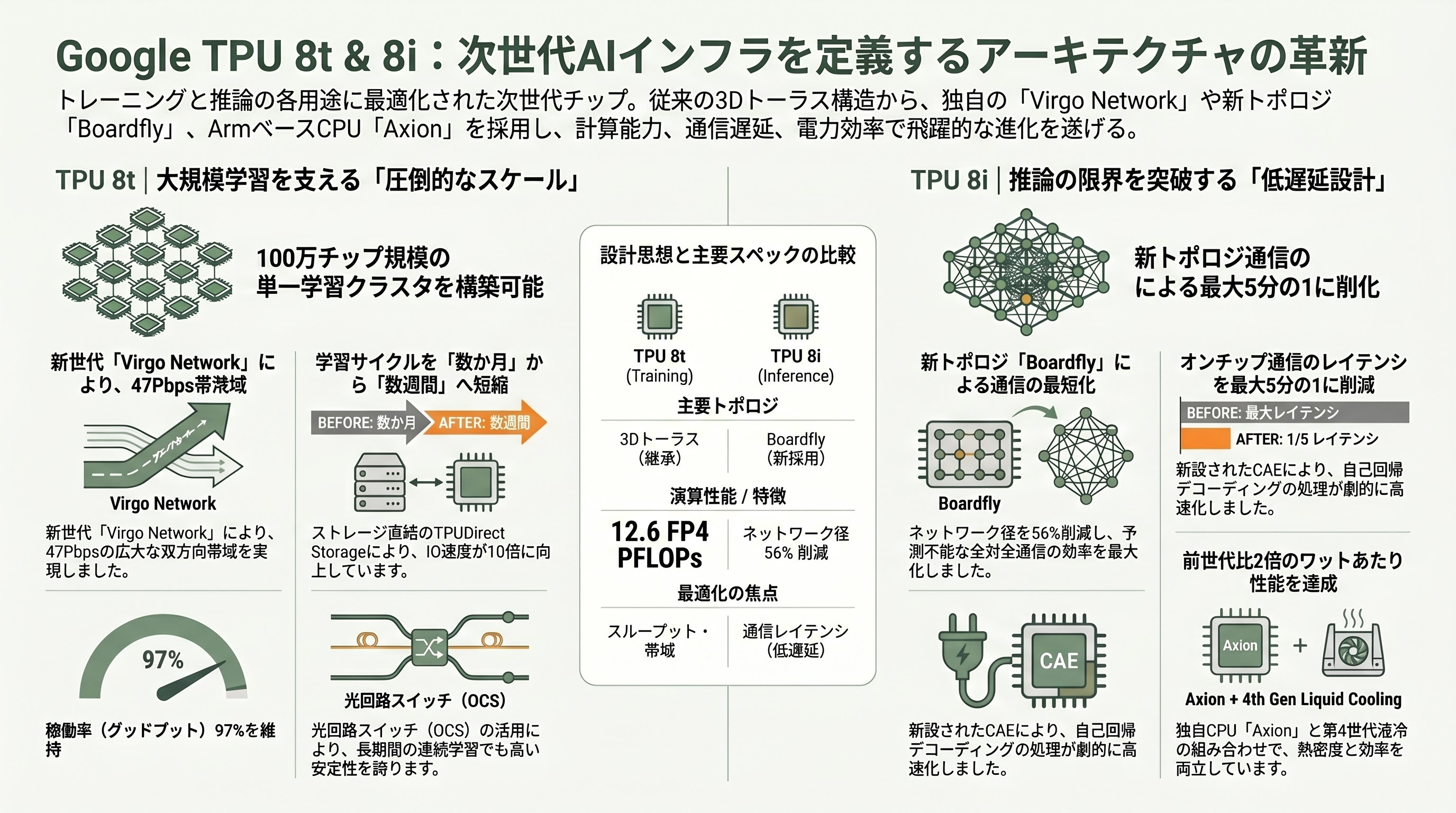
TPU 8tは従来の3Dトーラスを継承しつつ、FP4ネイティブ演算とTPUDirect RDMAを導入した。チップあたり12.6 FP4 PFLOPsを発揮し、216GBのHBM3eから6,528GB/sの帯域でデータを供給する。注目すべきはICI(Inter-Chip Interconnect)の19.2Tbps化と、ストレージ直結のTPUDirect Storageによる10倍のIO高速化で、これにより1ジョブの学習サイクルを数か月から数週間に短縮するというGoogleの主張が裏付けられる。さらにファブリック層では新世代の「Virgo Network」が134,000以上のTPU 8tチップを47ペタビット毎秒の双方向バイセクション帯域で結び、Pathwaysと組み合わせることで100万チップ規模の単一学習クラスタを構築できる設計となっている。光回路スイッチ(OCS)と組み合わせて稼働率を示す「グッドプット」97%を維持できる点も、長期間連続学習を要する基盤モデル開発にとって計り知れない価値を持つ。
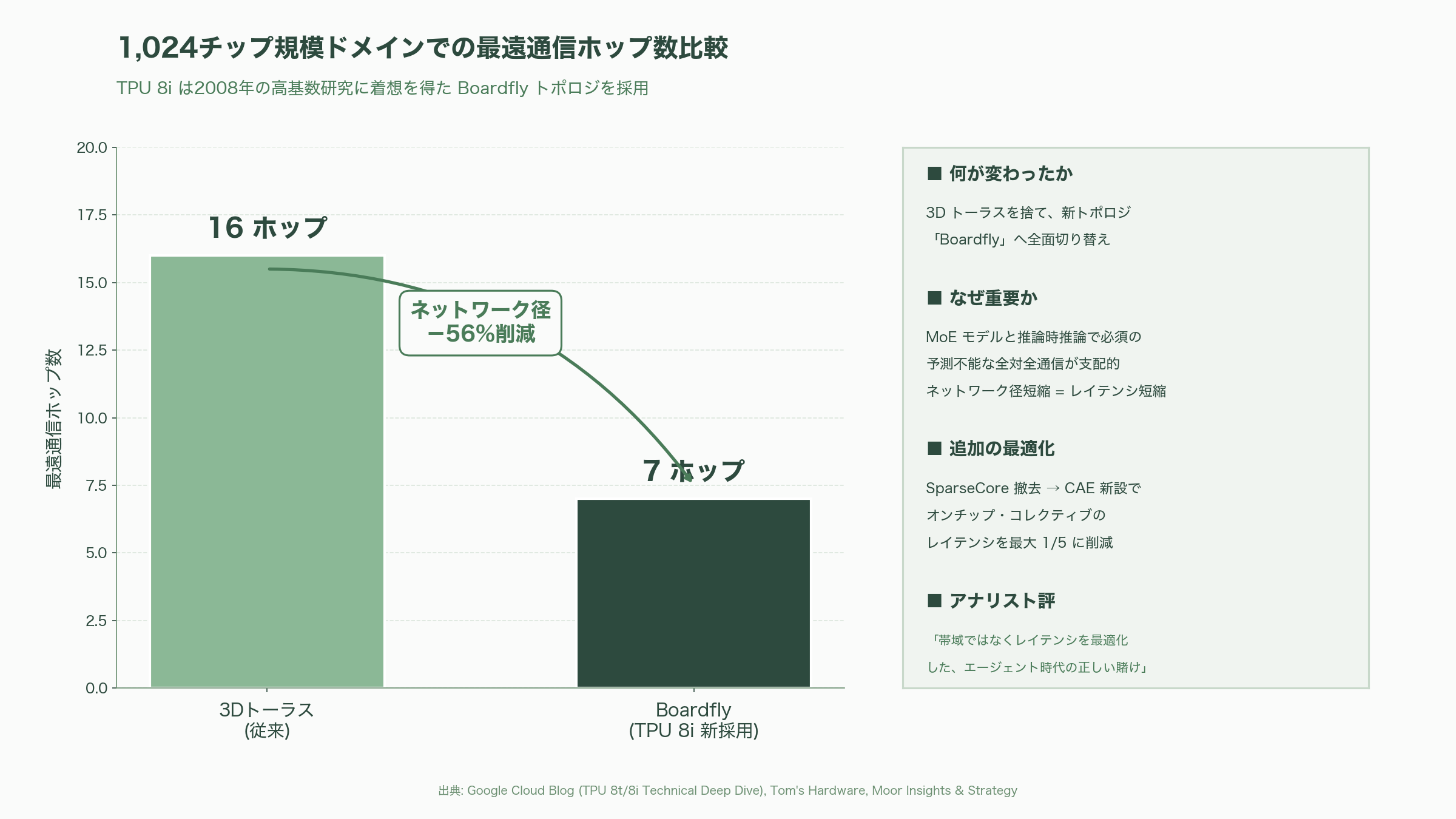
TPU 8iの設計はさらに踏み込んでいる。最大の構造的変更は、3Dトーラスを捨てて2008年の高基数研究に着想を得た「Boardfly」と呼ばれる新トポロジを採用したことだ。1,024チップ規模のドメインで比較すると、3Dトーラスでは最遠通信に16ホップを要したのに対し、Boardflyでは7ホップ、すなわちネットワーク径が56%削減された。これはMixture-of-Expertsモデルや推論時推論(chain-of-thought)のように予測不能な全対全通信を要するワークロードで決定的な意味を持つ。加えて、IronwoodのSparseCoreブロックを丸ごと撤去し、コア・チップレットダイ上に新設したCollectives Acceleration Engine(CAE)に置き換えたことで、自己回帰デコーディングにおけるオンチップ・コレクティブのレイテンシを最大5分の1に削減した。Patrick Moorheadはこれを「帯域ではなくレイテンシを最適化したエージェント時代の正しい賭け」と評している。また、両チップともホストCPUにGoogle独自のArmベース「Axion」を採用し、第4世代液冷を組み合わせることでラックあたり熱密度を引き上げつつワットあたり性能を前世代比2倍に持ち上げた。製造ノードはTSMCの2nm級プロセスとされるが、Googleは公式に明言しておらず、TSMC N3系列との見方も一部にあるため、ここは留保が必要な領域である。
シリコンバレーVCの受け止め ― 「ナイフは抜かれた」
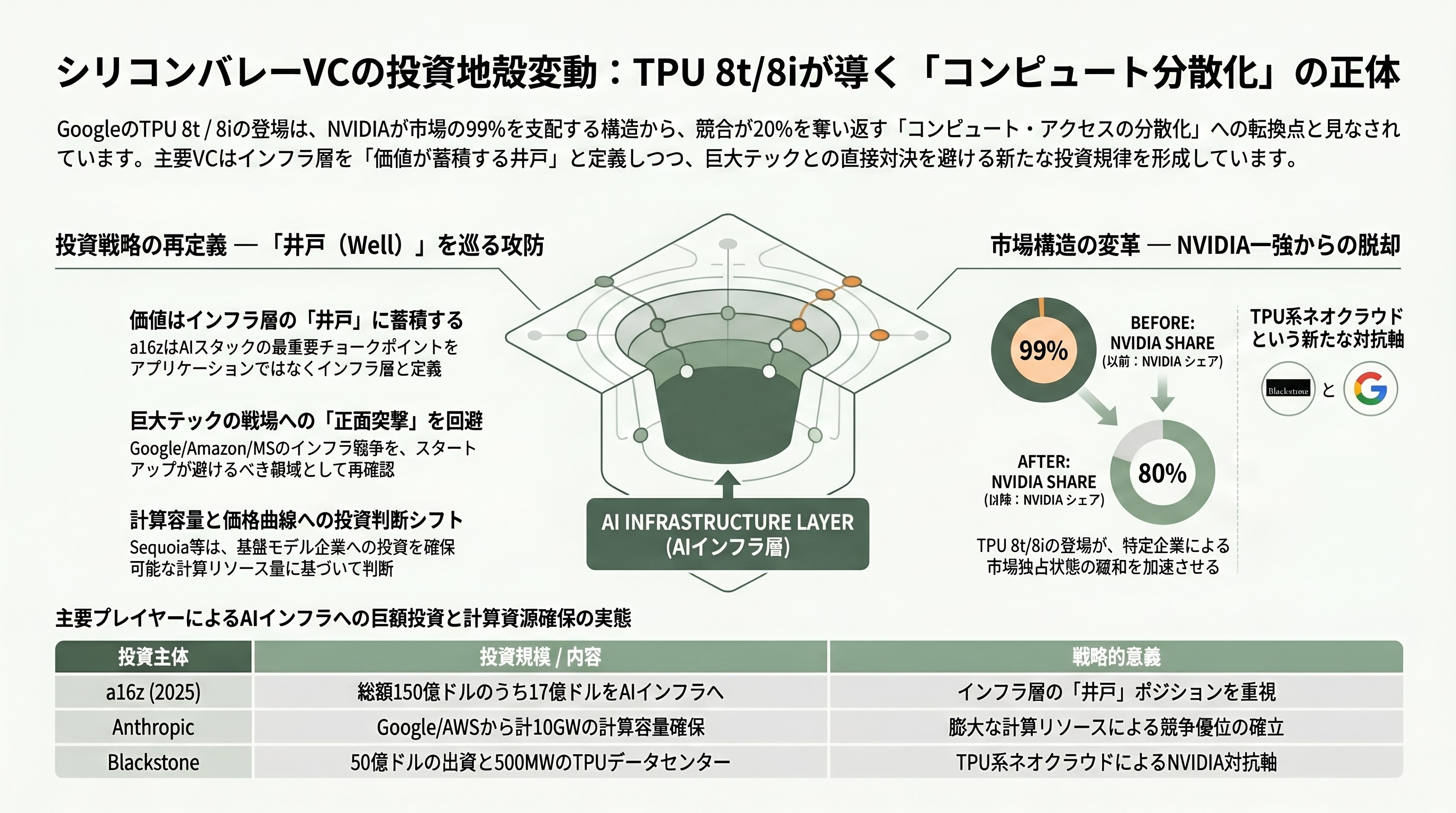
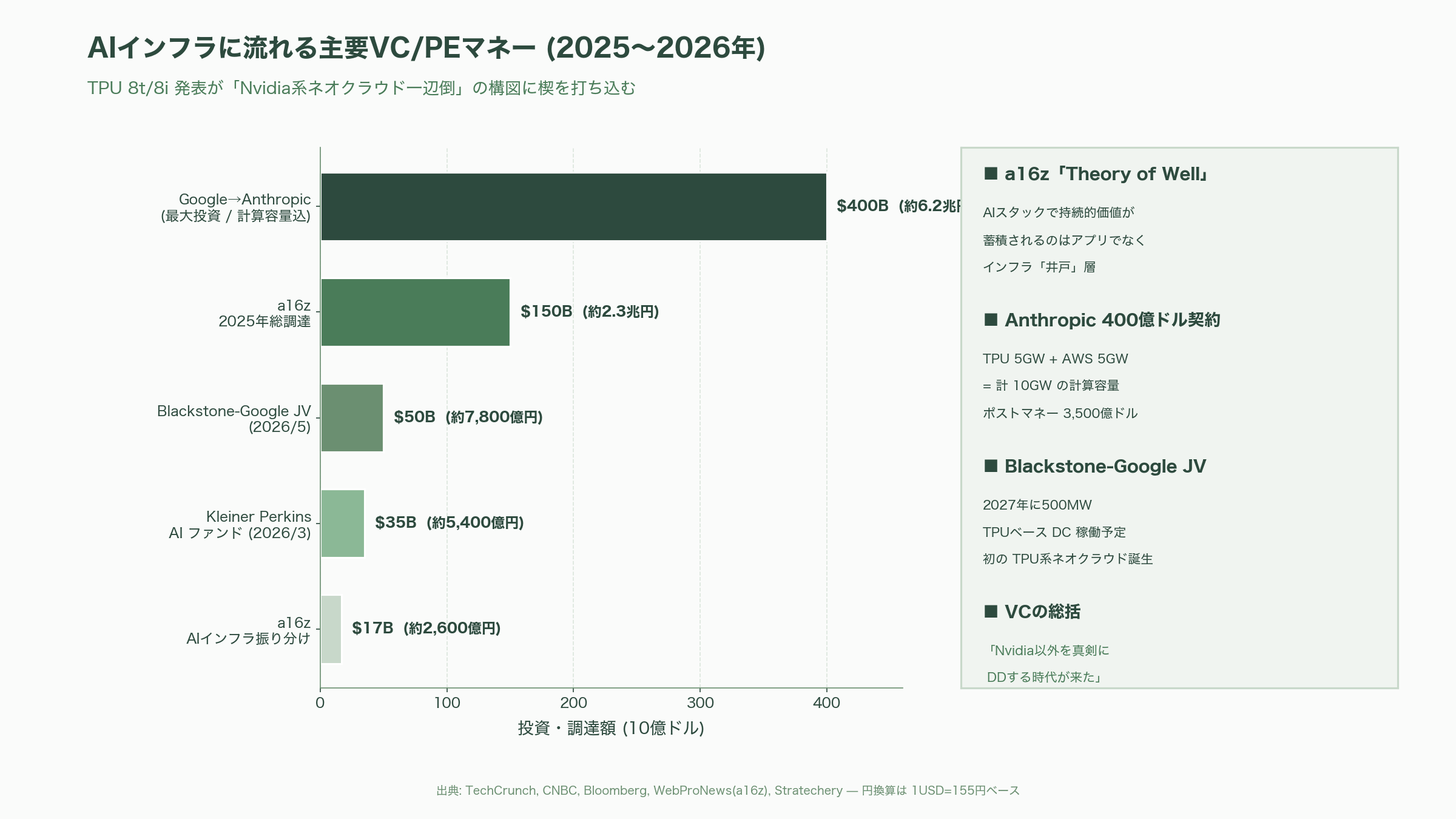
シリコンバレーの主要VCは、TPU 8t / 8iの発表を「Nvidiaが市場の99%を取る未来から、80%を取る未来への移行」を加速させるイベントとして受け止めている。Andreessen Horowitzのアンジネー・ミダ(Anjney Midha)パートナーが主導する「Theory of Well」テーゼでは、AIスタックの中で最も持続的な価値はアプリケーションではなく「井戸(well)」、すなわちチョークポイントを握るインフラ層に蓄積されるとされる。a16zは2025年に総額150億ドル(約2.3兆円)を調達し、うち17億ドル(約2,600億円)をAIインフラに振り分けると公表したが、同社の最近のメモでは「Googleが独自TPU、Amazonが Trainium / Inferentia、Microsoftが Maiaを推し進めるのは、井戸ポジションを死守するための戦争であり、スタートアップはここに正面突撃すべきではない」という整理が示されている。つまりa16zはTPU 8t / 8iの登場を、自社ポートフォリオがどこに張るべきでないかを再確認するシグナルとして読み解いている。
Sequoia Capitalや Founders Fundは公式コメントを控えているが、業界メディアの取材ではいずれもAnthropic、xAI、Cohere、Mistralなどの基盤モデル企業に対する投資判断を「アクセスできる計算容量とその価格曲線」に大きく依存する形へとシフトさせていると報じられている。Anthropicは2026年4月24日にGoogleから最大400億ドル(約6.2兆円)の追加投資と5ギガワットのTPU容量を受け、ポストマネー評価額は3,500億ドル(約54兆円)に達した。直後にAWSとも5GW契約を結んだことで合計10GWの計算容量を確保した格好で、Sequoiaが2025年に主導したラウンドの含み益は急拡大している。Kleiner Perkinsが2026年3月に発表した35億ドル(約5,400億円)のAIファンドにおいても、TPU 8tをめぐる新たなネオクラウド(Blackstone-Google共同事業など)への参画機会を模索する動きが報じられている。
最も象徴的な動きは、Blackstoneが2026年5月19日にGoogleとの合弁会社にエクイティ50億ドル(約7,800億円)をコミットし、2027年に500MWのTPUベース・データセンターを稼働させると発表したことだ。これは厳密にはVCではなくプライベートエクイティの動きだが、シリコンバレーのVCコミュニティが「Nvidia系ネオクラウド一辺倒だった世界に、初めてTPU系ネオクラウドが対抗軸として登場した」と認識した瞬間でもある。複数のVCパートナーは匿名で、「TPU 8t / 8iの発表でようやくNvidia以外を真剣にデューデリジェンスする時代が来た」と語っており、シリコンバレーVCの投資テーマ「コンピュート・アクセスの分散化」を後押しする触媒となっている。
各紙・各サイトの報道スタンス
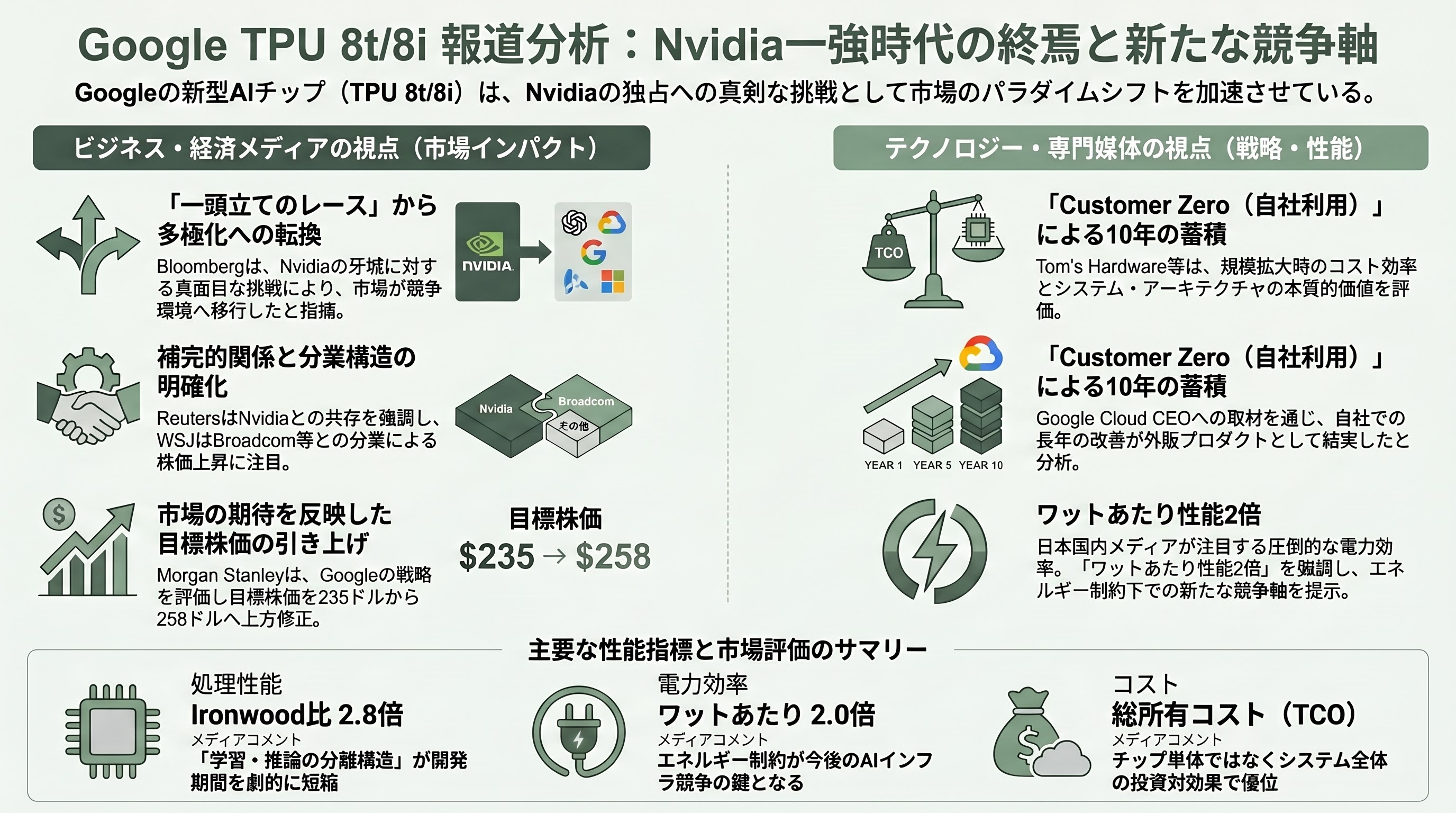
Bloomberg のイアン・キングは4月22日付の記事で、TPU 8t / 8iを「Nvidiaの牙城に対するこれまでで最も真面目な挑戦」と位置付け、Anthropic向け5GW契約とBlackstone JV発表をセットで取り上げ「Wall Streetは初めてAIチップ競争が一頭立てのレースでなくなったと理解した」と総括した。Reuters はより慎重な筆致で、Google自身が依然としてNvidia GPUインスタンス(Vera Rubin NVL72)も同じVirgoファブリック上で提供している事実を強調し、「補完であって完全置換ではない」と注意を促した。Wall Street Journal はBroadcomとMediaTekの分業構造に焦点を当て、Broadcom株のWall Street平均目標株価が478ドル(約7.4万円)に切り上がったこと、Morgan Stanleyのブライアン・ノワックが4月23日に目標株価を235ドル(約3.6万円)から258ドル(約4万円)へ引き上げたことを報じている。
テクノロジー専門メディアの論調はやや異なる。Tom's Hardwareは「チップ単体ではNvidiaに劣るが、スケール時の総所有コストで逆転」というフレームで詳細な数表を提示し、SemiAnalysisのダイラン・パテルもニュースレターで「マイクロアーキテクチャは AIインフラの真のコストのほんの一部に過ぎず、システム・アーキテクチャと展開柔軟性こそが本質」と書いた。Stratecheryのベン・トンプソンはトーマス・キュリアン Google Cloud CEOへの単独インタビューを掲載し、「Googleが自社をユーザー筆頭顧客(customer zero)として鍛え上げてきた10年の蓄積が、ようやく外販可能なプロダクトに結実した」と評価した。一方Moor Insights & StrategyのPatrick Moorheadは「TPUはNvidiaに『立ち向かう』のではなく、Apple Siliconのようにシステムレベルで競争している」とフレームし、ピアレビューされた第三者ベンチマーク(MLPerf、InferenceMax)が出るまで断定を避けるべきとの慎重論を示した。
日本国内では、日経新聞、ASCII、HelenTech、GIGAZINE、AI総合研究所などが軒並み「学習・推論で別チップ」という構造的論点と「Ironwood比2.8倍/80%」「ワットあたり2倍」という数値を一斉に取り上げ、ASCIIは「最先端モデル開発を数か月から数週間へ短縮」というGoogleの主張をそのまま見出しに採った。GIGAZINEは「ワットあたり性能2倍」を強調し、エネルギー制約が次の競争軸になることを示唆している。AI革命社などは Broadcom = Sunfish、MediaTek = Zebrafishという分業の構図と、これがTSMC CoWoS生産能力をめぐる新たな逼迫を生むという観点を補強した。
顧客と需要曲線 ― 「自社のサーバーが社内研究者に行き渡らない」
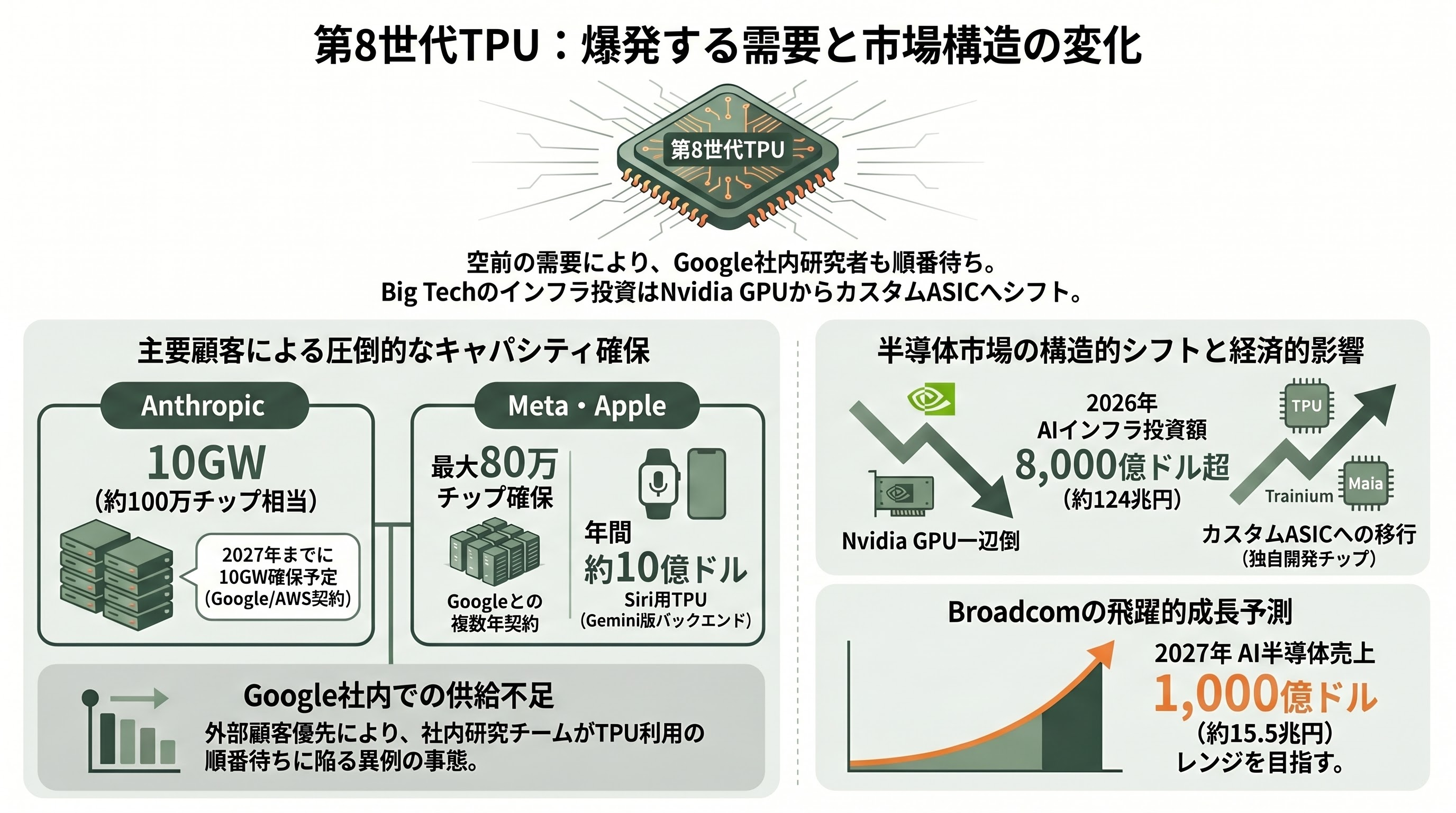
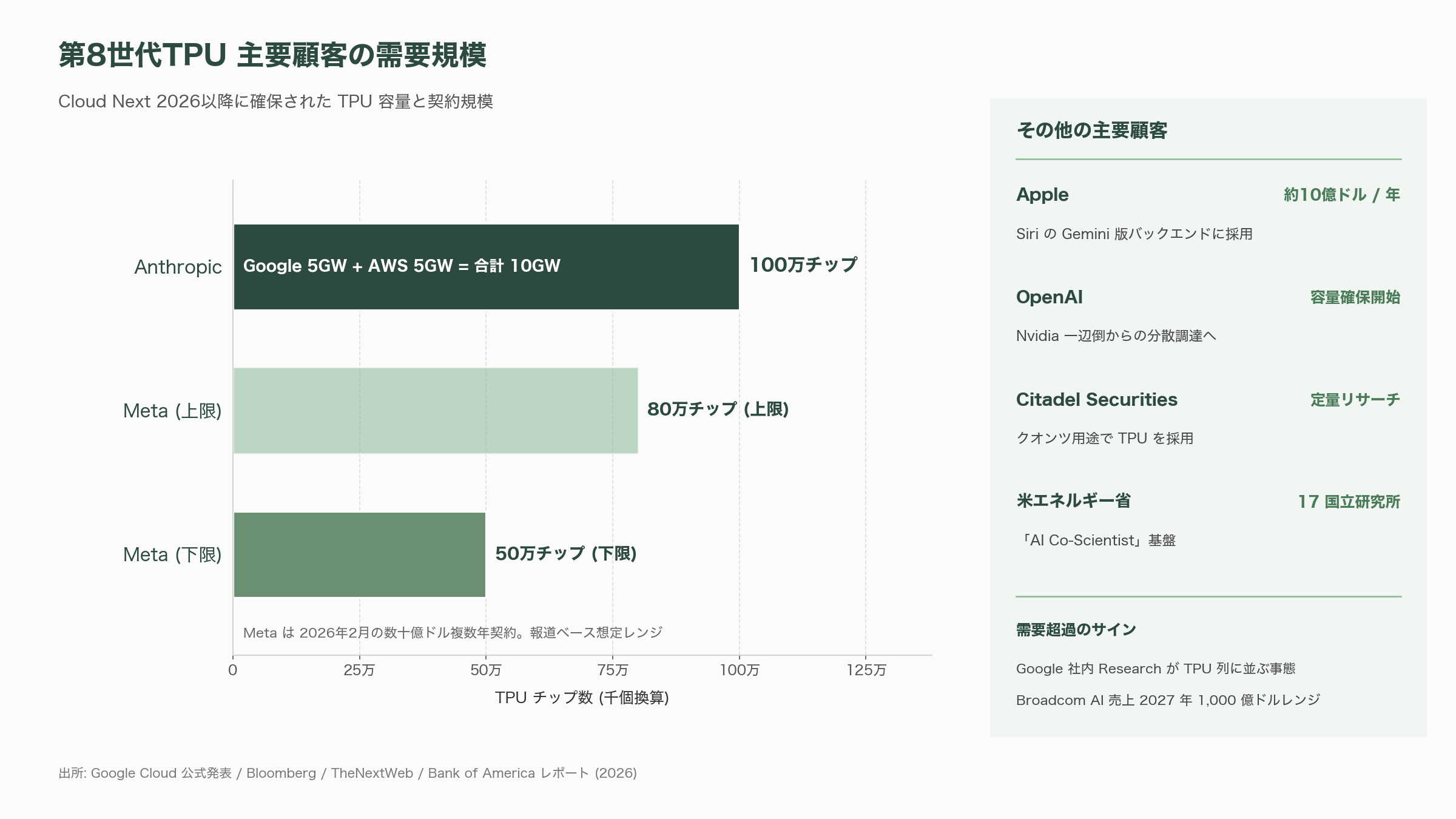
第8世代TPUの需要曲線は、過去の世代と比較しても異質である。最大顧客のAnthropicはGoogleとの新規契約で最大100万チップ、5GWの計算容量を確保し、AWSとの追加契約を含めると合計10GWに達する見込みだ。Anthropic CFOのクリシュナ・ラオは「2027年までに年間収益300億ドル(約4.6兆円)を目指す」と公言しており、その裏付けとして第8世代TPUが当てにされている。Metaは2026年2月にGoogleと数十億ドル規模の複数年契約を結び、報道ベースでは2027年までに50万〜80万チップを確保するとされる。AppleはSiriのGemini版バックエンドにTPUを採用し、年間およそ10億ドル(約1,550億円)規模の支出を行う見込みだ。Citadel Securitiesは定量リサーチソフトウェアにTPUを採用し、米エネルギー省17国立研究所が「AI Co-Scientist」と呼ばれる科学AIプラットフォームをTPU上に構築している。最近の報道ではOpenAIまでもがTPU容量の一部を確保し始めた。
需要超過の証拠として、TheNextWebは「Googleが社内研究者向けのTPUまでAnthropicに優先供給した結果、社内のResearchチームがTPUの順番待ち列に並ぶ事態が発生している」と報じている。Bank of Americaは外販拡大とGemini 3本格展開を踏まえ、BroadcomのAI半導体売上は2026年通期で前年比倍以上、2027年には1,000億ドル(約15.5兆円)レンジを目指せると見ている。Big Techの2026年AIインフラ投資総額は推定8,000億ドル(約124兆円)を超え、その配分の一定割合がNvidia GPUからTPU、Trainium、MaiaなどのカスタムASICへとシフトする構造変化が始まっている。
Nvidiaとの構図 ― Jensen Huangはどう反論したか
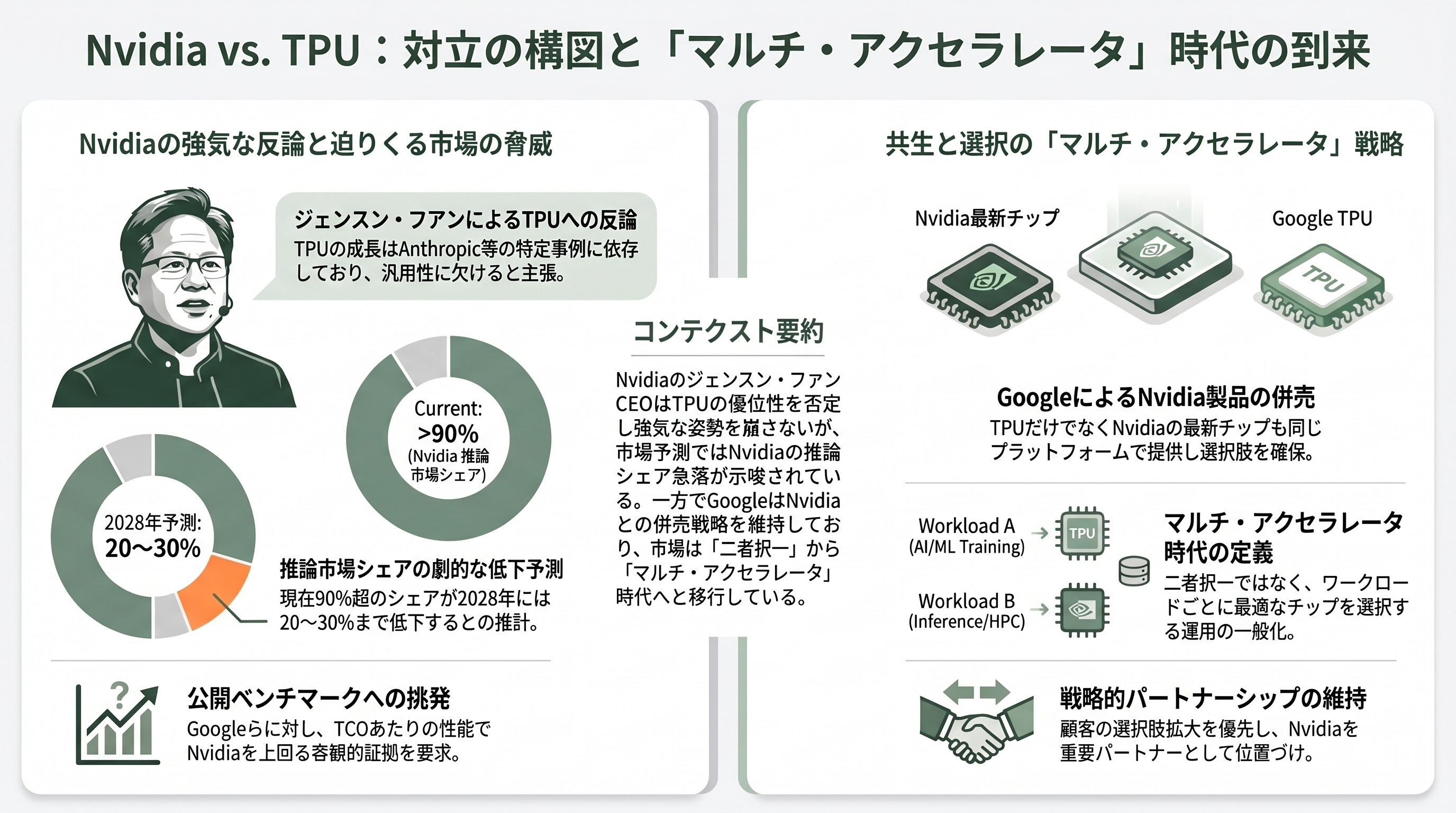
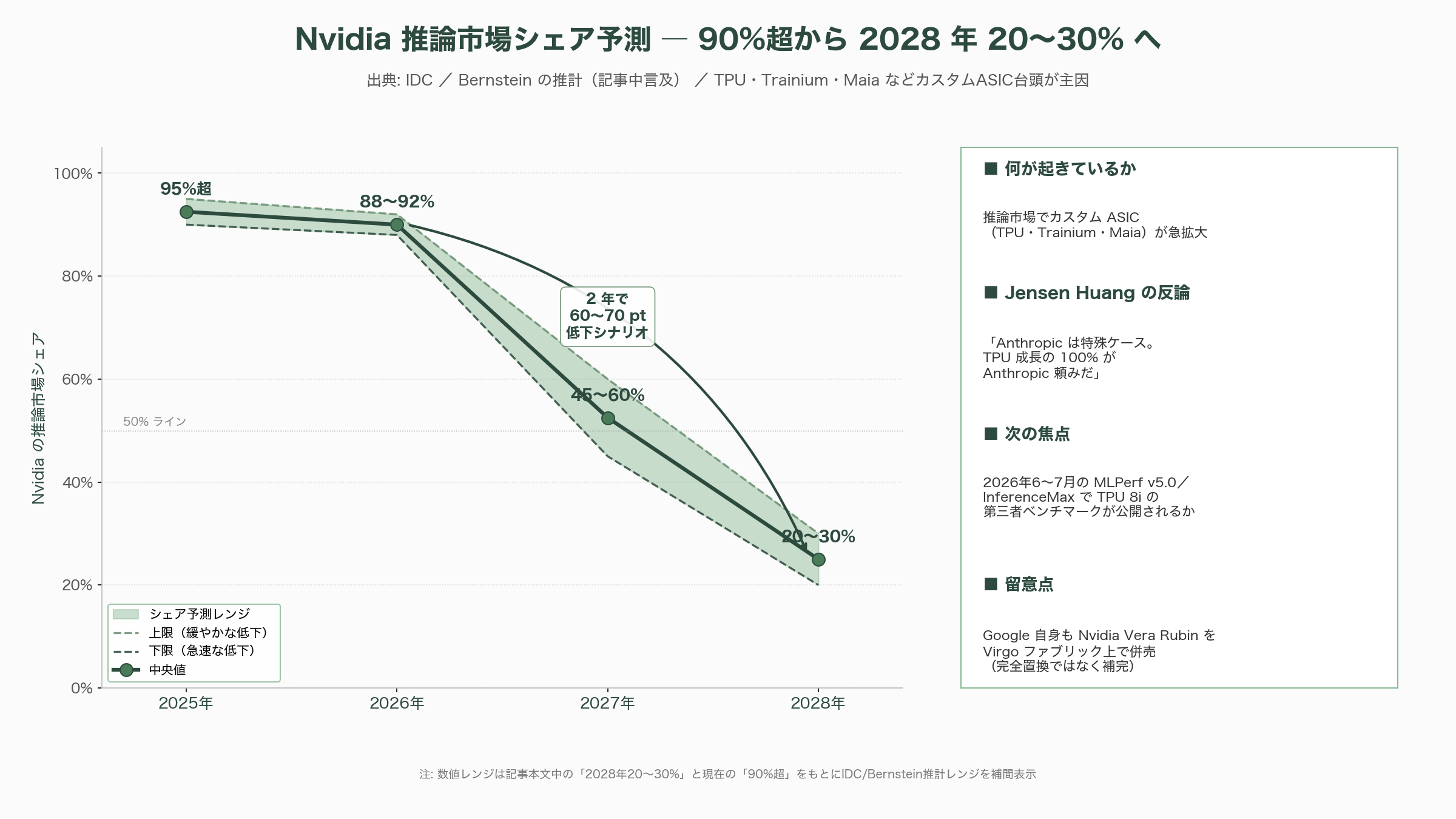
Nvidia CEOのジェンスン・フアンは、Dwarkesh Patelのポッドキャストで第8世代TPUに対する見解を問われ、「Anthropicは特殊ケースであり、トレンドではない。Anthropicを除けばTPU成長の源泉はどこにあるのか。100%Anthropic頼みだ」と反論した。フアンはまた、GoogleとAmazonに対して「MLPerfやInferenceMaxといった公開ベンチマークに結果を出すべきだ」と繰り返し挑発し、「総所有コストあたりの性能でNvidiaを上回るプラットフォームを誰も示せていない」と語った。アナリストの間では、フアンの強気発言とは裏腹に、Nvidia の推論市場シェアが現在の90%超から2028年までに20〜30%まで低下しうるという IDC や Bernstein の推計が広まりつつあり、推論市場でのカスタムASICの脅威は無視できない段階に入った。
ただしGoogle自身も「Nvidiaへの全面戦争」を宣言したわけではない。Cloud Next 2026では同じVirgoファブリック上でNvidia Vera Rubin NVL72インスタンスを併売することが明らかにされ、Thomas Kurian CEOは「顧客の選択肢を増やすことが最優先で、Nvidiaは引き続き重要なパートナー」と強調した。シリコンバレーVCの間でも、「NvidiaかTPUかの二者択一ではなく、ワークロードごとに最適なシリコンを選ぶマルチ・アクセラレータ時代へ」という整理が支配的になっている。GoogleがTPUを完全に外販するわけではなく、Google Cloud経由でのアクセスを基本としている点も「Nvidiaのチャネル経済を破壊する意図はない」というシグナルと解釈されている。
今後12〜18か月の観測点
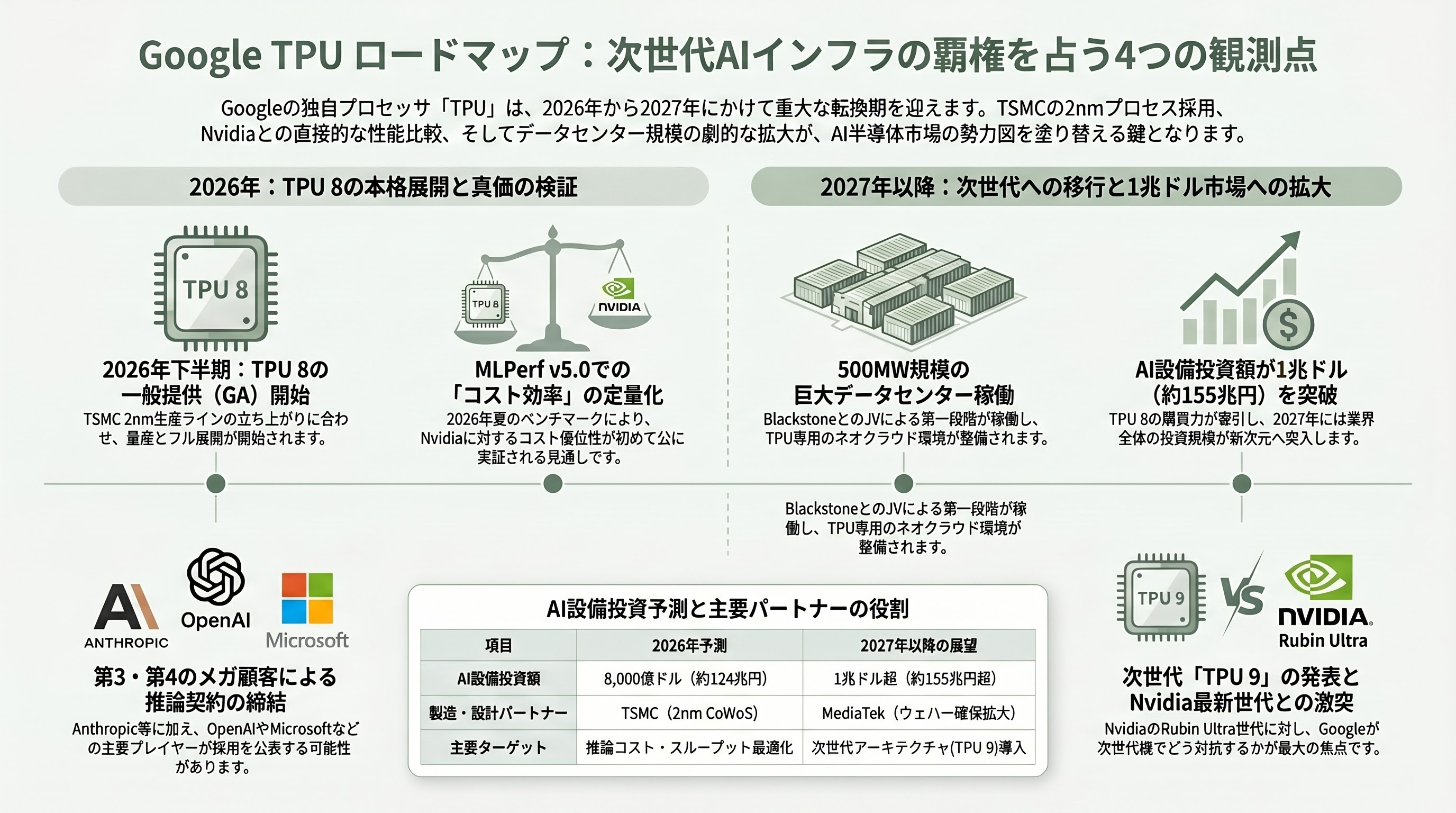
第一の観測点は、2026年下半期に予定されている一般提供(GA)の正確なタイミングである。Googleは「2026年下半期」とのみ述べており、量産能力の鍵を握るTSMCの2nm CoWoS生産ラインの立ち上がり次第で前後する可能性がある。Morgan Stanleyは「MediaTekのZebrafishは予定通り2026年下半期に量産入りする」と予測する一方、HyperFRAME Researchは「フル展開はTSMC 2nmが本格量産に乗る2027年後半」と注釈している。両者の差は、ベータ提供と本格的GW級展開の違いと見るのが妥当である。
第二の観測点は、2026年6〜7月に開催されるMLPerf v5.0およびInferenceMaxラウンドである。フアンが繰り返し要求している通り、GoogleがTPU 8t / 8iの第三者ベンチマーク結果を初めて公開するかが焦点となり、もし公開されれば「絶対性能でNvidiaに劣るがコスト効率で勝つ」という現在の論点が定量化される。並行して、Anthropic Claude 5 / Gemini 3 Pro のリリースに伴うTPU 8i上での推論コスト・スループット実測が、メディアと投資家の最大関心事となっている。
第三の観測点は、Blackstone-Google JV第一段階(500MW)の2027年稼働に向けた中間進捗と、これに追随する第二・第三のTPUネオクラウドの登場である。シリコンバレーVCの多くが「TPU系ネオクラウド」を新たな投資テーマとして掘り起こしており、CoreWeaveやLambda LabsがNvidia系で享受してきた急成長をTPU系でも再現できる事業者が現れるかが注目されている。さらに2026年秋には、AnthropicとMeta以外の第3、第4のメガ顧客(OpenAI、Microsoft、もしくはxAIなど)がTPU 8iベースの推論契約を公にする可能性が複数の関係者から囁かれている。
最後に、長期的観測点として、2027年中の「TPU 9」または同等の次世代発表が挙げられる。Broadcomは2031年までGoogleとの長期契約を持ち、設計と供給を継続する見通しで、MediaTekもCoWoS 12〜15万ウェハー相当の生産能力を2027年までに段階的に確保するとされる。Big Techの2026年AI設備投資 8,000億ドル(約124兆円)が「TPU 8世代の購買力」によって部分的に支えられ、2027年にはこれが1兆ドル超(約155兆円超)の領域に拡大する可能性が高い。第8世代TPUの本当の評価が下るのは、Nvidia Vera Rubin Ultra世代と直接ぶつかる2026年末から2027年前半にかけてであり、これがシリコンバレーVCにとって今後最も注視すべきマイルストーンとなる。