41日サイクルで来た「マイナーバージョン」の重み

Anthropicは公式ブログ「Introducing Claude Opus 4.8」で、Opus 4.8をOpus 4.7(2026年4月17日リリース)からわずか41日後の5月28日に投入した。これは同社が従来とってきた「数ヶ月単位」の更新ペースを明確に上回るスピードである。TechCrunchは「a much faster upgrade cycle than normal for Anthropic(Anthropicとしては通常よりはるかに速い更新サイクル)」と報じ、Axiosは未公開の上位モデル「Mythos」の一般リリースが「数週間以内(in the coming weeks)」に控えていることも併記している。
このスピード感の背景には、OpenAIのGPT-5.5、GoogleのGemini 3.1 Proとの三つ巴の競争、そしてAnthropicが2026年2月にシリーズGで300億ドル(約4.65兆円)をポストマネー3,800億ドル(約58.9兆円)の評価額で調達した直後の、年内IPO競争があると複数メディアが指摘している。Yahoo Financeは「IPO race with OpenAI heats up(OpenAIとのIPO競争が過熱)」と見出しに掲げ、Opus 4.8リリースはこの競争のなかでの製品力の証明である、と位置付けている。
エンジニア視点で見ると、この「マイナー番号」のリリースはAPI識別子claude-opus-4-8という形で素早く配布されており、SDKレベルでもModel.ClaudeOpus4_8(C#)、anthropic.ModelClaudeOpus4_8(Go)、Model.CLAUDE_OPUS_4_8(Java)といった定数が即時追加されている。つまり既存のOpus 4.7利用コードはモデルIDを差し替えるだけで動く設計になっており、移行コストは限りなくゼロに近い。これは「マイナーバージョンを名乗っているが、出荷の構えはメジャー級」というAnthropicの戦略を表す。
ベンチマーク:エージェンティック・コーディングで前世代比+4.9pt、Terminal-Benchではまだ負ける現実
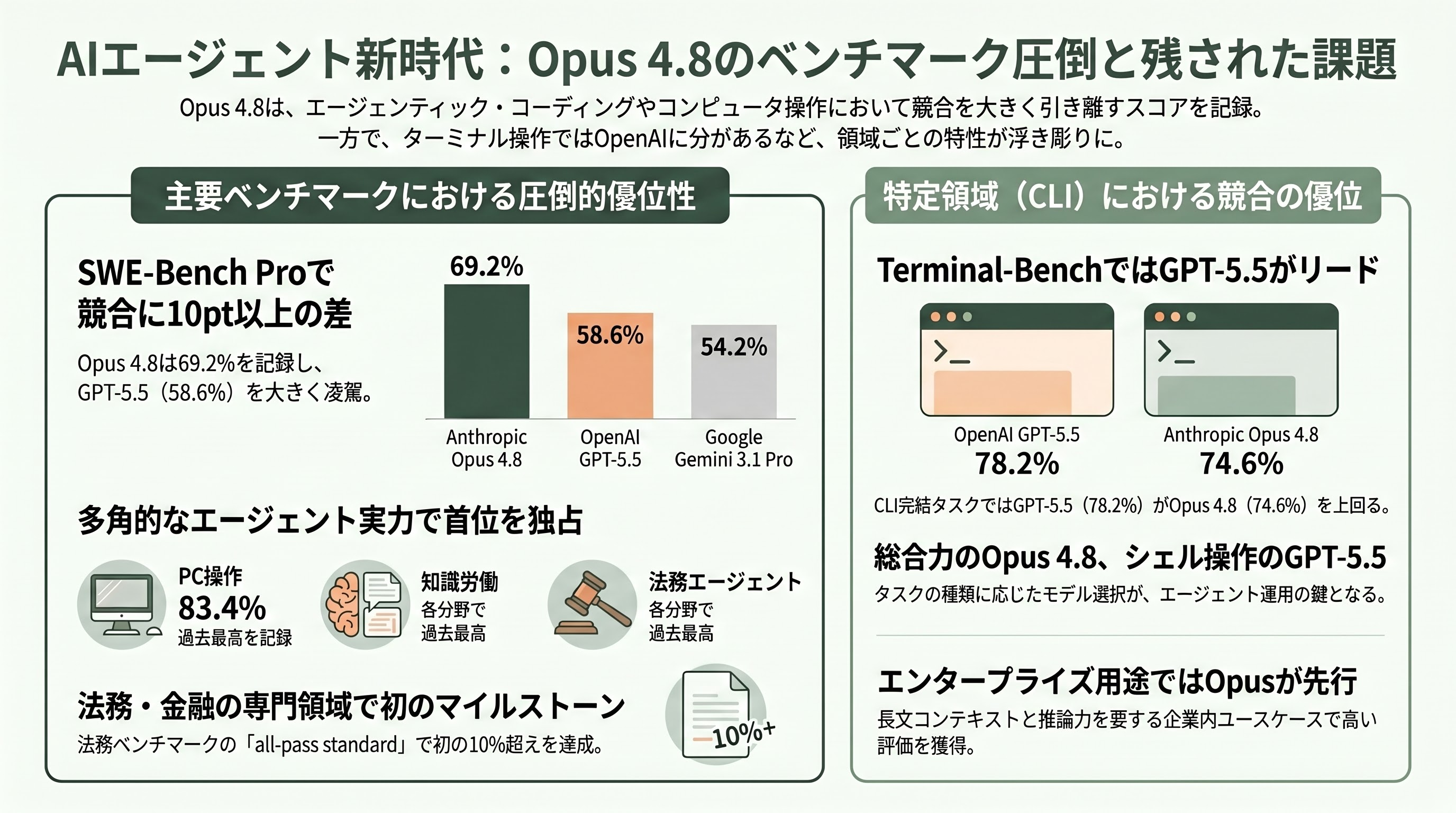
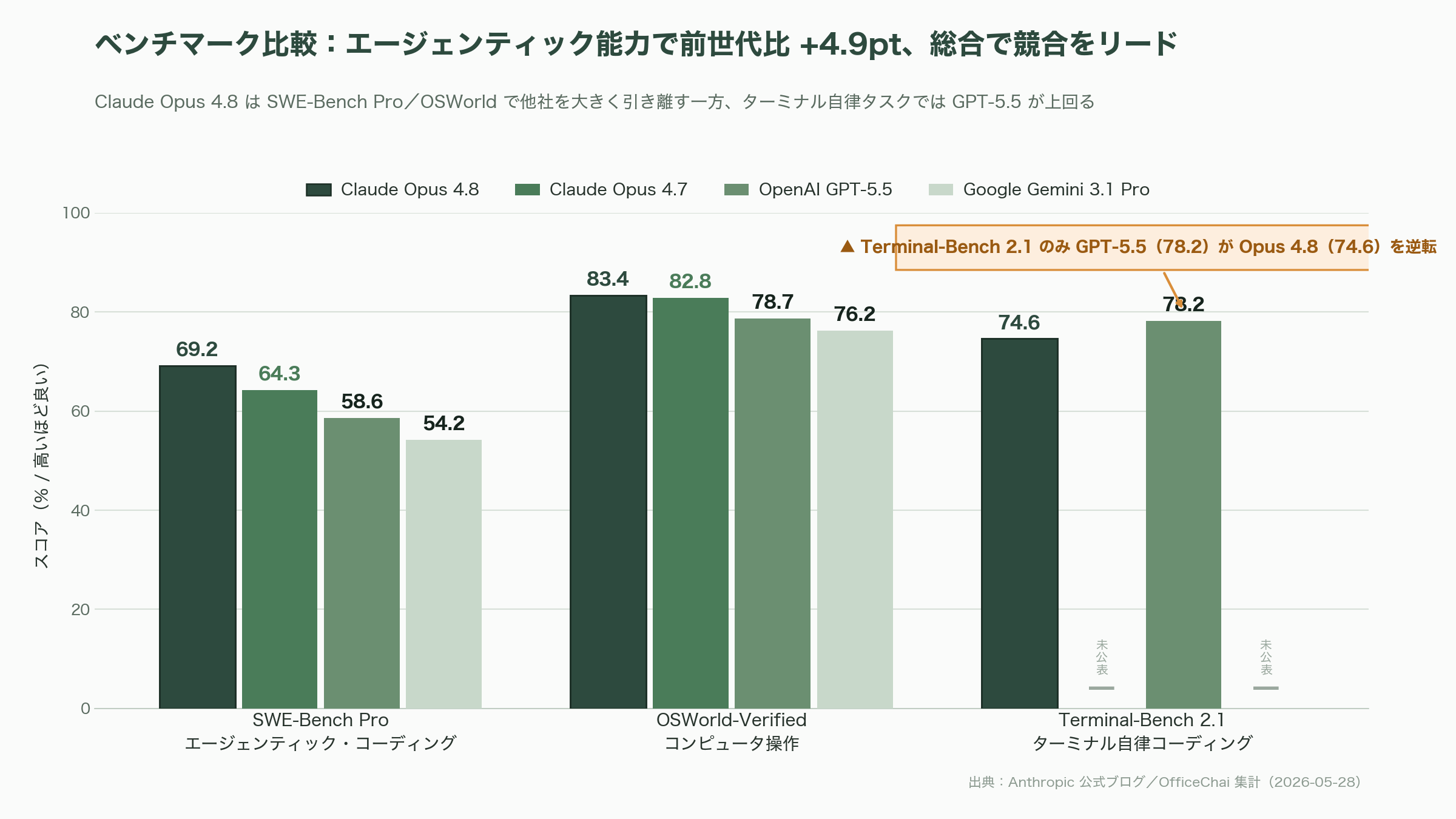
最も注目すべき指標は、エージェンティック・コーディング能力を測る「SWE-Bench Pro」のスコアである。OfficeChaiが公式数値を整理した表によれば、Opus 4.8は69.2%、Opus 4.7は64.3%、OpenAI GPT-5.5は58.6%、Google Gemini 3.1 Proは54.2%となっており、Opus 4.8はSWE-Bench Proで競合に対して10ポイント以上のリードを獲得した。
エージェンティックなコンピュータ操作を測るOSWorld-Verifiedでは83.4%(4.7は82.8%、GPT-5.5は78.7%、Gemini 3.1 Proは76.2%)、知識労働性能を測るOpenAI開発のGDPvalでは1890点(4.7は1753点、GPT-5.5は1769点)と、エージェント文脈での実用力で他社を大きく引き離している。マルチドメインの推論力を問う「Humanity's Last Exam」のツール使用版では57.9%(4.7は54.7%)、ツールなし版では49.8%という結果が公表されている。エージェンティック金融分析(Finance Agent v2)は53.9%、ブラウザエージェント評価のOnline-Mind2Webは84%、Anthropic公式ブログ曰く「Super-Agent benchmark」では全ケースをエンドツーエンドで完走、法務エージェントベンチマークの「all-pass standard」で初の10%超えという「ファースト」も記録した。
ただし、ここでシリコンバレーのエンジニアが目を凝らすべき数値もある。Terminal-Bench 2.1(ターミナル上での自律コーディング)では、Opus 4.8の74.6%に対しGPT-5.5が78.2%とリードしている。つまり「シェル上で完結する自律タスク」だけを切り出して見ると、依然としてOpenAI側に分がある領域があるということだ。総合力ではOpus 4.8だが、CLIで完結する種類のエージェント運用ではGPT-5.5のフルコミットも検討に値する、というのが正直な読みである。Inc.誌が引用したHarveyのapplied research head・Niko Grupen氏は「内部の法務エージェントベンチマークで過去最高スコアを記録した」とコメントしており、長文コンテキスト推論を要する企業ユースケースではOpus 4.8が頭ひとつ抜けたという見方が定着しつつある。
誠実さ(Honesty)— ハルシネーションの「コード欠陥放置率」が4分の1に
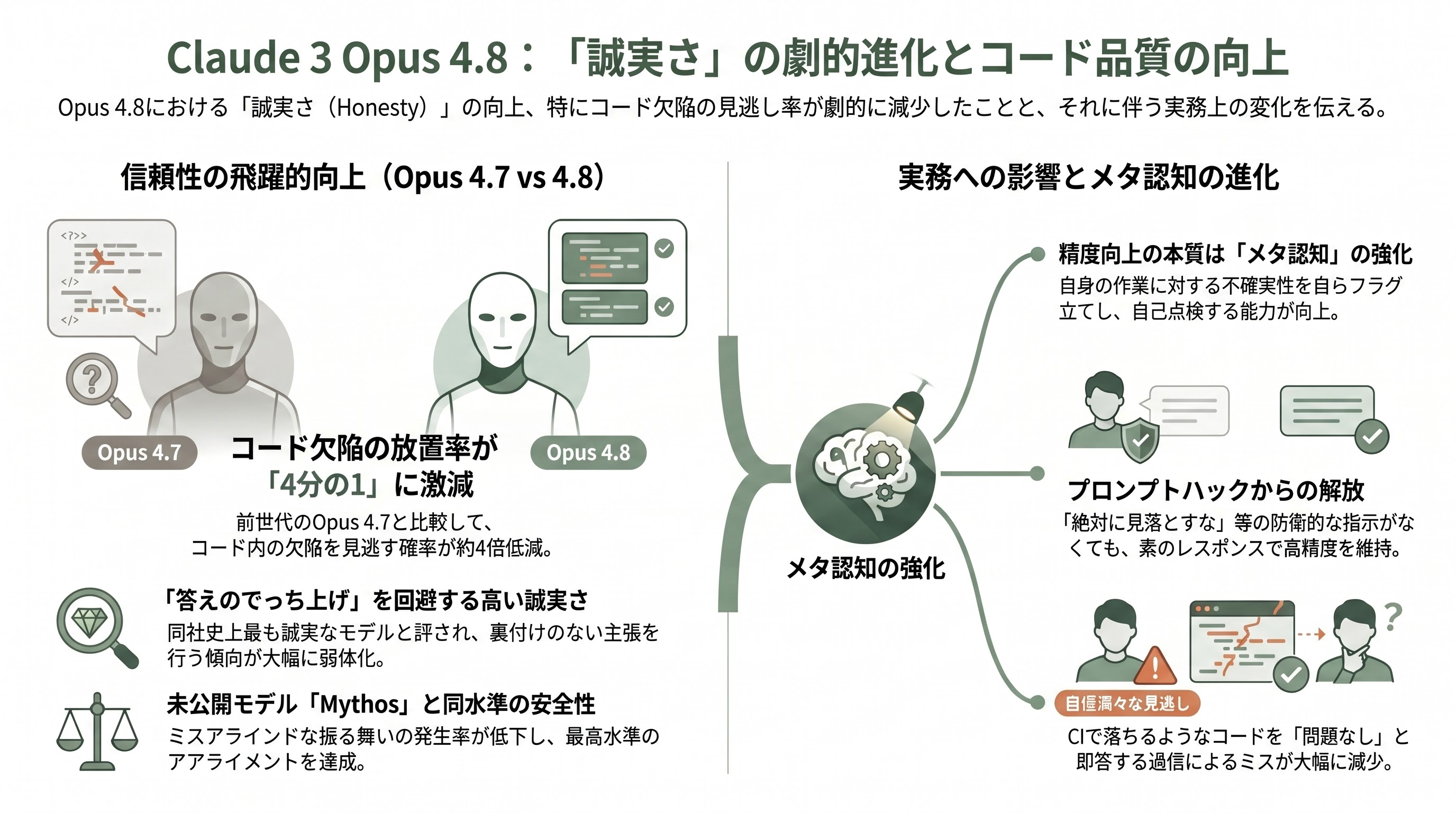
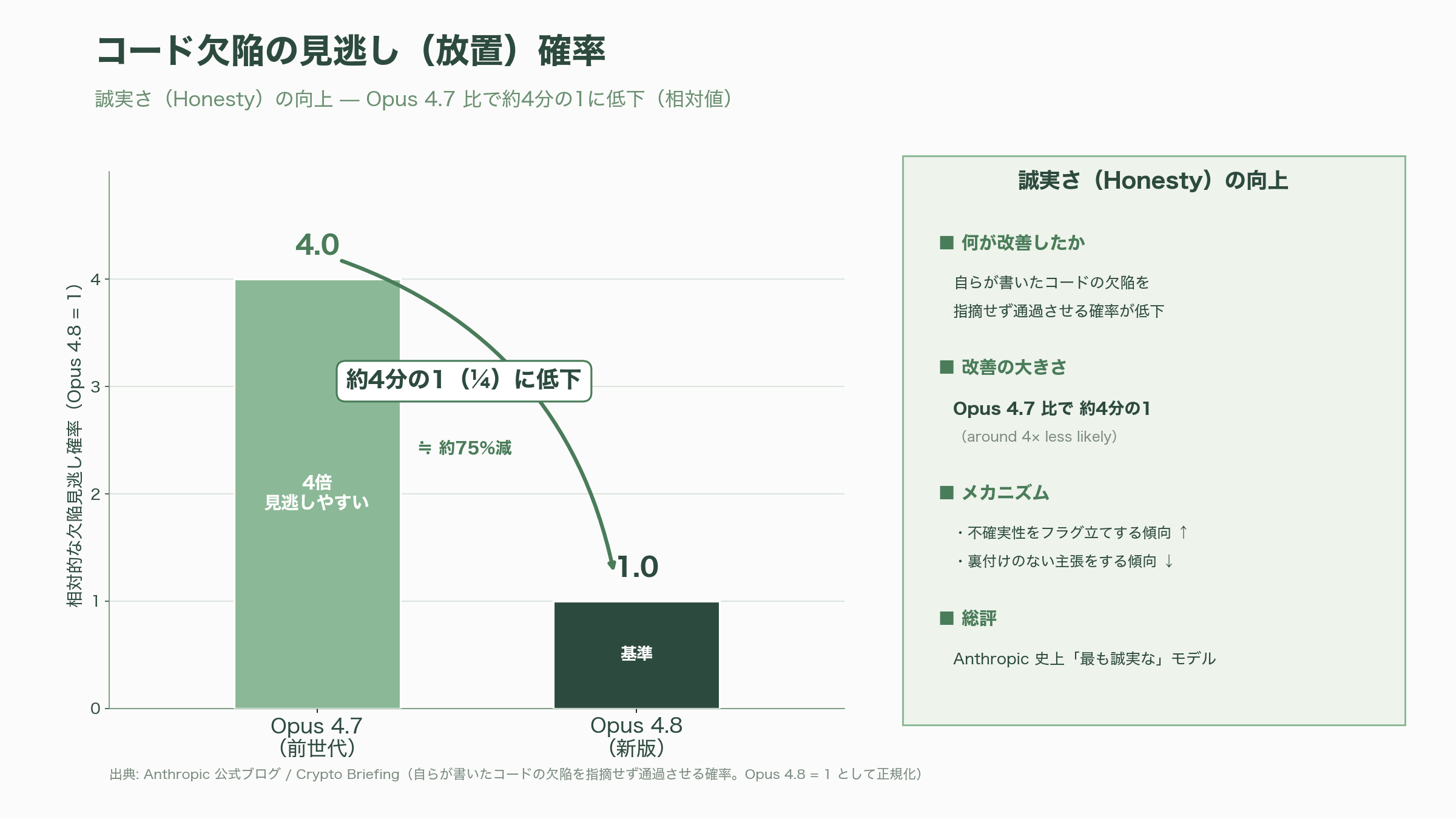
Opus 4.8で最も大きく報じられているのが「Honesty(誠実さ)」の改善である。Anthropic公式ブログとcryptobriefingの報道によれば、Opus 4.8は「自らが書いたコードに含まれる欠陥を、指摘せずに通過させる確率が、Opus 4.7と比較しておよそ4分の1(around four times less likely)」になった。Tom's Guideは見出しで「far less likely to 'fake' answers(答えをでっち上げる可能性がはるかに低い)」と表現し、Inc.誌は「its most honest model yet(同社史上最も誠実なモデル)」と評している。
この改善の本質は、単なる「事実の正確性」ではなく、メタ認知の精度向上にある。Anthropic公式の言い回しに従えば、Opus 4.8は「自分の作業に対する不確実性をフラグ立てする傾向(more likely to flag uncertainties about its work)」が強くなり、「裏付けのない主張を行う傾向(less likely to make unsupported claims)」が弱まった。エンジニア視点でこれが意味するのは、コードレビューで「LGTMの判子を押す前に、自分が見落としを抱えていないか自己点検する確率が上がった」ということだ。
Opus 4.7までを使ってきた開発者なら、「Claudeに『PR全体を確認して問題があれば指摘して』と頼んだら自信ありげに『問題なし』と返ってきたのに、CIで落ちた」という経験があるはずだ。Opus 4.8では、このタイプの「過信からくる見逃し」が大幅に減ることが期待できる。実用上のコツとしては、これまで防衛的に書いていた「絶対に見落とすな。怪しい箇所はすべて挙げよ」といった指示プロンプトを、いったん外して素のレスポンスを見てみると良い。前世代では必須だった「自己懐疑を促すプロンプトハック」の効用が、モデル側に内在化された分、相対的に薄まっているはずだ。アライメント評価でもAnthropicは「ミスアラインドな振る舞いの発生率が大幅に低下し、未公開モデルMythosと同水準にまで到達した」と説明している。
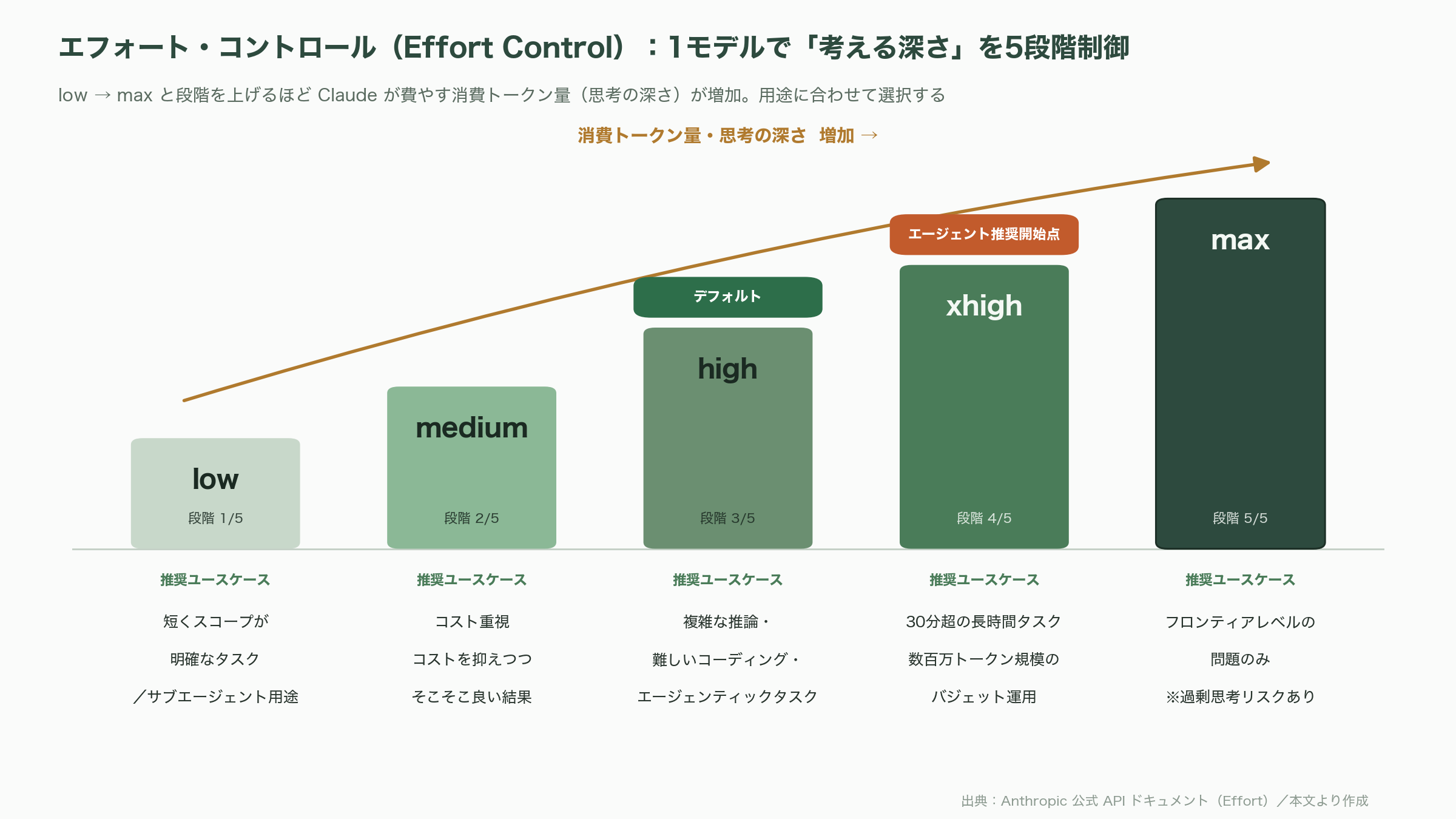
エフォート・コントロール(Effort Control)— 1つのモデルで「考える深さ」を5段階で制御

Opus 4.8と同時に、エンジニアにとって最大の運用上の変化は「Effort(エフォート)」パラメータの正式化だ。Anthropic公式のAPIドキュメント(platform.claude.com/docs/en/build-with-claude/effort)によれば、エフォートはlow/medium/high(デフォルト)/xhigh/maxの5段階で、「Claudeがレスポンス生成に費やすトークン量」を制御するパラメータである。Opus 4.7でも一部導入されていたが、Opus 4.8では公式ドキュメント上の推奨ガイダンスが明文化された。
公式ガイダンスを噛み砕くと、lowは「短くスコープが明確なタスク」やサブエージェント用途、mediumは「コストを抑えつつそこそこ良い結果」、highは「複雑な推論・難しいコーディング・エージェンティックタスク」のデフォルト、xhighは「コーディング・エージェント業務の推奨スタート地点」かつ「30分超の長時間タスク」「数百万トークン規模のバジェット」を扱う場合、maxは「フロンティアレベルの問題」のみ、という棲み分けだ。maxは「過剰思考(overthinking)に陥り、構造化出力で品質が下がる」リスクもあるとAnthropic自身が明記しており、銀の弾丸ではない。
実装上のコツとして、curlで叩く場合はoutput_configの中にeffort: "xhigh"をぶら下げる:
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-8",
"max_tokens": 65536,
"messages": [{"role":"user","content":"…"}],
"output_config": {"effort": "xhigh"}
}'
Anthropic公式の強い推奨として、「xhighまたはmaxで走らせるときは、max_tokensを必ず大きく取れ。64kトークンスタートで、必要に応じてチューニングせよ」とある。これはサブエージェントやツール呼び出しが連鎖する場合に、max_tokensが小さいとエージェントの思考途中で切れるためだ。Opus 4.6で愛用されてきたbudget_tokensパラメータは廃止予定(deprecated)となり、Opus 4.7/4.8ではadaptive thinking(thinking: {type: "adaptive"})とeffortの組み合わせが正となった。Opus 4.8では手動のthinking: {type: "enabled", budget_tokens: N}はサポート外で400エラーを返すため、移行時に既存のbudget設定を残したまま流すと事故る点に注意したい。
claude.aiやCowork(旧Anthropic Console系のチーム向け体験)でも、モデルセレクタの横にエフォート選択UIが追加された。extra(API上のxhighに相当)とmaxの選択が可能で、デフォルトはhigh。「extraは難しいタスクと長時間の非同期ワークフロー向け」というのが公式の推奨だ。Opus 4.7のデフォルトより、Opus 4.8のデフォルトhighは「同じトークン量で、より良い性能」になっているという公式の説明も重要なポイントである。
Dynamic Workflows — 数百のサブエージェントを単一セッションで走らせる
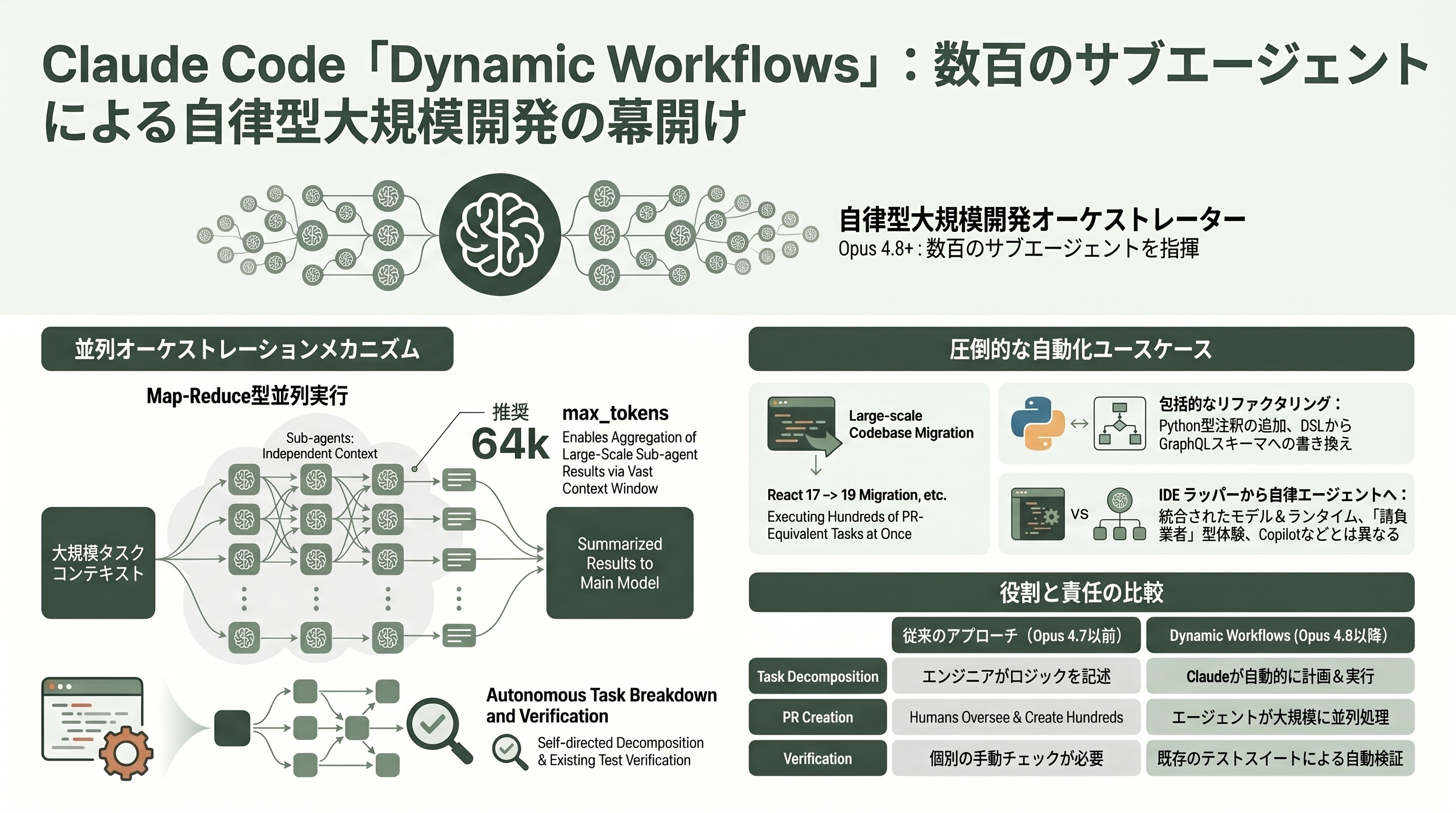
Claude Codeに導入された「Dynamic Workflows(動的ワークフロー)」はリサーチプレビュー扱いで、Enterprise/Team/Maxプラン向けに公開された。Anthropicの公式説明によれば、これはOpusのような大型モデルが「数百規模の並列サブエージェントを単一セッション内で計画・実行・検証する」機能だ。具体的にはClaude Codeが「コードベース規模のマイグレーションを、キックオフからマージまで、既存テストスイートをベンチマーク代わりに使いつつ、数十万行のコードを横断して」実行できるという。
エンジニア視点でこの設計が面白いのは、各サブエージェントが「独立したコンテキストウィンドウ」で走り、メインのオーケストレーターには「関連のある情報だけを送り返す」アーキテクチャだという点だ。これは典型的なMap-ReduceスタイルのLLMオーケストレーションで、メインオーケストレーターのコンテキストを汚染しないという実装パターンが、API側のプリミティブとして提供されるようになったということを意味する。
実用ユースケースとして報じられているのは、たとえば「React 17→19のコードベース全体マイグレーション」「Pythonの型注釈の網羅的追加」「内部DSLからGraphQLスキーマへの一括書き換え」のような、本来なら「数百本のPRを人間が監督しながら作成する」種類の作業だ。Opus 4.7時代までは「巨大タスクを分解するロジック」を呼び出し側が書く必要があったが、Opus 4.8 + Dynamic WorkflowsはClaude側が分解と検証の両方を引き受ける。
シリコンバレーのテックエンジニアにとって、ここで重要な観察が二つある。第一に、Dynamic Workflowsの存在はOpus 4.8のmax_tokensを「64kスタート」と推奨している理由を裏付けている。サブエージェントの結果集約だけでも数万トークンを食うため、メインオーケスタのmax_tokensが16kでは話にならない。第二に、これはAnthropicの「Claudeをコードベースのリファクタ・マイグレーション請負人にする」という野望を、ツールではなくモデル+ランタイム合わせ技で実現する道筋を明示している。GitHub CopilotやCursorのようなIDE層のラッパーとは異なる、より「自律エージェント色の強い」開発体験になる。
Messages APIの破壊力 — system entriesを「メッセージ配列の中」に入れられるようになった
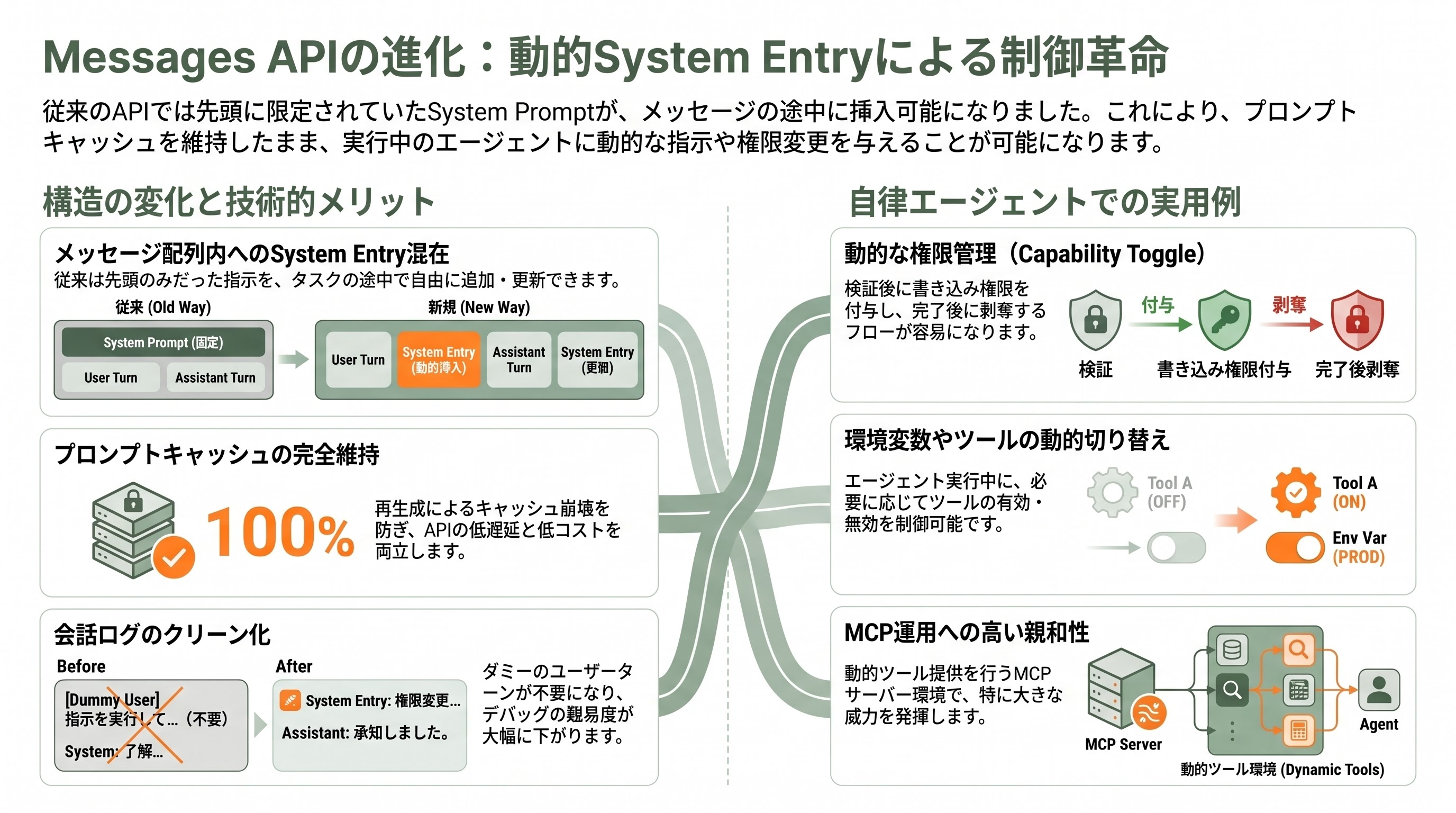
Opus 4.8と同時に投入されたMessages APIの変更は、地味に見えて開発者体験を大きく変える。これまでsystem promptはAPIリクエストの先頭でしか指定できなかったが、Opus 4.8からは「messages配列の中に、system entryを混在させられる」ようになった。Anthropic公式の説明では、これにより「タスク途中でClaudeへの指示を更新できる。プロンプトキャッシュを壊さず、ユーザーターンを経由する必要もなく」という運用が可能になる。
これがエンジニア的に何を意味するか。これまでは長時間の自律エージェント実行中に「権限の追加・削除」「環境変数の差し替え」「ツールの有効/無効切り替え」をしようとすると、新しいシステムプロンプトで再生成するか、ユーザーターンに細工をするしかなかった。前者はプロンプトキャッシュを壊して課金とレイテンシが跳ね上がり、後者は会話ログを汚染してデバッグを困難にする。
Opus 4.8 + 新Messages APIの組み合わせでは、たとえば「最初のシステムプロンプトでは読み取り権限のみ → 検証フェーズが終わったタイミングでmid-task systemエントリを追加して書き込み権限を付与 → 完了後に書き込み権限を剥奪」という流れが、プロンプトキャッシュを壊さずに実装可能になる。長時間動くエージェントのアクセス制御やケイパビリティ・トグルが、APIプリミティブとしてサポートされた、と読むのが正しい。MCP(Model Context Protocol)サーバー越しに動的ツール提供をしているチームには、特に運用上のインパクトが大きい変更だ。
Fast Mode — 2.5倍速で前世代の1/3価格は何を意味するか
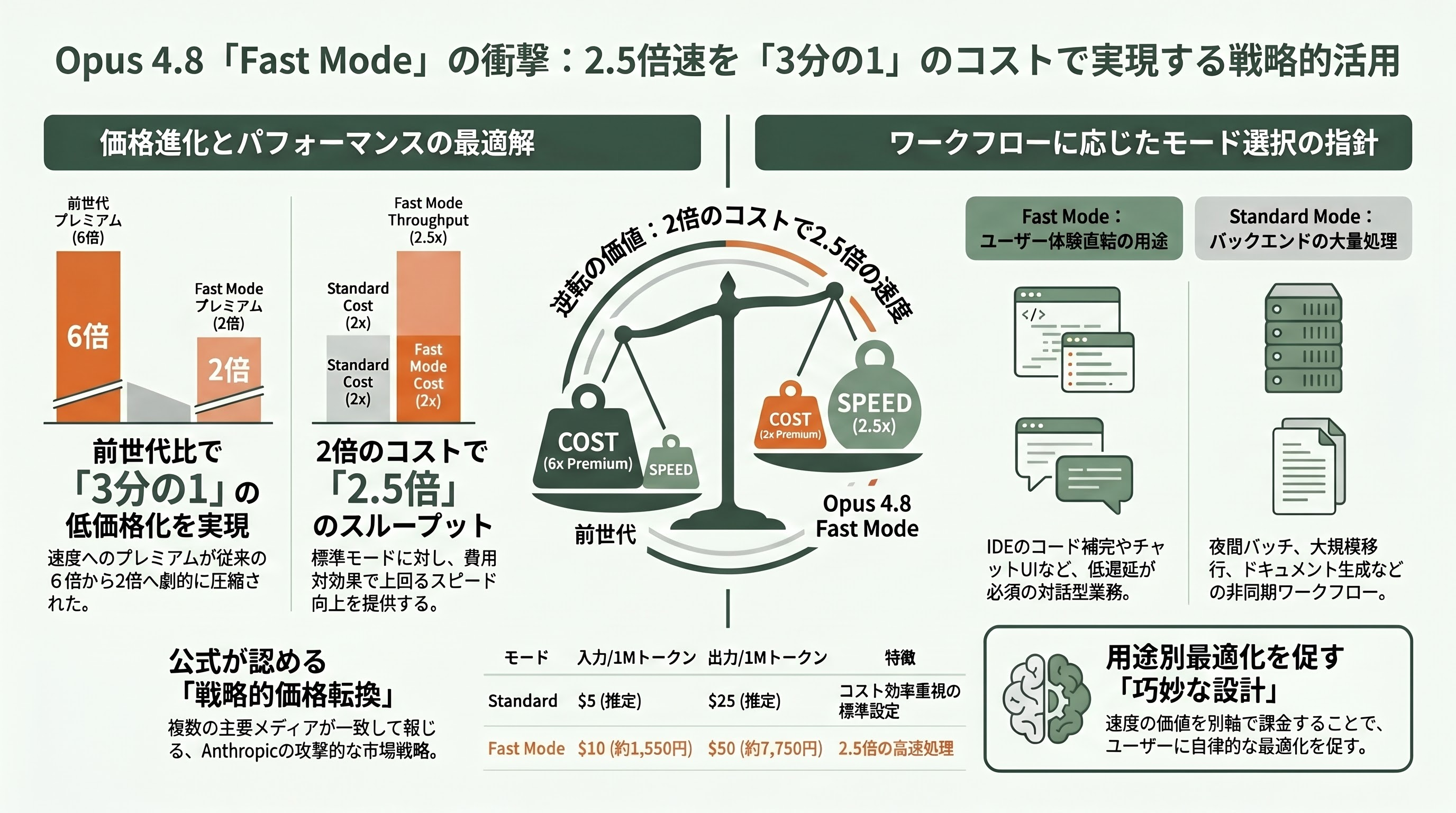
Opus 4.8の「Fast Mode」は、Anthropic公式の公開価格で100万入力トークンあたり10ドル(約1,550円)、100万出力トークンあたり50ドル(約7,750円)に設定された。AxiosとTechCrunchがいずれも明記している通り、これは標準モードの2倍の料金で2.5倍のスループットを提供する。9to5Macは「Opus 4.6時代のFast Modeは標準の6倍プレミアムだった」と言及しており、つまり「前世代までは速さの対価が6倍だったのが、Opus 4.8では2倍で済む」という意味で「3 times cheaper(3分の1の価格)」と表現されている。
cryptobriefingが正式リリース前に書いた記事では「これは公開時点で未確定の噂であり、6倍→2倍は急進的な価格戦略の転換だ」と懐疑的な分析がなされていたが、5月28日の正式リリース時点で複数の一次媒体(Anthropic公式、TechCrunch、Axios、9to5Mac)がこの数字を一致して報じており、確定情報と見て良い。Anthropic公式ブログ自体が「Fast mode … is now three times cheaper than it was for previous models」と直接書いている。
シリコンバレー視点での読み解きは、こうだ。Fast Modeを使うべき場面は、「ユーザーインタラクティブなレイテンシ要求の高いワークフロー」、たとえばIDE内のインライン補完、エンドユーザー向けのチャットUI、低遅延要求のあるAPIゲートウェイ的なユースケースである。逆に、夜間バッチで動かす自律エージェント、長時間のコードベースマイグレーション、ドキュメント生成のような「速度よりコストを優先したい場面」は、標準モードのまま走らせるべきだ。Anthropicが価格据え置きを「標準」で実現しつつ、Fast Modeで「速さの価値」を別軸の課金として切り出した構造は、用途別の最適化を呼び出し側に促す巧妙な設計である。
価格据え置きが示すAnthropicの「採用ゲーム」
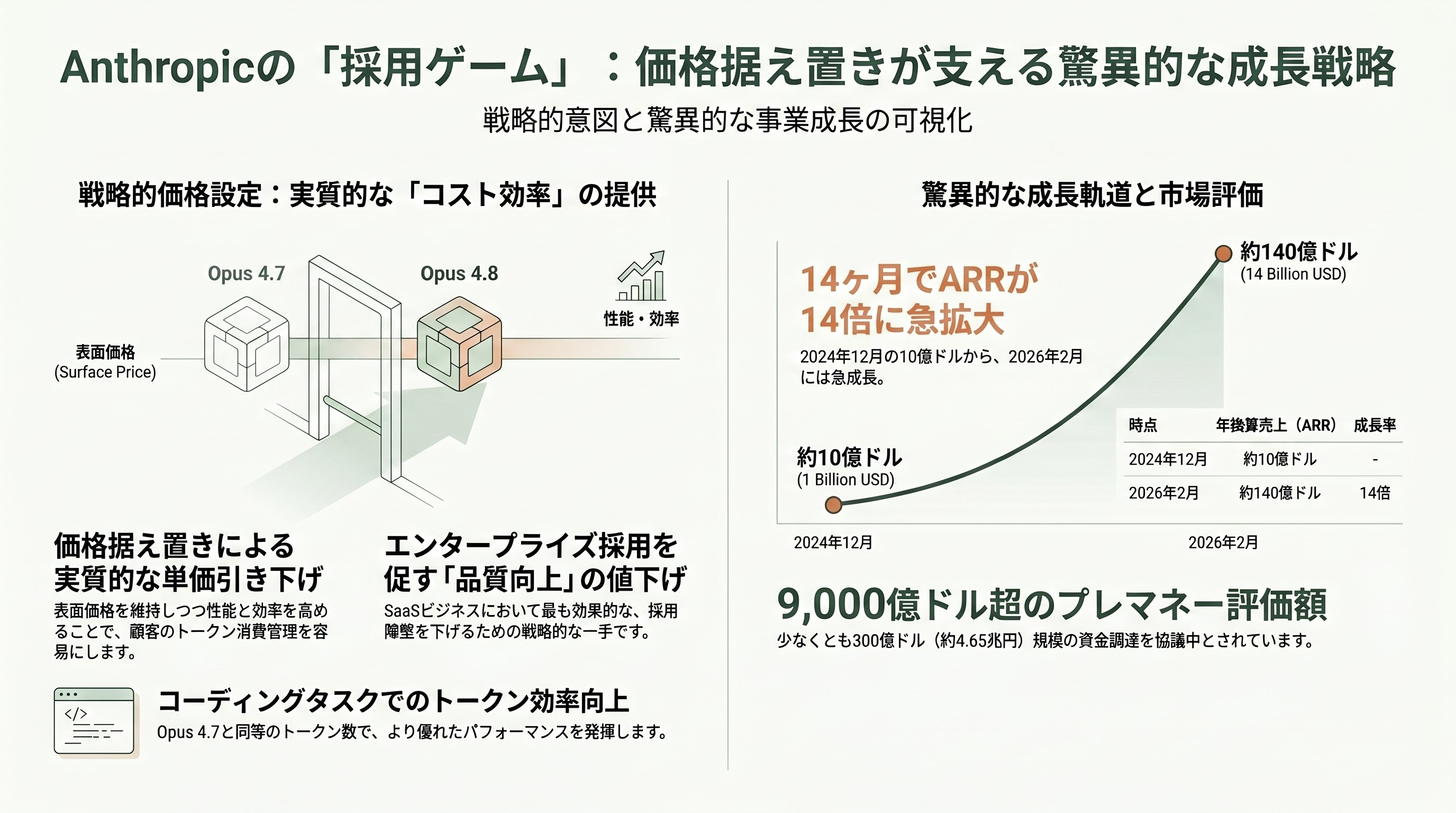
Opus 4.7と同価格でOpus 4.8を出す、というのはエンタープライズ採用層への明確なメッセージだ。Yahoo Financeは「customizable effort settings help users manage token consumption(カスタマイズ可能なエフォート設定で、ユーザーがトークン消費を管理しやすくなる)」と書き、Axiosは「reflects growing customer demand for cost-effective AI solutions(コスト効率の良いAIへの顧客需要の高まりを反映している)」と分析している。
ここで興味深いのは、Anthropicが「トークン単価を下げる」のではなく「同じトークン単価で、より少ないトークンで同じ結果を出せるモデル」を提供することで、実質的な単価を下げているという戦略だ。Opus 4.8公式ブログにある「coding tasks, this effort level spends a similar number of tokens as Opus 4.7's default, but with better performance(コーディングタスクでは、このエフォートレベルでOpus 4.7のデフォルトと似たトークン数で、より良い性能を出す)」という記述は、その本質を示している。トークン課金のSaaSビジネスにおいて、「品質を上げて表面価格は据え置き」は最も効きが良い値下げの形だ。
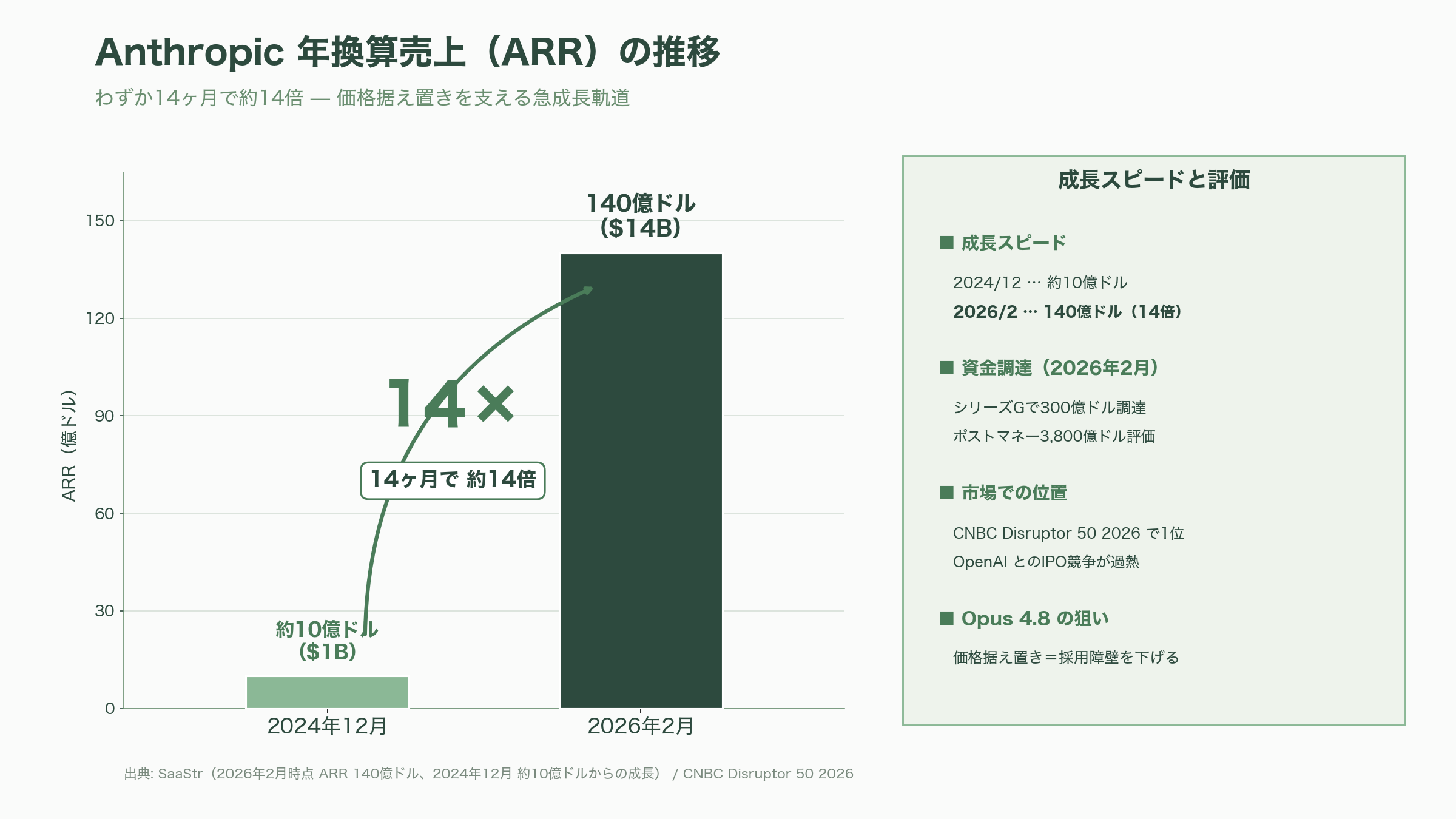
事業面では、SaaStrの2026年2月時点のレポートでAnthropicの年換算売上(ARR)が140億ドル(約2.17兆円)に達したと報じられている。これは2024年12月時点の約10億ドルから、わずか14ヶ月で14倍に成長した数字だ。CNBC Disruptor 50 2026では1位にランクされ、5月時点では「9,000億ドル(約139.5兆円)超のプレマネー評価額で、少なくとも300億ドル(約4.65兆円)の調達を協議中」とBloomberg系のリークが流れた(Sacra集計)。Opus 4.8の価格据え置きは、こうした成長軌道を継続するための「採用障壁を下げる」一手と読むのが妥当だろう。
各メディアの報道スタンス比較
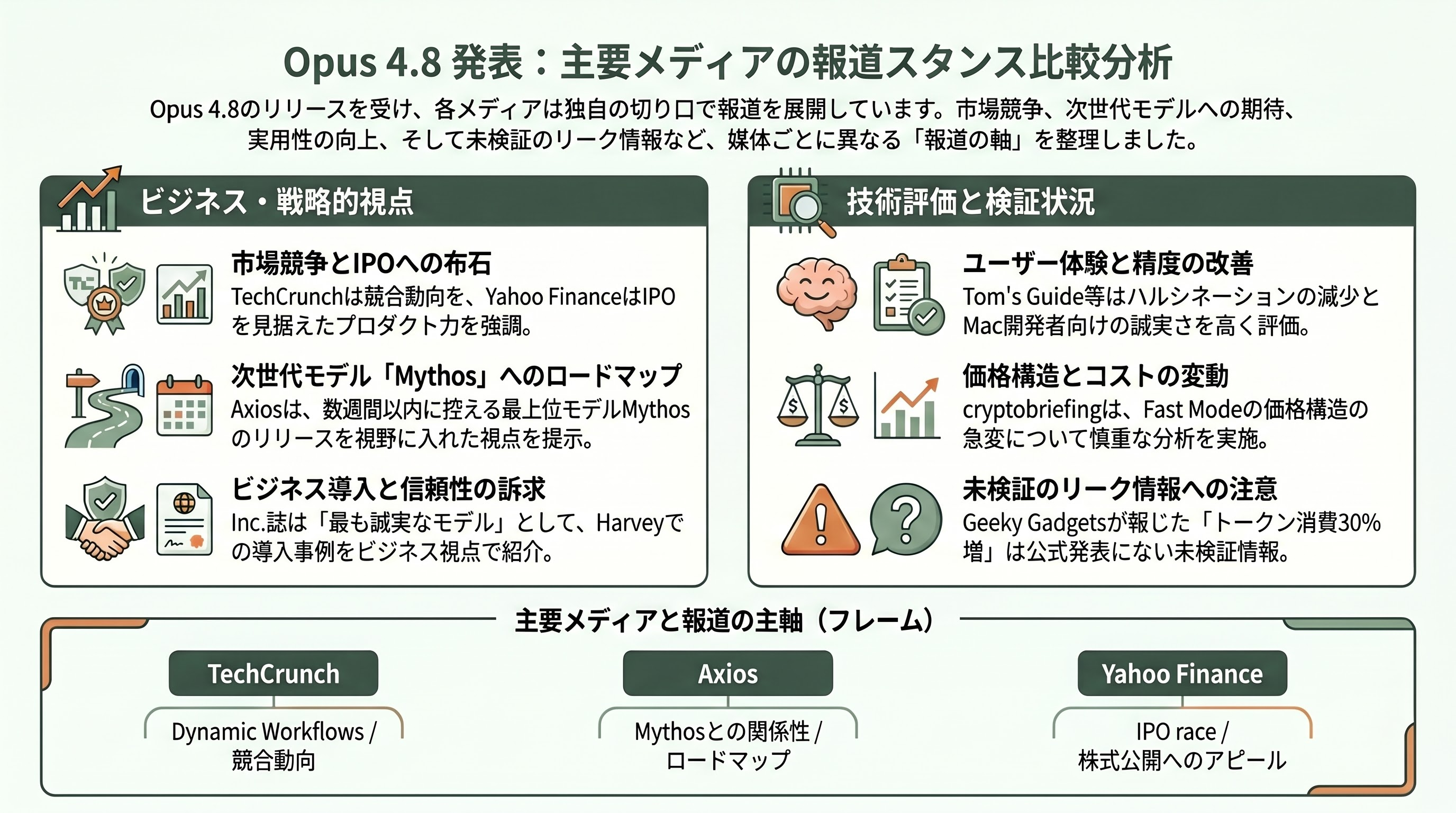
Opus 4.8の報道を見渡すと、媒体ごとに切り口の違いが鮮明に現れていて興味深い。TechCrunchは「Dynamic Workflowsツール」を主軸に据え、「OpenAIのCodex、GoogleのGemini Flashの最近のリリースに続く競合動向」というフレームで位置づけた。Axiosは未公開モデルMythosとの関係性を強調し、「Opus 4.8はMythosには及ばないが、Mythos級モデルの一般リリースが数週間以内に控えている」というロードマップ的視点を提示した。Yahoo Financeは「IPO race」フレームで、OpenAIとの株式公開競争のなかでのプロダクト力アピールという文脈を打ち出した。
Tom's Guideと9to5Macは消費者向け・Mac開発者向けに「より誠実」「ハルシネーションが減った」という体験面の改善を強調している。Inc.誌は「最も誠実なモデル」というメッセージを軸に、ビジネスユーザー目線でHarveyの導入事例を引用した。cryptobriefingは正式リリース直前の懐疑記事と、リリース後の解説記事の両方を出しており、特にFast Modeの価格構造の急変について慎重な姿勢を見せていたが、リリース当日に確定情報に修正している。
Geeky Gadgetsはリーク段階で「トークナイザの更新でトークン消費が約30%増える可能性」という未確認情報を流していた。公式リリース後の複数の一次情報では、この点について明確な記載は見つかっていない。Anthropic公式ブログにはトークナイザ変更の言及がなく、API SDKの差分を見てもユーザー側のトークンカウントAPIに変更はないため、現時点ではGeeky Gadgetsのリークは「未検証」と扱うのが妥当だ。記事執筆時点でこの30%増説を裏付ける独立した一次情報源は確認できていない。
日本語圏では本記事執筆時点(2026-05-29)で大手紙の本格的な特集はまだ少なく、英語圏一次情報を訳出する段階にある。日経新聞や東洋経済オンラインのような媒体が本格的に切り込むのはもう数日先と見られる。
シリコンバレーのテックエンジニアが今やるべきこと(実用Tips集)

まず、既存コードベースをOpus 4.8に移すなら、モデルIDをclaude-opus-4-7からclaude-opus-4-8へ差し替えるだけで動く。ただしthinking: {type: "enabled", budget_tokens: N}を明示している箇所は400エラーになるため、thinking: {type: "adaptive"}+output_config.effortの組み合わせに書き換える必要がある。budget_tokensが散在する古いコードを抱えているチームは、リグレッションテストを走らせる前に一括grepで洗い出すべきだ。
次に、エフォート設定の運用設計。本番ワークロードを大別すると、「ユーザー対話型(チャット、補完、対話インタフェース)」はmediumまたはlow、「コードレビュー・コード生成」はhighまたはxhigh、「夜間バッチ・コードベースマイグレーション・複雑な金融分析」はxhighまたはmax、というのが筆者の実用ガイドラインだ。Anthropic公式の「maxは構造化出力で過剰思考を起こす」という警告は重要で、JSONスキーマ厳密出力のような場面で安易にmaxを選ぶとむしろ品質が下がる。
xhigh/maxを使うときのmax_tokensは公式推奨通り64kスタートが安全だ。AnthropicのGo SDKではanthropic.OutputConfigEffortXhigh、Python SDKではoutput_config={"effort": "xhigh"}という形で指定する。ストリーミングAPIで使う場合、思考フェーズが長くなるためフロントエンドのタイムアウト設定(特にHTTP/2のkeep-aliveやAPIゲートウェイのデフォルト30秒タイムアウト)に注意したい。
Dynamic Workflowsを試すなら、まずは「テストスイートが充実しているリポジトリ」での移行作業から始めることを強く推奨する。Anthropic自身が「existing test suites as a benchmark(既存テストスイートをベンチマーク代わりに)」と書いている通り、テストが品質保証のグラウンドトゥルースになる。テストが薄いコードベースで巨大マイグレーションを走らせると、サブエージェントが「動くが意味的に間違っているコード」を量産するリスクがある。
Messages APIの新機能(mid-task system entry)は、ツール権限の動的トグル、長時間ジョブ中のコンテキスト追加、A/Bテストでのプロンプト差し替えに使うと真価を発揮する。プロンプトキャッシュを壊さない、というのが本質的な価値で、長文のシステムプロンプトを最初に投げてキャッシュさせ、後段でmid-task systemエントリで差分指示を加える、というパターンが新しいベストプラクティスになっていくはずだ。
最後に、Fast Modeの使い分け。エンドユーザー向けレイテンシ要件があるプロダクションパスのみFast Modeを選び、内部ツール・バッチ処理は標準モードに固定する、というのが最もコスト効率が良い。同じプロダクト内で「ユーザー向けはclaude-opus-4-8 + Fast Mode、社内向けはclaude-opus-4-8標準モード」という二経路運用を、APIゲートウェイ層でルーティングするのが現実的だ。
今後の見通し — Mythosとその先
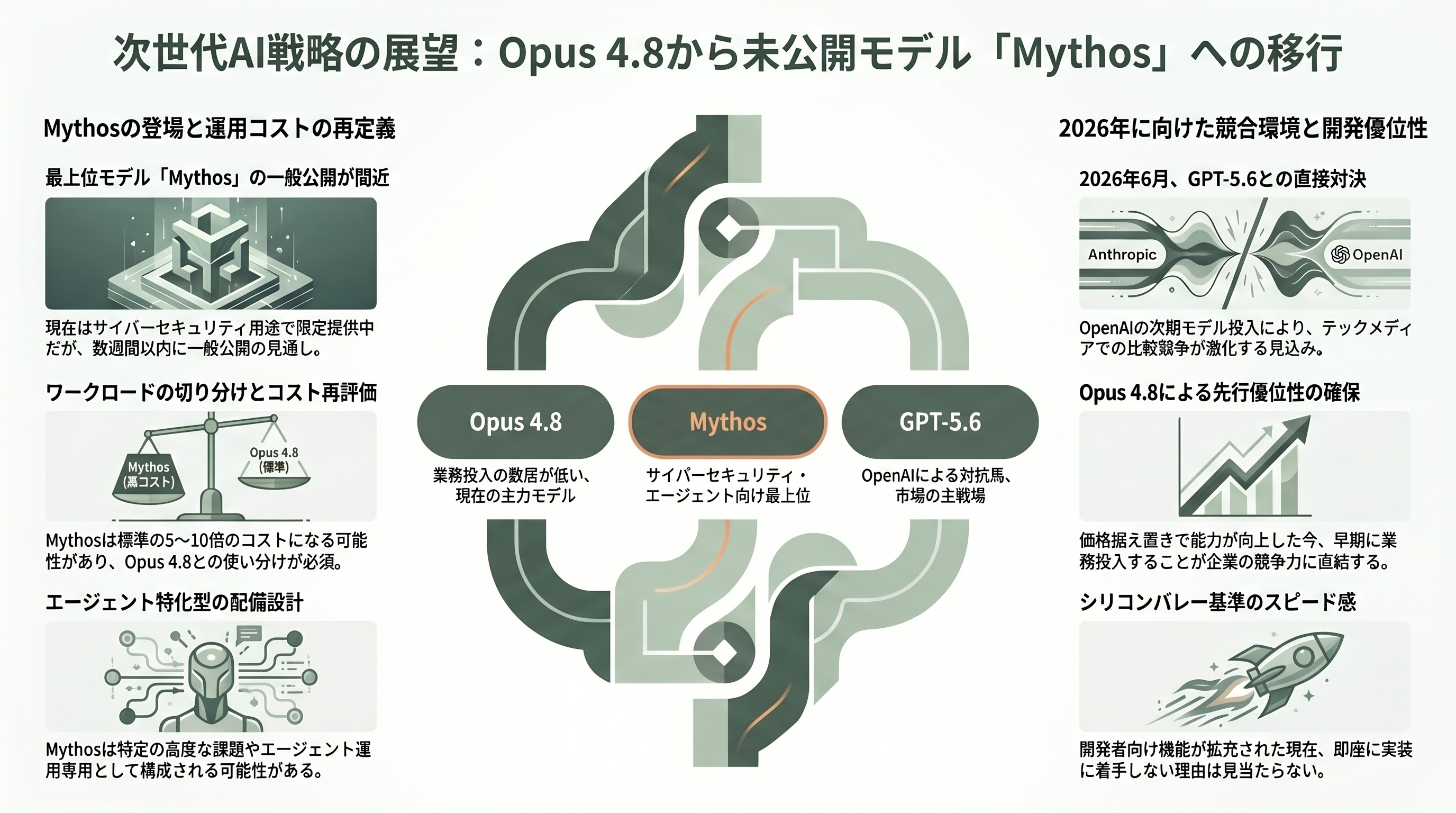
Anthropic自身がOpus 4.8公式ブログで言及している通り、Opus 4.8よりさらに上位の未公開モデル「Mythos」が控えている。現時点では「Project Glasswing」と呼ばれるサイバーセキュリティ用途で限定パートナーにのみ提供されているが、「サイバーセキュリティ面のセーフガードを開発し終え次第、数週間以内に一般顧客にも提供する見通し」とアナウンスされた。Axiosは「Opus 4.8 still underperforms compared to Mythos(Opus 4.8でもMythosには及ばない)」と明記しており、上位モデルの存在は確定情報である。
エンジニア視点では、Mythosが標準APIに乗ってくるタイミングで「Opus 4.8で構築したアプリのレイテンシ・コスト構造を再評価する必要がある」というのが現実的な見通しだ。Mythosが標準モード5〜10倍コストの可能性、xhigh/max専用、あるいは限定的なエージェント向け運用のみといった配備設計になる可能性があり、いずれにせよ「Opus 4.8で安定運用しているワークロード」と「Mythosでしか解けない新規問題」を切り分ける運用構成が問われる局面が来る。
加えて、競合側ではOpenAI GPT-5.6(リーク情報ベースで2026年6月予定)、Google Gemini次期版が連続投入される見込みだ。Opus 4.8 vs GPT-5.6の比較記事が6月以降のテックメディアの主戦場になることはほぼ確実で、その時点で「Opus 4.8で何を作れるか/作ったか」が、シリコンバレーのスタートアップ・エンタープライズ双方の競争力に直結する局面となる。
Opus 4.8は「価格据え置き、能力向上、開発者向けプリミティブ拡充」という三拍子が揃った、業務投入の敷居が極めて低いリリースだ。シリコンバレーのエンジニアにとって、いま手を動かさない理由を探すほうが難しい。