PLaMo 2.0 Prime ― 国産フルスクラッチLLMの到達点
PLaMo(Preferred Language Model)は、海外の公開モデルを日本語向けに微調整したものではなく、ゼロから自前で設計・学習した「フルスクラッチ」の大規模言語モデルである。この点が、後述する国産勢の多くと PFN を分ける最初の分水嶺になる。
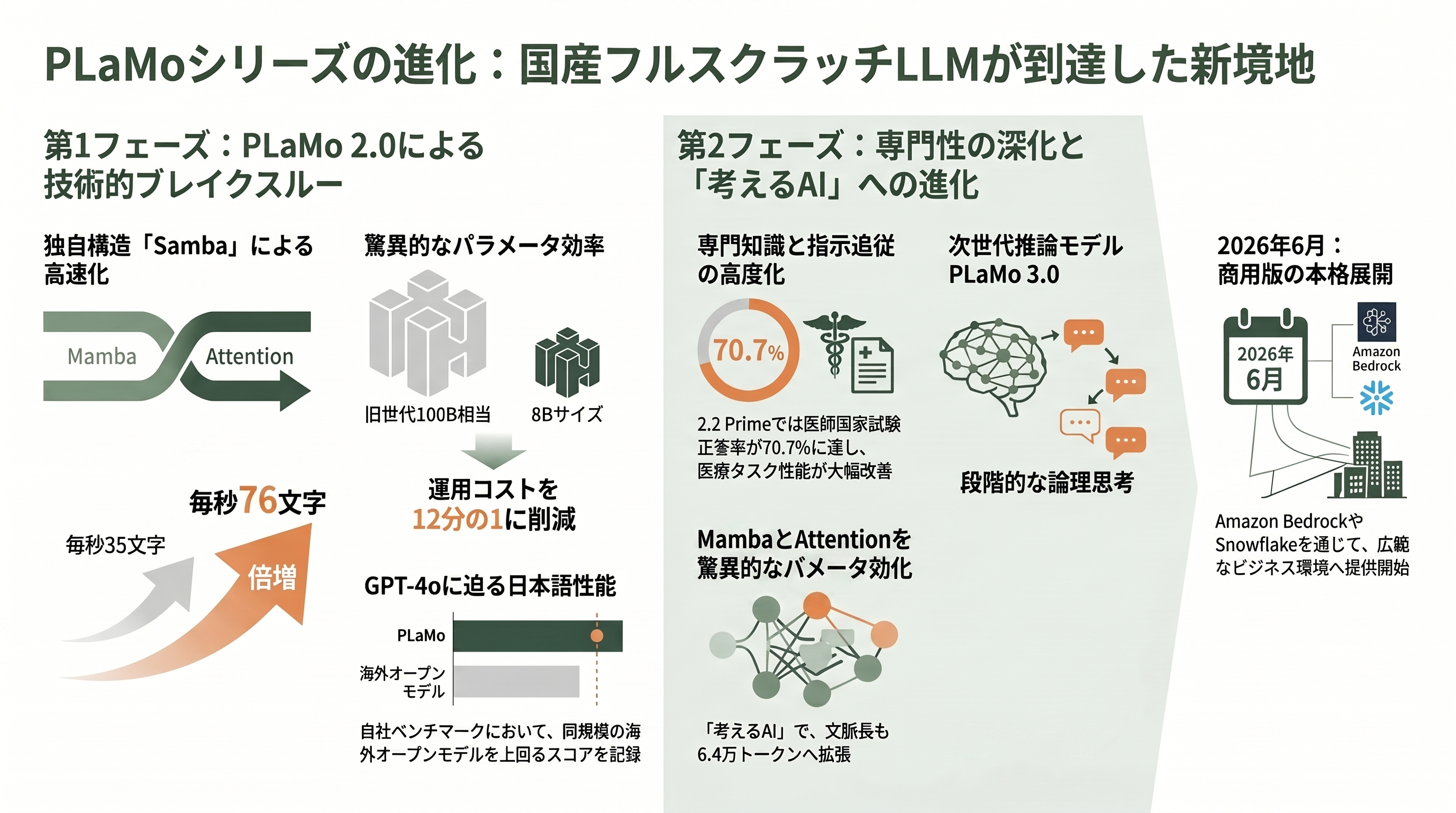
その主力が PLaMo 2.0 Prime だ。PFN は2025年5月22日にこのモデルをリリースし、80億パラメータ(8B)と310億パラメータ(31B)の二本立てで提供を始めた。技術的に最も特徴的なのは「Samba系」と呼ばれるハイブリッド構造を採った点である。一般的な大規模言語モデルは Transformer の自己注意(Self-Attention)機構を全層に積み重ねるが、自己注意は文章が長くなるほど計算量とメモリ消費が跳ね上がるという弱点を抱える。PLaMo 2.0 Prime は、その一部の層を、計算履歴をコンパクトに畳み込む状態空間モデル(Mamba)と、近い範囲だけに注意を絞る Sliding Window Attention に置き換えた。これにより、長い文章を読み込ませても処理が破綻しにくく、生成速度も向上した。PFN の技術ブログによれば、文字の生成速度は旧世代の毎秒35文字程度から毎秒76文字程度へと大幅に高速化している。
性能面では、PFN が自社開発した日本語生成ベンチマーク「pfgen」において、PLaMo 2.0 Prime(31B)が GPT-4o に次ぐスコアを記録し、同じ規模帯の海外オープンモデル(Qwen2.5-32B や Gemma 27B など)や、当時話題を呼んだ DeepSeek-R1・Qwen-Max をも上回ったと報告された。注目すべきは8B版の効率で、わずか80億パラメータながら、前世代の1000億パラメータ(100B)モデルと日本語性能で同等以上を、約12分の1のサイズで実現したという。これは「日本語に賢いモデルを、現実的なコストで動かす」という実務上の要請に応えるものだ。
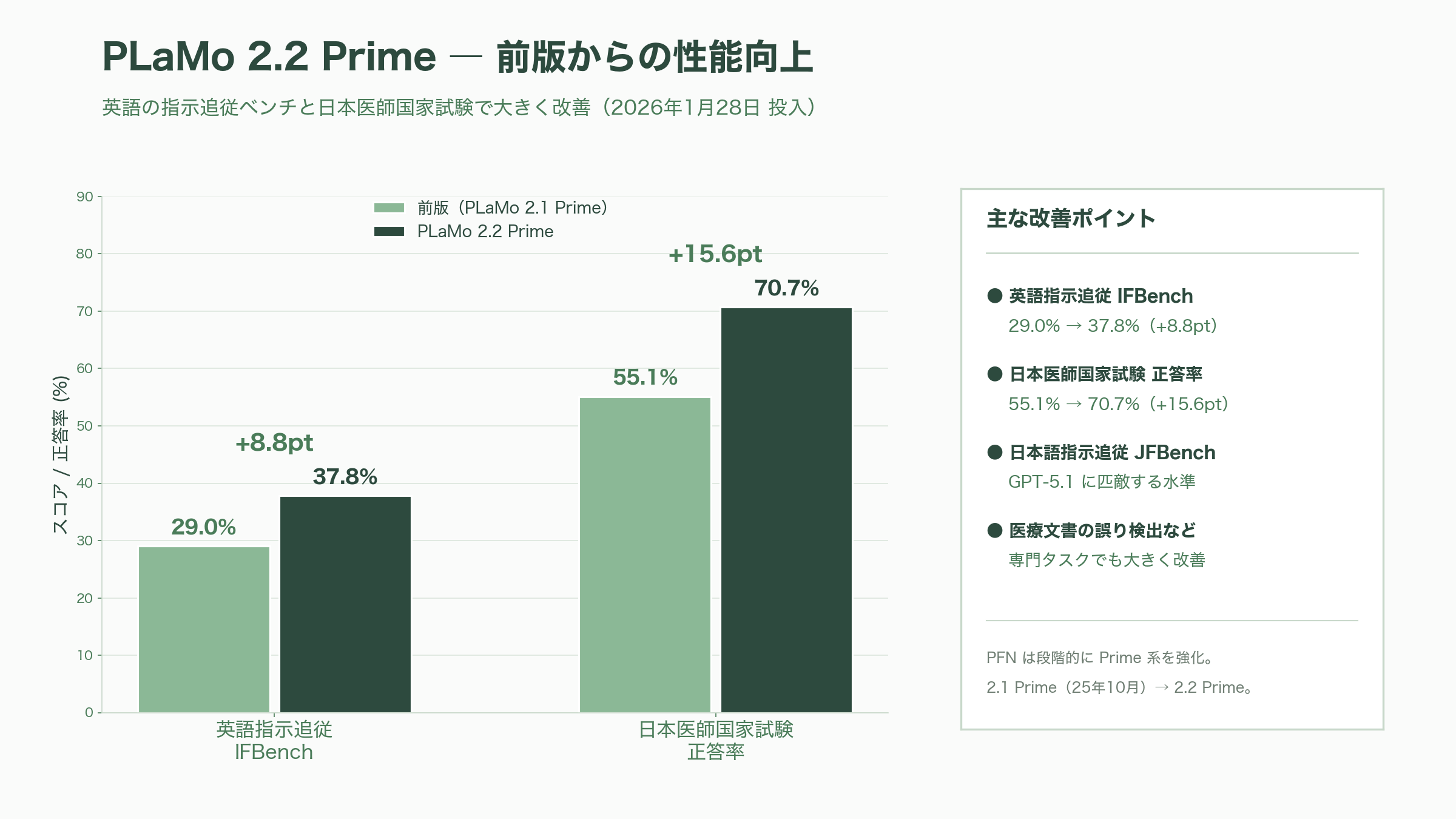
ここで重要な但し書きを添えておきたい。本稿のタイトルは依頼に従い「PLaMo 2.0 Prime」を冠しているが、2026年6月時点で PLaMo 2.0 Prime はすでに最新版ではない。PFN はその後、エージェント機能(外部ツールとの連携)を強化した PLaMo 2.1 Prime を2025年10月に、指示追従と専門知識を底上げした PLaMo 2.2 Prime を2026年1月28日に投入している。2.2 Prime は、英語の指示追従ベンチIFBenchで前版の29.0%から37.8%へ伸ばし、日本語の指示追従を測る自社ベンチ JFBench では「GPT-5.1 に匹敵する」水準に達したとされる。さらに、日本医師国家試験を解かせる評価では正答率が55.1%から70.7%へと跳ね上がり、医療文書の誤り検出といった専門タスクでも大きく改善した。
そして2026年3月19日、PFN は国産では初となるフルスクラッチの「推論(Reasoning)モデル」PLaMo 3.0 Prime のβ版を公開した。これは答えを即答するのではなく、複数の条件を論理的に整理しながら段階的に結論へ至る「考えるAI」で、扱える文脈長は従来の3万2千トークンから6万4千トークンへ、一度に出力できる長さも大幅に拡張された。PFN の公式発表によれば、PLaMo 3.0 Prime の商用版は2026年6月中旬に正式提供される予定で、Amazon Bedrock や Snowflake 経由での展開も計画されている。本稿の公開日である6月22日は、まさにこの商用版が市場に出始める時期にあたる。
翻訳・API・Chat・Lite ― 用途で使い分けるPLaMoファミリー
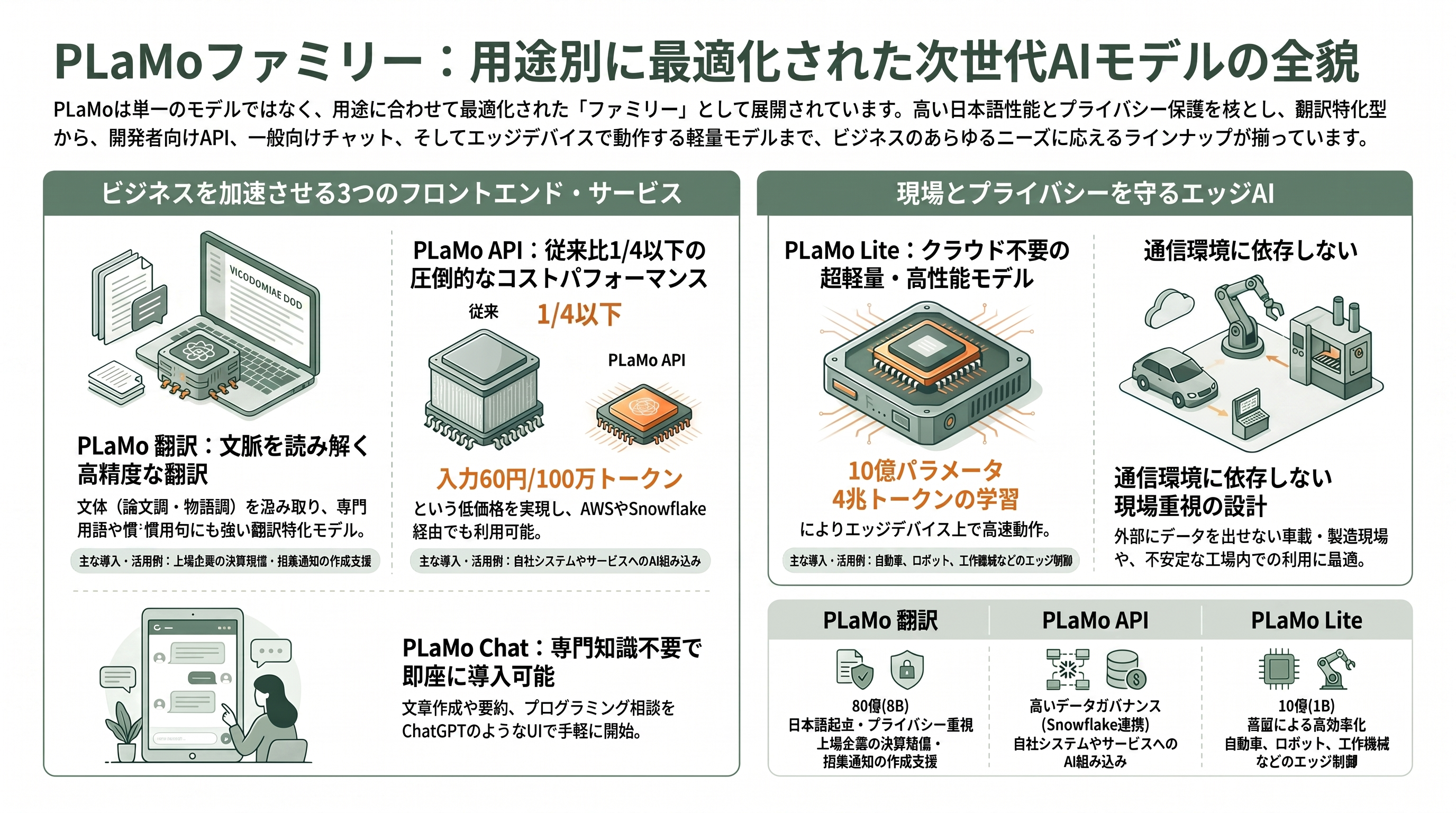
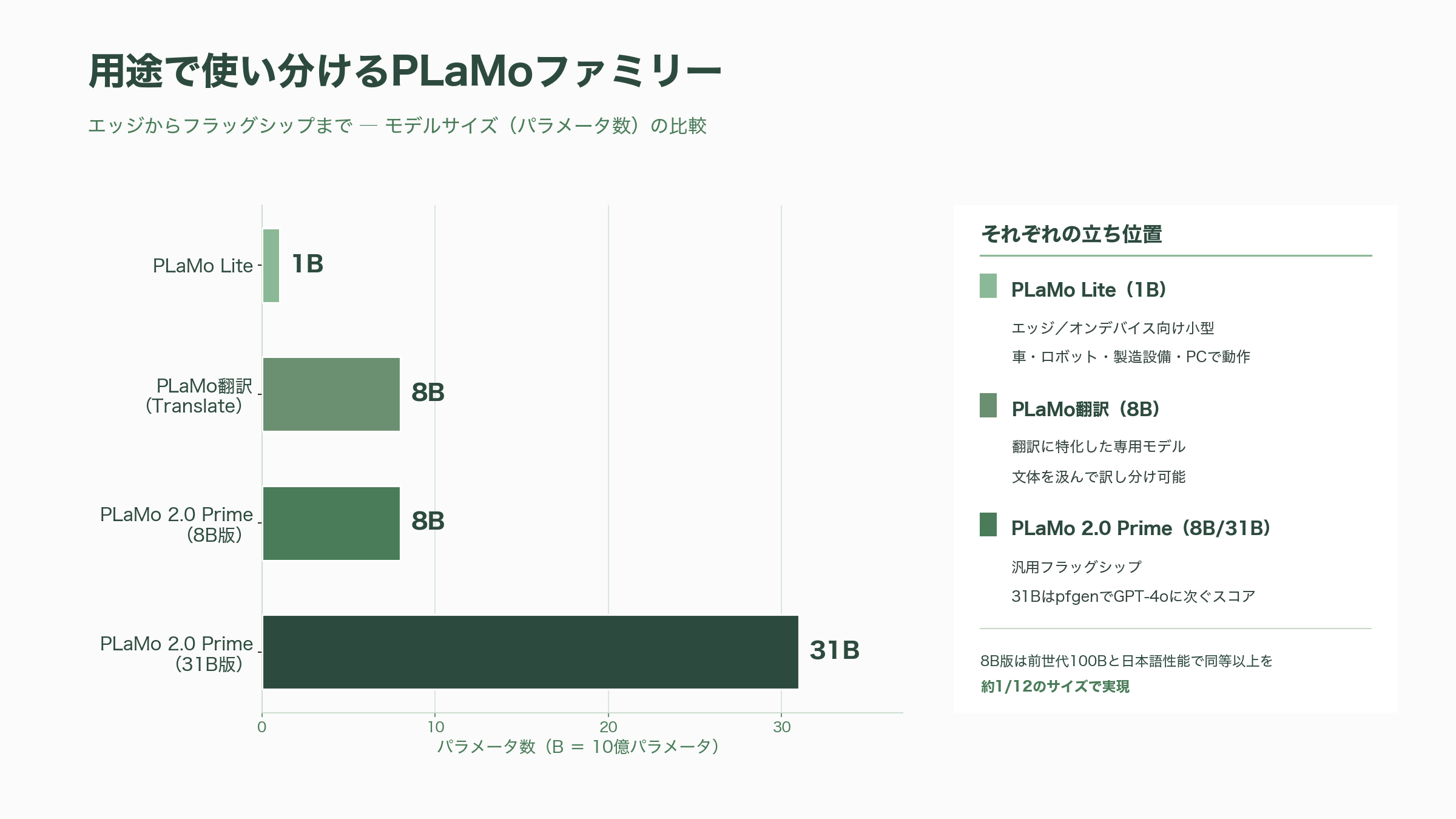
PLaMo は単一の汎用モデルではなく、用途ごとに姿を変えるファミリーとして展開されている。残る四つのサービスを順に見ていこう。
PLaMo翻訳(PLaMo Translate)は、汎用モデルではなく翻訳に特化させた80億パラメータの専用モデルで、2025年5月27日に公開された。最大の持ち味は、大規模言語モデルならではの文脈把握力を翻訳に活かしている点にある。たとえば学術論文の抄録は硬めの論文調で、物語は物語調でと、原文の文体を汲んで訳し分けることができ、慣用句やマイナーな言い回しにも従来の対訳コーパス依存型より強い。Web版のデモは無料で使え、ローカル動作版のモデルは Hugging Face 上で無償公開されている。WindowsやMac向けのデスクトップアプリも提供され、ショートカットキー一発での選択範囲翻訳や、用語集を効かせたファイル翻訳に対応する。料金は個人や小規模向けの Lite プランが用意され、5名以上のチーム向けプランはキャンペーン価格で1ユーザーあたり月額1,980円(税込2,178円)から利用できる。競合の DeepL や Google翻訳とは、入力したテキストが学習に使われる懸念がないというプライバシー設計、そして日本語を起点に扱う設計思想で差別化を図っている。実際の導入例として、開示書類作成支援を手がけるプロネクサスが、上場企業の決算短信や株主総会招集通知の翻訳に PLaMo翻訳を採用し、2026年4月からオンプレミスでの利用を始めている。
PLaMo API は、これらのモデルを自社のサービスやシステムに組み込みたい開発者・企業向けの提供形態である。PFN は2024年12月に Prime 系の API 提供を開始し、2025年5月の PLaMo 2.0 Prime 対応にあわせて料金を大胆に引き下げた。新料金は入力が100万トークンあたり60円、出力が100万トークンあたり250円で、旧 Prime と比べて4分の1以下という積極的な価格設定だ。新規契約者には1,000万トークン相当の無料クレジットも付く。提供チャネルも自社クラウドにとどまらず、Amazon Bedrock マーケットプレイスや、2026年5月には Snowflake マーケットプレイスにも登場した。Snowflake 経由であれば、企業は自社データを外部に持ち出すことなくモデルを呼び出せるため、データガバナンスを重んじる業務での採用障壁が下がる。
PLaMo Chat は、専門知識のない一般ユーザーでもブラウザからすぐに使える対話型サービスだ。メールアドレスの登録と6桁のログインコードだけで利用を始められ、文章作成や要約、プログラミングの相談まで ChatGPT のように扱える。リリース記念のキャンペーン期間中は無料で開放されている点が大きな魅力だが、この「無料」はあくまでキャンペーン措置であり、恒久的な無料化が約束されたものではない点には留意が必要だ。
PLaMo Lite は、ファミリーの中で最も小さく、最も現場に近いモデルである。2024年8月28日に発表された10億パラメータ(1B)の小型モデルで、クラウドに接続せずとも自動車やロボット、製造設備、PC といったエッジデバイス上で高速に動く点に主眼が置かれている。前世代の100Bモデルから知識を蒸留し、その100Bが生成した合成データも含めて4兆トークンを学習させることで、1Bという小ささでありながら同規模のモデルを大きく引き離す日本語性能を実現したという。通信が不安定な工場や、機密保持のためにデータを外に出せない車載・産業用途で、その真価が問われる設計だ。
競合との立ち位置 ― チップからアプリまで自前で抱える「フルスタック」の意味
PLaMo を国産LLMの地図の上に置くと、その独自性がくっきりと浮かび上がる。
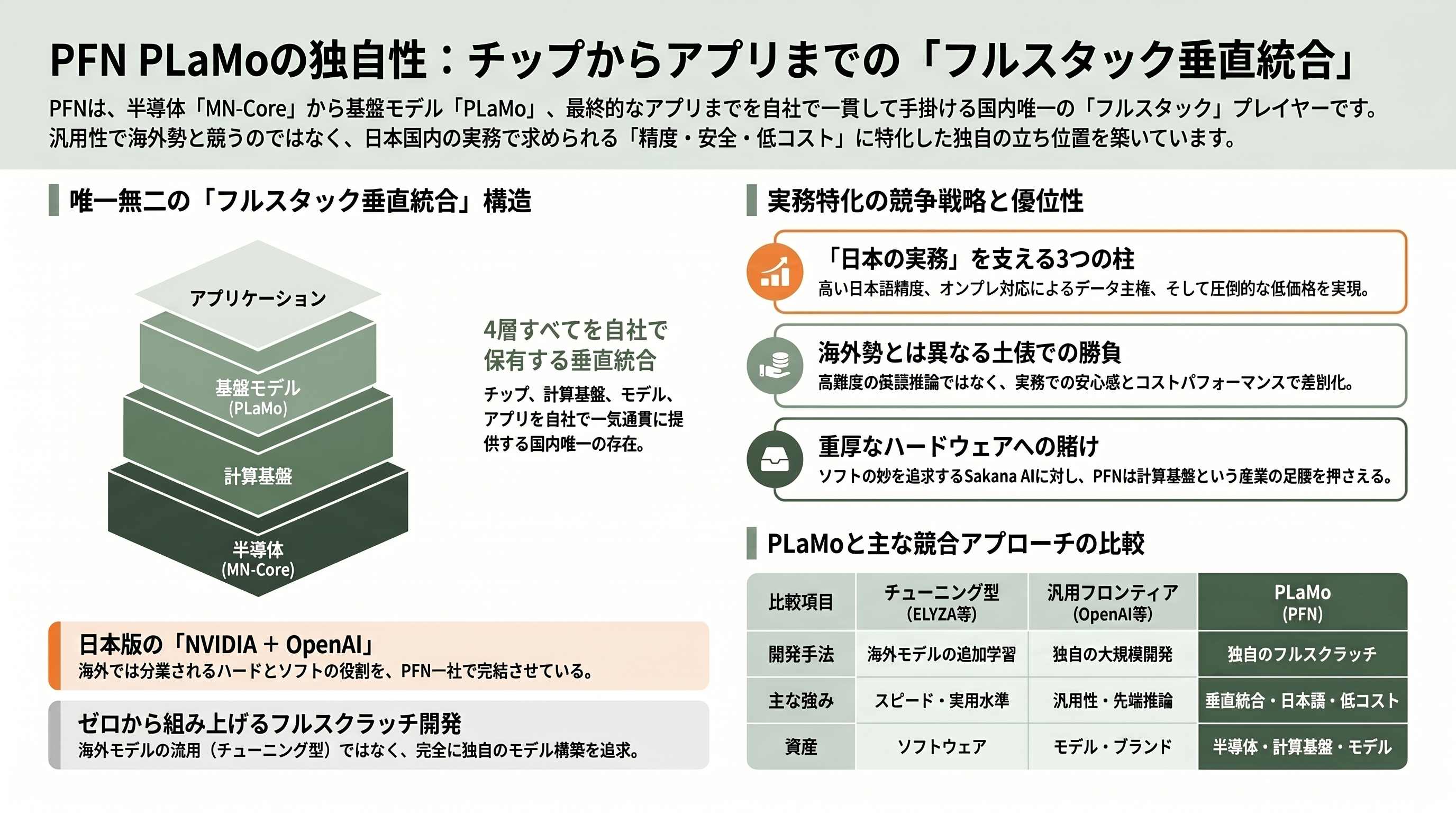
まず開発アプローチの違いがある。KDDI 傘下となった ELYZA や CyberAgent は、Meta の Llama や Alibaba の Qwen といった海外のオープンモデルに日本語の追加学習を施す「チューニング型」で素早く実用水準に到達する戦略をとる。一方、PFN やソフトバンク傘下の SB Intuitions(Sarashina 系)、NTT(tsuzumi 系)、Stockmark などは、海外モデルに依存せずゼロから組み上げる「フルスクラッチ型」を選んでいる。PLaMo はこの後者の代表格であり、複数の日本語ベンチマークで世界トップ級のスコアを掲げて差別化を図る。
しかし PFN の本当の独自性は、モデルそのものよりも、その下に敷かれた基盤にある。PFN は AI を動かす半導体「MN-Core」を自社開発し、その上に計算基盤(AIクラウド)を構築し、さらにその上で基盤モデル PLaMo を学習・運用し、最終的に業務ソリューションまで届ける――という四つの層をすべて自前で抱える。チップからアプリまでを垂直統合している国産プレイヤーは PFN だけであり、これが「フルスタック垂直統合」と呼ばれる所以だ。海外勢に置き換えれば、NVIDIA のシリコンと OpenAI のモデルと各社のアプリを、一社で串刺しにしようとしているに等しい。
対する OpenAI、Anthropic、Google といったフロンティア勢との比較では、評価は単純な勝ち負けにならない。PFN 自身が PLaMo 3.0 Prime β版の公開時に率直に認めているように、関数呼び出し(BFCL)や高難度の英語推論(GPQA)といった汎用・先端領域では、海外のフロンティアモデルに明確に水をあけられている。PLaMo が勝負を挑むのは、そこではない。日本語の精度、純国産であることによるデータ主権とオンプレミス運用のしやすさ、そして圧倒的な低価格――この三つを束ねた「日本の実務で安心して使える国産LLM」という土俵である。実際、PLaMo 2.0 Prime は2026年1月に日本経済新聞社の「2025年 日経優秀製品・サービス賞 最優秀賞」を受賞しており、国産という安心感と日本語実務性能、海外同等サイズ比でのコスト優位が高く評価された。
なお、国産ユニコーンとして並び称されることの多い Sakana AI とは、そもそも狙う場所が異なる。Sakana AI は複数のモデルを「進化的にかけ合わせる」独自技術を武器に金融分野へ深く食い込む戦略で、2025年11月には1億3,500万ドル(約200億円)を調達し、企業価値は26億5,000万ドル(約4,000億円)と国内最高水準のユニコーンに駆け上がった。一方の PFN は、巨額の VC マネーよりも事業会社や政府系金融との連携を軸に、産業の足腰となる計算基盤そのものを押さえにいく。同じ「国産AI」でも、片や軽やかなソフトウェアの妙、片や重厚なハードウェアの賭けという対照をなしている。

Preferred Networks ― 「現実世界を計算可能にする」会社の歩み

Preferred Networks の物語は、2014年の設立よりもさらに8年さかのぼる。源流は2006年3月、東京大学の学生らが立ち上げた Preferred Infrastructure(PFI)にある。自然言語処理と検索エンジンを主戦場とするこの会社から、ディープラーニングの実世界応用に専念するために2014年3月26日にスピンアウトして生まれたのが PFN だ。共同創業者は西川徹(代表取締役社長兼CEO)と岡野原大輔で、「現実世界を計算可能にする(make the real world computable)」をミッションに掲げ、交通システム・製造業・バイオヘルスケアの三領域を初期の重点に据えた。
設立直後から PFN は大企業との二人三脚で存在感を放つ。2014年10月に NTT と資本業務提携を結ぶと同時にトヨタとの共同研究を開始し、2015年6月には深層学習フレームワーク「Chainer」を公開した。これは Google の TensorFlow ベータ版よりも早く、当時としては先進的な「Define-by-Run」という設計思想で世界の研究者の注目を集めた。同じ2015年にはファナックやパナソニックとの提携も発表され、製造現場へとディープラーニングを持ち込む流れが固まっていく。
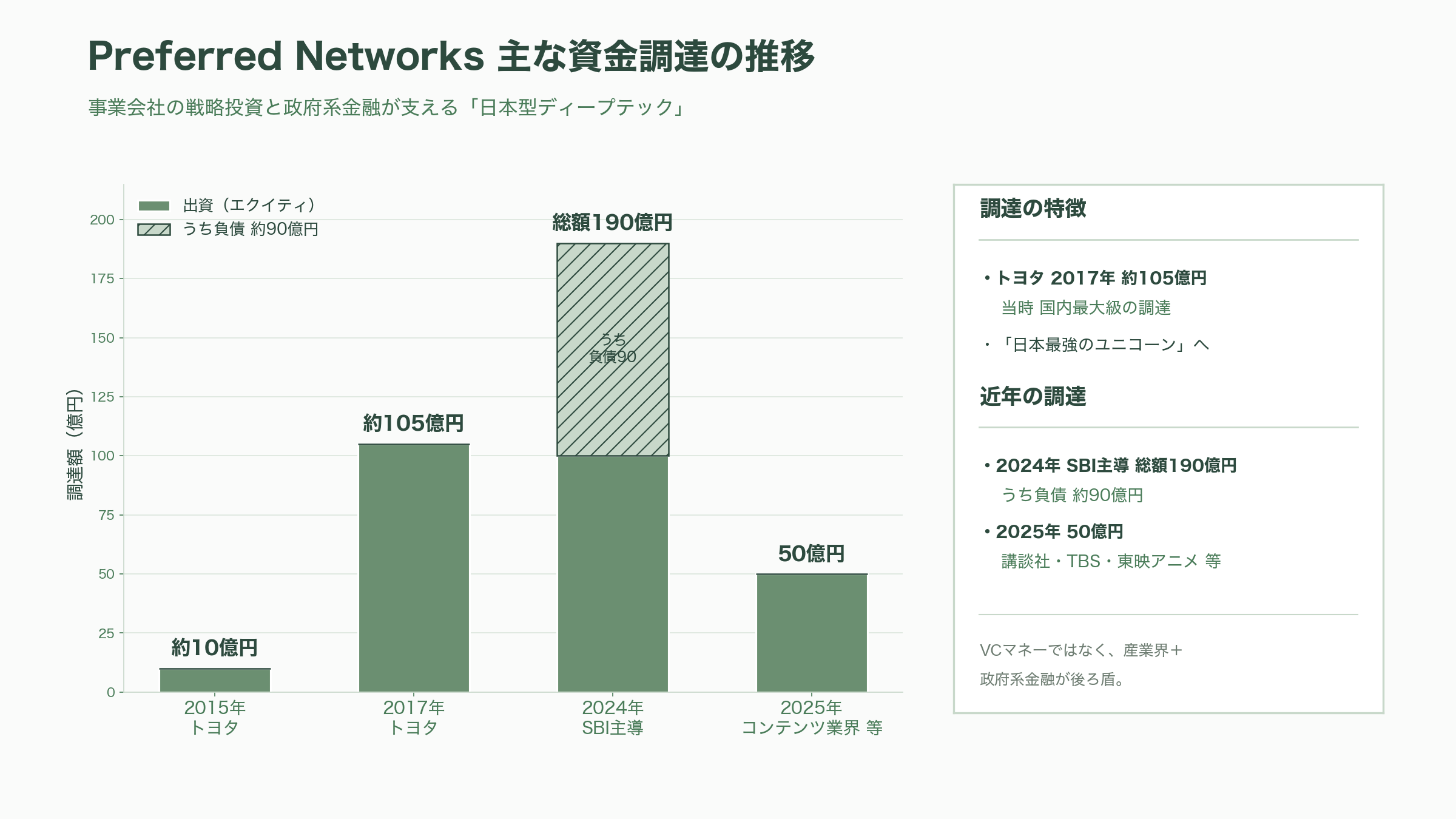
資金調達の歴史は、そのまま日本の主要産業との同盟の歴史でもある。2015年12月にトヨタが約10億円を出資し、2017年8月には同じトヨタが約105億円を追加出資した。これは当時の国内スタートアップとして最大級の調達であり、PFN を一躍「日本最強のユニコーン」と呼ばれる存在に押し上げた。その後も博報堂DY、日立、みずほ、三井物産、中外製薬、東京エレクトロン、JXTG(現ENEOS)といった各業界の代表企業が次々に出資者として名を連ねていく。直近では2024年12月に SBI が主導する形で総額190億円(うち負債が約90億円)を、2025年4月にはさらに50億円を調達し、講談社やTBS、東映アニメといったコンテンツ業界からも資金を集めた。
事業の裾野も大きく広がった。トヨタとの自動運転、ファナックとの産業用ロボットに始まり、2016年にはがん研究に乗り出し、2021年には ENEOS との合弁で材料探索シミュレータ「Matlantis」を世に出した。家庭用ロボット「カチャカ」を手がける Preferred Robotics も設立している。なかでも象徴的なのが、神戸大学の牧野淳一郎チームと共同開発した独自プロセッサ MN-Core だ。2018年に第1世代を発表し、これを積んだスーパーコンピュータ MN-3 は、電力あたり性能を競う世界ランキング「Green500」で2020年6月、2021年6月、2021年11月と三度にわたり世界1位に輝いた。
生成AIへの本格参入は2023年9月の PLaMo-13B 公開に始まる。同年11月にはLLM開発に特化した子会社 Preferred Elements を設立し(その代表に就いたのが岡野原である)、経済産業省・NEDO の国家プロジェクト GENIAC の支援を受けて2024年10月に純国産の PLaMo-100B を完成させた。なお Preferred Elements は2025年7月に PFN 本体へ吸収合併され、以降は PFN が直接 PLaMo を提供している。財務面では、官報の決算公告をもとにした報道によれば、2024年1月期に初の通期黒字化を達成したとされる(直近期の数値は非公開)。
そして2025年11月26日、PFN は経営体制を刷新した。長年 CTO を務めてきた岡野原大輔が代表取締役社長に就き、創業以来 CEO だった西川徹は代表取締役会長へ回った。技術開発と社会実装を社長がリードし、会長が経営の監督と企業文化の継承を担うという明確な役割分担への移行である。PLaMo を磨いてきた技術者が、いまや会社全体の舵を握ったことになる。
岡野原大輔の原点 ― いわきの少年が圧縮アルゴリズムに魅せられるまで

ここからは、PLaMo の実質的な生みの親であり、現在 PFN を率いる岡野原大輔という人物を、できる限り深く掘り下げたい。
岡野原大輔は1982年、福島県いわき市の郊外で生まれ育った。日経新聞の人物特集によれば、自転車で山や川を駆け回る普通の少年だった一方で、その知的な早熟ぶりは際立っていた。なんと小学校の低学年で、表計算ソフトを使って惑星の軌道をシミュレーションしていたという。本格的な没入のきっかけは、小学5年生の誕生日だった。両親が、当時としてはかなり高価だったパソコンとプログラミング言語のソフトを買い与えてくれたのだ。本人の述懐によれば「本格的にパソコンが好きそうだということで……誕生日にパソコンと……プログラミング言語のソフトを買ってくれた」のだという。
少年が夢中になったのは、ゲーム制作ではなく「データ圧縮」だった。情報をいかに小さく、無駄なく表現するか――その新しいアルゴリズムを自分で考えることに没頭していく。高学年からはパソコン通信を始め、中学に上がってもそれを続けた。そして驚くべきことに、中学1年の段階で、データ圧縮に関する海外の英語論文を読みあさっていたという。後年、岡野原はこの原点をこう振り返っている。「小学生の頃、情報という得体の知れないものを数学的に解いていくことに興味を覚えたのが最初でした」。目に見えない「情報」というものを数学の言葉で捉え直す快感が、すべての出発点にあった。
地元の進学校である福島県立磐城高等学校に進むと、その二面性はさらに鮮明になる。1年生からラグビー部に入って身体を張る一方、自作のソフトをインターネットに公開して称賛を浴びた。数学に関しては授業を自分でどんどん先に進めてしまうため、学校側が「みんなが同じように進まなくてもよい」という裁量を認めていたという逸話も伝わっている。スポーツに打ち込む快活さと、誰にも追いつけない速度で知の世界を駆け抜ける異能とが、一人の高校生のなかに同居していた。
東大、未踏、そして突出した才能 ― 学生時代の評価
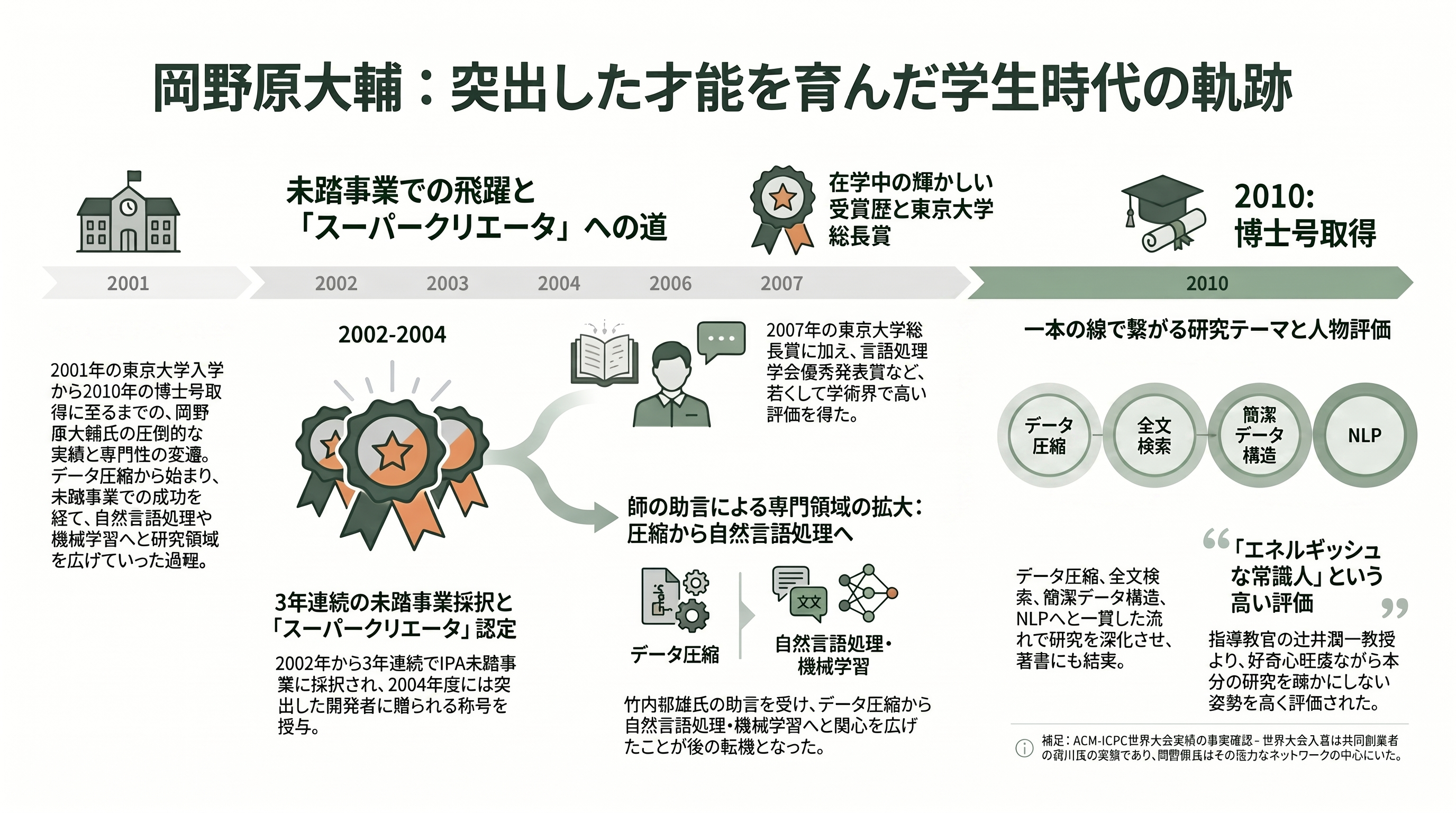
2001年4月、岡野原は東京大学理学部情報科学科に入学する。データ圧縮にのめり込んでいた彼の関心を大きく広げたのが、情報処理推進機構(IPA)の「未踏ソフトウェア創造事業」だった。
岡野原は学生時代に未踏へ複数回採択されている。IPA系の公式記録によれば、2002年に未踏ユースで「単語抽出法による次世代データ圧縮法の開発」、2003年に未踏本体で「汎用的データにおける確率的言語モデルの抽出及びその利用」、2004年に「文脈を考慮した文書分類」と、テーマを発展させながら採択を重ねた。そして2004年度の成果をもって、傑出した開発者にのみ与えられる「スーパークリエータ」に認定された(認定の発表は2005年)。日経新聞も「東大2年生で未踏に選ばれ、約300万円の研究資金を得てスーパークリエータに選定された」と裏付けている。この未踏で、彼の指導を担当したプロジェクトマネージャーの竹内郁雄が自然言語処理の研究を勧めたことが、岡野原を圧縮から検索・NLP・機械学習へと向かわせる転機になった。
学生時代の研究の軌跡は、一本の太い線で貫かれている。データ圧縮から始まり、全文検索、簡潔データ構造(succinct data structure)、そして自然言語処理へ。この一連の専門性は、後に上梓した著書『高速文字列解析の世界――データ圧縮・全文検索・テキストマイニング』(岩波書店)に結実した。人工知能学会の解説でも「岡野原氏による簡潔木を用いた文字列辞書の実装」が第一人者の仕事として言及されるなど、この分野で若くして名を知られる存在だった。在学中の2007年には東京大学総長賞を受け、言語処理学会の年次大会優秀発表賞なども複数回受賞している。
大学院は東京大学大学院情報理工学系研究科コンピュータ科学専攻に進み、自然言語処理の大家である辻井潤一の研究室に所属した。2010年に博士(情報理工学)を取得している。その辻井は、教え子だった岡野原を「エネルギッシュな常識人」と評し、「他分野の研究にも手を広げながら、研究室として与えた研究がおろそかになることはまったくなかった」と証言する。あふれる好奇心であちこちに手を伸ばしながら、本分の研究で結果を出し続ける――その評価は、いまの岡野原の仕事ぶりにそのまま重なる。
なお、岡野原の経歴を語る際に「ACM-ICPC(国際大学対抗プログラミングコンテスト)世界大会で上位入賞」というエピソードが混同されて語られることがあるが、これは正確には共同創業者である西川徹の実績である(西川は2006年の世界大会で19位)。岡野原本人については、プログラミングコンテストで意気投合した東大・京大の仲間のネットワークの中にいた、という関与までが信頼できる事実として確認できる。人物像を正確に描くために、ここは慎重に区別しておきたい。
研究者にして経営者 ― 職歴・人物像・同僚たちの証言
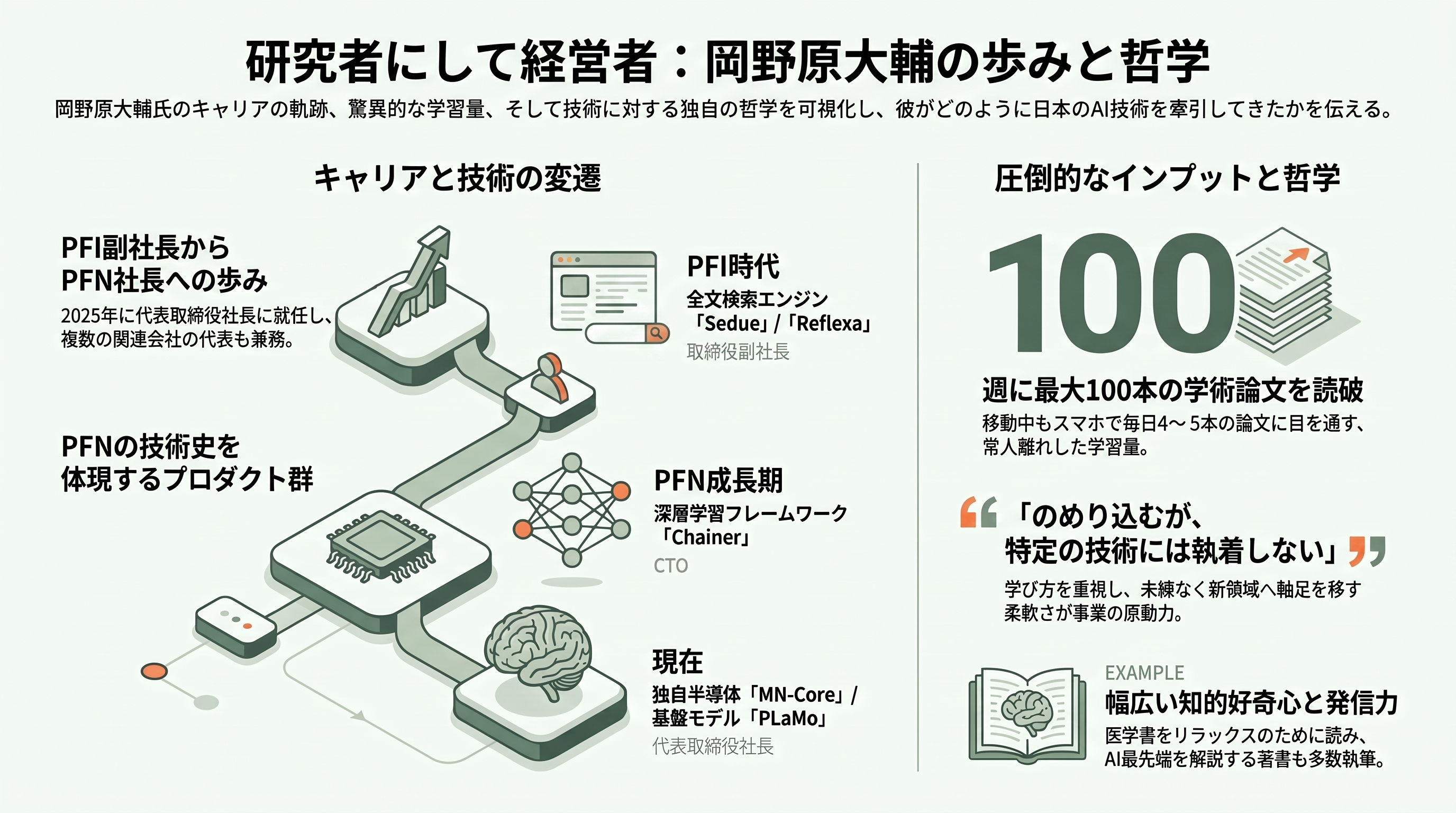
岡野原のキャリアは、Preferred Infrastructure の取締役副社長として始まった。PFN への移行後は最高技術責任者(CTO)として長く技術の屋台骨を支え、2025年2月には最高技術責任者兼最高研究責任者という肩書きに、そして2025年11月26日には代表取締役社長に就いた。加えて、材料探索の Matlantis 社の代表取締役社長、PLaMo を開発した Preferred Elements の代表取締役社長も務めるなど、研究の最前線と事業経営を同時に背負ってきた。2024年には日経クロステックの「CTO of the Year 2024」大賞を受賞している。
彼が携わったプロダクトを並べると、PFN の技術史そのものになる。PFI 時代の全文検索エンジン「Sedue」や連想検索「Reflexa」に始まり、深層学習フレームワーク Chainer の時代を経て、独自半導体 MN-Core の構想、そして PLaMo へと至る。とりわけ PLaMo については、Preferred Elements の最高責任者として基盤モデル事業全体を主導した、まさに実質的な総責任者である。
人物像として最も語り草になっているのが、その尋常でない学習量だ。日経新聞の取材によれば、多いときには週に100本もの学術論文を読み込む。社長となったいまも、通勤中などにスマートフォンで1日4〜5本の論文に目を通すという。専門の自然言語処理にとどまらず音声認識など隣接分野にも手を広げ、しかもそのどれもで論文を書いて成果を出してきた。リラックスするための読書が生理学や病理学といった医学の専門書だというのだから、知的好奇心の幅は常人離れしている。同僚の海野裕也は、その知識の広さに敬意を込めて「岡野原は3人いる」と冗談を言い、「自分は地球人、岡野原はサイヤ人」とまで表現した。
その一方で、特定の技術に執着しない柔軟さも併せ持つ。本人は「技術にはこだわるし、のめり込む。だけど特定の技術には執着しない」と語り、「博士課程では専門分野を学ぶこと以上に、学び方を覚えることに意味がある」という哲学を口にする。かつて少年時代から打ち込んだデータ圧縮の技術を手放したときも「未練はまったくなかった」という。この「のめり込むが、執着しない」という姿勢こそが、検索エンジンから深層学習へ、そして大規模言語モデルへと事業の軸足を大胆に移し替えてこられた原動力だろう。
発信者としての顔も持つ。最先端の動向をやさしく解き明かす書き手として、『大規模言語モデルは新たな知能か――ChatGPTが変えた世界』『ディープラーニングを支える技術』『拡散モデル』といった著書を相次いで世に問い、西川徹との共著『Learn or Die 死ぬ気で学べ』では PFN の経営哲学を語った。専門誌「日経Robotics」では創刊以来 AI 最前線の解説を連載し続けている。なお、機械学習の教科書として知られる講談社『深層学習』は名前のよく似た岡谷貴之の著書であり、岡野原の著作ではない点を付記しておく(混同されやすいが別人である)。
創業物語 ― 検索エンジンから深層学習への大転換
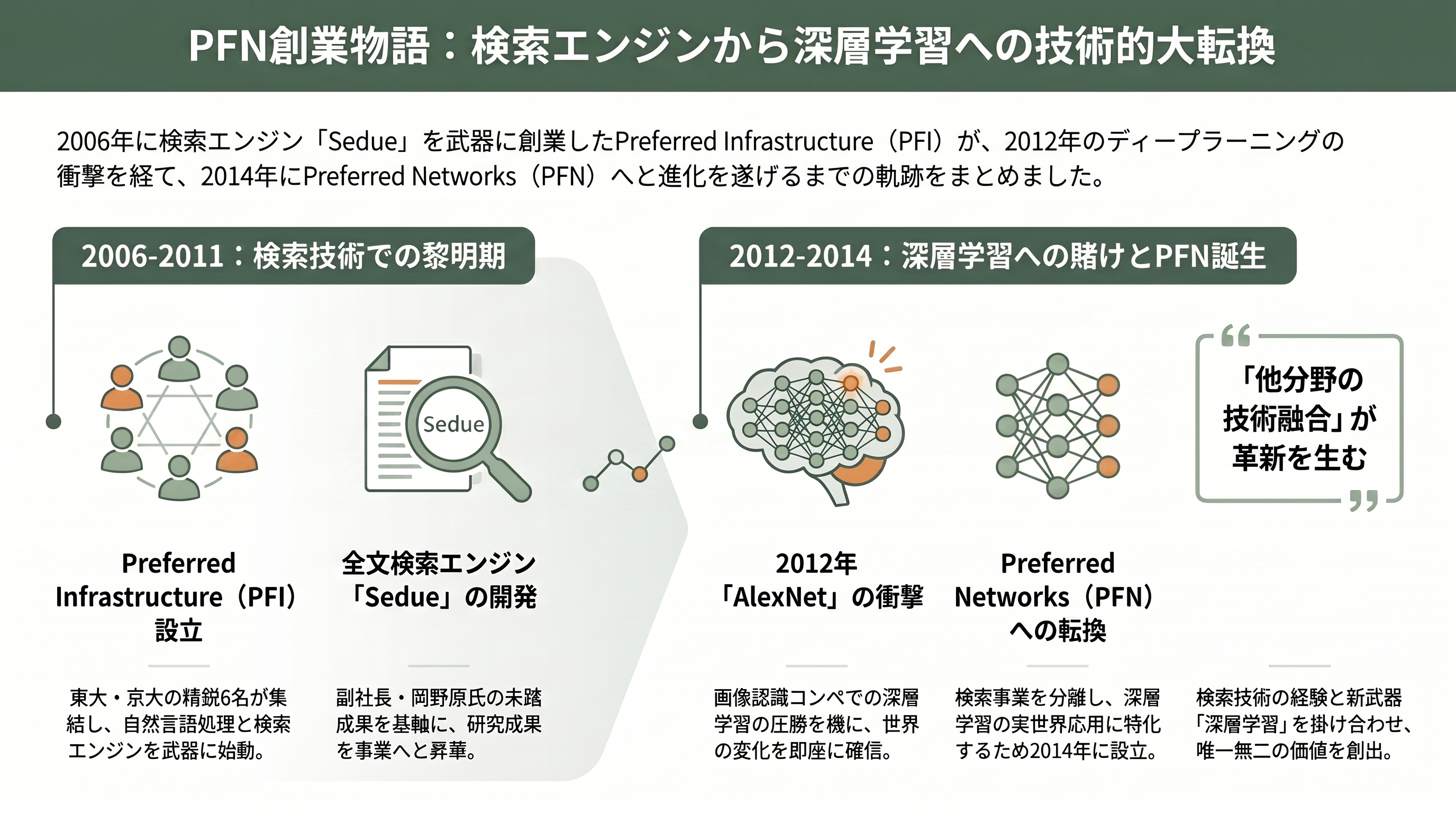
岡野原と西川徹の出会いは、東京大学に入学した学部1年にさかのぼる。二人は同じクラスになり、気が合って行動をともにすることが多かったという。やがて、プログラミングコンテストを通じて知り合った東大・京大の腕利きたちが集い、2006年、岡野原が修士1年のときに6人で Preferred Infrastructure を旗揚げした。
創業の直接の引き金になったのが、岡野原が未踏の成果として開発した大規模全文検索エンジン「Sedue」だった。「Sedue の上にアプリケーションを載せていく必要がある」――その発想から、研究の成果を事業へと育てる道が見えてきた。こうして PFI は、自然言語処理と検索・推薦エンジンを武器とするスタートアップとして走り出す。岡野原は副社長として、技術の中核を担った。
会社の運命を決定づけたのは、2012年の出来事だった。その年の10月、トロント大学のチームが画像認識コンペティションで深層学習を用いて圧勝したというニュース(後に「AlexNet」として知られる成果)が、Twitter のタイムラインを駆け巡った。岡野原は即座にその意味を理解する。ここに、世界を一変させる技術がある、と。日経新聞の取材で彼は当時「目を丸くした」と語っている。
そこから先の動きは速く、そして大胆だった。PFI が育ててきた検索エンジン事業は、それを続けたいメンバーに託し、岡野原と西川は深層学習の実世界応用に賭けるべく、2014年に Preferred Networks を立ち上げる。少年時代に没頭したデータ圧縮をあっさり手放したのと同じ身軽さで、自分たちが築いてきた検索事業からも軸足を移したのだ。「イノベーションが起きるのは大半の場合、他分野の技術を融合させたとき」という岡野原の信念は、まさにこの大転換に体現されている。検索という現実世界の問題に向き合ってきた経験と、深層学習という新しい武器とを掛け合わせたところに、PFN という会社は生まれた。
VCとメディアの受け止め ― 「VCなき」ディープテックという特異点
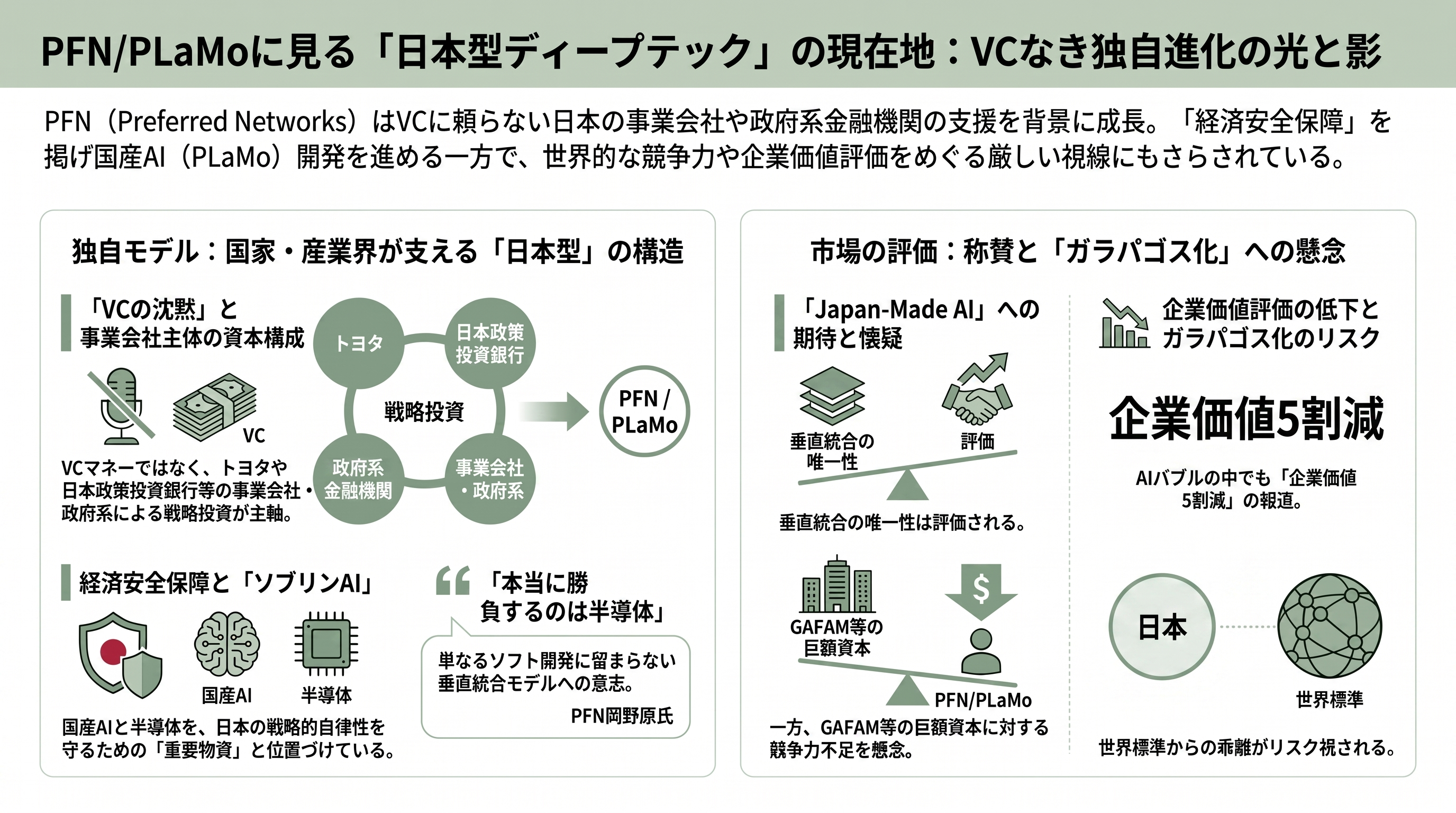
PLaMo と PFN をベンチャーキャピタル(VC)の視点から眺めると、まず気づくのは「沈黙」である。今回の徹底的な調査の範囲では、PFN や PLaMo を名指しで論評した日本・海外の VC の公開コメントは、ただの一件も確認できなかった。これは取材不足ではなく、PFN の資本構造そのものに根ざした構造的な事実だ。PFN を支えてきたのはトヨタ、ファナック、SBI、三菱商事、講談社といった事業会社の戦略投資と、日本政策投資銀行のような政府系金融である。すなわち PFN は、シリコンバレー流の VC マネーではなく、産業界と国家が後ろ盾につく「日本型ディープテック」の典型なのだ。
出資者たちの言葉は、その性格をよく物語る。SBI ホールディングスの北尾吉孝会長は出資にあたり「次世代AI半導体の自社開発を手掛ける PFN の画期的取り組みは、国内外で重要な役割を果たすと確信」と述べ、日本政策投資銀行は MN-Core への出資を「我が国の重要物資である先端半導体の開発力強化に資する」と経済安全保障の観点から位置づけた。語っているのは純粋な財務リターンではなく、国家の戦略的自律性なのである。岡野原自身も「本当に勝負するのは半導体」「国産AIの存在は日本の経済安全保障にとって重要」と繰り返している。
メディアの論調は、おおむね二つの軸に収斂する。一つは「フルスタック垂直統合の唯一性」への称賛であり、もう一つは「ソブリンAI(主権AI)/経済安全保障」という文脈づけだ。日経新聞は PLaMo 2.0 Prime の最優秀賞受賞を大きく報じ、Impress や ITmedia は新版のリリースや政府採用を逐次伝えてきた。象徴的なのは、2026年6月に発表された三菱重工業との業務提携で、両社は「社会インフラおよび国家安全保障分野」で PLaMo と MN-Core を活用すると謳い、これを「Japan-Made AI」と表現した。国産AIが、いよいよ国の重要インフラの中枢へと足を踏み入れたことを示す出来事だった。
ただし、礼賛一色ではない。性能面で海外フロンティアに差をつけられている現実は各種ベンチマークが示すとおりで、「日本だけで使う生成AIは儲からず実用的でない」「GAFAMの資本規模に日本は競争できない」といった懐疑論も根強い(こうした趣旨の発言は、AI研究の象徴的存在である東京大学の松尾豊教授からも過去に発せられている)。国産にこだわるあまり世界標準から取り残される「ガラパゴス化」のリスクを指摘する論考も少なくない。さらに見過ごせないのが、企業価値をめぐる報道だ。日経新聞は2025年3月、PFN が直近の調達で「企業価値5割減」という割安な評価を受け入れたと報じた(この点は実質的に単一ソースであり、要留保として扱うべきだが)。世界的なAIバブルの只中で、日本のディープテックの評価が必ずしも追い風を受けていない構図がここにある。
シリコンバレーの視点で読む今後 ― いつ、何が動くか
最後に、シリコンバレーの投資家の目線を借りて、PFN と PLaMo の現在地と今後を読み解いてみたい。
シリコンバレーの VC が近年こぞって注目するテーマの一つが「ソブリンAI」である。Khosla Ventures の Vinod Khosla は「ほとんどの主権国家は、国家安全保障と地域の文化・価値観への適合のために、自国独自の基盤モデルを欲するだろう」と語り、Lux Capital も「日本は地政学的AI競争の時代に成功する独自のポジションにある」と評価する。象徴的なのは、Andreessen Horowitz(a16z)が初の海外拠点を2026年夏に東京へ開設すると表明したことだ。日本のディープテックへの関心は、確かにかつてなく高まっている。
ところが、ここに皮肉な捻れがある。これら米VCの「日本ソブリンAI」称賛は、その多くが PFN ではなく Sakana AI に向けられているのだ。シリコンバレーの投資家にとって、Sakana のような身軽でグローバルに資金調達するスタートアップは投資しやすい。一方、事業会社と政府系金融に支えられ、半導体という重厚長大な領域に踏み込む PFN は、彼らの典型的な投資対象からはむしろ外れる。だからこそ PFN には VC の直接コメントが付かない。これは弱みではなく、むしろ「日本でしか成立しないモデル」という独自性の裏返しでもある。
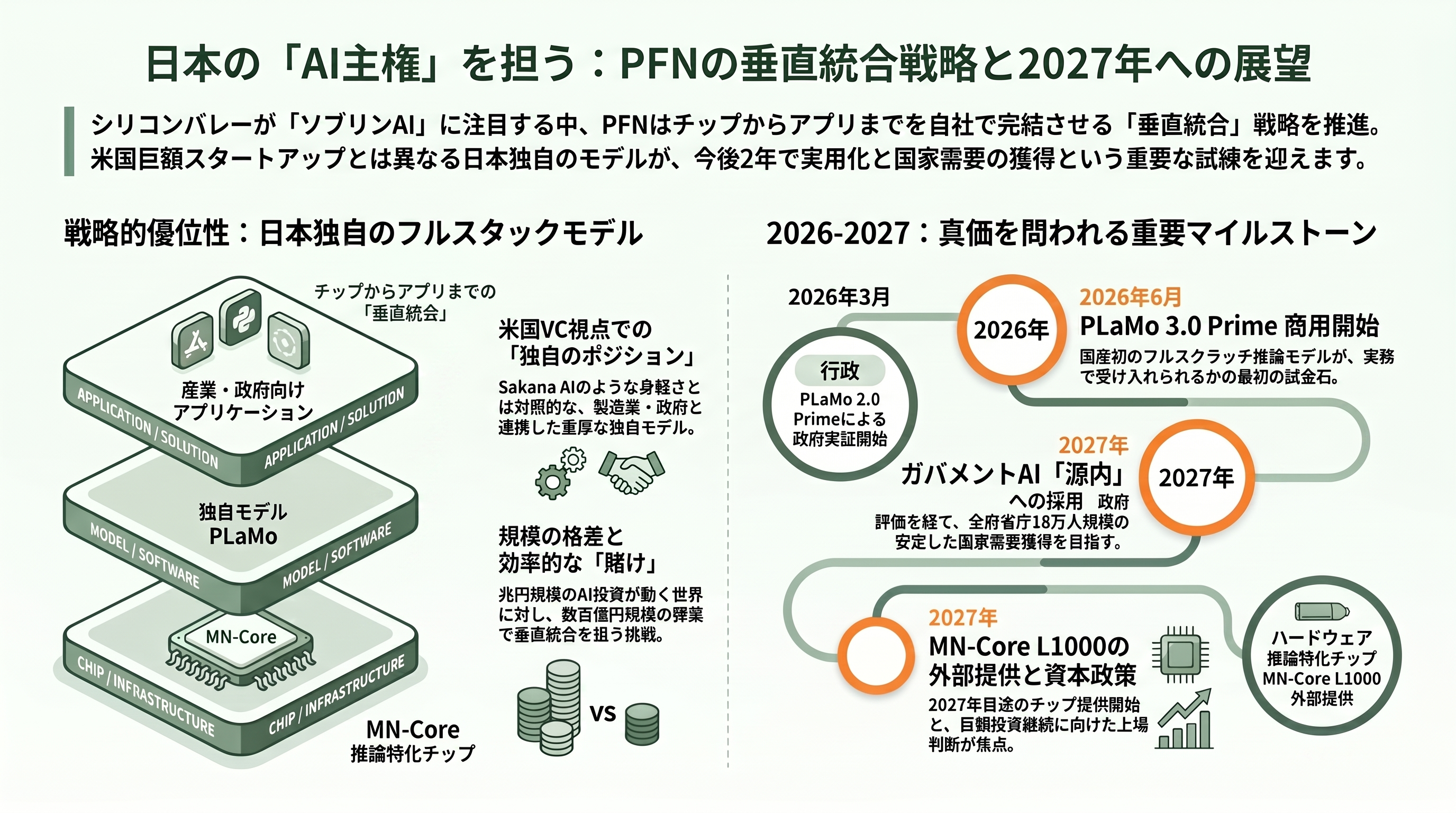
戦略の観点で見れば、PFN の賭けはきわめてシリコンバレー的でもある。チップからアプリまでの垂直統合は、NVIDIA や OpenAI が体現する「フルスタックを制した者が総取りする」という発想と通底する。とりわけ生成AIの推論に特化した次世代チップ MN-Core L1000 は、Groq や Cerebras、SambaNova といった「推論専用シリコン」のスタートアップが米国で巨額の資金を集めているのと同じ土俵に立つ挑戦だ。ただし、その規模はまだ桁が違う。世界の AI 投資が兆円単位で動くなかで、PFN の調達は数百億円規模にとどまる。同じ方向の賭けを、はるかに少ない弾薬で続けているのが実情である。
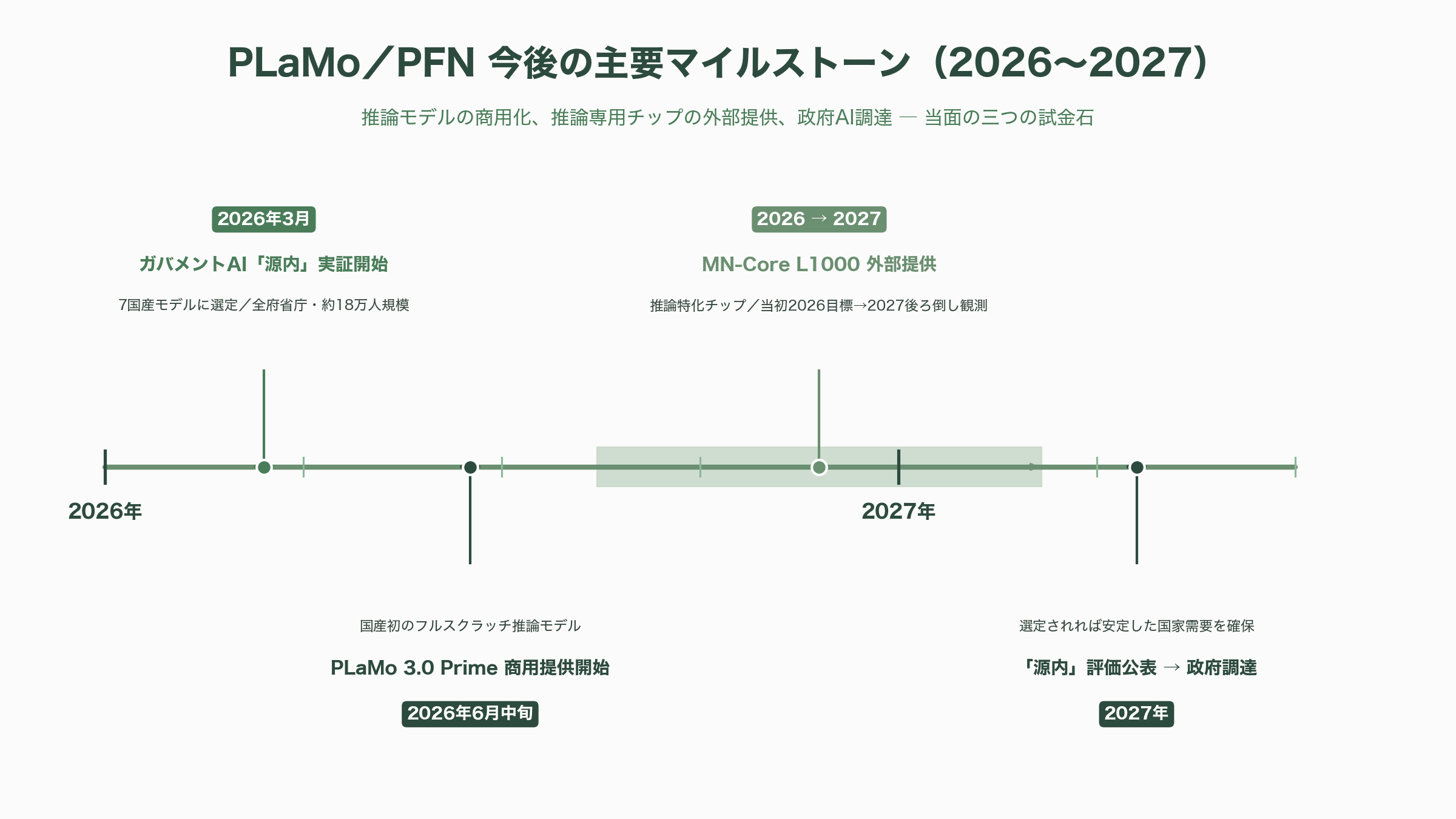
では、いつ何が動くのか。直近で最も注目すべきは、2026年6月中旬に商用提供が始まる PLaMo 3.0 Prime である。国産初のフルスクラッチ推論モデルが実務でどれだけ受け入れられるかが、PFN の生成AI事業の真価を測る最初の試金石になる。次に、生成AI推論特化チップ MN-Core L1000 の外部提供だ。当初は2026年が目標とされたが、最新の資料では2027年への後ろ倒しもうかがわせており、このスケジュールの行方が垂直統合戦略の成否を左右する。政策面では、デジタル庁のガバメントAI「源内」の動きが決定的に重要だ。PLaMo 2.0 Prime は2026年3月に選ばれた7つの国産モデルの一角として、全府省庁・約18万人規模での実証に進んでいる。2027年には評価が公表され、その後に優秀なモデルが有償で政府調達される見通しで、ここで選ばれれば PFN は安定した国家需要を手にすることになる。
そして最大の問いが IPO(株式公開)である。西川徹は過去のインタビューで「資金面で必要でなければ上場したくない」という趣旨を語っており、トヨタや SBI から直接資金を調達できる PFN には、急いで市場へ出る動機が乏しい。公式な上場申請も確認されていない。だが、フルスタック戦略を完遂するには半導体への継続的な巨額投資が欠かせず、いずれ資本市場との対話が避けられない局面は来るだろう。岡野原という「研究者にして経営者」が社長として下す資本政策の判断こそ、シリコンバレーの投資家が次に最も注視するポイントである。少年時代に圧縮アルゴリズムへ没頭したいわきの天才は、いま、日本のAI主権を背負う会社の舵を握っている。