tsuzumi(つづみ)とは ― 「大きさ」ではなく「軽さ」で勝負する純国産AI

まず、tsuzumiがどんなAIなのかを具体的なイメージから説明したい。地方銀行の行員が「この社内システムのエラーコードの対処法は」と尋ねると即座に答えが返り、病院の事務が分厚い診療ガイドラインを要約させ、市役所が住民向け通知文の下書きを作らせる――こうした業務を、データを一切社外のクラウドに送らず、庁舎やデータセンターに置いた1台のサーバー(GPU1基)の中だけで完結させる。これがtsuzumiが想定する使われ方だ。
tsuzumiはNTTが自社開発する日本語特化の大規模言語モデル(LLM)である。名称は和楽器の「鼓(つづみ)」に由来し、小さくとも豊かに響く、という日本発のAIらしさを込めている。OpenAIのGPTシリーズやGoogleのGeminiが「とにかく巨大化して何でもこなす万能モデル」を志向するのに対し、tsuzumiの発想は正反対だ。NTTは「LLMの大規模化・一極集中化ではなく、異なる個性を持った多数のAIが連携することで、ヒトとともに社会のWell-beingを実現する」という未来像を掲げ、巨大な1つの頭脳ではなく、現場の予算とハードウェアの制約に収まる「使える大きさ」のAIを作ることを最初の設計条件に置いた。
この「軽さ」は単なる思想ではなく、経済合理性に直結する。フロンティアの巨大モデルは推論(実際にAIを動かすこと)に数十~数百基のGPUを必要とし、電力消費と運用コストが企業導入の壁になってきた。tsuzumiはこれを1基のGPUに収め、消費電力と費用を大幅に下げる。加えて、学習にはNTTが権利を持つ、あるいは利用許諾を得たデータのみを用いる「フルスクラッチ(ゼロからの自社開発)」を貫いており、Web上の文章を無断で大量に取り込んだ海外モデルにつきまとう著作権・知的財産の係争リスクを避けている点も、企業や官公庁が安心して使ううえで重要な差別化要因になっている。
tsuzumiの歩み ― 2023年の登場から商用化、そして世代交代へ
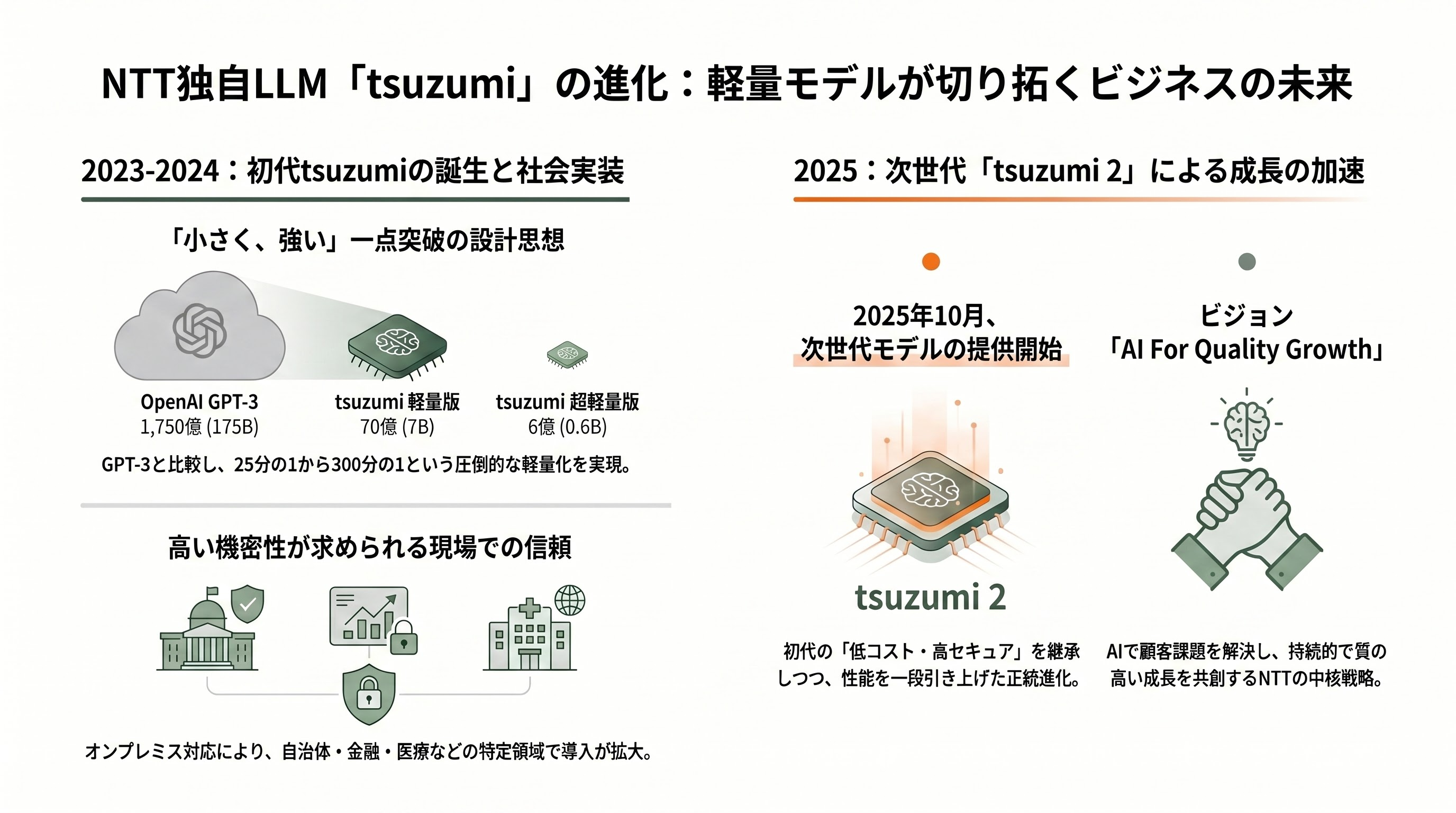
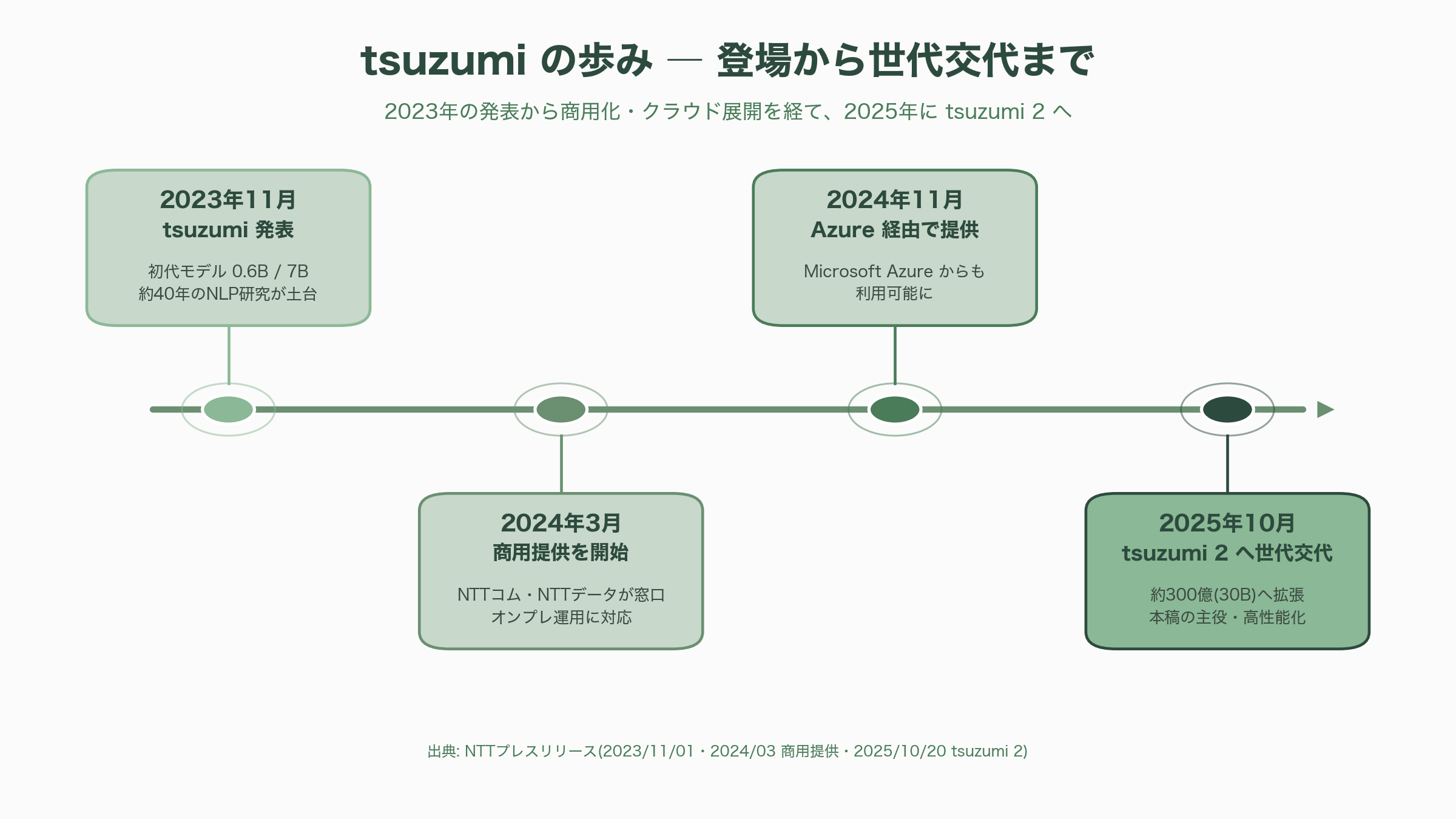
tsuzumiが世に出たのは2023年11月1日だ。NTTは記者会見で、研究所が積み上げてきた約40年の自然言語処理研究を土台に開発した独自LLMとしてtsuzumiを発表した。初代tsuzumiは超軽量版が6億(0.6B)、軽量版が70億(7B)パラメータという小ささで、これはOpenAIのGPT-3(1,750億=175B)のそれぞれおよそ300分の1、25分の1にあたる。「小さいのに日本語が強い」という一点突破の設計思想は、この時点ですでに明確だった。
2024年3月25日、NTTはtsuzumiの商用提供を開始した。まずNTTコミュニケーションズとNTTデータが窓口となり、その後NTT東日本・西日本などグループ各社が順次展開する体制を整えた。オンプレミス(自社設置)で使いたいという顧客の声に応えられる軽量モデルは、クラウド前提の海外勢にはない強みとして受け止められた。さらに2024年11月にはMicrosoft Azure経由での提供も始まり、初代tsuzumiは自治体・金融・医療といった「機密性が高く、海外クラウドに預けにくい」現場を中心に導入を広げていった。
そして2025年10月20日、NTTは次世代モデル「tsuzumi 2」の提供を開始する。初代の路線(軽量・高セキュア・低コスト)を受け継ぎながら、性能を一段引き上げた世代交代であり、本稿の主役である。NTTは島田明社長が掲げる「AI For Quality Growth」――AIで顧客の課題を解決し、持続的で質の高い成長をともに実現する――というビジョンの中核に、このtsuzumi 2を据えている。
tsuzumi 2 ― 30Bへの拡張と「1GPUで動く」という設計思想
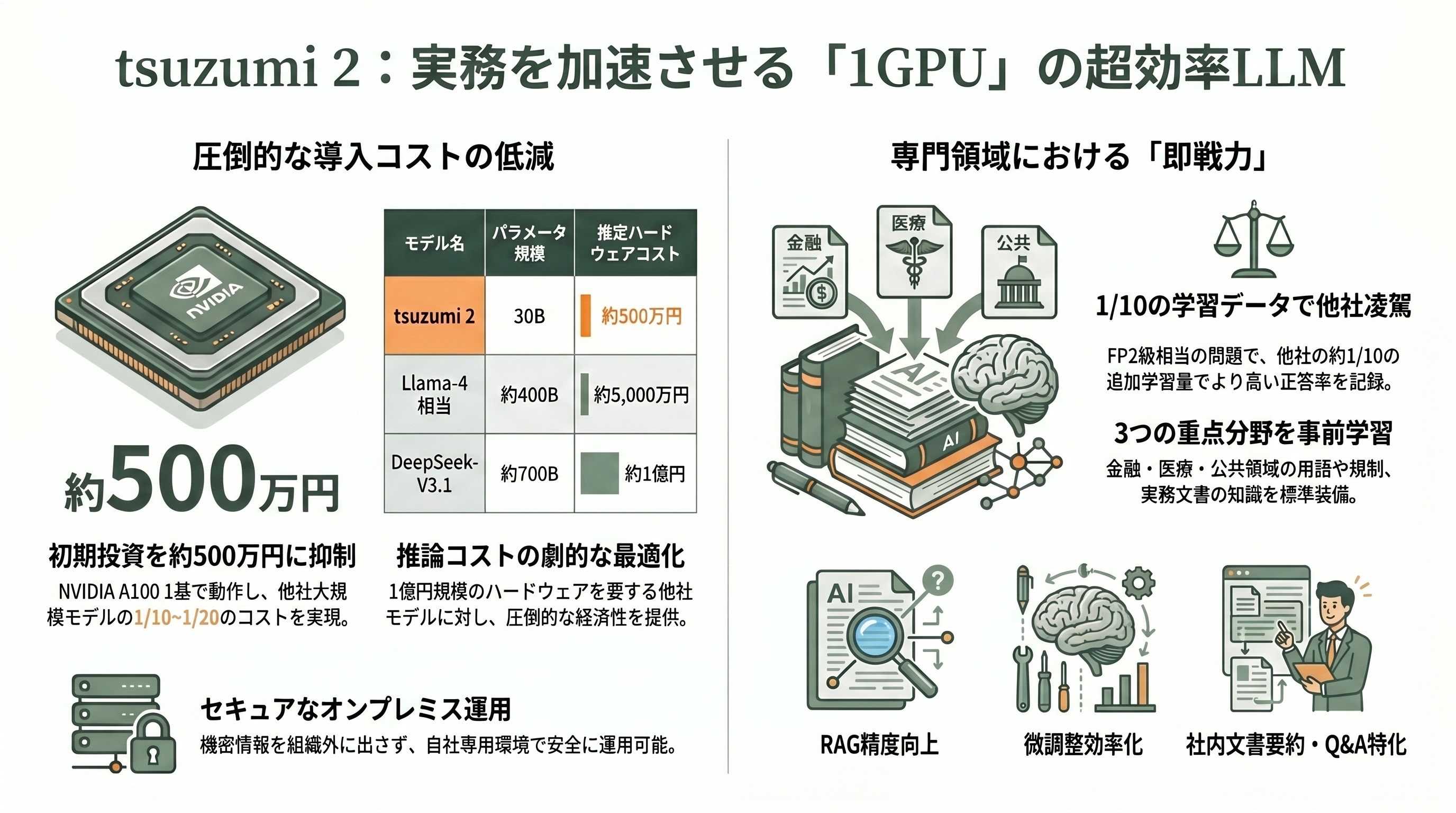
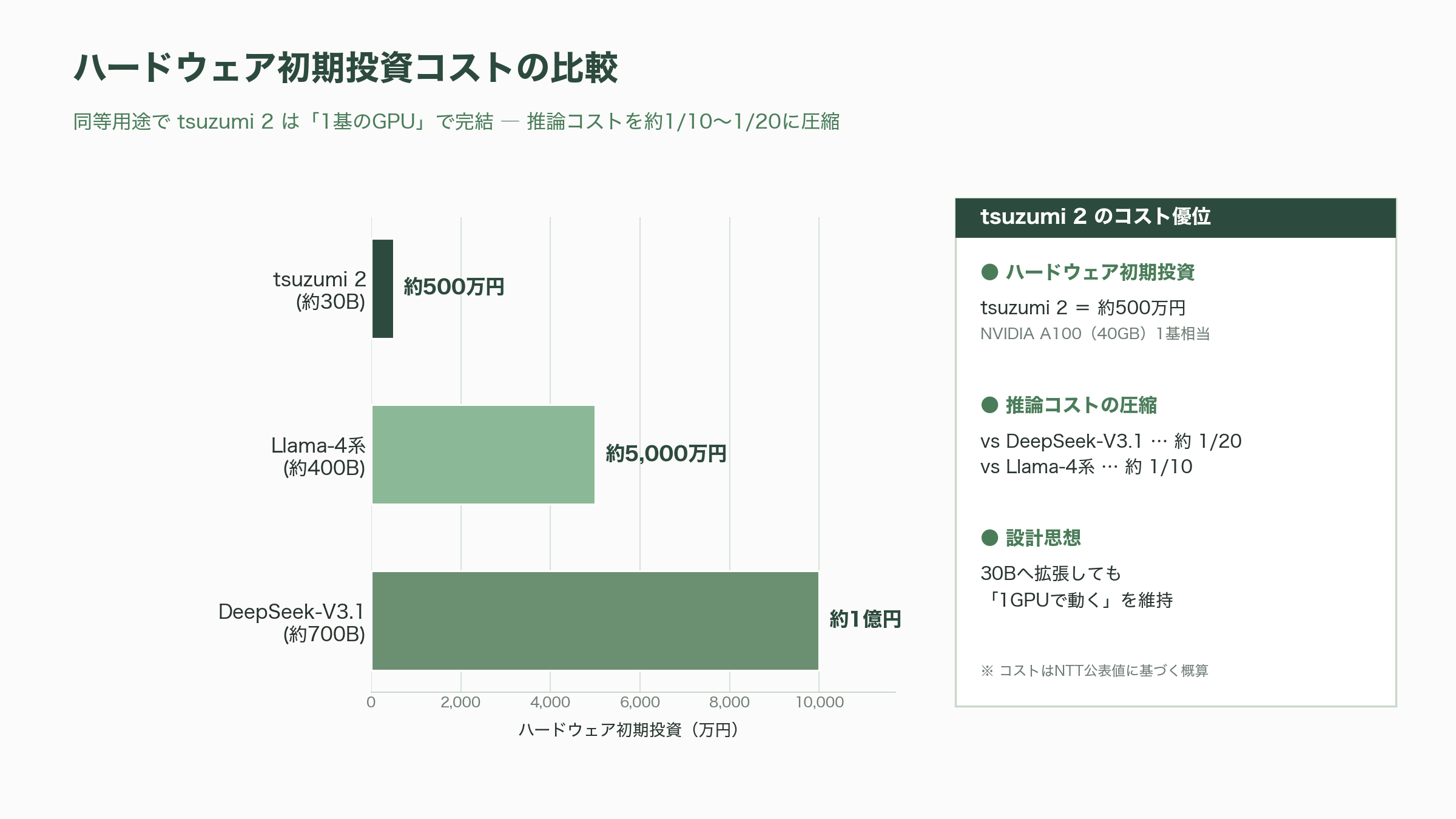
tsuzumi 2の最大の変化は、パラメータ規模を初代の7Bから約300億(30B)へと大幅に拡張したことだ。一般に大きなモデルほど賢くなるが動かすコストも跳ね上がる。tsuzumi 2はサイズを増やしながらも、推論時に必要なメモリを抑える工夫により「1基のGPUで動く」という初代からの絶対条件を維持した。NTTによれば、必要なハードウェアの初期投資はNVIDIA A100(40GB)1基相当の約500万円で済む。これは、同等の用途で比較したとき、DeepSeek-V3.1(約700B)で約1億円、Meta系のLlama-4(約400B)で約5,000万円とされるハードウェアコストに対し、推論コストをおよそ10分の1から20分の1に抑えられるという計算になる。
中身の作り込みも、汎用の賢さを競うのではなく「日本企業が実際に使う領域」に振り切っている。NTTは金融・医療・公共(自治体)の3分野について、業界用語・規制・実務文書を踏まえた知識を事前学習の段階から強化した。さらに、社内文書を検索しながら回答するRAG(検索拡張生成)の精度と、用途に合わせて少量データで微調整するファインチューニングの効率を高めている。象徴的なのが金融分野の検証で、ファイナンシャル・プランニング技能検定2級(FP2級)相当の問題で、Google系のGemma 27Bモデルが追加学習1,900件で正答率64%だったのに対し、tsuzumi 2はわずか200件の追加学習で70%に到達したとNTTは示している。つまり「少ない教材で、その業界の専門家に育てやすい」ことが、現場導入での実利になる。
tsuzumi 2はオンプレミスやプライベートクラウドでの運用を前提とし、機密情報を組織の外に出さずに扱える。万能の知識エンジンというより、社内マニュアルの要約、規程の検索、文書に基づくQ&Aといった日々の業務の「摩擦」を減らす実務の道具――NTT自身もtsuzumi 2をそう位置づけている。
tsuzumi 2 Visionモデル ― 図表入りビジネス文書を「画像として」読み解く
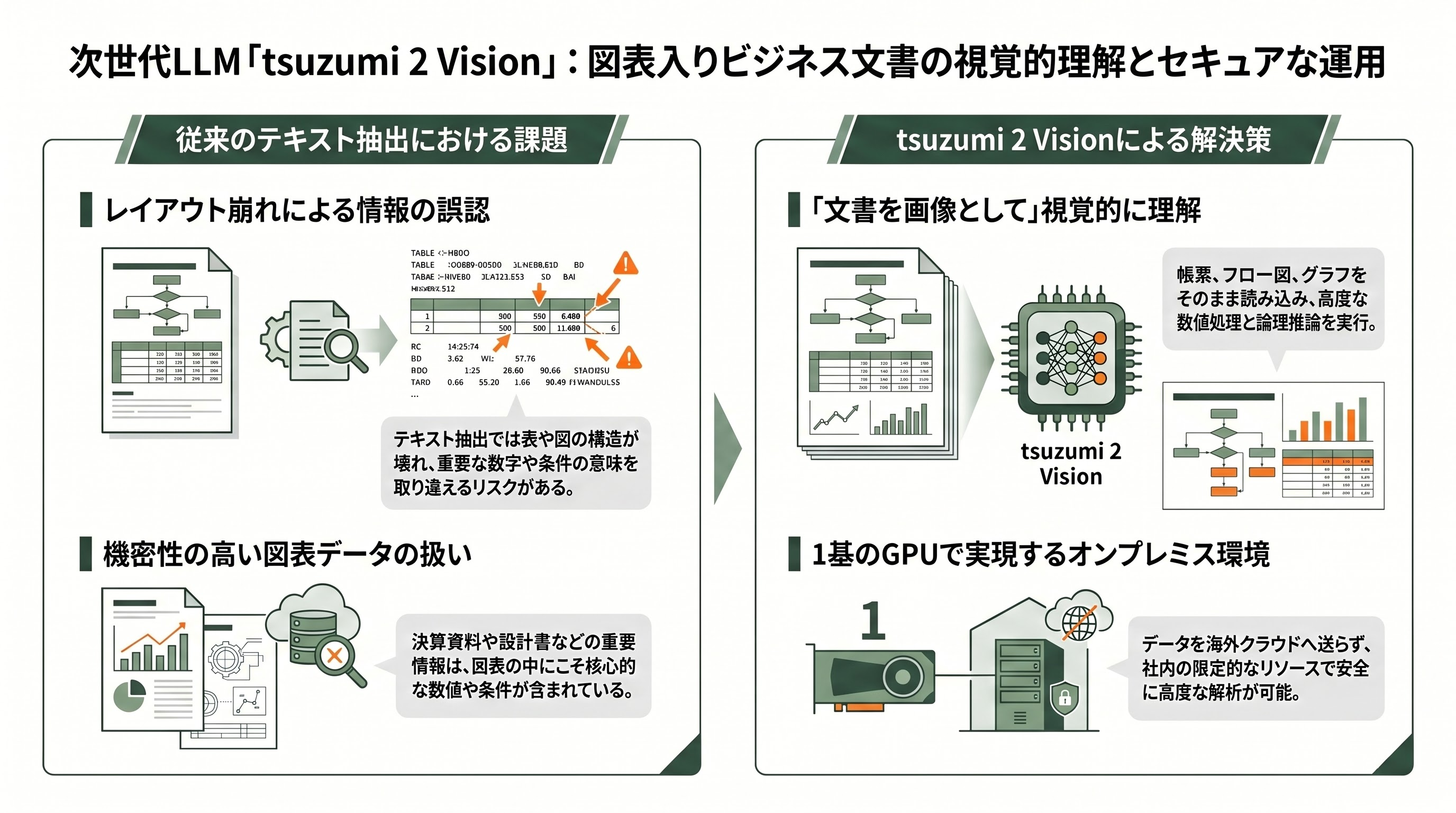
2026年5月19日、NTTはtsuzumi 2に大型のアップデートを加え、いわゆる「tsuzumi 2 Visionモデル」を発表した。これは文章だけでなく画像を理解できるマルチモーダル拡張で、日本のビジネス文書につきものの表・グラフ・図(チャート)を、文書を画像としてまるごと読み込んで視覚的に理解する点に主眼がある。
なぜ「画像として」なのかには現場の事情がある。決算資料、設計書、申込書、稟議書といった機密文書は、テキストだけでなく図表に重要な数字や条件が詰め込まれていることが多い。これを従来のようにテキスト抽出してから処理すると、レイアウトや表の構造が壊れて意味を取り違える。tsuzumi 2 Visionは図表の中から特に重要な情報を抜き出してデータベース化したり、帳票から必要事項を抽出したり、フロー図の流れを理解したりできる。あわせて、売上金額などの数値情報の理解や計算、APIドキュメントなど技術文書に含まれる関数の解釈といった「論理推論・数値処理」の水準も引き上げられた。
NTTが挙げる想定ユースケースは、図表だらけの資料を読み込ませる与信審査業務や、技術文書を参照しながら答える技術問合せ業務支援などだ。重要なのは、この高度な図表理解を、依然として1基のGPU環境で実現している点である。機密性の高い図表入り文書を、海外クラウドに上げることなく社内で読み解けることが、オンプレ志向の企業・官公庁にとって大きな意味を持つ。提供はNTTグループ各社を通じて順次行われる予定だ。
日本語性能をどう読むか ― 「GPT-5級」という評価の中身と限界
tsuzumi 2を語るとき必ず登場するのが「GPT-5級の日本語性能」という表現だ。これは正確に理解しておく必要がある。
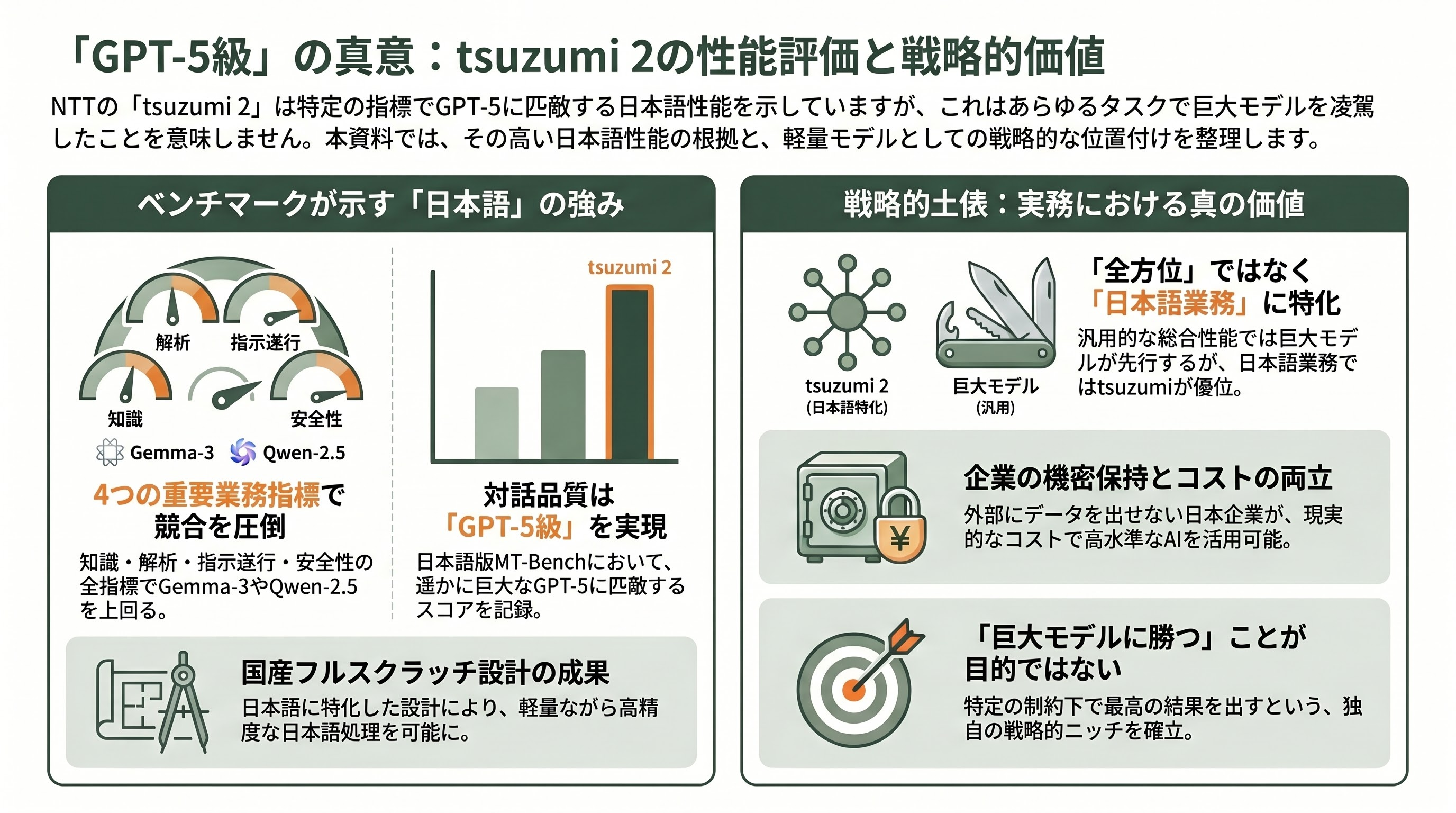
NTTの評価では、tsuzumi 2は知識・解析・指示遂行・安全性という業務で重要な4つのベンチマークにおいて、同じサイズ帯の競合であるGoogleのGemma-3 27BやAlibabaのQwen-2.5 32Bを上回ったとされる。さらに対話品質を測る日本語版MT-Benchの多くのタスクで、自社よりはるかに大きいGPT-5に匹敵するスコアを示すとNTTは説明しており、Ledge.aiなど複数の専門メディアも「フルスクラッチ設計でGPT-5級の日本語性能を軽量モデルで実現」と報じている。
ただし、ここには冷静な留保が要る。複数の分析記事が指摘するとおり、これはあくまで「日本語」かつ「同サイズ帯」での評価であって、あらゆるタスクを横断する汎用の総合性能では、GPT-5やAnthropicのClaude、GoogleのGemini 3 Proといったフロンティアモデルが依然として先行している。tsuzumi 2は「全方位でChatGPTより上」のモデルではなく、「機密を外に出せない日本企業が、現実的なコストで、日本語の業務を高水準にこなす」という土俵で強いモデルだ。この土俵設定こそがtsuzumiの戦略の核心であり、ベンチマークの数字を額面どおり「巨大モデルに勝った」と読むのは誤りである。
開発を率いる西田京介 上席特別研究員
tsuzumiの研究開発を率いるのが、NTT人間情報研究所の西田京介(にしだ きょうすけ)上席特別研究員だ。「上席特別研究員」はNTTグループが、極めて優秀で長期的な活躍が期待できる研究者に与える役職で、グループにとって長期的に重要な分野で革新的・先導的な技術開発を牽引する使命を担う。
西田氏の専門は大規模言語モデル、自然言語処理、機械読解(文章を読んで質問に答えるAI)、そして文章と画像を結びつけるVision-and-Language(視覚言語)モデルや深層学習に及ぶ。この経歴は示唆的だ。tsuzumi 2 Visionが図表入り文書を画像として読み解く方向に進んだのは、機械読解と視覚言語モデルを長年研究してきた西田氏らの蓄積と地続きである。研究実績も豊富で、自然言語処理分野の最難関国際会議であるACL・AAAI・ICLR・EMNLPに多数の論文を発表し、NLP2021最優秀賞、2024年のNTT R&Dアワード、2025年の言語処理学会関連の各賞など、国内外で高い評価を受けてきた。
西田氏が繰り返し語るのは、巨大な1つのAIに知能を集約するのではなく、それぞれ個性を持った多数のAIが人と協調して働く未来像だ。「あらゆる環境で人と自然に共存できる汎用AIの実現」を掲げつつ、その実装が超巨大モデルではなく軽量なtsuzumiである、という一見逆説的な選択にこそ、NTTのAI哲学が表れている。
導入事例 ― 大学、電力、そして政府「源内」へ
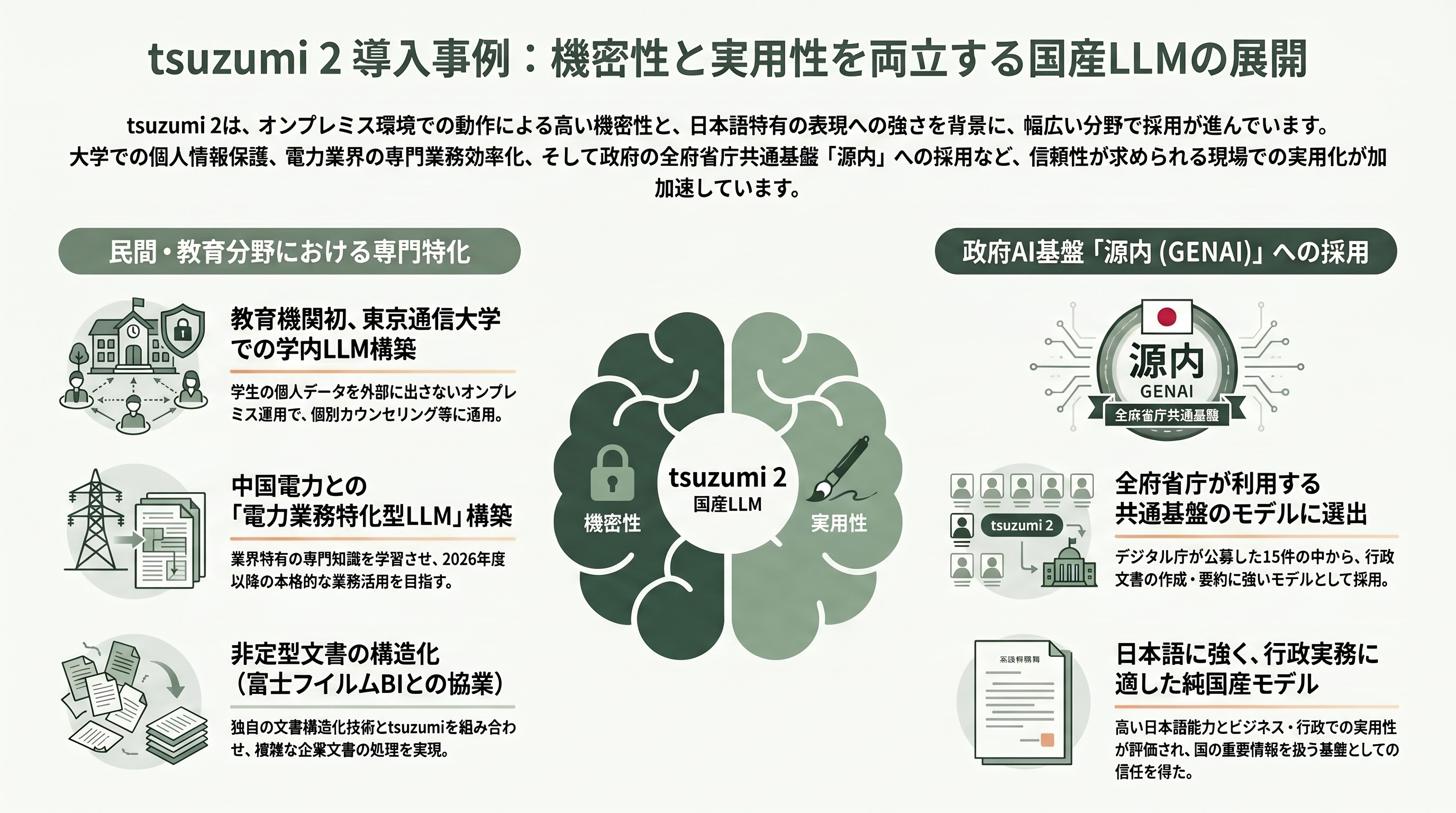
tsuzumi 2の採用は、機密性とコストの両立が刺さる現場から着実に広がっている。
教育分野では、東京通信大学が教育機関として初めてtsuzumi 2を導入した。同大はクラウドに依存せず、学生・教職員のデータを学内にとどめたまま使える学内LLM基盤を構築し、授業に関する高度なQ&A、教材・試験作成の支援、履修やキャリアに関する個別カウンセリングなどに活用する。学生の個人データを守りながらAIを使える点が、オンプレで動くtsuzumiならではの選定理由となった。
エネルギー分野では、2026年1月26日、NTTドコモビジネス(NTTコミュニケーションズ)と中国電力がtsuzumi 2を活用した電力業務特化型LLMの構築・検証の開始を発表した。中国電力の業務情報や専門知識を学習させて電力業界に特化したLLMを作り、2026年度以降の本格活用を視野に入れる。金融分野では、富士フイルムビジネスイノベーションが持つ文書構造化技術「REiLI」とtsuzumiを組み合わせ、非定型の企業文書を扱う協業も進む。
そして最も象徴的なのが政府への採用だ。デジタル庁は2026年3月6日、全府省庁の職員向け生成AI基盤「源内(げんない/GENAI)」で試用する国産LLMとして、応募15件の中からtsuzumi 2を含む7モデルを選定した。「源内」という名は江戸の発明家・平賀源内に由来し、生成AI(GenAI)との語呂合わせにもなっている。tsuzumi 2は「日本語に強く、ビジネス・行政での実用を志向したモデル」として、行政文書の作成・要約・整理や業務知識の活用での貢献が期待されている。国の重要情報を扱う基盤に純国産モデルが選ばれたことは、tsuzumiにとって大きな信任である。
シリコンバレーと世界はどう見ているか ― 「ソブリンAI」という地政学
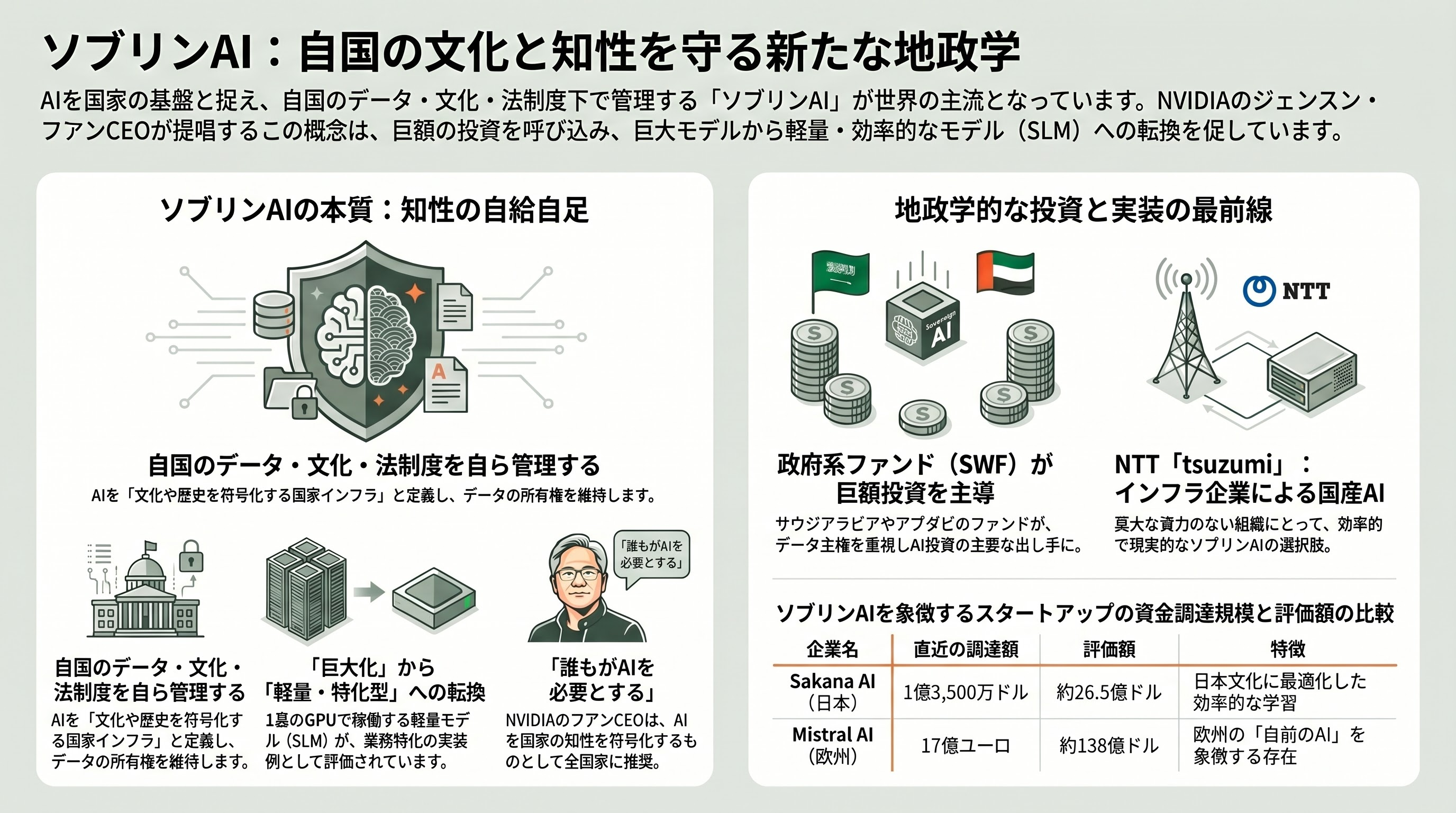
ここでtsuzumiを、シリコンバレーのVC(ベンチャーキャピタル)が今まさに注目する文脈に置き直してみたい。キーワードは「ソブリンAI(Sovereign AI/AI主権)」――自国のデータ・文化・法制度の管理下でAIを開発・運用するという考え方だ。
この潮流を最も声高に唱えるのが、AI半導体で世界を席巻するNVIDIAのジェンスン・フアンCEOである。彼は世界政府サミットなどで「すべての国がAIを構築することになる」「誰も原爆を必要としないが、誰もがAIを必要とする」と述べ、ソブリンAIを「あなたの文化、社会の知性、常識、歴史を符号化するもの。あなた自身のデータを、あなたが所有する」ことだと定義する。発展途上国のリーダーへの助言として「自国の言語と文化のデータを、自国の大規模言語モデルに符号化せよ」とまで踏み込む。AIインフラを国家の基盤とみなすこの世界観の中で、NTTのtsuzumiはまさに「日本のソブリンAI」の代表例として位置づけられる。NTTの島田社長自身、各国がそれぞれの文化・歴史的背景に適合した技術を発展させるべきだという、ソブリンAIそのものの思想を語っている。
VCの資金もこの方向に厚く流れている。2026年のAI投資では、サウジアラビアのPIFやアブダビのムバダラといった政府系ファンド(ソブリン・ウェルス・ファンド)が、巨額調達の主要な出し手として存在感を増している。各国市場には、データの所在(データレジデンシー)、規制順守、情報セキュリティへの懸念から、自国向けにつくられたAIへの強い需要があるためだ。
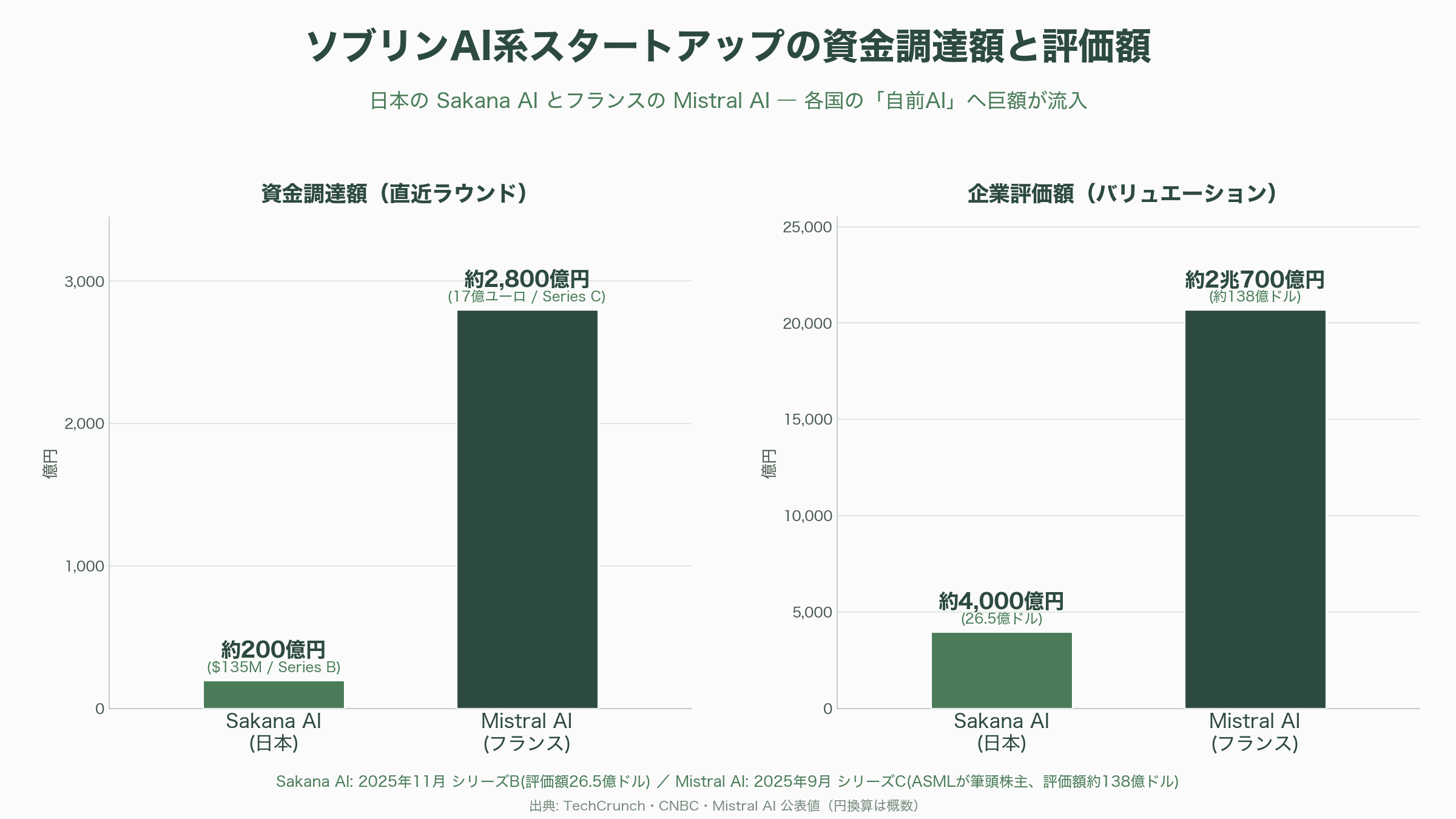
日本でこの需要を体現するのが、tsuzumiの直接の比較対象となるスタートアップ群だ。中でもSakana AIは、2025年11月17日に1億3,500万ドル(約200億円)のシリーズBを調達し、評価額は26.5億ドル(約4,000億円)に達した。「Attention Is All You Need」論文の共著者リオン・ジョーンズ氏らGoogle出身者が2023年に創業した同社は、日本語・日本文化に最適化したモデルを少ないデータと効率的な事後学習(ポストトレーニング)で作る点に特徴があり、出資にはMUFG(三菱UFJフィナンシャル・グループ)に加え、Khosla Ventures、NEA、Lux Capital、さらに米国情報機関系VCのIn-Q-Telといった顔ぶれが名を連ねる。欧州では、フランスのMistral AIが2025年9月、半導体露光装置のASMLを筆頭株主とする17億ユーロ(約2,800億円)のシリーズCを調達し、評価額は約138億ドル(約2兆700億円)に跳ね上がった。同ラウンドにはNVIDIAやAndreessen Horowitz(a16z)も名を連ねる。各国・各地域が「自前のAI」へ巨額を投じる構図は、まさにソブリンAIの世界的な熱気を映している。
これらと比べると、tsuzumiはVCマネーで急成長を狙うスタートアップではなく、通信インフラ企業NTTが研究開発を母体に自前で育てるモデルである、という出自の違いがある。だが、海外メディア(AI Newsやcomputerweekly等)が一様に「数十~数百基のGPUを要するハイパースケーラー戦略に対し、1基のGPUで動く軽量路線」としてtsuzumiを評価し、フロンティア大モデルを使う資力のない組織にとっての現実解として位置づけている点は重要だ。シリコンバレーで起きている「巨大化一辺倒からの揺り戻し」――小型で効率的なモデル(SLM)を業務特化で使い分けるという潮流――の、日本における最有力の実装例がtsuzumiなのである。
競合する国産LLMの布陣 ― tsuzumiの立ち位置
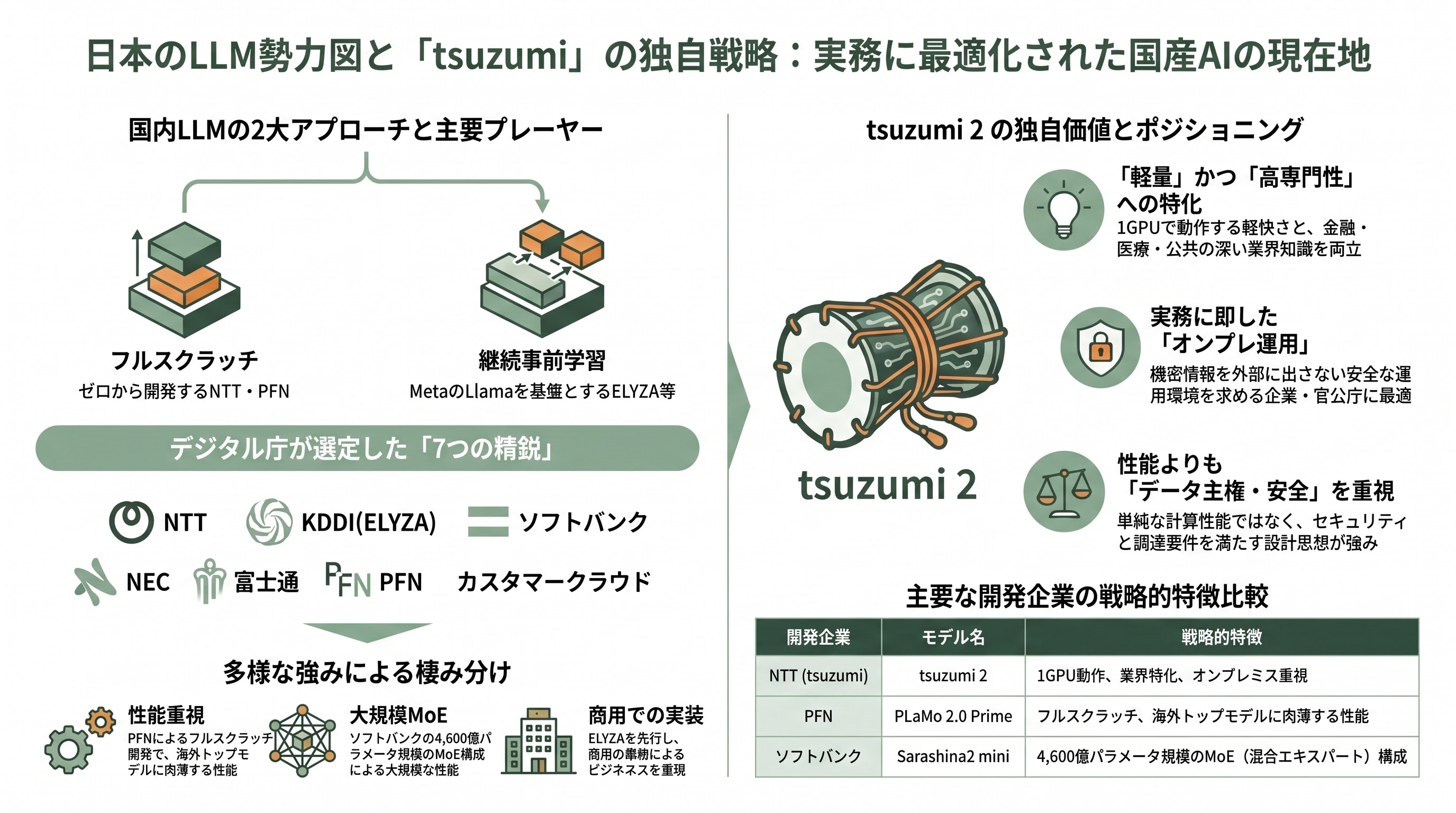
ソブリンAIの国内市場でtsuzumiが戦う相手も整理しておきたい。デジタル庁「源内」が選んだ7モデルが、いまの日本のLLM勢力図をほぼそのまま映している。選ばれたのはNTTデータの「tsuzumi 2」、KDDI・ELYZAの「Llama-3.1-ELYZA-JP-70B」、ソフトバンクの「Sarashina2 mini」、NEC(日本電気)の「cotomi v3」、富士通の「Takane 32B」、Preferred Networks(PFN)の「PLaMo 2.0 Prime」、そしてカスタマークラウドの「CC Gov-LLM」の7件である。
開発アプローチは大きく二つに分かれる。tsuzumiやPFNのPLaMoのように基盤モデルをゼロから自社開発するフルスクラッチ派と、ELYZAのようにMetaのLlamaを日本語データで追加学習する継続事前学習派だ。PFNはさくらインターネットやNICTと組み、長考できる「PLaMo 3.0 Prime」へと開発を進め、海外のQwen3-235Bやgpt-oss-120bに肉薄すると主張する。ソフトバンク傘下のSB Intuitionsは約4,600億パラメータ(460B)規模のMoE(混合エキスパート)構成を持つSarashina系を擁し、富士通のTakaneは量子化と蒸留を組み合わせたエンタープライズ路線、KDDI傘下のELYZAは商用展開で最も先行する、といった具合に、各社が異なる強みで棲み分けている。
この布陣の中でtsuzumi 2の立ち位置は明確だ。最大パラメータ数を競う路線(PLaMoやSarashina)とは一線を画し、「1GPUで動く軽さ」と「金融・医療・公共の業界知識」「機密を外に出さないオンプレ運用」という、企業・官公庁の実務要件に最適化した中量級モデルとして自らを定義している。源内の選定が示すのは、政府が国産にこだわる理由が必ずしも「単純な性能の高さ」ではなく、データ主権・セキュリティ・調達要件といった設計思想にあるという事実であり、ここはtsuzumiの土俵そのものである。

今後 ― 多言語・音声、そして2027年の政府調達という分水嶺
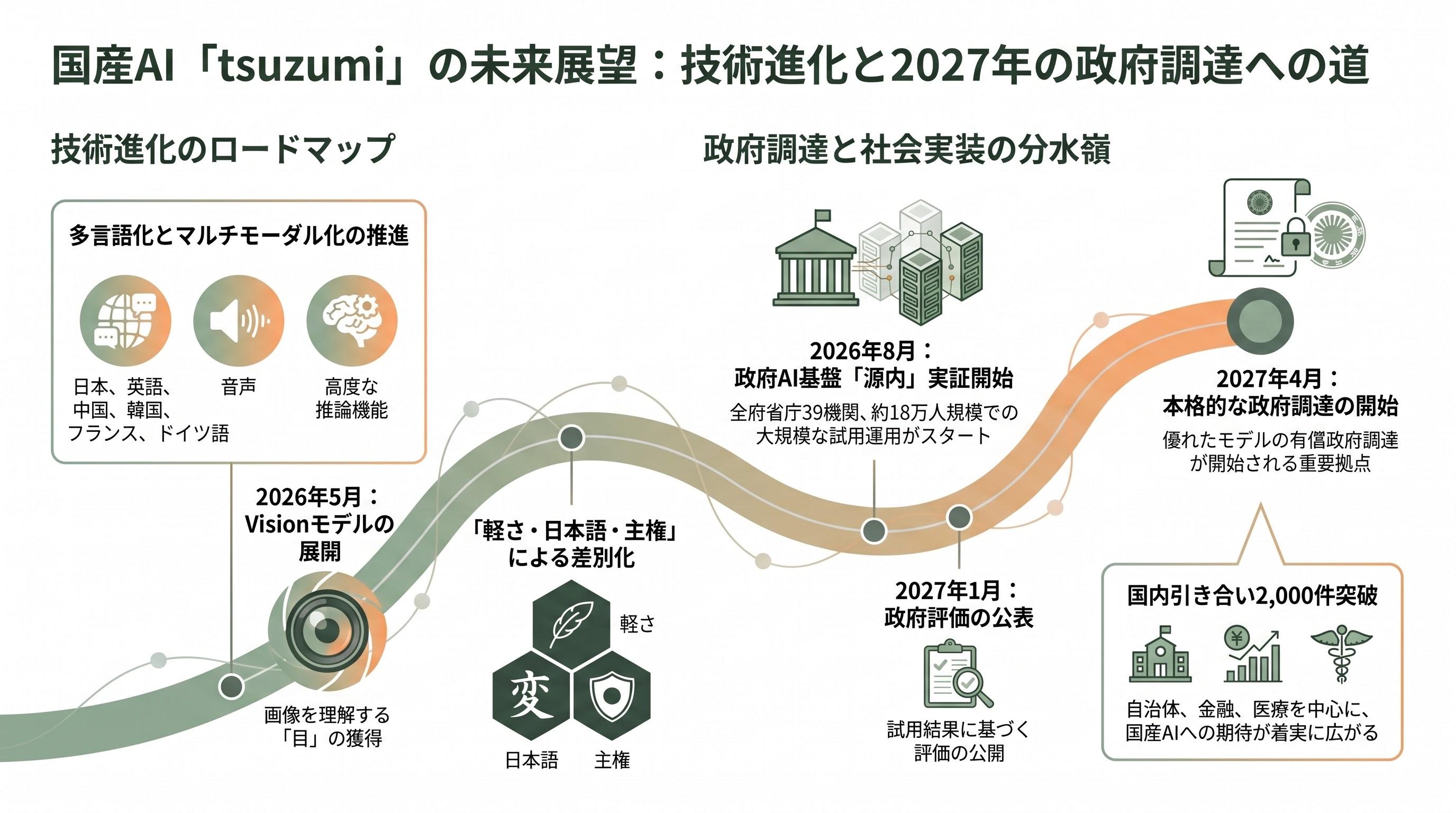
最後に、tsuzumiがいつ頃どこへ向かうのかを見通しておく。
技術面では、NTTは日本語と英語の処理性能をさらに高めつつ、中国語・韓国語・フランス語・ドイツ語など対応言語を広げてユーザー層を拡大する方針を示している。tsuzumi 2はテキスト・画像に加えて音声も扱うマルチモーダル対応を視野に入れており、2026年5月のVisionモデルは、その「目」を獲得する第一歩と位置づけられる。西田氏らが描く「個性を持つ多数のAIが連携する」未来像に向けて、図表理解の次は音声や、より高度な推論への拡張が次のマイルストーンになると見られる。
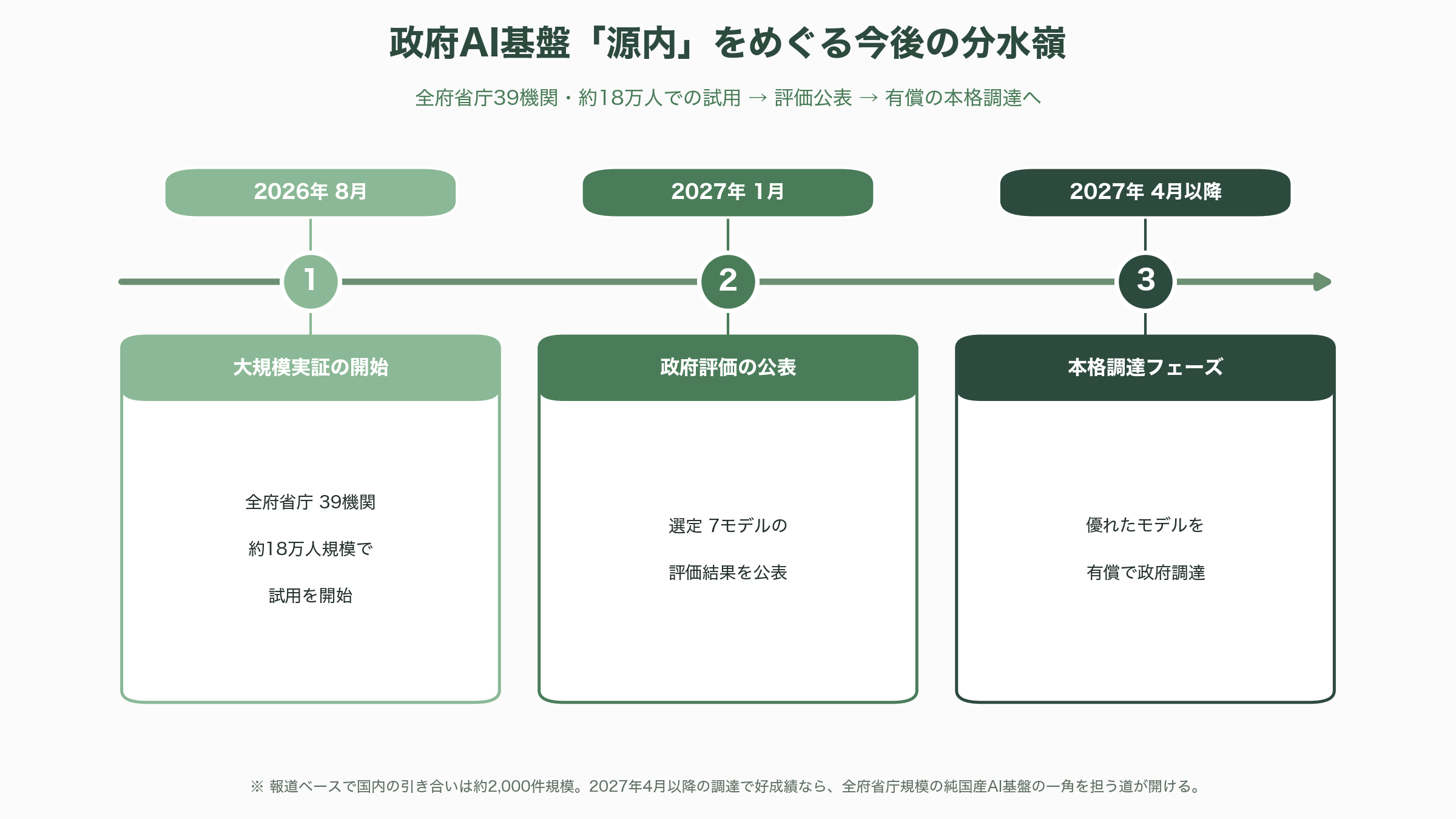
事業面で最大の分水嶺は、政府AI基盤「源内」をめぐる時間軸だ。デジタル庁の計画では、選定された7モデルは2026年夏(8月頃)から全府省庁39機関・約18万人規模で試用が始まり、2027年1月頃に評価結果が公表される。そして2027年4月以降、優れたモデルが有償で政府調達される予定である。つまり、今後の注目イベントは「2026年8月の大規模実証の開始」「2027年1月の政府評価の公表」「2027年4月以降の本格調達」という三つの時点に集約される。ここでtsuzumi 2が好成績を収めれば、全府省庁規模の純国産AI基盤の一角を担う道が開ける。報道ベースでは国内の引き合いはすでに2,000件規模に達したとされ、自治体・金融・医療を中心に裾野は着実に広がっている。
巨大化の競争では世界のフロンティアに追いつけない――その現実を直視したうえで、NTTは「軽さ」「日本語」「主権」という別の軸で勝負を挑んでいる。ジェンスン・フアンが言うように各国が自国のAIを必要とする時代において、tsuzumi 2とtsuzumi 2 Visionは、日本が自らの言語・文化・機密を自らの手で扱うための、最も現実的な選択肢の一つとして、その真価を問われる局面に入った。