「PoCの壁」とは何か——まず言葉と背景を整理する
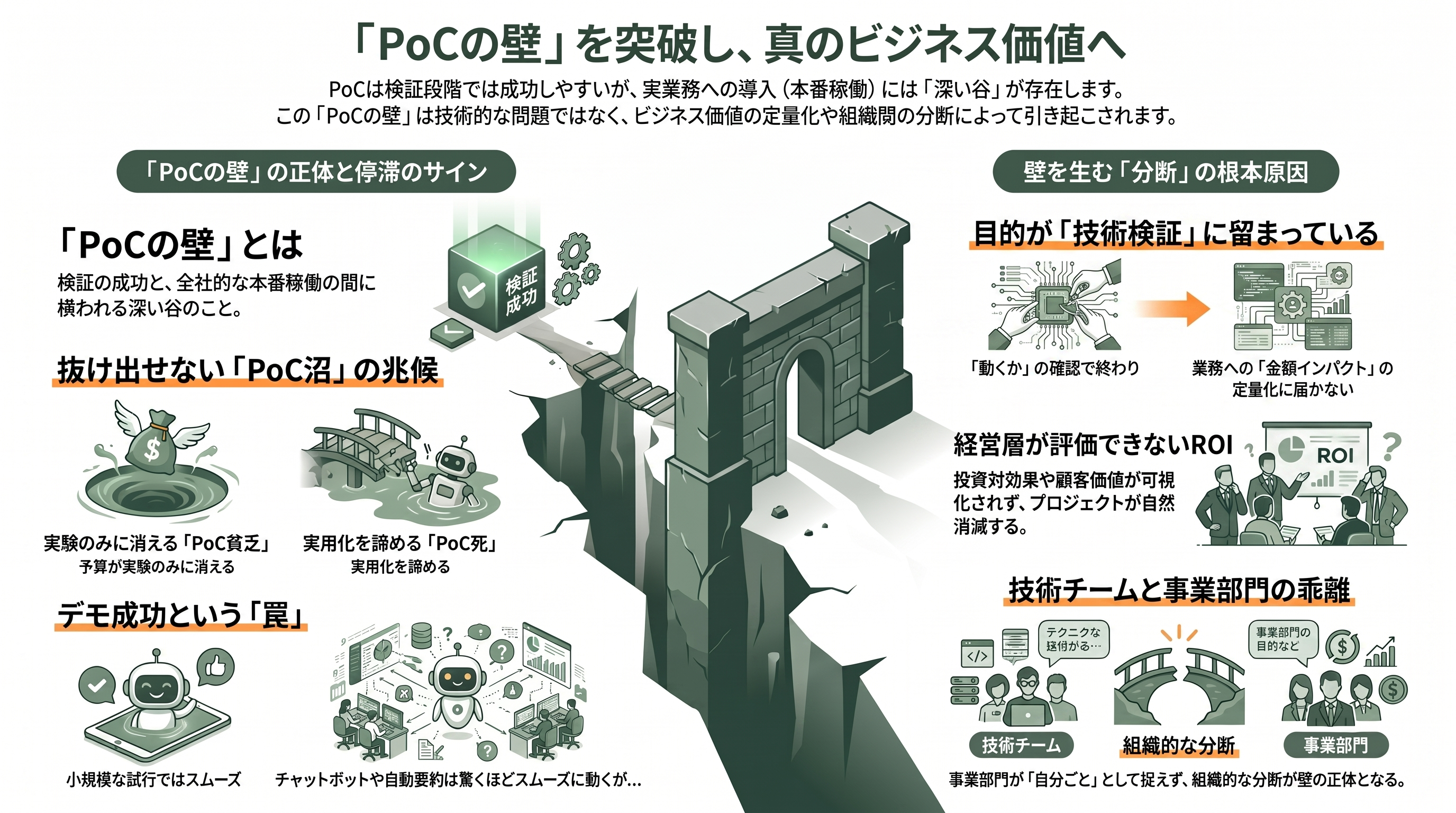
PoC(Proof of Concept、概念実証)とは、新しい技術やアイデアが「本当に役に立つのか」を小規模に試し、本格投資の前に実現可能性を見極める検証プロセスを指す。生成AIの文脈では、たとえば社内規程やマニュアルを自然言語で質問できるチャットボットを一部門で試したり、コールセンターの通話を自動で要約して応対履歴を生成する仕組みを数十席だけで動かしてみたり、経理で請求書PDFから金額・取引先を自動抽出させたり、製造ラインのカメラ画像から不良品を検知させたりといった取り組みが典型である。いずれも「まずは小さく動かして効果を確かめる」段階であり、デモとしてはしばしば驚くほどうまく動く。
問題は、その先である。デモで感心させたPoCが、いざ全社の日常業務に組み込み、数千人が毎日使い、誤りや例外に耐え、コストとセキュリティを満たし、明確な金額効果を生む「本番システム」へと育つ確率は、驚くほど低い。この、検証成功と本番稼働のあいだに横たわる深い谷こそが「PoCの壁」である。日本では、検証だけ繰り返して本番に至らない状態を「PoC死」、次フェーズの予算が下りず実験ばかりに費用が消える現象を「PoC貧乏」、抜け出せない状態を「PoC沼」「PoC疲れ」などと呼び、DX(デジタルトランスフォーメーション)が進まない象徴的な失敗パターンとして語られてきた。
なぜ壁が生まれるのか。本質は技術の優劣ではなく、PoCの目的が「技術的に動くか」の確認にとどまり、「業務にどれだけの金額インパクトを生むか」の定量化まで到達しないことにある。日本企業では、PoCが情報システム部門の実験で完結し、経営層がそのROI(投資対効果)や顧客価値への影響を評価できないまま自然消滅するケースが多い。技術チームは熱心でも、当事者であるはずの事業部門が「自分ごと」として受け止めない——この分断が、世界共通の壁の正体である。
数字が示す「PoCの壁」の深刻さ
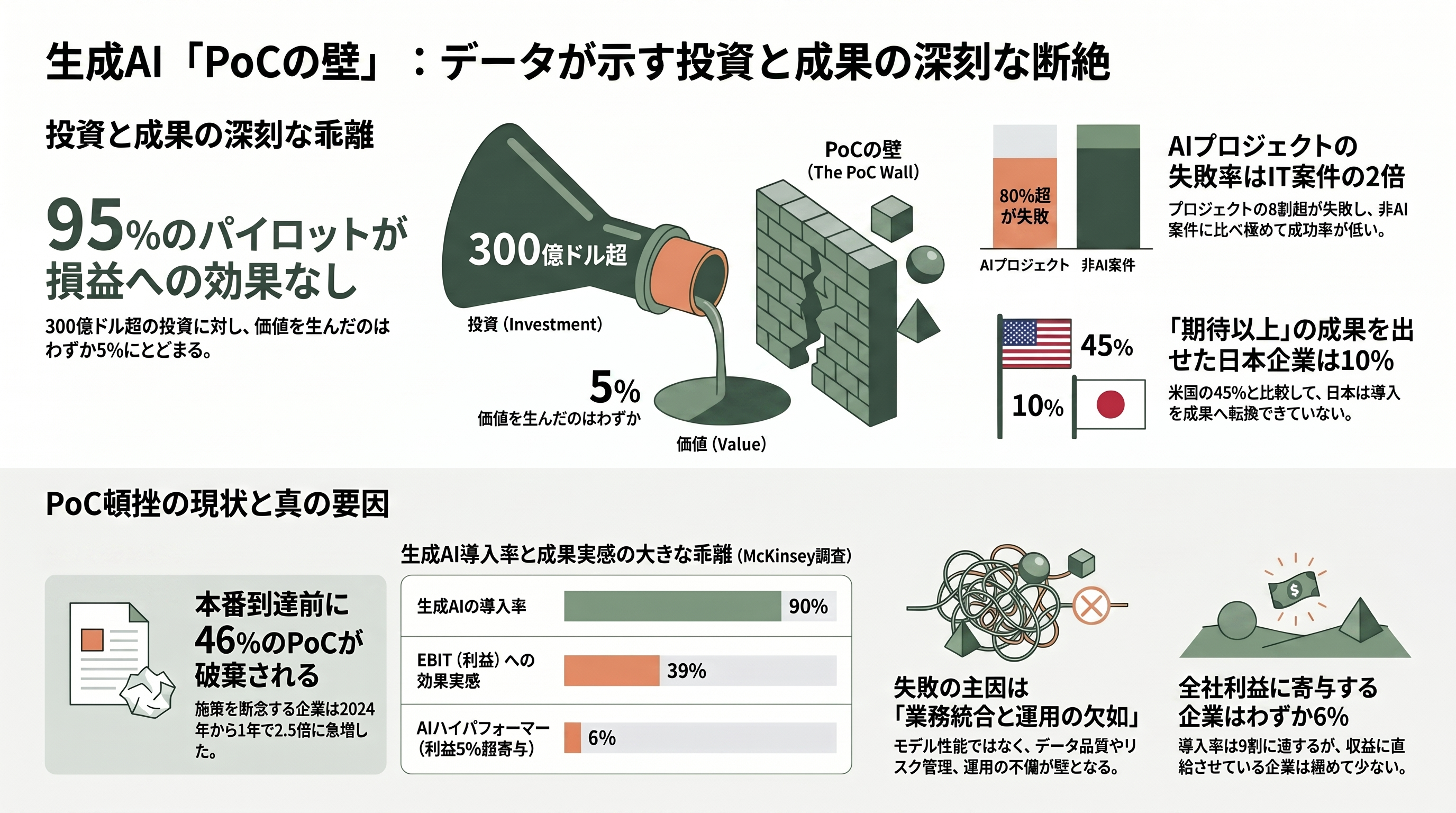
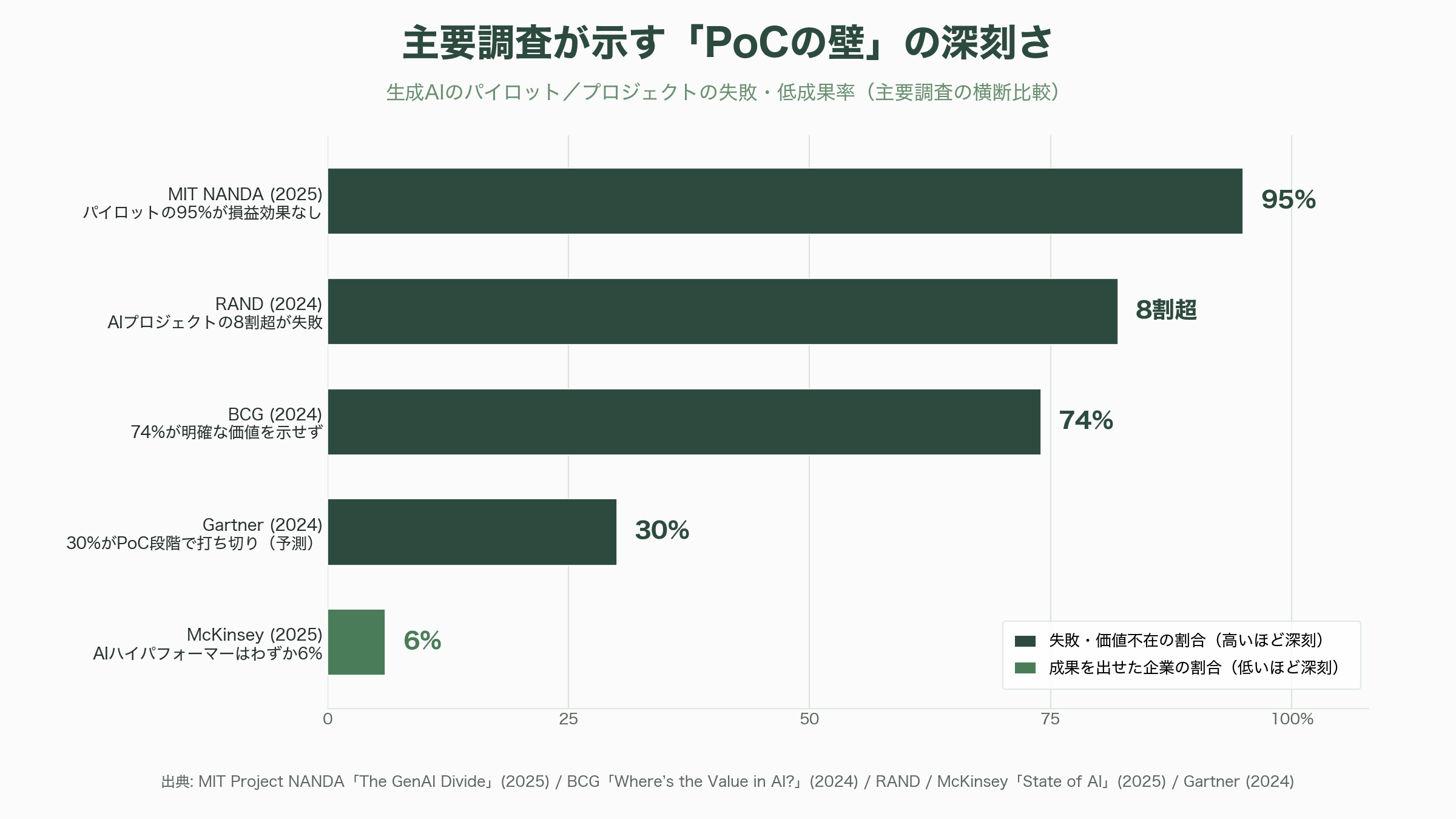
壁の深刻さは、2024年から2026年にかけて相次いだ調査が定量的に裏づけている。最も大きな波紋を呼んだのは、MITのProject NANDAが2025年に公表した報告書「The GenAI Divide: State of AI in Business 2025」だ。同報告は、公開された300件超のAI導入事例、52件の経営層インタビュー、153人のシニアリーダーへの調査をもとに、企業が生成AIに投じた推計300億〜400億ドル(約4.7兆〜6.2兆円)に対し、パイロットの95%が損益への測定可能な効果を生んでいないと結論づけた。価値を生み出せたのはわずか5%にすぎず、報告書はこの断絶を「GenAI Divide(生成AIの分断)」と名づけている。
この数字は経営層だけでなく金融市場をも揺らした。米Fortuneなどが2025年8月に大きく報じると、「企業は大金を燃やしているのではないか」との懸念が広がり、同月のエヌビディア決算と重なって、AIバブル論の引き金の一つとなった。同決算のデータセンター部門の売上高は411億ドル(約6.4兆円)と前年同期比56%増だったが、市場の期待をわずかに下回っていた。もっとも、Fortuneは続報で「投資家以上に怯えるべきは経営層だ」と論じている。失敗の理由がモデルの性能ではなく、業務への統合や学習・運用の欠如にある点こそ、本来直視すべき問題だからである。
他の調査も同じ方向を指す。コンサルティング大手BCGが2024年10月に公表した「Where's the Value in AI?」は、1,000人のCxOを対象に、PoCを超えて具体的価値を生み出す能力を備えた企業はわずか26%、残る74%は明確な価値を示せていないとした。S&P Global Market Intelligenceが北米・欧州の1,000社超に実施した調査では、大半のAI施策を断念した企業の割合が2024年の17%から2025年には42%へと急増し、平均的な企業は本番到達前にAI PoCの46%を破棄していた。McKinseyの「State of AI 2025」は、生成AIの導入率が9割近くに達する一方、AIに全社EBIT(利払い・税引き前利益)の5%超を帰属できる「AIハイパフォーマー」はわずか6%程度、何らかのEBIT効果を実感した企業も39%にとどまると報告した。RAND Corporationに至っては、AIプロジェクトの8割超が失敗し、これは非AIのIT案件のおよそ2倍の失敗率だと指摘している。
調査会社Gartnerの予測も厳しい。2024年7月の発表では、生成AIプロジェクトの少なくとも30%がデータ品質の低さ、不十分なリスク管理、コスト増大、不明確なビジネス価値を理由に、2025年末までにPoC段階で打ち切られるとした。さらに2025年6月には、3,400社超を対象にした調査をもとに、エージェンティックAI(自律的に業務を遂行するAIエージェント)プロジェクトの40%超が、2027年末までに中止されると予測している。日本に目を転じれば、PwC Japanの「生成AIに関する実態調査2025春 5カ国比較」が、日本企業の56%が生成AIを実際に活用している(推進中を含めると76%)一方、成果が「期待を大きく上回った」とする企業は10%にとどまり、前年の9%からほぼ横ばいだったと報告した。同期間に米国企業は33%から45%へ伸びており、日本の課題が「導入率」ではなく「成果への転換」にあることを浮き彫りにしている。
壁の種類——5つの典型的な障壁
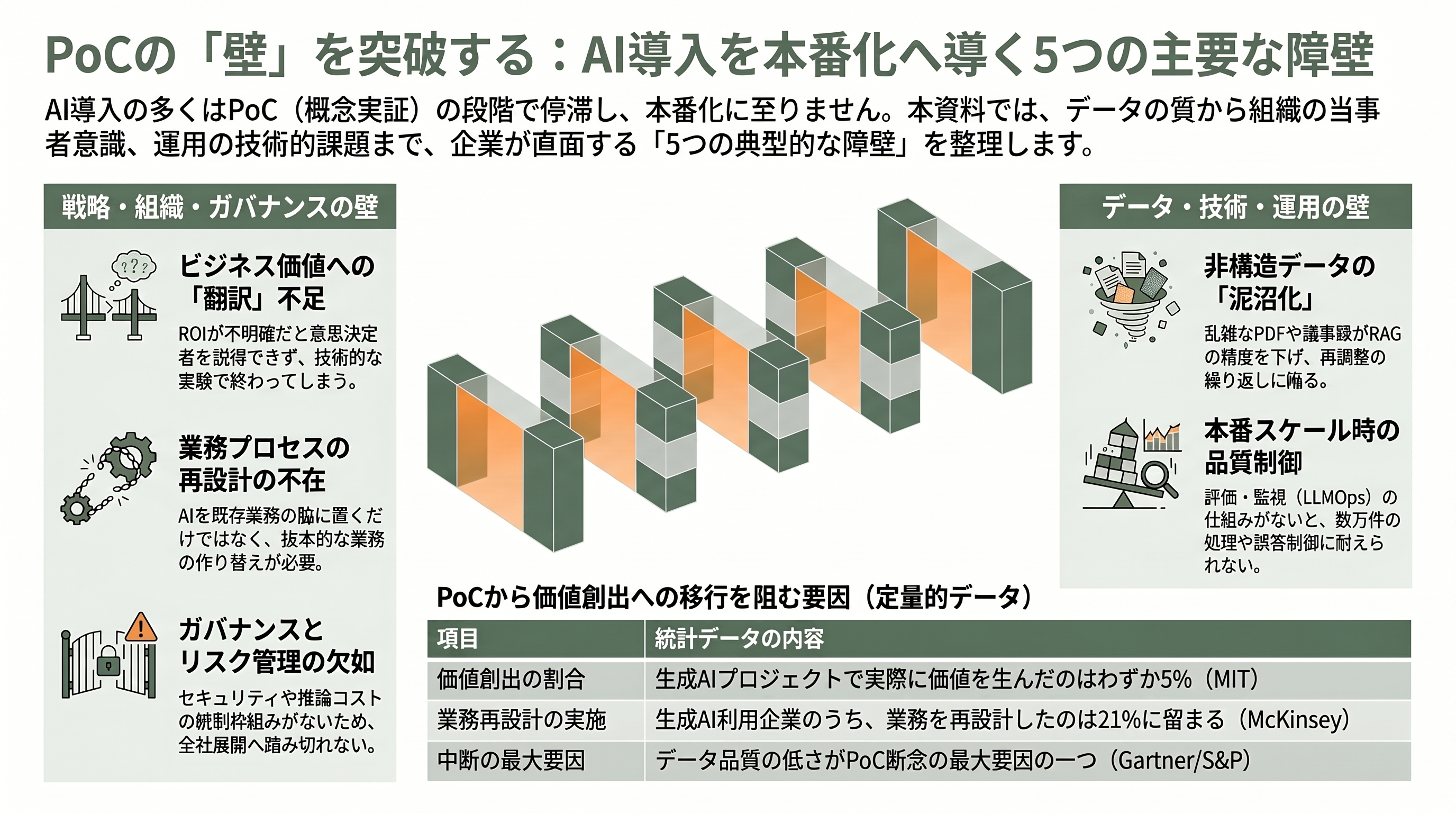
PoCの壁は単一ではなく、性質の異なる複数の障壁が折り重なって企業を立ち止まらせる。各種報告と現場の知見を統合すると、壁は大きく5つに整理できる。
第一はデータの壁である。生成AIや機械学習の性能は学習・参照するデータの質と量に強く依存するため、PoCではデータの収集・名寄せ・前処理に想定以上の時間を要する。GartnerもS&P Globalも、断念の最大要因の一つにデータ品質の低さを挙げている。とりわけ企業内に眠るデータの多くは、PDF・動画・ログ・議事録といった非構造データであり、a16zが指摘するように、こうした乱雑なデータがRAG(検索拡張生成)やエージェントの足を引っ張る。検索精度が出ないまま「期待した精度に届かない」と再調整を繰り返し、目的を見失って泥沼化する——これが典型的なデータ起因のPoC死である。
第二はROI・ビジネス価値の壁だ。PoCの目的が「技術的に動くか」の確認にとどまり、どの業務でいくらのコスト削減や売上貢献を生むのかという損益への翻訳に至らないと、本番化の意思決定者を説得できない。MITが言う「価値を生んだ5%」とそれ以外を分けたのも、突き詰めればこのビジネスケースの有無だった。McKinseyが「パイロットがEBITを動かさないなら、問題はモデルではなくオペレーティングモデルと測定にある」と断じたのも同じ論点である。
第三は組織・人の壁である。技術チームは前のめりでも、事業部門が当事者意識を持たず、経営のスポンサーシップも欠ける。日本企業に多い「情シスの実験で完結する」構図はこの典型だ。McKinseyは、EBIT効果と最も強く相関するのは業務プロセスの抜本的な再設計だとしながら、生成AIを使う企業のうち実際に業務を再設計したのは21%にすぎないと指摘する。人と業務の作り替えを伴わない限り、AIは既存業務の脇に置かれた「便利な実験」のまま終わる。
第四は技術・運用の壁だ。デモでは10件うまくいっても、本番では数万件を処理する。そこではハルシネーション(もっともらしい誤答)の制御、出力品質の継続的な評価、監視、例外処理、レイテンシ(応答速度)とスケール時のコストが一気に重くのしかかる。MITは、失敗の核心を「学習ギャップ」と表現した。多くの生成AIシステムはフィードバックを記憶せず、文脈に適応せず、使うほど賢くならない。だからこそ評価・監視の仕組み(後述するLLMOps)が決定的に重要になる。
第五はガバナンス・コスト・セキュリティの壁である。S&P Globalの調査で企業が挙げた障壁の上位は、コスト、データプライバシー、セキュリティリスクだった。利用が拡大するほど推論コストは膨らみ、機密情報の漏洩や規制対応のリスクが顕在化する。リスク統制の枠組みを欠いたまま全社展開に踏み切れず、PoCで足踏みする企業は少なくない。
なぜシリコンバレーは「壁」を別の角度から見るのか
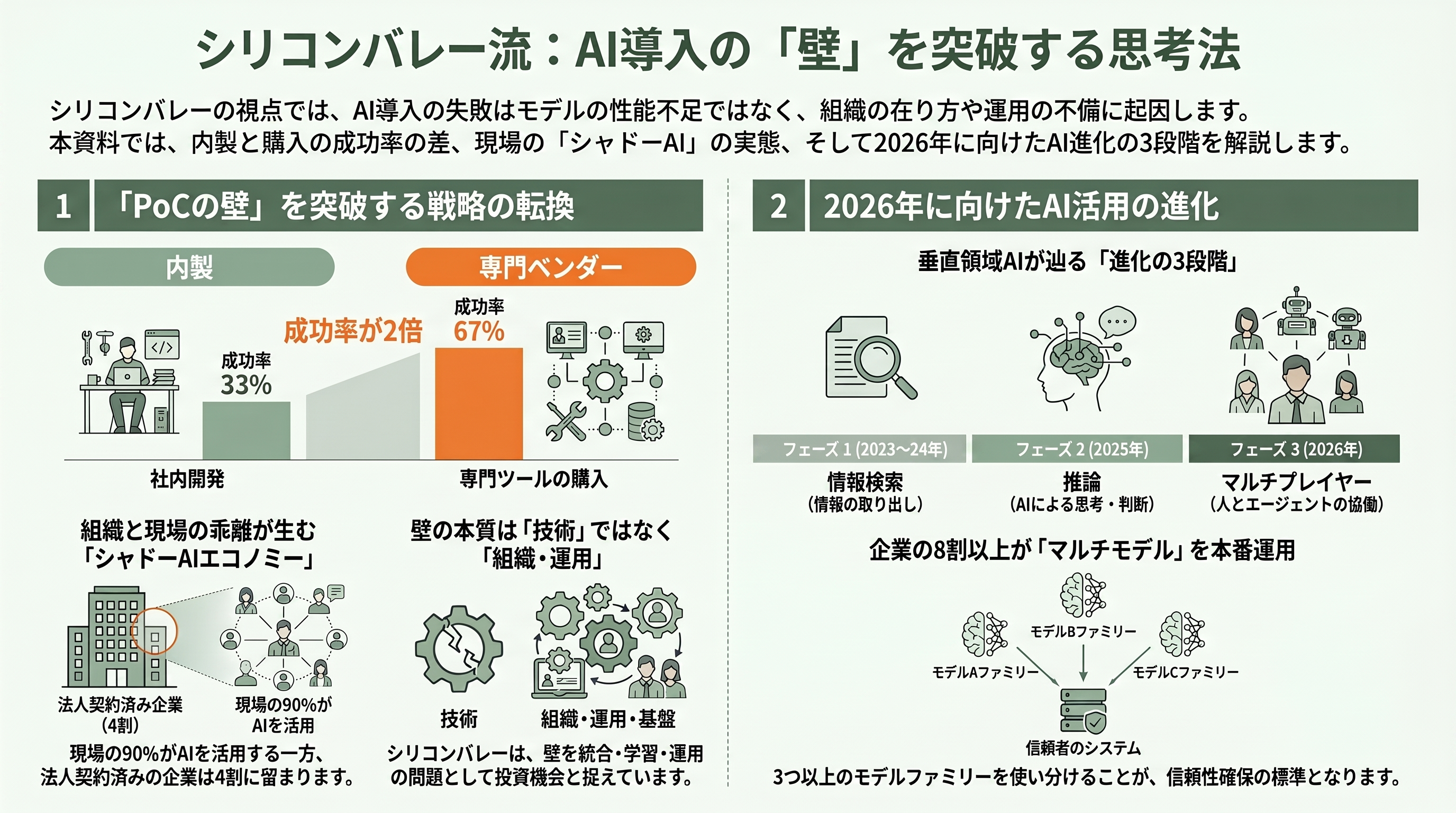
同じ「PoCの壁」でも、シリコンバレーのテック企業やVC、アナリストの語り口は日本の議論と微妙に角度が異なる。彼らはこの壁を「モデルの問題」としてではなく、「統合・学習・運用・組織の問題」として一貫して捉え、そこにこそ次の事業機会があると見る。
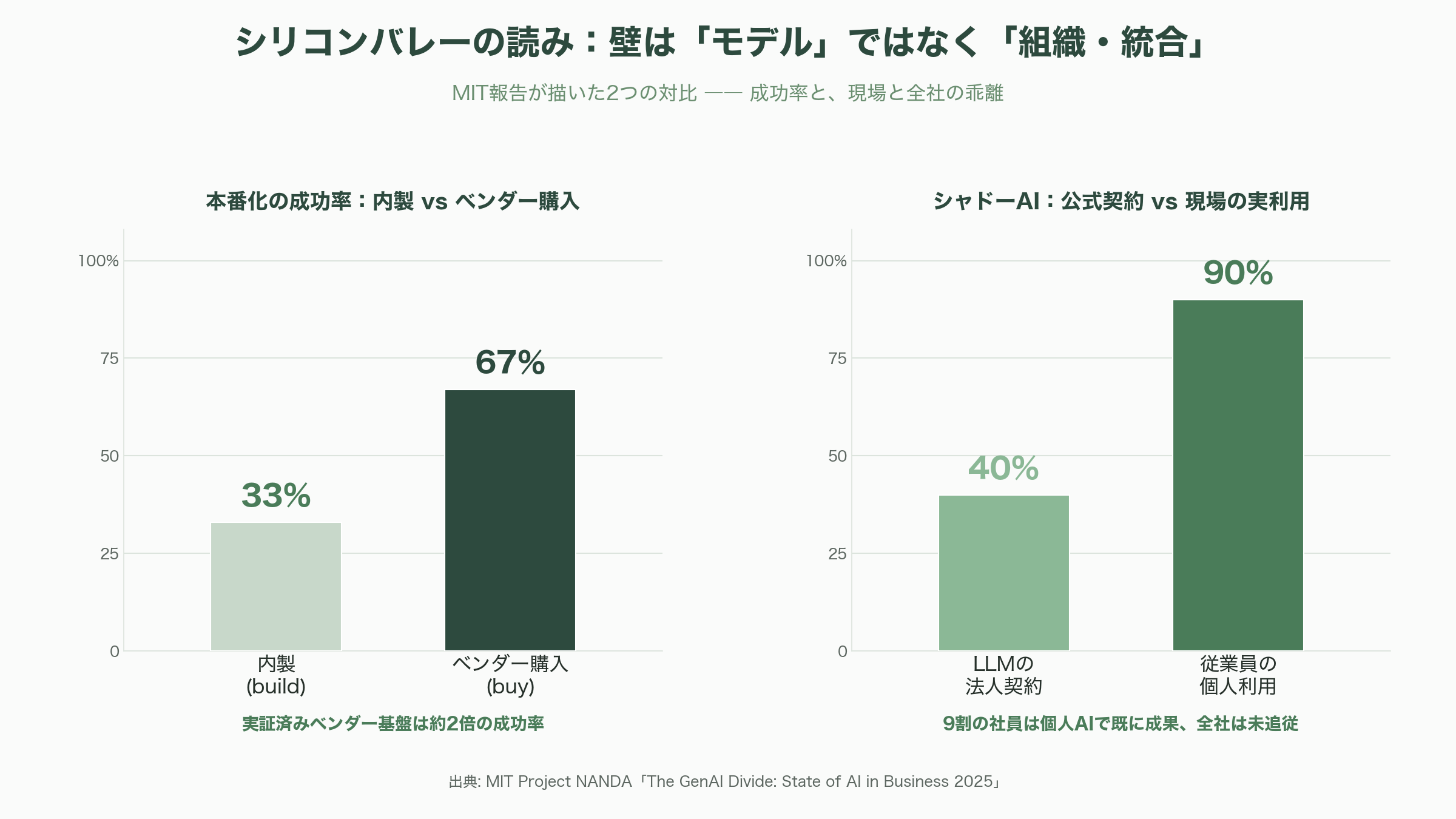
象徴的なのがMIT報告の「内製対購入(build vs. buy)」の発見だ。報告書によれば、専門ベンダーから購入したAIツールは約67%が成功した一方、社内で内製したシステムの成功率は約33%にとどまった。ベンダーの専門知、迅速な導入、実証済みの実装パターン、そして多数の顧客を横断した継続的なモデル改善が差を生んだという。「とりあえず自前でPoCを作る」発想こそが壁を高くしている、という逆説的な示唆である。
同報告はまた「シャドーAIエコノミー」も描き出した。公式にLLMの法人契約を結んでいる企業は40%にとどまる一方、従業員の90%はChatGPTやClaudeといった個人向けAIを日常業務で使っていた。現場はすでにAIで成果を出しているのに、全社システムが追いついていない——壁は技術ではなく組織の側にある、という見立てを裏づける。
VCの視点はさらに前のめりだ。Andreessen Horowitz(a16z)は2026年の論考「Notes on AI Apps in 2026」で「AIはアプリケーションソフトウェアを飲み込む」と論じ、医療・法務・住宅といった垂直領域のAIが数年で1億ドル(約155億円)超のARR(年間経常収益)に到達していると指摘する。同社のAlex Immermanは垂直AIの進化を、情報検索のフェーズ1(2023〜24年)、推論のフェーズ2(2025年)、複数の人とエージェントが協働する「マルチプレイヤー」のフェーズ3(2026年)という三段階で捉える。乱雑な非構造データを構造化・統治することにこそ巨大な価値があり、それを解く新興企業が次の勝者だ、というのがシリコンバレーの読みである。Anthropicが2026年に公表した「State of AI Agents」レポートも、エージェント本番化のボトルネックはモデルの能力ではなく、安全で信頼できる訓練・評価基盤の不足にあると指摘し、同レポートが伝えるところでは本番では3つ以上のモデルファミリーを使い分ける企業が8割を超えたという。壁の正体を「基盤の未整備」と読み替える点で、各社の見立ては符合している。
第一の突破策——ビジネス課題から始め、狭く深く攻める
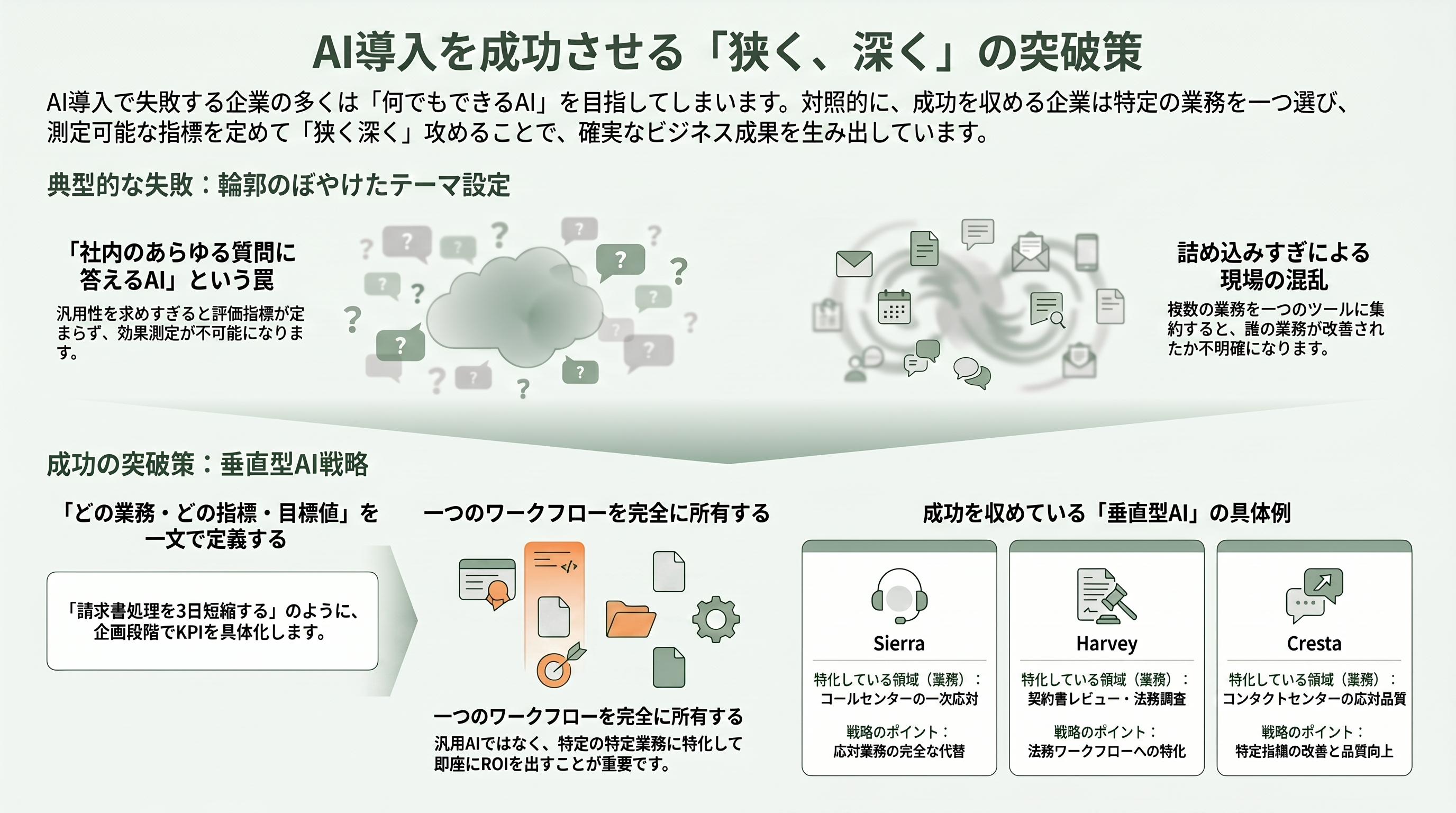
では、どうすれば壁を越え、あるいは回避できるのか。各調査と実装現場の知見は、いくつかの共通解に収斂する。その第一が、技術検証ではなくビジネス課題から始め、狭く深く攻めることだ。MITは、成果を出した企業は汎用的な万能AIを狙わず、一つの業務(ワークフロー)を選んでそこを完全に所有し、即座に測定可能なROIを出していると指摘する。
分かれ目は対象の絞り込みに表れる。「社内のあらゆる質問に答えるAIアシスタント」のような輪郭のぼやけたテーマは、典型的な失敗の入口だ。問い合わせ対応も経理処理も法務レビューも一つのチャットボットに詰め込もうとした瞬間、評価指標が定まらず、誰の業務がどれだけ楽になったのかを誰も答えられなくなる。対照的に成功例は徹底して狭い。コールセンターの一次応対を丸ごと引き受けるSierra、契約書レビューと法務調査に的を絞ったHarvey、コンタクトセンターの応対品質に特化したCresta——いずれも「一つの業務を所有し、即座に測定可能なROIを出す」というMIT流の処方箋を、創業から数年でARR1億ドル級の事業へと結晶させた。a16zが称揚する垂直AIの成功は、まさにこの「ナローに攻める」戦略の体現にほかならない。
要は、PoCの企画段階で「どの業務の、どの指標を、いくら動かすか」を一文で言い切れるかどうかだ。請求書処理の自動化なら「月次の経理締めを3日短縮する」、コールセンターの通話要約なら「一件あたりの後処理時間を4割削る」といった具合に、対象業務・指標・目標値をあらかじめ定義する。そのうえで本番運用の評価基準・監視・例外処理・業務フローへの組み込みまで設計に含めておくことが、検証止まりを防ぐ最大の分岐点になる。
第二の突破策——内製とベンダー購入を冷静に切り分ける

第二の突破策は、内製とベンダー購入を冷静に切り分けることだ。内製成功率33%対購入成功率67%というMITの数字は、汎用的な基盤や評価ツールは実績あるベンダーを使い、自社固有の業務ロジックやデータ統合に内製リソースを集中せよ、という現実的な指針を与える。
切り分けの具体例はこうだ。エージェントのオーケストレーションや評価・監視のような、どの企業でも構造が似通う土台は、LangChainやLangGraph、LangSmithのような実証済みの基盤を買ってくるほうが速く、確実に動く。同じ車輪を自前で再発明しても、ベンダーが多数の顧客を横断して積み上げた実装パターンや継続的なモデル改善には追いつけない。逆に、自社の請求書フォーマットの癖、固有の承認フロー、社内データベースとの接続といった「自社にしか存在しない部分」こそ、外注では埋まらず、内製の人的リソースを集中すべき領域である。
ありがちな失敗は、この優先順位が逆転することだ。汎用基盤をゼロから自作することに技術チームの体力を吸い取られ、肝心の業務ロジックに手が回らないまま予算が尽きる。検証は延々と繰り返せるのに次フェーズの投資が下りない「PoC貧乏」は、まさにこの「すべてを自前で抱え込む」発想から生まれる。MIT報告が「とりあえず自前でPoCを作る」発想こそが壁を高くしていると逆説的に示したのも、この一点にほかならない。
第三の突破策——データ基盤と評価・監視基盤(LLMOps)を先に整える
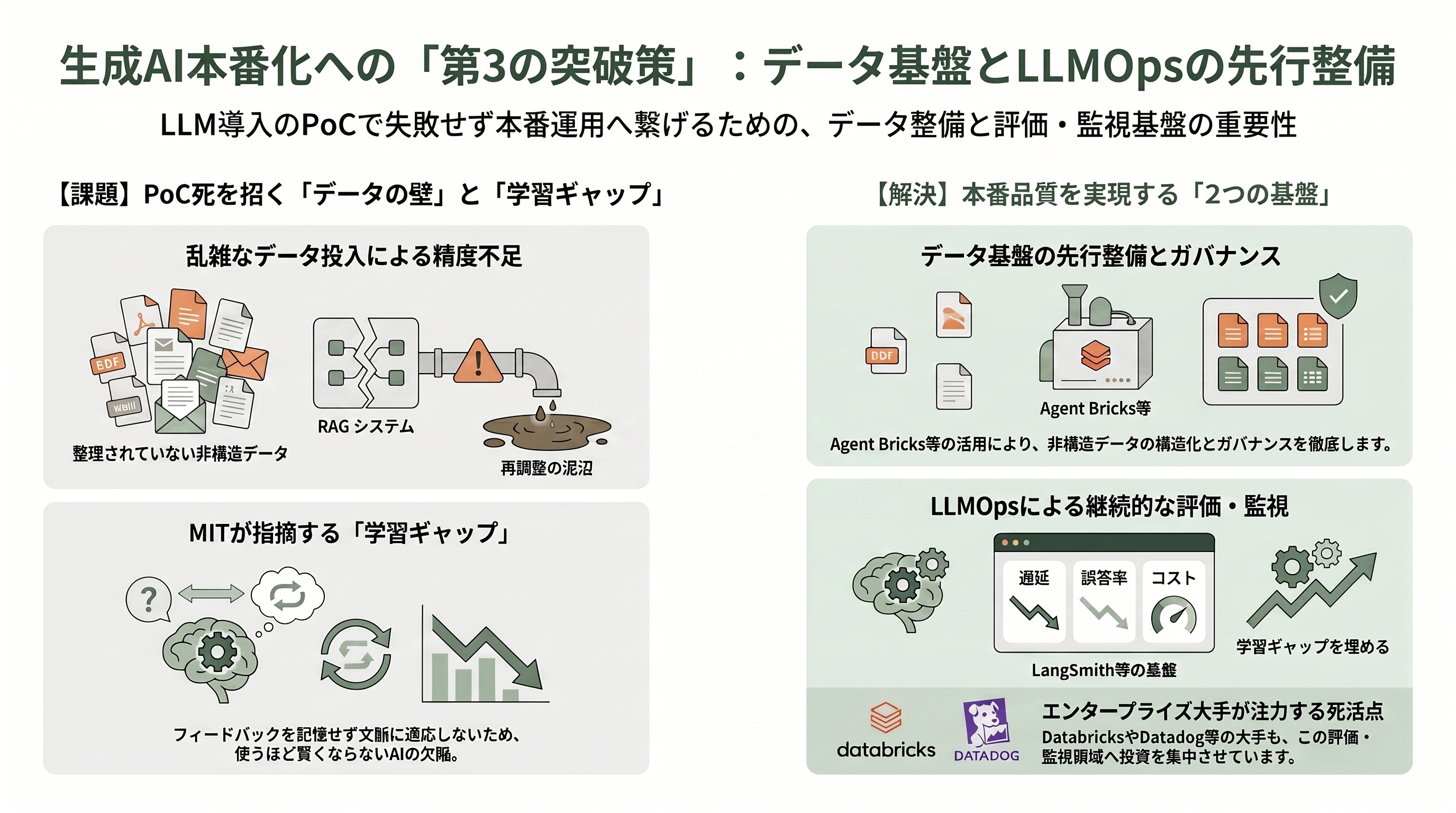
第三の突破策は、データ基盤と評価・監視基盤(LLMOps)を先に整えることだ。非構造データの構造化とガバナンスがRAGやエージェントの精度を左右する以上、データ整備は後回しにできない。社内に眠るマニュアルやPDF、議事録、コールログといった乱雑な非構造データをそのままRAGに流し込めば、検索精度は出ず、「期待した精度に届かない」と再調整を延々と繰り返すデータ起因のPoC死に直行する。だからこそDatabricksは、企業データの上に本番品質のエージェントを構築する「Agent Bricks」や、自然言語で分析する「Genie」、運用データベース「Lakebase」へ投資を集中させ、「データの壁」と「運用の壁」を同時に崩しにいっている。
データ整備と並んで欠かせないのが、出力品質を継続的に測る評価(eval)、本番での挙動を追う可観測性(observability)、ハルシネーションや逸脱を検知・是正する監視である。具体的には、本番投入の前に正解データセットに対する正答率を測り、本番後も応答の遅延・誤答率・コストをLangSmithやBraintrust、Arizeのような評価・監視基盤で追い続ける。MITが失敗の核心と名指しした「学習ギャップ」——多くの生成AIシステムがフィードバックを記憶せず、文脈に適応せず、使うほど賢くならないという欠陥——を埋めるのは、まさにこの評価と監視のフィードバックを回す仕組みにほかならない。LangChainの評価・監視基盤に、Sequoiaに加えてServiceNowやWorkday、Cisco、Datadog、Databricksといったエンタープライズ大手が軒並み出資しているのも、ここが本番化の死活点だと各社が見抜いているからだ。
第四の突破策——業務を再設計し、人を介在させる(human-in-the-loop)
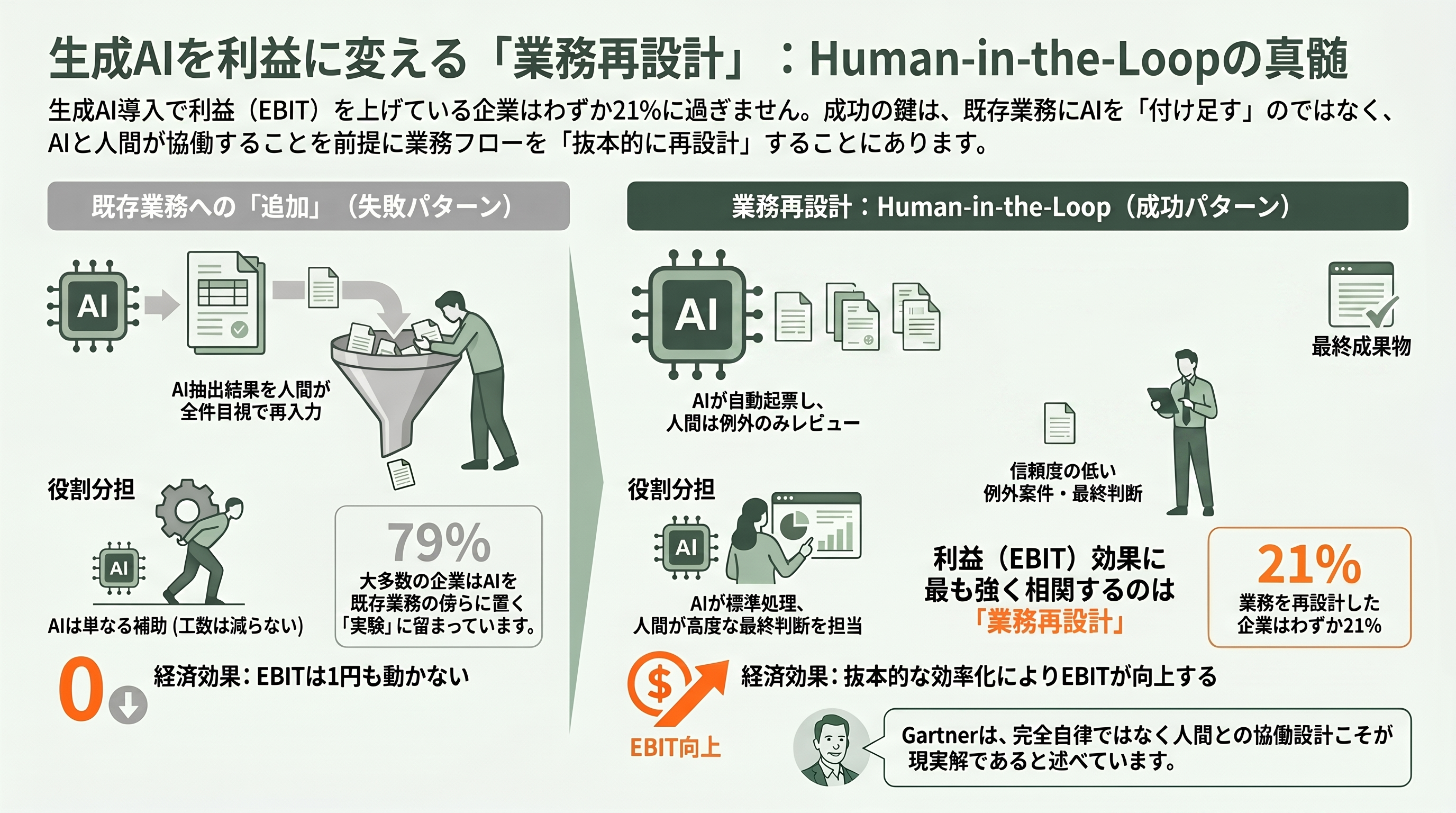
第四の突破策は、業務そのものを再設計し、人を介在させる(human-in-the-loop)ことだ。McKinseyが示したとおり、EBIT効果と最も強く相関するのは業務プロセスの抜本的再設計であり、生成AIを使う企業のうち実際に業務を再設計したのはわずか21%にすぎない。裏を返せば、残る大多数はAIを既存業務の脇に置かれた「便利な実験」のまま終わらせている。
両者の違いは、業務の組み方に具体的に表れる。請求書処理にAIを足すだけの企業は、AIが抽出した金額を人間が従来どおり全件目視で入力し直す——これでは工数は減らず、EBITは1円も動かない。業務を作り替えた企業は逆に、AIが請求書から金額・取引先を自動抽出して会計システムへ起票するまでを既定のフローに組み込み、人間は信頼度の低い例外案件だけをレビューする。判断の重い契約審査でも、AIが論点と修正案を提示し、最終判断は弁護士が下すという分業を業務フローそのものに埋め込む。肝心なのは、人間のレビューを「後から付け足す保険」ではなく、最初から設計の一部として組み込むことだ。Gartnerが「エージェンティックAIの普及はかえって人間を不可欠にする」と述べたのも、完全自律ではなく人間との協働設計こそが現実解だという含意にほかならない。
第五の突破策——経営のスポンサーシップとガバナンスを確立し、小さく始めて段階的に広げる
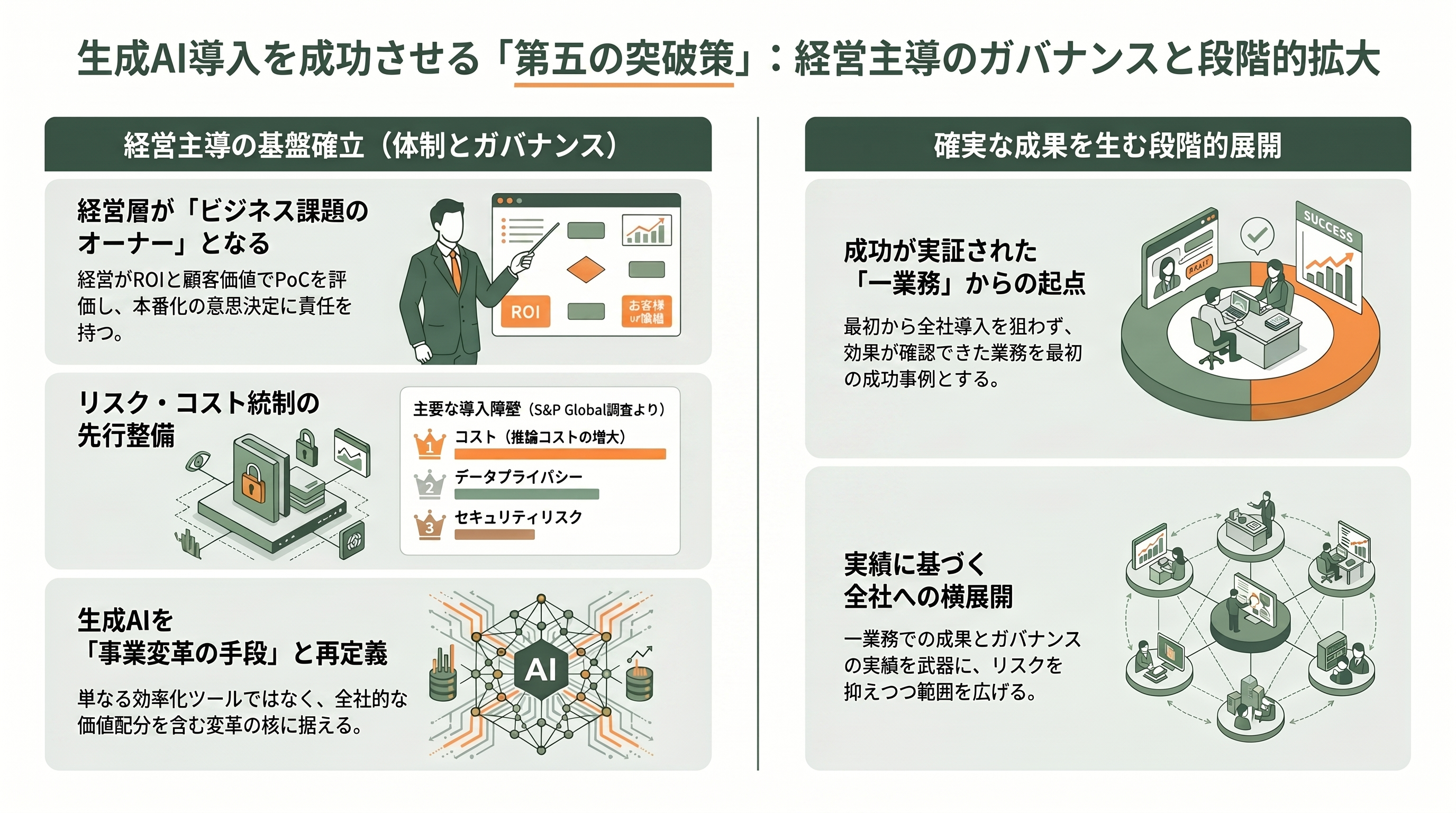
第五の突破策は、経営のスポンサーシップとガバナンスを確立し、小さく始めて段階的に広げることだ。日本企業に典型的な「情シスの実験で完結する」構図では、経営層がROIや顧客価値を評価できないままPoCが自然消滅する。これを断ち切るには、経営層自身がビジネス課題のオーナーとなり、ROIと顧客価値の観点でPoCを評価し、本番化の意思決定に責任を持つ体制が要る。
同時に欠かせないのが、リスク統制・セキュリティ・コスト管理の枠組みである。S&P Globalの調査で企業が障壁の上位に挙げたのは、まさにコスト、データプライバシー、セキュリティリスクだった。利用が広がるほど推論コストは膨らみ、機密情報の漏洩や規制対応のリスクが顕在化する。だからこそ、機密データの取り扱いルール、利用量とコストの上限、出力の監査ログといったガバナンスを先に用意したうえで、成果の出た一業務から全社へ横展開する。一気に全社導入を狙わず、効果が実証された一業務を起点に段階的に広げることが、リスクを抑えながら本番化を進める現実解になる。PwC Japanが各国の高成果企業に共通して見出したのも、生成AIを単なる効率化ツールではなく事業変革の手段と位置づけ、ガバナンスと従業員への価値配分まで含めて全社で取り組む姿勢だった。日本企業の課題が導入率ではなく成果への転換にある以上、この経営主導の全社改革こそが、壁を越える最後にして最大の分岐点となる。
壁を越えるための主要サービスとプロダクト、その出資元
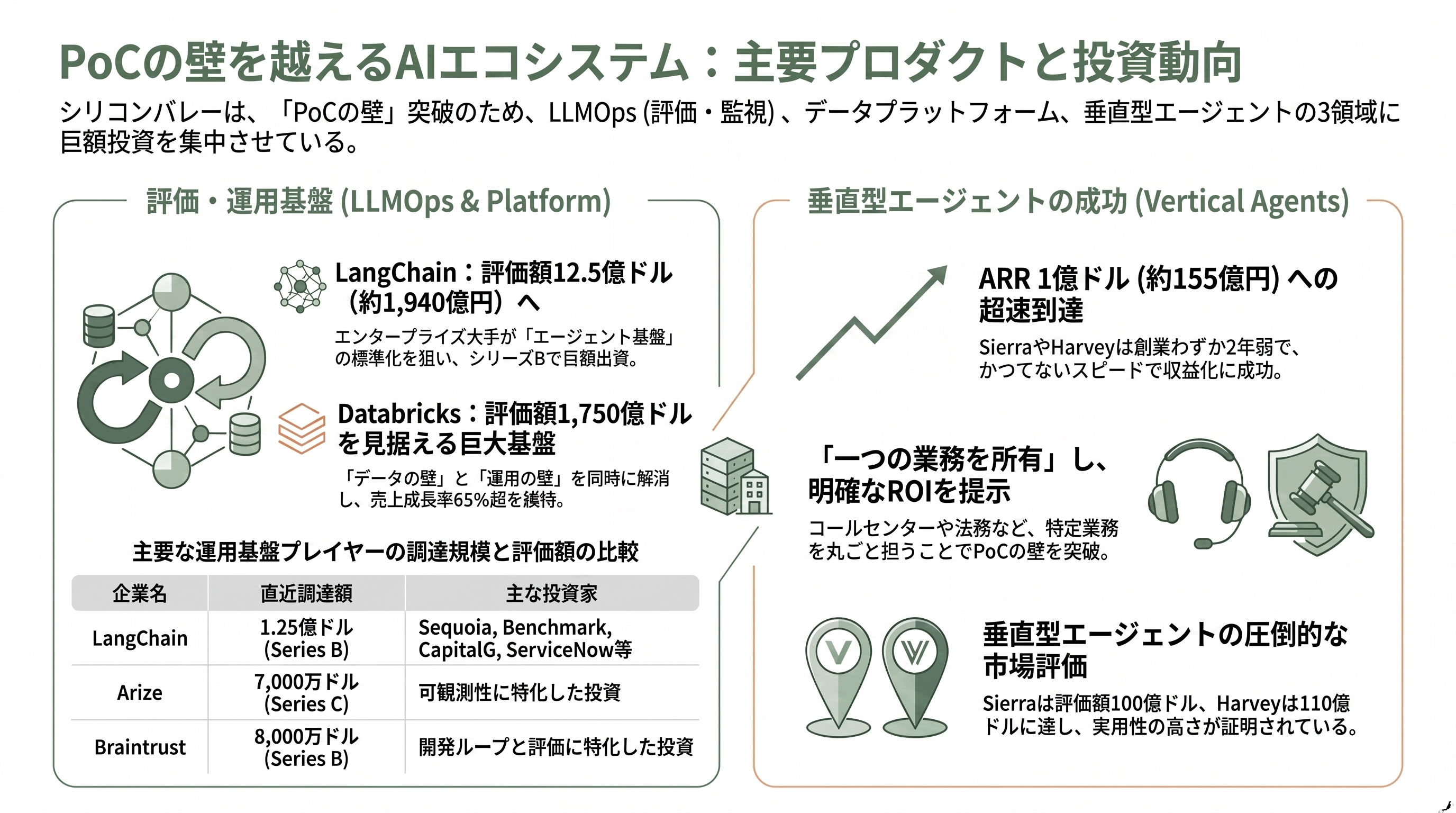
こうした突破策を支える製品群と、その背後にいる投資家を概観すると、シリコンバレーが「PoCの壁」をどこにビジネス機会と見ているかが立体的に見えてくる。
評価・監視(LLMOps)の領域では、LangChainが代表格だ。同社はLLMアプリ構築フレームワーク「LangChain」、エージェントのオーケストレーションを担う「LangGraph」、そして評価・監視の中核「LangSmith」を擁する。2025年10月にはIVPが主導するシリーズBで1億2,500万ドル(約194億円)を調達し、評価額は12億5,000万ドル(約1,940億円)に達した。出資にはSequoia、Benchmark、CapitalG、ServiceNow Ventures、Workday Ventures、Cisco Investments、Datadog、Databricksなどが名を連ね、エンタープライズソフト大手が軒並み「エージェント基盤」に張っている構図がうかがえる。同社は2024年2月のシリーズAではSequoia主導で2,500万ドル(約39億円)を調達していた。可観測性に強いArizeは2025年2月のシリーズCで7,000万ドル(約109億円)を、開発ループと評価に特化するBraintrustは2026年2月のシリーズBで8,000万ドル(約124億円)を調達するなど、「本番AIの品質を測る」基盤への投資は途切れない。
データとエージェントを統合するプラットフォーム層の主役はDatabricksだ。同社は2025年8月に評価額1,000億ドル(約15.5兆円)を突破し、同年12月のシリーズLで1,340億ドル(約20.8兆円)に到達。米The Informationが2026年6月9日に報じたところでは、さらに1,650億〜1,750億ドル(約25.6兆〜27.1兆円)での新規調達を協議中とされる。売上のランレートは54億ドル(約8,400億円)規模で前年同期比65%超の成長を続け、企業データ上で本番品質のAIエージェントを構築する「Agent Bricks」や、自然言語で分析を行う「Genie」、運用データベース「Lakebase」に投資を集中させている。まさに「データの壁」と「運用の壁」を同時に崩しにいく布陣だ。
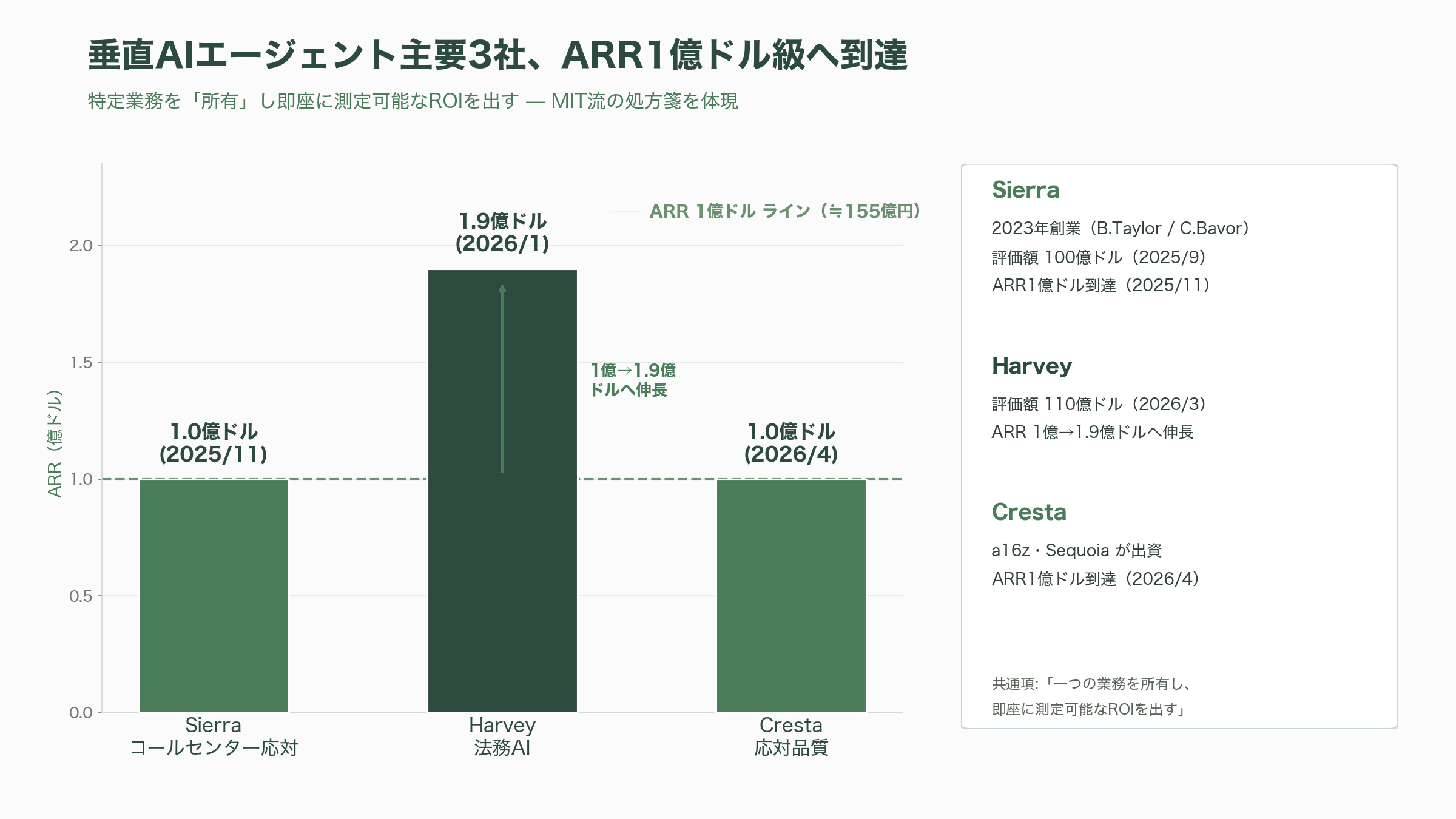
そして、PoCの壁を実際に越えた成功例として注目されるのが、特定業務を丸ごと担う垂直エージェント群である。元Salesforce共同CEOでOpenAI会長のBret Taylorとグーグル出身のClay Bavorが2023年に創業したSierraは、コールセンターの音声・チャット応対を自律的に担うエージェントを提供し、2024年10月に評価額45億ドル(約7,000億円)、2025年9月にはGreenoaks主導の3億5,000万ドル(約540億円)調達で100億ドル(約1.55兆円)へと倍増した。2025年11月には創業2年弱でARR1億ドル(約155億円)に到達したとされ、2026年5月にもCNBCなどが10億ドル(約1,550億円)近い追加調達を報じている(評価額はさらに上昇したと一部で報じられているが、確報値には揺れがある)。法務AIのHarveyは、CNBCが2026年3月に報じたところでは2億ドル(約310億円)の調達で評価額110億ドル(約1.7兆円)に達し、ARRは2025年8月の1億ドル(約155億円)から2026年1月には1億9,000万ドル(約295億円)へ伸びた。a16zとSequoiaが出資するコンタクトセンター向けのCrestaも、2026年4月にARR1億ドル(約155億円)到達がAxiosにより報じられている。いずれも「一つの業務を所有し、即座に測定可能なROIを出す」というMIT流の処方箋を、事業として体現した存在である。
まとめ——「PoCの壁」は技術ではなく経営と運用の壁
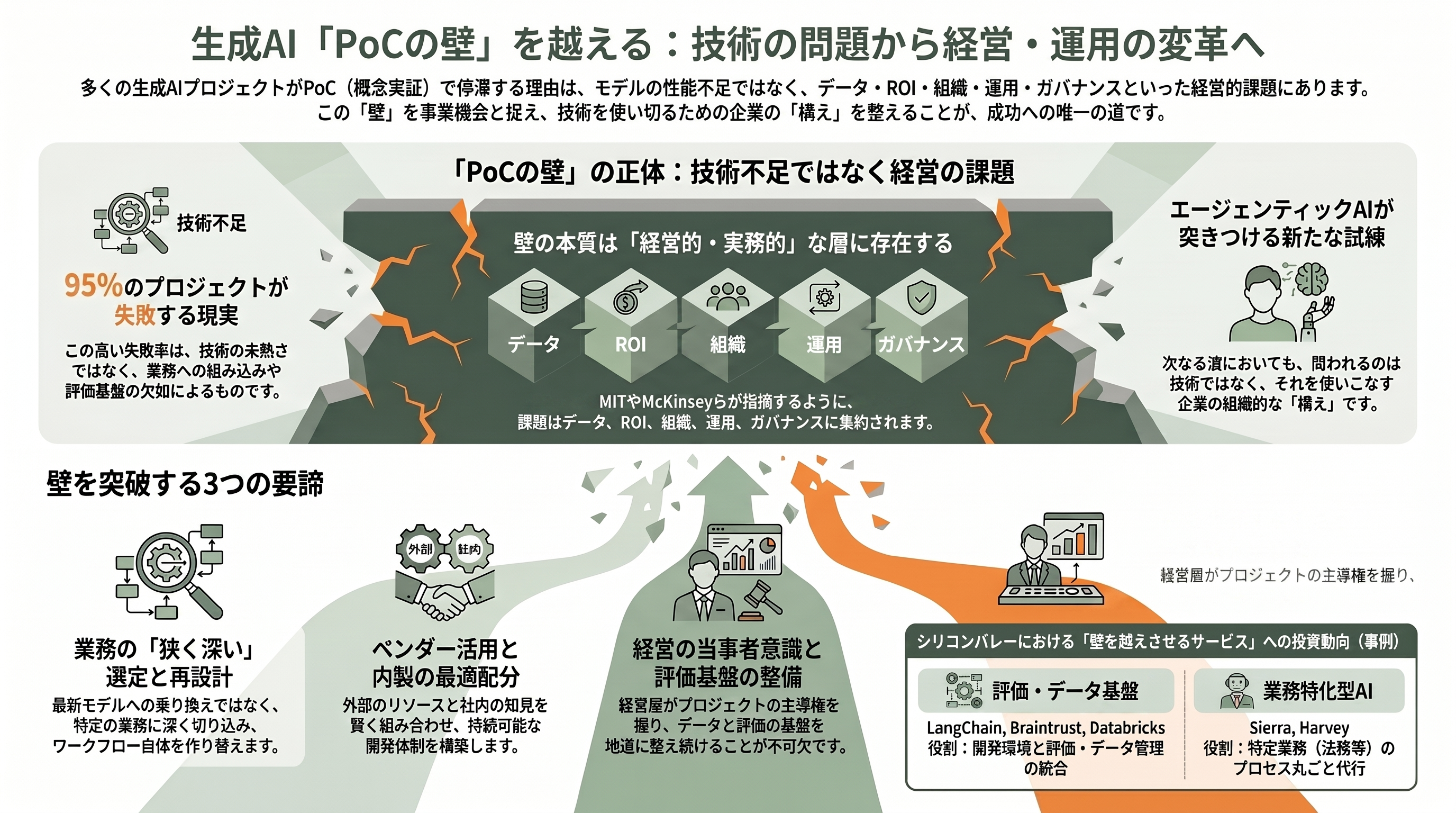
ここまで見てきたとおり、PoCの壁の本質は、生成AIモデルの賢さの不足ではない。MITが「学習ギャップ」と呼び、McKinseyが「オペレーティングモデルと測定の問題」と断じ、a16zが「データとワークフローの問題」と読み替えたように、壁はデータ・ROI・組織・運用・ガバナンスという、きわめて経営的かつ実務的な層に立っている。だからこそ、それを越える方法もまた、最新モデルへの乗り換えではなく、業務を狭く深く選び、ベンダーと内製を賢く配分し、データと評価の基盤を整え、業務を作り替え、経営が当事者になる、という地道な積み重ねに尽きる。
シリコンバレーは、この壁を悲観の材料ではなく、巨大な事業機会として捉え直している。評価基盤のLangChainやBraintrust、データとエージェントを束ねるDatabricks、業務を丸ごと担うSierraやHarveyへ巨額の資金が流れ込むのは、「95%が失敗する」現実の裏側に「壁を越えさせるサービス」の市場が広がっているからにほかならない。エージェンティックAIという新しい波もまた、同じ壁を再び突きつけるだろう。問われているのは技術ではなく、それを使い切る企業の側の構えである。