リーク報道から48時間、Anthropicが見せた「破壊と踏襲」
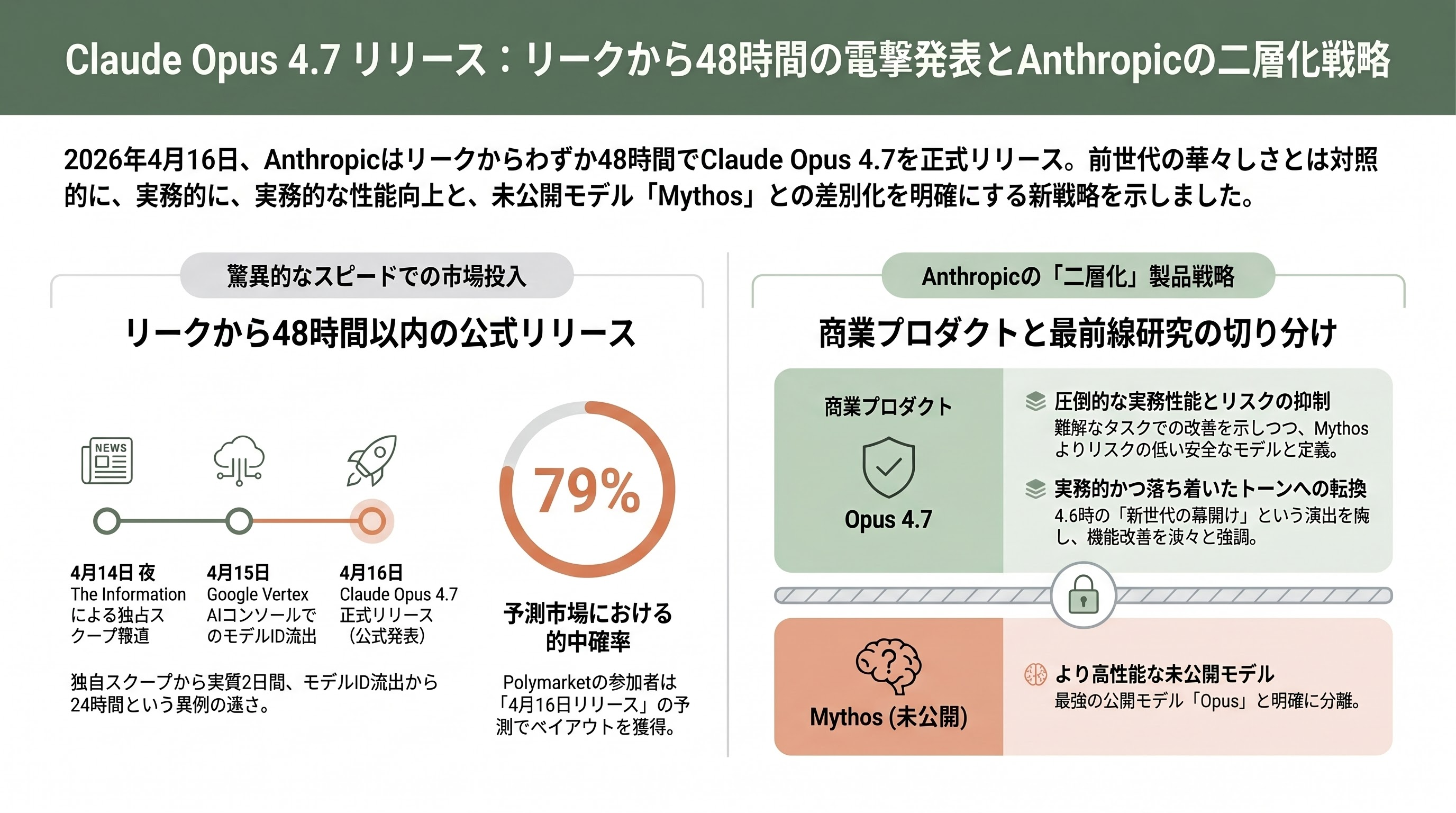
Anthropicは2026年4月16日(米国太平洋時間)、生成AI業界の耳目を集めていたClaude Opus 4.7を正式リリースした。The Informationが独占スクープを打った4月14日夜から実質わずか48時間、Google Vertex AIコンソールでのモデルID流出からはわずか24時間後という、極めて迅速な公式アナウンスであった。Polymarketで79%の暗黙確率が付いていた「4月16日リリース」は的中し、予測市場の参加者はペイアウトを受け取った。
公式ブログ『Introducing Claude Opus 4.7』の論調は、前世代Opus 4.6のリリース時に見られた「新世代の幕開け」という華々しいトーンとは対照的に、極めて実務的で落ち着いたものであった。Anthropicは「Opus 4.7はOpus 4.6に対する顕著な改善であり、最も難しいタスクで特に大きな成果を示した」と淡々と記し、同時に「一般公開モデルとしては最強だが、未公開のClaude Mythos Previewにはまだ及ばない」と公然と認めた。CNBCは「Mythosよりリスクが低いAIモデル」、Axiosは「未公開のMythosに及ばないことを認めた」と報じ、Anthropicが自社内の「最前線研究成果」と「商業プロダクト」を明確に二層化した戦略を取っていることを浮き彫りにした。
本記事では、Anthropicの公式ドキュメント、社員のSNS投稿、パートナー企業の公式声明を一次ソースとして変更点を整理した上で、CodeRabbit・Warp・Cursor・Factory Droidsといった初期採用パートナーのエンジニアリングチームの実測データ、Hacker Newsでの技術者コミュニティの反応、そしてシリコンバレーVCの受け止めを統合し、「何が変わったのか」「どう使えばよいのか」「どう受け止められているのか」を立体的に明らかにする。
リリース直後の公式数値——ベンチマークは「地殻変動」ではなく「着実な上積み」
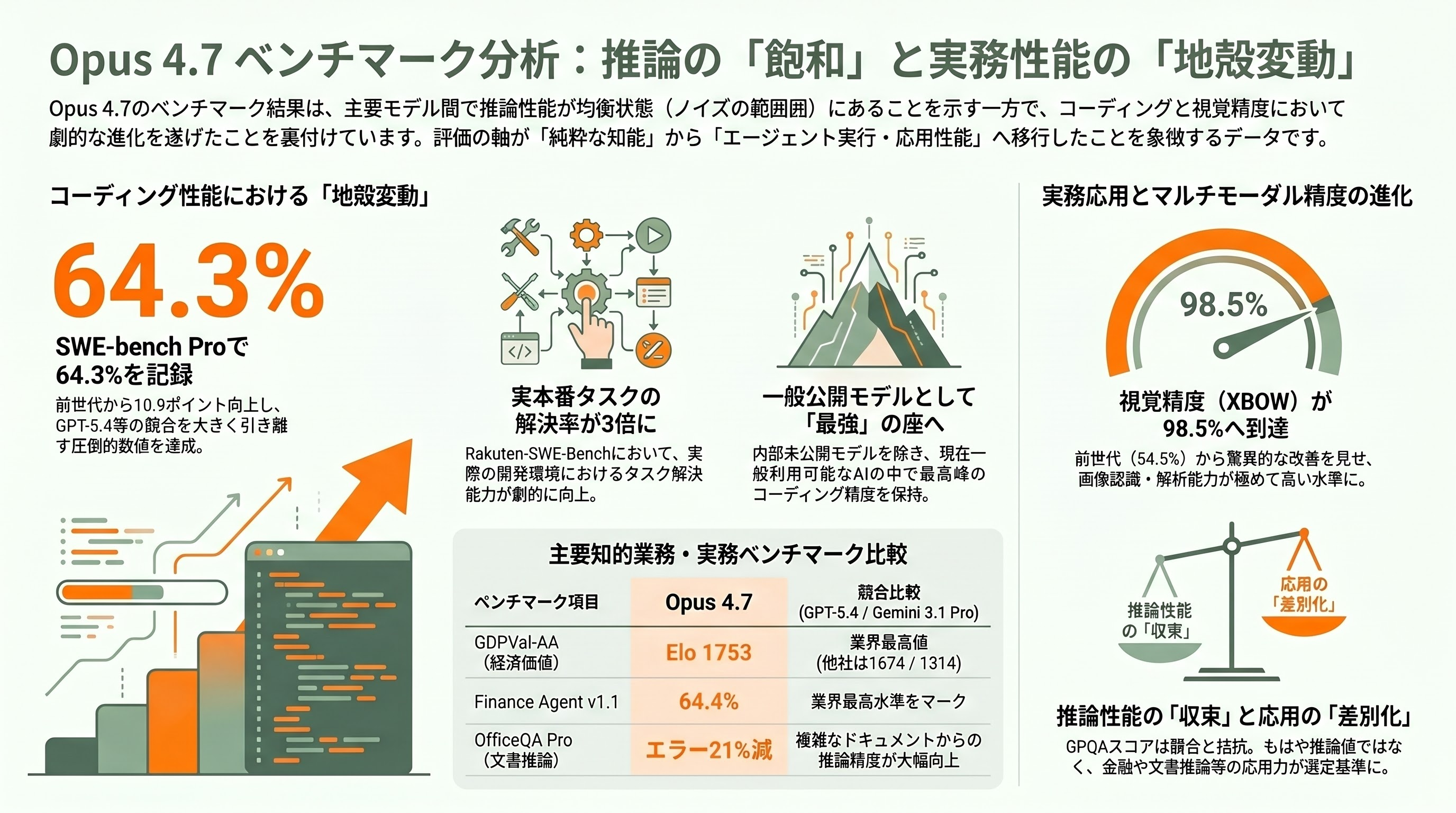
Anthropic公式ブログおよびAWS Bedrock公式ブログ、Google Cloud Vertex AIブログに掲載された数値を総合すると、Opus 4.7の主要ベンチマークは以下の通りである。
コーディング系ベンチマーク
| ベンチマーク | Opus 4.7 | Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
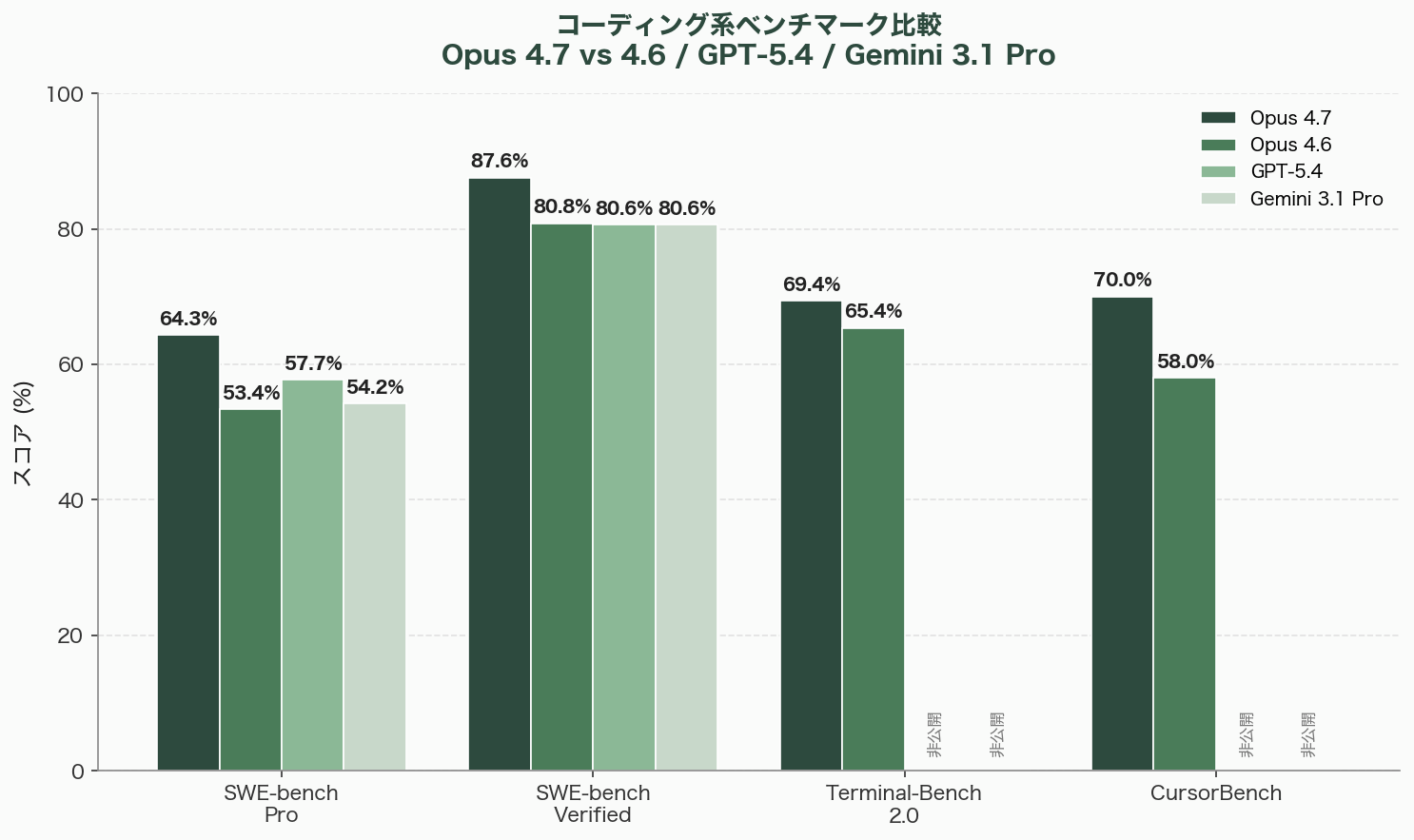
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| SWE-bench Verified | 87.6% | 80.8% | 80.6% | 80.6% |
| Terminal-Bench 2.0 | 69.4% | 65.4% | 非公開 | 非公開 |
| CursorBench | 70% | 58% | 非公開 | 非公開 |
SWE-bench Proでの10.9ポイントの伸びは、前々世代からの改善がせいぜい2〜3ポイント程度であったことを考えると、明確な「地殻変動」である。ただしこの数値は、未公開のMythos Previewが記録した93.9%には遠く及ばない。Anthropicが「一般公開の最強」を謳いながらも、内部に「封じ込められた最強」を温存している構造が、ベンチマーク上でも明確に読み取れる。
マルチモーダル・知的業務系
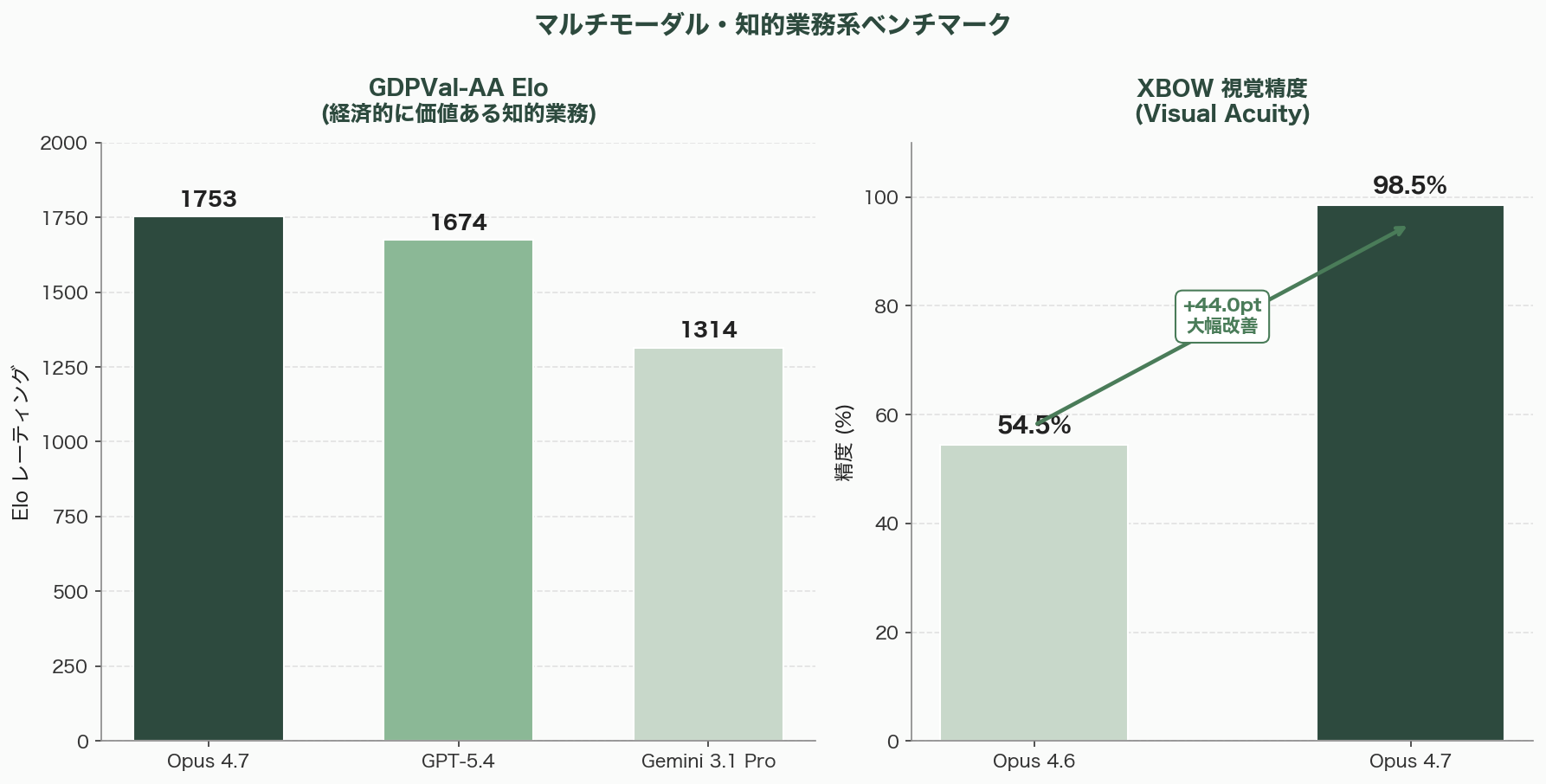
- GDPVal-AA(経済的に価値ある知的業務): Elo 1753(GPT-5.4: 1674、Gemini 3.1 Pro: 1314)
- Finance Agent v1.1: 64.4%(業界最高水準)
- GPQA Diamond(大学院レベル推論): 94.2%(GPT-5.4 Pro 94.4%、Gemini 3.1 Pro 94.3%とほぼ拮抗)
- XBOW視覚精度(Visual Acuity): 98.5%(Opus 4.6の54.5%から大幅改善)
- OfficeQA Pro(文書推論): 21%エラー減
- Rakuten-SWE-Bench: 本番環境タスクの解決率が3倍
興味深いのはGPQA Diamondの結果で、The Next Webが指摘するように「主要フロンティアモデル間の差がノイズの範囲内に収束している」。純粋な推論スコア勝負の時代は終わり、差別化の軸は「応用性能」「エージェント実行」「マルチモーダル精度」へと完全に移行したことが鮮明になった。
【本丸】新機能の技術詳細——Anthropic公式ドキュメントから直接引く
ここからが本記事の核心部分である。Anthropicの公式ドキュメント(platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7)に基づき、新機能を一次ソースで検証していく。
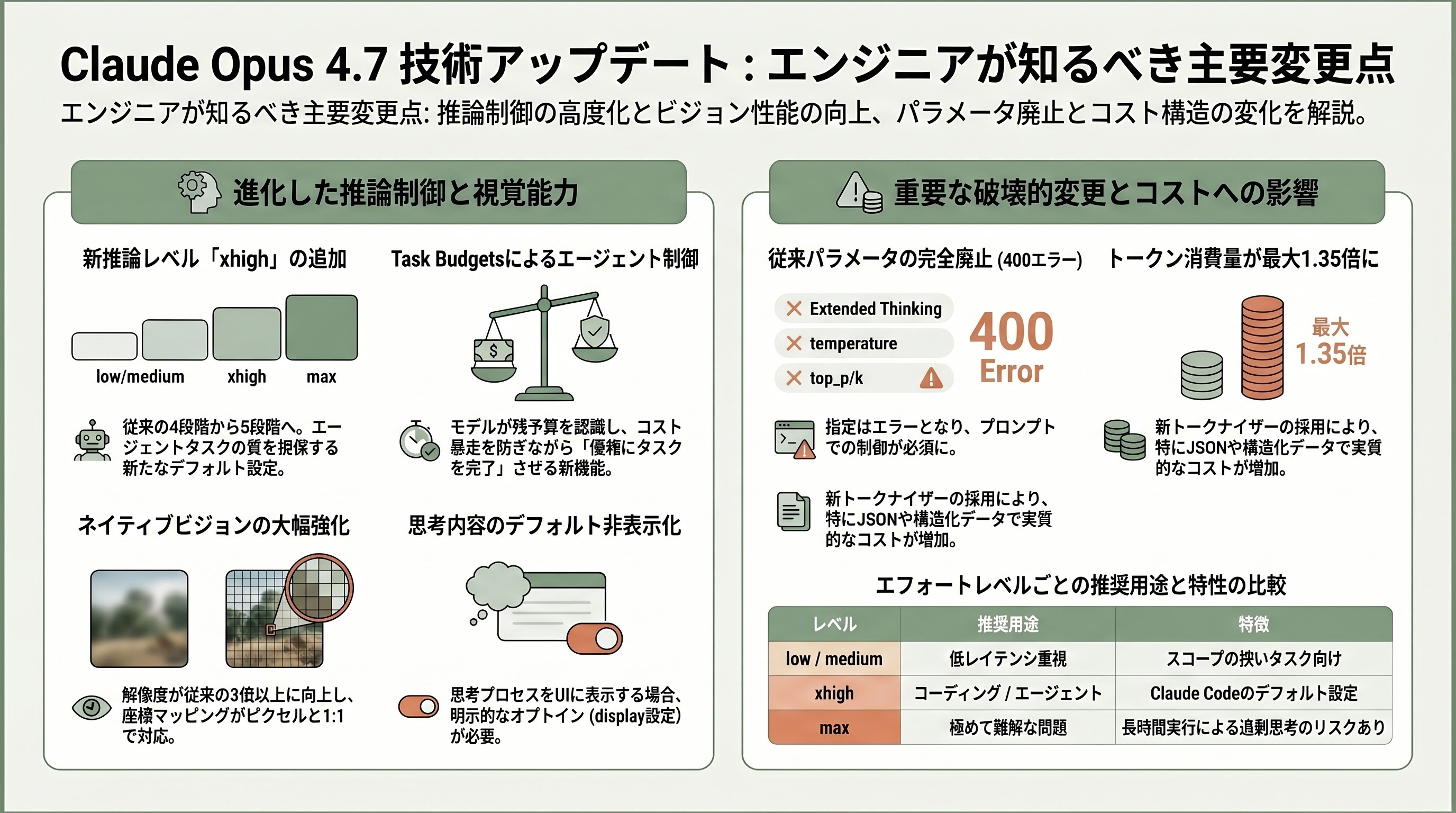
1. xhigh 推論レベル——「コストと知性のスイートスポット」
Opus 4.7で最も注目すべき新機能が、effortパラメータの5段階化である。従来はlow / medium / high / maxの4段階であったが、新たにhighとmaxの間に位置するxhighが追加された。
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=12000,
thinking={"type": "adaptive"},
output_config={"effort": "xhigh"},
messages=[{"role": "user", "content": "Refactor this codebase..."}]
)
Claude Codeの作者Boris Cherny氏は自身のX投稿(4月16日)で「Opus 4.7 uses adaptive thinking instead of thinking budgets. To tune the model to think more/less, we recommend tuning effort.」と述べ、Claude Codeでは全プランでxhighをデフォルトに設定したと明言した。これはエンジニアにとって重要なシグナルで、「highでは agenticコーディングワークフローで質を取り逃している」という開発者フィードバックに応じた決断だと説明されている。
Anthropic公式のエフォート別ガイドは以下の通りである。
| レベル | 推奨用途 |
|---|---|
low / medium | コスト・レイテンシ重視、スコープの狭いタスク |
high | 知性とコストのバランス、並列セッション運用 |
xhigh(Claude Code デフォルト) | ほとんどのコーディング・エージェントタスク |
max | 本当に難しい問題のみ。長時間実行では過剰思考のリスク |
Vellum AIの分析によれば、「Opus 4.7のlow効果レベルは、おおむねOpus 4.6のmediumレベルに相当する」とされ、底上げが全レベルで起きていることが確認されている。
2. Task Budgets(公開ベータ)——エージェント暴走対策の本命
task_budgetは、エージェントループ全体(思考・ツール呼び出し・ツール結果・最終出力を含む)に対して「おおよそこれだけのトークン予算で完遂してほしい」とモデルに伝える新パラメータである。重要なのは、これがmax_tokensとは根本的に異なる概念である点だ。
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
output_config={
"effort": "high",
"task_budget": {"type": "tokens", "total": 128000},
},
messages=[{"role": "user", "content": "Review the codebase..."}],
betas=["task-budgets-2026-03-13"],
)
Anthropic公式ドキュメントは明確に区別している。「max_tokensはリクエストごとの生成トークンのハードキャップ(モデルには伝えられない)、task_budgetはエージェントループ全体に対するアドバイザリーキャップ(モデルに伝えられ、カウントダウンを見て自己調整する)」。最小値は20,000トークン、ベータヘッダーtask-budgets-2026-03-13の指定が必要である。
エンジニアにとって特に有用なのは、モデルが残予算のカウントダウンを認識できる点だ。予算が減ってくると、モデルは探索を絞り、重要な出力を優先して「gracefully(優雅に)完了」しようとする。シリコンバレーのエンジニアコミュニティでは、Claude Code運用時の「コスト暴走」対策として歓迎されている。ただしAnthropic自身は「品質を優先したいオープンエンドなエージェントタスクではtask_budgetは設定しないこと」を推奨している。過度に厳しい予算を与えると、タスクを中途半端に終えたり、タスク自体を拒否したりする可能性があるためだ。
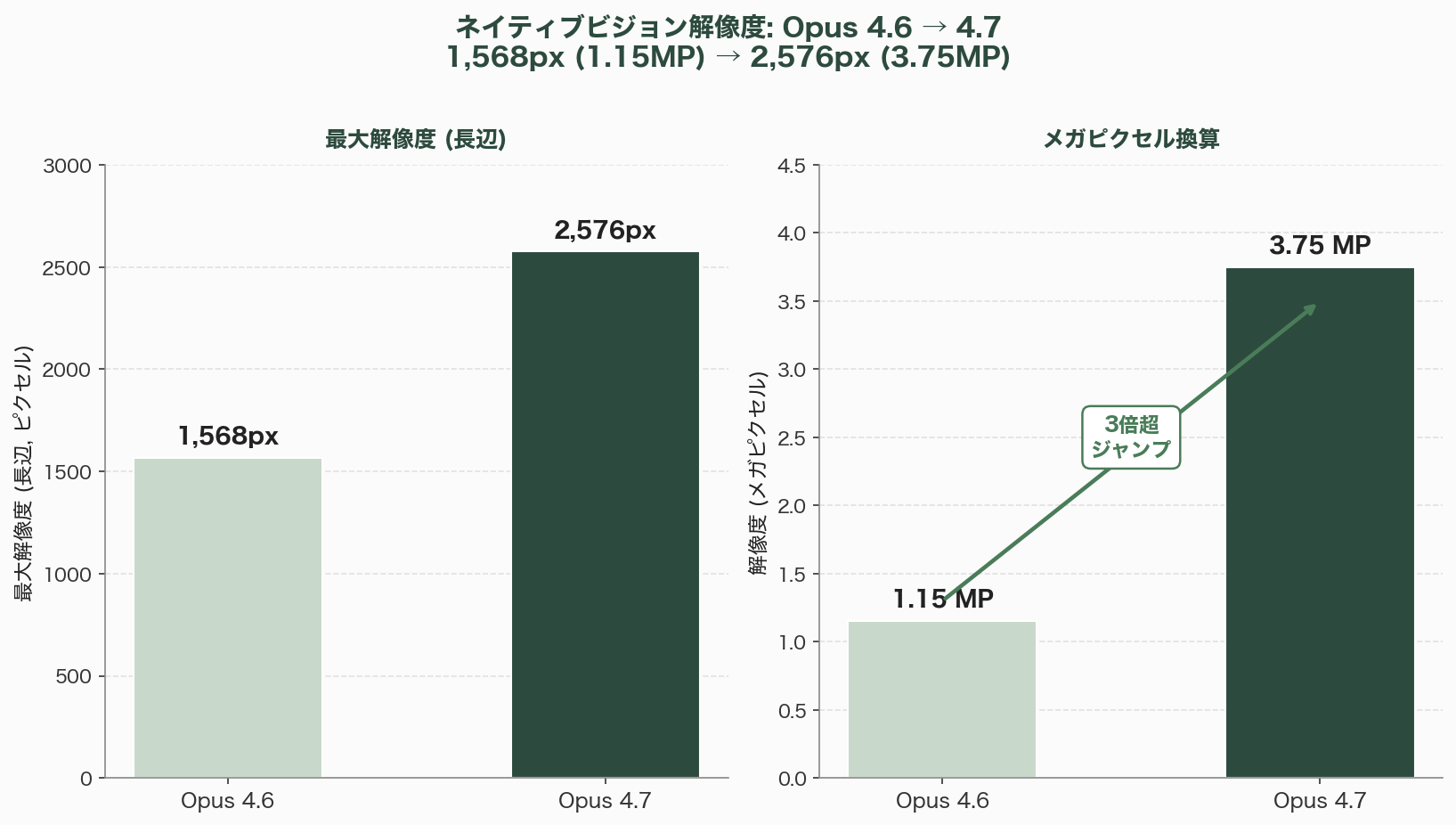
3. 高解像度ネイティブビジョン——2,576px / 3.75MP
ビジョン能力の強化は、Opus 4.7における最大のアーキテクチャ上のジャンプである。
- 最大解像度: 2,576px(長辺、3.75メガピクセル、従来の1,568px/1.15メガピクセルから3倍超)
- XBOW Visual Acuity: 54.5% → 98.5%(単発テキスト認識の超高精度化)
- 低レベル知覚: ポインティング、測定、カウンティングの精度向上
- 画像ローカライゼーション: 自然画像のバウンディングボックス検出の改善
- 座標マッピング: 画像座標がピクセルと1:1対応(スケール係数計算が不要)
最後の「1:1座標マッピング」は、Computer Use(Claudeにマウス操作をさせる)やスクリーンショット解析を行うエージェント開発者にとって朗報である。Opus 4.6までは、モデルの出力する座標は内部リサイズ後の画像系であり、実画像へのマッピングに煩わしい変換処理を要した。これが不要になった意義は大きい。
Dev.to のGabriel Anhaia氏は6時間のハンズオンテストで「密度の高いターミナルスクリーンショットを完璧に読み取った——すべての行、終了コード、タイムスタンプ、zsh プロンプトの薄いグレーのテキストまで」と報告している。
ただしAnthropicは「高解像度画像はより多くのトークンを消費する。細部が不要なら事前にダウンサンプリングせよ」と明記している。エンジニア視点では、入力画像の用途に応じた解像度管理が新たなコスト最適化ポイントとなる。
4. 【破壊的変更】Extended Thinking(固定予算思考)の完全撤廃
Opus 4.7で最も多くのコードベースに影響する破壊的変更がこれである。従来のthinking={"type": "enabled", "budget_tokens": N}という固定予算思考モードは廃止され、指定すると400エラーを返す。代わりに、Adaptive Thinking({"type": "adaptive"})のみがサポートされる。
# Opus 4.6まで
thinking = {"type": "enabled", "budget_tokens": 32000}
# Opus 4.7以降
thinking = {"type": "adaptive"}
output_config = {"effort": "high"}
さらに注意すべきは、Adaptive ThinkingがデフォルトではOFFであることだ。thinkingフィールドを明示指定しないリクエストは、思考なしで実行される。Anthropic は内部評価で「Adaptive Thinkingは Extended Thinking を一貫して上回った」と説明しているが、Hacker News(47793411)の議論では「adaptive thinking chooses to not think when it should」という批判的な報告も多く、モデルが思考すべき場面で思考を省略してしまうケースへの不満が噴出している。
5. 【破壊的変更】サンプリングパラメータの完全撤廃
temperature、top_p、top_kのいずれかをデフォルト以外の値に設定すると、400エラーとなる。推奨される移行パスは、これらのパラメータをリクエストから完全に省略することである。
Anthropicは明言している。「もしあなたがtemperature=0を決定論のために使っていたとしても、それは決して出力の同一性を保証しなかった」。モデルの挙動を制御したければ、プロンプトエンジニアリングで行うべし、というのがAnthropicの哲学である。
6. 【破壊的変更】思考内容のデフォルト非表示
デフォルトでは、思考ブロックはレスポンスストリームに現れるが、thinkingフィールドは空になる。ユーザに推論過程を表示する UI を持つプロダクトは、明示的にオプトインする必要がある。
thinking = {
"type": "adaptive",
"display": "summarized", # または "omitted"(デフォルト)
}
Anthropic公式はレイテンシがわずかに改善するとしているが、Hacker Newsでは「長時間の沈黙の後に出力が始まる」という UX の悪化が議論されている。ストリーミング UI を持つプロダクトでは、"display": "summarized"の設定が事実上必須となるだろう。
7. 新トークナイザー——同一入力に対して最大1.35倍のトークン
見落とされがちだが、エンジニアにとって最も痛いのがこの変更である。Opus 4.7は新しいトークナイザーを採用しており、同一テキストに対して1.0〜1.35倍のトークンを消費する。Finout社の分析によれば、JSON・構造化データほどトークン数の増加が顕著(1.2〜1.35倍)で、純粋な英語散文ではほぼ変化がないという。
表面的な単価は据え置きでも、「1リクエスト$0.10がOpus 4.7では$0.135に」という形で実質コストが上昇する。Finout社は「多くのチームにとって、正解は『4.7にアップグレード』ではなく『トラフィックの半分をSonnetに移す』である」と示唆しており、シリコンバレーの財務担当者に警鐘を鳴らしている。
GitHub Copilotでのpremium request multiplierが、Opus 4.6の3倍からOpus 4.7の7.5倍(4月30日までの促進価格)に引き上げられたのも、このトークン増加を反映したものと推測される。
8. リアルタイム・サイバーセキュリティ・セーフガード
Opus 4.7には、禁止または高リスクなサイバーセキュリティ用途を自動検出してブロックする仕組みが搭載された。合法的な脆弱性研究、ペネトレーションテスト、レッドチーミング目的のセキュリティ専門家向けに、新たな「Cyber Verification Program」(claude.com/form/cyber-use-case)への申請が案内されている。
これはMythos Previewと対になる設計で、Anthropicは「Mythos相当の能力を一般公開モデルに与えないため、訓練中にサイバー能力を差分的に削減する実験を行った」と認めている。Help Net Securityは「これはモデルの能力低下ではなく、意図的なスコーピング」と報じている。
Claude Codeの強化ポイント——エンジニアにしか分からない現場の変化
Opus 4.7のリリースと同時に、Claude Code側でも複数の機能強化が行われた。
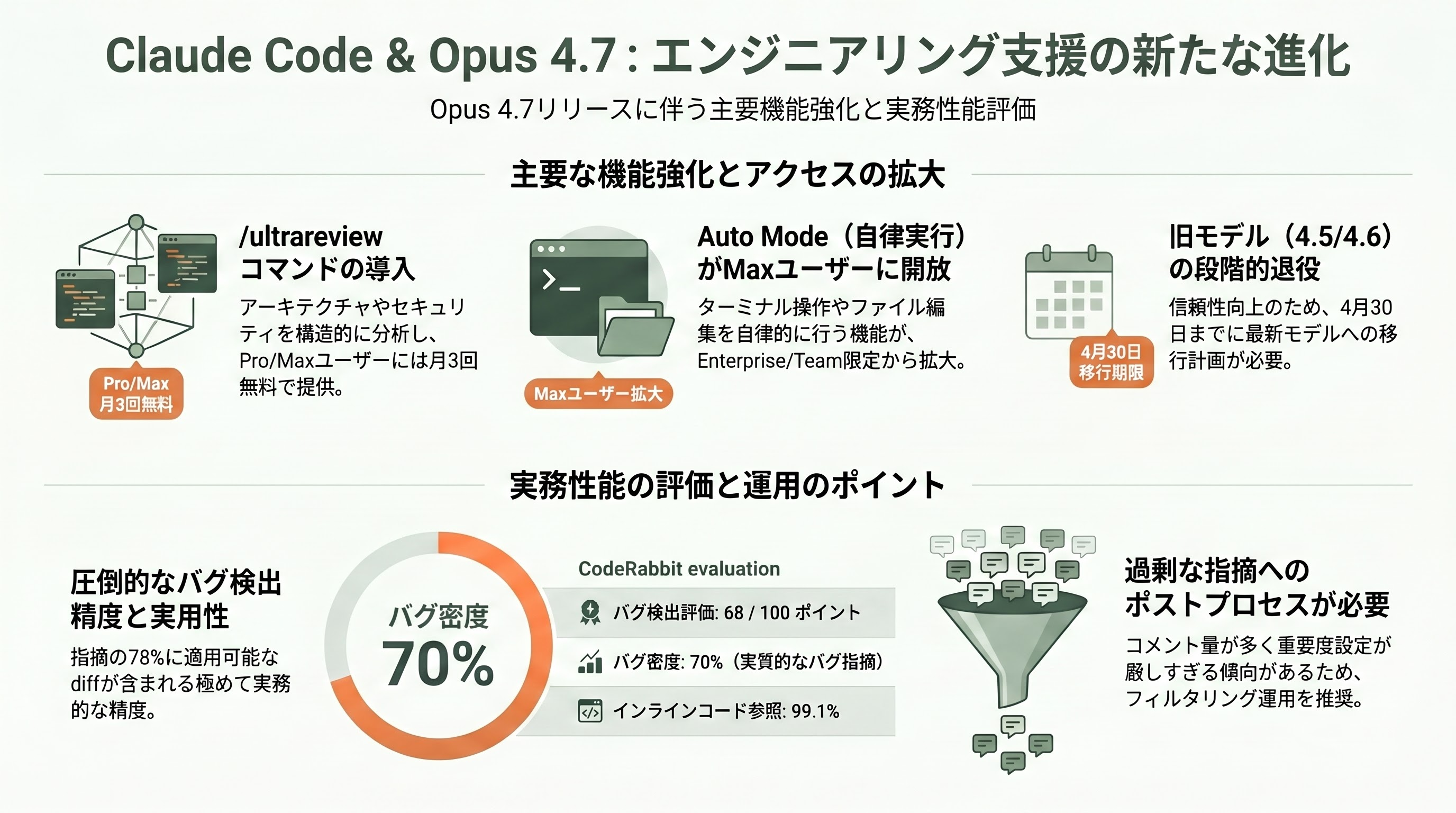
/ultrareview コマンドの追加
max効果レベルで実行される専用コードレビューセッションで、アーキテクチャ、ロジック、セキュリティ、性能、保守性を構造化された形式で分析する。Pro/Maxユーザーには月3回無料のクレジットが付与される。
CodeRabbit は100件の実在OSS PRでの評価で「Opus 4.7は最もシャープなモデル」と評価した。バグ検出評価では68/100ポイントを獲得、100コメントあたりのバグ密度は70%(スタイル指摘ではなく実質的なバグ)、99.1%のコメントにインラインコード参照、78%が適用可能なdiffを含む、という極めて実務的なレビュー能力を示した。
一方、CodeRabbitは明確な注意点も挙げている。「厳しすぎる重要度ラベル付け(テスト専用の失敗にもcriticalを付けがち)」「コメント量の過多(PR当たり平均19件以上)」「類似コードパスでの重複指摘」。本番投入時にはポストプロセスでのフィルタリングが必須とされる。
Auto Modeの拡張
Claudeが自律的にターミナルコマンドを実行・ファイル編集・反復する「Auto Mode」(Shift+Tab)が、従来はEnterprise/Teams限定であったが、Opus 4.7リリースと同時にMaxプラン加入者にも解放された。
旧モデルの段階的退役
GitHub Copilotは、Opus 4.5と4.6を数週間かけてPro+ユーザーのモデルピッカーから段階的に削除することを発表した。信頼性改善の一環と説明されているが、エンタープライズユーザーは4月30日までに移行計画を立てる必要がある。
非エンジニアのユーザにとっての変化——「ちょっと寡黙でプロフェッショナルになった」Claude

ビジネスユーザーや非エンジニアが日常的にClaude.aiやデスクトップアプリを使う場合、Opus 4.7の変化は以下のように現れる。
振る舞いの変化(プロンプトを書き直す必要があるもの)
Anthropic公式の『Behavior changes』セクションから列挙すると:
1. より文字通りの指示追従: 以前のClaudeは「ある項目への指示を他の項目にも暗黙的に適用する」傾向があったが、Opus 4.7は言われたことしかしない。例えば「このコードのコメントを英語にして」と指示すると、明示的に言わない限り変数名までは変えてくれない。
2. 応答の長さがタスクの複雑さに合わせて自動調整: 短い質問には短く、複雑な質問には長く、というキャリブレーションが強化された。決まった冗長さで答える傾向が減る。
3. ツール呼び出しが減少: デフォルトではより推論で済ませようとする。ウェブ検索が必要な場合は明示指示が有効。
4. 直接的・断定的な口調: 「Claude Opus 4.6の温かいスタイル」と比べて、より直接的・意見表明的な語り口。絵文字も減り、「Guard against nil」のような命令形が増える。CodeRabbitは「77.6%の断定率、16.5%のヘッジ率」という定量評価を出している。
5. 長時間タスク中の進捗報告が頻繁に: 「X をやっている途中です」「残りYを処理します」といった中間ステータスが自然に挿入される。
6. デフォルトではサブエージェントを生成しない: 旧版は並列処理を勝手に始めがちだったが、Opus 4.7は控えめ。並列化したい場合は明示的に指示する必要がある。
Aj Orbach CEO(ダッシュボード構築企業)は「データ豊富なUIに対するOpus 4.7の設計センスは、私が実際にshipするクオリティだ」と評価した。シリコンバレーのデザイナー業界では「AIが"taste"を持ち始めた」という文脈で語られている。
使い方のコツ(非エンジニア向け)
- 「十分に指示を明示する」: 暗黙的な期待を持たず、望むアウトプットの長さ・形式・トーンを最初のプロンプトで明示する。
- 長時間タスクには効果レベルを意識する: Claude.aiのUIでも効果レベルがユーザに公開されており、単純タスクは
medium、重要な思考タスクはhigh、コーディングや難しい分析はxhighという使い分けが推奨される。 - スクリーンショットの解像度を気にする: 高解像度対応のため、スマホのスクリーンショットや高精細のグラフ画像も正確に読み取れるようになった。表の数値やチャートの軸を読ませるタスクの精度が大きく向上している。
エンジニアだけが知る「小技とコツ」——コミュニティが発見した技法

Hacker News(47793411)、Boris Cherny氏の連続ツイート、Dev.to の6時間テスト記事、そしてCodeRabbit/Warp/Vercel/Cursorのパートナー報告から、エンジニアリングコミュニティが発見した小技を整理する。
コツ1: xhighを常用しつつmaxは例外扱いに
Anthropic公式は「maxは本当に難しい問題にのみ使用を。長時間実行では過剰思考で逆効果」と明言している。シリコンバレーの多くのエンジニアは「Opus 4.7のxhighで詰まるようなら、プロンプトを見直すべし。maxに上げて解決することは少ない」という感覚を共有している。
コツ2: プランモードを最初に使う
Boris Cherny氏はOpus 4.5の時代から一貫して「ほぼ常にplan modeで始めるのが最大のコツ」と発信しており、Opus 4.7でもこの原則は変わらない。詳細なプランに合意してから実装に入ると、Opus 4.7の「より文字通りの指示追従」が最大の味方になる。
コツ3: 従来の scaffolding(足場)を取り除く
Opus 4.7ドキュメントには「既存プロンプトにdouble-check the slide layout before returningのような修正的なscaffoldingがあれば、それを外して再ベースラインせよ」と明記されている。モデル自身が自己検証を行うようになったため、旧世代向けの防御的な指示文が逆に冗長性や過剰修正を誘発する。
コツ4: Claude Codeで思考サマリーを復活させる
デフォルトでは思考内容が非表示になったが、Claude CodeユーザはshowThinkingSummaries: true設定で復活可能。API直接利用の場合は"display": "summarized"をリクエストに加える。
コツ5: 1Mコンテキストのコスト制御
CLAUDE_CODE_DISABLE_1M_CONTEXT=1環境変数で、1Mコンテキストウィンドウを無効化し、コストを抑えられる。大規模リポジトリを扱わないシナリオでは有効。
コツ6: 「エンジニアに委譲する」メンタルモデル
Anthropic公式ブログ『Best practices for using Claude Opus 4.7 with Claude Code』は明示的に述べている。「Opus 4.7をペアプログラマとして行ごとにガイドするのではなく、有能なエンジニアに委譲するように使え」。最初のターンで意図・制約・受け入れ基準・関連ファイル位置を全て伝える方が、Opus 4.7の自律性を最大限引き出せる。
コツ7: プロンプトキャッシュと Sonnet 併用
Finout社の分析によれば、「Opusコスト制御の最大のレバーはプロンプトキャッシュ(最大90%削減)」。さらに、「多くのチームにとってはSonnet 4.6に半分のトラフィックを移す方が合理的」。月額$652のRAGワークロードがSonnet 4.6では$392に下がるという試算が示されている。
コツ8: タスクバジェットは閉鎖的タスクのみ
Anthropic公式は明言している。「品質が速度に勝るオープンエンドなエージェントタスクではtask_budgetを設定しないこと」。スコープが明確な「レビューを100ファイル終える」「リファクタリング計画を完成させる」といった閉鎖的タスクにのみ有効活用すべきである。
コツ9: 既存テストの一部を5〜10%のトラフィックで A/B 運用
NxCodeのデベロッパーガイドは「本番全面投入前に5-10%のトラフィックでA/Bテスト」を強く推奨している。トークナイザーの1.35倍増、指示追従の厳密化など、既存プロンプトの再調整を要する変更が多いため、段階的ロールアウトがリスク最小化のための標準手順となる。
パートナーエンタープライズ各社の実測データ
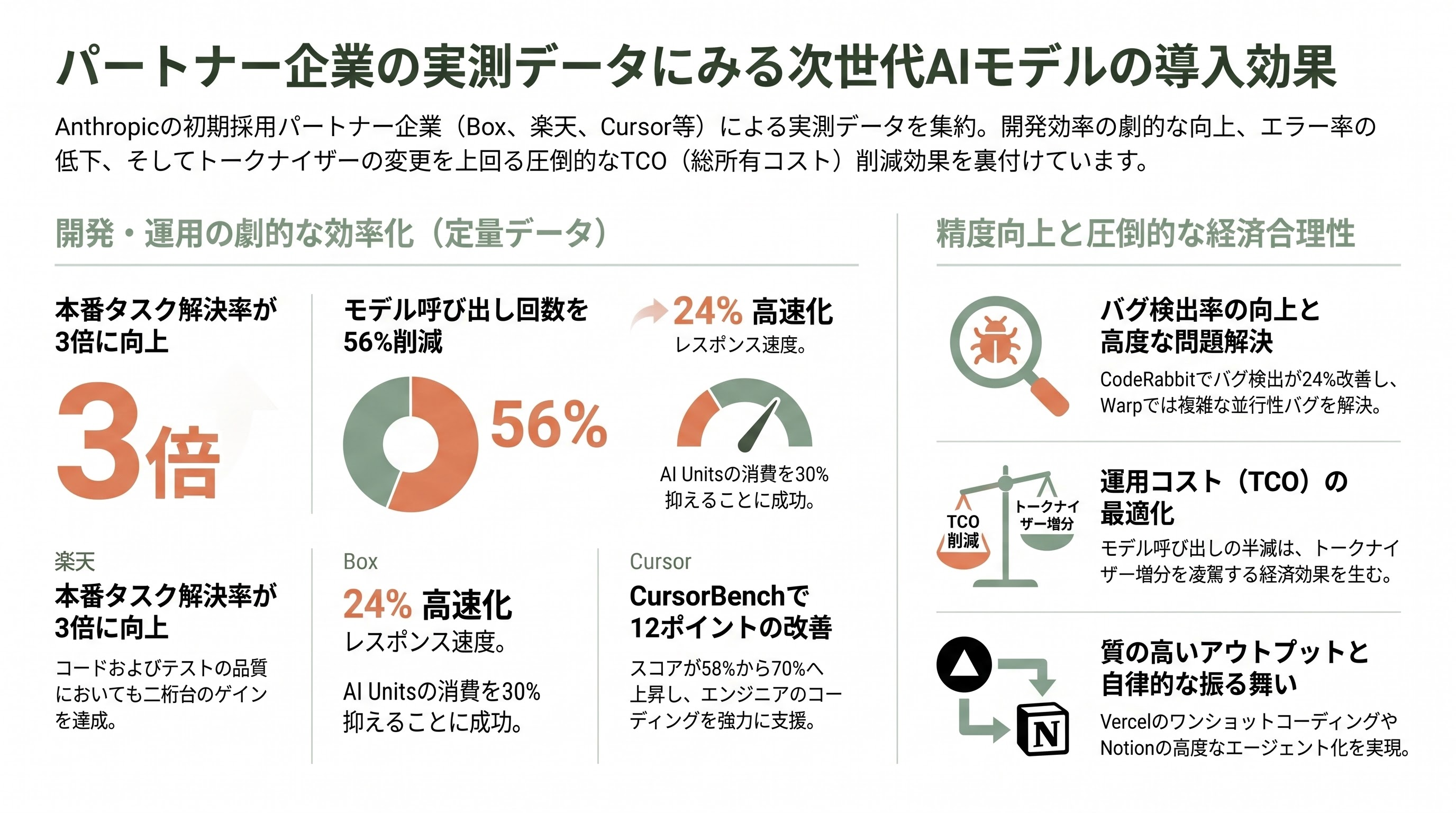
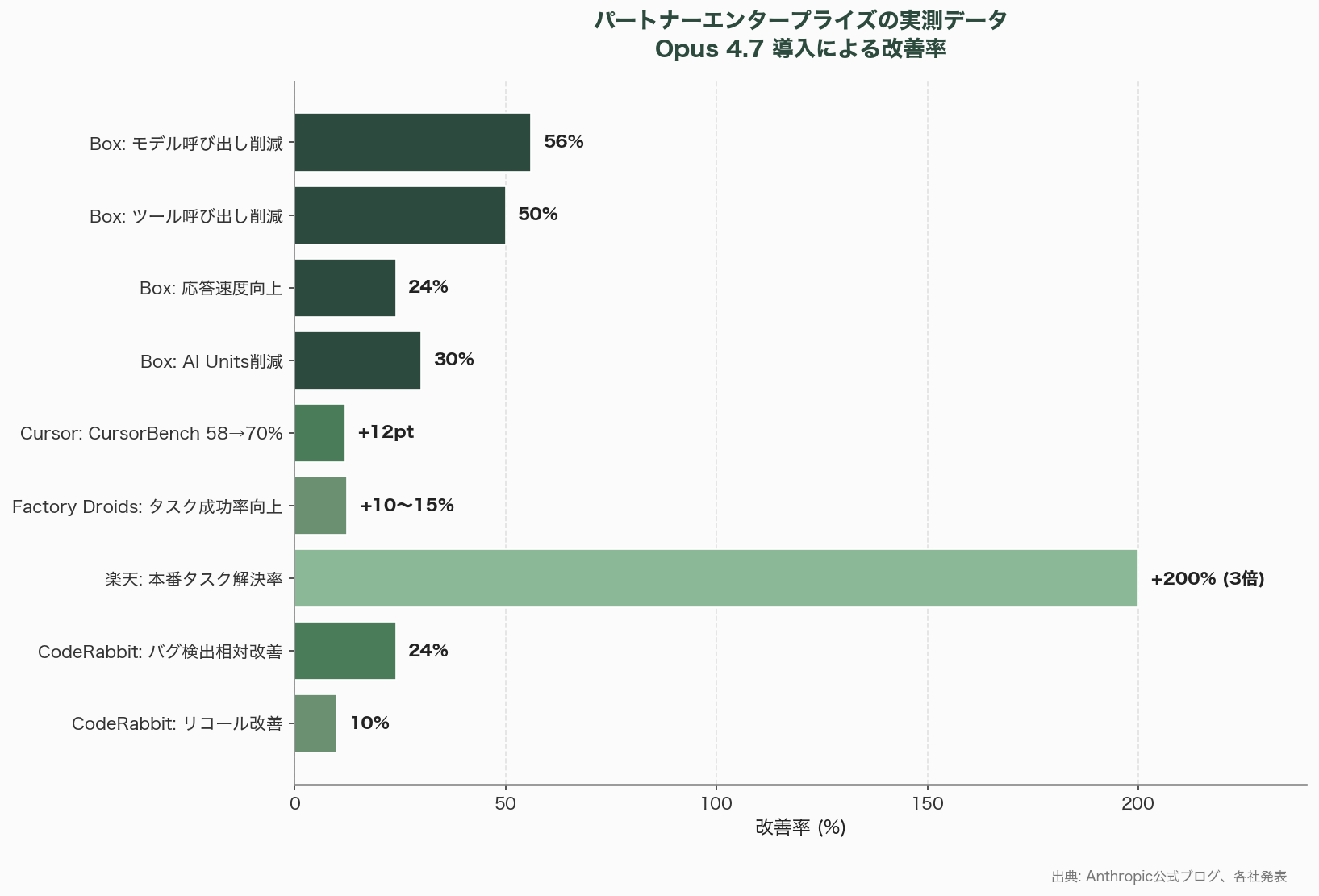
Anthropicの公式ブログおよび各社の発表から、初期採用エンタープライズの定量データを以下にまとめる。
- CodeRabbit: 「最もシャープなモデル」、リコール10%以上改善、バグ検出24%相対改善
- Warp: 「Opus 4.6で解けなかった並行性バグを解決」「計測可能に徹底的」
- Factory Droids: タスク成功率10-15%上昇、ツール呼び出しエラー減少、「中途半端に止まらない」
- Cursor: CursorBench 58% → 70%(12ポイント改善)
- Vercel: 「ワンショットコーディングで驚異的」「システムコードの事前証明を行う新しい振る舞い」
- Box(Yashodha Bhavnani AI責任者): モデル呼び出し56%削減、ツール呼び出し50%削減、応答24%高速化、AI Units 30%削減
- Notion: 「Notion Agentが真のチームメイトのように感じる」
- Rakuten(楽天): 本番タスク解決率3倍、Code Quality・Test Qualityで二桁ゲイン
- Hebbia: RAG、スライド生成、文書生成のエージェント意思決定が改善
Boxの数値は特に示唆に富む。同じ性能を達成しながらモデル呼び出しが半減以下になるということは、エンタープライズTCO(総所有コスト)の観点ではトークナイザー1.35倍増を凌駕する経済効果が期待できるということだ。
シリコンバレーVCの受け止め——「800BをAIチャンピオンへの入場券と見るか、狂気と見るか」
Opus 4.7のリリースは、VCコミュニティにとっても重大な評価イベントであった。
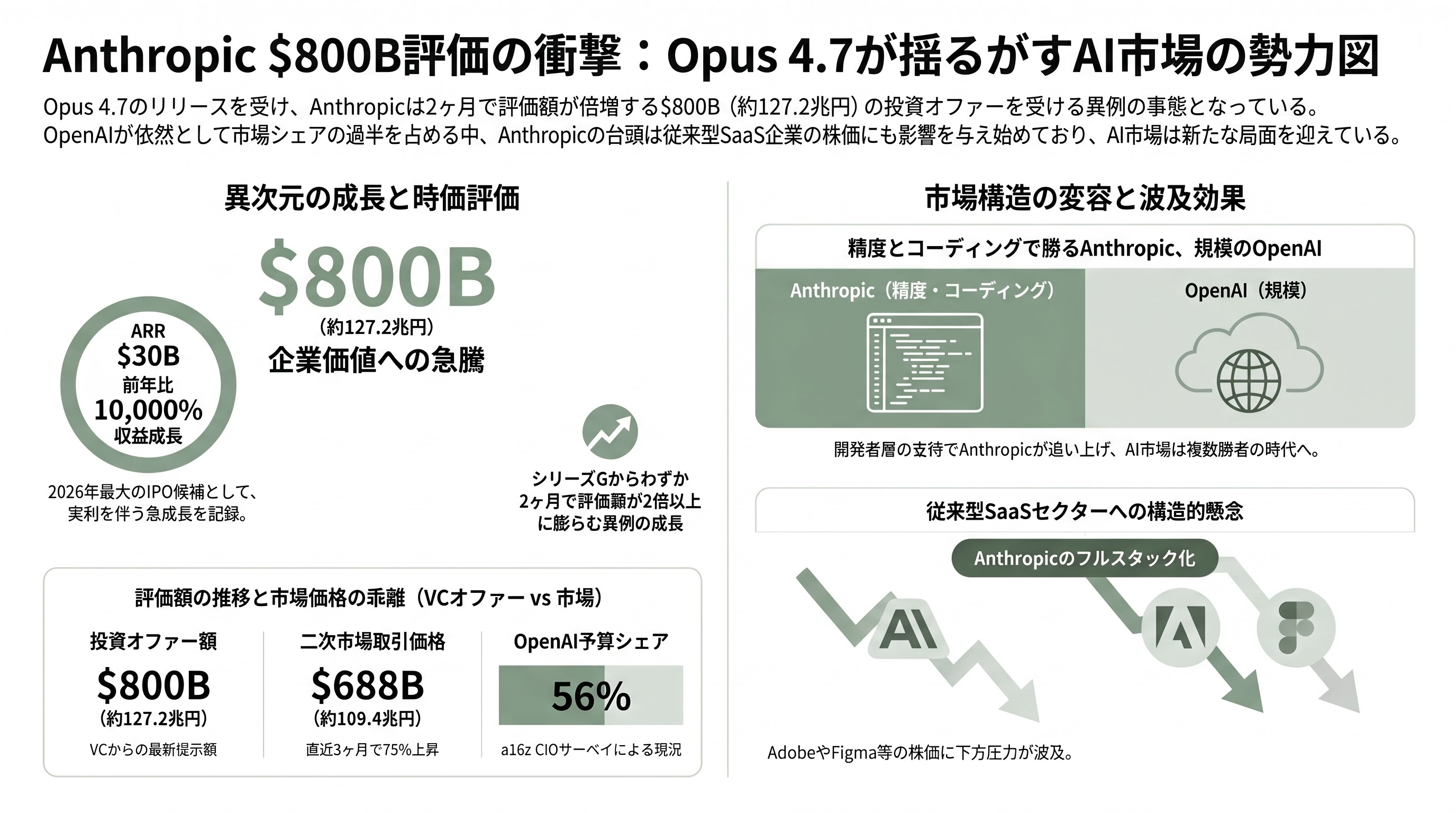
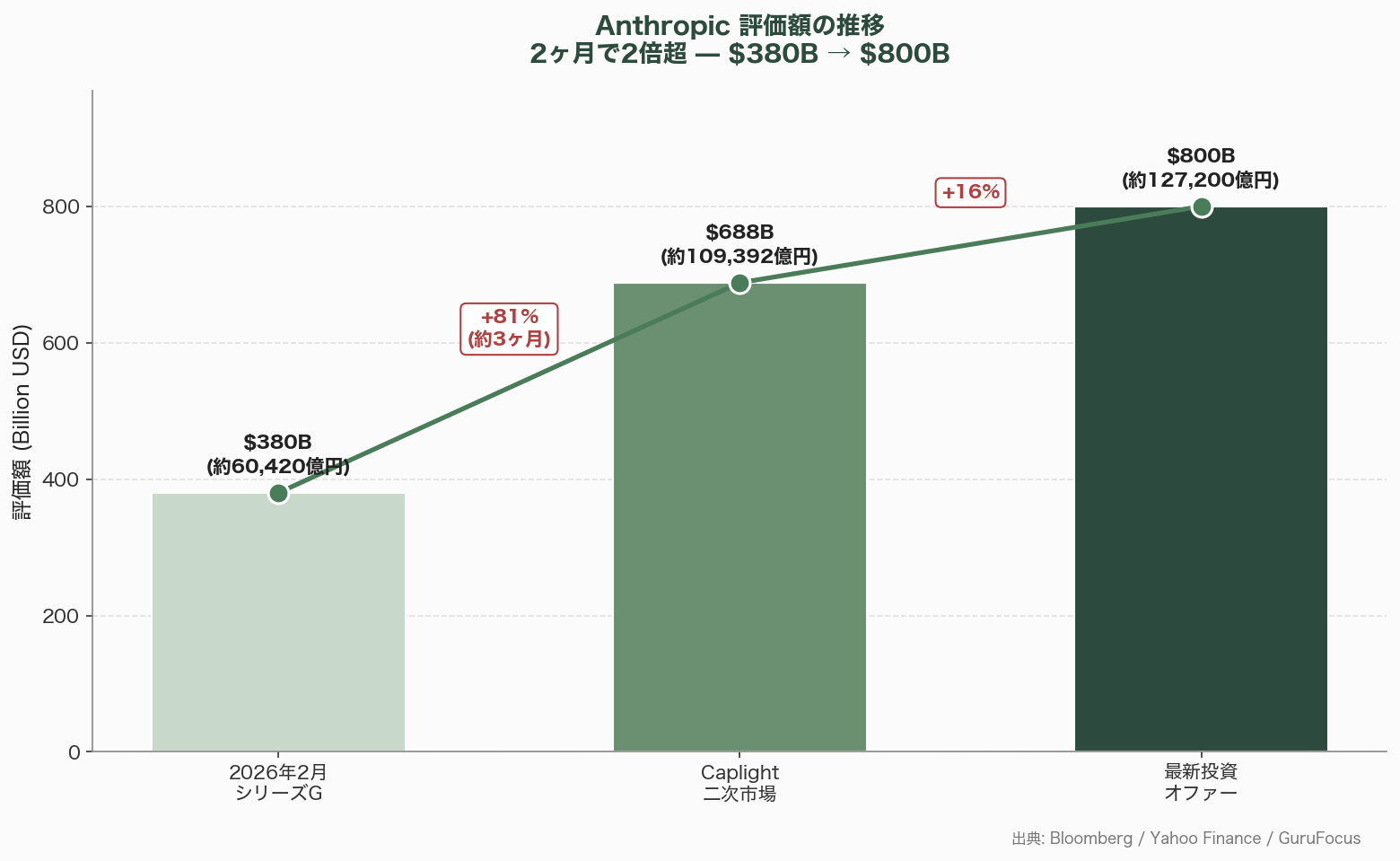
$800B評価オファーの意味
Bloomberg、Yahoo Finance、GuruFocus の報道によれば、AnthropicにはOpus 4.7リリースと並行して$800B(約127兆2,000億円)の評価額での投資オファーが複数VCから寄せられている。2026年2月のシリーズG($380B=約60兆4,200億円)から2ヶ月で2倍超という膨張ペースは、テック史上でも極めて異例である。二次市場Caplightでは$688B(約109兆3,900億円)が実質取引価格となっており、3ヶ月で75%の上昇を記録している。
これらの数字の背景には、同社のARR $30B(約4兆7,700億円)という実績がある。InvestorPlaceは「前年比10,000%の収益成長率」と評し、「2026年最大のIPO候補」と位置付けている。
Altimeterの冷静な視点
Altimeter CapitalのBrad Gerstner氏は4月16日前後に「OpenAIへのFUDはピークに達した」「OpenAIを排除するのは愚かだ」と発言し、Anthropicへの一極集中的な見方に釘を刺した。同氏は「AI市場は非ゼロサム。複数の勝者に十分な余地がある」と主張し、OpenAIのSpud(未公開モデル)が「Mythosに匹敵する」と期待を示した。
シリコンバレーVCの主流派は、Opus 4.7リリースを「Anthropicの勢いを裏付ける材料」としつつも、$800B評価の受け入れには慎重である。Anthropic自身も「現時点では」オファーを保留しており、評価額は「IPO前のさらなる事業成長」を待つ姿勢と解釈されている。
a16z CIOサーベイの示すもの
a16zが実施したCIOサーベイでは、OpenAIのwallet share(AI予算シェア)が依然として56%と過半を占めている。ただしAnthropicとGeminiが着実に侵食しており、2026年はそのシフトが加速するとの見通しが示された。「精度とコーディング能力を重視する開発者・ライターの層でAnthropicが勝ち、消費者規模と分配力でOpenAI・Googleが押さえる」という棲み分けが、Opus 4.7リリース後も基本構造として維持されるという分析が主流である。
関連銘柄への波及
Opus 4.7リリース直後の株式市場では、Adobe、Figma、Wixが各々2%以上下落した。これは、前日のリーク報道が株価に織り込まれていた影響もあるが、「AIデザインツール『Project Prism』とセットでAnthropicがフルスタックAIスタジオへ転換する」シナリオが投資家の警戒材料となっていることを示している。S&P 500 Software & Services Indexは2026年に入って約26%下落しており、従来型SaaSへの構造的な懸念がセクター全体を重しにしている。
メディア各紙の論調分析

- VentureBeat: 「Claude Opus 4.7、最強の一般公開LLMの座を僅差で奪還」——技術的勝利を明確に評価
- Axios: 「未公開のMythosに及ばないことを認めた」——Anthropicの自制的メッセージングを強調
- CNBC: 「Mythosよりリスクが低いAIモデル」——安全性×商用バランスを主軸に報道
- Gizmodo: 「MythosがいかにすごいかをみんなにリマインドするためにOpus 4.7をリリース」——皮肉交じりの論評
- TheNextWeb: 「SWE-benchとエージェント推論でGPT-5.4とGemini 3.1 Proを凌駕」——ベンチマーク優位性を強調
- The Decoder: 「コーディングの飛躍とサイバー能力の意図的な削減」——セキュリティの視点
- Help Net Security: 「自動サイバーセキュリティ・セーフガード搭載」——セキュリティ業界向けの実務解説
- LessWrong: 「Opus 4.7はMythosの存在感を際立たせるための踏み台かもしれない」——AI安全性コミュニティの鋭い指摘
- 9to5Mac: 「先進的ソフトウェアエンジニアリングにフォーカス」——Appleエコシステム視点
- TechCrunch: 「VCから$800B+評価オファー、Anthropicは保留」——資金調達の文脈
- Bloomberg: 「$800B評価で投資家オファーを引き付ける」——投資家視点
- PYMNTS.com: 「Anthropicのデザインツール、AdobeとFigmaに肉薄」——金融メディア視点
全体として、テック専門メディアは技術的改善を肯定的に評価しつつ、「Mythosに及ばない」という自己制限的な位置付けに注目。金融・投資メディアは$800B評価とIPO見通しに焦点を当て、シリコンバレーの「フルスタックAIカンパニー」への構造転換シナリオを論じる傾向が強い。
Hacker Newsで観測されたエンジニアの本音
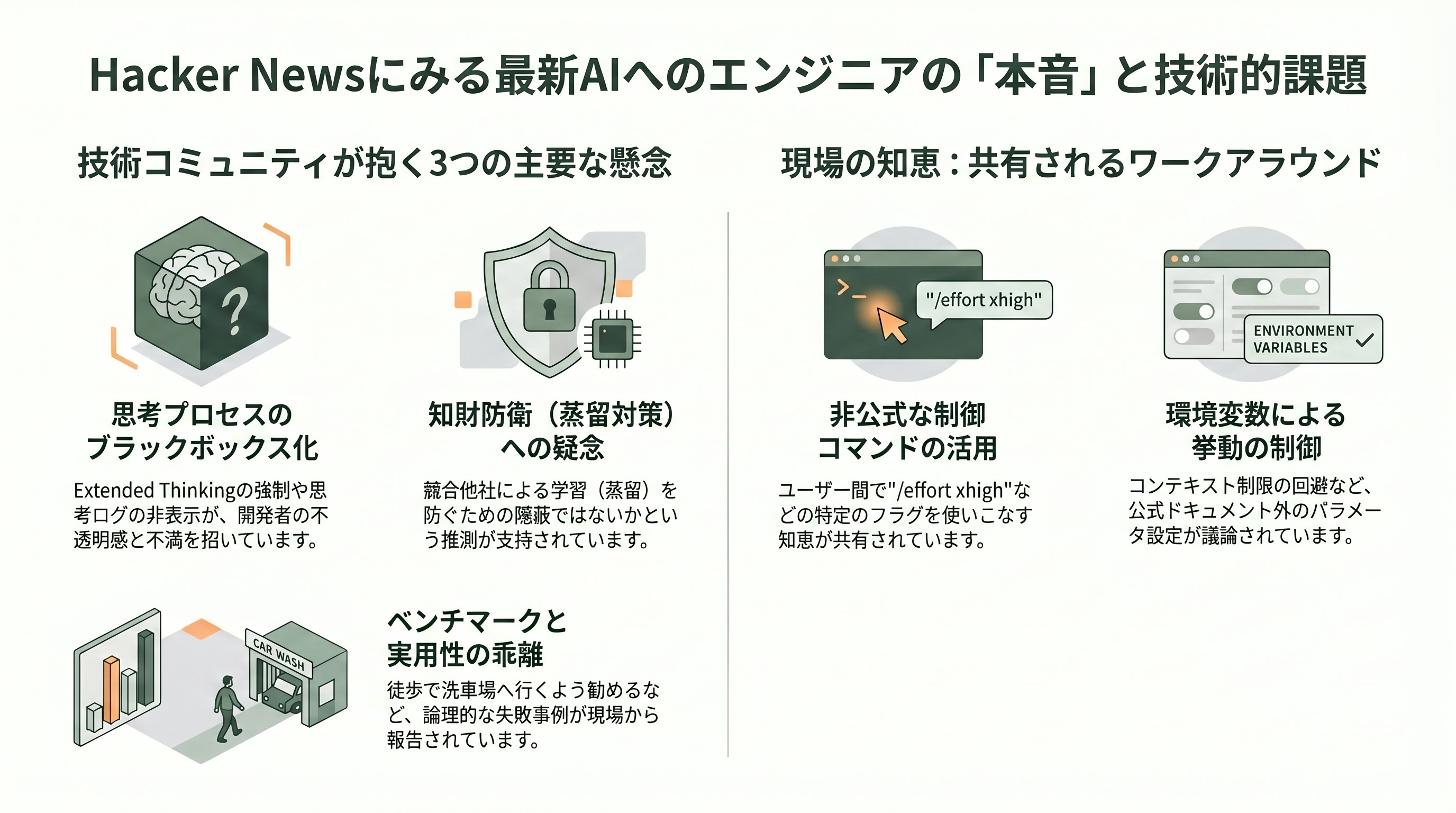
Hacker News スレッド47793411では、以下の論点が技術者コミュニティで活発に議論されている。
1. Adaptive Thinkingの不透明性: 「思考すべき場面で思考しない」という報告が複数。「Extended Thinkingを無効化できなくなった」ことへの不満が根強い。
2. 思考内容の非表示: 「APIを使っているのに、なぜチェーンオブソートが隠されるのか。これは初期のAnthropicの透明性コミットメントに反するのではないか」という批判。
3. ワークアラウンドの共有: "display": "summarized"、CLAUDE_CODE_DISABLE_1M_CONTEXT=1、/effort xhigh などのTipsが投稿され、公式ドキュメントに載らない知見がコミュニティで共有されている。
4. ロジック失敗の報告: 「車洗浄施設まで徒歩で行くよう勧められた」といった具体的な失敗事例も共有され、「ベンチマークスコアと現場感の乖離」への警戒感が表明されている。
5. 競合蒸留対策説: 「推論の非表示は、競合モデルによる蒸留(distillation)を防ぐための知財防衛ではないか」という推測が強く支持されている。
今後のロードマップ——いつ、何が動くか
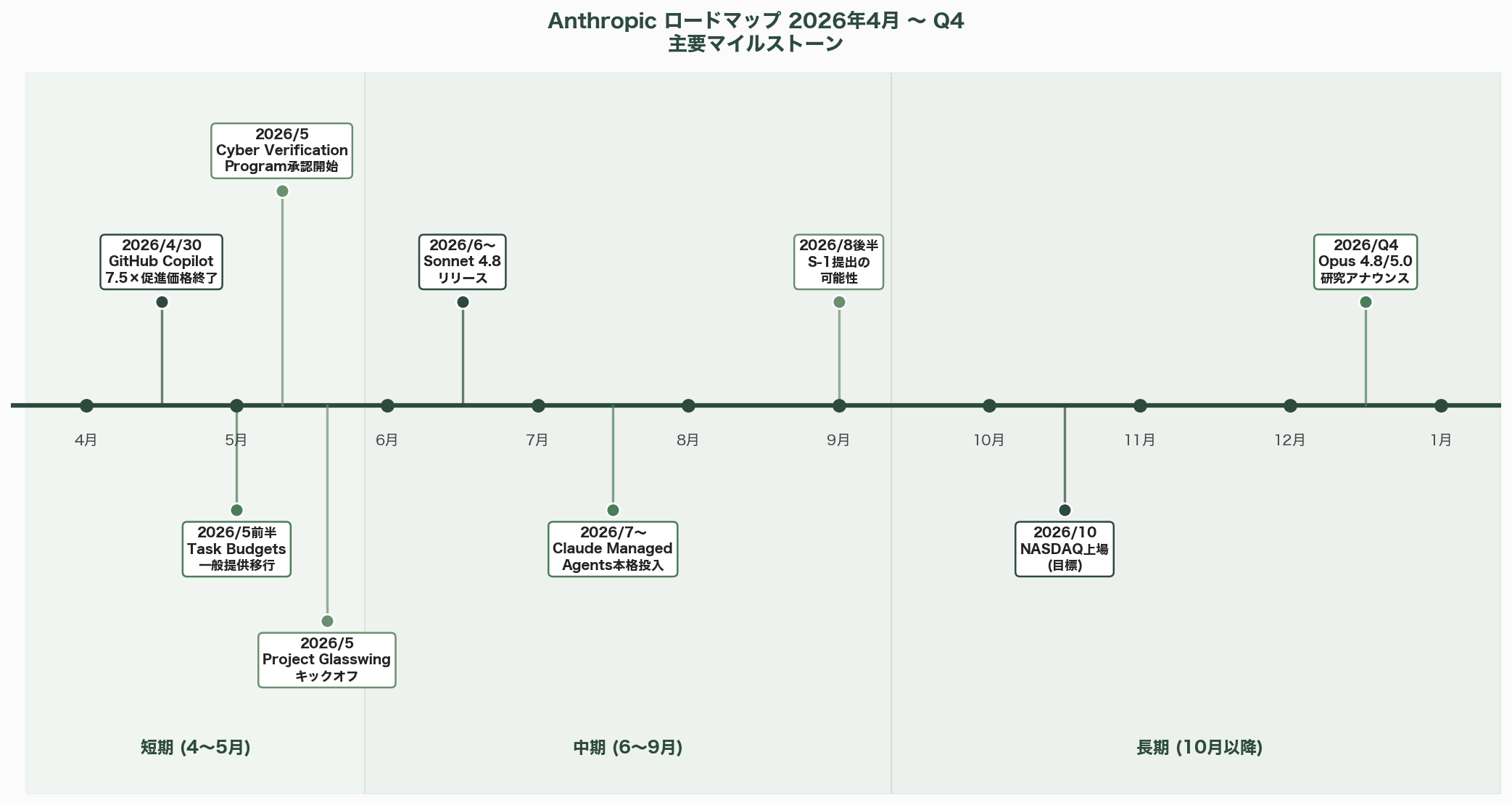
Anthropicの公式発表と各種報道から、今後の主要マイルストーンを整理する。
短期(2026年4〜5月)
- 4月30日: GitHub Copilotの7.5×促進価格終了。以降はペナルティ価格または再設定の可能性
- 5月前半: Task Budgetsが公開ベータから一般提供へ移行する可能性(Anthropic社員のほのめかしあり)
- 5月内: Cyber Verification Programの初期承認バッチが配布開始
- 5月: Project Glasswingの公式キックオフ、Mythos Previewのパートナー展開本格化
中期(2026年6〜9月)
- 6月〜: Sonnet 4.8のリリース(npmリークで確認済みのコードネーム)。Opus 4.7のコストパフォーマンス対応版として期待
- 7月〜: Opus 4.7ベースのClaude Managed Agentsの本格投入とエンタープライズ顧客実績の開示
- 8月後半: AnthropicのS-1提出の可能性
長期(2026年10月以降)
- 10月: AnthropicのNASDAQ上場(Goldman Sachs、JPMorgan、Morgan Stanleyが引受主幹事候補)
- Q4: Opus 4.8またはOpus 5.0に向けた研究アナウンス(Mythos Previewの一部能力の一般公開モデルへの移植可能性)
Dario Amodei CEOが繰り返し述べる「データセンター内の天才国家」ビジョンのタイムラインは2026〜2027年である。Opus 4.7は「商業フラグシップ」として、Mythosへの橋渡しの役割を担う存在と位置付けられる。
結論——Opus 4.7は「マイナーバージョン」の皮をかぶった大改訂
Claude Opus 4.7は、バージョン番号の「0.1アップ」というマイナー性を装いながら、実態としてはAPI互換性の破壊、トークナイザー変更、推論アーキテクチャの刷新(Adaptive Thinking強制)、ビジョン能力の3倍化、新推論レベルxhigh、新パラメータtask_budgetなど、エンジニアリング観点では極めて大きな変更を含む。
シリコンバレーのテックエンジニアにとって、このリリースが突きつける課題は3つに整理できる。
1. 移行コスト: API互換性の破壊により、既存コードベースのリファクタが必要。特にtemperature、top_pの依存除去、Extended Thinkingの排除、思考表示のオプトイン化。
2. コスト再評価: トークナイザー1.35倍増とGitHub Copilot 7.5×multiplierという「見えないコスト上昇」を踏まえた、プロンプトキャッシュやSonnet併用の再設計。
3. プロンプト再チューニング: 「より文字通りの指示追従」に合わせた明示化、旧scaffoldingの除去、xhighデフォルト前提でのプロンプト設計。
一方で、CodeRabbit、Warp、Cursor、Box、Notion、楽天といった初期採用パートナーの定量データは、Opus 4.7が単なるスコアの上積みではなく、本番ワークフローで実質的な品質改善・コスト削減・開発者体験向上を同時に達成しうる、数少ないモデルアップグレードであることを裏付けている。
「Opus 4.7は Mythos の踏み台」という見方もあるが、シリコンバレーの日々のエンジニアリング現場においては、これが当面のフラグシップとして君臨することになる。問題は「使うか使わないか」ではなく、「いつ、どのように、どんな再設計と共に、プロダクションに組み込むか」——その判断の質が、2026年下半期のAIネイティブ・プロダクトの競争力を左右する。
結論——Opus 4.7は「マイナーバージョン」の皮をかぶった大改訂
Claude Opus 4.7は、バージョン番号の「0.1アップ」というマイナー性を装いながら、実態としてはAPI互換性の破壊、トークナイザー変更、推論アーキテクチャの刷新(Adaptive Thinking強制)、ビジョン能力の3倍化、新推論レベルxhigh、新パラメータtask_budgetなど、エンジニアリング観点では極めて大きな変更を含む。
シリコンバレーのテックエンジニアにとって、このリリースが突きつける課題は3つに整理できる。
1. 移行コスト: API互換性の破壊により、既存コードベースのリファクタが必要。特にtemperature、top_pの依存除去、Extended Thinkingの排除、思考表示のオプトイン化。
2. コスト再評価: トークナイザー1.35倍増とGitHub Copilot 7.5×multiplierという「見えないコスト上昇」を踏まえた、プロンプトキャッシュやSonnet併用の再設計。
3. プロンプト再チューニング: 「より文字通りの指示追従」に合わせた明示化、旧scaffoldingの除去、xhighデフォルト前提でのプロンプト設計。
一方で、CodeRabbit、Warp、Cursor、Box、Notion、楽天といった初期採用パートナーの定量データは、Opus 4.7が単なるスコアの上積みではなく、本番ワークフローで実質的な品質改善・コスト削減・開発者体験向上を同時に達成しうる、数少ないモデルアップグレードであることを裏付けている。
「Opus 4.7は Mythos の踏み台」という見方もあるが、シリコンバレーの日々のエンジニアリング現場においては、これが当面のフラグシップとして君臨することになる。問題は「使うか使わないか」ではなく、「いつ、どのように、どんな再設計と共に、プロダクションに組み込むか」——その判断の質が、2026年下半期のAIネイティブ・プロダクトの競争力を左右する。
Sources
- Introducing Claude Opus 4.7 — Anthropic
- What's new in Claude Opus 4.7 — Claude API Docs
- Best practices for using Claude Opus 4.7 with Claude Code — Claude
- Introducing Anthropic's Claude Opus 4.7 model in Amazon Bedrock — AWS
- Claude Opus 4.7 is now available in Amazon Bedrock — AWS What's New
- Announcing Claude Opus 4.7 on Snowflake Cortex AI — Snowflake
- Claude Opus 4.7 on Vertex AI — Google Cloud
- Claude Opus 4.7 is available on Microsoft Foundry — Microsoft
- Claude Opus 4.7 is generally available — GitHub Changelog
- Claude 4.7 Opus — Cursor Docs
- Boris Cherny on X (Opus 4.7 in Claude Code)
- Boris Cherny on X (Configure your effort level)
- Anthropic releases Claude Opus 4.7, narrowly retaking lead — VentureBeat
- Claude Opus 4.7 leads on SWE-bench and agentic reasoning — The Next Web
- Anthropic rolls out Claude Opus 4.7, an AI model that is less risky than Mythos — CNBC
- Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos — Axios
- Claude Opus 4.7 makes a big leap in coding, while deliberately scaling back cyber capabilities — The Decoder
- Anthropic releases Claude Opus 4.7 with automated cybersecurity safeguards — Help Net Security
- Anthropic Releases Opus 4.7 — LessWrong
- Claude Opus 4.7 Hacker News Discussion
- Anthropic's Claude Opus 4.7 Released: All You Need to Know — FelloAI
- What Claude Opus 4.7 means for AI code review — CodeRabbit
- Claude Opus 4.7 Pricing: The Real Cost Story — Finout
- Claude Opus 4.7 Developer Guide — NxCode
- Claude Opus 4.7: Benchmarks, Vision, xhigh Effort & Migration Guide — Lushbinary
- Claude Opus 4.7 Just Dropped. I Tested It For 6 Hours Straight — Dev.to
- Claude Opus 4.7 Benchmarks Explained — Vellum AI
- Anthropic Attracts Investor Offers at an $800 Billion Valuation — Bloomberg / Yahoo Finance
- Altimeter's Brad Gerstner Says 'Peak OpenAI FUD' Is Here — CapitalAI Daily
- Anthropic's Claude Opus 4.7 Now Available on GitHub Copilot with 7.5x Premium Multiplier — BotBeat
- Anthropic launches Claude Opus 4.7 with enhanced coding capabilities — Investing.com
- Anthropic reveals new Opus 4.7 model with focus on advanced software engineering — 9to5Mac
- Anthropic Releases Claude Opus 4.7 to Remind Everyone How Great Mythos Is — Gizmodo
- Claude Opus 4.7: Benchmarks, Pricing, Context & What's New — LLM-Stats