Open-VLA
1. サービス概要
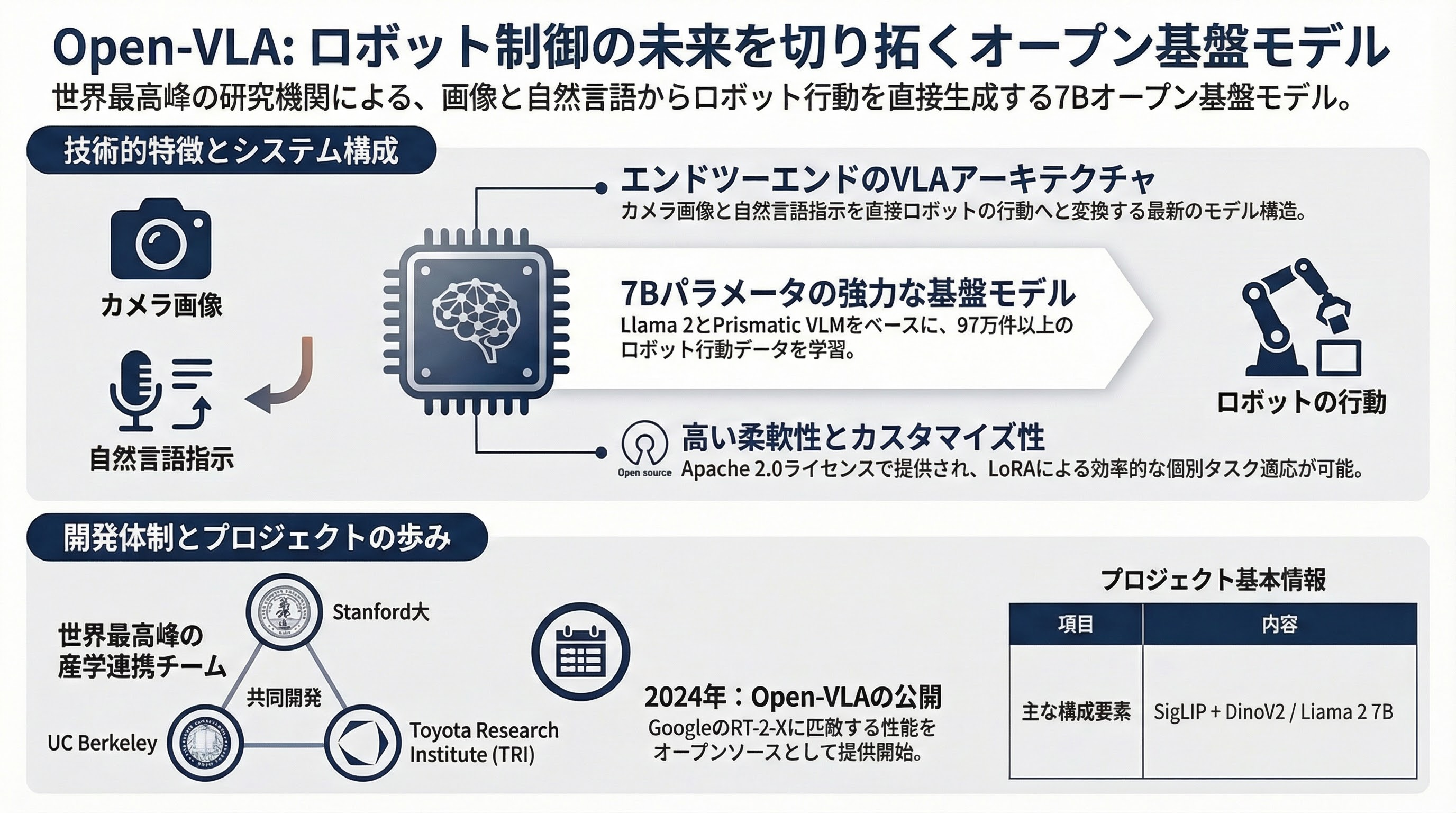
Open-VLA(Open Vision-Language-Action Model)は、ロボット制御のためのオープンソースのVision-Language-Action(VLA)モデルである。Stanford大学、UC Berkeley、Toyota Research Institute(TRI)の研究者らにより開発された。7Bパラメータの大規模モデルであり、Prismatic VLM(Vision-Language Model)をベースにファインチューニングされている。カメラ画像と自然言語の指示を入力として受け取り、ロボットの行動(アクション)を直接出力するエンドツーエンドのモデルアーキテクチャを採用している。Open X-Embodimentデータセットを用いた大規模な学習により、多様なロボットプラットフォームやタスクに対する汎化能力を実現している。Apache 2.0ライセンスで公開されており、研究・商用利用の両方が可能である。
2. 使用している技術スタック
- モデルアーキテクチャ: Vision-Language-Action(VLA)モデル。7Bパラメータ
- ベースモデル: Prismatic VLM(視覚言語モデル)をベースにロボット行動出力層を追加
- 視覚エンコーダ: SigLIP + DinoV2のデュアルビジョンエンコーダ
- 言語モデル: Llama 2 7Bベース
- 学習データ: Open X-Embodimentデータセット(970K以上のロボットエピソード)
- 学習手法: 教師あり学習(行動クローニング)。LoRAによる効率的なファインチューニングにも対応
- フレームワーク: PyTorch、Hugging Face Transformers
- ライセンス: Apache 2.0
- リポジトリ: github.com/openvla/openvla
3. 会社概要
| 項目 | 内容 |
|---|---|
| プロジェクト名 | Open-VLA(Open Vision-Language-Action) |
| 開発元 | Stanford大学、UC Berkeley、Toyota Research Institute |
| 主要研究者 | Moo Jin Kim、Chelsea Finn、Sergey Levine、Dorsa Sadigh |
| ライセンス | Apache 2.0 |
| カテゴリ | オープンソースロボット基盤モデル |
| モデルサイズ | 7Bパラメータ |
4. 沿革、資本構成、国籍、役員情報
沿革
- 2023年: Open X-Embodimentプロジェクトが公開。Google DeepMind主導で世界中のロボティクス研究所からロボットデータを集約した大規模データセットが構築される。RT-2-Xモデルが発表される
- 2024年: Open-VLAが発表・公開。Prismatic VLMベースのオープンソースVLAモデルとして、RT-2-Xに匹敵する性能をオープンに提供
- 2024年: Hugging Face Hub上でモデルウェイトを公開。研究コミュニティでの利用が拡大
- 2024年: LoRAベースの効率的なファインチューニング手法を提供し、個別タスクへの適応を容易化
研究機関の概要
- Stanford大学: AI研究の世界的拠点。Stanford AI Lab(SAIL)、Stanford Vision & Learning Lab(SVL)を中心にロボット学習研究を推進
- UC Berkeley: Berkeley AI Research Lab(BAIR)が世界有数のロボティクス・AI研究を展開
- Toyota Research Institute(TRI): トヨタ自動車の米国AI研究所。2015年設立。ロボティクス・自動運転の研究開発に注力。年間約10億ドルの研究予算
主要研究者
- Moo Jin Kim(筆頭著者): Stanford大学博士課程。ロボット基盤モデルの研究
- Chelsea Finn(共著者): Stanford大学助教。メタラーニング・ロボット学習の第一人者。Physical Intelligenceの共同創業者でもある
- Sergey Levine(共著者): UC Berkeley教授。強化学習・ロボット学習の世界的権威
- Dorsa Sadigh(共著者): Stanford大学助教。人間-ロボットインタラクション・ロボット学習の研究者