ニュースの全体像:5月5日、Googleが「先読み」を標準装備に格上げした
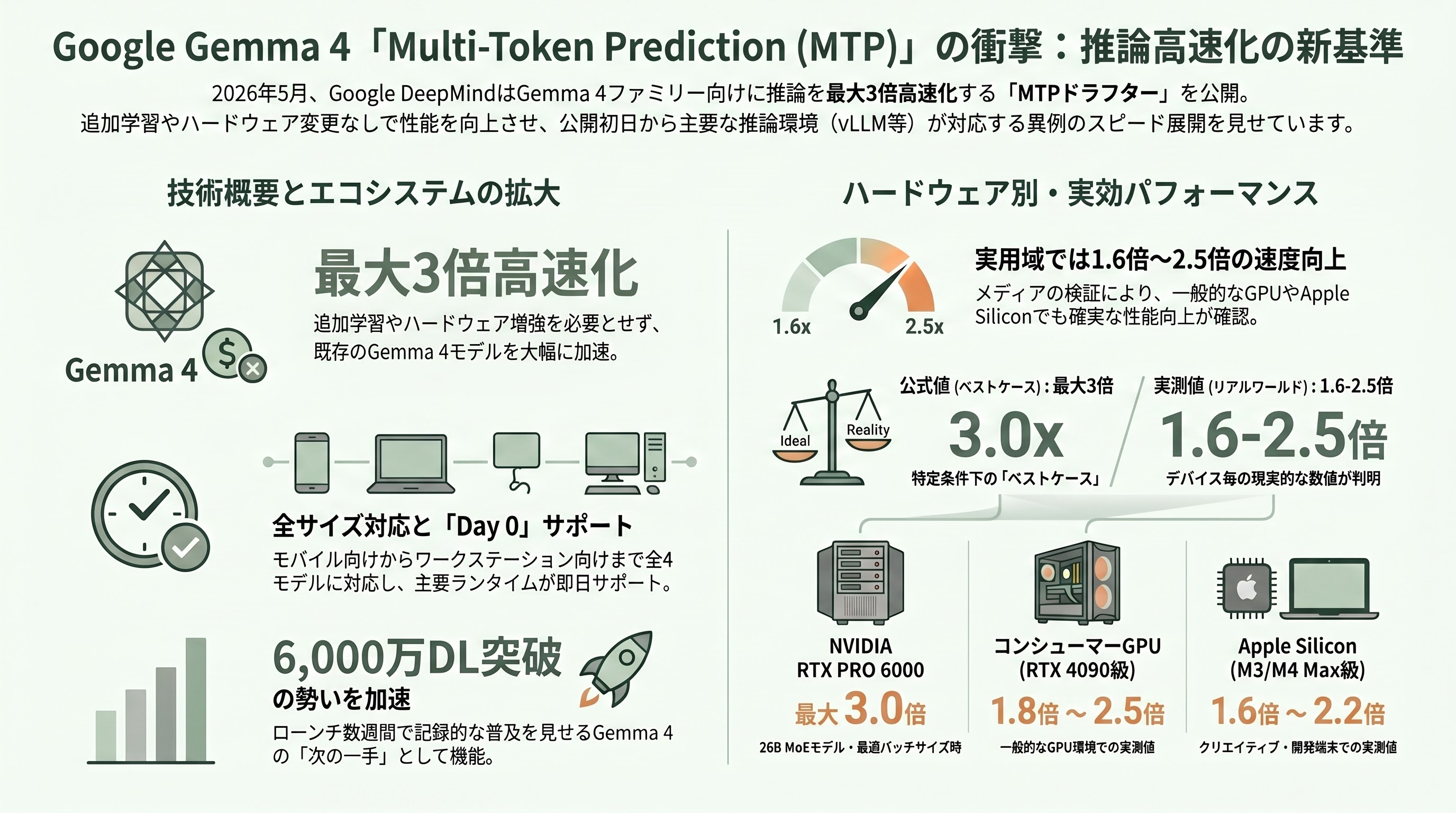
2026年5月5日、Google DeepMindは公式ブログ「Accelerating Gemma 4: faster inference with multi-token prediction drafters」を通じて、Gemma 4ファミリー向けの「Multi-Token Prediction(MTP)ドラフター」をリリースした。Gemma 4は同年4月2日にGoogle Open Source Blogで「Gemma 4: Expanding the Gemmaverse with Apache 2.0」として公開され、ローンチからわずか数週間で6000万ダウンロードを突破した、いま最も勢いのあるオープンウェイトLLMである。MTPはその「次の一手」として、追加学習なし・追加ハードなしで、すでに走っているGemma 4を最大3倍高速化させる役回りを担う。
公開された補助モデル群は、Gemma 4の4サイズ(モバイル向けE2B、エッジ向けE4B、コンシューマーGPU向けの26B A4B Mixture-of-Experts、ワークステーション向けの31B Dense)すべてに対応する。Hugging Face、Kaggleで配布が始まり、Hugging Face Transformers、MLX、vLLM、SGLang、Ollama、Google AI Edge GalleryのLiteRT-LMといった主要推論ランタイムが「Day 0」でサポート済みだ。Google公式リリースに対しては、vLLMが公式X上で「🚀 Day-0 MTP support for Gemma4 now available at vLLM」と告知し、HopperおよびBlackwell向け専用Dockerイメージ(vllm/vllm-openai:gemma4-0505-cu129/cu130)を同時公開している。
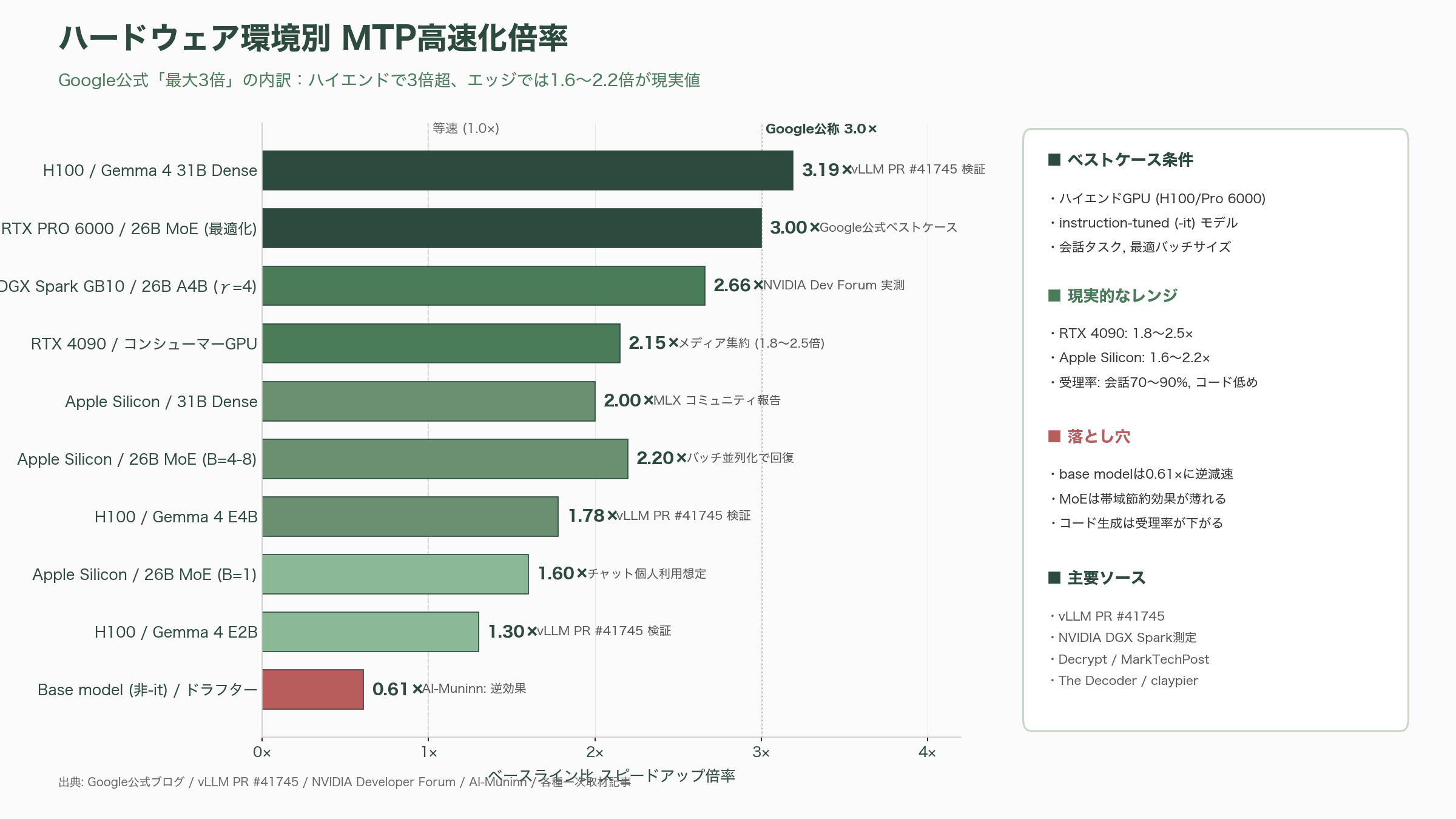
数字の見立てとしては、Googleは「最大3倍」を強調する一方、一次取材を行った海外メディアは現実的なレンジを慎重に伝えている。Decrypt、MarkTechPost、Eastern Herald、The Decoder、claypierといった媒体は、最大3倍はNVIDIA RTX PRO 6000上で26B MoEを最適バッチサイズ・会話タスクで回した「ベストケース」であり、コンシューマーGPU(RTX 4090級)では1.8〜2.5倍、Apple Silicon(M3 Max/M4 Max級)では1.6〜2.2倍といった、より地味だが実用的な数字に落ち着くと報じている。
「LLM版Ajax」と呼ぶ理由:先読みと検証で時間軸をひっくり返す
技術的な要点を、まず一段抽象化して説明しておきたい。なぜタイトルで「LLM版Ajax」と呼んだのか。Ajax(Asynchronous JavaScript and XML)は、ブラウザがページ全体の再読み込みを待つ代わりに、ユーザーが要求しそうな部分を非同期に先読み・部分更新してUXを変えた技術だった。MTPがLLM推論にもたらす本質的な変化はこれに似ている。すなわち、「ユーザーが本当に必要なトークンが何かを、上流の重いモデルが確定する前に、軽いモデルが先に何個か作っておく」というアプローチである。
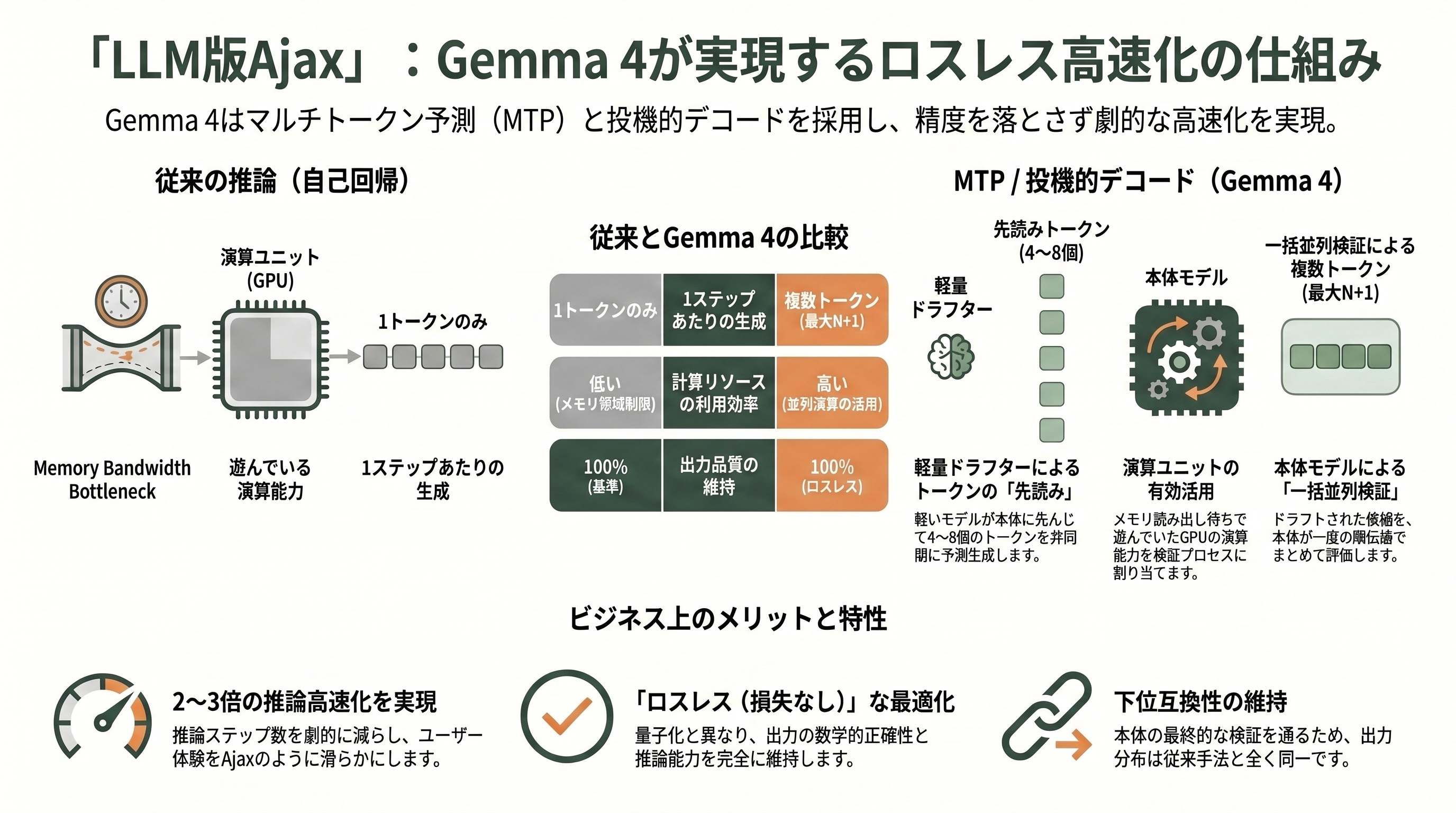
通常のTransformer推論は、自己回帰(autoregressive)と呼ばれる仕組みで、ひとつのトークンを出すごとに数十億〜数百億のパラメータをメモリから読み出している。GPUの演算ユニット自体は余裕があるのに、メモリ帯域がボトルネックとなって演算器が遊んでしまう。Google ResearchがYaniv Leviathan、Matan Kalman、Yossi Matiasらの名で2022年に発表した論文「Fast Inference from Transformers via Speculative Decoding」(ICML 2023採択)は、まさにこの観察から出発している。同論文はT5-XXL(11B)を60Mパラメータの小型T5でドラフトさせ、2〜3倍の高速化を「出力分布をいっさい変えずに」実現できることを示し、業界の標準的な高速化レイヤーとして定着した。
MTPはこの系譜の最新形だ。Gemma 4のMTPドラフターは「Q-only attention」で構成された軽量4層モデルで、ターゲットモデル(本体)のKVキャッシュを共有するという大きな工夫がなされている。具体的なメカニズムは次のように動く。まずドラフターが、本体の最終層活性化と入力埋め込み表を共有しながら、未来のトークンをN個(典型的には4〜8個)連続で先読みする。そのN個をまとめて、本体のGemma 4が一度の順伝播で並列に検証する。本体が「自分の予測と一致する」と判断したトークンは丸ごと採用され、最初に食い違ったところでドラフトを切り捨てて、本体自身が正しいトークンをひとつ吐く(ここまでで最低1トークンは確実に得られるので無駄打ちにならない)。あとはまたドラフターが先読みを再開する、というサイクルを高速に回す。
実例に置き換えるとイメージしやすい。たとえば「東京の天気は」とプロンプトを与えると、ドラフターは「晴れ」「、明日は」「曇り」「のち雨」のような4トークンを先読みする。本体は本来なら4回フォワードパスを回す必要があったところを、1回のパスでこの4候補を一気に評価する。3トークンまで一致していれば、3トークン+本体自身の補正1トークン=合計4トークンが、ほぼ1ステップで確定する。これがGoogleの公式ブログにある「the target model accepts the entire sequence in a single forward pass — and even generates an additional token of its own in the process」(本体は一度の順伝播で連なりごと受理し、加えて自分のトークンを1つ生成する)という記述の意味するところだ。
注意したいのは、これは「精度を犠牲にした高速化」ではないという点である。本体が最終的な検証を必ず通すため、出力分布はMTPなしの場合と数学的に同一に保たれる。Hugging Faceの公式ブログ「Welcome Gemma 4」がはっきりと「Same outputs as target model with no quality loss and no changes to reasoning behavior」と書いている通り、これは「ロスレス(lossless)」な高速化レイヤーである点が、量子化や蒸留と決定的に異なる。
「ドラフターは何を見ているか」をもう少し噛み砕く
初学者にとって難しいのは、なぜ小さなドラフターが本体と同じ確率分布から「ほぼ正解」を引けるのか、という直感的な部分だろう。これには二つの実装上の鍵がある。
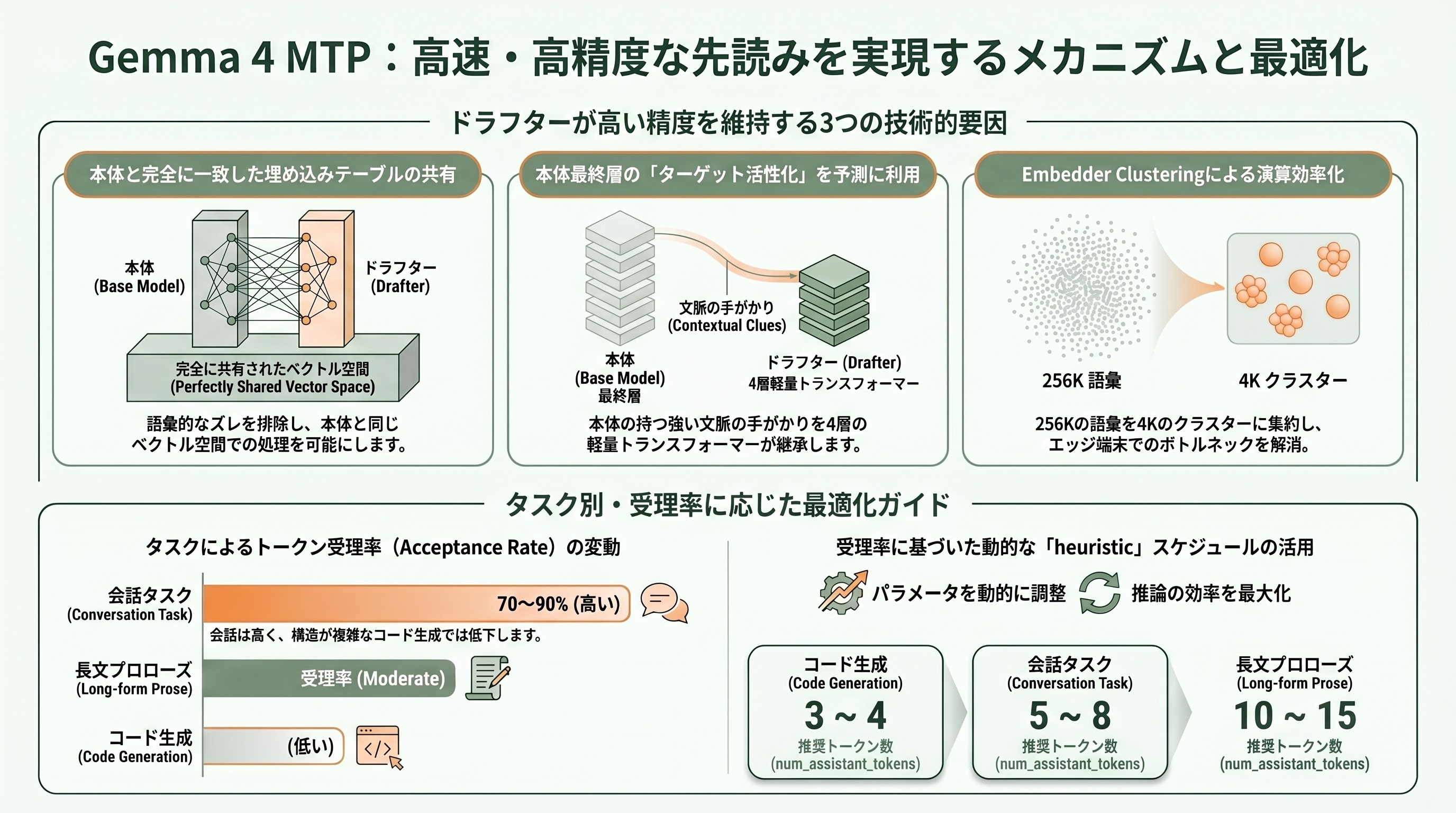
ひとつめは「埋め込みテーブルの共有」である。ドラフターはGemma 4本体と同じ入力埋め込みテーブルを参照する。「dog」「猫」「東京」といったトークンを、本体と全く同じベクトル空間で扱うため、語彙的なズレが原理的に発生しない。ふたつめは「ターゲット活性化の利用」だ。本体の最終層が出力した活性化ベクトルを、ドラフターは入力として受け取り、軽量な4層トランスフォーマーで未来Nトークン分の予測を作る。つまり、本体がすでに「次に何が来るか」についてかなり強い手がかりを持っており、ドラフターはその手がかりを受け継ぐ形で先読みを行うため、文脈的に外れにくい。
Gemma 4の場合、特にエッジ向けのE2B(実効2.3B)/E4B(実効4.5B)モデルでは、語彙256K個のうち、文脈的に「ありそうな」4K個のクラスターに絞り込む「embedder clustering」という工夫が追加で入る。これにより、スマートフォンのような限られたメモリ・演算でも、ドラフターのロジット計算がボトルネックにならない。Google AI for Developersのドキュメント「Speed-up Gemma 4 with Multi-Token Prediction」では、ドラフターが「the model groups similar tokens into clusters」(似たトークンをクラスターに束ねる)と記載されている。
トークン受理率(acceptance rate)も重要な指標である。buildfastwithai社の検証によれば、Gemma 4 MTPドラフターは会話タスクで70〜90%、コード生成タスクではそれより低めの値を示す。コードのほうがランダム性が低い一方で、長距離依存(数十トークン先のクロージャや構文)が多く、ドラフター単独では予測しきれない場面が増えるためだ。実際にvLLMでGemma 4 MTPを動かす際、推奨パラメータ「num_assistant_tokens」をコード用なら3〜4、会話用なら5〜8、長文プロローズ用なら10〜15に設定し、「heuristic」スケジュールで受理率に応じて動的調整する運用が、開発者ブログdasrootやkaitchupなどで紹介されている。
DeepSeek、Meta、EAGLEとの系譜:MTPは「次の主戦場」
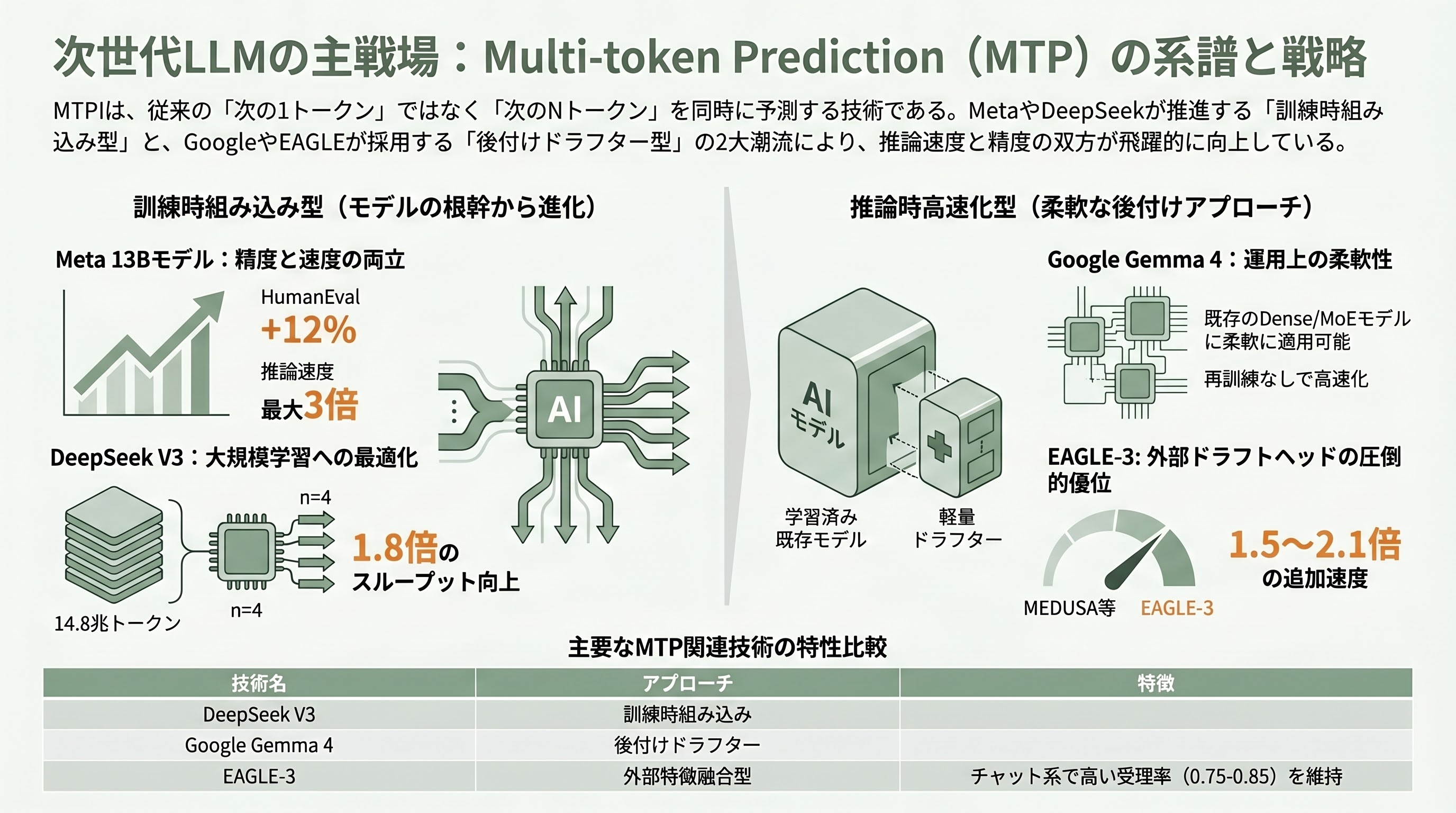
Google公式ブログにあるとおり、MTP的なアプローチは突発的なブレイクスルーではなく、累積した研究系譜の最新ステップに位置づけられる。Metaは2024年4月、Fabian Gloeckle、Badr Youbi Idrissi、Baptiste Rozière、David Lopez-Paz、Gabriel Synnaeveらの名で「Better & Faster Large Language Models via Multi-token Prediction」(arXiv:2404.19737)を公開し、訓練時に「次のNトークン」を独立した出力ヘッドで予測させることで、13Bモデルが既存の次トークン予測モデルよりHumanEvalで12%、MBPPで17%高いスコアを叩き出し、4トークン同時予測のモデルは推論で最大3倍速くなることを示した。DeepSeekは同社のV3でこのMTPを採用し、n=4の予測ヘッドで14.8兆トークンの事前学習を行い、推論時にはMTP1の受理率が80%を超えることで約1.8倍の生成スループット向上を実現していると、ArXivの技術レポートに記している。
訓練時にMTPを目的関数に組み込むDeepSeek型と、推論時にだけ補助ドラフターを足すGoogle型は、似た名前で呼ばれているがアプローチが異なる。Google Gemma 4の場合、本体のトレーニング自体は標準の次トークン予測で完結しており、後から軽量ドラフターを別途学習させて取り付ける形になっている。これにより、すでに学習済みの31B Denseや26B MoEに対しても、追加で訓練し直すことなく高速化を後付けできる、という運用上の柔軟性が大きい。
このほか、関連技術として、Tianle Caiらの「MEDUSA」(複数の予測ヘッドを本体に直接生やすアプローチ)、Yuhui Liらの「EAGLE-3」(早期・中間・後期の三層特徴を融合した外部ドラフトヘッド)、「Lookahead Decoding」(2Dウィンドウでn-gramを並列生成)などがある。SyncSoft.AIのブレンディング解説によれば、EAGLE-3はチャット系で受理率0.75〜0.85を維持し、MEDUSAやLookaheadに比べて1.7〜2.1倍、1.5〜1.6倍の追加速度を稼ぐとされる。実際、Gemma 4でも公式MTPリリース前にコミュニティが先行してEAGLE-3ドラフターを訓練しており、thoughtworks/Gemma-4-31B-Eagle3、RedHatAI/gemma-4-31B-it-speculator.eagle3として公開されている。Eastern Heraldとclaypierの記事は、Googleの今回の公式リリースが「Gemma 4の初回ウェイト公開時に削除されていたMTPヘッドを、ようやく公式の形でコミュニティに返した」位置づけだとも指摘している。
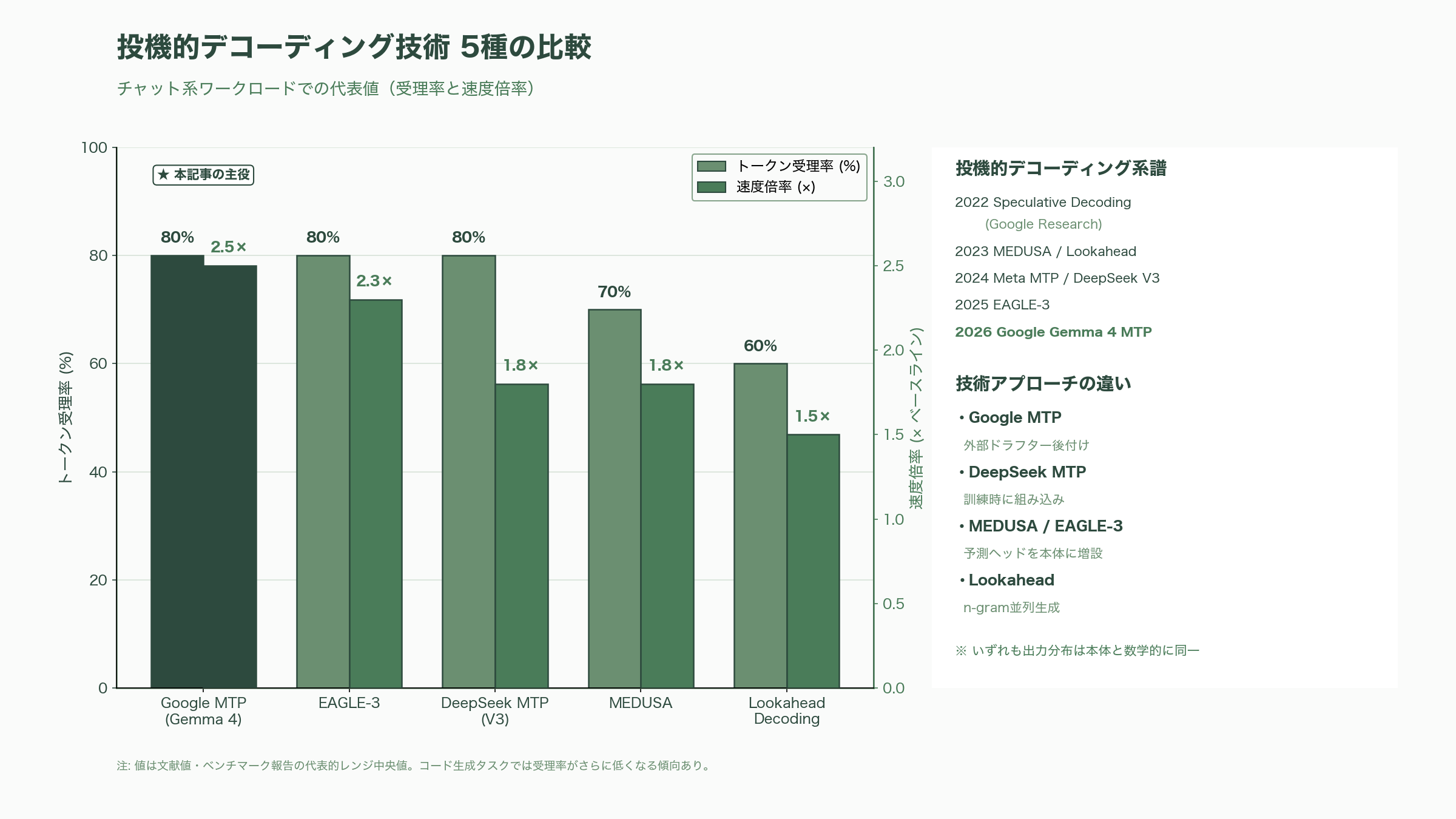
ベンチマークの読み解き:3倍はどこで、現実は何倍か

メディア各社が一斉に注目したのは、Googleが掲げる「最大3倍」という数字の妥当性である。この点については、複数のソースを突き合わせると比較的見通しが立ってきた。
ハイエンドのワークステーション環境では数字が良い。NVIDIA Developer Forumに投稿されたNVIDIA DGX Spark/GB10での測定では、Gemma 4 26B A4B-it(FP8量子化)にγ=4のMTPを組み合わせて、単一リクエストで108.78 tokens/sec(MTPなしのベースライン40.85 tokens/secに対して2.66倍)を記録。並行8リクエストでは集約スループット674 tokens/secと、個別ユーザー視点でも従来比約2倍を維持しながらサーバー全体としては16.5倍にスケールした、と報告されている。vLLM側のPR #41745(Luciano Martins氏起票、2026年5月6日マージ)の検証データでも、H100上でE2Bが130%、E4Bが178%、そして31B Denseが319%という大きなスループット改善が報告されている。
一方、ノートPCクラスやMacBookでの体感は、もう少し控えめだ。Decryptが触れているように、Apple Siliconでバッチサイズ1(つまり個人ユーザーのチャット用途)の場合は、Gemma 4 26B MoEは1.5〜1.7倍程度に留まる。これは、MoE(Mixture-of-Experts)アーキテクチャでトークンごとに異なるエキスパートが起動する設計上、ドラフターが先読みするトークン列の各位置で異なるエキスパート重みをロードしなくてはならず、メモリ帯域の節約効果が薄れるためだ。バッチサイズを4〜8に上げて並列リクエストを束ねれば、約2.2倍まで戻る。Dense版である31Bモデルは、こうしたルーティング上の制約がないため、Apple Silicon上でもより安定して2倍前後の効果を出しやすい、というのがHugging FaceブログとMLXコミュニティの一致した見解になっている。
Google公式ブログとMarkTechPostが共通して指摘しているもうひとつのポイントは「base modelではなくinstruction-tuned(-it)モデルが前提」という点だ。AI-Muninnの実機検証では、ベースモデルにドラフターを付けると逆に0.61倍へとスピードが落ちることが報告されており、これはGoogleの公式アナウンスではあまり強調されていない注意事項である。
シリコンバレーVCの見立て:「推論層」が次の主戦場という確信
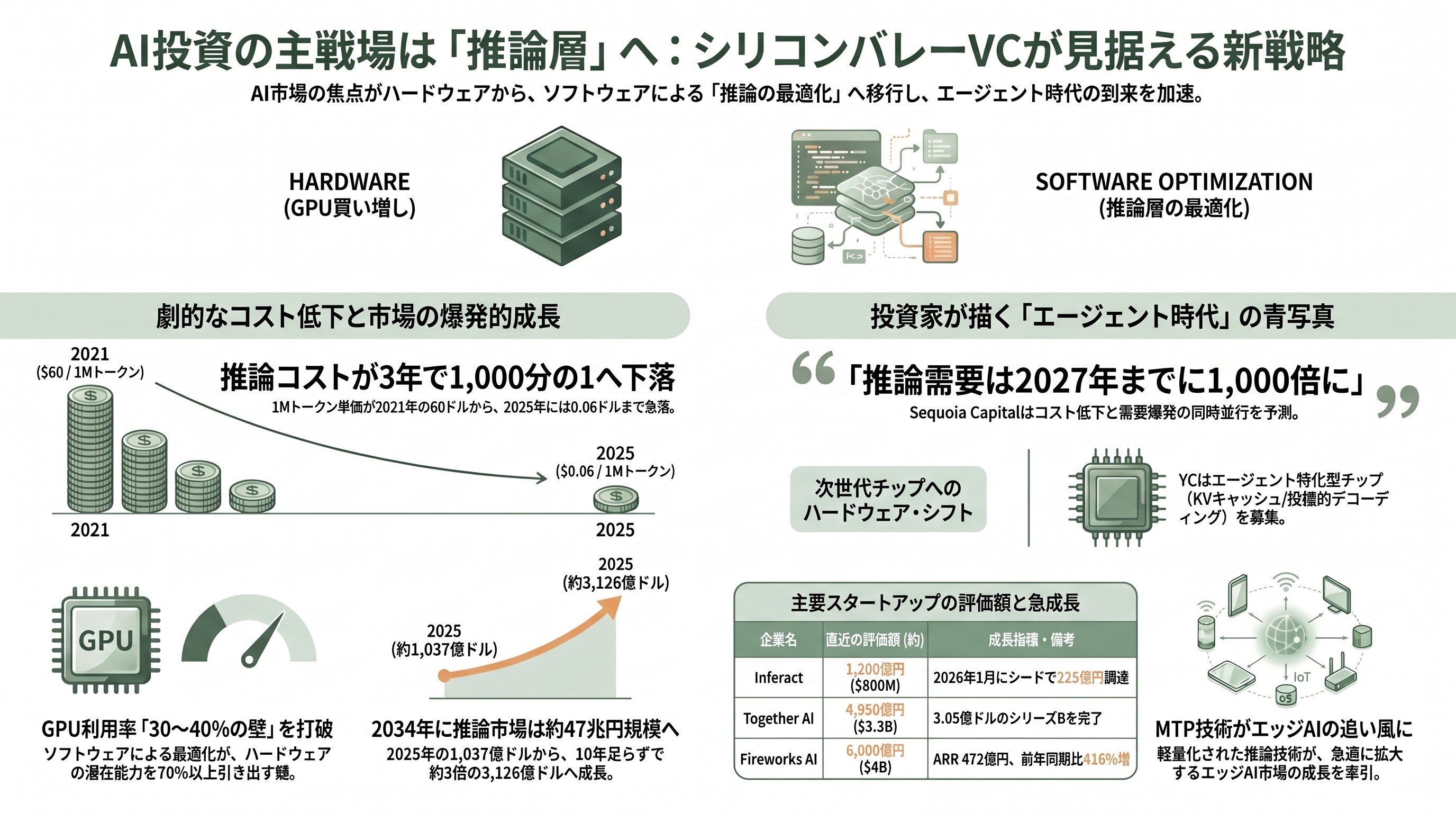
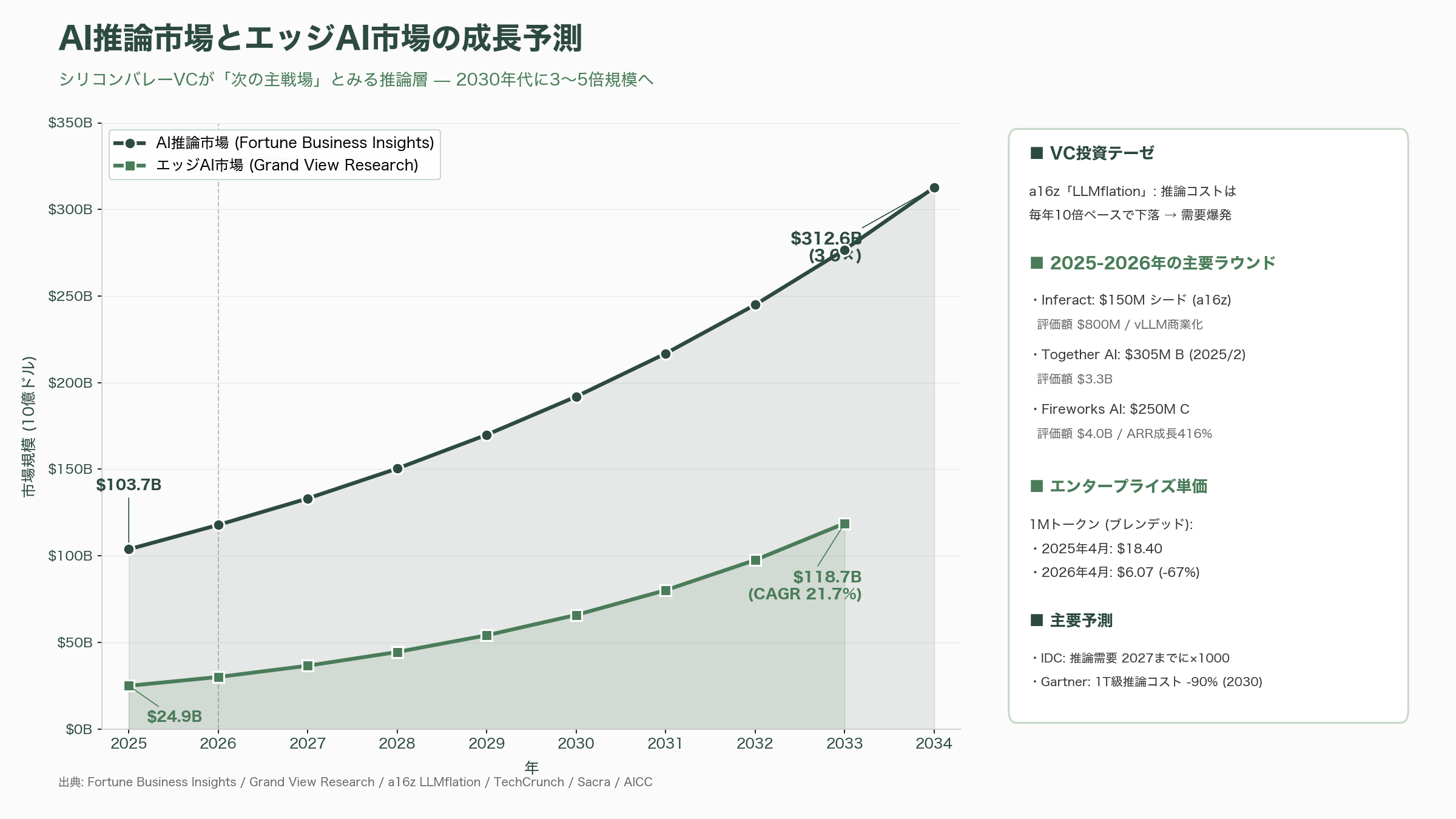
シリコンバレーのVCコミュニティは、このGoogleの動きを単独の製品アップデートとしてではなく、「推論層(inference layer)」という新しい市場カテゴリーが成熟しつつあるサインとして読み取っている。Andreessen Horowitz(a16z)のGuido Appenzeller氏が発表した「Welcome to LLMflation — LLM inference cost is going down fast」レポートは、同等性能のLLM推論コストが毎年10倍のペースで下落し、2021年11月に1Mトークン60ドルだったGPT-3クラスのコストが、2025年時点ではLlama 3.2 3Bで1Mトークン0.06ドル(3年で1000倍下落)まで落ちたと数字で示し、その下落の主要因として「ソフトウェア最適化による計算・メモリ帯域要求の削減」を6本柱のひとつに挙げている。MTPはまさにその「ソフトウェア最適化による帯域改善」の代表選手だ。
このテーゼを資金で裏付けるように、2026年1月にはvLLMの主要メンテナ陣(Simon Mo、Woosuk Kwon、Kaichao You、Roger Wang)が立ち上げたInferactが、a16zとLightspeed Venture Partnersのコリードで1.5億ドル(約225億円)のシードラウンドを完了し、評価額8億ドル(約1200億円)でローンチした。出資にはSequoia Capital、Altimeter Capital、Redpoint Ventures、Databricks Venturesも加わっている。TechCrunchの報道によれば、a16zは投資テーゼとして「H100を買い増すだけでは、GPU利用率30〜40%の壁を越えられない。残り70%の余剰演算を引き出すのは、ソフトウェアレイヤーだ」と明確に述べた。Inferactが商業化しようとしているvLLMは、いままさにGemma 4 MTPのDay 0サポートを実装したそのものであり、テーゼと現実のプロダクトが噛み合っている格好だ。
同じく投資家から熱い視線を浴びているのが、推論クラウドのTogether AIとFireworks AIである。Together AIは2025年2月に3.05億ドル(約457.5億円)のシリーズBをGeneral Catalystとプロスペリティ7のコリードで調達し、評価額33億ドル(約4950億円)まで一気に駆け上がった。同社は公式に「投機的デコーディング、量子化、FP8カーネルを組み合わせて性能を出している」と説明しており、MTP系のドラフターを自社推論プラットフォームへ素早く取り込める体勢を整えている。Fireworks AIは2025年10月に2.5億ドル(約375億円)のシリーズCを評価額40億ドル(約6000億円)で実施。Sacraの分析によれば、同社のARRは2026年2月時点で3.15億ドル(約472.5億円)に達し、前年同期比416%の急成長を遂げている。
Y Combinatorの「Summer 2026 Requests for Startups」では、ジェネラルパートナーのDiana Hu氏が「エージェントループ専用チップ」を明示的に募集している。彼女は「現状のGPUはエージェント・ワークロード(ループ、ツール呼び出し、ブランチ、バックトラック、長期コンテキスト保持)で30〜40%の利用率しか出ない。我々は、モデル間の高速コンテキスト切替、ネイティブな投機的デコーディング、実行グラフ全体にまたがるKVキャッシュを設計したチップが欲しい」と述べており、ハードウェア側からの呼応も顕在化している。MTPはこのうち「ネイティブな投機的デコーディング」の中核を成す技術だ。
Sequoia Capitalは2026年4月、AI/後期段階投資向けの70億ドル(約1兆500億円)拡張ファンドを発表し、同社レポート「AI in 2026: A Tale of Two AIs」「2026: This is AGI」で、エージェント時代の推論需要は2027年までに1000倍に膨らむというIDCの予測を引きながら、「推論コストの構造的下落と需要爆発は同時並行で進む」と述べている。Bloombergやfinsmesの報道を総合すると、Sequoiaは推論最適化に特化したInferactとFireworks AIに加えて、MTPの根幹である投機的デコーディング技術を売る形態のスタートアップ(Pipeshiftなど)を、シードからシリーズBレンジで積極的に拾っている。
エンタープライズへの影響は数字としても出始めている。AICCレポートは「2026年4月時点で、エンタープライズの実効トークン単価(ブレンデッド)は1Mトークンあたり6.07ドルにまで下落し、1年前の18.40ドルから67%下がった」と報告。Fortune Business Insightsは、AI推論市場が2025年の1037.3億ドル(約15.6兆円)から2026年に1178億ドル(約17.7兆円)、2034年には3126.4億ドル(約46.9兆円)に達すると見ている。エッジAI市場についてはGrand View Researchが2025年249.1億ドル(約3.7兆円)→2026年299.8億ドル(約4.5兆円)→2033年1186.9億ドル(約17.8兆円、CAGR 21.7%)と予測しており、エッジ向けE2B/E4Bが軽量化されたMTPで動くという今回のリリースは、ちょうどこのカーブの真ん中で大きな追い風になる。
報道のトーン:「ロスレス3倍」の出処と冷静な分析
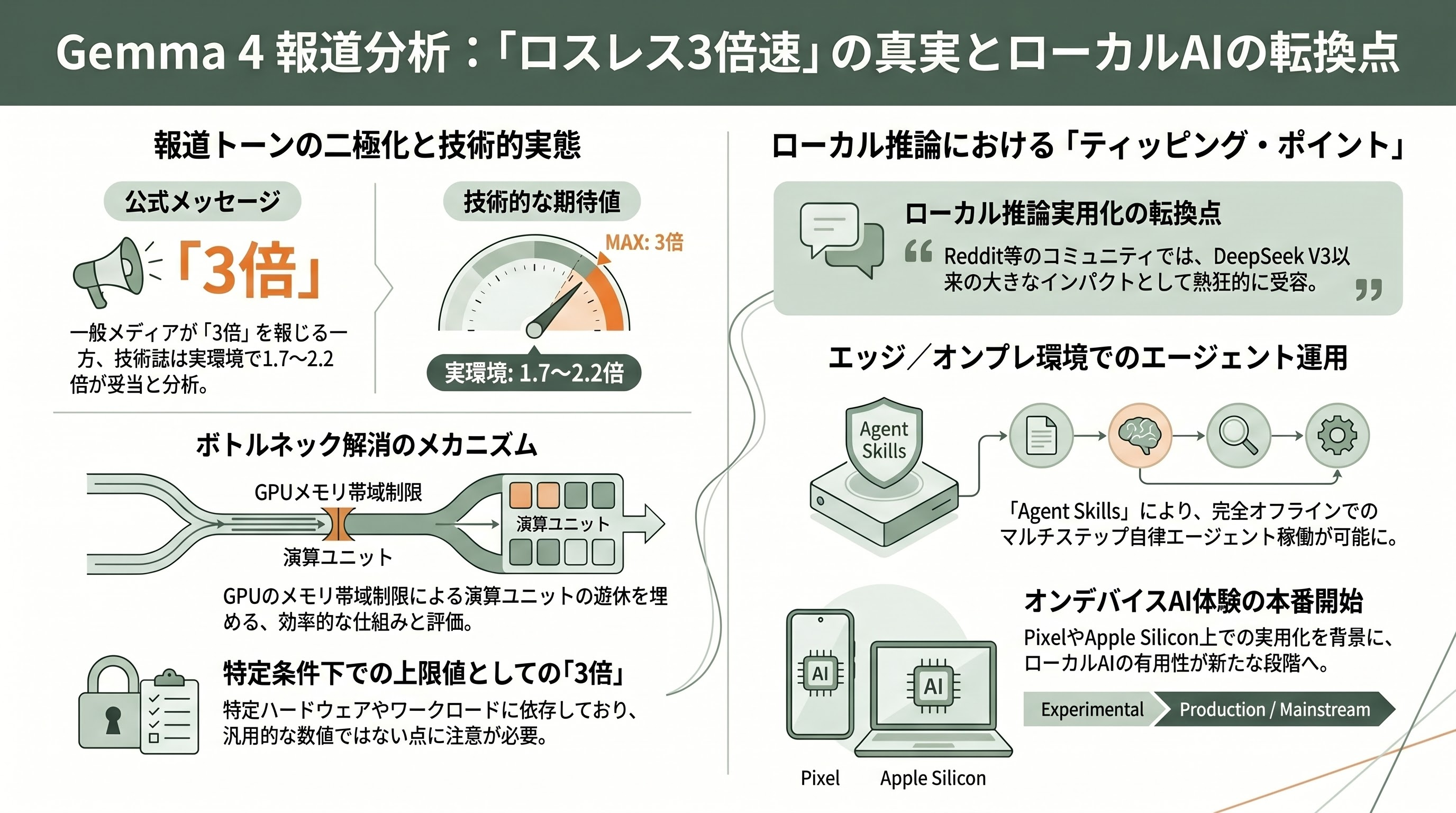
各メディアの報じ方には微妙な濃淡がある。Eastern Herald、MarkTechPost、AIToolly、Pulse2.0、Neuronadは概ね「3倍高速化、品質劣化なし」というGoogle公式メッセージにストレートに乗ったトーンで報じている。これに対し、The Decoder(Heise系)、Decrypt、claypier、buildfastwithaiといったテクニカル寄りの媒体は、3倍はあくまで「特定ハードウェア・特定バッチサイズ・特定ワークロード」での上限であり、実環境では1.7〜2.2倍が「あるべき期待値」だと強調する。Hacker News(item 48024540)のスレッドでは、ベテラン開発者から「これは結局、自分の予想した未来パスに対して自己バッチングしているのと同じ」「メモリ帯域がボトルネックのGPUで演算ユニットの遊休を埋める仕組み」といった的確な解説が多数寄せられ、Gemma 4のトークン効率の良さを称賛する声と、コード生成や複雑なツール呼び出しではClaudeやGPTに比べて見劣りする、という冷静な評価が並んだ。
Reddit r/LocalLLaMAのコミュニティ反応も注目に値する。Startup Fortuneによれば、5月5日のリリース当日に同サブレディットには3時間で463 upvote/128 commentが集まり、当日中にllama.cpp、Ollama、vLLM、LM Studioで動作確認が次々と報告された。「同じハードでローカル推論がここまで速くなったのは、DeepSeek V3で訓練時MTPが入ったとき以来のインパクト」「これは新モデルのリリースという以上に、ローカル推論実用化のtipping pointになる動き」という評価が支配的だった。
日本語圏での報道はまだ限定的だが、Google公式ブログの翻訳を通じて主要技術メディアが取り上げ始めており、特にエッジ/オンプレ展開の文脈で「Pixel TPUおよびApple Silicon上でのオンデバイスエージェント実用化」を意識した解説が増えている。Google Developers Blogが同時公開した「Bring state-of-the-art agentic skills to the edge with Gemma 4」では、Agent Skillsという新機能と組み合わせて、Gemma 4 E2B/E4Bが完全オフラインでマルチステップ自律エージェントを動かす運用例が紹介されており、Tris Warkentin氏(Google DeepMindプロダクト責任者)はX(旧Twitter)上で「ローカルでのAI体験はここからが本番」と発信している。
影響の射程:チャット、エージェント、そしてデバイス内AIへ
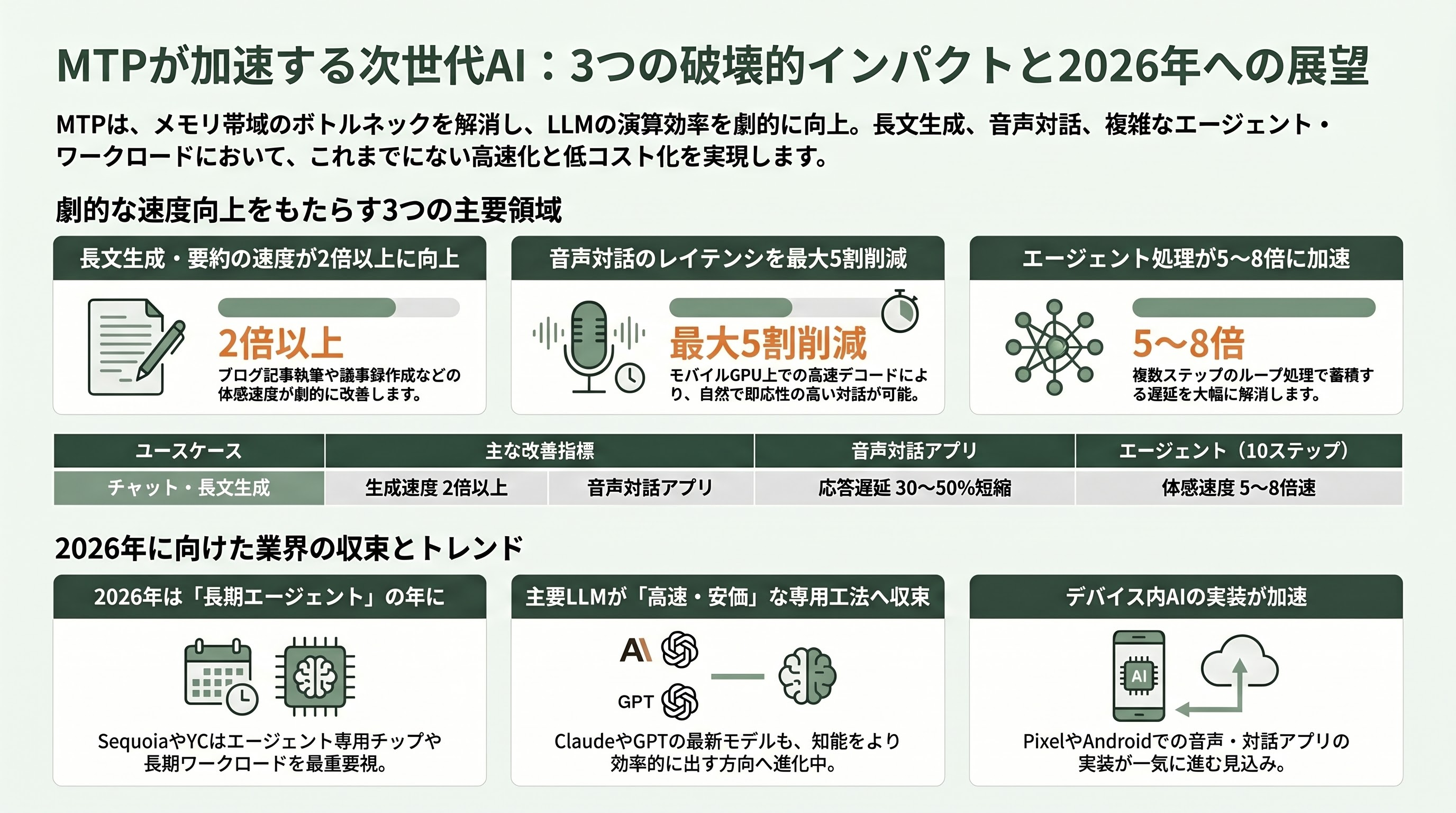
技術的に見ると、MTPが本質的に効くのは「メモリ帯域がボトルネックで、演算器が遊んでいる」局面である。これは特に、次の三つのユースケースに直撃する。
ひとつは長文の連続生成や、要約・翻訳のように長めの出力が連なるチャットタスクである。AIにブログ記事をまるごと書かせる、議事録を整形する、長文プレゼン草稿を生成する、といったケースで、体感速度が文字通り倍以上になる。ふたつめは音声インターフェース。音声合成パイプラインのなかで、LLMからの応答テキスト生成がレイテンシのクリティカルパスになっていた領域で、応答の頭出しが体感で3割〜半分縮まる。Google AI Edge GalleryのリリースノートおよびLiteRT-LMドキュメントでは、モバイルGPU上でデコード速度が2倍以上速くなる、と数字付きで触れられており、PixelとAndroidエンドポイントでの音声・対話アプリの実装が一気に進む可能性がある。
三つめが、シリコンバレーVCが2026年最大のテーマと位置づけている「エージェント・ワークロード」だ。Sequoiaが「2026 is the year of long-horizon agents」と宣言し、Y CombinatorのDiana Hu氏が「エージェントループ専用チップ」を募集していることに象徴されるように、ツール呼び出し・ブランチ・バックトラックを含む数十ステップのループでは、LLM呼び出しのレイテンシが累積する。1呼び出しが2倍速くなれば、10ステップのエージェントは体感で5〜8倍速く感じられる。さらに、KVキャッシュをドラフター・本体・ステップ間で共有できれば、コンテキストの再ロードを抑えられる。Anthropicが2026年5月のニュースで打ち出した「Claude Opus 4.6 Fast Mode」がスループット2.5倍を出している件や、OpenAIのGPT-5.3-Codexが25%高速化された件と並べると、業界全体が「同じ知能を、より速く・より安く出すための専用工法」に同時収束しつつあるのが見えてくる。
VC視点でのリスクと留意点:3倍は誰でも享受できるわけではない

シリコンバレーVCの観点からは、MTPの普及には三つの未解決点が指摘されている。
第一に、ハードウェア依存の偏在。MTPの効果は、メモリ帯域と演算密度の比率に強く依存するため、NVIDIA H100/RTX PRO 6000やApple Siliconの上位機では大きく恩恵がある一方、RaspberryPi 5などの真のローエンドや、メモリ階層の浅いマイコンでは効果が限定的である。LiteRT-LMドキュメントによれば、Raspberry Pi 5でのGemma 4 E2BデコードはCPU上で7.6 tokens/secで、Qualcomm Dragonwing IQ8のNPUでは31 tokens/secまで上がる。NPU上でMTPがどこまで効くかは、まだ各SoCベンダー側の実装次第というのが正直なところだ。投資家が「On-Device AI」のスタートアップを見るときには、ハード選定とMTP相性が大きく数字に効く点を意識する必要がある。
第二に、コード生成ワークロードでの精度トレードオフ。AI-Muninnやkaitchupの検証では、コード生成タスクではドラフター受理率が下がり、無駄な投機的計算が増えるため、ベストケースの3倍からはかなり目減りする。Anthropic Claude Code、GitHub Copilot、Cursor、Replit Agentのようなコード支援系プロダクトは、MTPによる恩恵が会話系ほど素直に得られない可能性がある。VCがこの領域でデューデリを行う際には、ベンチマークがチャット中心になっていないかを確認する重要性が上がっている。
第三に、エコシステム標準化の競争。Googleのオフィシャル「Gemma 4 MTP Drafter」と、コミュニティ発のEAGLE-3、MEDUSA、Lookahead、DeepSeek式訓練時MTPなど、複数の流派が同時並行で発展中であり、推論ランタイム側(vLLM、SGLang、MLX、llama.cpp、TensorRT-LLM)がどれを「第一級市民」として優遇するかで、勢力図が変わりうる。vLLMがDay 0でGoogleドラフターを優遇したことは、Google×vLLM×Inferactという同盟関係の存在を示唆しており、a16zのポートフォリオ戦略を読み解くうえでも興味深い動きだ。
いつ何が起きるか:直近6〜18ヶ月のロードマップ
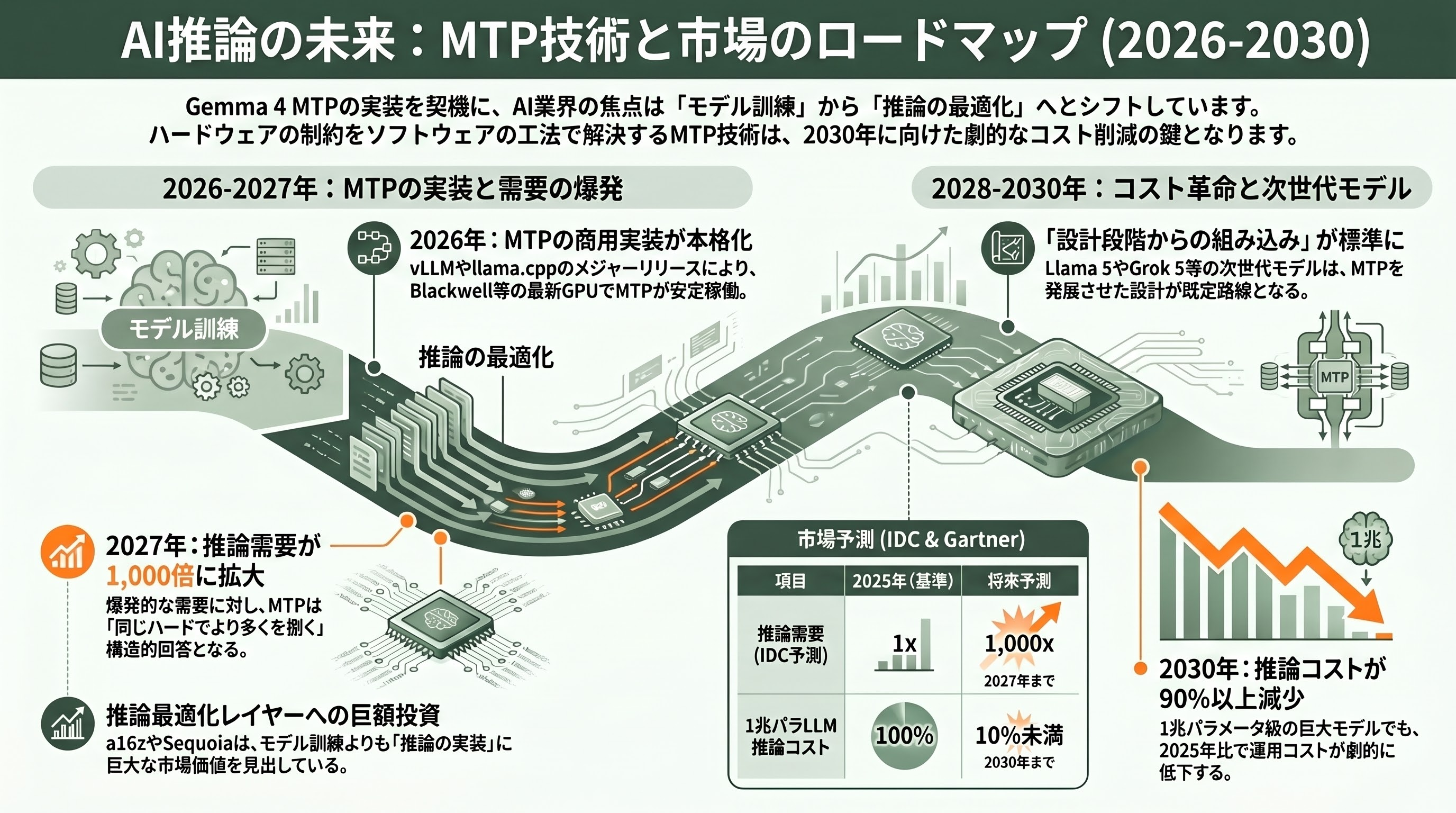
直近の動きとして、まず2026年5〜6月にはvLLM v0.20.x系列のメジャーリリースで、Gemma 4 MTPが安定版に組み込まれる見通しが立っており、GitHub Issue #42005やPR #41745の議論からは、HopperおよびBlackwellの両方で公式Dockerイメージが提供される段階に到達している。年内にはMLXとllama.cppでもMTPがプロダクション品質に達する見込みで、kaitchupは「llama.cppでMTPがベータからGAに上がる」とブログで予告している。
中期的には、Sequoia Capitalが2026年を「a year of delays」と表現したように、データセンター増設の遅れとAGIタイムラインの遅延がぶつかり、推論コスト削減の重要性は2027年に向けてさらに増す。IDCの「2027年までに推論需要は1000倍」という予測を踏まえれば、MTPのような「同じハードでもっと多くを捌く」工法は、GPU供給制約への構造的回答として強い意味を持つ。Gartnerはさらに踏み込んで、2030年までに1兆パラメータLLMの推論コストはGenAI事業者にとって2025年比90%以上下がると予測している。
長期的な伏線として、DeepSeek V4(2026年後半に噂される次世代モデル、空間・時間・モダリティの三次元アテンションが取りざたされている)、Meta Llama 5、xAI Grok 5、Mistral Largeの次バージョンといった、いずれのフロンティアモデル候補も、MTPあるいはその発展形を「設計段階から組み込む」ことが既定路線になりつつある。NVIDIAは公式技術ブログで「DeepSeek V4 with NVIDIA Blackwell」を打ち出し、Blackwell世代のテンソルコアを投機的デコーディング向けに最適化する流れを示している。Y Combinatorが募集中の「エージェントループ専用チップ」スタートアップが市場に出てくれば、ハードとソフトの両側からMTPの恩恵が増幅される。
シリコンバレーのVCにとって、今回のGoogle MTPリリースは「Gemma 4そのものへの追加コミット」というより、自分たちが2024年から張り続けてきた「推論最適化レイヤー」テーゼに対する、グーグルからの強力な裏付けと映っている。a16zのLLMflationレポート、Inferactへの225億円シード、Together AIとFireworks AIへの巨額の追加投資、そしてSequoia Capitalの1兆円規模新ファンドは、いずれも「モデル訓練の派手な勝者と、推論実装の地味だが巨大な勝者は別物だ」というロジックの上に成り立っている。MTPはまさにその「地味だが効く工法」の象徴であり、Gemma 4というアクセスしやすいオープンウェイトモデル上で誰でも検証できるようになったことで、推論層の市場の存在を一気に可視化した、というのが2026年5月時点の総括である。
いつ何が起きるか:直近6〜18ヶ月のロードマップ
直近の動きとして、まず2026年5〜6月にはvLLM v0.20.x系列のメジャーリリースで、Gemma 4 MTPが安定版に組み込まれる見通しが立っており、GitHub Issue #42005やPR #41745の議論からは、HopperおよびBlackwellの両方で公式Dockerイメージが提供される段階に到達している。年内にはMLXとllama.cppでもMTPがプロダクション品質に達する見込みで、kaitchupは「llama.cppでMTPがベータからGAに上がる」とブログで予告している。
中期的には、Sequoia Capitalが2026年を「a year of delays」と表現したように、データセンター増設の遅れとAGIタイムラインの遅延がぶつかり、推論コスト削減の重要性は2027年に向けてさらに増す。IDCの「2027年までに推論需要は1000倍」という予測を踏まえれば、MTPのような「同じハードでもっと多くを捌く」工法は、GPU供給制約への構造的回答として強い意味を持つ。Gartnerはさらに踏み込んで、2030年までに1兆パラメータLLMの推論コストはGenAI事業者にとって2025年比90%以上下がると予測している。
長期的な伏線として、DeepSeek V4(2026年後半に噂される次世代モデル、空間・時間・モダリティの三次元アテンションが取りざたされている)、Meta Llama 5、xAI Grok 5、Mistral Largeの次バージョンといった、いずれのフロンティアモデル候補も、MTPあるいはその発展形を「設計段階から組み込む」ことが既定路線になりつつある。NVIDIAは公式技術ブログで「DeepSeek V4 with NVIDIA Blackwell」を打ち出し、Blackwell世代のテンソルコアを投機的デコーディング向けに最適化する流れを示している。Y Combinatorが募集中の「エージェントループ専用チップ」スタートアップが市場に出てくれば、ハードとソフトの両側からMTPの恩恵が増幅される。
シリコンバレーのVCにとって、今回のGoogle MTPリリースは「Gemma 4そのものへの追加コミット」というより、自分たちが2024年から張り続けてきた「推論最適化レイヤー」テーゼに対する、グーグルからの強力な裏付けと映っている。a16zのLLMflationレポート、Inferactへの225億円シード、Together AIとFireworks AIへの巨額の追加投資、そしてSequoia Capitalの1兆円規模新ファンドは、いずれも「モデル訓練の派手な勝者と、推論実装の地味だが巨大な勝者は別物だ」というロジックの上に成り立っている。MTPはまさにその「地味だが効く工法」の象徴であり、Gemma 4というアクセスしやすいオープンウェイトモデル上で誰でも検証できるようになったことで、推論層の市場の存在を一気に可視化した、というのが2026年5月時点の総括である。
Sources
- Accelerating Gemma 4: faster inference with multi-token prediction drafters - Google Blog
- Speed-up Gemma 4 with Multi-Token Prediction - Google AI for Developers
- Gemma 4 Multi-Token Prediction (MTP) using Hugging Face Transformers - Google AI for Developers
- Gemma 4: Byte for byte, the most capable open models - Google Blog
- Gemma 4 - Google DeepMind
- Gemma 4: Expanding the Gemmaverse with Apache 2.0 - Google Open Source Blog
- Welcome Gemma 4: Frontier multimodal intelligence on device - Hugging Face
- Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4 - MarkTechPost
- Google speeds up Gemma 4 threefold with multi-token prediction - The Decoder
- Google Found a Way to Make Local AI Up to 3x Faster - Decrypt
- Google's Gemma 4 Gets 3× Faster With MTP Upgrade - Eastern Herald
- Google Releases MTP Drafters for Gemma 4 - claypier
- Gemma 4 MTP Drafter: Get 3x Faster Inference (2026 Guide) - Build Fast With AI
- Liftoff: Gemma 4 hits 670 tok/s aggregate on DGX Spark - AI Muninn
- vLLM PR #41745: Add Gemma4 MTP speculative decoding support
- Hacker News: Accelerating Gemma 4 (item 48024540)
- Fast Inference from Transformers via Speculative Decoding - Yaniv Leviathan et al., arXiv:2211.17192
- Looking back at speculative decoding - Google Research Blog
- Better & Faster Large Language Models via Multi-token Prediction - Meta, arXiv:2404.19737
- DeepSeek-V3 Technical Report - arXiv:2412.19437
- Welcome to LLMflation - LLM inference cost - Andreessen Horowitz
- Investing in Inferact - Andreessen Horowitz
- Inferact lands $150M to commercialize vLLM - TechCrunch
- Together AI Announces $305M Series B
- Fireworks AI revenue, valuation & funding - Sacra
- Sequoia Capital - AI in 2026: A Tale of Two AIs
- Sequoia Capital - 2026: This is AGI
- YC Summer 2026 Requests for Startups (Diana Hu)
- LiteRT-LM Overview - Google AI Edge
- Bring state-of-the-art agentic skills to the edge with Gemma 4 - Google Developers Blog
- vLLM Day-0 MTP support announcement (X)
- AI Inference Market Size & Forecast - Fortune Business Insights
- Edge AI Market Size & Trends - Grand View Research
- Gartner: Inference cost on 1T-param LLM down 90% by 2030