序章:RAGとは何か — パラメトリック記憶の限界と「外部知識」という発想
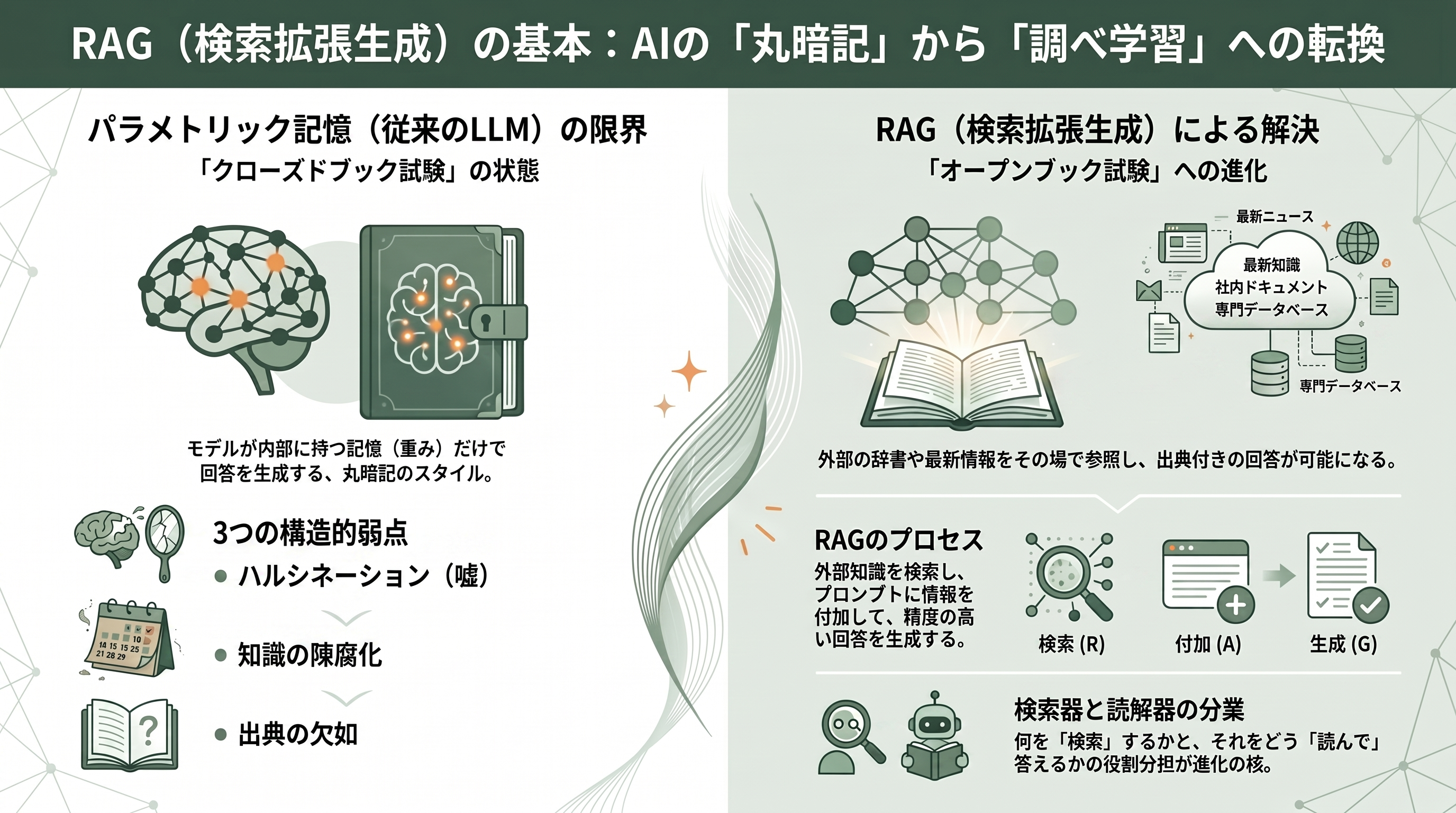
GPTやClaude、Geminiのような大規模言語モデルは、膨大なテキストを学習する過程で、知識を自らの重み(パラメータ)の中に圧縮して畳み込んでいる。これを研究者は「パラメトリック記憶」と呼ぶ。試験にたとえれば、参考書を持ち込めない「クローズドブック試験」を、丸暗記だけで突破するようなものだ。この方式には三つの構造的な弱点がある。第一に、覚えていないことを問われると、それらしい嘘を自信満々に答えてしまう「作話(ハルシネーション)」。第二に、学習を打ち切った時点で知識が凍結され、新しい出来事を知らない「陳腐化」。第三に、答えの根拠を示せない「出典の欠如」である。たとえば学習打ち切り後に起きた決算や買収について尋ねれば、モデルは平然と存在しない数字を口にするし、なぜそう答えたのかを後から検証する術もない。
RAGは、この問題を発想の転換で解く。知識を重みの中に閉じ込めるのをやめ、外部に「更新でき、引用できる」知識庫として置いておき、質問が来るたびに関連する文書を検索(Retrieval)して取り出し、それをプロンプトに付加(Augmented)したうえで、モデルに答えを生成(Generation)させるのだ。クローズドブック試験を、参考書を引ける「オープンブック試験」に変える、と言い換えてもよい。暗記力(パラメトリック記憶)に頼る代わりに、必要な情報をその場で調べる外部記憶(ノンパラメトリック記憶)を併用する。この発想によって、最新情報への追従、社内文書への接続、そして「どの文書を根拠にしたか」という出典提示が一挙に可能になる。実際、出典付きで回答するPerplexityも、社内の散在する文書を横断検索して答えるGleanも、その中核はこのRAGである。
本稿が辿る15本の論文に一本の背骨があるとすれば、それは「検索器(リトリーバ)と読解・生成器(リーダー)の分業」という構図だ。何を取ってくるかを担う検索器と、取ってきたものを読んで答えを作る読解器。この二分法は2017年に確立され、以後の進化はすべて「検索器をどう賢くするか」「読んだものをどう融合するか」「いつ検索すべきか」「正解なしにどう評価するか」という問いへの回答として現れる。素朴な単語一致の検索から、意味をベクトルで捉える密検索へ。一文の答え探しから、何百もの文書を束ねる生成融合へ。一度きりの検索から、生成しながら能動的に調べ直す検索へ。そして平坦な文書集合から、関係性を表す知識グラフへ。RAGの発展史は、この分業の各パーツが順番に鍛えられていく物語として読める。
第1章 2017年 DrQA — Wikipediaを丸ごと読んで答える「検索と読解の分業」
すべての出発点は、Danqi Chen(当時スタンフォード、現プリンストン大学准教授)らがFacebook AI Researchと共同で発表した *Reading Wikipedia to Answer Open-Domain Questions*(ACL 2017、arXiv:1704.00051)である。著者にはJason WestonやAntoine Bordesといった対話・記憶研究の重鎮も名を連ねた。彼らが掲げたのは「Machine Reading at Scale(大規模な機械読解)」という旗印で、特定の文書を与えられて答えるのではなく、英語版Wikipedia全体を知識源として任意の質問に答えるという、現在のRAGそのものの問題設定だった。
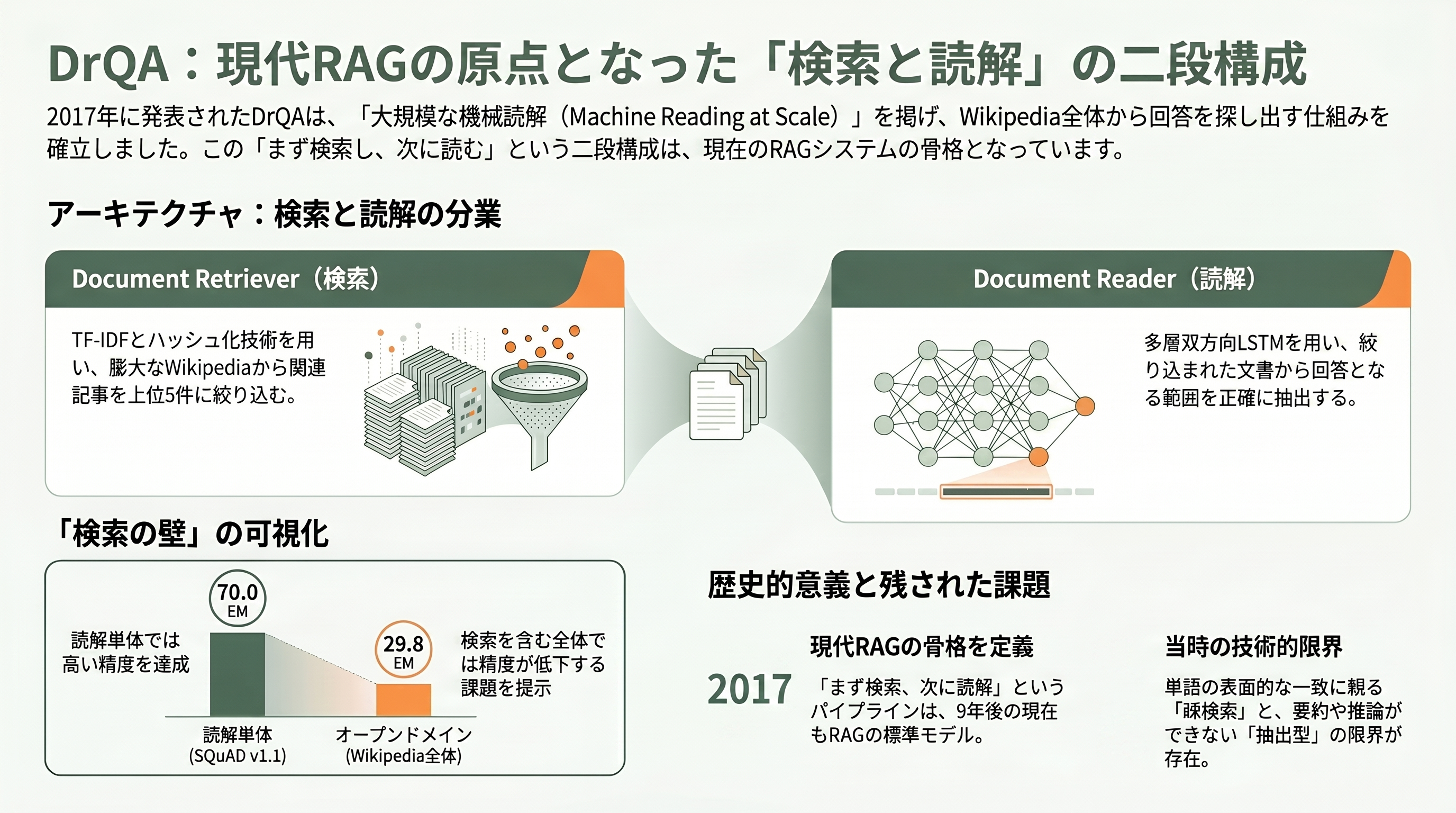
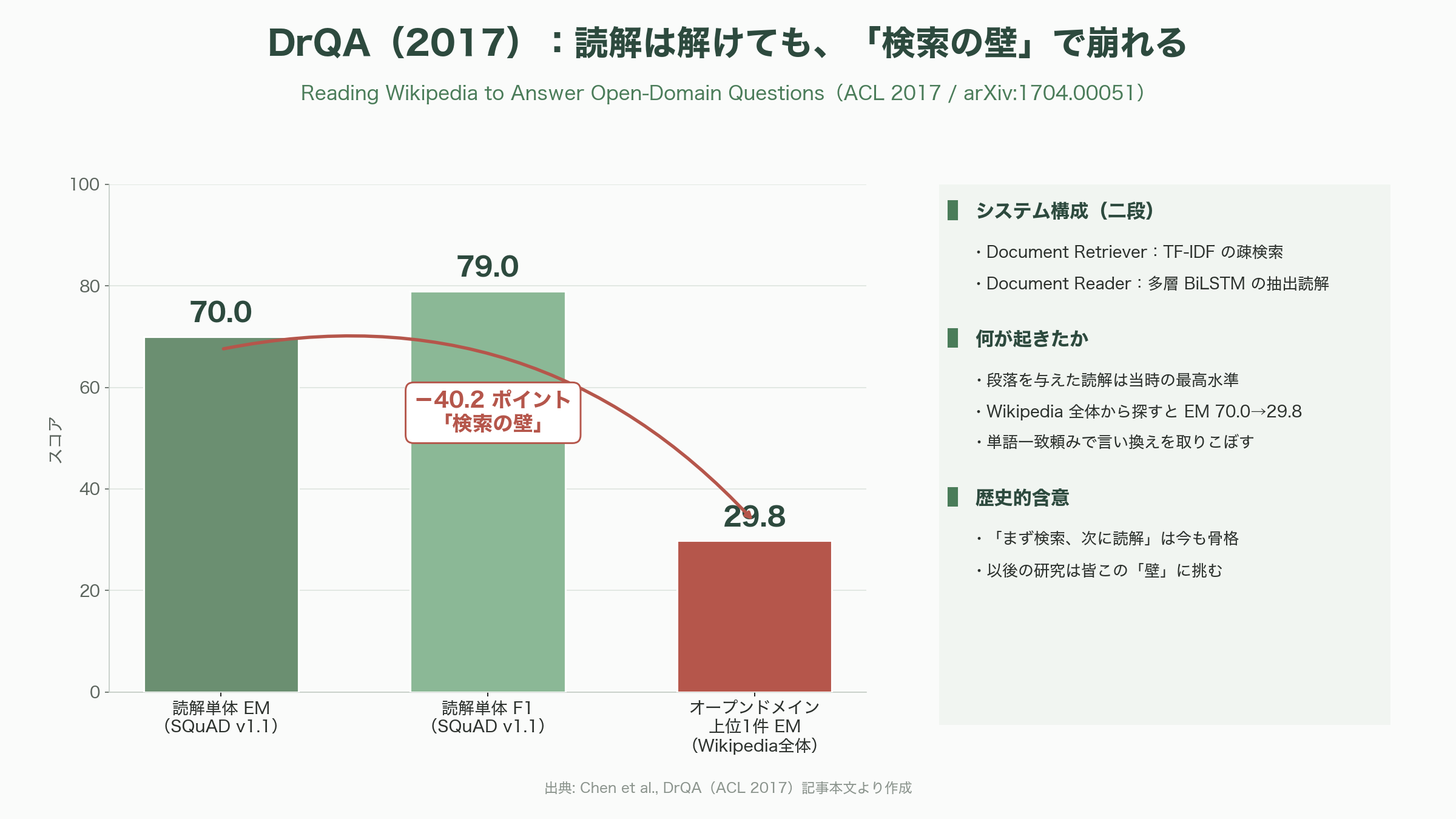
DrQAの設計は明快な二段構えだ。前段の Document Retriever は、TF-IDFで重み付けした単語・連接語(バイグラム)のベクトルで、質問に関連する記事を上位5件まで絞り込む。連接語のカウントはmurmur3ハッシュで約1,670万個(2の24乗)のビンに畳み込むという、当時としては実装上の工夫が施されていた。後段の Document Reader は、多層の双方向LSTMが、絞り込まれた段落の中から答えにあたる範囲(スパン)を抜き出す。読解単体ではSQuAD v1.1で完全一致(EM)70.0/F1 79.0という当時最高水準を出したが、Wikipedia全体から答えを探すオープンドメイン設定では、SQuAD由来の質問で上位1件EMが29.8まで落ちた。この落差こそが、後続研究すべてが挑む「検索の壁」を可視化した。
シリコンバレーの視点で振り返ると、DrQAの本質的な貢献は数字ではなくアーキテクチャの分解にある。「まず検索、次に読解」という二段パイプラインは、9年後のいまも、あらゆるRAGシステムの骨格として生き残っている。一方で限界も明確だった。検索は単語の表層的な一致に頼る疎検索であり、「自動車」と「クルマ」のような言い換えを取りこぼす。読解は本文から語句を抜き出す抽出型で、複数の文書をまたいで要約したり推論したりはできない。この二つの限界を埋める作業が、続く論文群の主題になっていく。
第2章 2020年 REALM — 検索を「事前学習」に組み込む
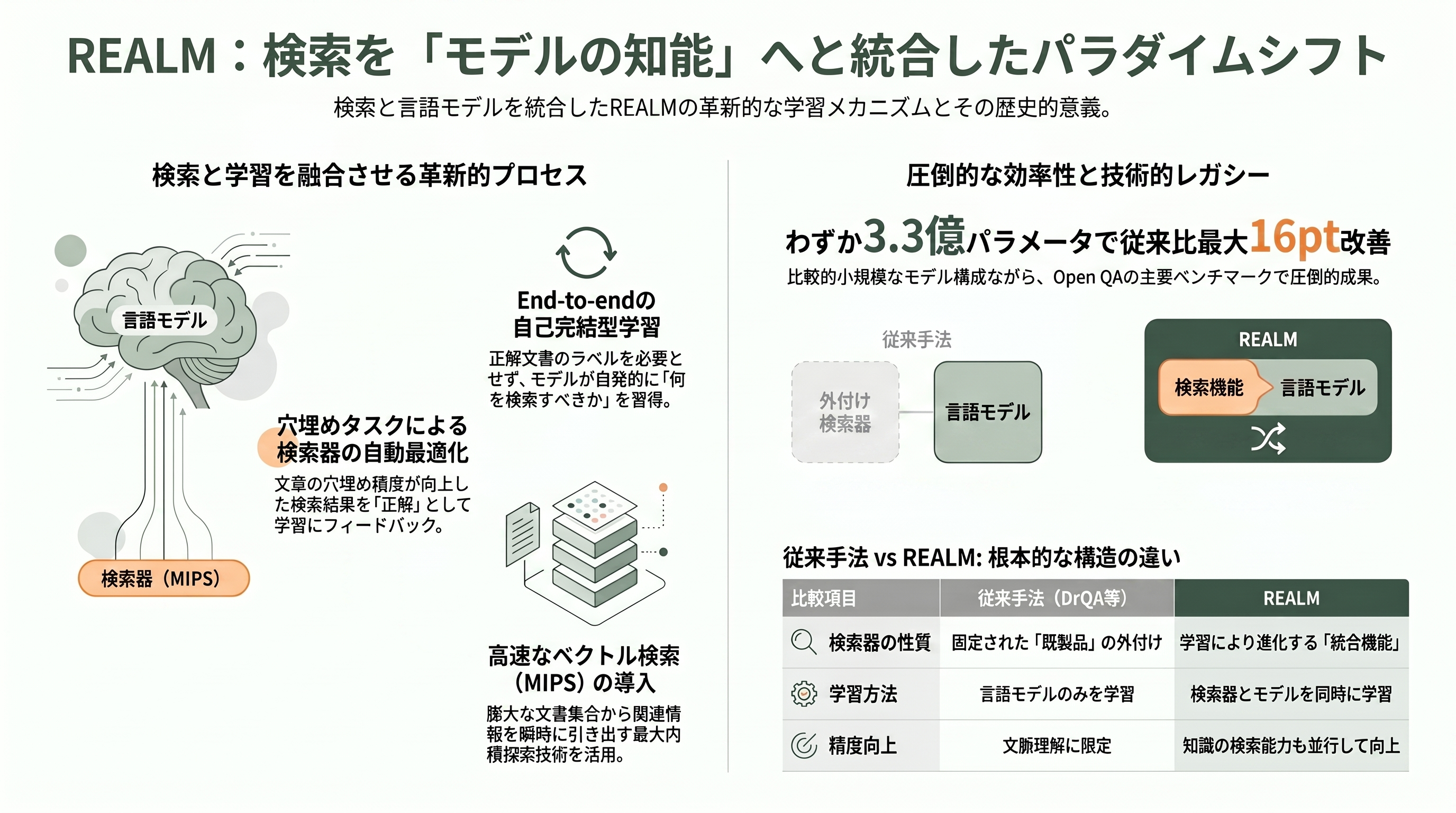
DrQAの検索器は、言語モデルとは別に作られた既製品だった。これに対しGoogle ResearchのKelvin Guuらは *REALM: Retrieval-Augmented Language Model Pre-Training*(ICML 2020、arXiv:2002.08909)で、踏み込んだ問いを立てた。「何を検索すべきか」を、言語モデルの学習そのものから教えられないか、というものだ。
REALMの仕掛けはこうだ。事前学習でおなじみのマスク穴埋め(masked language modeling)を行う際、モデルはまず数百万件の文書から関連文書を引いてきて、それを手がかりに穴を埋める。もしある文書が穴埋めの精度を上げたなら、その文書は「役に立った」とみなされ、検索器はそういう文書を引きやすくなるよう更新される。正解の文書ラベルは一切与えず、穴埋めという代理タスクの成否だけを信号にして、検索器を end-to-end で鍛えるのだ。技術的には、巨大な文書集合から関連文書を高速に引くために最大内積探索(MIPS)を使い、学習でモデルが動くたびに古くなる文書ベクトルの索引を、数百ステップごとに裏側で非同期に貼り替えるという力技も導入した。結果としてオープンQAの三つのベンチマークで従来手法を絶対値で4〜16ポイント上回り、Natural Questionsで39.2〜40.4(事前学習コーパスにより変動)を、わずか3.3億パラメータで達成した。
REALMは「検索を事前学習に溶かし込む」という、最も野心的な路線を最初に示した記念碑である。実装は複雑でコストも高く、そのままの形で広く製品化されたわけではないが、ここで灯った理想は後のRETROやAtlasへと受け継がれていく。研究者の目には、REALMは「検索とは外付けの前処理ではなく、モデルの能力の一部になりうる」という思想的な出発点として映る。
第3章 2020年 DPR — 密ベクトル検索がBM25を超えた日
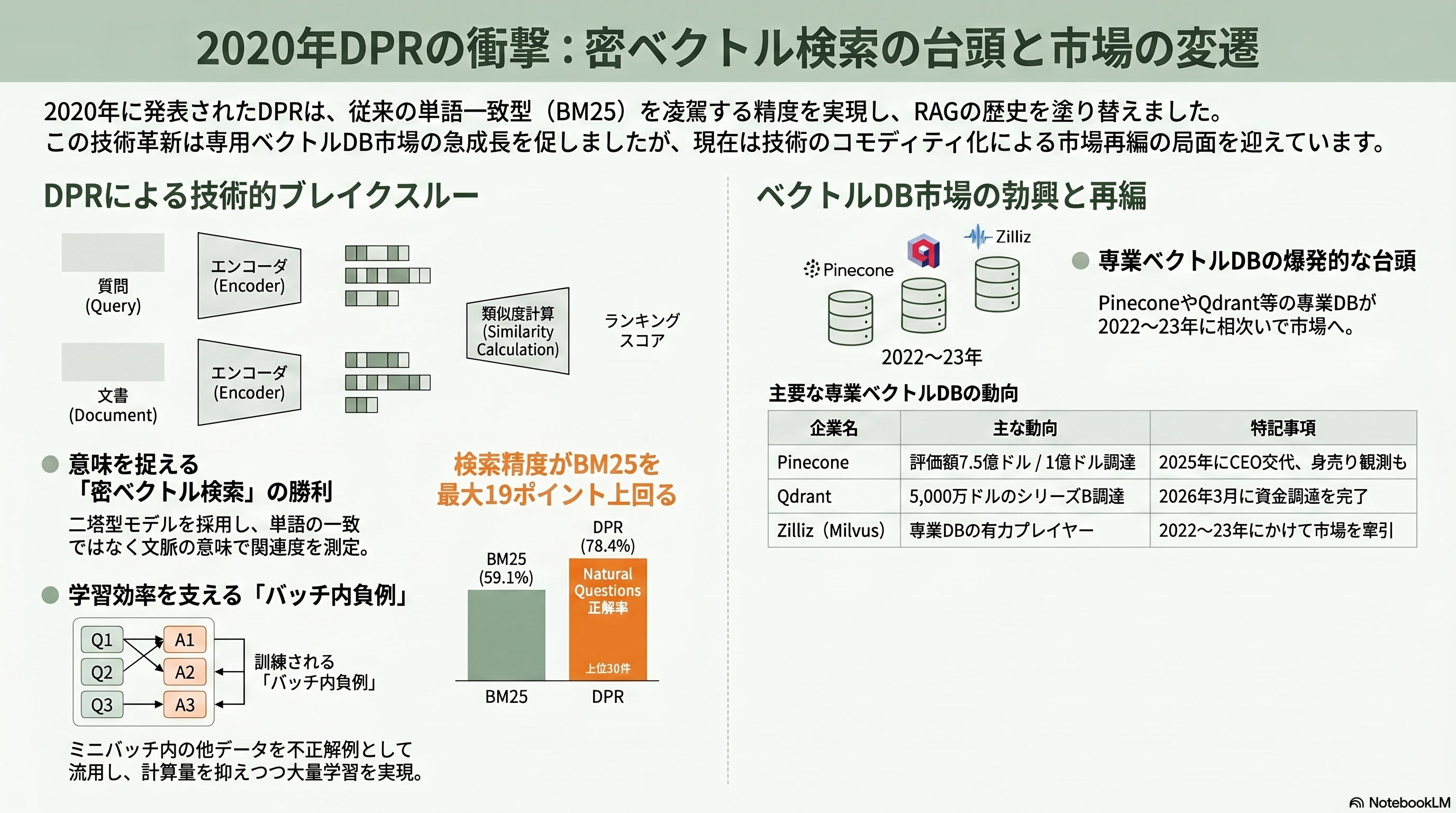
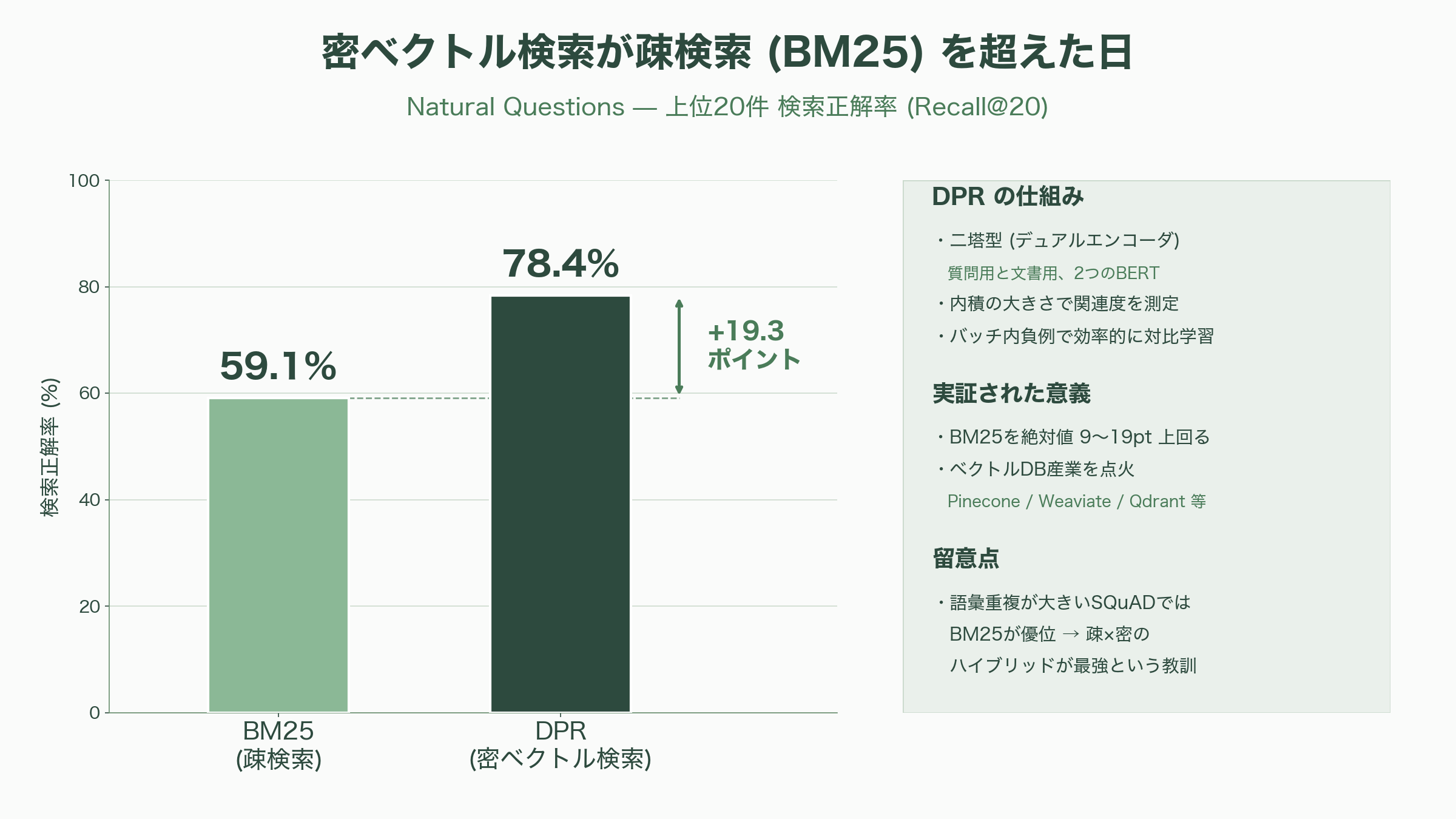
RAG産業の地図を最も大きく塗り替えた一本を挙げるなら、Vladimir KarpukhinらFacebook AI Researchの *Dense Passage Retrieval for Open-Domain Question Answering*(EMNLP 2020、arXiv:2004.04906)だろう。長年、情報検索の現場ではBM25に代表される単語一致ベースの疎検索が王者であり続けた。DPRはそれを、意味を捉える密ベクトル検索で明確に打ち負かした。
仕組みは「二塔型(デュアルエンコーダ)」と呼ばれる。質問用と文書用の二つのBERTを用意し、それぞれを固定長のベクトルに変換して、内積の大きさで関連度を測る。学習を効率化する鍵が「バッチ内負例(in-batch negatives)」で、同じミニバッチに入った他の質問の正解文書を、自分にとっての不正解例として流用することで、計算をほとんど増やさずに大量の対比学習を回す。成果は劇的で、上位20件の検索正解率でBM25を絶対値9〜19ポイント上回った。Natural Questionsでは上位20件で78.4%対59.1%という大差をつけている。ただし万能ではなく、質問と本文の語彙的重なりが極端に大きいSQuADでは、DPRはBM25に及ばなかった。この例外は、後に「疎と密のハイブリッドが最強」という実務的教訓へとつながる。
研究者の視点で見れば、DPRはベクトルデータベース産業そのものを点火した論文である。文書をベクトルに変えて意味で引く、というDPRの作法を高速・大規模に支えるインフラとして、Pinecone・Weaviate・Chroma・Qdrant・Milvus(Zilliz)といった専業ベクトルDBが2022〜2023年に相次いで台頭した。カテゴリの旗艦Pineconeは2023年4月に評価額7億5,000万ドル(約1,160億円)で1億ドル(約155億円)のシリーズBを調達したが、以後の新規ラウンドはなく、2025年9月にはCEOが交代し身売り観測も流れるなど、変調が伝えられる。背景にあるのは「コモディティ化」だ。PostgreSQLの拡張pgvectorがあらゆるマネージドDBに載り、数千万件規模までなら専業DBを使わずとも十分になった。実際、2026年3月にシリーズB(5,000万ドル=約78億円、累計調達額は8,780万ドル=約136億円)を決めたQdrantのような新興もある一方、Elasticのカルカルニ最高経営責任者(CEO)が「ベクトルDBは機能であって、それ単体で事業にはならない」と述べたように、検索インデックスは大型データ基盤に飲み込まれつつある。DPRが切り拓いた市場は、わずか数年で勃興と再編をひと巡りした。
第4章 2020年 ColBERT — 「遅延相互作用」が精度と速度を両立させる
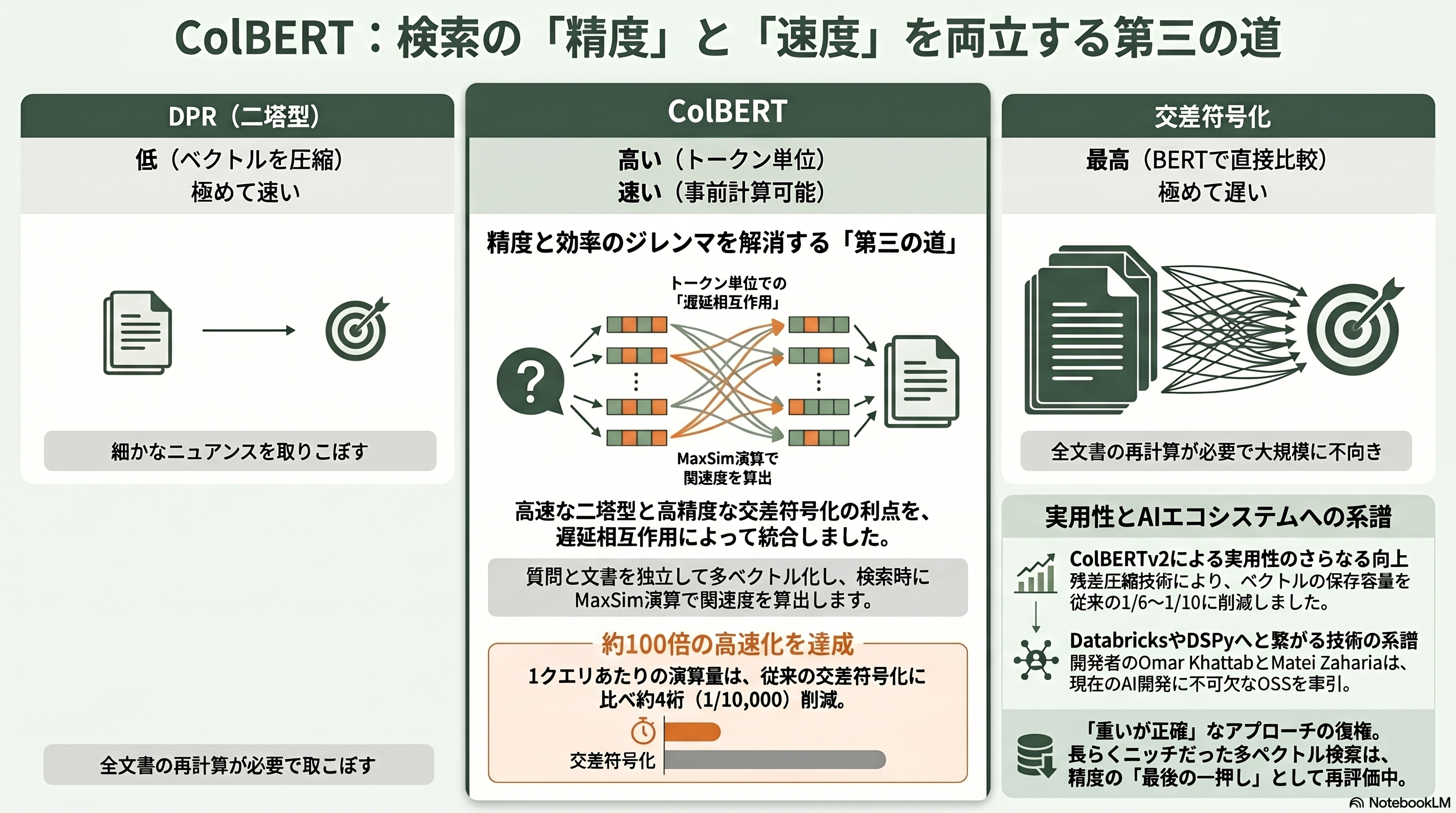
DPRの二塔型は速いが、質問と文書を一つのベクトルに潰してしまうため、細かなニュアンスを取りこぼす。逆に、質問と文書を一緒にBERTへ通す「交差符号化(クロスエンコーダ)」は精度が高いが、全文書を質問ごとに計算し直す必要があり、大規模検索には遅すぎる。この精度と効率のジレンマに、スタンフォードのOmar KhattabとMatei Zahariaが *ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT*(SIGIR 2020、arXiv:2004.12832)で第三の道を示した。
その鍵が「遅延相互作用(late interaction)」である。質問と文書を、それぞれ独立にトークン単位の複数ベクトルへ符号化しておく。文書側のベクトルはあらかじめ計算して索引に置ける。検索時には、質問の各トークンについて文書側で最も似たトークンとの類似度を取り(MaxSim演算)、それらを足し合わせて関連度とする。交差符号化のきめ細かさを保ちつつ、文書の重い計算を事前に済ませられるため、論文によればBERTの交差符号化に比べ約2桁高速で、1クエリあたりの演算量は約4桁少ない。2021年の改良版ColBERTv2(NAACL 2022)は残差圧縮でベクトルの保存量を6〜10分の1に削り、実用性をさらに高めた。
シリコンバレーの研究者にとってColBERTが面白いのは、その系譜だ。第一著者のOmar Khattabは、のちに「プロンプトを書くのではなくプログラムする」を掲げる宣言的フレームワークDSPyを生み出し、これは2026年現在Databricksに深く統合され、ShopifyやMoody'sでの採用が語られる主力OSSになった。共著のMatei ZahariaはApacheSparkの生みの親であり、現在はDatabricksの最高技術責任者(CTO)として、奇しくも教え子のDSPyを擁する立場にある。トークン単位の多ベクトル検索という「重いが正確」なアプローチは、長らくニッチ扱いだったが、近年は再評価が進み、遅延相互作用は検索精度の最後の一押しとして静かな復権を遂げている。
第5章 2020年 RAG — 「RAG」という名前と、二つの記憶の融合
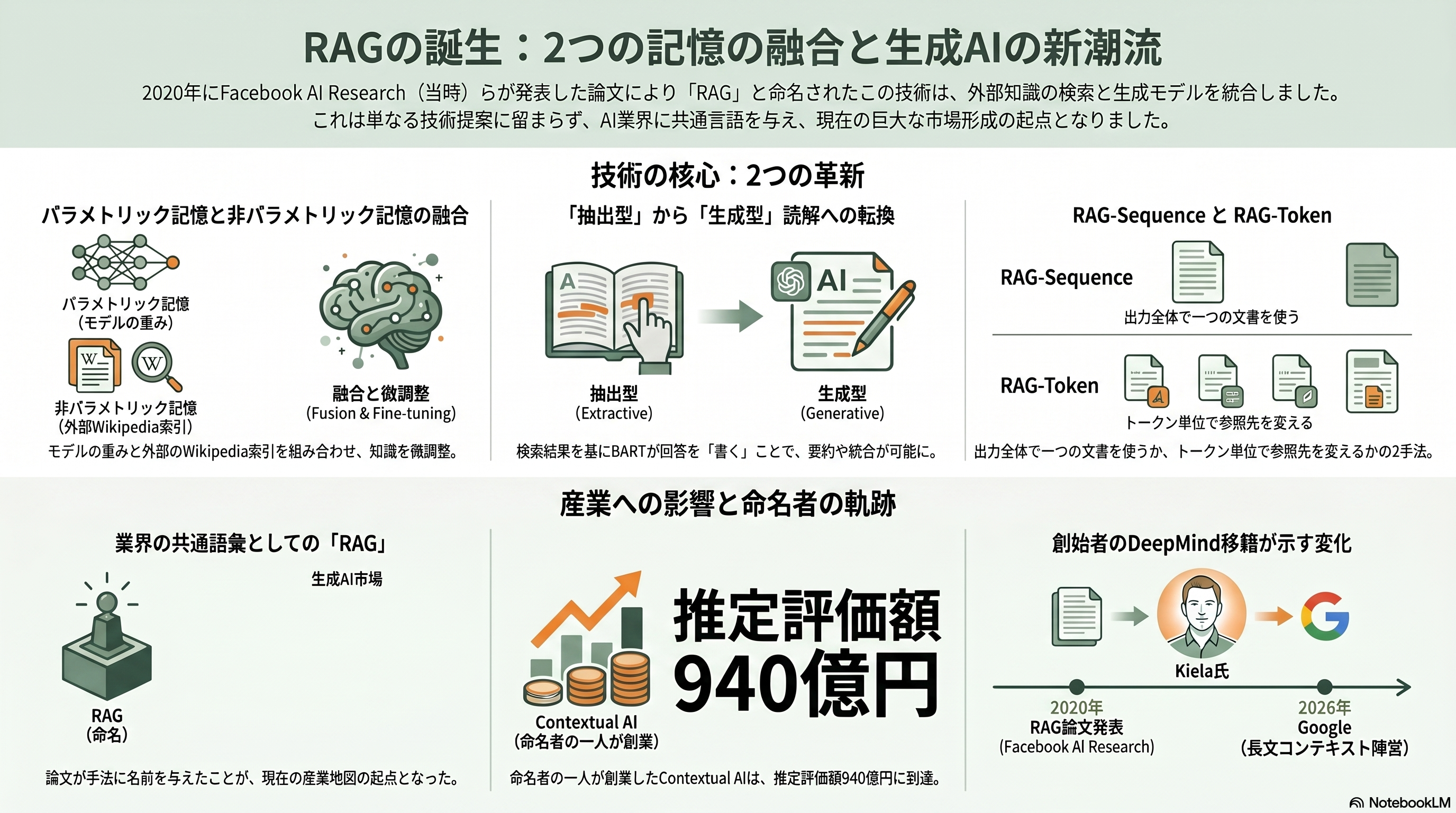
2020年、Patrick LewisらFacebook AI Research・UCL・ニューヨーク大学の混成チームが、この分野に名前を与えた。*Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks*(NeurIPS 2020、arXiv:2005.11401)である。共著者の末尾には、のちにこの分野の論争の中心人物となるDouwe Kielaの名がある。
この論文の核心は二つだ。一つは、序章で述べたパラメトリック記憶とノンパラメトリック記憶の融合を、明示的なアーキテクチャとして定式化したこと。生成モデルBARTが持つ重み(パラメトリック)と、DPRでWikipediaを引く密索引(ノンパラメトリック)を組み合わせ、両者をまとめて微調整する。もう一つは、読解器を抽出型から生成型へ転換したことだ。DrQAのように本文の語句を抜き出すのではなく、検索した複数文書を踏まえてBARTが答えを「書く」。これにより言い換えや要約、統合的な応答が可能になった。論文は二つの変種を提案した。出力全体を通して一つの文書を使うRAG-Sequenceと、トークンごとに異なる文書を参照できるRAG-Tokenである。オープンドメインQAではNatural Questionsで44.5などの当時最高水準を記録した。
研究者の視点で見れば、この論文は単に手法を提案しただけでなく、「RAG」という共通語彙を業界に与えたことに最大の歴史的意義がある。そして著者たちのその後が、現在の産業地図と直結している。末尾著者のDouwe KielaはスタートアップContextual AIを創業し、検索器と生成器を継ぎ目なく end-to-end で最適化する「RAG 2.0」を旗印に、累計1億ドル(約155億円)を調達した(PitchBookは評価額を約6億900万ドル=約940億円と推定するが、同社は非開示)。ただし2026年5月、Kiela自身は約20名の研究者とともにGoogle DeepMindへ移籍したとBloombergが報じており、RAGの命名者は皮肉にも、いま長文コンテキスト陣営の総本山に身を置いている。命名から6年、その作者たちは業界中に散り、それぞれがRAGの次章を書こうとしている。
第6章 2021年 FiD — 検索文をデコーダで束ねて「数」で勝負する
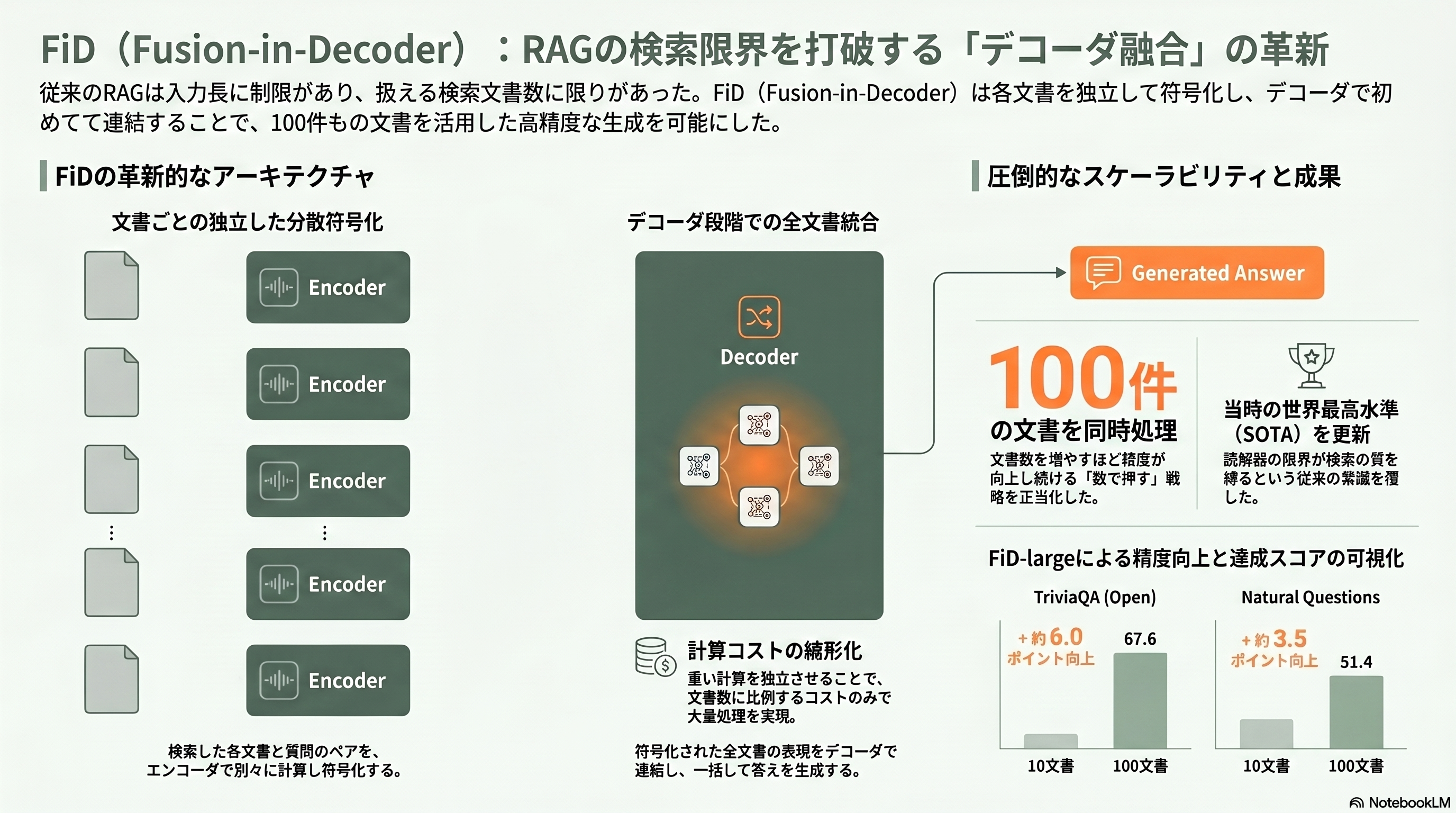
RAGの生成器は、扱える検索文書の数に限りがあった。文書を増やすほど入力が長くなり、計算が破綻するからだ。Gautier IzacardとEdouard Grave(Facebook AI Research/INRIA)は *Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering*(EACL 2021、arXiv:2007.01282)で、この制約を巧みに外した。手法の名は「Fusion-in-Decoder(FiD)」、デコーダでの融合だ。
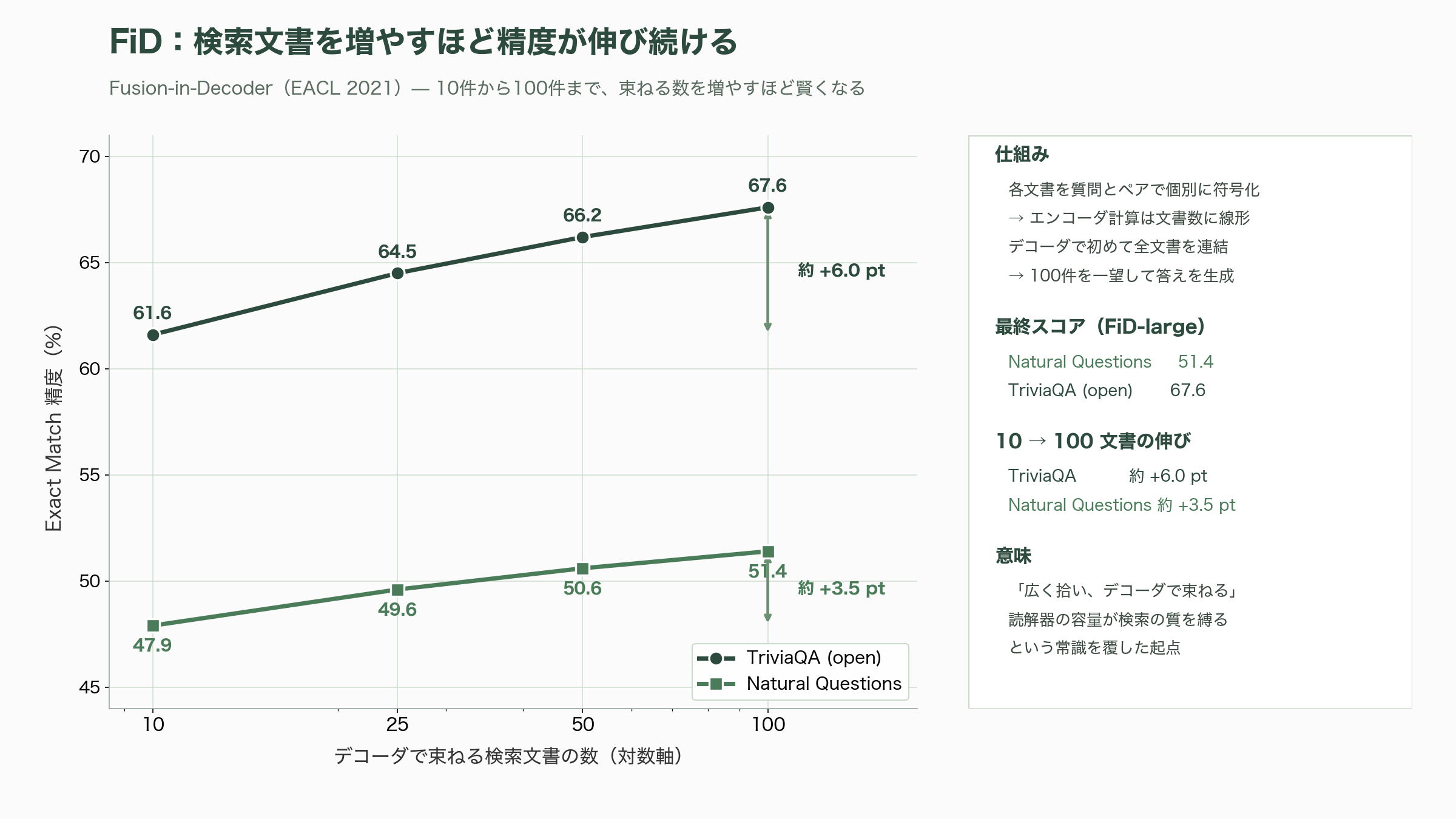
発想は単純で強力である。検索してきた各文書を、質問とペアにしてT5エンコーダで別々に符号化する。重いエンコーダの計算は文書ごとに独立なので、コストは文書数に比例して線形に増えるだけで済む。そして符号化したすべての文書の表現をデコーダの段階で初めて連結し、デコーダが全文書を一望しながら答えを生成する。融合をデコーダまで遅らせることで、100件もの検索文書を一度に扱えるようになった。重要なのは、文書数を10件から100件へ増やすほど精度が上がり続けたことだ。TriviaQAで約6ポイント、Natural Questionsで約3.5ポイントの向上が観測された。FiD-largeはNatural Questionsで51.4、TriviaQAのオープン設定で67.6と、当時の最高水準を更新した。
FiDが示した「検索量を増やすほど賢くなる」という性質は、RAGの設計思想に大きな影響を与えた。読解器のキャパシティが検索の質を縛るという従来の常識を覆し、「広く拾って、デコーダで束ねる」という方向性を正当化したのである。IzacardとGraveのコンビは、この成果を土台に次章のAtlasへと突き進む。なお、現在のLLMが長い文脈に大量の検索結果を詰め込んで答える振る舞いは、FiDが切り拓いた「数で押す」発想の延長線上にあると見ることもできる。
第7章 2021年 Contriever — ラベルなしで汎用検索器を鍛える
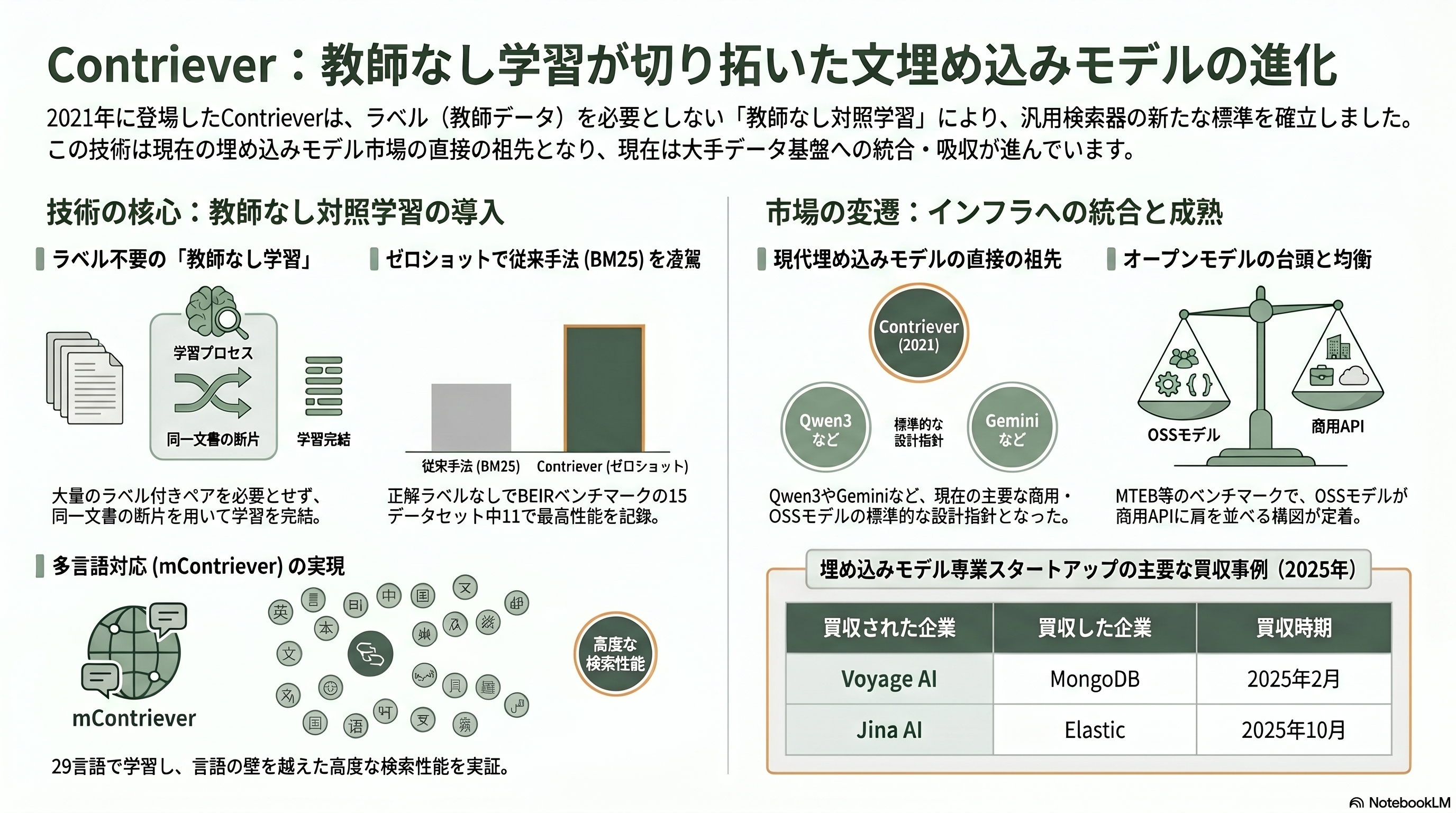
DPRの密検索は強力だが、質問と正解文書のペアという教師データを大量に必要とした。新しい分野やマイナー言語ごとにラベルを用意するのは現実的でない。Gautier IzacardらFacebook AI Researchは *Unsupervised Dense Information Retrieval with Contrastive Learning*(TMLR 2022、arXiv:2112.09118)で、この制約を教師なし学習で取り払った。
Contrieverの鍵は対照学習である。同じ文書から切り出した二つの断片を「似ているべきペア(正例)」とみなし、無関係な断片を負例として、似たものは近く・無関係なものは遠くなるよう埋め込み空間を整える。負例を大量かつ安定に供給するため、画像分野で成果を上げたMoCo(モメンタム対照学習)の枠組みを採り入れ、モメンタムエンコーダと負例キューを使う。正解ラベルを一切使わずに、ゼロショットの検索性能ベンチマークBEIRの15データセット中11でRecall@100がBM25を上回った。さらに29言語で学習した多言語版mContrieverは、言語を越えた検索でも威力を見せた。
Contrieverは、現在の埋め込みモデル市場の直接の祖先である。ラベルなしの対照学習で汎用的な文埋め込みを作るという路線は、その後の商用・OSS埋め込みモデルの標準的レシピになった。2026年現在、埋め込みの優劣を測るMTEBベンチマークでは、AlibabaのオープンモデルQwen3-Embeddingが多言語首位を占め、Googleのgemini-embedding-001が英語で先頭に立つなど、オープンモデルが商用APIに肩を並べる構図が定着した。専業勢の去就も象徴的で、Voyage AIはMongoDBに買収され(2025年2月、Bloombergは約2億2,000万ドル=約340億円と報道、MongoDBは金額非開示)、ベルリンのJina AIはElasticの傘下に入った(2025年10月)。Contrieverが示した「教師なしで賢い検索器」の理想は、いまや誰もが使うインフラ部品として、大手データ基盤の中に吸収されつつある。
第8章 2022年 RETRO — 2兆トークンから検索する
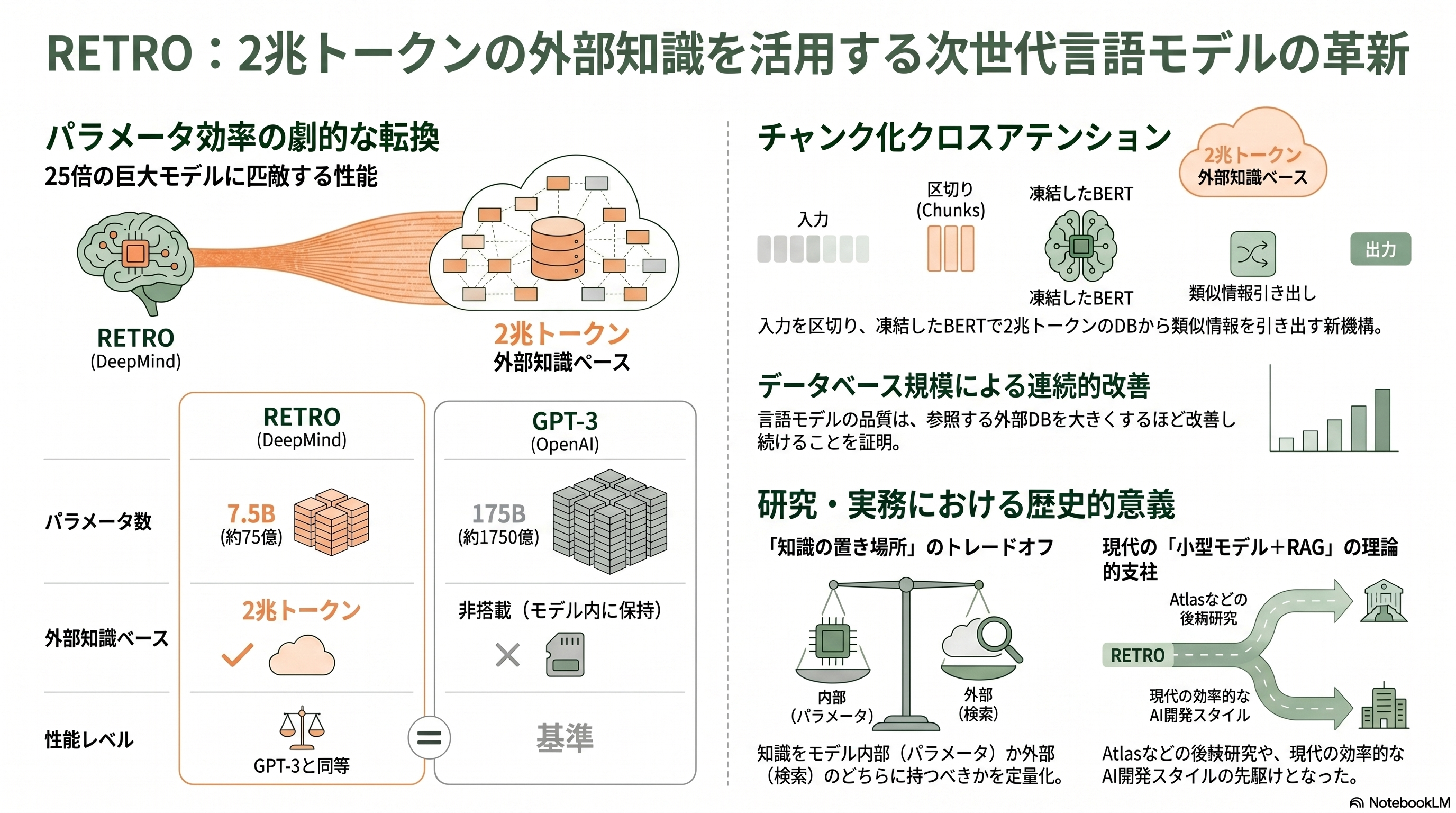
REALMが灯した「検索を事前学習に溶かす」理想を、桁外れのスケールで追求したのがDeepMindのSebastian Borgeaudら(28名)による *Improving Language Models by Retrieving from Trillions of Tokens*(ICML 2022 Spotlight、arXiv:2112.04426)、通称RETROである。
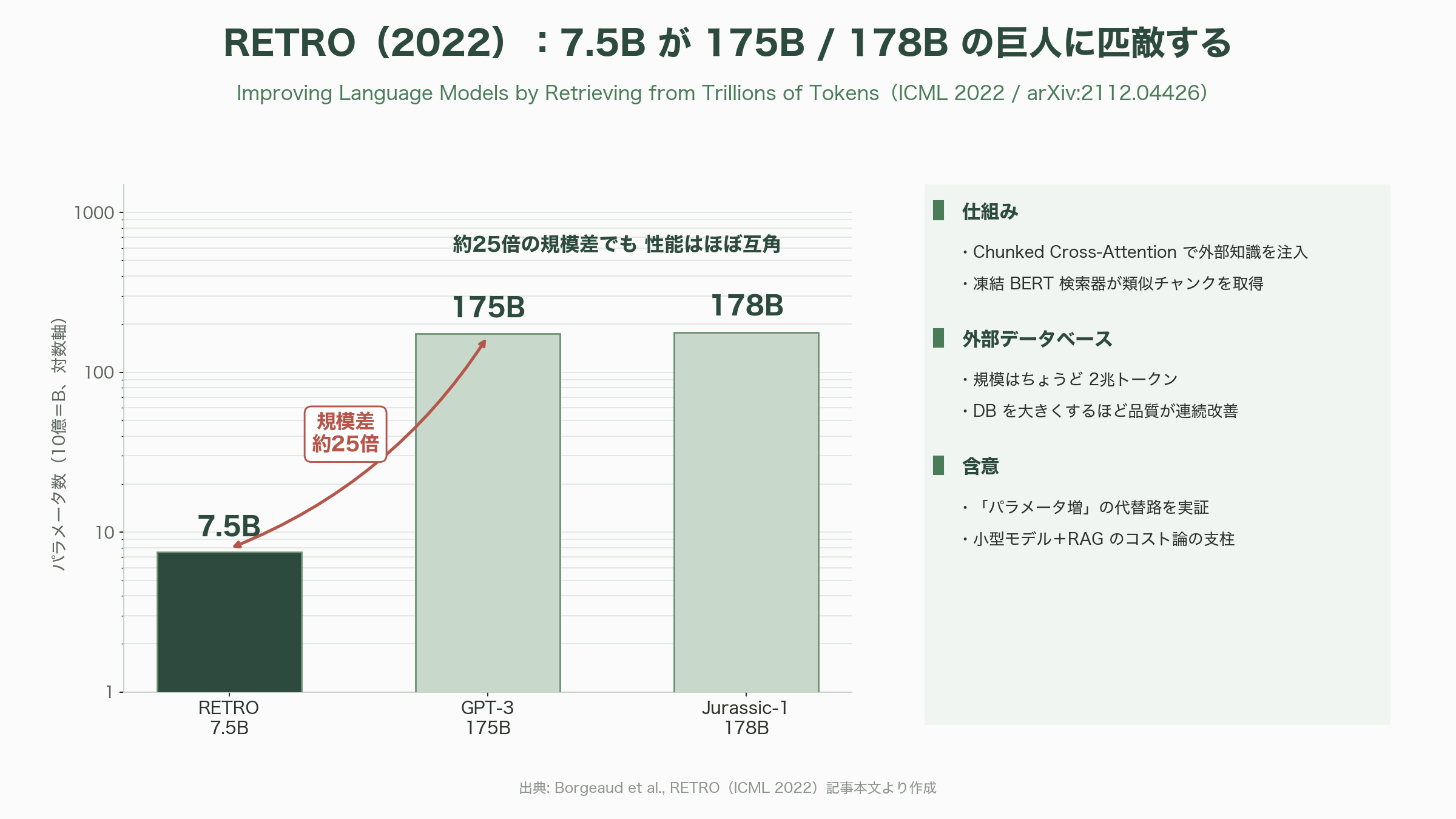
RETROは、自己回帰型のTransformerに「チャンク化クロスアテンション(Chunked Cross-Attention)」という新機構を加える。入力を一定長のチャンクに区切り、各チャンクに対して、凍結したBERT検索器が巨大な外部データベースから類似する文書チャンクを引いてきて、それを cross-attention で本体に注ぎ込む。そのデータベースの規模が、まさに論文の題名どおりちょうど2兆トークンだ。DeepMindのブログは「言語モデルの品質は少なくとも2兆トークンまで、データベースを大きくするほど連続的に改善する」と述べている。最大75億(7.5B)パラメータのRETROが、175Bや178Bという約25倍規模のGPT-3やJurassic-1に匹敵する性能を、Pileの多くの部分集合で示した。「パラメータを増やす代わりに、引ける知識を増やす」という代替路を、説得力ある形で証明したのである。
RETROは実装の複雑さゆえに、そのままの形で広く製品化されたわけではない。だが研究者にとっての意義は大きい。第一に、検索はモデルの推論時だけでなく事前学習のスケールそのものを拡張する手段になりうると示した。第二に、知識をパラメータと検索のどちらに持たせるべきかという、コストと性能のトレードオフ論を定量的な土俵に乗せた。小さなモデルに強力な検索を付ければ巨人に勝てる——この命題は、後の「小型モデル+RAG」のコスト論の理論的支柱になり、次章のAtlasで少数事例学習という形で結実する。
第9章 2022年 Atlas — 検索器と読解器を一緒に鍛え、少数事例で巨人に勝つ
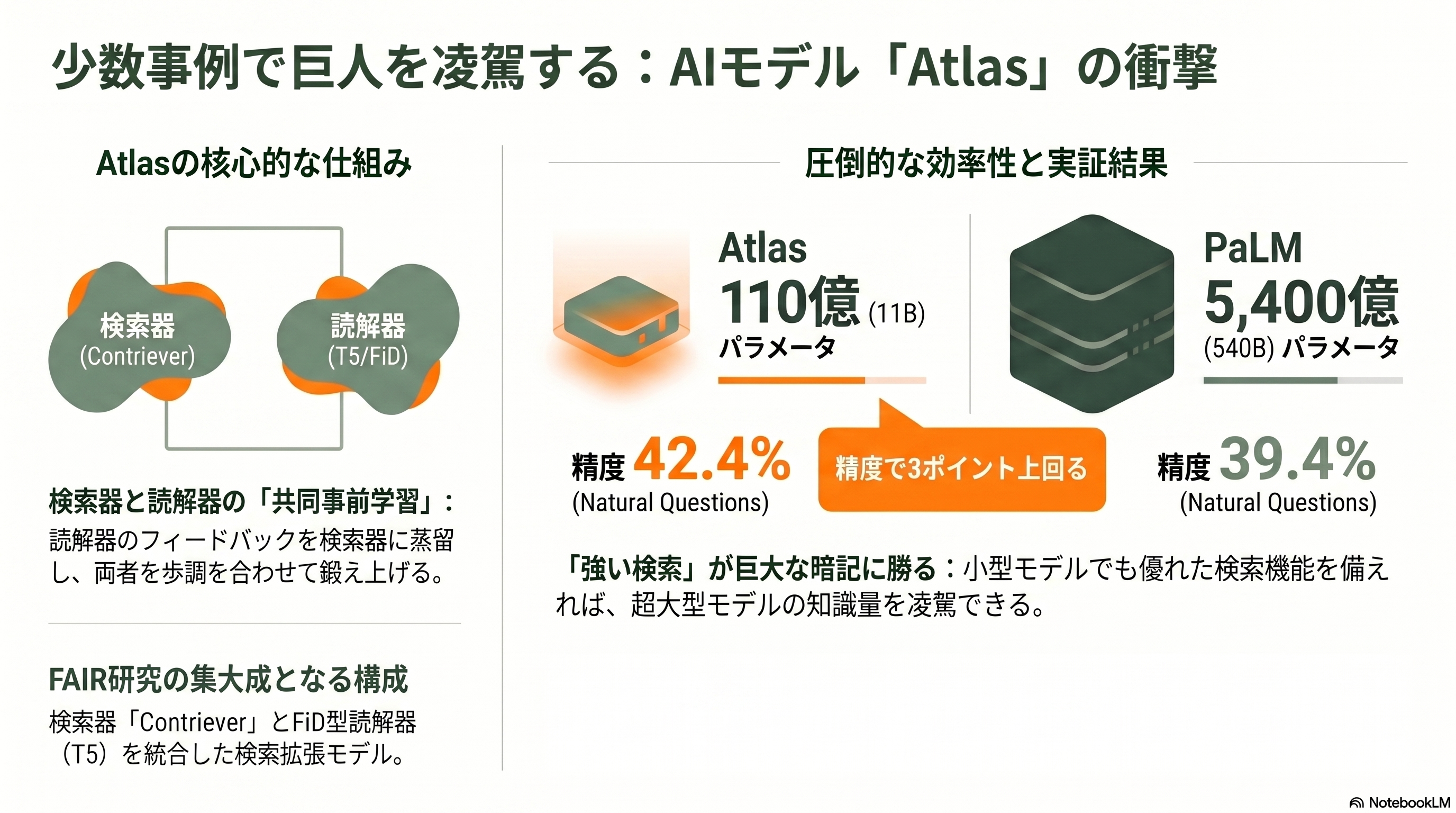
Facebook AI Researchの検索拡張研究の系譜——DPR、FiD、Contriever——を一つに束ねて頂点に押し上げたのが、Gautier Izacard、Patrick Lewisらによる *Atlas: Few-shot Learning with Retrieval Augmented Language Models*(JMLR 2023、arXiv:2208.03299)である。著者リストにはこれまでの章で登場した名前が勢ぞろいしており、まさにFAIR検索チームの集大成といえる。
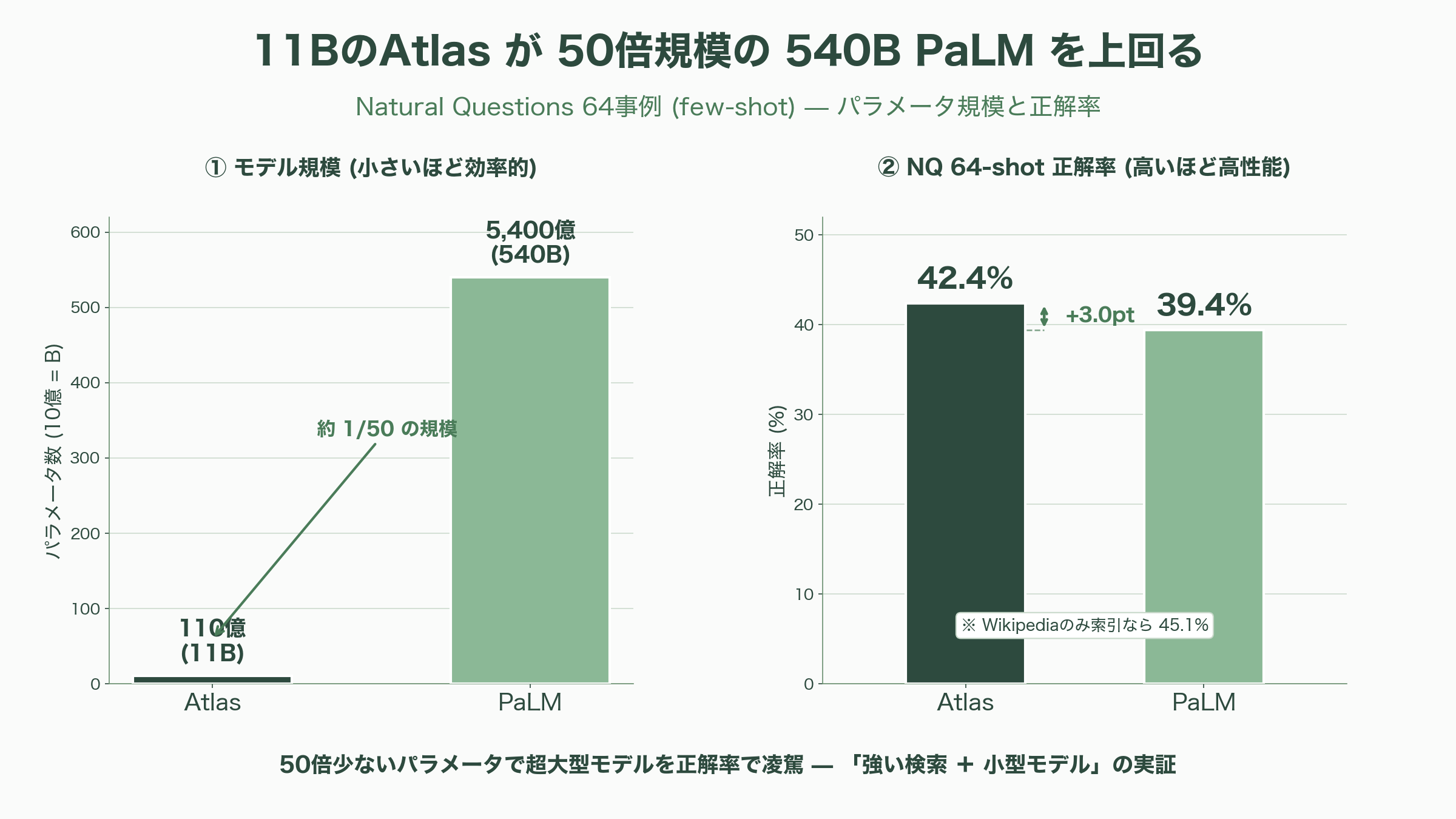
Atlasの構成は、Contrieverの検索器とFiD型(T5ベース)の読解器の組み合わせだ。その新規性は、検索器と読解器を共同で事前学習する点にある。読解器が「この文書は役に立った」と感じた度合い(注意の重みや perplexity の改善)を蒸留して検索器に伝え、両者を歩調を合わせて鍛える。狙いは、ラベルがごく少数しかない少数事例(few-shot)の知識タスクで強くなることだ。成果は鮮烈で、わずか110億パラメータのAtlasが、64事例だけ与えられたNatural Questionsで42.4%(Wikipediaのみを索引にすれば45.1%)を達成した。論文の要旨は「50倍少ないパラメータでありながら、5,400億パラメータのPaLMを3ポイント上回る」と謳う。
Atlasの含意は、いまなお実務に効いている。巨大な暗記モデルでなくとも、強い検索を備えた小型モデルが、知識タスクで超大型モデルを凌駕できる——この実証は、序章で触れたコスト論の核心そのものだ。後章で扱う「RAGは死んだのか」論争で、長文コンテキスト派に対しContextual AIのKielaらが繰り返し持ち出す「効率」の論拠は、Atlasの系譜がすでに数字で裏づけていたものである。研究の集大成が、数年後の産業論争の弾薬になっている点が興味深い。
第10章 2023年 REPLUG — ブラックボックスのLLMに検索器を後付けする
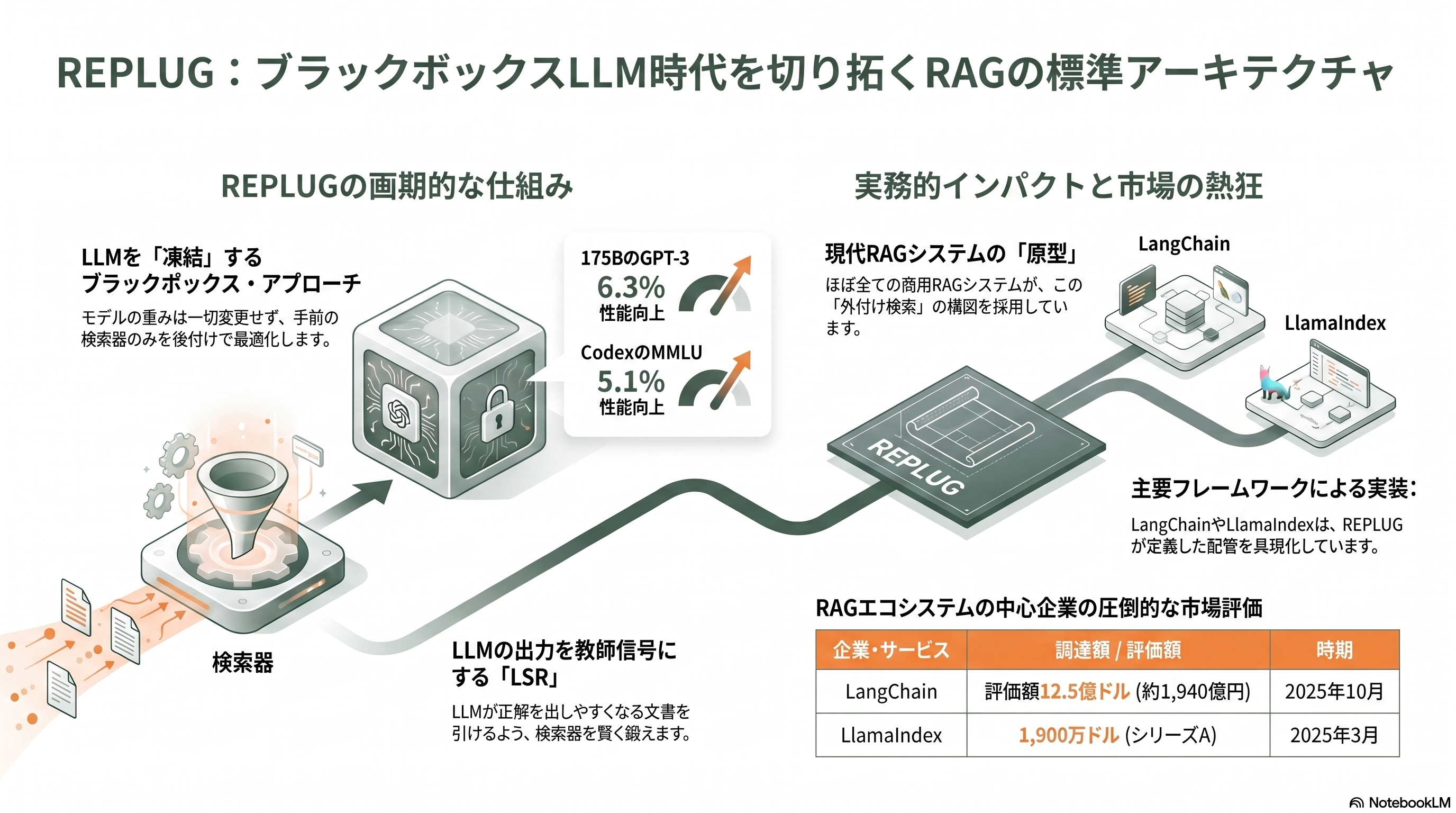
ここまでの論文の多くは、検索器と言語モデルを一緒に学習することを前提にしていた。しかし2023年、状況は一変していた。GPT-3.5やGPT-4のような最強のモデルはAPIの向こう側にあり、重みを触ることも勾配を流すこともできない。ワシントン大学とMetaのWeijia Shiらは *REPLUG: Retrieval-Augmented Black-Box Language Models*(NAACL 2024、arXiv:2301.12652)で、この現実に正面から応えた。
REPLUGの発想は、関係を逆転させることだ。LLMは凍結したブラックボックスとして一切いじらず、その手前に検索器を置いて、引いてきた文書を入力に前置するだけ。さらに巧妙なのが「REPLUG LSR(LM-Supervised Retrieval)」という変種で、LLMの出力そのものを教師信号にして検索器を鍛える。つまり、LLMが正解を出しやすくなる文書を引けるように、検索器側だけを最適化するのだ。複数の検索文書はそれぞれ別々に前置して推論し、出力確率をアンサンブルして統合する。これにより、175BのGPT-3で言語モデリング性能が6.3%、CodexのMMLU(5-shot)が5.1%向上した。
研究者の目には、REPLUGは実務RAGの原型として映る。今日、世の中で動いているRAGシステムのほぼすべてが、この「凍結したLLM+外付けの検索」という構図を取っている。LangChainやLlamaIndexといったフレームワークが提供するのは、まさにこのパターンの配管だ。LangChainは2025年10月に評価額12億5,000万ドル(約1,940億円)で1億2,500万ドル(約194億円)を調達しユニコーンとなり、LlamaIndexも2025年3月に1,900万ドル(約29億円)のシリーズAを決めた。モデルが手の届かない場所にあるという制約を、検索器の工夫で乗り越える——REPLUGが定式化したこの割り切りこそ、生成AI実装の現実的な土台になっている。
第11章 2023年 In-Context RALM — 訓練なしで「文脈に貼るだけ」の最小RAG
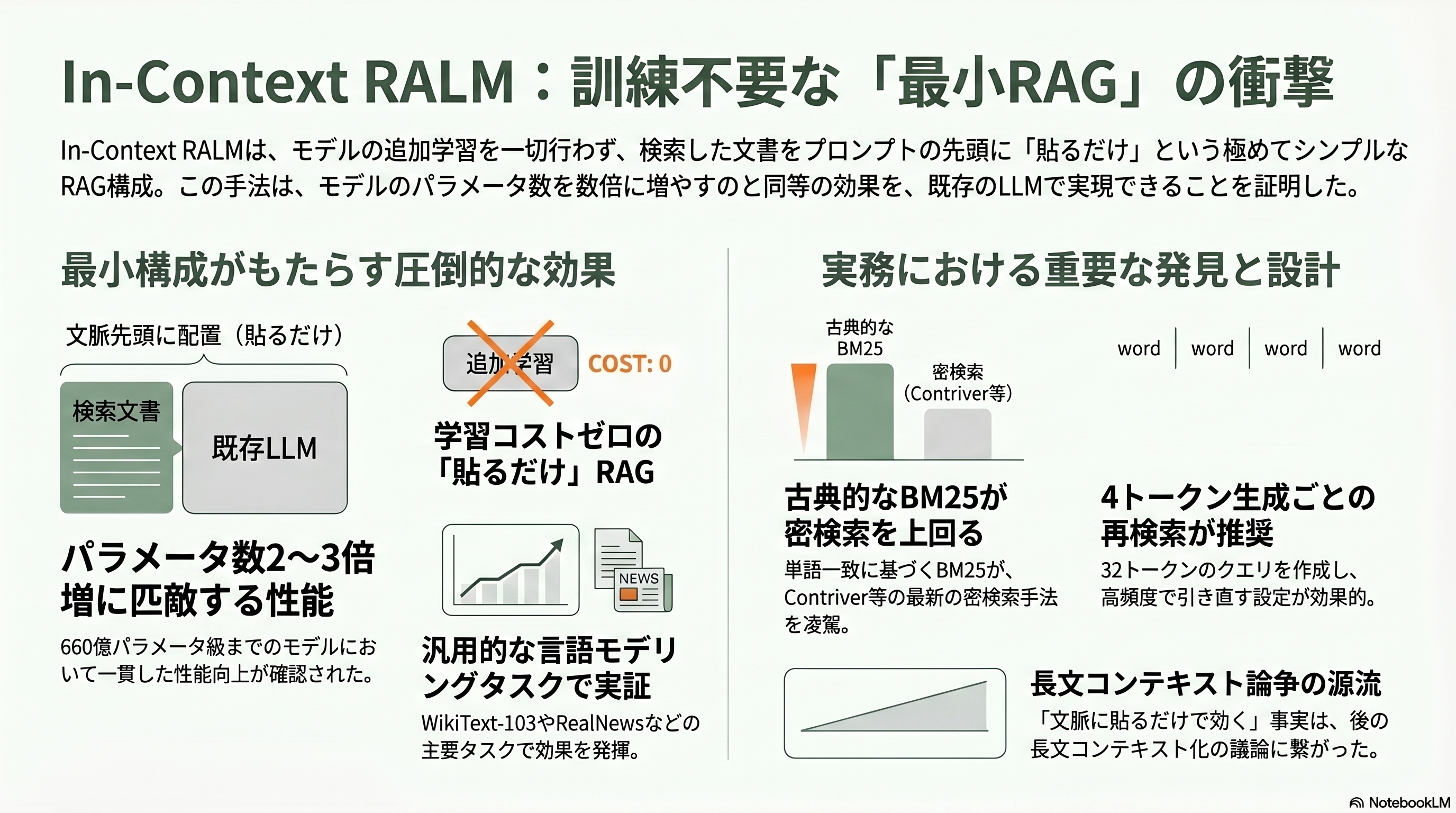
REPLUGは検索器を学習し直したが、AI21 LabsのOri Ramらは *In-Context Retrieval-Augmented Language Models*(TACL 2023、arXiv:2302.00083)で、さらに極限まで切り詰めた。何も学習しない。既製のLLMの文脈の先頭に、検索してきた文書をただ貼り付けるだけ、というミニマルな構成だ。
拍子抜けするほど単純だが、効果は本物だった。論文によれば、この「貼るだけ」RAGがもたらす性能向上は、モデルのパラメータを2〜3倍に増やすのに匹敵する。しかも660億パラメータ級までのモデルで、WikiText-103やRealNewsといった言語モデリングタスクで一貫して確認された。もう一つの重要な発見が、密検索全盛のこの時期にあって、古典的なBM25が驚くほど強いことだった。In-Context設定では、ContriverやBERT埋め込みといった密検索を、単語一致のBM25が上回ったのである。推奨設定として、BM25で32トークン分の質問を作り、4トークン生成するごとに引き直す、といった実務的な勘所まで示している。
この論文は、RAGの「最小構成」を定義した。チュートリアルで最初に教わる「文書をプロンプトに入れて聞く」という素朴なRAGは、まさにこのIn-Context RALMの形だ。AI21 Labsは共著者にYoav Shoham(スタンフォード名誉教授)を擁する老舗で、自社の大規模モデルJurassicやJambaでも知られる。そして本章には、次章以降への伏線がある。「文脈に貼るだけで効く」という発見は、裏を返せば「文脈が無限に長ければ検索などいらないのでは」という疑念の種でもあった。長文コンテキスト論争の遠い源流が、ここに芽生えている。
第12章 2023年 FLARE — 生成しながら先を読み、必要なときだけ検索する
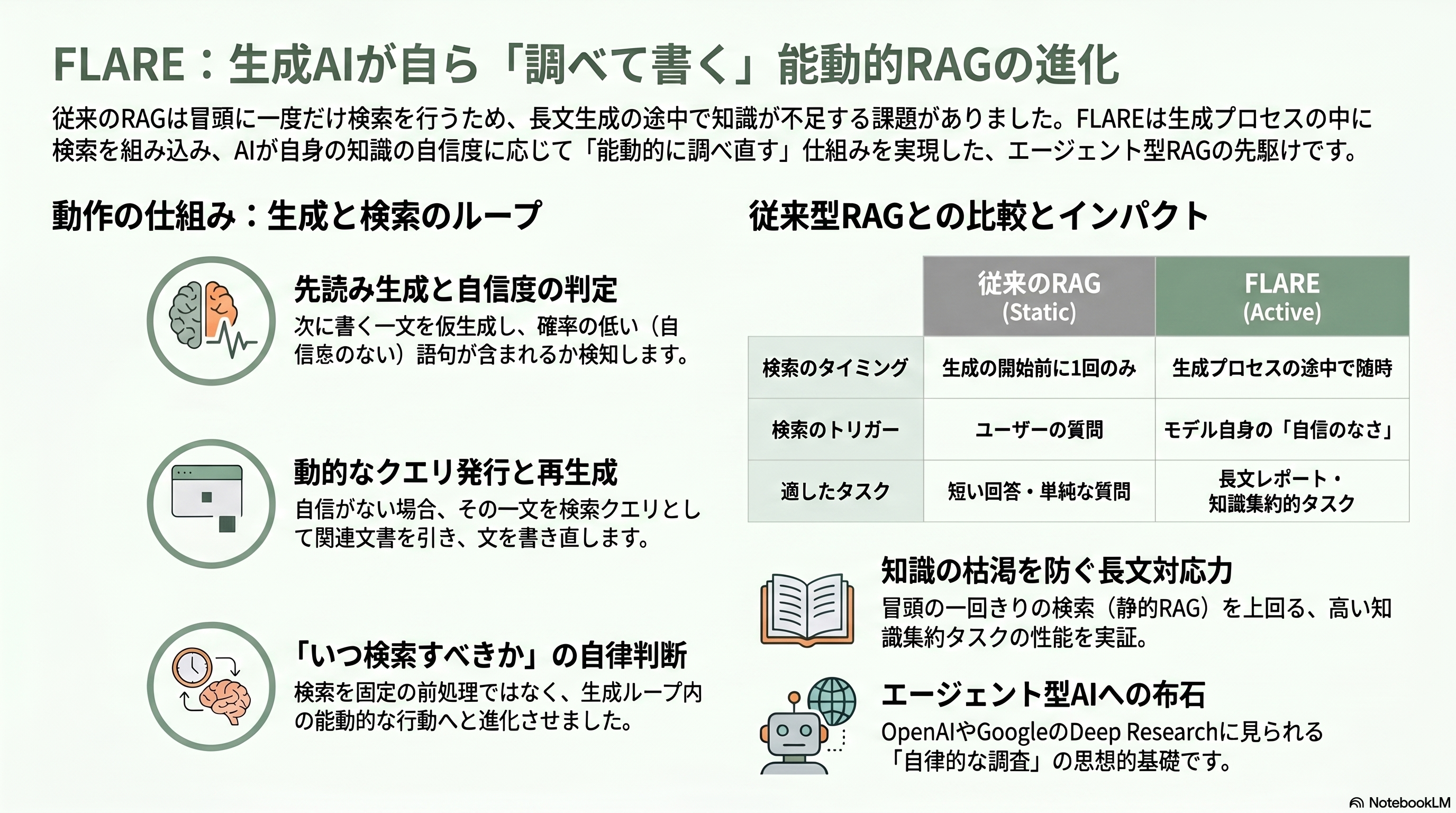
ここまでのRAGは、ほぼすべて「最初に一度だけ検索する」方式だった。短い質問なら十分だが、長い文章を書かせる場合、話が進むにつれて必要な知識は移り変わっていく。冒頭の検索だけでは途中で根拠が尽きてしまう。カーネギーメロン大学のZhengbao Jiangら(共著にGraham Neubig)は *Active Retrieval Augmented Generation*(EMNLP 2023、arXiv:2305.06983)で、検索を生成プロセスの中に織り込む能動的な方式FLARE(Forward-Looking Active REtrieval)を提案した。
FLAREの動きは人間の調べ物に似ている。モデルはまず、次に書こうとしている一文を仮に生成してみる。その仮の文に自信のない(確率の低い)トークンが含まれていたら、それは知識が足りないサインだ。そこでその仮の文を検索クエリとして使い、関連文書を引いてきて、文を生成し直す。自信があればそのまま進み、不安があれば立ち止まって調べる——この先読みと検索を、生成の間じゅう繰り返す。複数の長文知識集約タスクで、一度きり検索する方式を上回るか肩を並べる性能を示した。
研究者にとってFLAREが重要なのは、「いつ検索すべきか」を動的に決めるという発想を持ち込んだ点だ。これは、検索を固定の前処理から、生成ループに組み込まれた行動へと格上げする一歩であり、後述する「エージェント型RAG」の直接の前駆けである。実際、OpenAIやGoogleの「Deep Research」のように、AIが自ら何度も検索を繰り返して長大なレポートを書き上げる現在の製品は、FLAREが示した能動的検索の思想を大規模に実装したものと位置づけられる。第一線の研究者であるNeubigが名を連ねる本論文は、静的RAGから能動的RAGへの転回点を刻んだ。
第13章 2023年 RAGAS — 正解なしでRAGを採点する
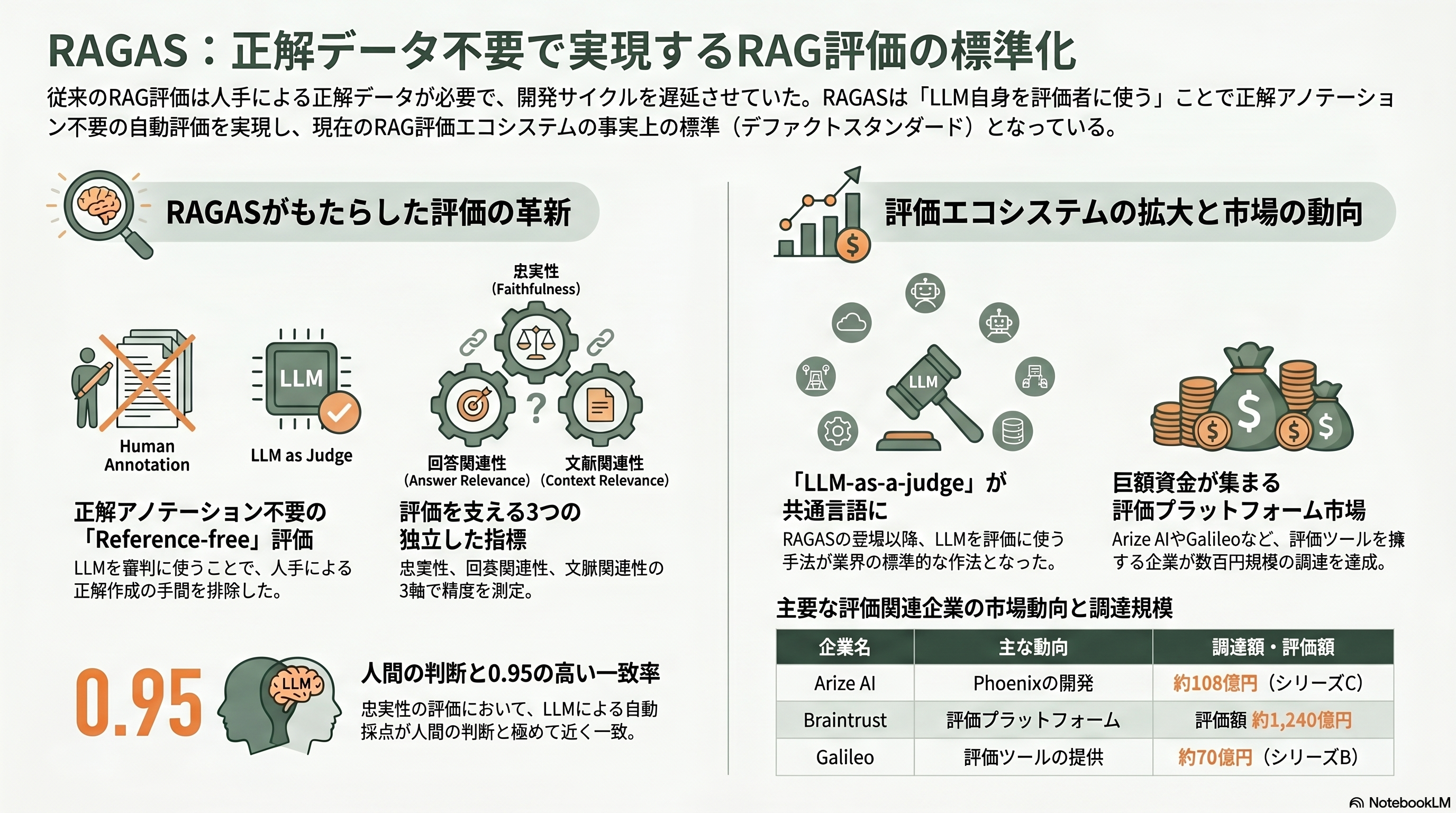
RAGシステムを作ったはいいが、その良し悪しをどう測るのか。検索が的外れなのか、生成が幻覚を起こしているのか。従来の評価は人手で作った正解が必要で、システムを少し変えるたびに採点し直すのは現実的でなかった。Exploding Gradients(現Vibrant Labs)のShahul Esらは *RAGAS: Automated Evaluation of Retrieval Augmented Generation*(EACL 2024 デモ論文、arXiv:2309.15217)で、正解アノテーション不要(reference-free)の自動評価を提案した。
RAGASの考え方は、LLM自身を採点者に使い、評価を独立した観点に分解することだ。論文が提案した指標はちょうど三つ。生成された答えが検索文書に忠実か(Faithfulness)、答えが質問に的を射ているか(Answer Relevance)、そして引いてきた文脈が質問に適合しているか(Context Relevance)である。これらをLLMで自動採点し、WikiEvalデータセットで人間の判断との一致を検証したところ、忠実性で0.95という高い一致を示した。なお、現在ragasライブラリで広く使われる「文脈精度」「文脈再現率」といった指標は、論文そのものにはなく、後にライブラリへ追加されたものである点は、正確を期すなら押さえておきたい。
RAGASは、RAG評価の事実上の標準になった。「LLMを審判に使う(LLM-as-a-judge)」というこの作法は、いまや評価エコシステム全体の共通言語だ。周辺には専門企業が群がっている。Galileoは2024年に4,500万ドル(約70億円)のシリーズBを、Arize AI(OSSのPhoenixを擁する)は2025年2月に7,000万ドル(約108億円)のシリーズCを調達し、SnowflakeはTruEra(TruLensの開発元)を買収、Braintrustは2026年2月に評価額約8億ドル(約1,240億円)で8,000万ドル(約124億円)を集めた。皮肉なことに、RAGAS本体を生んだVibrant Labs(Yコンビネータ2024年冬)は大型調達をせず、近年は長期エージェント向けの強化学習環境へと軸足を移している。標準を作った者が必ずしも市場を取るわけではない、という生成AI時代の縮図がここにある。
第14章 2023年 Self-RAG — 「検索すべきか」をモデル自身が判断する
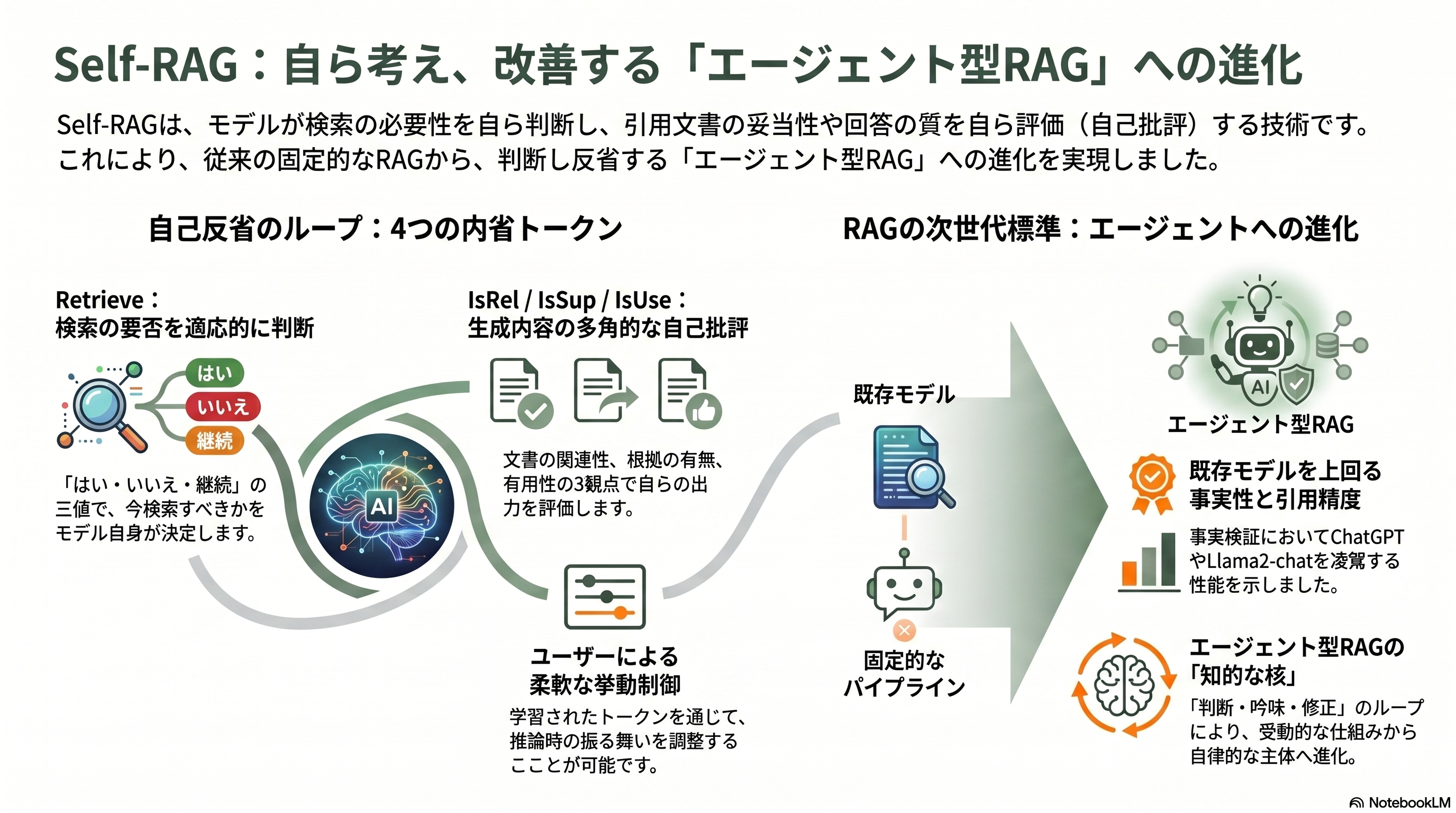
FLAREは生成の自信度から検索のタイミングを測ったが、ワシントン大学・Allen AI・IBMのAkari Asaiらは *Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection*(ICLR 2024 Oral、arXiv:2310.11511)で、その判断能力をモデルの中に学習させてしまった。
Self-RAGの主役は「リフレクション・トークン(内省トークン)」と呼ばれる特殊な制御記号だ。モデルは生成の途中で、まず「いま検索すべきか」を表すRetrieveトークンを出す。これは「はい・いいえ・継続」の三値で、常に引くのでも引かないのでもなく、必要に応じて適応的に検索する。検索した後は、引いた文書が関連するか(IsRel)、答えがその文書に裏づけられているか(IsSup、完全/部分/なしの三段階)、答えが有用か(IsUse、1〜5の五段階)という批評トークンを自ら出力し、自分の出力を自己批評する。これらの内省トークンを生成と一体で学習することで、推論時にはユーザーが挙動を制御できる柔軟さも手に入れた。7Bと13Bで公開され、オープンドメインQAや事実検証で、ChatGPTや検索拡張版Llama2-chatを上回る性能を、とりわけ事実性と引用の正確さで示した。
Self-RAGは、エージェント型RAGの知的な核である。「検索の要否を自分で決め、結果を自分で吟味し、ダメなら直す」という自己反省のループは、検索した文書を採点して必要なら検索し直すCorrective RAG(CRAG)とともに、2025年1月に出たエージェント型RAGのサーベイ(arXiv:2501.09136)が体系化した設計パターンの基礎をなす。第一著者のAsaiは、この分野で最も注目される若手研究者の一人だ。固定パイプラインから、判断し反省する主体へ——Self-RAGは、RAGが「エージェント」へと進化する扉を開けた。
第15章 2024年 GraphRAG — 知識グラフで「全体像」を問う
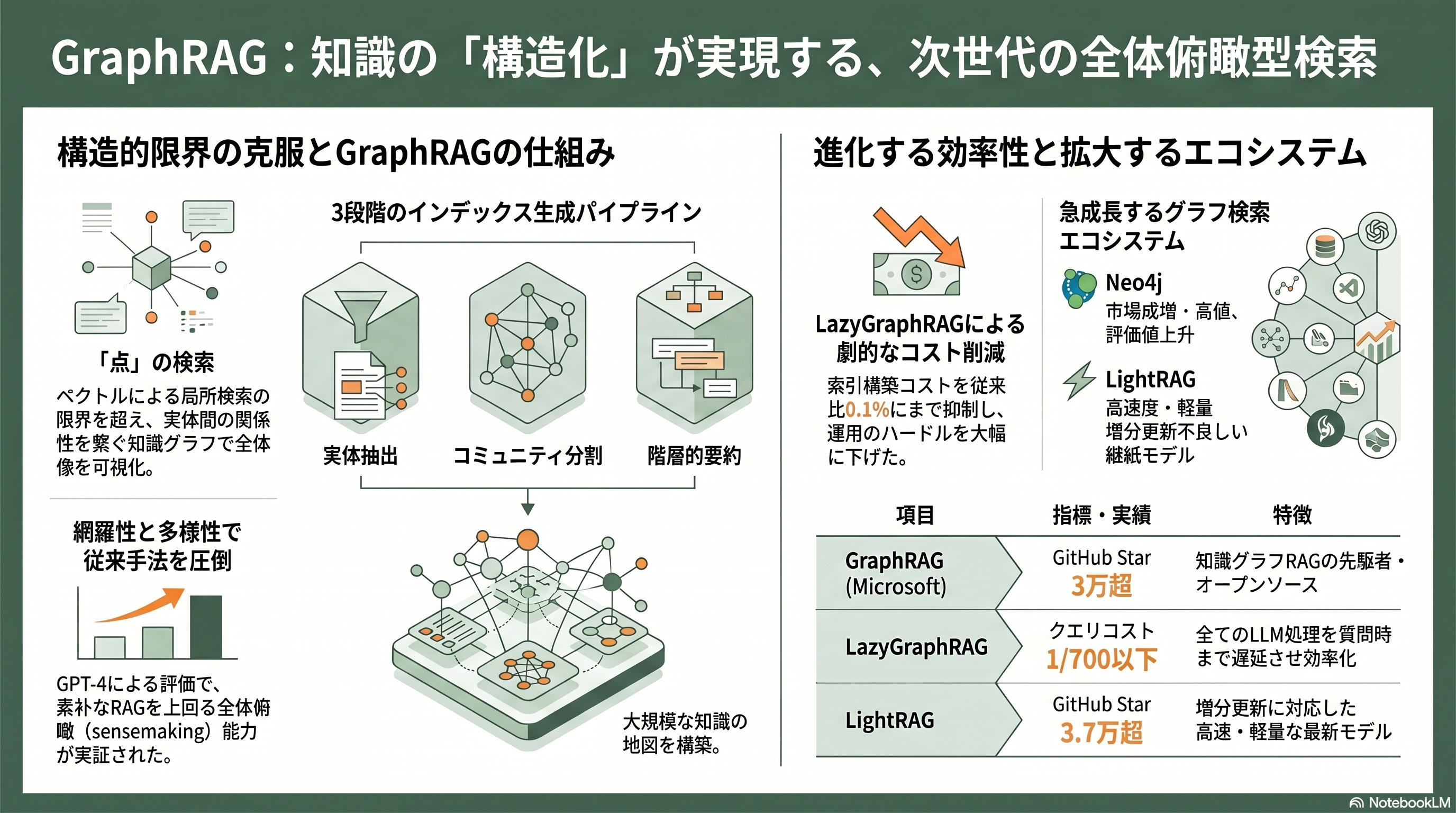
ベクトル検索ベースのRAGには、構造的な弱点がある。質問に意味的に近い数個の断片を引いてくるのは得意だが、「この資料群の全体を通して、主要なテーマは何か」といった全体俯瞰型(sensemaking)の問いには無力なのだ。答えが特定の断片ではなく、コーパス全体に分散しているからである。Microsoft ResearchのDarren Edgeらは *From Local to Global: A Graph RAG Approach to Query-Focused Summarization*(arXiv:2404.16130)で、この穴を知識グラフで埋めた。
GraphRAGのパイプラインは三段だ。第一に、LLMが文書群を読み込み、登場する実体(エンティティ)とその関係を抽出して、巨大な知識グラフを構築する。第二に、そのグラフを階層的Leiden法でコミュニティ(密に結びついた部分集合)に分割する。第三に、LLMが各コミュニティの要約をあらかじめ生成しておく。全体俯瞰型の質問が来ると、これらコミュニティ要約をマップ・リデュース方式で集約して大局的な答えを作り、個別の事実質問なら実体から局所的に辿って答える。約100万トークン規模のコーパスで、素朴なRAGを網羅性と多様性の点で上回ることが、GPT-4を審判とする評価で示された。Microsoftはこれをオープンソース化し、GitHubで3万を超えるスターを集める。
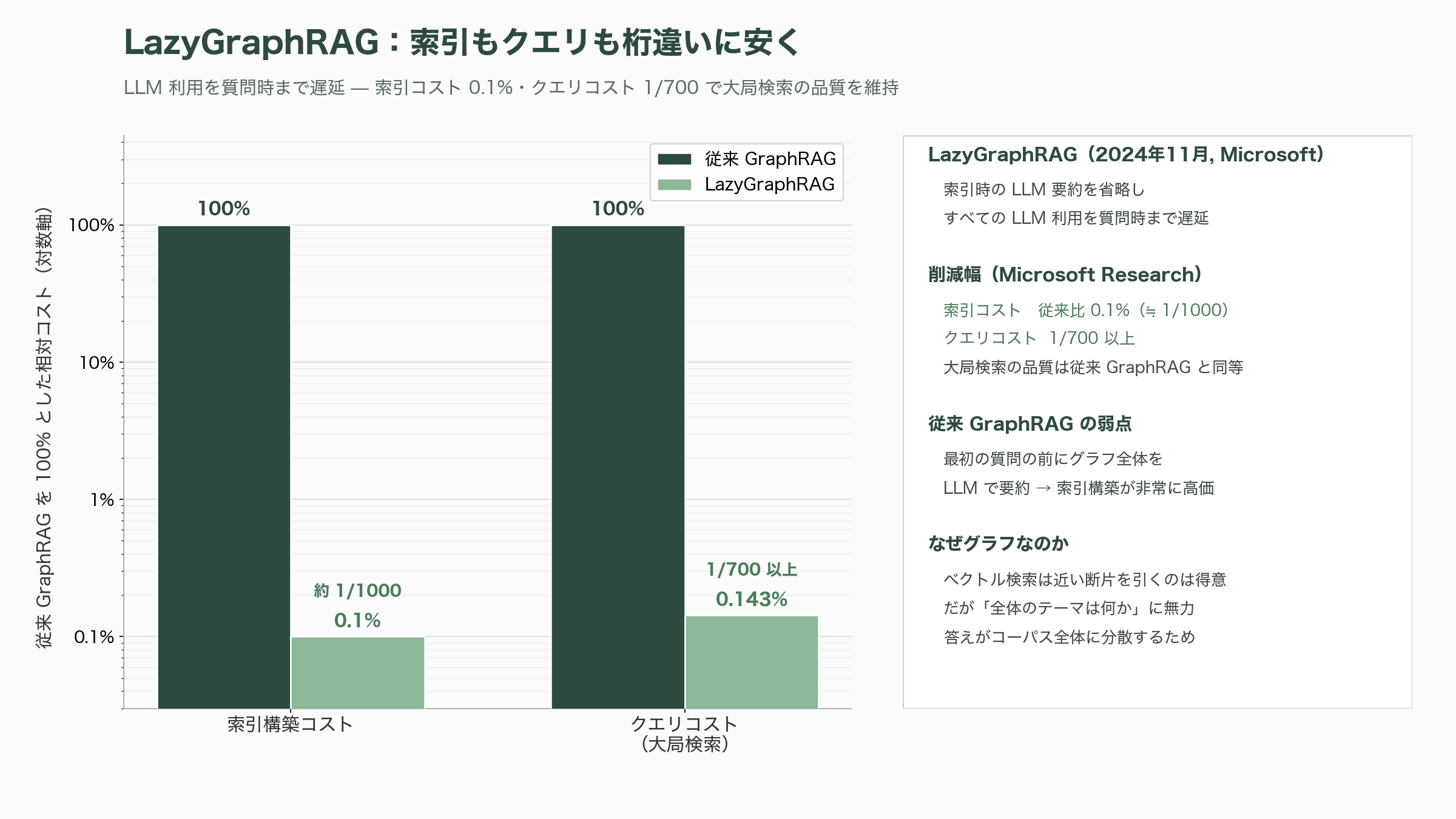
ただしGraphRAGには弱点もあった。最初の質問が来る前に、グラフ全体をLLMで要約しておく索引構築コストが非常に高いのだ。Microsoftはこれに対し、2024年11月にLazyGraphRAGを発表した。索引時のLLM要約を省き、すべてのLLM利用を質問時まで遅らせるこの方式は、Microsoft Researchによれば索引コストが従来GraphRAGの「0.1%」、大局検索に匹敵する品質を「700分の1以上のクエリコスト」で実現するという。研究者の視点では、GraphRAGは「ベクトルだけでは点と点を結べない」という根源的な限界への回答であり、構造化知識への回帰を象徴する。周辺ではNeo4j(2024年末で評価額約20〜22億ドル=約3,100〜3,400億円、ARR2億ドル=約310億円超)がグラフDBの旗手として攻勢を強め、香港大学のLightRAG(EMNLP 2025、増分更新が売りでGitHubスター約3.7万と本家を上回る)やHippoRAGといった軽量・高速な後継も相次ぐ。平坦なベクトル空間から関係の網へ——RAGの最前線は、いま知識の構造そのものへと向かっている。
終章:RAGは死んだのか
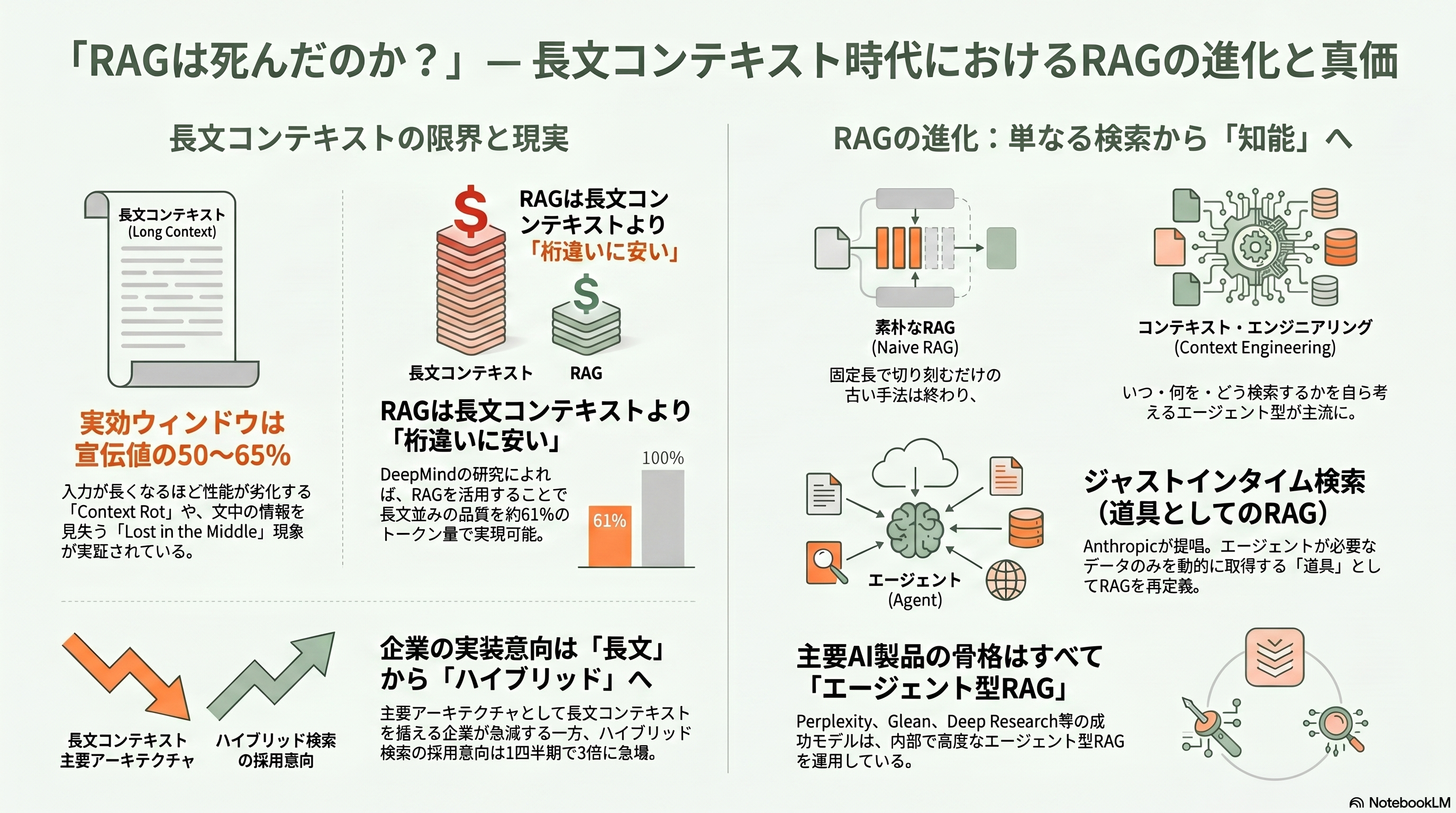
15本の論文を辿り終えたところで、避けて通れない論争に踏み込もう。「RAGは死んだ」という宣告は、実のところ周期的に繰り返されてきた。引き金はいつも、コンテキストウィンドウ(一度に読める文脈長)の拡大だ。2023年にAnthropicのClaudeが10万トークンを、2024年初頭にGoogleのGemini 1.5 Proが100万トークンを実現するたびに、「コーパス全部をプロンプトに入れられるなら、検索などいらない」という声が上がった。そして最も大きな波が、2025年4月のMetaのLlama 4 Scoutだった。1,000万トークンという前代未聞のウィンドウを掲げたこのモデルは、「RAGは死んだ」言説を一気に再燃させた。
ところが実証は、楽観論に冷や水を浴びせ続けた。Llama 4 Scoutの1,000万トークンは額面どおりには機能せず、独立評価のFiction.LiveBenchでは12万8,000トークンの読解で約15.6%にとどまり、Gemini 2.5 Proの約90.6%と惨憺たる差がついた。そもそも長文が均一に使われないことは、スタンフォード勢の「Lost in the Middle」(TACL 2024、arXiv:2307.03172)が早くに示していた。関連情報が文脈の先頭や末尾にあれば拾えるが、真ん中に置くと精度が落ちるU字曲線である。AdobeのNoLiMa(ICML 2025)は、質問と手がかりの語彙的な重なりを消すと、13モデル中11が3万2,000トークンで短文時の半分以下に崩れることを突き止めた。ベクトルDB企業Chromaの「Context Rot」(2025年7月)は、入力が長くなるほど性能が単調に劣化し、実効的に使える文脈は宣伝値の50〜65%程度だと結論づけた。Contextual AIのKielaの比喩を借りれば、「RAMが十分あるからハードディスクは要らない、と言うようなもの」なのだ。
では何が正しいのか。Google DeepMind自身の研究「Self-Route」(EMNLP 2024、arXiv:2407.16833)が、最もバランスの取れた答えを出している。潤沢に計算資源を使えば長文コンテキストは平均品質でRAGをやや上回るが、RAGは桁違いに安い。だから質問ごとに「これは検索が要るか、文脈だけで答えられるか」をモデルに判断させて振り分ければ、長文並みの品質を約61%のトークンで得られる。AlibabaとHKUSTのLaRA(ICML 2025、arXiv:2502.09977)も、その題名どおり「長文かRAGかに銀の弾丸はない(No Silver Bullet)」と結論づけ、最適解はモデル・文脈長・タスク・検索品質の絡み合いで決まると示した。
論争は2025年、新しい言葉で再定義された。「コンテキスト・エンジニアリング」である。Shopify CEOのTobi Lütkeが2025年6月18日に提唱し、その一週間後にAndrej Karpathyが「プロンプト・エンジニアリングより的を射た言葉だ」と賛同して広まった。これは、検索をコンテキストウィンドウを最適に整える技術の一部として位置づけ直す発想だ。Anthropicは2025年9月の技術ブログで、エージェントが軽い識別子だけ持ち、実行時に必要なデータをツールとして動的に引く「ジャストインタイム検索」を提唱した。つまりRAGは、検索を一度きりの前処理から、エージェントがいつでも呼べる「道具」へと組み替えられたのである。Kielaは2025年4月のブログ「RAG is dead, long live RAG!」で、そして6月のO'Reilly対談で、こう言い切った——「ハリー・ポッターの校長が誰かを知るのに、全7巻を読み返す必要があるか?」「うまくいくのはRAGと長文の両方だ。両者の二者択一など、そもそも存在しない」。
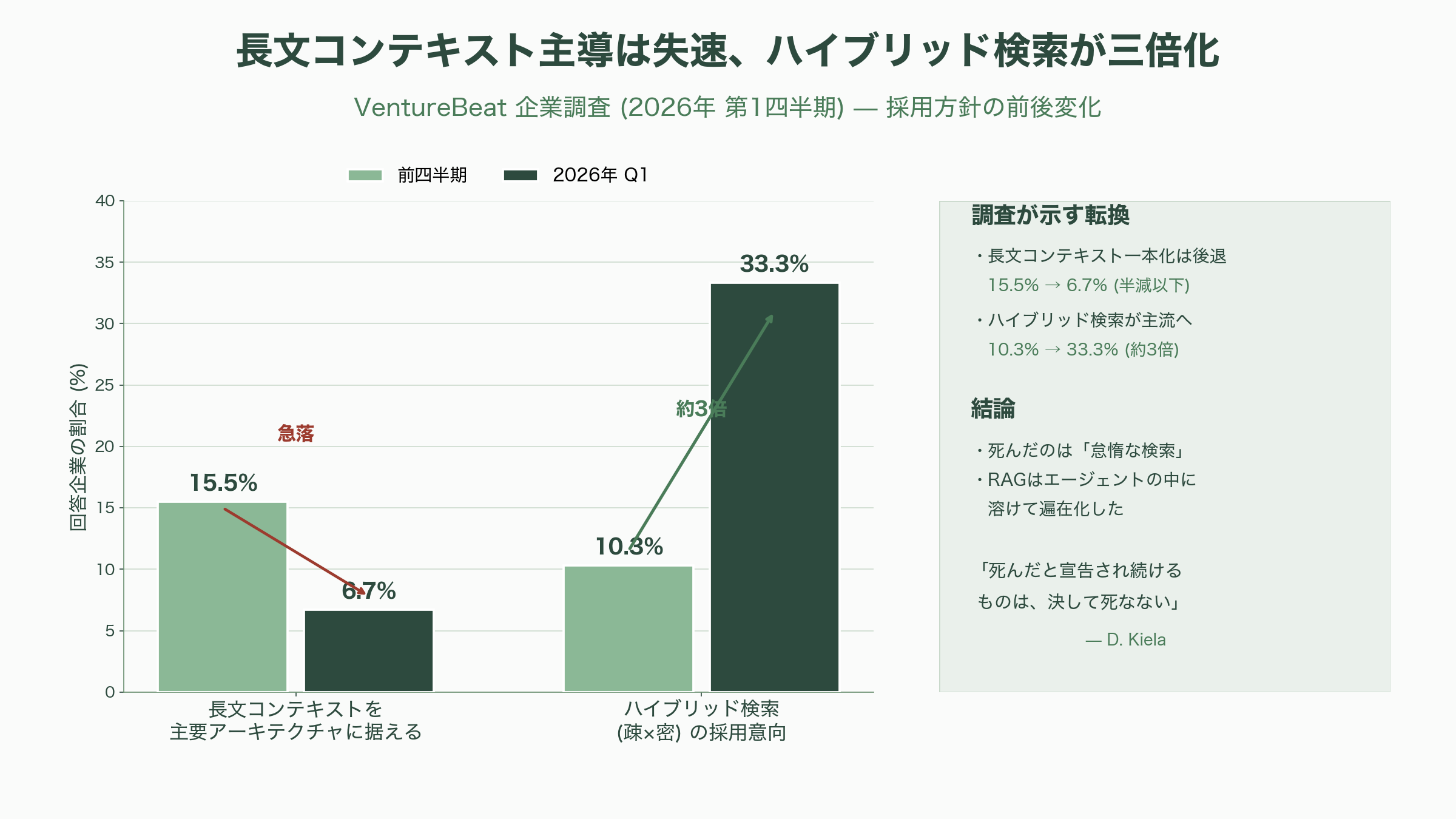
産業の現実も、この「融合」を裏づけている。VentureBeatの企業調査(2026年第1四半期)では、「長文コンテキストを主要アーキテクチャに据える」とした企業の割合が15.5%から6.7%へ急落する一方、疎検索と密検索を組み合わせる「ハイブリッド検索」の採用意向は10.3%から33.3%へと一四半期で三倍化した。そして、いま最も注目される製品群——出典付きで答えるPerplexity(2025年9月時点で評価額200億ドル=約3.1兆円、FTによれば2026年3月のARRは約4億5,000万ドル=約700億円)、社内知識を横断するGlean(2025年6月に評価額72億ドル=約1.1兆円、2026年5月にARRランレート3億ドル=約465億円)、そして各社の「Deep Research」——は、いずれも内部ではエージェント型のRAGが動いている。検索の対象が社内文書か、Webか、知識グラフかの違いはあれ、骨格は本稿が辿った「検索器+読解器」の正統な末裔だ。
結論を述べよう。死んだのは、固定長で切り刻み、闇雲に上位k件を貼り付けるだけの素朴なRAGである。長文コンテキストが殺したのは、検索そのものではなく「怠惰な検索」だった。唯一、明確な例外はコーディングだ。Jason Liuら実務家は、コードのように構造化され論理的な対象では、埋め込み検索よりエージェントによるファイル探索(grep)が勝ると論じ、この領域に限れば「埋め込みRAGは終わった」という見立てに分がある。だが全体としては、RAGは死んだのではなく、エージェントの中に溶けて遍在化した。小さなコーパス向けには、コーパス全体を一度だけ文脈に入れてキャッシュするCache-Augmented Generation(CAG)のような簡素な代替も生まれたが、企業規模のデータには届かない。2017年のDrQAが「まず検索、次に読解」と分けて以来、9年をかけてRAGが手にしたのは、いつ・何を・どう検索するかを自ら考える知性だった。論争の只中でKielaが残した一言が、この技術の生命力を言い当てている——「死んだと宣告され続けるものは、決して死なない」。