生成AIガイドラインとは何か — 政府が「使いながら守る」ための共通ルール
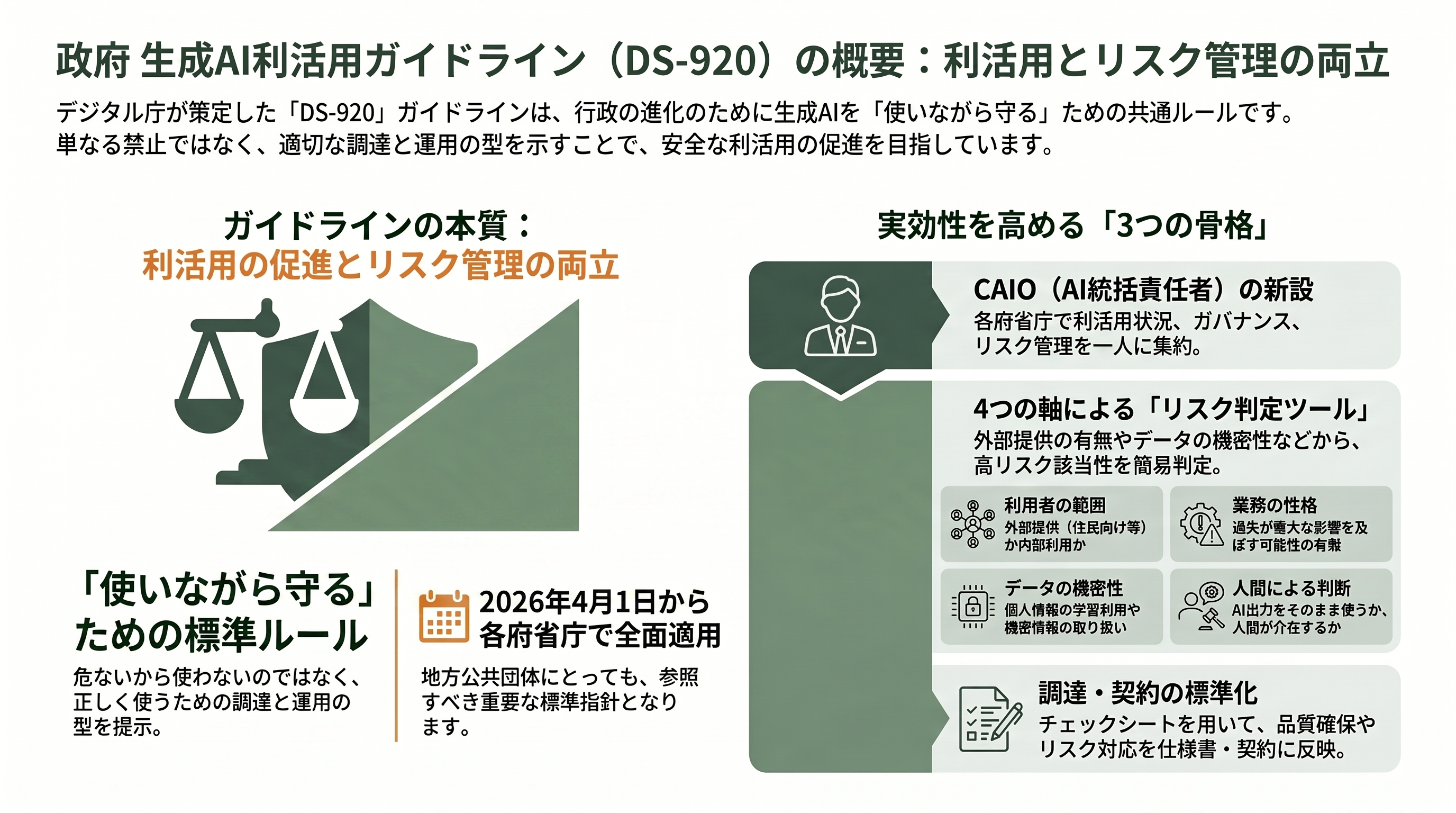
まず、今回改定された文書が何者なのかを具体的に押さえておきたい。正式名称は「行政の進化と革新のための生成AIの調達・利活用に係るガイドライン」で、デジタル庁が整備する「デジタル社会推進標準ガイドライン群」の中で「DS-920」という番号を与えられた一冊である。初版(第1.0版)は2025年5月27日にデジタル社会推進会議幹事会で決定され、経済産業省や総務省など関係省庁と協働して作られた、本文約61ページの文書だ。各府省庁にとっては「参考」ではなく従うべき標準であり、2026年4月1日から全面適用されている。地方公共団体についても、これを参考にすることが想定されている。
このガイドラインが対象にするのは、職員がブラウザで文章を要約させるような単純な利用にとどまらない。議事録の自動要約、政策立案のための調査補助、住民からの問い合わせに答えるチャットボット、申請書類のチェック、プログラムコードの生成支援といった、行政の現場で実際に立ち上がりつつある幅広いユースケースを念頭に置いている。重要なのは、その狙いが「利活用の促進」と「リスク管理」を対立物ではなく表裏一体のものとして同時に進める点にある。つまり「危ないから使うな」ではなく「正しく使えるように調達と運用の型を示す」というのが、この文書の一貫した立場だ。
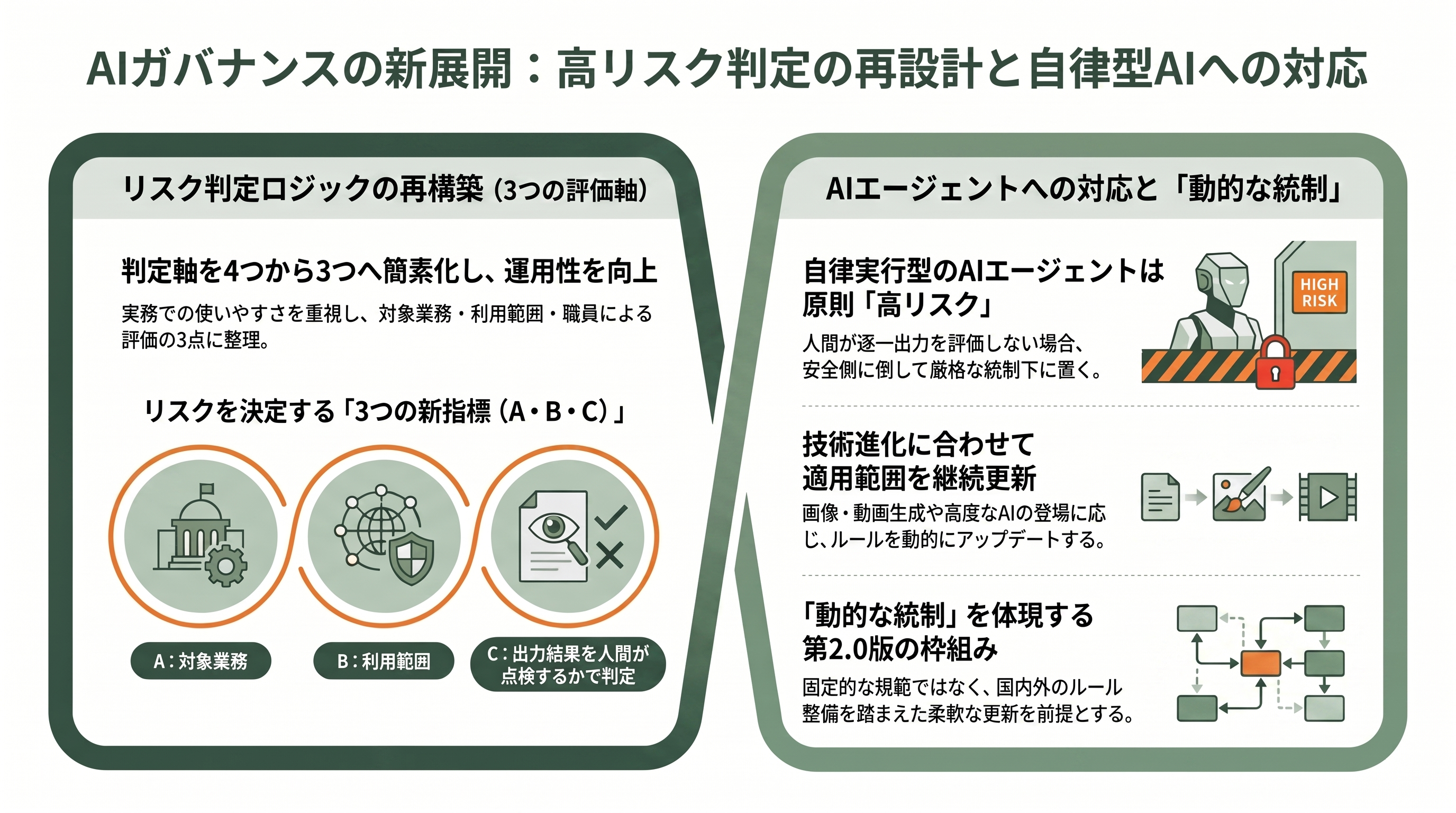
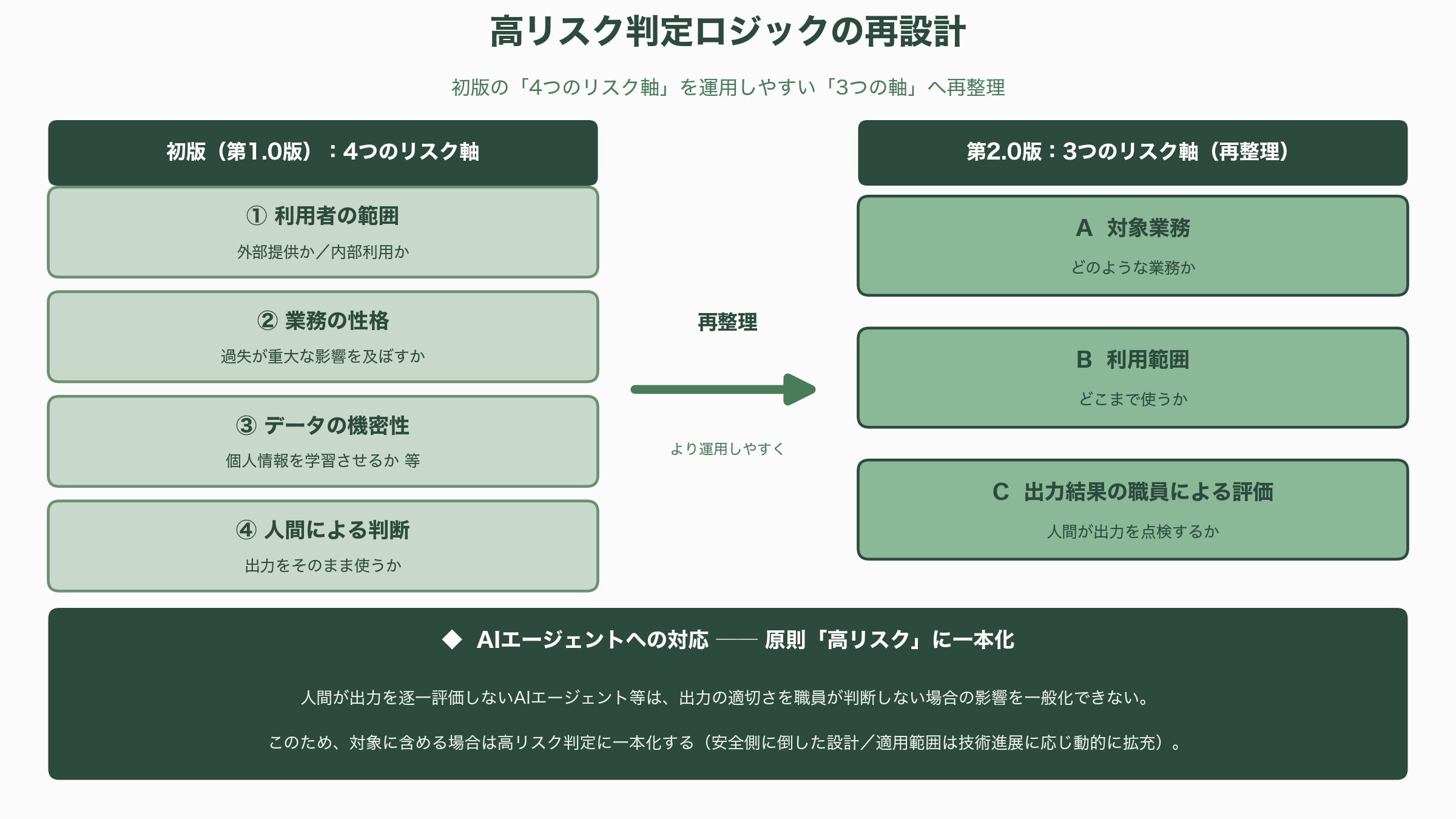
ガイドラインを貫く骨格は三つある。第一に、各府省庁にAI統括責任者(CAIO=Chief AI Officer)を新設し、生成AIの利活用状況の把握、ガバナンス、リスク管理を一人の責任者の下に束ねること。第二に、導入しようとする使い方が「高リスクに該当する可能性が高いか」を簡易に判定するためのツールを備えること。初版はこの判定を、利用者の範囲(外部提供か内部利用か)、業務の性格(過失が重大な影響を及ぼすか)、データの機密性(個人情報を学習させるか等)、人間による判断(出力をそのまま使うか)という四つのリスク軸への設問で行う設計だった。第三に、調達の現場で使う「調達チェックシート」と「契約チェックシート」を用意し、AIガバナンス、入出力やデータの適切な取り扱い、偽・誤情報の出力防止を含む品質確保、生成AI特有のリスクが顕在化した際の対応確保といった観点を、仕様書や契約に落とし込めるようにしたことである。
ここで混同しやすいのが、経済産業省と総務省が所管する「AI事業者ガイドライン」との違いだ。後者がAIを開発・提供・利用する民間事業者全般に向けた共通指針であるのに対し、デジタル庁のこのDS-920は、あくまで「政府自身が生成AIをどう買い、どう使うか」に焦点を絞った、いわば発注者・利用者としての政府のための手引きである。政府が巨大な需要側として明確な要求事項を示すことは、市場に対して事実上の標準を発信する行為でもある。この「調達を通じた標準形成」という性格が、第2.0版でいっそう前面に出てくることになる。
なぜ1年での改定だったのか — 前提が変わった
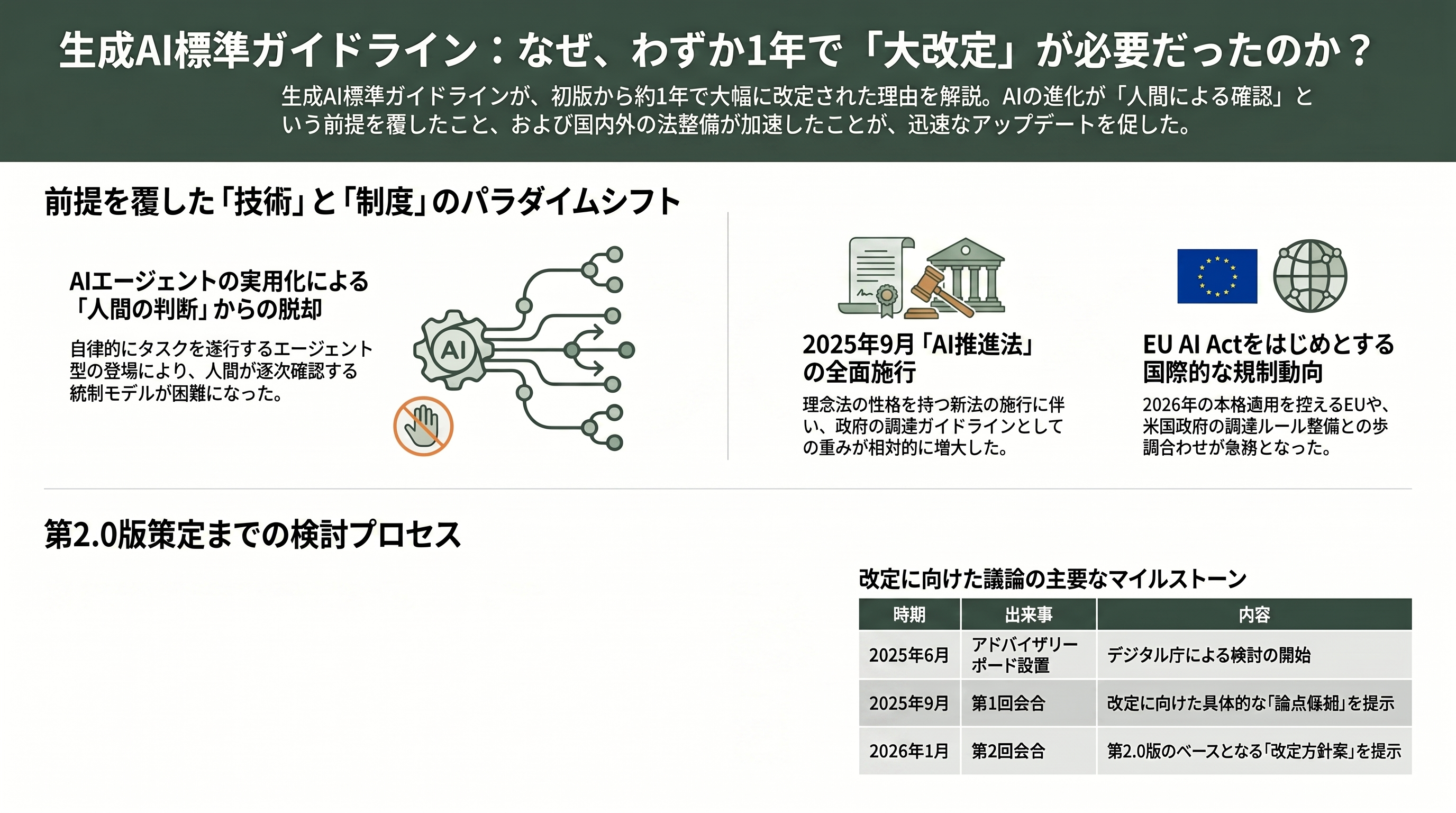
標準ガイドラインが約1年で大改定されるのは異例である。その理由は、初版が想定していた「生成AIの姿」そのものが、この1年で大きく変わったことにある。
技術面で最も大きいのは、AIエージェントの実用化だ。初版が主に想定していたのは、人間が指示(プロンプト)を入力し、出力された文章を人間が確認して使う、という比較的単純なループだった。しかし2025年から2026年にかけて、AIが複数のツールやシステムを自律的に呼び出し、人間の逐一の確認を介さずにタスクを連鎖的に遂行する「エージェント」型の利用が現実味を帯びてきた。出力を人間が必ず点検するという前提が崩れれば、初版の四つのリスク軸のうち「人間による判断」を起点にした統制は機能しにくくなる。
制度面では、2025年9月に「人工知能関連技術の研究開発及び活用の推進に関する法律」(通称AI推進法、AI新法)が全面施行された。この法律は罰則を伴う規制法ではなく、内閣にAI戦略本部を置き、政府がAI基本計画を策定して研究開発と活用を後押しする「基本法+理念法」の性格を持つ。直接の義務づけが少ない分、政府自身が範を示す調達ガイドラインの重みは相対的に増す。さらに海外では、後述するようにEUのAI Actが2026年8月に高リスクAIや透明性義務の本格適用を控え、米国でも連邦・州レベルで政府調達ルールの整備が進んでいた。
こうした変化を受け、デジタル庁は2025年6月に有識者による「先進的AI利活用アドバイザリーボード」を設置し、改定の検討を本格化させた。同ボードは2025年9月18日の第1回で「論点候補」を、2026年1月13日の第2回で「改定方針案」を示し、各府省庁の利活用状況や内外の動向を踏まえた議論を重ねている。第2.0版は、この約半年の検討の成果が結実したものだといえる。
第2.0版の核心 —「禁止」から「動的な統制」へ
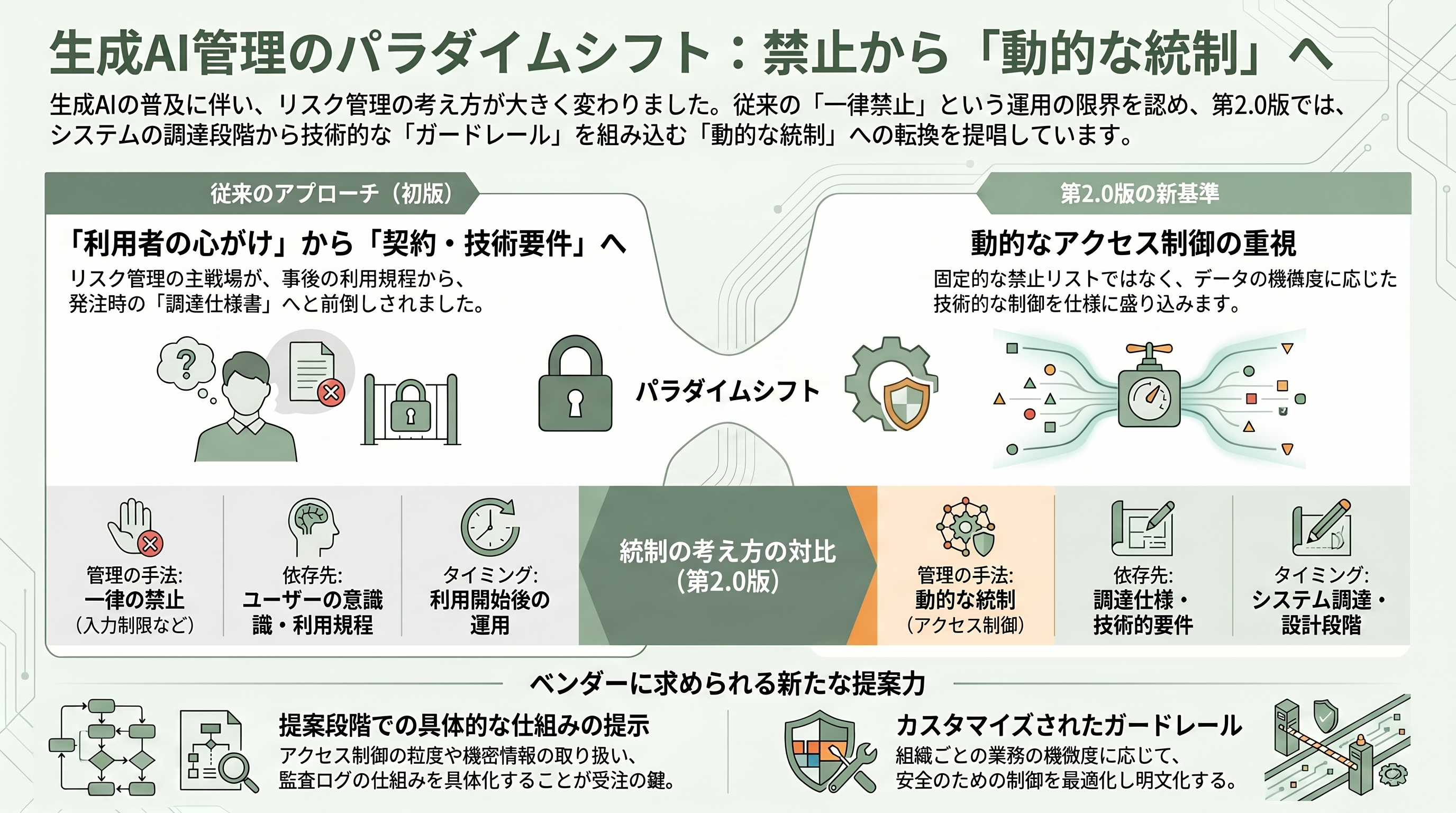
第2.0版を一言で表すキーワードが「禁止から動的な統制へ」である。DXマガジンはこの改定の本質を、まさにこの言葉で要約している。
初版的な発想では、リスクへの対処はしばしば「機密情報は入力しない」「この用途には使わない」といった、あらかじめ線を引いた一律の禁止ルールに依存しがちだった。しかしAIが自律的にシステム間を動き回り、扱える情報や実行できる操作が動的に変わっていく時代には、固定的な禁止リストはすぐに陳腐化する。そこで第2.0版は、統制の重心を「何を禁止するか」から「どのデータまでアクセスを許すか(アクセス制御)」「機密情報の入力や学習をどう防ぐか」へと移し、しかもそれを利用開始後の運用任せにするのではなく、調達段階の仕様書で握るべきだとする方向を打ち出した。
この転換が現場にもたらす含意は大きい。組織ごとに、扱う業務の機微度に応じてガードレール(安全のための制御)をカスタマイズし、それを発注時の要求事項として明文化することが求められる。言い換えれば、生成AIのリスク管理が「利用者の心がけ」や「事後の利用規程」から、「調達仕様という契約上の技術要件」へと前倒しされたのである。これは、AIシステムを構築・提供するベンダーにとって、提案段階でアクセス制御の粒度、機密情報の取り扱い、ログと監査の仕組みを具体的に示せるかどうかが受注の分かれ目になることを意味する。
高リスク判定の再設計とAIエージェントへの対応
思想転換は、リスク判定ロジックの作り替えという具体的な形でも現れている。
第2回アドバイザリーボードで示された改定方針案は、初版の四つのリスク軸を、より運用しやすい三つの軸へと再整理する方向を示した。すなわち、A=対象業務(どのような業務か)、B=利用範囲(どこまで使うか)、C=出力結果の職員による評価(人間が出力を点検するか)という三軸である。注目すべきは、AIエージェントのように人間が出力を逐一評価しないケースの扱いだ。改定方針案は、「重大な影響がない」とされる業務であっても、出力の適切さを職員が判断しない場合の影響を現時点で一般化することは困難であるとして、AIエージェント等を対象に含める場合は高リスク判定に一本化する考え方を示している。要するに、自律実行型のAIは原則として手厚い統制下に置く、という安全側に倒した設計だ。
加えて、画像や動画を生成するAI、より高度なタスクを実行できるAIエージェント等については、政府における利活用状況や国内外のルール整備の進展を踏まえ、ガイドラインの適用範囲そのものを必要に応じて拡充していく方針も示されている。つまり第2.0版は、現時点で完成した固定的な規範というより、技術の進展に合わせて適用範囲とリスク判定を継続的に更新していく「動的な枠組み」として設計されている。この姿勢自体が、「動的な統制」という今回の標語を制度設計のレベルで体現しているといえる。
ガバメントAI「源内」という実装 — ガイドラインが動く現場
第2.0版を空文に終わらせないための実装が、政府AI基盤「源内(げんない)」である。ガイドラインが「ルール」だとすれば、源内はそのルールが実際に動く「現場」にあたる。
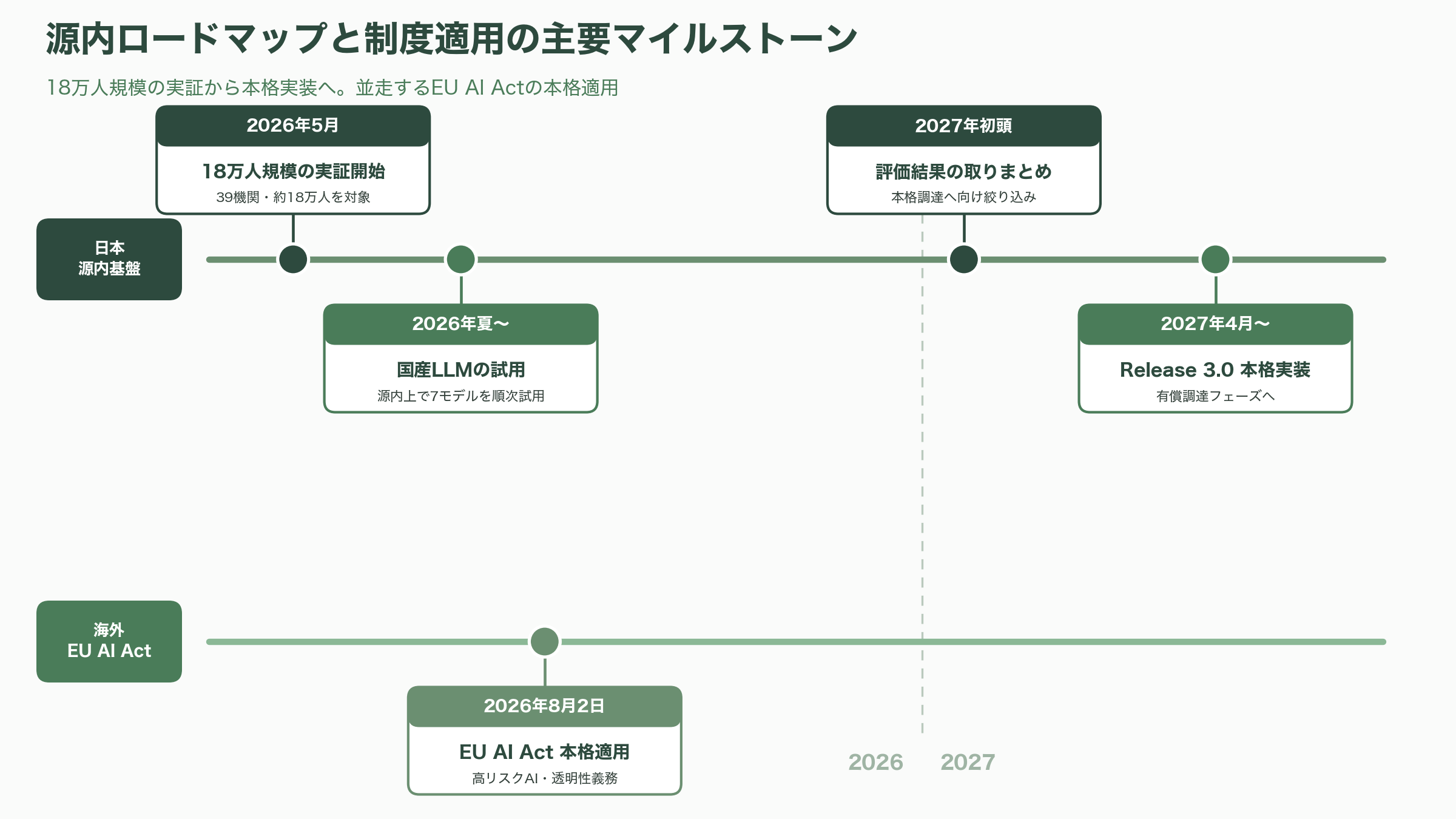
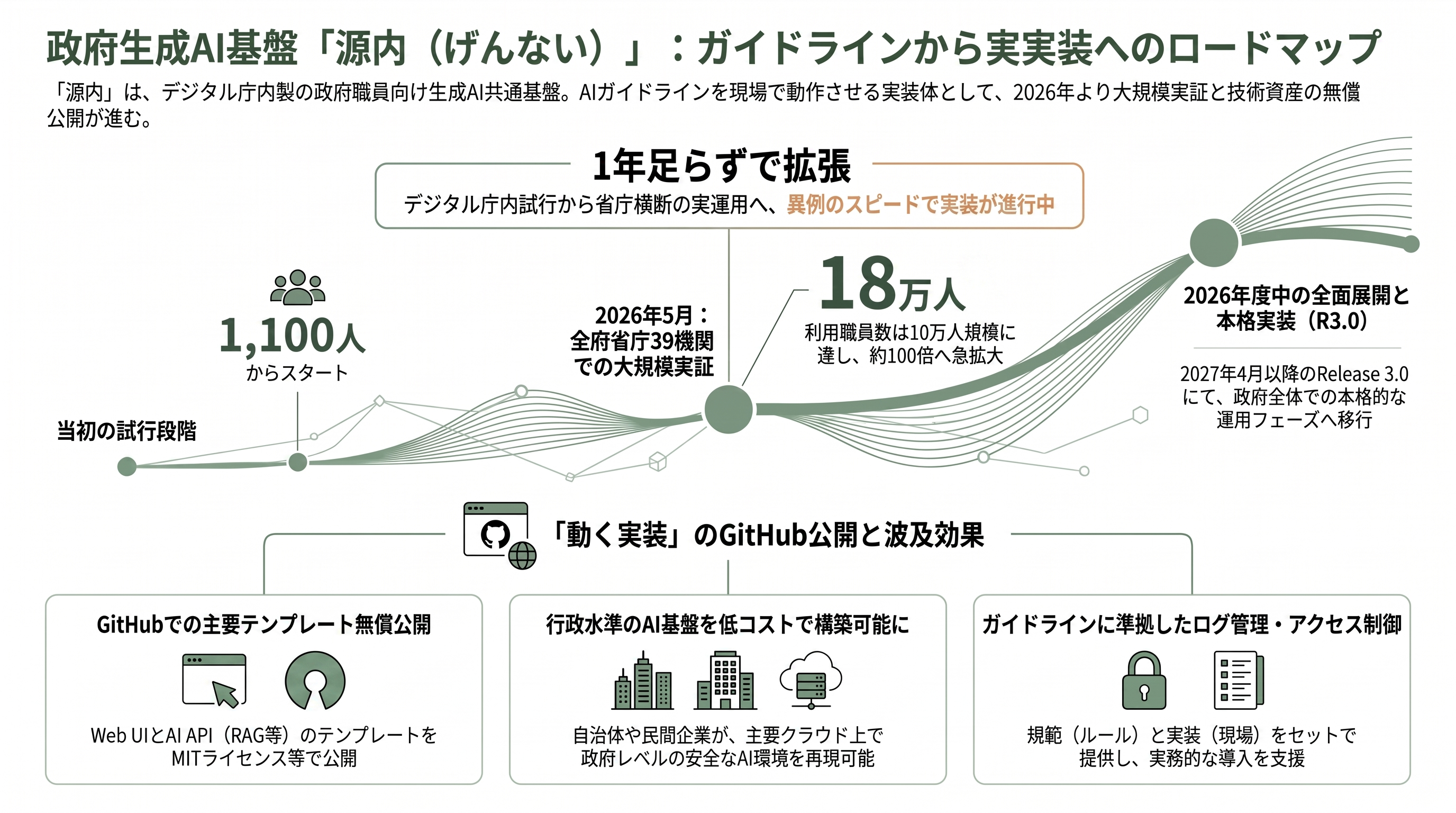
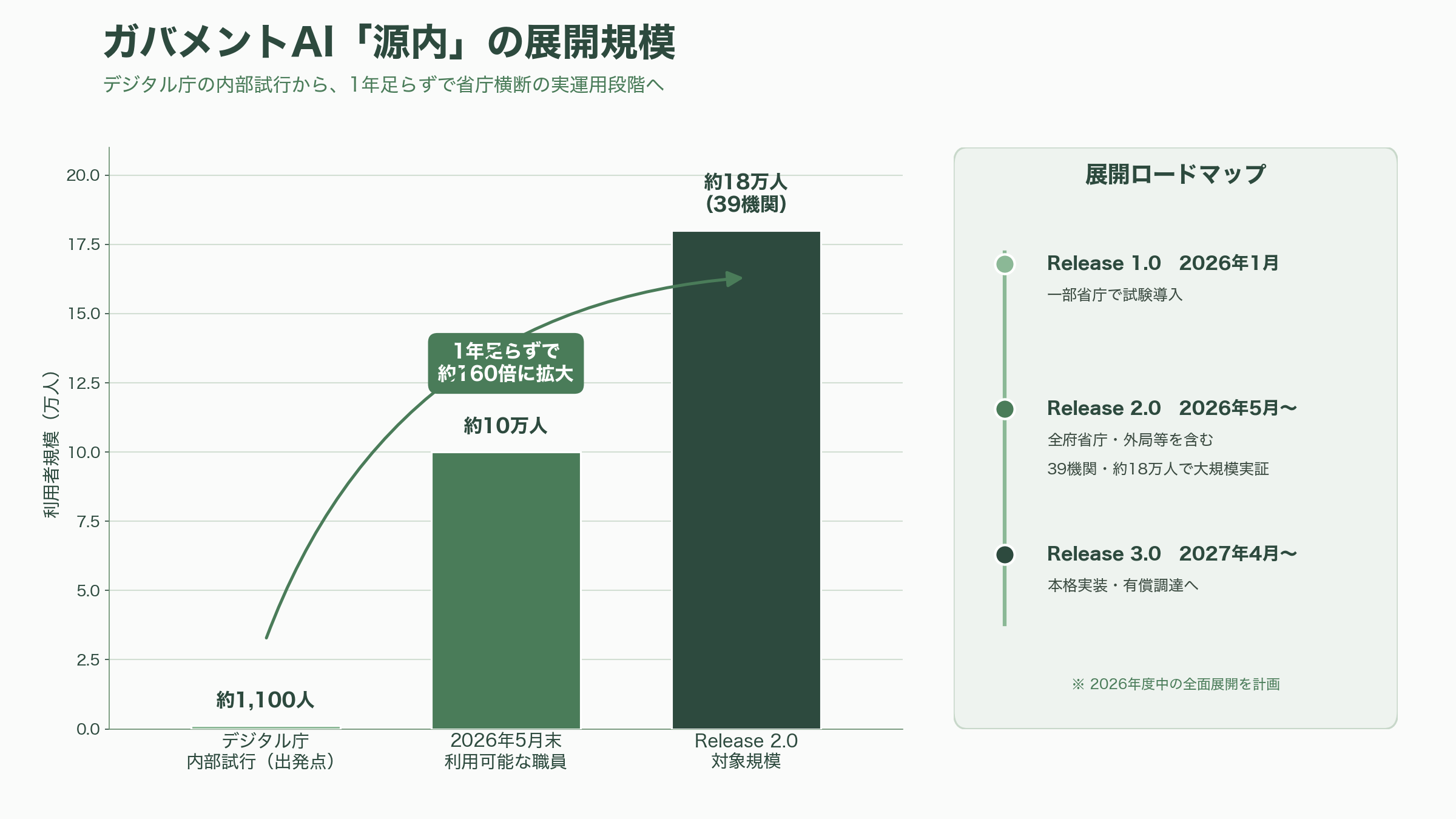
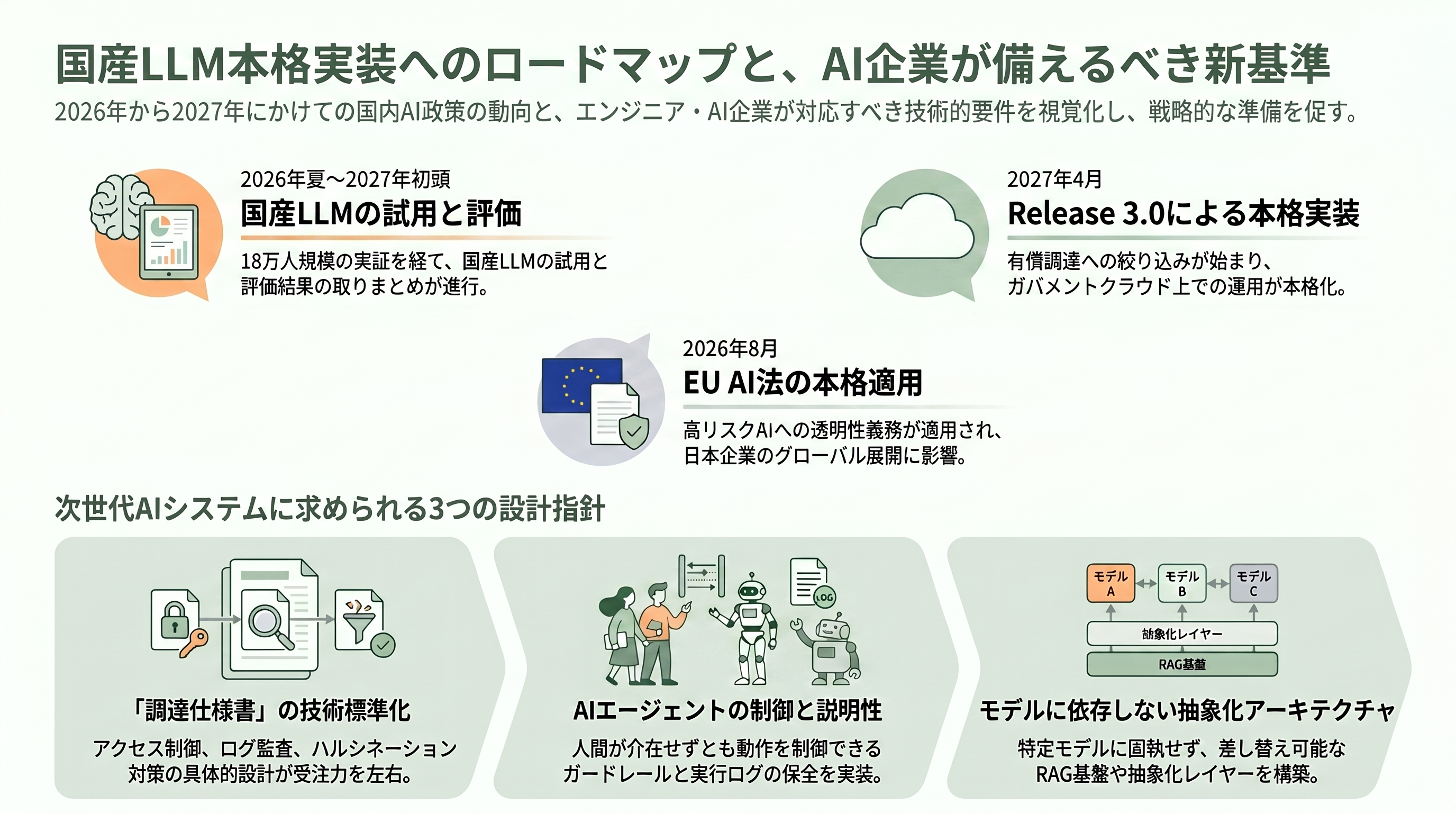
源内は、デジタル庁が内製した政府職員向けの生成AI共通基盤で、安全性を確保した環境で業務特化のAIアプリケーションを利用できるようにするものだ。技術的にはAWSが公開するオープンソースの「Generative AI Use Cases(GenU)」をベースに、政府要件に合わせて改修・機能追加が施されている。展開は段階的で、2026年1月のRelease 1.0で一部省庁の試験導入から始まり、2026年5月開始のRelease 2.0で全府省庁・外局等を含む39機関・約18万人を対象とする大規模実証へと拡大した。デジタル庁の展開状況資料によれば、2026年5月末時点で利用可能な職員はおよそ10万人規模に達し、2026年度中の全面展開、そして2027年4月以降のRelease 3.0で本格実装へ進む計画である。出発点がデジタル庁職員(およそ1,100人)の内部試行だったことを思えば、1年足らずでの18万人規模への拡張は、政府のAI実装が試行錯誤の段階から省庁横断の実運用段階へ移ったことを示している。
そして2026年4月24日、デジタル庁は源内のWebインターフェースと主要なAIアプリの開発テンプレートを、GitHub上で無償公開した。公開はおおむねMITライセンスなど商用利用可能な条件の下で行われ、リポジトリは画面側の「digital-go-jp/genai-web」と、RAG(検索拡張生成)やLLMデプロイのテンプレートを含む「digital-go-jp/genai-ai-api」に分かれている。これにより、地方自治体や民間企業が、AWS・Azure・Google Cloudといった主要クラウド上に、行政水準のAI基盤を低コストで自前構築できる道が開けた。標準ガイドラインという「規範」と、源内という「動く実装」が同時に提供されることで、第2.0版が要求するアクセス制御やログ管理を、現場が参照できる具体物として手にできるようになった点は、今回の一連の動きの中でもとりわけ実務的な意味が大きい。
国産LLM7モデル選定が映す「調達」の思想

源内の上で試用される大規模言語モデル(LLM)として、デジタル庁は2026年3月、国産7モデルの選定結果を公表した。2025年12月から始まった公募には15件が応募し、書類審査と評価テストを経て7件が残ったとされる。
選ばれたのは、フルスクラッチ開発で1GPU環境でも動く軽量さを売りにするNTTの「tsuzumi 2」、ソフトバンク傘下のSB Intuitionsが手がける「Sarashina2 mini」、日本語性能で世界トップクラスをうたうPreferred Networksの「PLaMo 2.0 Prime」、MetaのLlamaを基盤に日本語を追加学習したKDDI・ELYZA陣営の「Llama-3.1-ELYZA-JP-70B」、敬語や専門用語の再現性に強いNECの「cotomi v3」、オンプレミス運用に対応する富士通の「Takane 32B」、そして政府向けに独自開発されたカスタマークラウドの「CC Gov-LLM」である。性能の方向性も規模もばらばらな7つを並行採用した点に、選定の思想がよく表れている。
ここで生成AIエンジニアの視点を入れると、この選定が「いちばん性能が高い1モデルを選ぶ」競争ではなかったことが見えてくる。Qiitaに掲載された分析は、源内が国産にこだわった理由は性能そのものではなく、政府システムとしての設計要件にあったと指摘する。法令・通知・公文書の定型表現に対応できる言語適合性、データがどこで処理され誰がどこまで追跡・監査できるかというガバナンス、特定ベンダーへの依存を避けるための複数モデル併用、国内ベンダーに本番規模の改善機会を与える産業政策的な市場育成、緊急時や輸出規制に備えて重要業務を外部APIに預けきらないデジタル主権、帳票形式への合わせ込みや障害時の連絡体制といった業務統合の柔軟性、そして「なぜその答えになったか」を組織として説明できる説明責任――こうした条件群を満たすことが、海外最先端モデルの単純な性能スコアよりも重視されたという読み解きだ。実際、評価では機密性2相当の情報を扱えるか、ガバメントクラウド上で動くか、ハルシネーションや差別的表現に対処できるかといった点が問われたとされる。「国産AI」という言葉の意味が、開発者の国籍から「説明責任の総体」へと静かに更新されつつある、というこの見立ては、第2.0版の「調達を通じた統制」という発想とちょうど符合する。

影響を受ける企業と、その出資の構図
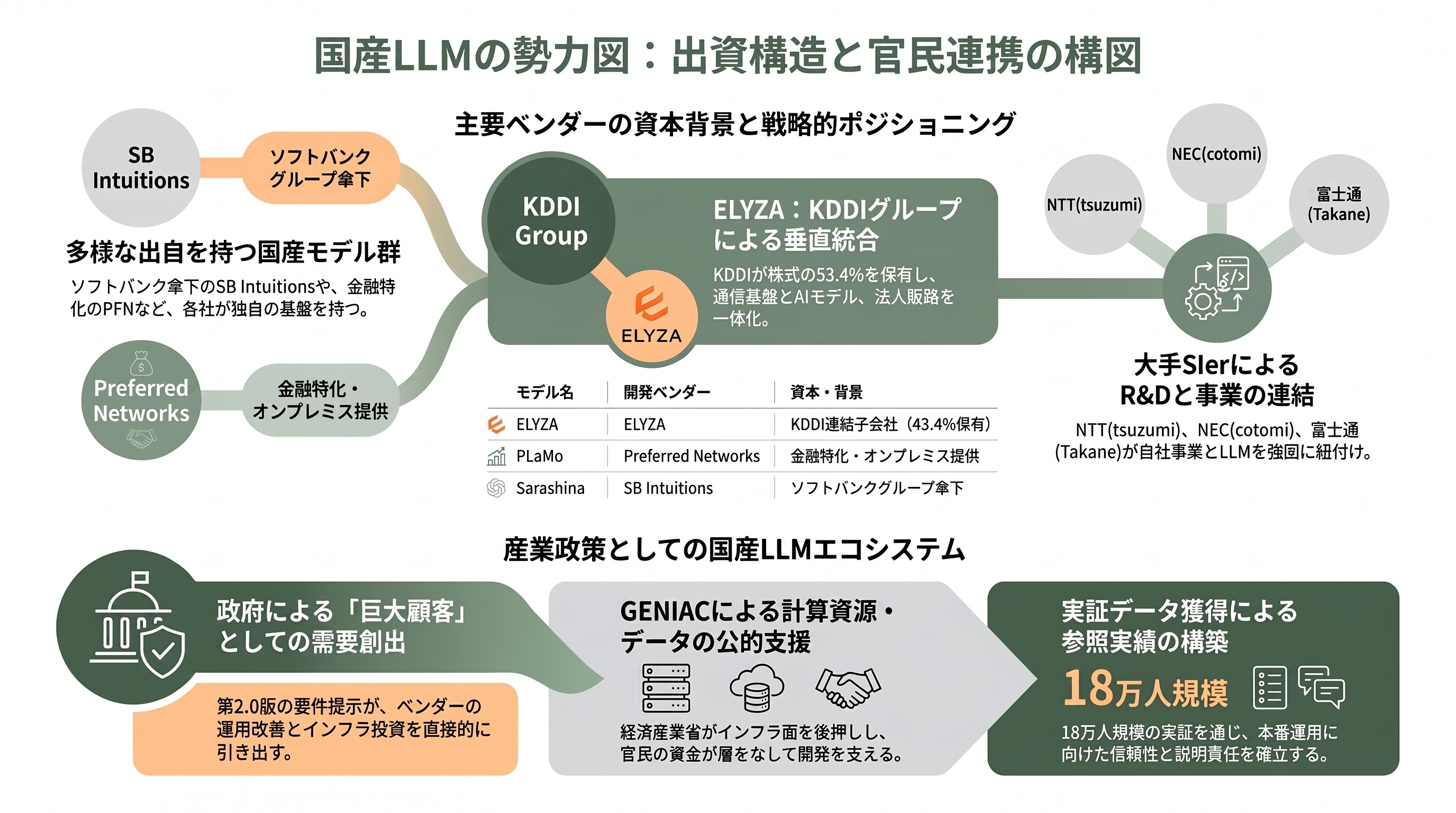
7モデルの選定と18万人規模の実証は、関係する企業にとって単なる名誉ではなく、本番運用に向けた実証データと参照実績を獲得する機会である。第2.0版がベンダーに求める「説明責任」「アクセス制御」「機密情報対応」を満たせる事業者が、政府という巨大顧客に選ばれる構図が立ち上がりつつある。ここでは、各社とその背後の出資の流れを整理しておきたい。
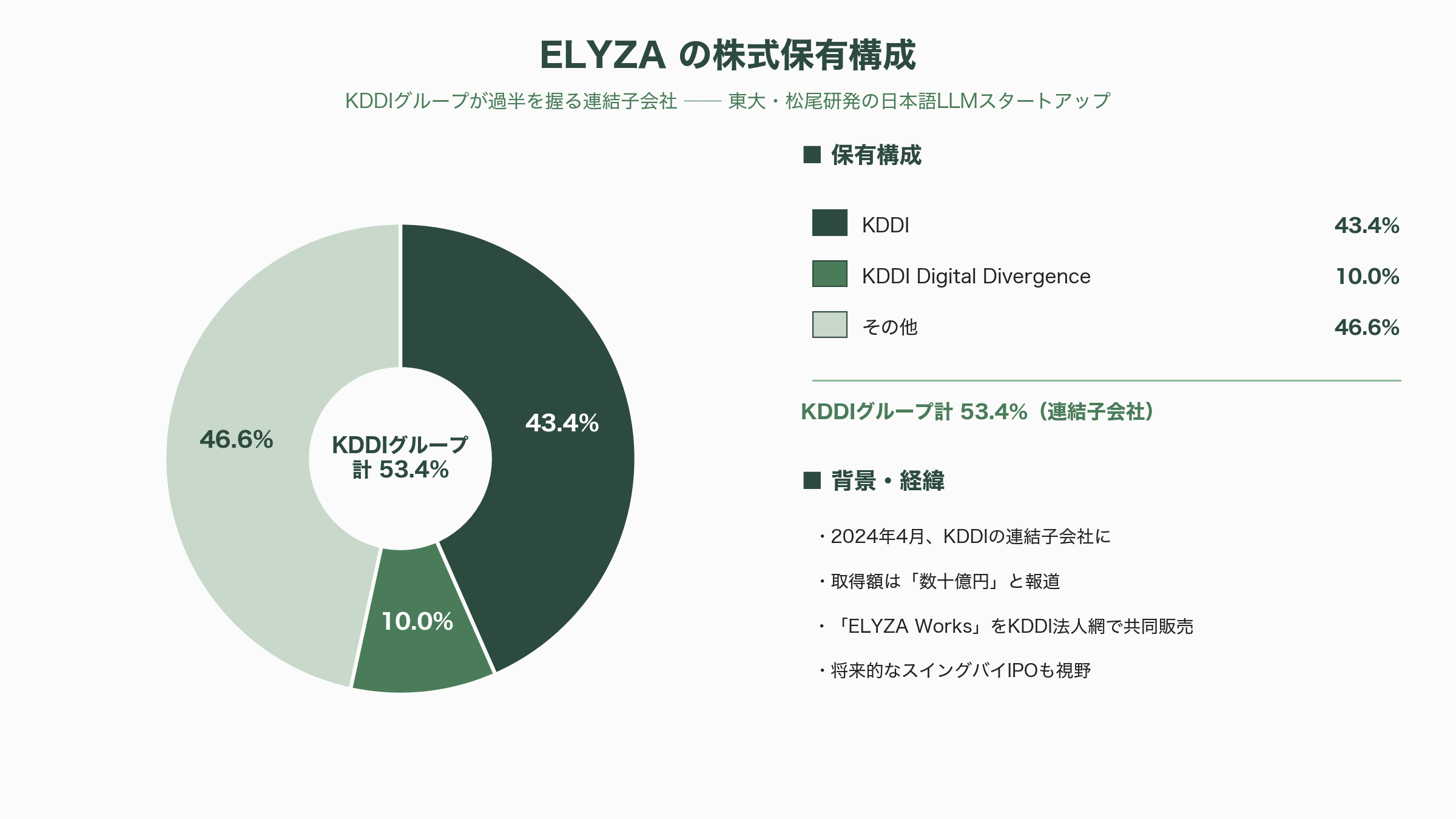
最も象徴的なのがELYZAだ。東京大学松尾研究室発のこの日本語LLMスタートアップは、2024年3月18日にKDDIグループと資本業務提携を結び、KDDIが43.4%、KDDI Digital Divergenceが10.0%の株式を保有する形で同年4月にKDDIの連結子会社となった。取得額は「数十億円」と報じられている。ELYZAは子会社化後の2025年9月に自社製品「ELYZA Works」を投入し、「ELYZA Works with KDDI」としてKDDIの法人顧客チャネルでの共同販売を始めており、将来的なスイングバイIPO(親会社の支援を受けた後の上場)も視野に入れる。KDDIは1,000億円規模の計算基盤投資も打ち出しており、通信事業者が計算資源とAIモデルの双方を抱え込む動きの一例といえる。
他のモデルも、それぞれ明確な出資・事業基盤を背負っている。Preferred Networksは、機密データを公開クラウドに出せない金融機関向けにオンプレミス提供を進めるなど、エンタープライズ用途に的を絞ったPLaMoファミリーを展開し、金融特化の「PLaMo-fin-base」では日本語金融ベンチマークで高評価を得ている。Sarashinaを手がけるSB Intuitionsはソフトバンクの傘下にあり、グループの計算基盤を背景に基盤モデル開発を進める。tsuzumiのNTT、cotomiのNEC、Takaneの富士通はいずれも自社の研究開発とSI事業を結びつけた大手であり、カスタマークラウドは政府特化を掲げる新興プレイヤーだ。これらの国産モデル開発の裾野には、経済産業省が計算資源やデータ整備を後押しする国産基盤モデル支援の枠組み(GENIAC)があり、官民の資金とインフラが層をなして国産LLM群を支えている。政府が大口需要者として明確な要求を示し、その需要が国内ベンダーの本番運用改善とインフラ投資を引き出す――第2.0版とその実装は、リスク管理の文書であると同時に、こうした産業政策の駆動装置としても機能している。
各紙・各サイトはどう報じたか
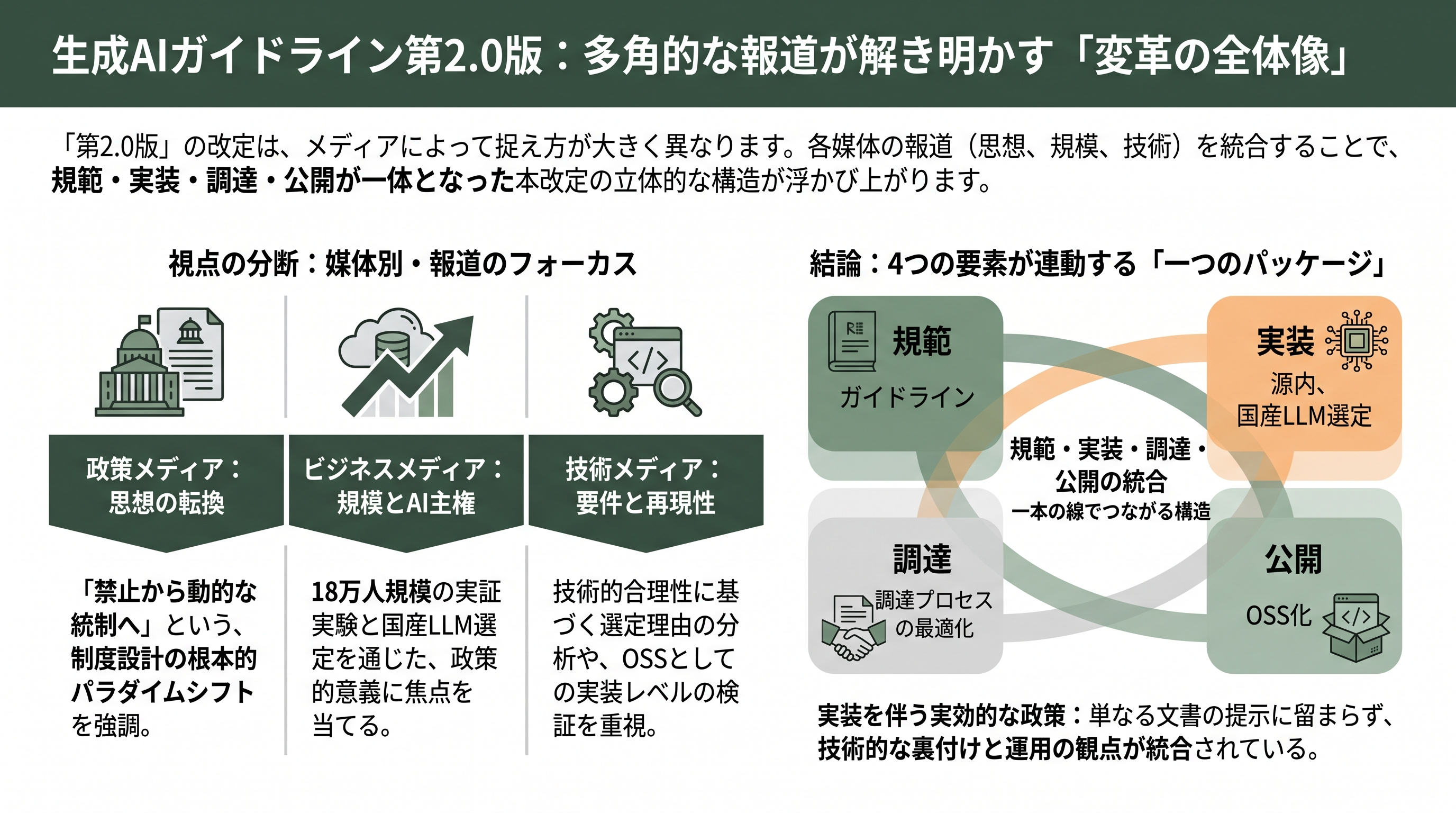
同じ改定でも、媒体によって光の当て方は異なる。情報を統合して読むことで、第2.0版の多面性が立体的に見えてくる。
DXマガジンは、改定の本質を「禁止から動的な統制へ」という思想転換として捉え、AIが自律的にシステム間を動く時代にはアクセス制御や機密情報対策を調達段階の仕様書で握る必要がある、という制度設計の眼目を前面に出した。これに対しLedge.aiやアドタイ(advertimes)、innovatopiaといった媒体は、源内の国産LLM7選定と18万人実証という「事実」と「規模」、そして「AI主権」という政策的意義に焦点を当てて報じた。一方、Qiitaに代表されるエンジニアコミュニティの分析は、「国産にこだわる理由は性能じゃなかった」として、政府システムの設計要件という技術・運用の観点から選定の合理性を読み解いた。さらに、源内のOSS公開を受けて、DevelopersIOのような技術メディアは、AWSのGenUとの差分を検証しながら実際にAWSアカウントへデプロイしてみる、といった実装レベルの検証記事を出している。
つまり、政策メディアは「思想転換」を、ビジネスメディアは「規模とAI主権」を、エンジニアメディアは「設計要件と再現可能性」を、それぞれの読者に向けて切り出した。これらを重ね合わせると、第2.0版は単なる文書改定ではなく、規範(ガイドライン)・実装(源内)・調達(国産LLM選定)・公開(OSS化)が連動した一つのパッケージであることが浮かび上がる。本稿が試みたのは、まさにこの分断された報道を、生成AIエンジニアとAI企業の視点から一本の線でつなぐことである。
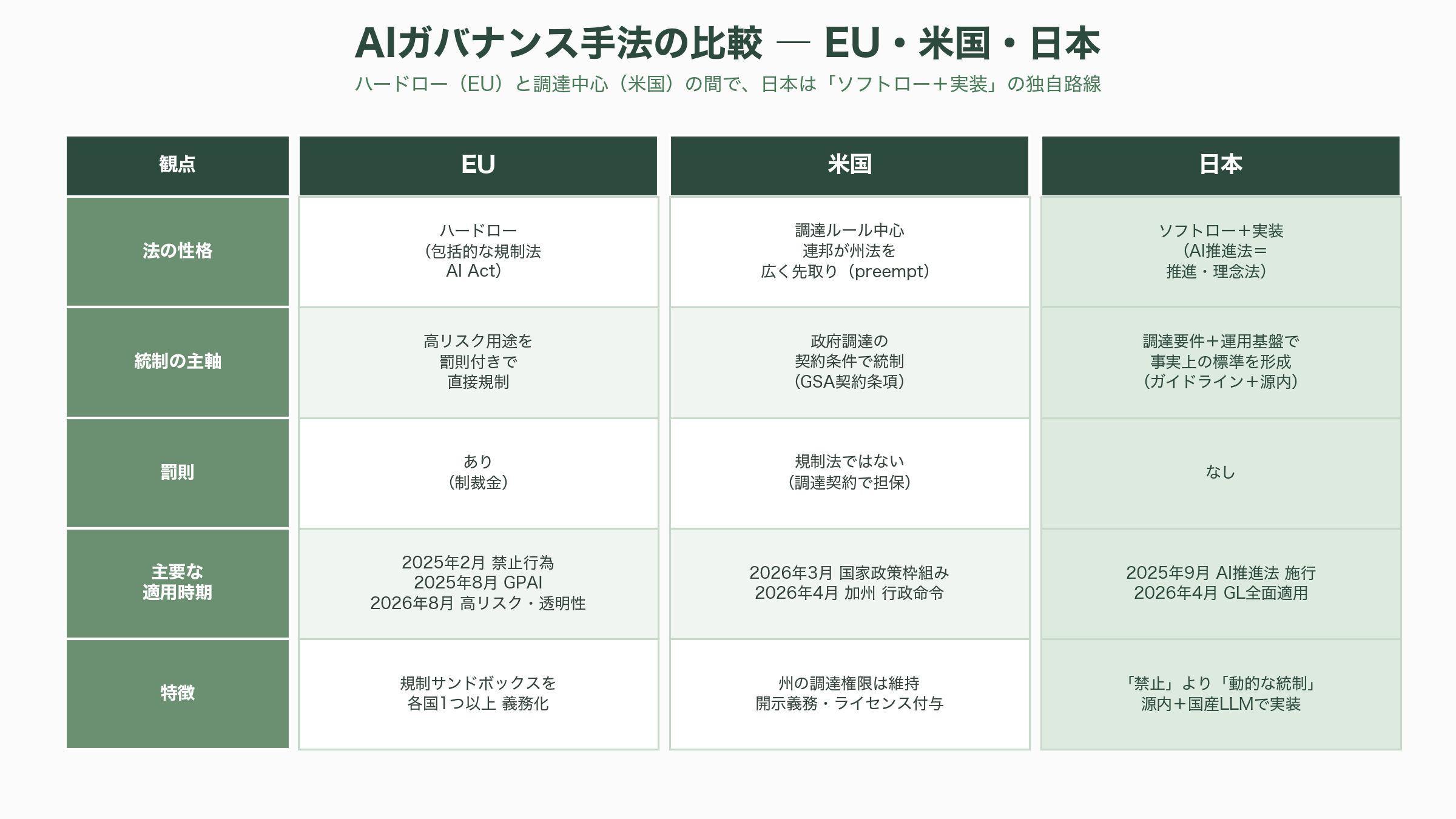
世界の潮流の中の日本 — EU・米国との比較
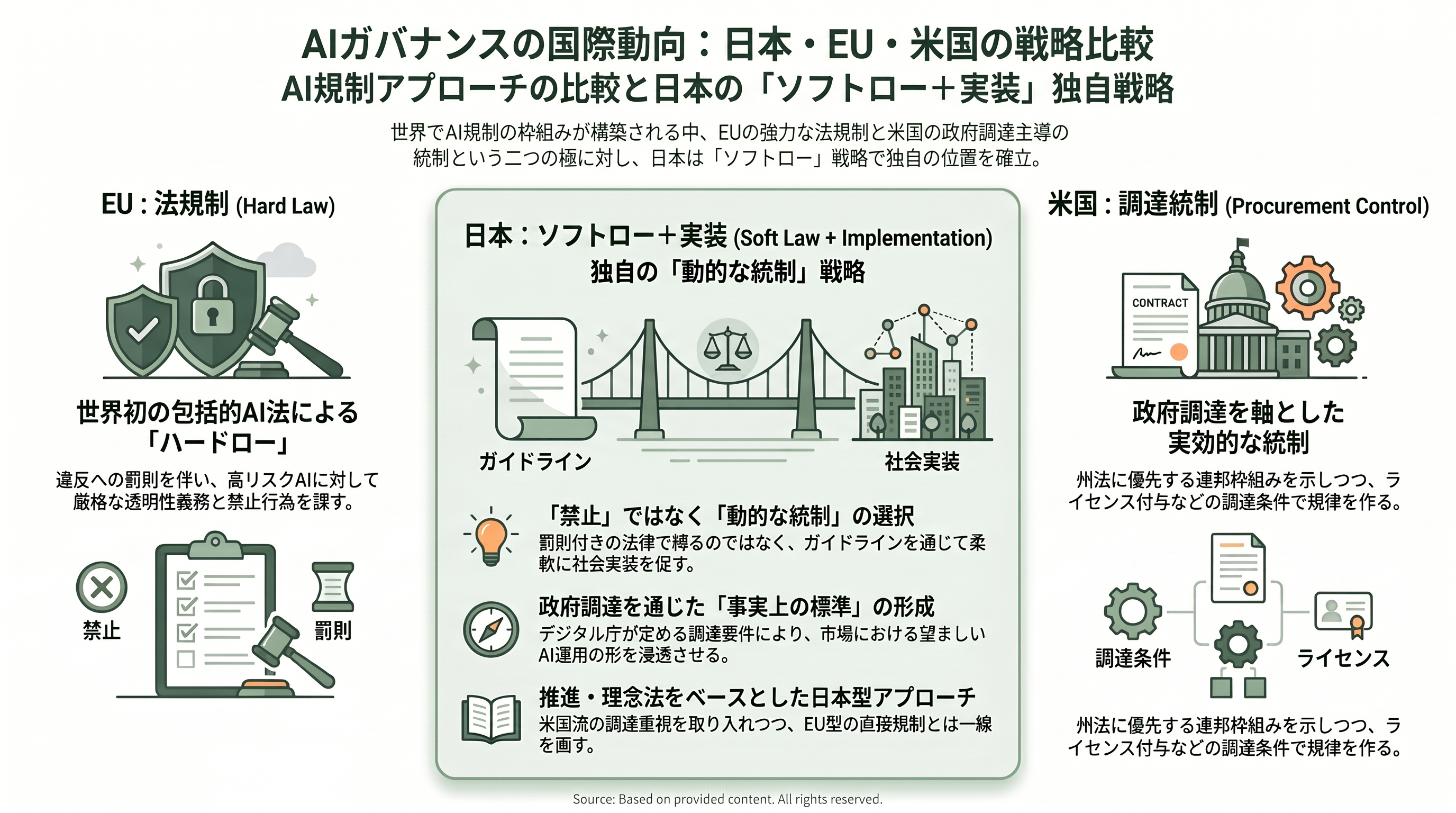
第2.0版の位置づけは、海外の制度動向と並べると一段とはっきりする。
EUでは、世界初の包括的なAI規制法であるAI Actが段階的に効力を持ち始めている。禁止行為やAIリテラシーの規定は2025年2月から、汎用AI(GPAI)に関する義務は2025年8月から適用が始まっており、附属書IIIに定める高リスクAIへの要求や第50条の透明性義務は2026年8月2日から本格適用される。各加盟国は同じ2026年8月2日までに、企業がAIを試験できる規制サンドボックスを少なくとも一つ整備する義務を負う。EUのアプローチは、罰則を伴う「ハードロー」でリスクの高い用途を直接縛る点に特徴がある。
米国は対照的だ。ホワイトハウスは2026年3月20日に「National Policy Framework for Artificial Intelligence(AIに関する国家政策枠組み)」を公表し、州ごとにばらつくAI法を連邦が広く先取り(preempt)する方向を示しつつ、州政府によるAIの調達と利用に関する権限は維持するとした。連邦調達では、一般調達庁(GSA)の契約条件案が、AIシステムに関する開示義務や、政府が適法な目的に利用できる取り消し不能なライセンスの付与といった新たな要求を盛り込もうとしている。州レベルでも、カリフォルニア州知事が2026年4月にAIベンダーの認証と調達の枠組みを定める行政命令に署名するなど、「調達」を軸にした統制が広がっている。
この二つの極の間で、日本のアプローチは独特の位置を占める。AI推進法が罰則のない推進・理念法である以上、日本はEU型のハードローには寄らない。しかし米国のように調達を統制の主戦場にする点では共通しており、デジタル庁のガイドラインと源内は、まさに政府自身の調達と実装を通じて事実上の標準を形づくる「ソフトロー+実装」の戦略だといえる。第2.0版が「禁止」ではなく「動的な統制」を選んだのは、規制で縛るのではなく、調達要件と運用基盤を通じて望ましい行動を引き出すという、この日本型アプローチの必然的な帰結でもある。
今後の見通しと、エンジニア・AI企業への含意
最後に、今後いつ頃どのような動きが起きるのか、そしてそれが生成AIエンジニアとAI関連企業にとって何を意味するのかを整理しておきたい。
時間軸でみると、当面の焦点は源内における国産LLMの本格試用である。複数の報道を総合すると、2026年5月から始まった約18万人規模の実証の上で、2026年夏以降に国産LLMの試用が進み、2027年初頭に評価結果が取りまとめられ、2027年4月以降のRelease 3.0で本格実装と有償調達への絞り込みへ向かう、という段取りが見込まれる(具体的な月次のスケジュールは媒体により表現に幅がある点に留意したい)。並行して、2026年4月に公開された源内OSSを土台に、自治体や民間でのデプロイ事例が積み上がっていくだろう。総務省も自治体向けの活用・導入ガイドブックを2026年版へ改訂しており、令和6年末時点で生成AI利用ガイドラインが未策定だった1,000超の自治体が、源内OSSと国の標準を参照しながら整備を進める展開が予想される。海外では2026年8月2日にEU AI Actの高リスク・透明性義務が本格適用され、日本企業のグローバル展開にも影響が及ぶ。そして第2.0版自体が「動的な枠組み」を標榜する以上、画像・動画生成AIやエージェントの普及度に応じた次の改定が、早晩議論の俎上に載るとみてよい。
エンジニアとAI企業にとっての含意は明快だ。第一に、リスク管理の重心が運用から調達へ移ったことで、調達仕様書が事実上の技術標準になる。アクセス制御の粒度、機密性2相当の情報の取り扱い、入出力のログと監査、ハルシネーションや差別的表現への対処、ガバメントクラウド上での動作といった要件を、提案段階で具体的に設計・提示できる能力が、そのまま受注競争力に直結する。第二に、AIエージェントが原則高リスク扱いとなる方向は、自律実行に「人間が介在しなくても説明と制御ができる仕組み」――承認フロー、操作範囲の制限、実行ログの保全、ガードレールの組み込み――を実装することの価値を押し上げる。第三に、複数モデルの並行採用が標準になりつつある以上、特定モデルへの最適化に閉じず、モデルを差し替え可能な抽象化レイヤーやRAG基盤を持つアーキテクチャが有利になる。第2.0版は政府向けの文書でありながら、「説明できること」「制御できること」「差し替えられること」という、これからのAIシステム設計の評価軸そのものを、調達という形で社会に提示している。その意味で、これは行政だけの話ではなく、日本のAI開発・提供の作法を更新する一里塚として読むべき改定である。