はじめに——10本の論文が描く「三幕の物語」として現代AIを読む
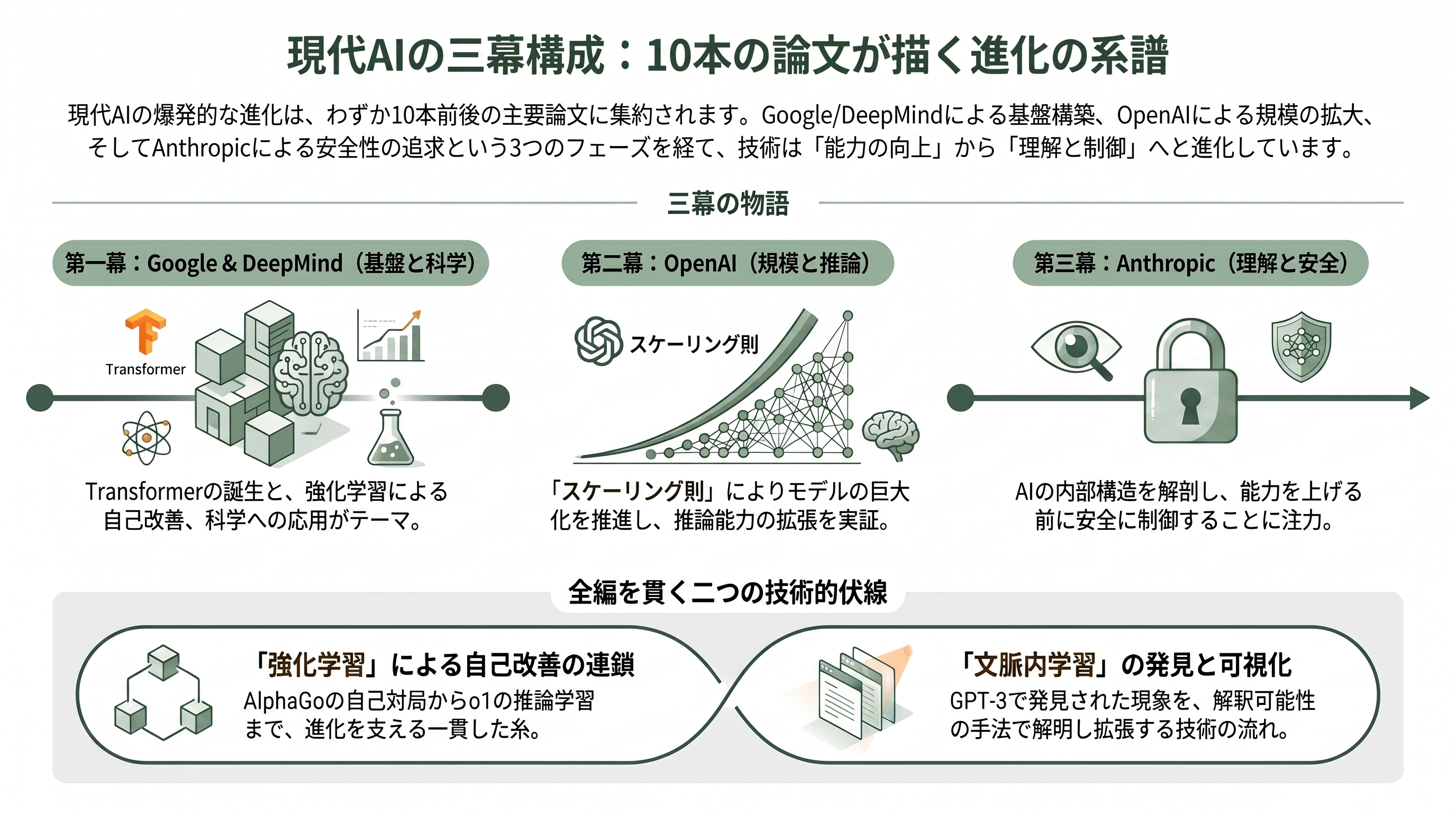
シリコンバレーでAIの研究に携わっていると、ある奇妙な感覚に襲われることがある。いま自分たちが当たり前に使っている技術のほとんどが、たった10本前後の論文に源流をたどれてしまう、という感覚だ。チャットボットも、タンパク質の構造予測も、囲碁で人類を超えたプログラムも、そして「考えてから答える」推論モデルも、すべてが少数の決定的なアイデアの上に積み上がっている。本稿で取り上げる10本は、まさにその「珠玉の論文たち」である。
これらの論文は、大きく三つの幕に分かれて読むと、現代AIの物語として一気に見通しがよくなる。第一幕はGoogleとDeepMindだ。2017年にGoogleが発表した「Attention Is All You Need」は、いまのあらゆる生成AIが乗るアーキテクチャ「Transformer(トランスフォーマー)」を生んだ。同じ2017年、DeepMindは囲碁を人間の棋譜なしで独学した「AlphaGo Zero」を、2021年にはタンパク質構造予測の50年問題を解いた「AlphaFold」を世に問うた。ここでのテーマは、新しいアーキテクチャと、強化学習による「自己改善」、そして科学への応用である。
第二幕はOpenAIだ。OpenAIは「大きくすれば賢くなる」という素朴な、しかし当時は誰も本気で信じていなかった仮説を、2020年の「スケーリング則」の論文で法則として定式化し、同年の「GPT-3」でそれを実証した。モデルにいくつか例を見せるだけで新しいタスクをこなす「文脈内学習(in-context learning)」という不思議な現象が、ここで世界に知られることになる。そして2024年、OpenAIは「答える前に考える」推論モデルo1を発表し、スケーリングの軸を学習時から推論時へと拡張した。
第三幕はAnthropicである。Anthropicは、OpenAIを離れた研究者たちが「能力を上げる前に、まずモデルを理解し、安全にする」という旗を掲げて2021年に創業した会社だ。彼らはTransformerの内部を回路として解剖する「機械的解釈可能性(mechanistic interpretability)」、AI自身のフィードバックで無害化する「Constitutional AI」、文脈内学習を数百例規模に拡張した「メニーショット学習」、そして本番のClaudeから人間に理解できる「特徴」を抽出した「Scaling Monosemanticity」を世に出した。能力の物語が、理解と制御の物語へと折り返していく。
本稿の狙いは、単なる論文要約の羅列ではない。これら10本がどう連鎖し、互いをどう引用し、そしてシリコンバレーの研究者コミュニティの中でどのような人の移動と思想の対立を生んだのかを、内側の視点で縫い合わせることにある。注意深い読者は、この三幕を貫く二つの伏線に気づくはずだ。一つは「強化学習」——AlphaGo Zeroの自己対戦から、Constitutional AIのRLAIF、o1の推論学習までを貫く糸。もう一つは「文脈内学習」——GPT-3で発見され、Transformer回路で機構が解明され、メニーショットで拡張され、Monosemanticityで可視化されるという糸だ。では、第一幕の幕開けから始めよう。
Attention Is All You Need(2017, Google)——すべての生成AIが乗る土台
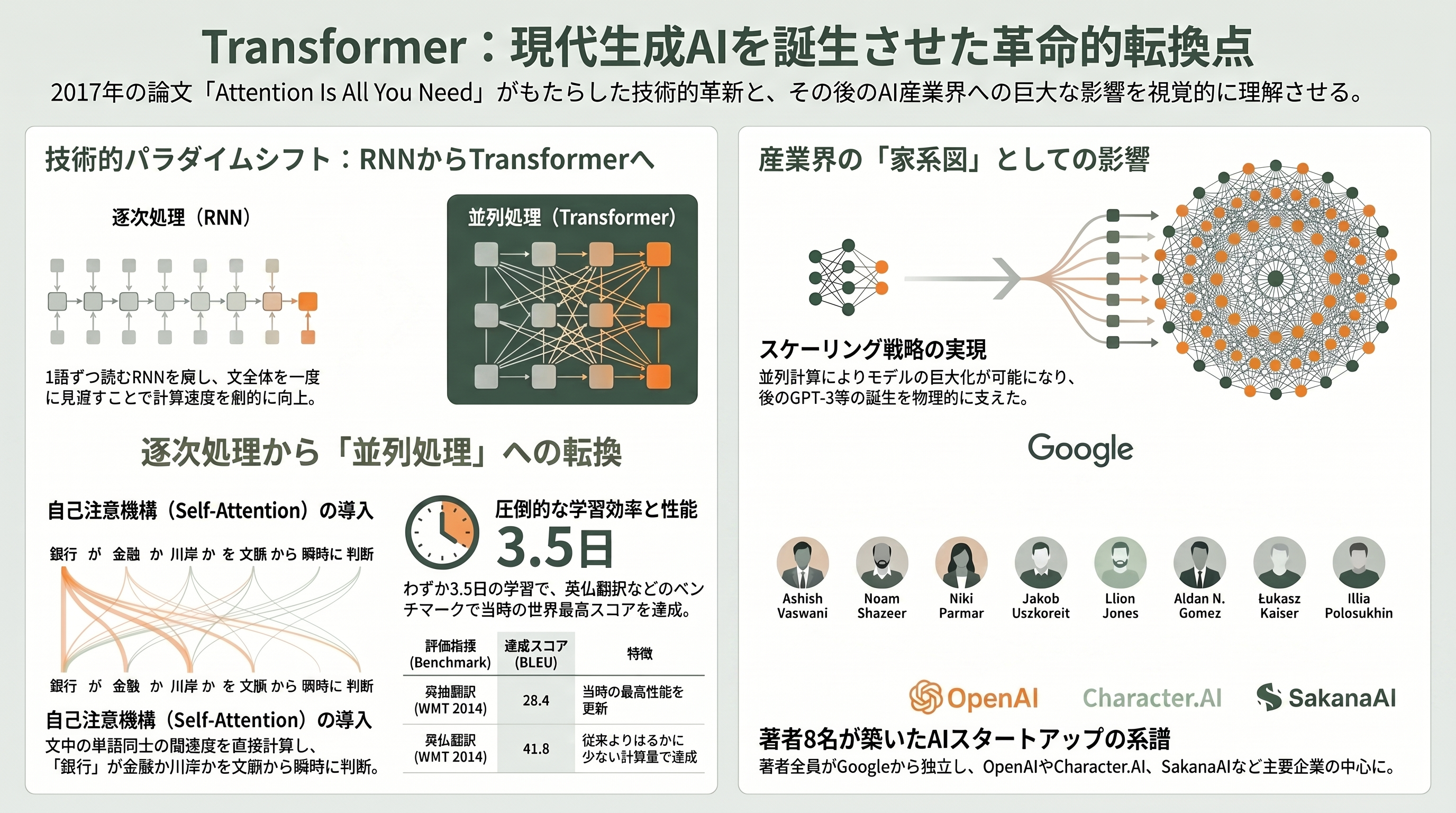
まず、現代AIで最も引用される論文から始めたい。2017年にGoogle Brainの8人が発表した「Attention Is All You Need」は、それまで機械翻訳などで主流だった「再帰型ニューラルネットワーク(RNN)」を捨て去り、「注意機構(attention)」だけで文章を処理するTransformerという新しい設計図を提示した。タイトルの直訳は「注意こそがすべて」。当時は挑発的なジョークに見えたが、いまや文字どおりの真実になった。
具体例で考えよう。「彼は銀行で釣りをした」という文を機械が理解するには、「銀行(bank)」が金融機関なのか川岸なのかを、「釣り」という遠く離れた単語から判断する必要がある。従来のRNNは単語を左から右へ一語ずつ順番に読むため、離れた語の関係をとらえるのが苦手で、しかも逐次処理ゆえに並列計算ができなかった。Transformerの自己注意機構は、文中のすべての単語が一度に互いを「見渡し」、どの語にどれだけ注目すべきかの重みを直接計算する。「釣り」という語が「銀行」を見て「ああ、これは川岸の方だ」と重みづけする、という具合だ。これを複数の視点(マルチヘッド注意)で同時に行い、語順の情報は「位置エンコーディング」という形で別途加える。
この設計には二つの革命的な含意があった。第一に、文全体を一括で並列処理できるため、GPUの能力をフルに使える。論文の大型モデルは8基のNVIDIA P100 GPUでわずか3.5日学習しただけで、英独翻訳のベンチマークWMT 2014でBLEUスコア28.4、英仏翻訳で41.8という当時の最高性能を、はるかに少ない計算量で達成した。第二に、この並列性こそが「とにかく大きくする」という後のスケーリング戦略を物理的に可能にした。Transformerがなければ、GPT-3もClaudeも存在しえない。
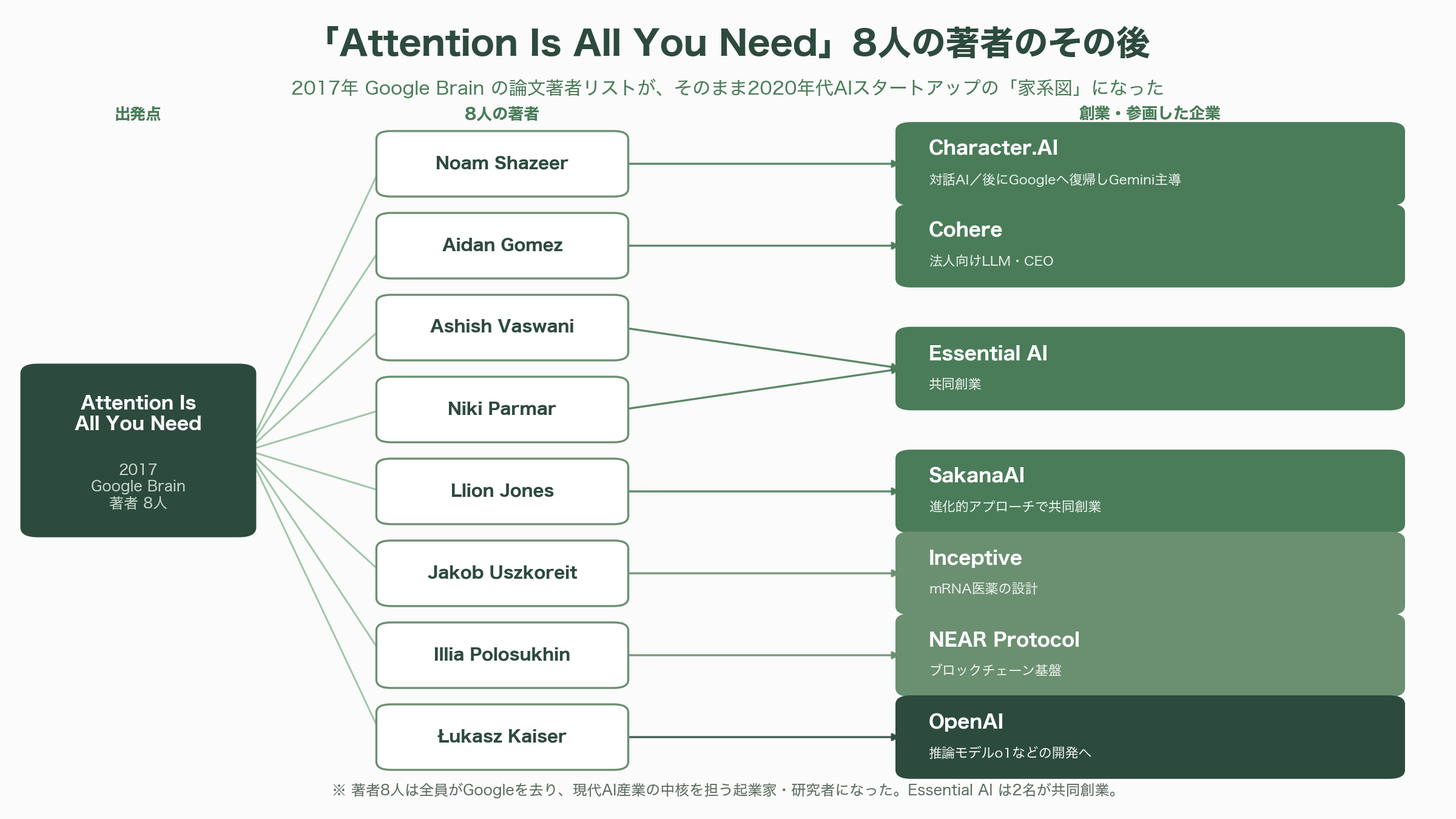
シリコンバレーの内側から見て興味深いのは、この論文の8人の著者たちのその後だ。彼らは全員がGoogleを去り、現代AI産業の中核を担う起業家・研究者になった。Noam Shazeerは対話AIのCharacter.AIを創業し(後にGoogleへ復帰してGeminiを率いる)、Aidan GomezはCohereのCEO、Ashish VaswaniとNiki ParmarはEssential AIを、Llion JonesはSakanaAIを、Jakob UszkoreitはmRNA設計のInceptiveを共同創業し、Illia PolosukhinはブロックチェーンのNEAR Protocolへ、Łukasz KaiserはOpenAIへ移った。一本の論文の著者リストが、そのまま2020年代AIスタートアップの「家系図」になっているのである。なお、この論文を生んだGoogle BrainとDeepMindは2023年4月に統合され、現在は「Google DeepMind」という一つの組織になっている。次章のDeepMindの仕事も、同じ屋根の下の物語だ。
Mastering the game of Go without human knowledge(2017, DeepMind)——人間を一切まねしない「白紙からの天才」
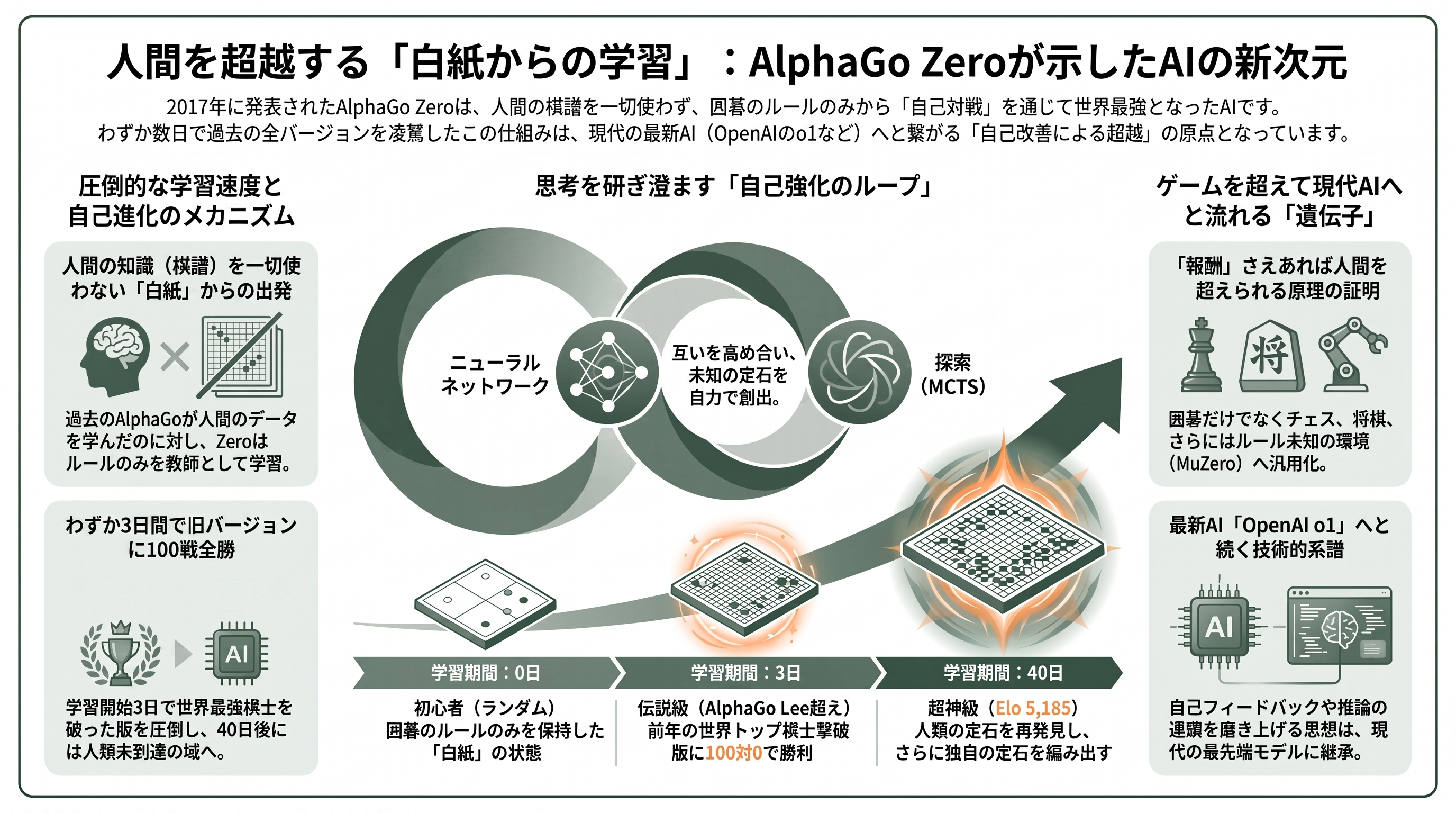
2017年10月、DeepMindはNature誌に「人間の知識なしに囲碁を極める(Mastering the game of Go without human knowledge)」を発表した。ここで登場するAlphaGo Zeroは、前年に世界トップ棋士イ・セドルを破った初代AlphaGoの後継だが、決定的に違う点が一つある。初代AlphaGoが人間のプロ棋士の棋譜を大量に学習していたのに対し、AlphaGo Zeroは囲碁のルールだけを与えられ、人間の対局データを一切使わずに、自分自身との対戦だけで強くなったのだ。
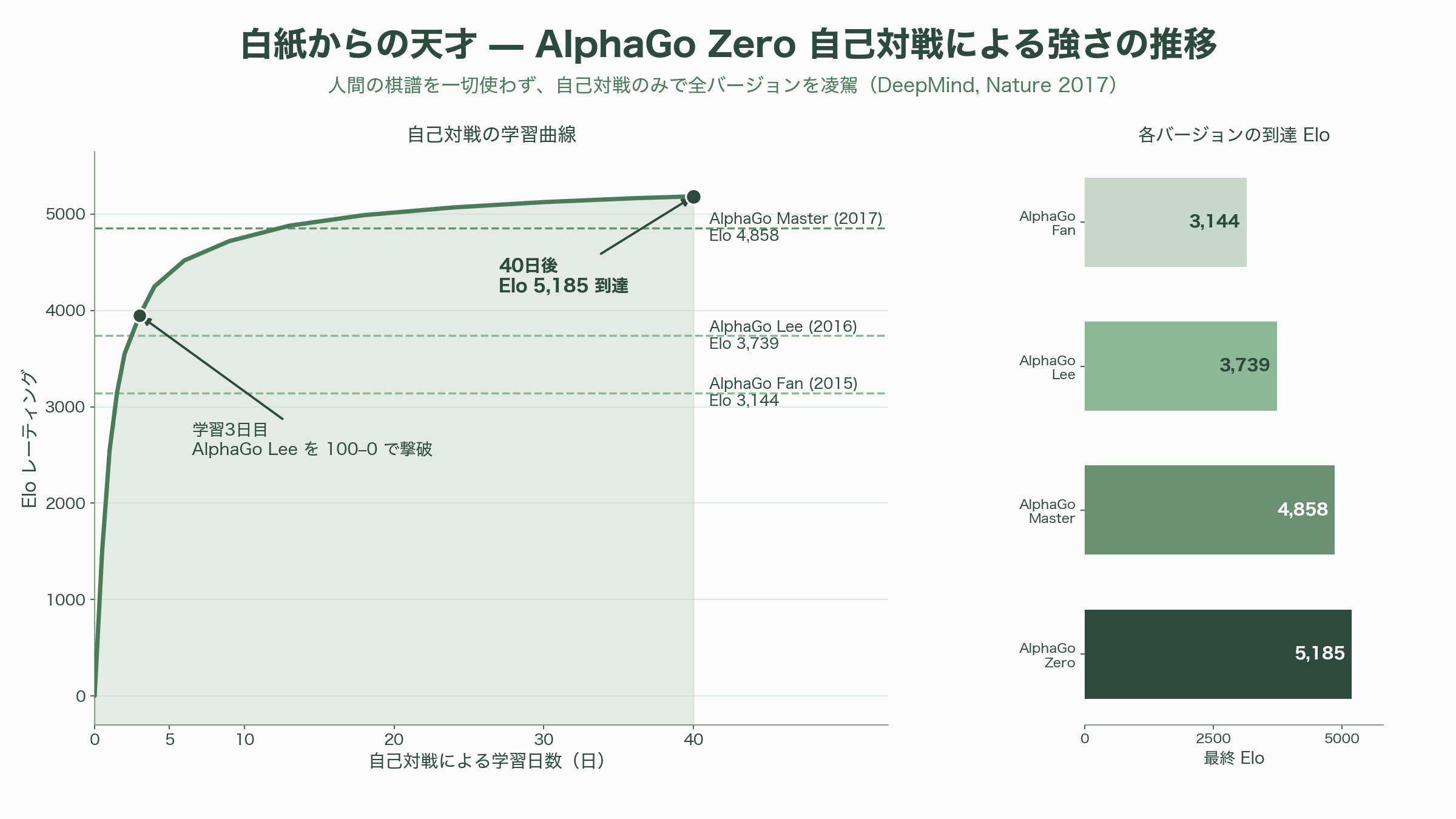
これがどれほど異様なことか、たとえ話で考えてみたい。誰からも教わらず、棋譜も一切見ず、ただ盤と石とルールブックだけを渡された人間が、部屋に閉じこもって自分と打ち続け、数日後に出てきたら歴代最強の棋士を100戦100勝で下していた——AlphaGo Zeroがやったのは、まさにこれである。最初はランダムに石を置くだけだった「白紙」の状態から出発し、自己対戦で生成した経験だけを教師として、自らを少しずつ上書きしていく。論文によれば、学習開始からわずか3日でイ・セドルを破った版(AlphaGo Lee)を100対0で上回り、40日後には推定Eloレーティング5,185に到達して、それまでの全バージョンを凌駕した。
技術的な核心は、強化学習と探索の見事な融合にある。AlphaGo Zeroは「次の一手の確率」と「この局面の勝率」を一つのニューラルネットワークで予測する。そして対局のたびにモンテカルロ木探索(MCTS)という先読みを行い、その先読みの結果を「より良い手本」としてネットワークを訓練する。ネットワークが強くなれば探索も鋭くなり、鋭い探索がさらに良い訓練データを生む——この自己強化のループが、人間の知識という外部の足場なしに超人的な強さを生み出した。注目すべきは、AlphaGo Zeroが定石(人間が数百年かけて発見した良い形)を自力で再発見し、さらに人間が知らなかった新しい定石まで編み出した点だ。
シリコンバレーの視点で言えば、この論文の本当の射程は囲碁ではない。「報酬さえ定義できれば、自己対戦による強化学習だけで人間を超えられる」という原理の証明である。DeepMindはこの手法を一般化し、同じアルゴリズムで囲碁・チェス・将棋を制覇するAlphaZero、さらにはゲームのルールさえ与えずに学ぶMuZeroへと発展させた。そしてこの「自己改善による超越」の思想は、形を変えて本稿後半に何度も再来する。AIが自分でフィードバックを生成して無害化するAnthropicのConstitutional AIにも、自分で推論の連鎖を生成して報酬で磨き上げるOpenAIのo1にも、AlphaGo Zeroの遺伝子が流れている。強化学習は、本稿を貫く第一の伏線なのである。
Highly accurate protein structure prediction with AlphaFold(2021, DeepMind)——AIが解いた「生物学50年の難問」

DeepMindが示したもう一つの金字塔が、2021年にNature誌へ発表した「AlphaFoldによる高精度なタンパク質構造予測」だ。これは囲碁のようなゲームではなく、生物学における50年来の難問そのものをAIが解いてしまった、という点で歴史的意味がまるで違う。2024年、この成果に対しDeepMindのデミス・ハサビスとジョン・ジャンパーがノーベル化学賞を受賞したことが、その重みを物語っている(賞の半分は計算による新規タンパク質設計を行ったワシントン大学のデイヴィッド・ベイカーに贈られた)。
そもそも何が難問なのか。タンパク質は20種類のアミノ酸が一列に連なった「ひも」だが、そのひもは細胞の中で瞬時に複雑な立体構造へと折りたたまれ、その「かたち」がそのまま機能を決める。酵素も、抗体も、筋肉も、かたちが働きを生む。ところが、アミノ酸の並び(配列)から最終的な立体構造を予測する「タンパク質折りたたみ問題」は、組み合わせが天文学的すぎて、1972年にこの問題提起でノーベル賞が言及されて以来、半世紀にわたり生物学最大の未解決問題とされてきた。従来はX線結晶構造解析などで一つの構造を決めるのに数か月から数年、莫大な費用がかかっていた。
AlphaFold2の革新は、Evoformerと呼ばれる新しいニューラルネットワークにある。これは進化の過程で蓄積された「似たタンパク質の配列の集まり(多重配列アラインメント、MSA)」と、「アミノ酸どうしの距離関係の表」という二つの情報を、注意機構(ここでも前章のTransformerの考え方が効いている)で何度も往復させながら磨き上げ、最後に三次元座標を一気に出力する。鍵となったのは、二つのアミノ酸の関係を、三つ目のアミノ酸を経由した「三角形」の整合性で補正するという幾何学的な工夫だ。2020年のタンパク質構造予測の世界大会CASP14で、AlphaFold2は中央値GDTスコア92.4——100点満点で実験構造とほぼ見分けがつかない精度——を叩き出し、第2位以下を圧倒して「問題は本質的に解かれた」と評された。
この論文が並の技術的成果と一線を画すのは、その後の社会的インパクトの大きさだ。DeepMindは予測した構造を惜しみなく公開し、AlphaFold Protein Structure Databaseには既知のほぼ全タンパク質にあたる約2億件の構造が登録され、190か国・200万人以上の研究者が利用している。創薬、酵素設計、抗生物質耐性やマラリアの研究まで、生命科学のあらゆる現場の「前提」が変わった。シリコンバレーの研究者として強調したいのは、AlphaFoldが「AIは言葉を操るだけのおもちゃではなく、人類が解けなかった自然科学の難問を解く道具になる」ことを最も鮮烈に示した点だ。ハサビスがAlphaFoldを起点に創薬企業Isomorphic Labsを立ち上げ、2024年にはタンパク質だけでなくDNAやRNA、低分子化合物との複合体まで予測するAlphaFold 3へと進化させたのは、その射程の広さを物語っている。
Scaling Laws for Neural Language Models(2020, OpenAI)——「大きくすれば賢くなる」を法則にした
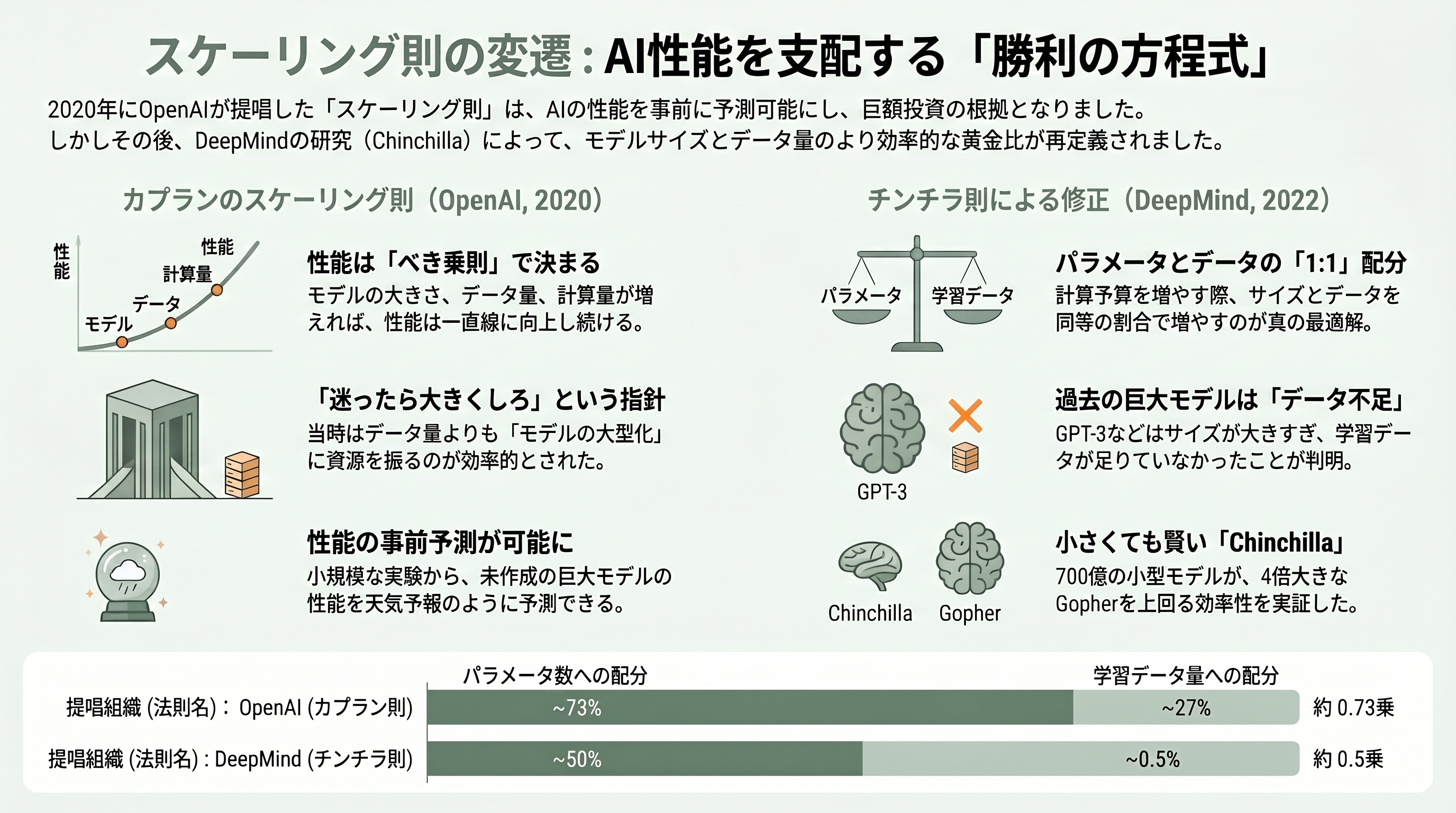
ここから第二幕、OpenAIの物語に移る。2020年1月、OpenAIのジャレッド・カプランらは「ニューラル言語モデルのスケーリング則」という、一見地味だが現代AIの戦略そのものを決定づけた論文を発表した。主張を一言でいえば、「言語モデルの賢さ(予測誤差の小ささ)は、モデルの大きさ・データ量・計算量に対して、驚くほどきれいな『べき乗則』で改善し続ける」というものだ。
この発見の何がすごいのか。研究開発というのは普通、何が起きるかやってみるまで分からない、博打のような営みだ。ところがカプランらは、パラメータ数を7桁にわたって変えた200以上のモデルを訓練し、その性能をグラフにプロットしたところ、点がほぼ一直線(両対数グラフ上の直線=べき乗則)に並ぶことを見出した。つまり、小さなモデルでの実験結果から、まだ作っていない巨大モデルの性能を事前に予測できるということだ。天気予報のように「このくらい計算資源を投じれば、このくらい賢くなる」と見積もれる。これは、巨額の投資を正当化する経営判断の道具にもなった。
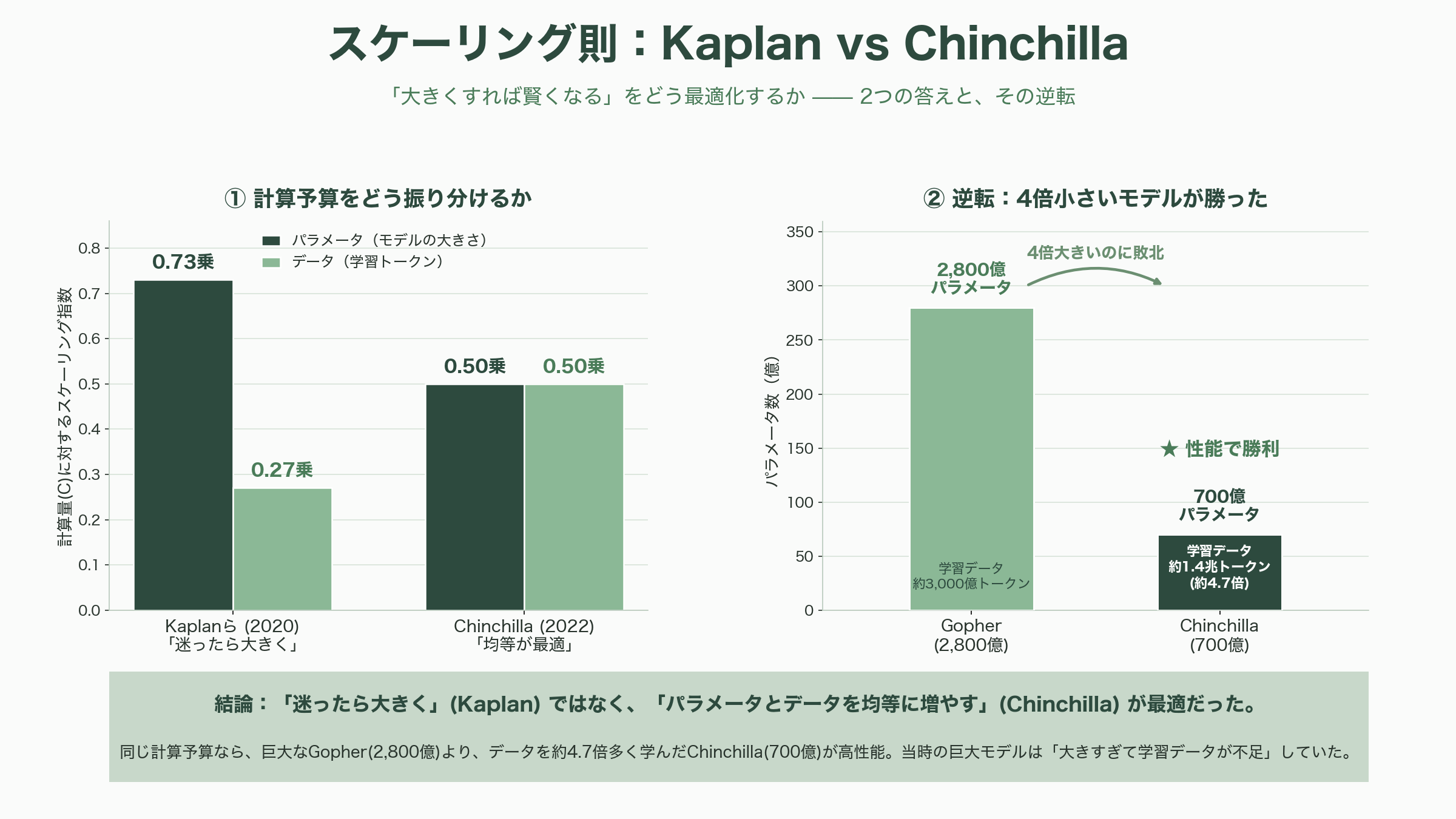
具体的な含意も鮮烈だった。論文は、与えられた計算予算を最も効率よく使うには、データを増やすことよりもモデルを大きくすることに資源を振り向けるべきだと示唆した(最適なパラメータ数は計算量のおよそ0.73乗、データ量は0.27乗で増やすべき、という配分)。さらに「大きなモデルほど、少ないデータからより多くを学ぶ(サンプル効率が高い)」とも述べた。この「迷ったら大きくしろ」というメッセージが、直後のGPT-3という史上空前の巨大モデルへの賭けを後押しした。次章のGPT-3は、このスケーリング則の最初の壮大な実証実験だったのである。
ただし、研究者として誠実に付け加えるべき後日談がある。2022年、DeepMindのホフマンらは「Chinchilla(チンチラ)」と呼ばれる研究で、カプランらの最適配分は偏っていたと指摘した。同じ計算予算なら、パラメータとデータをほぼ同じ割合(それぞれ計算量の約0.5乗)で増やすのが最適であり、当時のGPT-3を含む巨大モデルは「大きすぎて、学習データが足りていなかった」というのだ。実際、700億パラメータのChinchillaは、4倍大きい2,800億パラメータのGopherを上回った。この食い違いの主因は、カプランらが埋め込み層を除いたパラメータで数えていたことや学習率の設定にあったと後に分析されている。スケーリング則は一枚岩の真理ではなく、修正を重ねて精度を増してきた——その自己修正の過程こそが、この分野の健全さの証だと私は思う。
Language Models are Few-Shot Learners(2020, OpenAI)——「例をいくつか見せるだけ」で学ぶ巨人
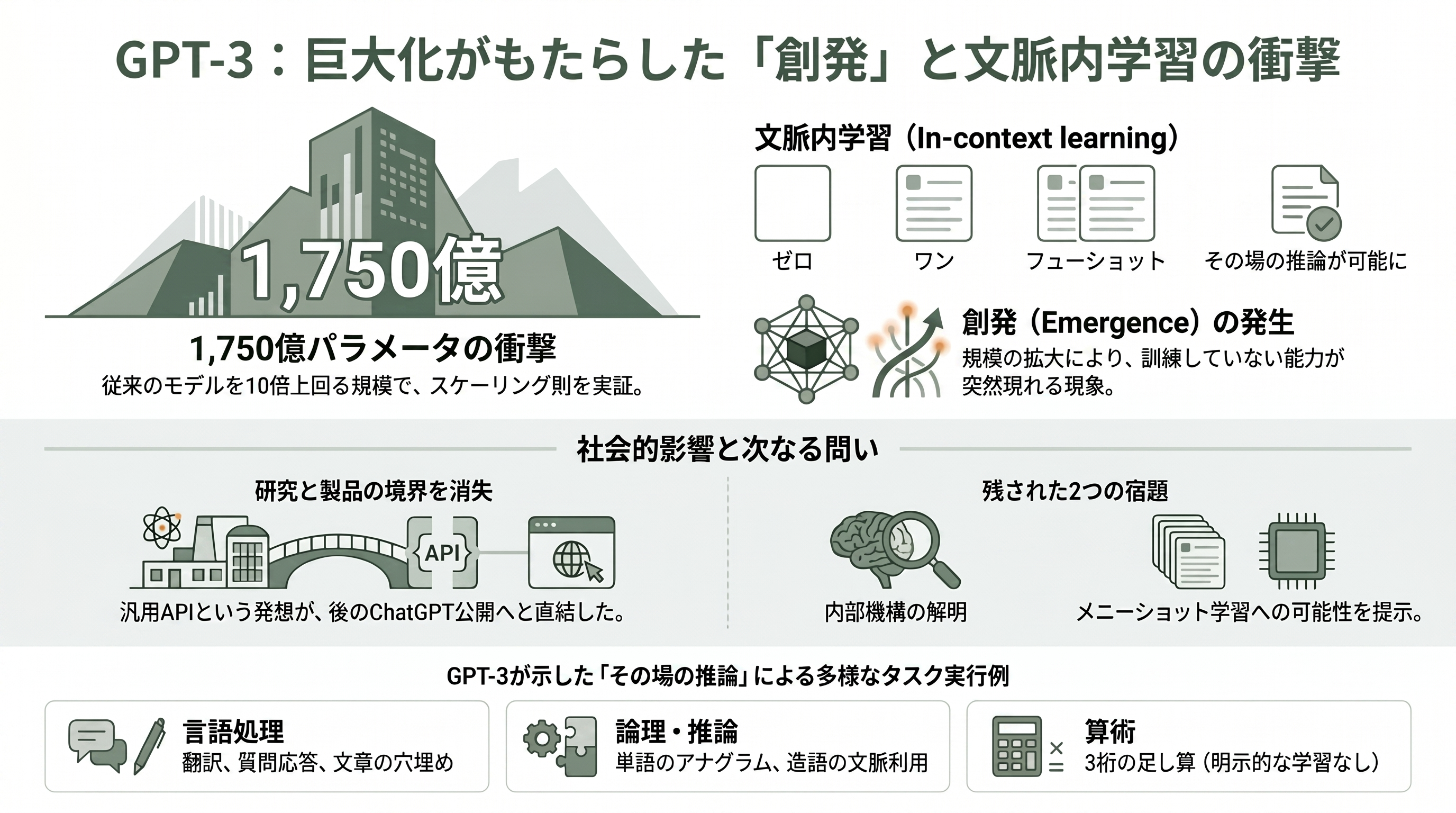
スケーリング則の理論を、世界が度肝を抜く形で実証したのが、2020年に発表されたGPT-3の論文「言語モデルは少数例学習器である(Language Models are Few-Shot Learners)」だ。NeurIPS 2020の最優秀論文賞に輝いたこの研究は、当時としては桁外れの1,750億パラメータ——それまでのどの非スパースモデルより10倍大きい——という巨大言語モデルが、思いもよらない能力を獲得することを示した。
その能力こそが、本稿を貫く第二の伏線、文脈内学習(in-context learning)である。たとえ話で説明しよう。普通の機械学習では、翻訳ができるようにしたければ翻訳用のデータで「追加の訓練(微調整)」をやり直す必要がある。ところがGPT-3は違った。プロンプト(入力文)の中に「sea otter → loutre de mer、cheese → fromage」と数個の例を書いて、最後に「dog →」と書くだけで、モデルは追加の訓練なしに「chien」と続けてしまう。重みを一切更新せず、ただ与えられた文脈を読んで「ああ、これは英仏翻訳のタスクだな」とその場で察してやってのける。論文はこれを、例を一つも見せない「ゼロショット」、一つだけ見せる「ワンショット」、10〜100個見せる「フューショット」という三段階で体系的に評価した。
GPT-3が見せた芸当は多岐にわたる。翻訳、質問応答、文章の穴埋めに加え、単語のアナグラムを解く、新しく作った造語を文中で使ってみせる、3桁の足し算をする、といった「その場の推論」を要するタスクまでこなした。誰も明示的に「足し算を教えていない」のに、大量のテキストを読む中で算術の規則性を内部に獲得していた。この「規模を大きくすると、訓練していないはずの能力が突然現れる」という現象——後に創発(emergence)と呼ばれる——こそ、GPT-3が研究者コミュニティに与えた最大の衝撃だった。
シリコンバレーの視点で振り返ると、GPT-3は「研究」と「製品」の境界を溶かした論文でもあった。この汎用APIという発想がChatGPTへと直結し、2022年末のChatGPT公開で生成AIは一般社会の現象になる。同時に、GPT-3は本稿後半への二つの宿題を残した。第一に「なぜ文脈内学習が起きるのか、その内部機構は何か」——これに答えるのが次章以降のAnthropicの解釈可能性研究だ。第二に「フューショットの『数個』を『数百個』に増やしたらどうなるのか」——これがメニーショット学習の章につながる。GPT-3は答えであると同時に、巨大な問いの宝庫だったのである。
Learning to Reason with LLMs(2024, OpenAI)——「考えてから答える」がスケーリングの新しい軸を開いた

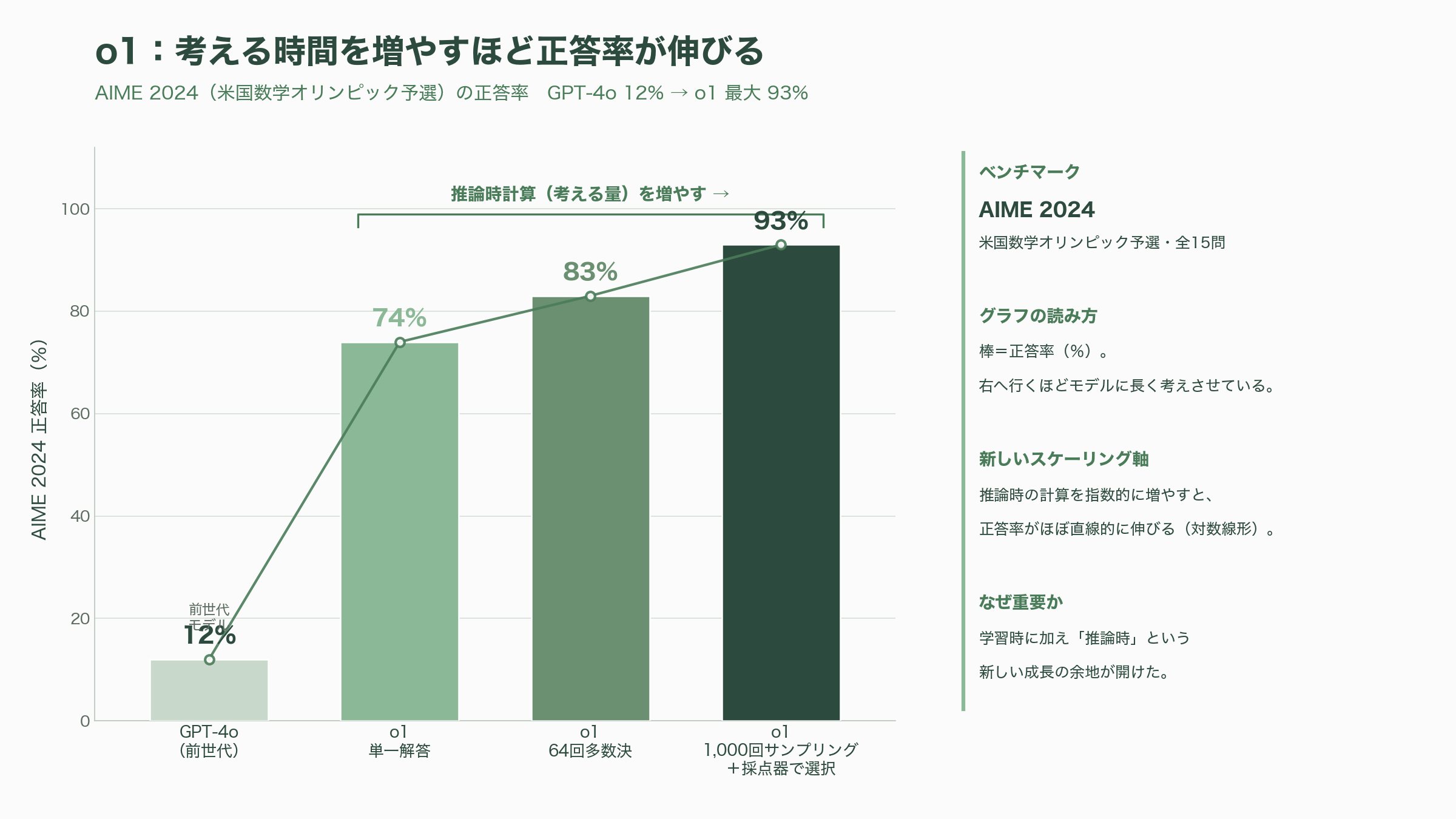
OpenAIの第三作として、2024年9月に発表された推論モデルo1の技術レポート「Learning to Reason with LLMs」を取り上げたい。これは、それまでの「モデルを大きくし、学習の計算を増やせば賢くなる」というスケーリングの常識に、まったく新しい軸を付け加えた。すなわち「答える前に、モデルに長く考えさせる(推論時の計算を増やす)ほど賢くなる」という軸だ。
直感的な例で考えよう。難しい数学の問題を、人間が反射的に即答するのと、紙に途中式を書きながらじっくり10分考えるのとでは、正答率がまるで違う。従来の言語モデルは、いわば全問を反射で即答していた。o1がやったのは、答えを出す前に内部で長い「思考の連鎖(chain of thought)」——仮説を立て、検算し、間違いに気づいて方針を変える——を展開させることだ。しかも、その考え方をうまく教え込むために、人間が書いた手本を真似させるのではなく、大規模な強化学習を使った。モデルに問題を解かせ、正しい推論の筋道には報酬を与え、自分で「productive(生産的)に考える」やり方を発見させる。ここでも、AlphaGo Zeroから続く「自己改善による強化学習」の系譜が効いていることに注目してほしい。
成果は劇的だった。アメリカ数学オリンピックの予選AIME 2024で、前世代のGPT-4oが平均12%(15問中1.8問)しか解けなかったのに対し、o1は1回の解答で74%、64回の多数決で83%、1,000回サンプリングして学習済みの採点器で選び直すと93%にまで到達した。競技プログラミングのCodeforcesでは上位11%(89パーセンタイル)に入り、博士レベルの科学問題でも専門家に匹敵した。そして論文が示した最も重要なグラフは、「考える時間(推論時計算)を指数的に増やすと、正答率が直線的に伸びる」という対数線形の関係だ。学習時の計算と推論時の計算という、二つの独立した軸でモデルを賢くできることが、ここで初めてはっきり示された。
研究者として、この論文の意義を二点強調したい。第一に、Chinchilla以降「学習データが枯渇しつつあり、スケーリングは頭打ちでは」という懸念が業界に漂っていた中で、o1は「推論時計算」というまったく新しい成長の余地を開いた。これは資金調達のロジックも、半導体への需要も塗り替えた。第二に、o1の系譜はその後のo3などの推論モデル群へと受け継がれ、2026年現在、各社のフラッグシップは「考える」ことを前提とした設計になっている。後述するAnthropicのClaude Opus 4.8も、OpenAIのGPT-5.5も、この「推論時スケーリング」の世界を生きている。第二幕のOpenAIが描いたのは、「スケールは一つの方向ではなく、複数の軸を持つ」という、より豊かなスケーリングの地図だった。
A Mathematical Framework for Transformer Circuits(2021, Anthropic)——ブラックボックスを「回路」として読み解く
ここから第三幕、Anthropicの物語に入る。Anthropicは2021年、OpenAIでGPT-3やスケーリング則を主導した研究者たち——ダリオ・アモデイ、ダニエラ・アモデイ兄妹や、スケーリング則の筆頭著者ジャレッド・カプランら——が「能力を闇雲に上げる前に、まずモデルを理解し安全にする」という理念を掲げて独立して創業した。その思想を最も純粋に体現するのが、2021年12月に発表された「Transformer回路のための数学的枠組み(A Mathematical Framework for Transformer Circuits)」である。
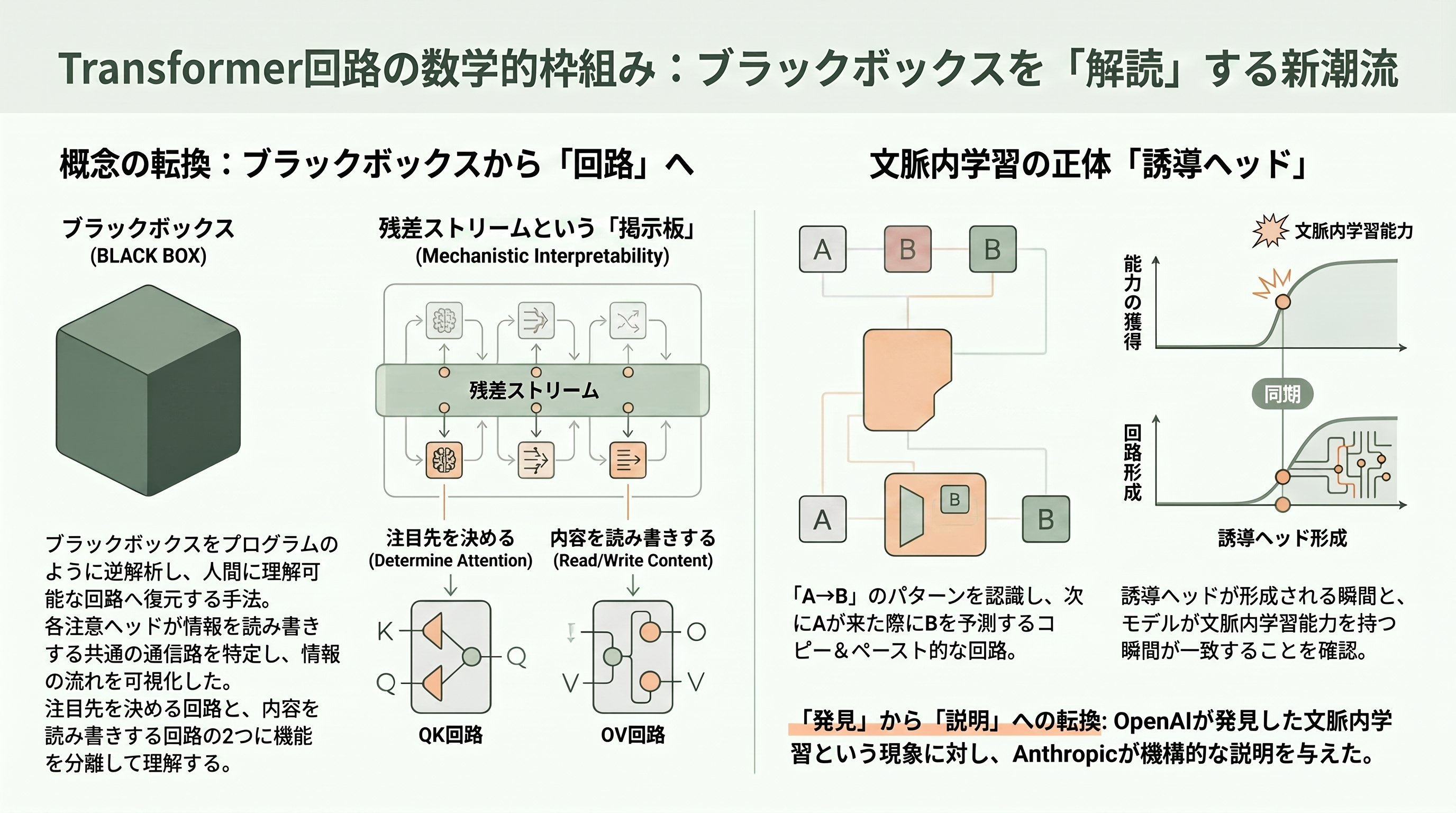
この論文の問題意識を、たとえ話で説明しよう。巨大言語モデルは数千億の数値の塊で、入力を入れると出力が出てくるが、その中で「何が起きているのか」は誰も分からない、巨大なブラックボックスだ。著者のネルソン・エラージュらが目指したのは、このブラックボックスを、まるでコンパイル済みのプログラムを逆アセンブルしてソースコードに復元するように、人間に理解できる「回路(circuit)」へと逆解析することだった。この分野は機械的解釈可能性(mechanistic interpretability)と呼ばれ、Anthropicがその旗手となった。
論文はまず、本物の巨大モデルではなく、注意機構だけを持つ「0層・1層・2層」という極端に小さなおもちゃのモデルを徹底的に分解した。そこで導入された見方が美しい。Transformerの内部には「残差ストリーム(residual stream)」という共通の通信路があり、各注意ヘッドはそこから情報を読み出し、計算結果を書き戻す——いわばモデル内部の「掲示板」のように働く。そして個々の注意ヘッドの働きは、「どの単語に注目するかを決める回路(QK回路)」と「注目した先から何を読み取って書き込むかを決める回路(OV回路)」という二つに分解できる、と示した。ブラックボックスが、解釈可能な部品の組み合わせとして見え始めたのである。
この論文の最大の発見が「誘導ヘッド(induction heads)」だ。これは2層のモデルで初めて出現する回路で、「直前に『AならばB』というパターンを見たら、次にAが来たときにBを予測する」というコピー&貼り付けのような働きをする。一見地味だが、これこそ前章でGPT-3が見せた「文脈内学習」の正体の有力候補なのだ。実際、Anthropicは続く2022年の研究で、この誘導ヘッドがモデル内に形成される瞬間と、文脈内学習能力が立ち上がる瞬間が一致することを示した。つまり本章は、第二幕でOpenAIが「発見」した不思議な現象に、第三幕のAnthropicが「機構的な説明」を与えた、という伏線回収になっている。能力の物語が、理解の物語へと折り返す転回点が、この論文なのである。
Constitutional AI: Harmlessness from AI Feedback(2022, Anthropic)——AIがAIを躾ける「憲法」という発明
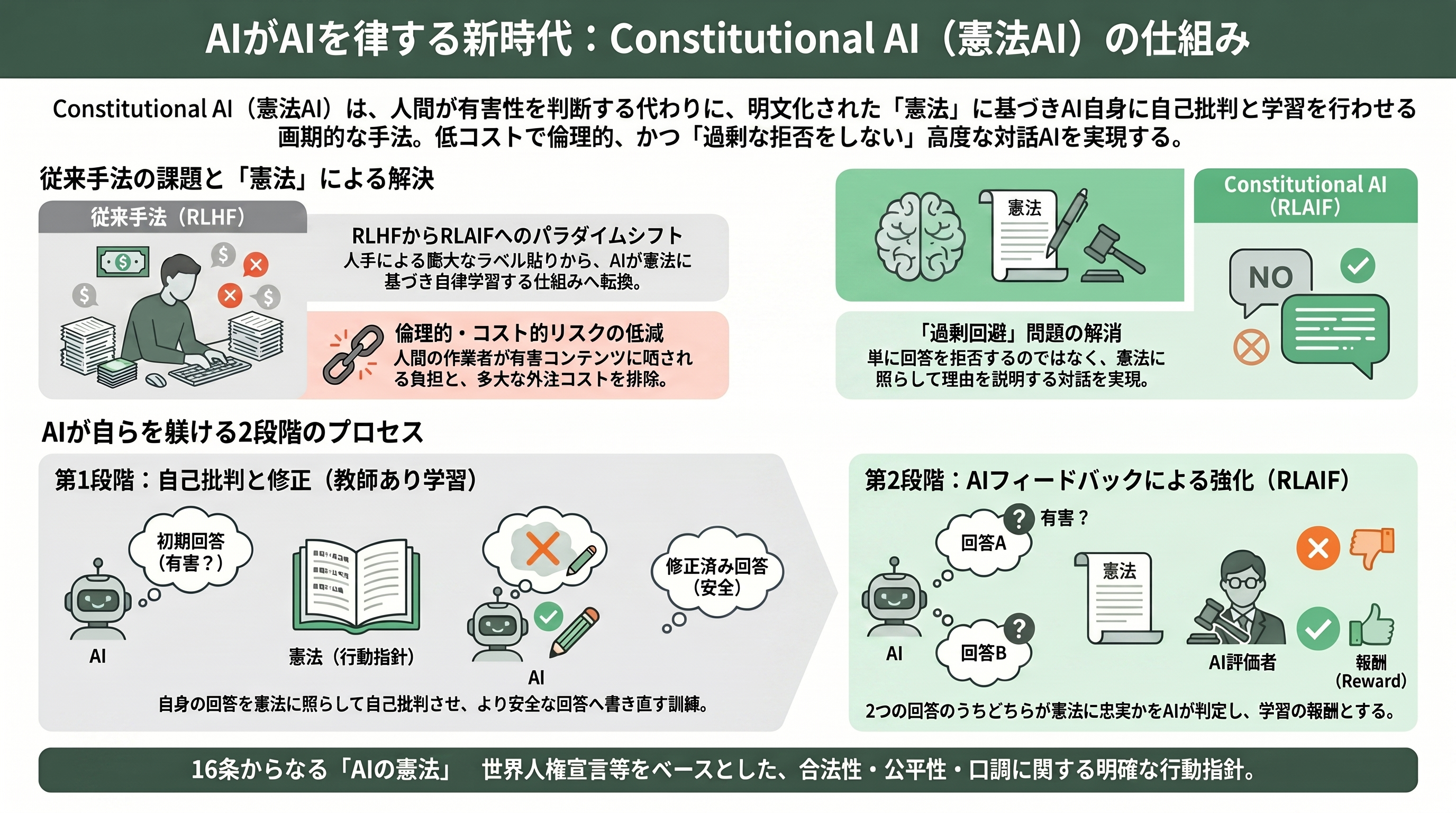
Anthropicの二つ目の代表作が、2022年12月に発表された「Constitutional AI: AIフィードバックによる無害性」だ。これは、その後のAnthropicの製品Claudeの根幹をなす訓練手法であり、「AIを安全にするのに、有害な出力へ人間が一つひとつダメ出しのラベルを貼り続ける必要はない」という、実務的にも思想的にも重要な転換を示した。
背景を説明しよう。ChatGPTなどで使われる標準的な安全化手法は「人間のフィードバックによる強化学習(RLHF)」で、何万もの有害/無害の判定を人間が手作業で行う。だがこれは高コストで、人間の作業者が大量の有害コンテンツに晒される倫理的問題もあり、何を有害とするかの基準も不透明だった。Anthropicの問いはこうだ——基準を明文化した「憲法(constitution)」としてあらかじめ与え、躾の作業そのものはAI自身にやらせられないか。
仕組みは二段階からなる。第一段階(教師あり学習)では、まずモデルにわざと有害な質問をぶつけて危うい答えを出させ、次にそのモデル自身に「いまの答えは憲法の○○という原則に照らして問題がある」と自己批判させ、答えを書き直させる。そして書き直した無害な応答でモデルを微調整する。第二段階(強化学習)では、モデルに二つの応答を生成させ、どちらが憲法に適っているかをAI自身に判定させて選好データを作り、それを報酬としてさらに訓練する。人間のラベルではなくAIのフィードバックで報酬を作るので、この手法はRLAIF(Reinforcement Learning from AI Feedback)と呼ばれる。憲法は世界人権宣言などを参照した16条ほどの原則からなり、合法性・有害性・公平性・口調といった観点をカバーする。
この論文が見事なのは、安全性と有用性のトレードオフに新しい解を出した点だ。従来の手法では、無害化を強めるとモデルが「その質問にはお答えできません」と何でも拒否する過剰回避に陥りがちだった。Constitutional AIで訓練したモデルは、有害な要求に対して単に黙るのではなく、なぜ応じられないのかを説明しながら対話する「無害だが回避的でない」アシスタントになった。研究者の視点で言えば、ここでもAlphaGo Zero以来の「自己改善」の思想が効いている——モデルが自分の出力を批判し、改訂し、自分の選好で自分を訓練する。Anthropicはこの手法を後に「集団的Constitutional AI」として一般市民の意見を憲法に反映させる実験へと発展させ、AIの価値観を誰がどう決めるのかという統治の問題にまで踏み込んでいる。
Many-Shot In-Context Learning(2024, DeepMind)とMany-shot Jailbreaking(2024, Anthropic)——文脈内学習の光と影
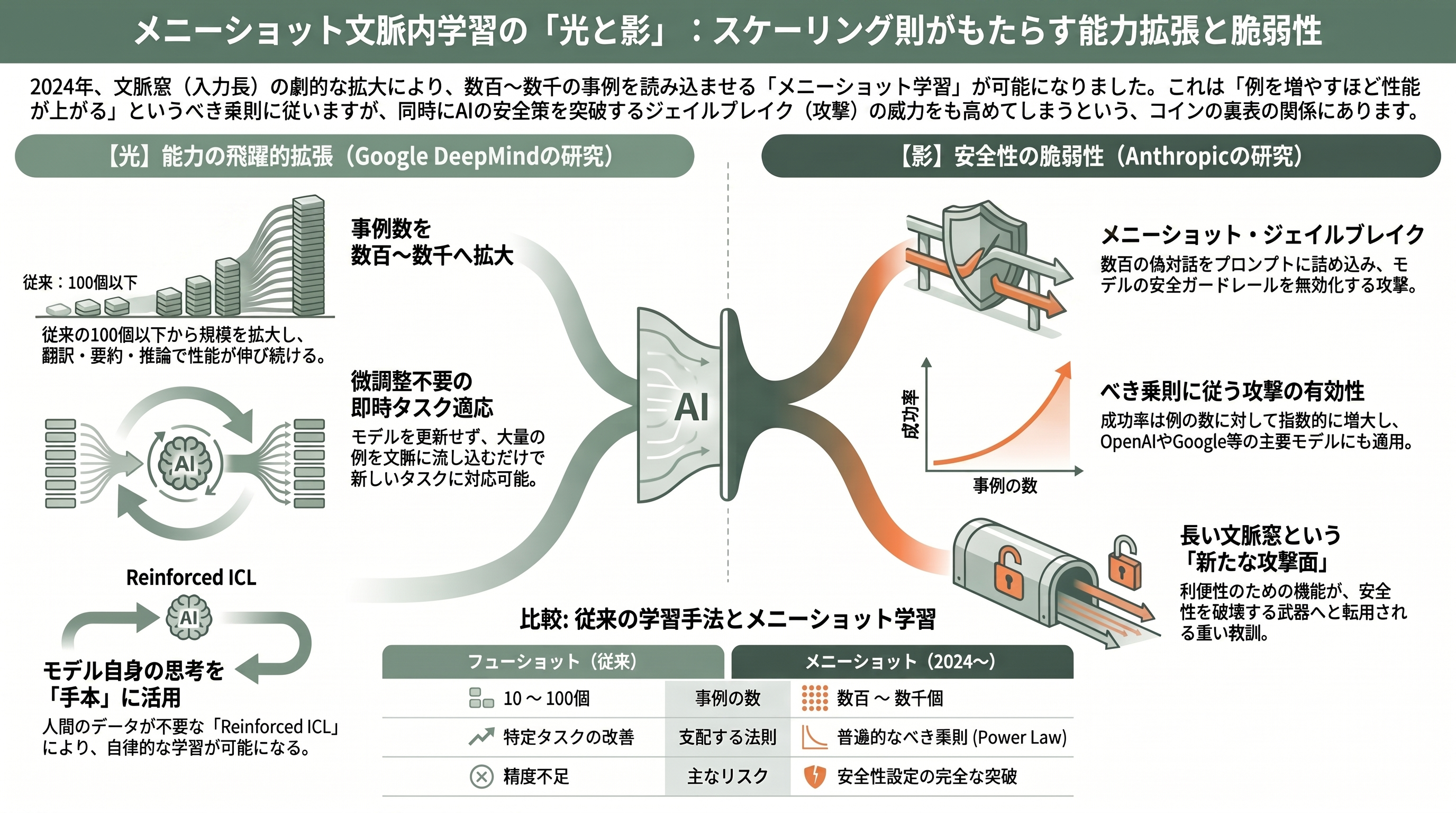
本章では、2024年に文脈内学習を新たな規模へ押し広げた「メニーショット学習」を扱う。
まず現象そのものを押さえよう。第二幕のGPT-3が示したフューショット学習は、プロンプトに例を「10〜100個」入れるものだった。ところが2024年までに各社の文脈窓(一度に読み込める入力長)が爆発的に伸び、数十万トークンを扱えるようになった。そこでGoogle DeepMindは素朴な実験をした——例を数百個から数千個まで増やしたらどうなるか。結果、翻訳・要約・推論など幅広いタスクで性能が大きく伸び続けることが分かった。さらに彼らは、人間が用意した手本が枯渇する問題に対し、モデル自身が生成した思考の連鎖を手本に使う「Reinforced ICL」や、手本の答えすら与えず問題だけを大量に並べる「Unsupervised ICL」でも効果が出ることを示した。微調整に頼らず、ただ大量の例を文脈に流し込むだけで、モデルを新しいタスクへ適応させられるのである。
ではAnthropicの「メニーショット・ジェイルブレイク」とは何か。これは同じ原理の危険な裏面だ。Anthropicの研究者は、安全に訓練されたはずのモデルに対し、「危険な質問に丁寧に答えている」偽の対話を数百回ぶんプロンプトに詰め込むと、モデルがその文脈に引きずられて、本来は拒否すべき有害な要求にまで応じてしまうことを発見した。恐ろしいのは、その有効性が例の数に対してべき乗則で増大する点だ——これはまさに、文脈内学習が持つ普遍的な性質そのものである。しかもこの攻撃はAnthropic自身のClaudeだけでなく、OpenAIやGoogle DeepMindのモデルにも通用した。長い文脈窓という「便利な機能」が、そのまま新しい攻撃面になるという、安全性研究の重い教訓だ。
この二本を並べて読むと、現代AIの本質が見えてくる。文脈内学習は、GPT-3で発見され(第二幕)、Transformer回路で機構が解明され(本幕の誘導ヘッド)、そしてメニーショットで「規模を上げれば上げるほど強力になる、べき乗則に従う現象」だと確認された。スケーリング則がモデルの「学習」を支配したように、べき乗則は「文脈内学習」をも支配していたのである。そして同じ力が、能力の拡張(DeepMind)にも、安全性の破壊(Anthropic)にも使えてしまう。この両義性こそ、能力と安全を同時に見すえるAnthropicが、わざわざ攻撃手法を公表してまで業界に警告した理由だった。
Scaling Monosemanticity(2024, Anthropic)——本番のClaudeから「意味の部品」を取り出す
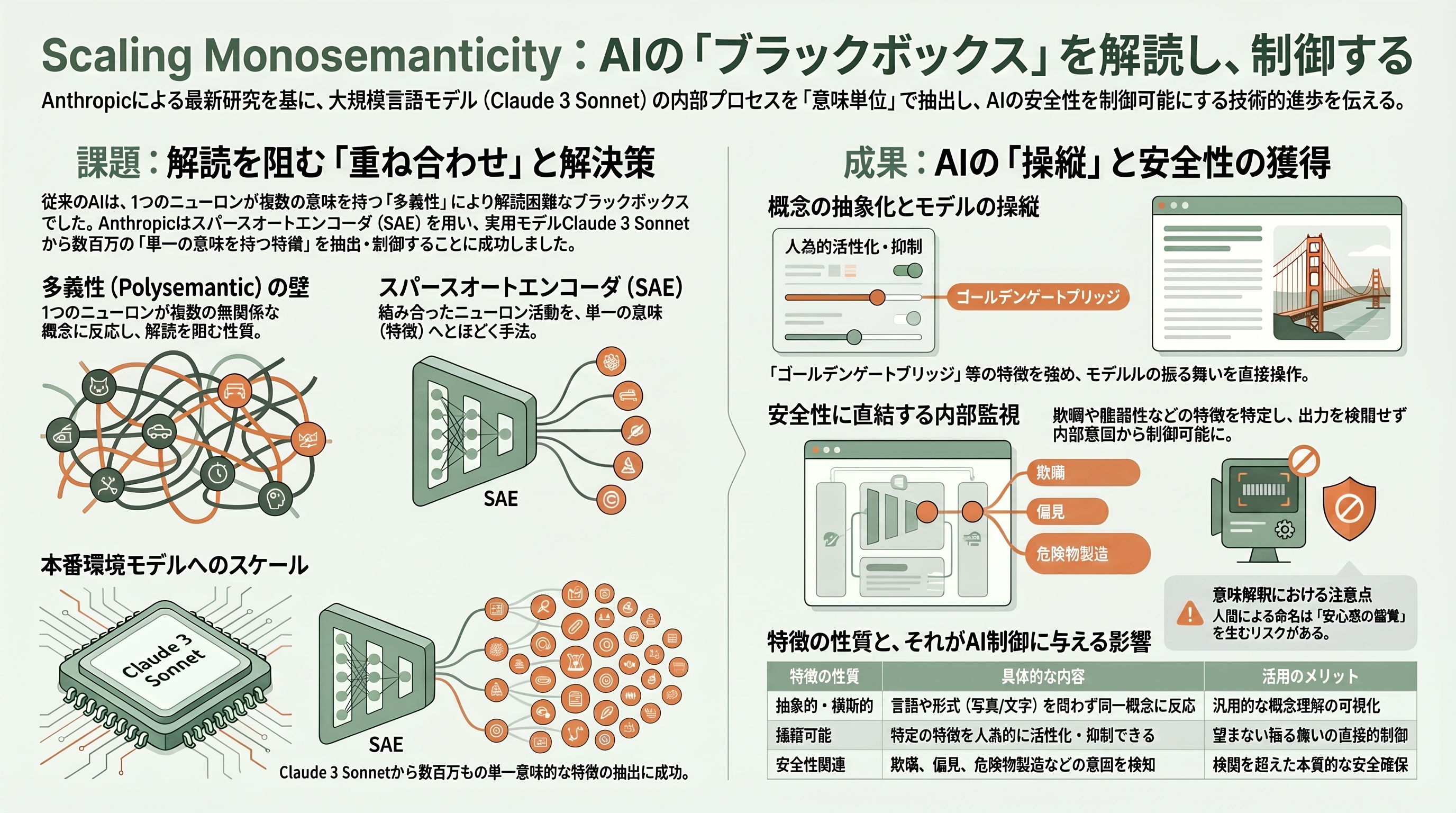
第三幕の締めくくり、そして本稿10本目の論文が、2024年5月にAnthropicが発表した「Scaling Monosemanticity: Claude 3 Sonnetから解釈可能な特徴を抽出する」だ。Transformer回路の章で芽生えた機械的解釈可能性の野心が、ついに本番環境で稼働する実物の大規模モデルClaude 3 Sonnetに対して結実した、記念碑的な研究である。
問題の核心は「重ね合わせ(superposition)」と呼ばれる厄介な性質にある。ニューラルネットの一つひとつのニューロンは、人間が期待するように「犬」や「悲しみ」といった一つの概念にきれいに対応してくれない。一個のニューロンが何十もの無関係な概念に同時に反応する多義的(polysemantic)な状態になっており、これがモデル解読を阻む最大の壁だった。Anthropicは2023年の先行研究「Towards Monosemanticity」で、スパースオートエンコーダ(SAE)という手法を使えば、絡み合ったニューロンの活動を「一つの意味に対応する特徴(feature)」へとほどける、と小さなモデルで示していた。本論文の問いは「この手法は、おもちゃのモデルから本物の巨大モデルへスケールするのか」だった。
答えはイエスだった。Anthropicは辞書学習の要領で、Claude 3 Sonnetの中間層の活動から数百万もの単一意味的(monosemantic)な特徴を抽出することに成功した。それらの特徴は驚くほど抽象的で、言語や様式をまたいでいた。たとえば「ゴールデンゲートブリッジ」に対応する特徴は、英語でも日本語でも、橋の写真でも、その名に反応する。さらに重要なのは、これらの特徴が単にモデルの状態を観測できるだけでなく、人為的に活性を強めることで振る舞いを操縦できた点だ。研究チームが「ゴールデンゲートブリッジ特徴」を最大まで引き上げたところ、Claudeは何を聞かれても自分をその橋だと思い込み、あらゆる話題を橋へ結びつけて語り出した——これが一時公開され話題を呼んだデモ「Golden Gate Claude」である。
研究者として最も重要だと考えるのは、安全性に直結する特徴が見つかったことだ。Anthropicは、欺瞞・おべっか(追従)・偏見・危険物の製造・コードの脆弱性といった、まさに監視したい振る舞いに対応する特徴を発見した。モデルが「嘘をつこうとしている」内部状態を特徴として捉え、操作できるなら、AIの安全性は「出力を後から検閲する」段階から「内部の意図を直接読み、制御する」段階へと進みうる。もっとも論文は誠実に限界も認めている。たとえば「ゴールデンゲートブリッジ特徴」と名付けても、その特徴が活性化する場面の大半は橋と無関係で、本当に橋を表すのは活性が極めて高い1割未満のときだけだ——特徴に人間が名前を付ける行為には、安心感の錯覚という落とし穴がある。それでもこの論文は、Transformer回路の章で掲げた「ブラックボックスを回路として読む」という夢が、最先端モデルでも現実になりうることを証明した。第三幕は、能力の物語を「理解と制御の物語」として完成させたのである。
全体の流れの振り返りと、ここから先への見解
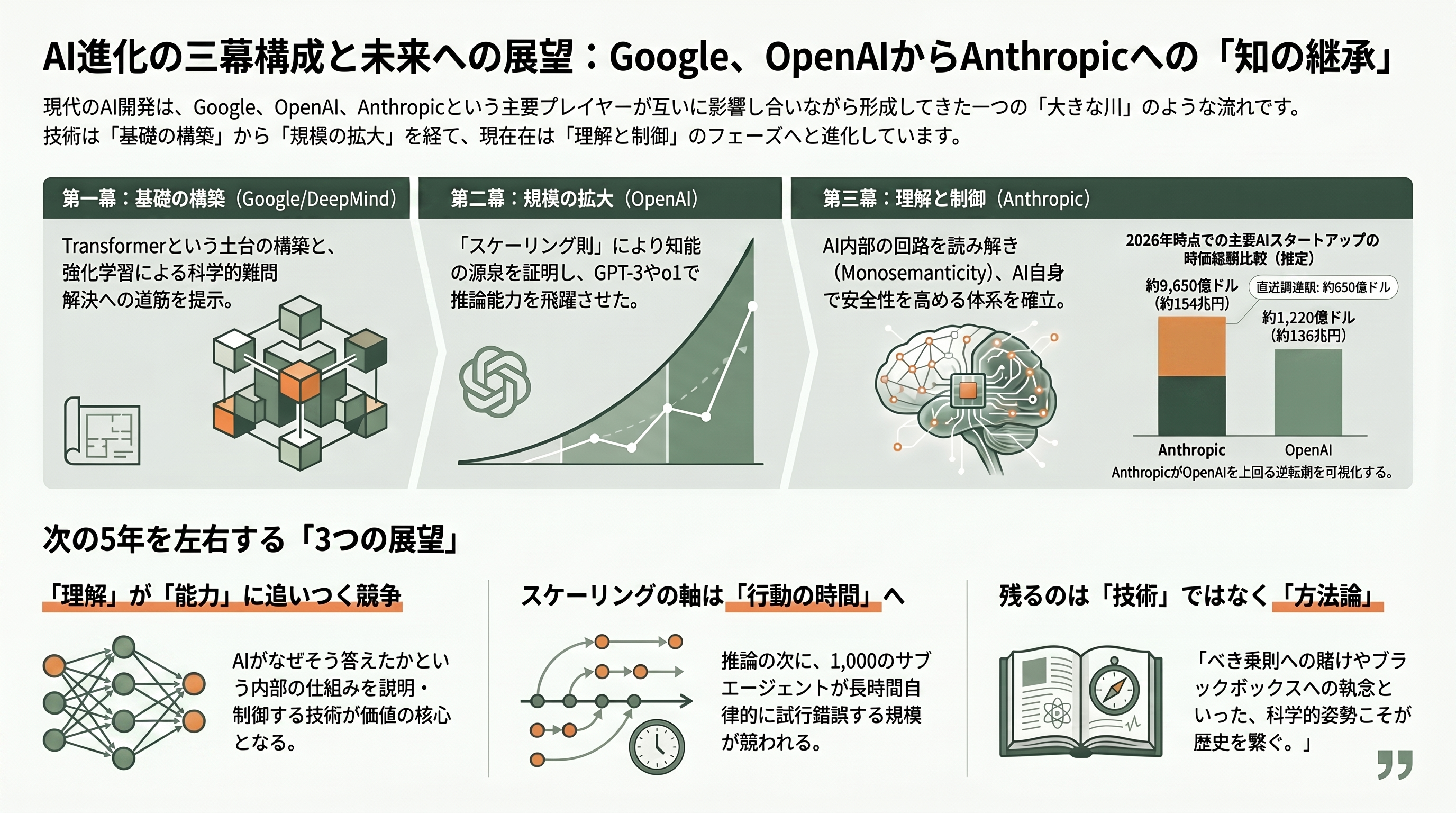
10本を読み終えたいま、改めて全体を俯瞰しよう。三幕の物語は、独立した発見の寄せ集めではなく、互いに引用し、批判し、引き継ぎ合う一本の太い川だった。第一幕でGoogleがTransformerという土台を据え、DeepMindが「自己対戦の強化学習で人間を超える」原理(AlphaGo Zero)と「AIで自然科学の難問を解く」射程(AlphaFold)を示した。第二幕でOpenAIが、その土台の上で「スケールこそが知能を生む」と法則化し(スケーリング則)、実証し(GPT-3)、さらに「推論時に考える」という新しいスケールの軸を開いた(o1)。第三幕でAnthropicが、第二幕が生んだ巨大な力に対し、「中で何が起きているかを回路として読み(Transformer回路、Monosemanticity)、AI自身のフィードバックで躾け(Constitutional AI)、その力の両義性を直視する(メニーショット)」という、理解と制御の体系を築いた。
この川を貫く二本の伏線は、見事に回収された。強化学習は、AlphaGo Zeroの自己対戦から、Constitutional AIのRLAIF、o1の推論学習へと姿を変えて流れ続け、「モデルが自分の出力を評価して自分を改善する」という思想を現代AIの中核に据えた。文脈内学習は、GPT-3で発見され、誘導ヘッドで機構が解かれ、メニーショットでべき乗則として拡張され、Monosemanticityで特徴として可視化された——発見・説明・拡張・観測という科学の理想的なサイクルを、わずか数年で駆け抜けたのである。そしてTransformerは、文章だけでなくタンパク質(Evoformer)まで、すべての土台であり続けた。「Attention Is All You Need」は、文字どおり真実だった。
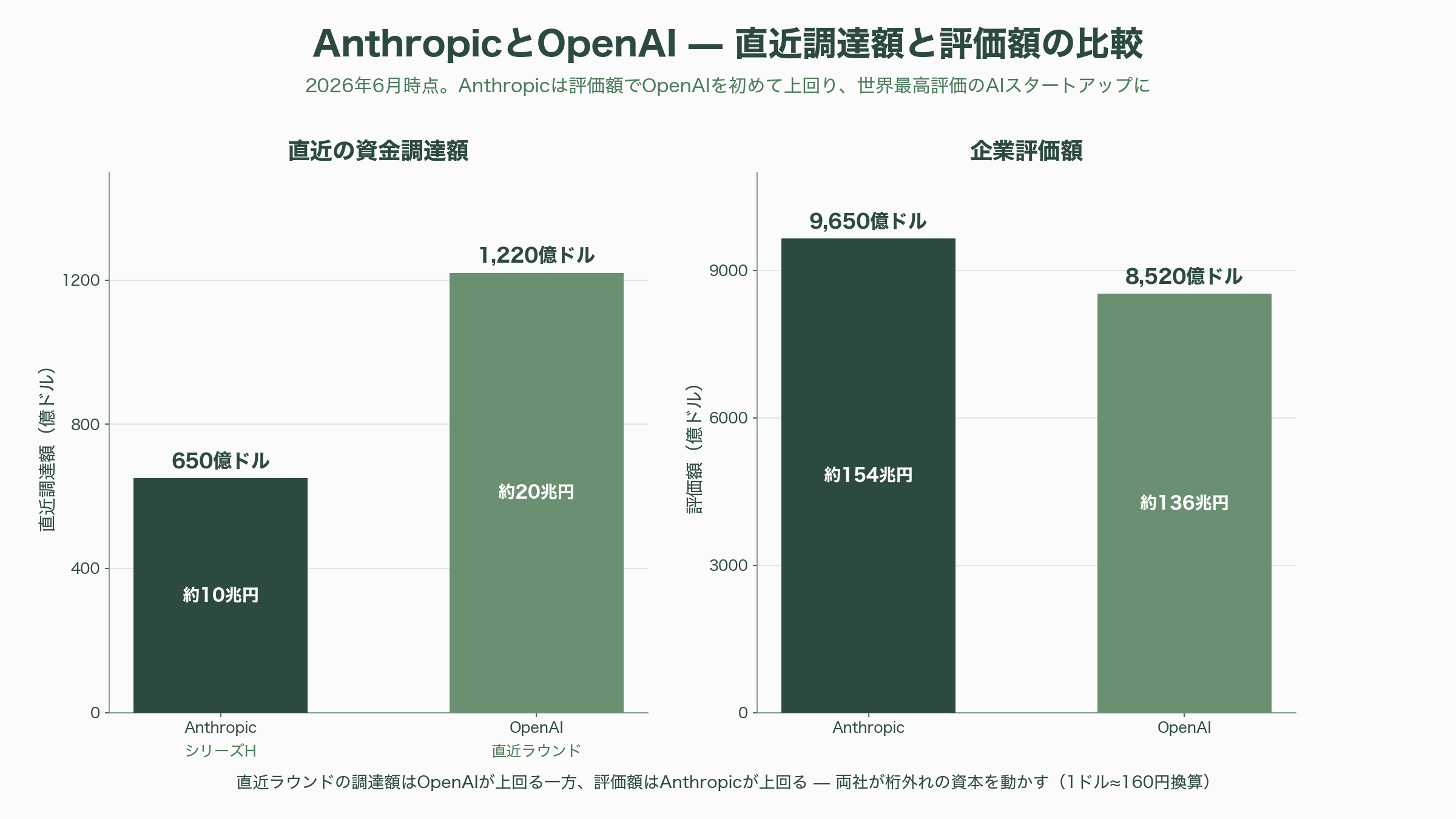
シリコンバレーの内側から見て痛感するのは、これが「論文の歴史」であると同時に「人の移動の歴史」だった、ということだ。Transformerの8人の著者はGoogleを去って業界の家系図そのものになり、スケーリング則とGPT-3を率いた研究者たちはOpenAIを去ってAnthropicを創った。能力を追う者と安全を問う者が同じ研究室の出身であり、互いの論文を引用し合いながら別の旗を掲げている——この緊張関係こそが、この分野の進化を駆動してきた。そしてその緊張は、2026年6月のいま、資本市場にもそのまま映し出されている。Anthropicは2026年5月、シリーズHで650億ドル(約10兆円)を調達して評価額約9,650億ドル(約154兆円)に達し、長年のライバルOpenAI(直近の調達額約1,220億ドル=約20兆円、評価額約8,520億ドル=約136兆円)を初めて上回って、世界で最も価値あるAIスタートアップとなり、IPOの準備に入ったと報じられている。10本の論文に始まった知の探究は、いまや一国の経済規模に匹敵する資本を動かしている。
では、ここから先はどこへ向かうのか。私の見立てを三点述べたい。第一に、「理解」が「能力」に追いつく競争が本格化する。Monosemanticityが切り開いた解釈可能性は、まだモデルのごく一部を照らしたにすぎない。だが、AIが社会の重要な意思決定に入り込むほど、「なぜそう答えたか」を内部から説明し、危険な内部状態を検知・制御する技術の価値は跳ね上がる。能力の指数関数に、理解の指数関数をどこまで並走させられるかが、今後5年の核心的な問いになる。第二に、スケーリングの軸はさらに増える。学習時・推論時に続き、エージェントが長時間にわたり自律的に試行錯誤する「行動の時間軸」が次の戦場だ。実際、2026年5月に登場したClaude Opus 4.8は最大1,000のサブエージェントを並列に走らせる機能を備え、GPT-5.5と長時間タスクの完遂能力を競っている。o1が開いた「考える時間」の先に、「動き続ける時間」がある。
第三に、そして最も重要なこととして、これら10本が示したのは「終着点」ではなく「方法論」だということを強調したい。きれいなべき乗則を信じて巨大な賭けに出る勇気、ブラックボックスを諦めずに回路として読み解く執念、能力と同じ熱量で安全性を問う規律——個々の技術はやがて陳腐化しても、この方法論は次の10本、次の100本を生み続けるだろう。DeepMindからOpenAI、そしてAnthropicへと受け渡されてきたのは、特定のアーキテクチャや数式ではなく、「自然と知能の最も深い謎に、計算という道具で正面から挑む」という姿勢そのものだった。次にAIの歴史を変える珠玉の論文は、いままさにどこかのラボで書かれている。その源流をたどれば、きっと本稿の10本に行き着くはずだ。