なぜシリコンバレーのエンジニアは静観したのか
2026年4月1日の早朝、Claude Codeのソースコード(裏側ではなく、フロントのCLIツール部分)が流出した。2025年2月に続いて2回目であるがシリコンバレーのエンジニアはこれを静観している。
これはつまり、既にClaude Codeを始めとするAIは、マシン語(バイナリ・アセンブリ)を理解する能力を持ち、配布モジュールのソースコードを秘匿するのは無意味なことであり、復元されても問題無いものとすべきだというアンソロピックのメッセージなのかも知れない。実際、Geminiも「難読化ツールが使われていても2026年のAIは見抜く確率が上がっている」としている。
2025年2月の最初の流出時、Geoffrey Huntleyはクリーンルーム方式の難読化解除プロジェクトを公開し、こう述べた。
「これらのLLMは、難読化解除、トランスパイル、構造間変換が驚くほど上手い。」
1年後、その言葉はさらに重みを増している。2026年のAIは、バイナリからソースコードを復元する能力を飛躍的に向上させた。そもそも我々が「隠している」と思っているソースコードは、本当に隠されているのか。問題はもはや「AIでソースコードを復元できるか」ではなく、「どの程度の精度で、どこまで復元できるか」だ。
AIによるバイナリ→ソースコード復元——2026年の到達点
LLM4Decompile——専用モデルによるバイナリ逆コンパイル
LLM4Decompileは、バイナリコードからソースコードを復元するために設計されたオープンソースのLLMだ。1.3Bから33Bまでのパラメータサイズで提供され、GCC O0〜O3最適化レベルのLinux x86_64バイナリに対応する。
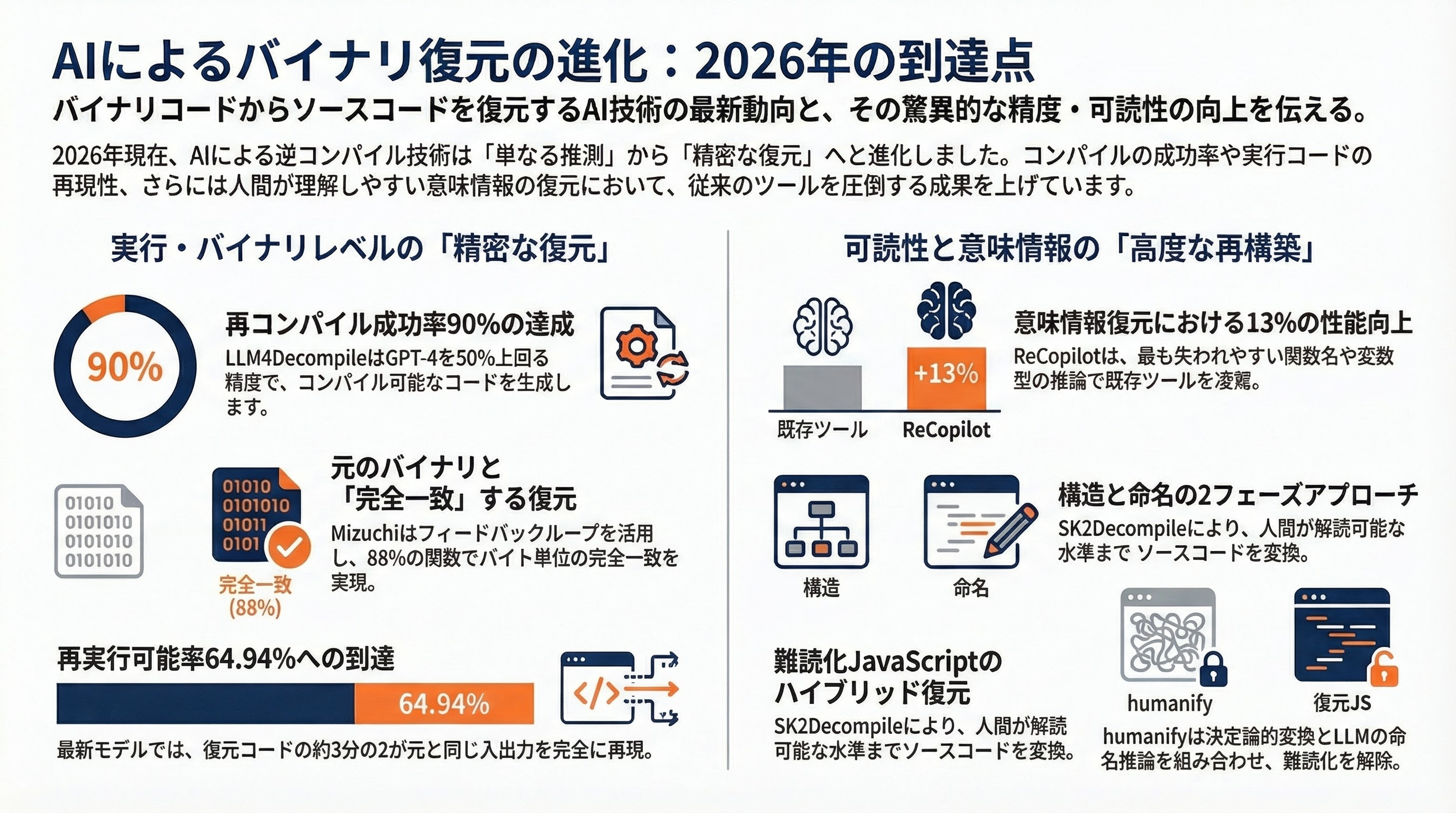
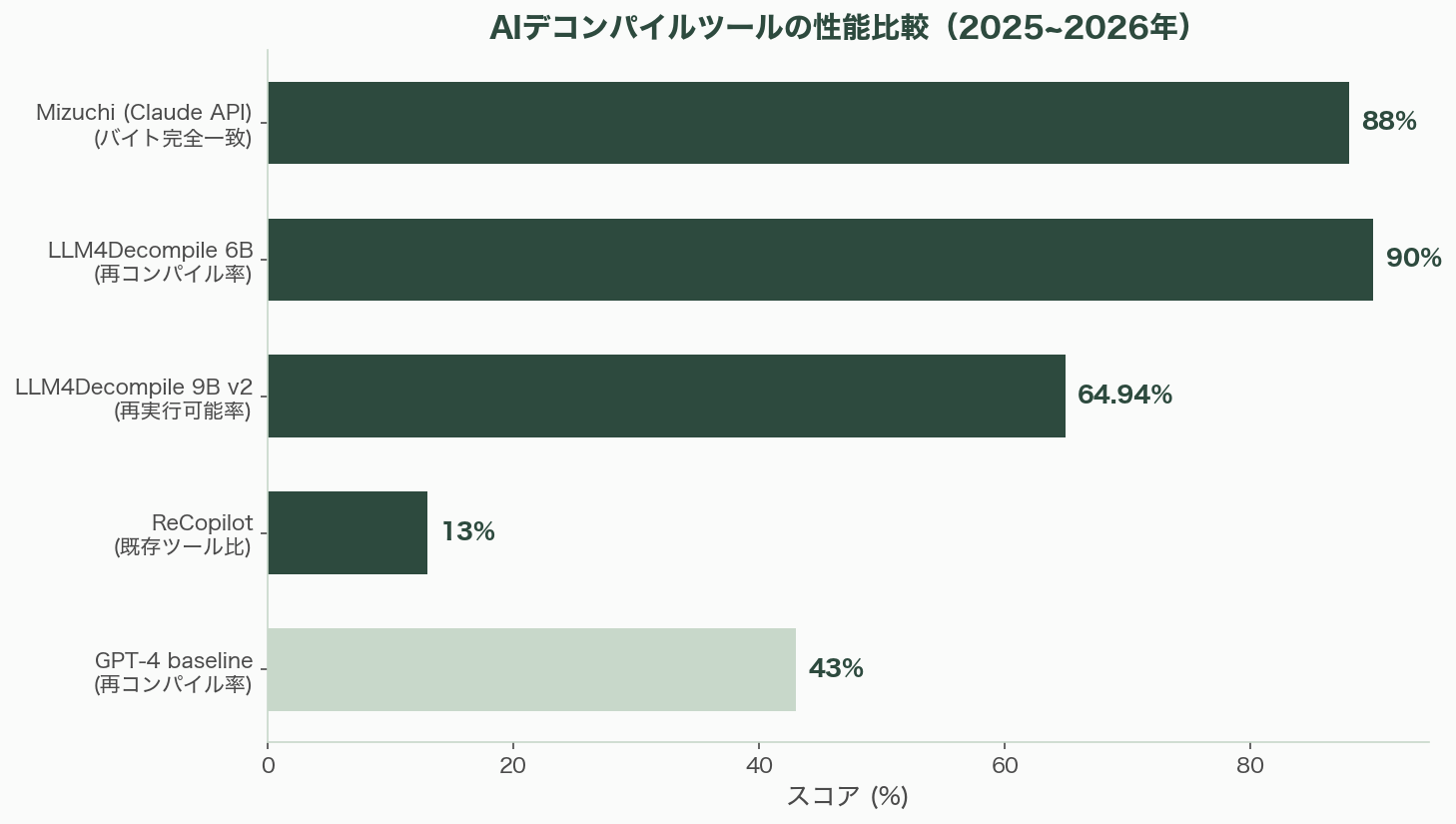
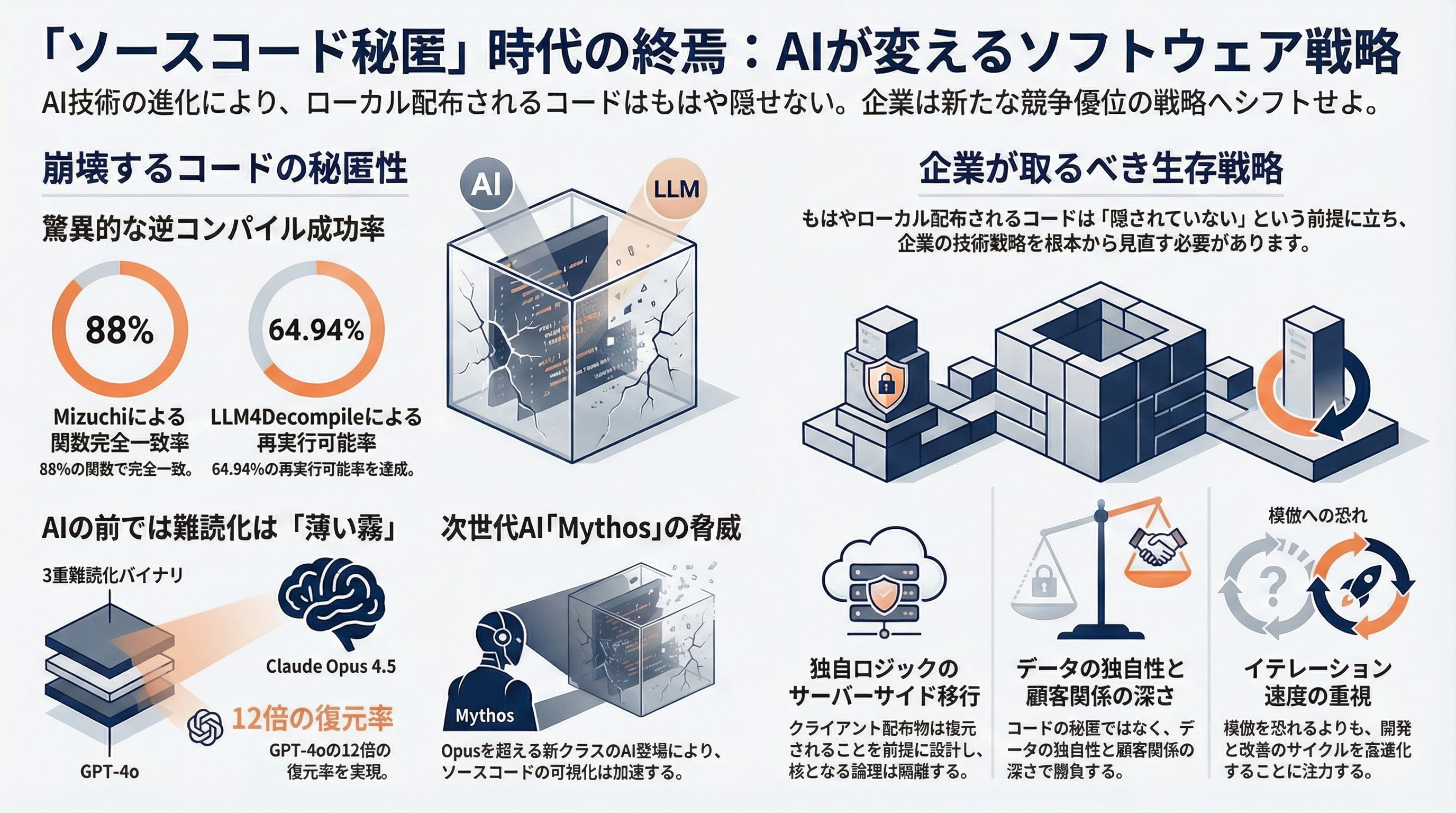
その性能は急速に進化している。6.7BモデルはHumanEvalベンチマークで45.4%の精度を達成し、6Bモデルは90%の再コンパイル可能率——つまり、復元されたCコードの90%がコンパイルを通る——を記録した。これはGPT-4を50%上回る改善だ。さらに、最新のLLM4Decompile-9Bv2は再実行可能率を64.94%にまで引き上げた。復元されたコードの約3分の2が、元のプログラムと同じ入出力を再現できるのだ。
Decompile-Benchプロジェクトは、100万規模のバイナリ-ソースコード関数ペアを提供し、実世界のデータで訓練されたLLM4Decompileは、合成データのみで訓練した場合と比較して21.5%高いR2Iスコアを達成した。実際のコードで訓練すれば、実際のコードをより正確に復元できる——当然の帰結だが、その効果の大きさは注目に値する。
Mizuchi——バイト単位で完全一致する逆コンパイル
2026年に登場したMizuchiは、Claude APIを活用した自動マッチング逆コンパイルパイプラインだ。このツールの目標は、復元されたCコードをコンパイルしたとき、元のバイナリとバイト単位で完全に一致する出力を得ることだ。
コンテキスト認識型のリトライメカニズムがコンパイルエラーをLLMにフィードバックし、自動的に修正を繰り返す。結果、60関数中53関数——88%の一貫性——で同一結果を実現した。これは単にソースコードを「それらしく」復元するのではなく、コンパイラの最適化パターンまで含めて元の実装を忠実に再現できることを意味する。
ReCopilotとSK2Decompile——意味的復元の進化
2025年に発表されたReCopilotは、関数名復元と変数型推論において既存ツールとLLMを13%上回る性能を示した。バイナリを逆コンパイルしたとき、最も失われるのは変数名や関数名、型情報といった意味的情報だ。ReCopilotはこの領域に特化し、コードの「読みやすさ」の復元を推進する。
SK2Decompile(2025年10月)は、構造復元(Structure Recovery)とIdentifier命名(Identifier Naming)の2フェーズアプローチを採用し、バイナリ/疑似コードから人間が読める水準のソースコードに変換する。
humanify——難読化JavaScriptのAI支援復元
JavaScript/TypeScriptの難読化解除に特化したhumanifyは、LLM(ChatGPT、llama等)を使い、意味を保持したまま変数名・関数名を復元する。Babel ASTレベルで構造変換を行い、LLMは命名のヒントを提供する——つまり、構文的な変換は決定論的に行い、意味的な復元はAIに委ねる、というハイブリッドアプローチだ。
Claude Codeのようなバンドル・ミニファイされたJavaScriptパッケージに対して、このアプローチは極めて効果的だ。変数名がa、b、cに短縮されていても、LLMはコンテキストからpage、selector、timeoutといった元の名前を高い精度で推論できる。
具体的な復元手順——AIでバイナリをソースコードに戻す実際のワークフロー
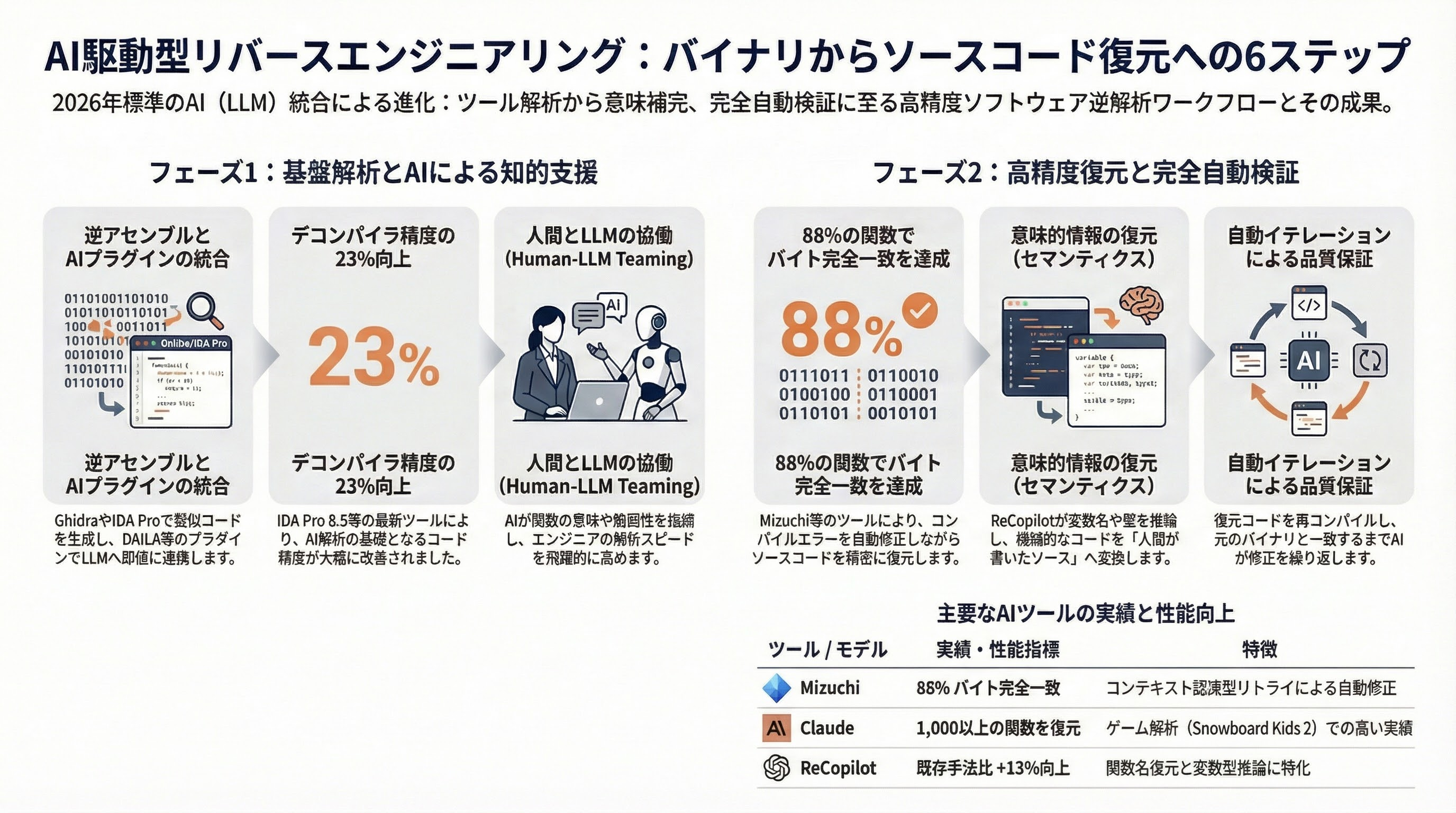
2026年時点で、AIを用いたリバースエンジニアリングの実際のワークフローは、以下の5つのステップで構成される。
ステップ1: 逆アセンブル/逆コンパイル。バイナリをGhidraまたはIDA Proに投入し、擬似コード(デコンパイラ出力)を取得する。Ghidra 11.2(2025年後半リリース)はAI支援分析を強化し、IDA Pro 8.5はデコンパイラ精度を23%改善した。この段階で得られるのは、コンパイラ生成の低レベルな擬似Cコード——変数名は失われ、制御フローは最適化で変形している。
ステップ2: AIアシスタントによる解析。DAILA(Decompiler Artificially Intelligent Language Assistant)は、GPT-4、Claude、ローカルモデルをGhidra/IDA Proに統合するプラグインだ。NDSS 2026(ネットワーク・分散システムセキュリティシンポジウム)の論文「Decompiling the Synergy: An Empirical Study of Human-LLM Teaming in Software Reverse Engineering」は、人間とLLMの協働によるリバースエンジニアリングの有効性を実証した。DAILAはボタン一つでデコンパイラ出力をLLMに送り、関数の意味、変数名の推測、脆弱性の指摘を受け取る。
ステップ3: 関数単位の高精度復元。LLM4DecompileまたはMizuchiに逆アセンブル結果を投入し、Cソースコードを復元する。Mizuchiのコンテキスト認識型リトライは、コンパイルエラーを自動修正し、88%の関数でバイト完全一致を達成する。Claudeの「ワンショット逆コンパイル」はゲーム(Snowboard Kids 2)の解析で1,000以上の関数を高いマッチング率で復元した実績がある。
ステップ4: 意味的情報の復元。変数名、関数名、コメント、型アノテーションの推論はLLMが最も得意とする領域だ。ReCopilotは関数名復元と変数型推論で既存手法を13%上回る。humanifyはミニファイされたJavaScriptの変数名を文脈から復元する。この段階で、コードは「コンパイラ出力」から「人間が書いたように見えるソースコード」に変わる。
ステップ5: 検証とイテレーション。復元されたコードをコンパイルし、元のバイナリと比較する。差分があれば、その情報をLLMにフィードバックして修正を繰り返す。Mizuchiはこのプロセスを完全に自動化した。人間の介入なしに、バイナリからソースコードへ、そしてソースコードからバイト完全一致するバイナリへ——このサイクルが回る。
復元可能なポイントと現在の限界
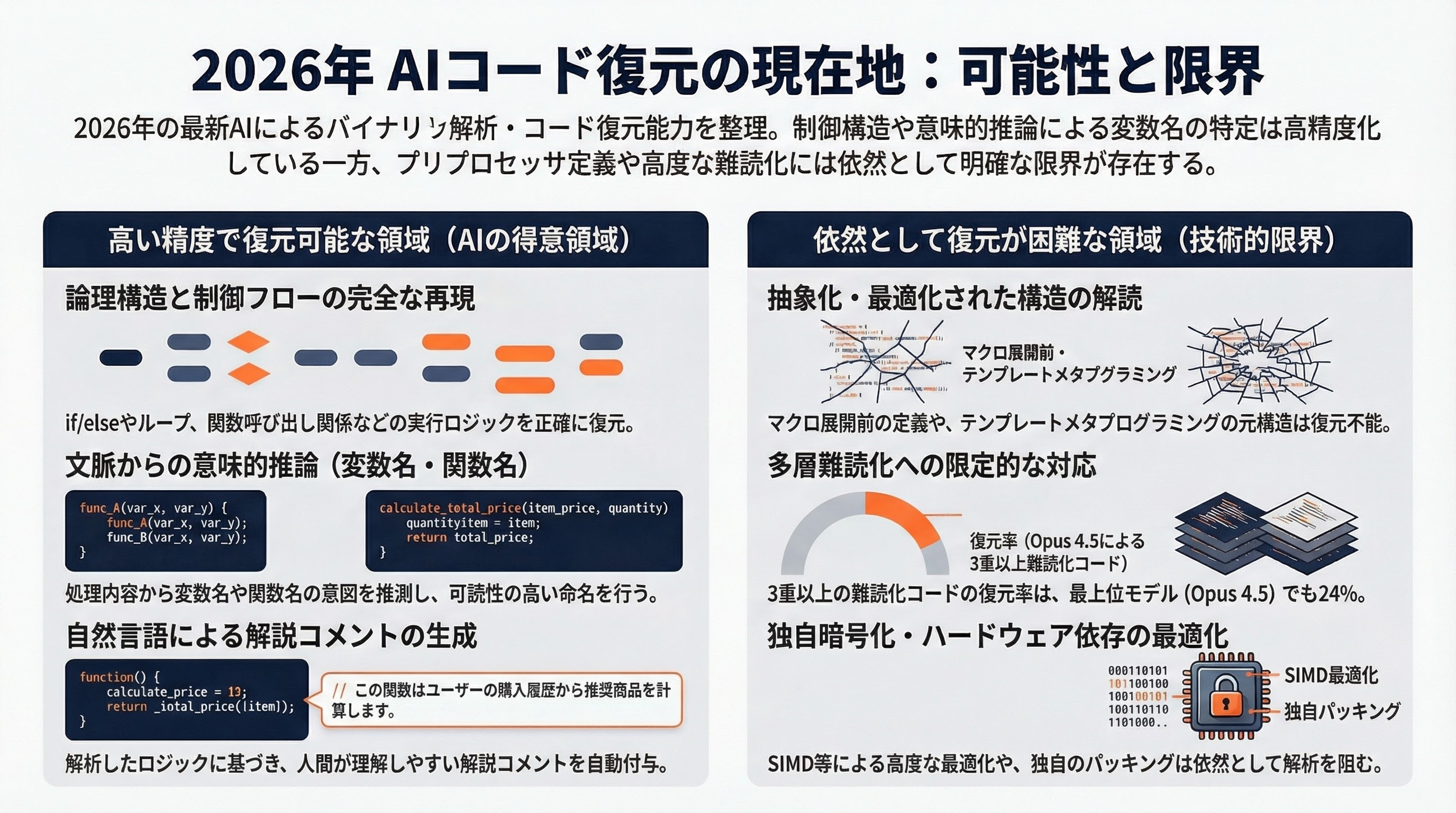
2026年のAIが得意とする復元ポイントと、依然として困難な領域を整理する。
高い精度で復元可能なもの:
- 制御フロー(if/else、for/whileループ、switch文)の構造
- 関数の呼び出し関係とパラメータ
- 数値演算、文字列操作のロジック
- 標準ライブラリの関数呼び出しパターン
- 変数名・関数名の意味的推論(コンテキストから)
- コメントの推測(処理内容から自然言語で生成)
復元が困難なもの:
- マクロ展開前のプリプロセッサ定義
- テンプレートメタプログラミングの元の構造
- 高度に最適化された数値計算(SIMDインストラクション等)
- 3重以上の多層難読化が適用されたコード(ただしClaude Opus 4.5で24%)
- 独自の暗号化やパッキングが施されたバイナリ
難読化 vs AI——10モデルのベンチマーク

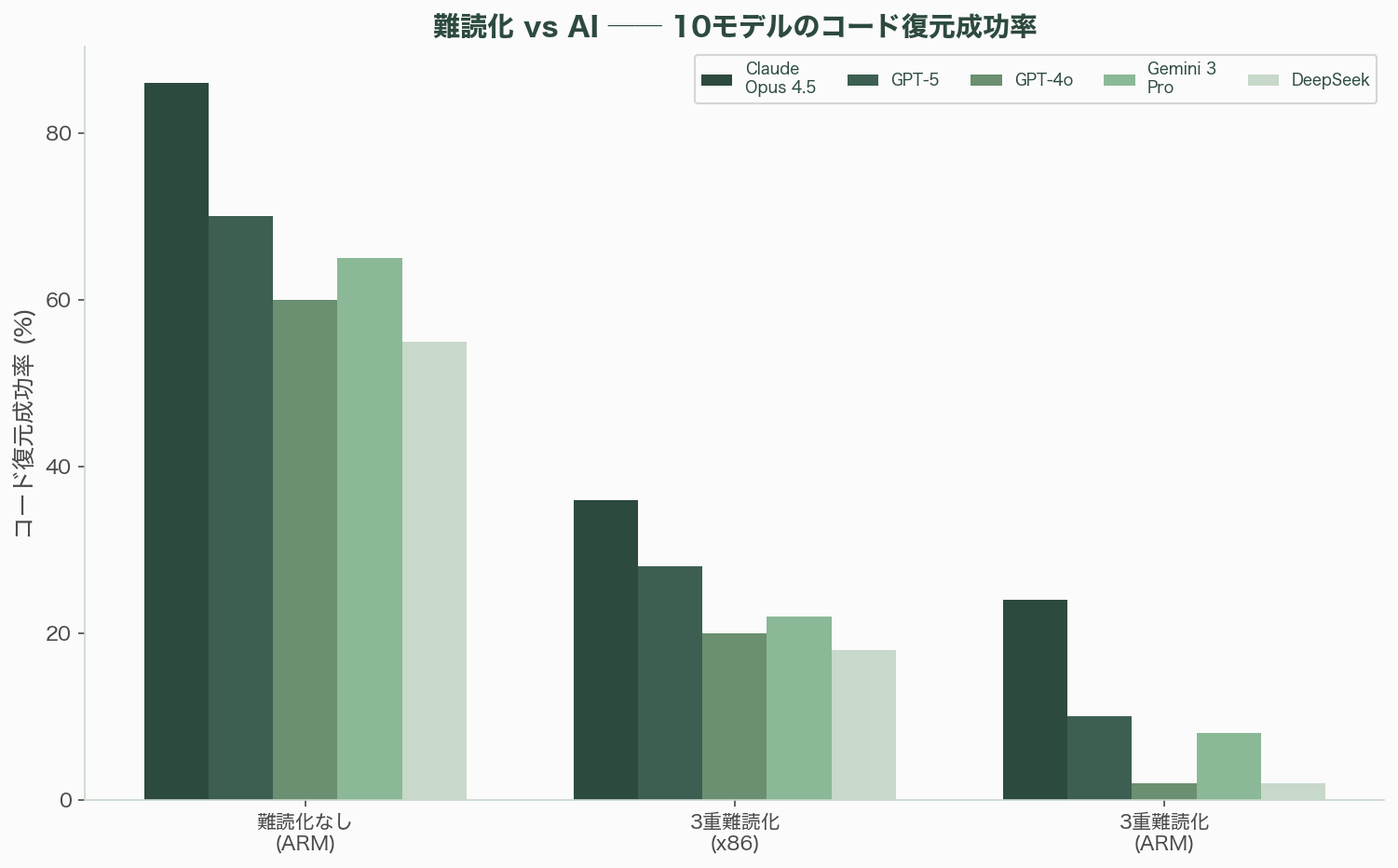
ノルウェーのアプリ保護企業Promonは、2026年Q1の「App Threat Report」で画期的なベンチマークを公開した。Obfuscator-LLVM(OLLVM)で難読化されたバイナリに対し、10のAIモデルを対決させた。対象は、Claude Opus 4.5、Sonnet 4.5、Haiku 4.5、GPT-5、GPT-4o、Gemini 3 Pro、3 Flash、2.5 Pro、DeepSeek Chat、DeepSeek Reasonerだ。
難読化なし(クリーン)のARMアセンブリに対する平均成功率は63.7%。最高でも86%を超えるモデルはなかった。つまり、AIは難読化がなくてもアセンブリの完全な理解には至っていない。
3重難読化(SUB+FLA+BCF)を適用すると、x86バイナリに対して20〜36%、ARMバイナリに対して8.5%の平均成功率に低下した。FLA(制御フロー平坦化)とBCF(偽分岐挿入)の組み合わせは、BCF単独のx86で4.18倍、ARMで5.50倍強いバリアとなった。
注目すべきはClaude Opus 4.5の成績だ。3重難読化ARMバイナリに対して、疑似コードからの復元で50%、生のアセンブリからの復元で24%を達成した。GPT-4oは疑似コード10%、生アセンブリ2%。弱いモデルは1〜2%に留まった。Claude Opus 4.5は2位以下を大幅に引き離している。
Promonの結論は、軍拡競争は終わったのではなく進化しているというものだ。しかし、その方向は一方的だ。2025年のGPT-4oの2%から、Claude Opus 4.5の24%へ——12倍の改善が1年で起きた。この成長曲線が続けば、多層難読化の有効期間は数年単位で短縮し続ける。
VCの視点——「フィーチャーモートは死んだ」
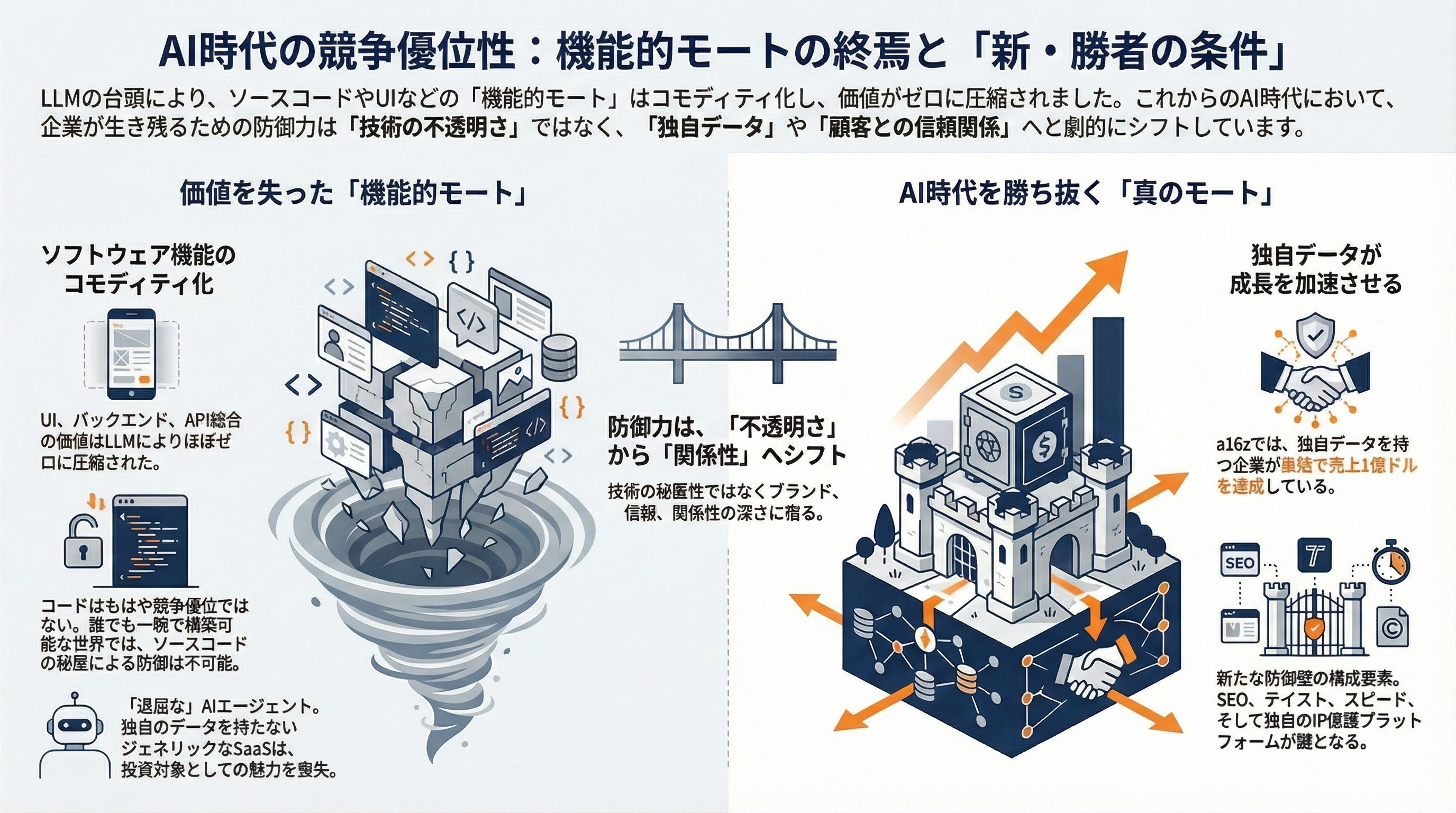
シリコンバレーのVCは、ソースコード秘匿に依存するビジネスモデルの終焉をはっきりと認識している。
TechCrunchが2026年3月に報じた投資家の声は象徴的だ。
「AIエージェントが今できることは全て、『かなり退屈』だ。」
「全ての機能的モート——UI、バックエンドロジック、APIインテグレーション——はほぼゼロに圧縮された。LLMがインターフェースをコモディタイズしたとき、残るのは純粋なデータの価値だ。データが独自のものでなければ、何も残らない。」
a16zのポートフォリオでは、独自データで構築されたモートを持つ企業がゼロから1億ドルの売上に最速で到達している。a16zは、AI時代のIP保護プラットフォームStory Protocol(PIP Labs)のシリーズBで8,000万ドルをリードし、Marc Andreessenは「オープンソースAIは自由に普及し、競争すべきだ」と述べた。
別の投資家は核心を突く。
「誰でも一晩で何でも構築できるとき、AIが複製できない唯一のモートは、SEO、ブランド、テイスト、スピード、データ、そして信頼だ。防御力は今や、技術的な不透明さではなく、関係性の深さにある。」
独自データモートを持たないジェネリックなバーティカルSaaSは、もはやVCに人気がない。コードが復元可能な世界では、コードそのものは競争優位ではない。
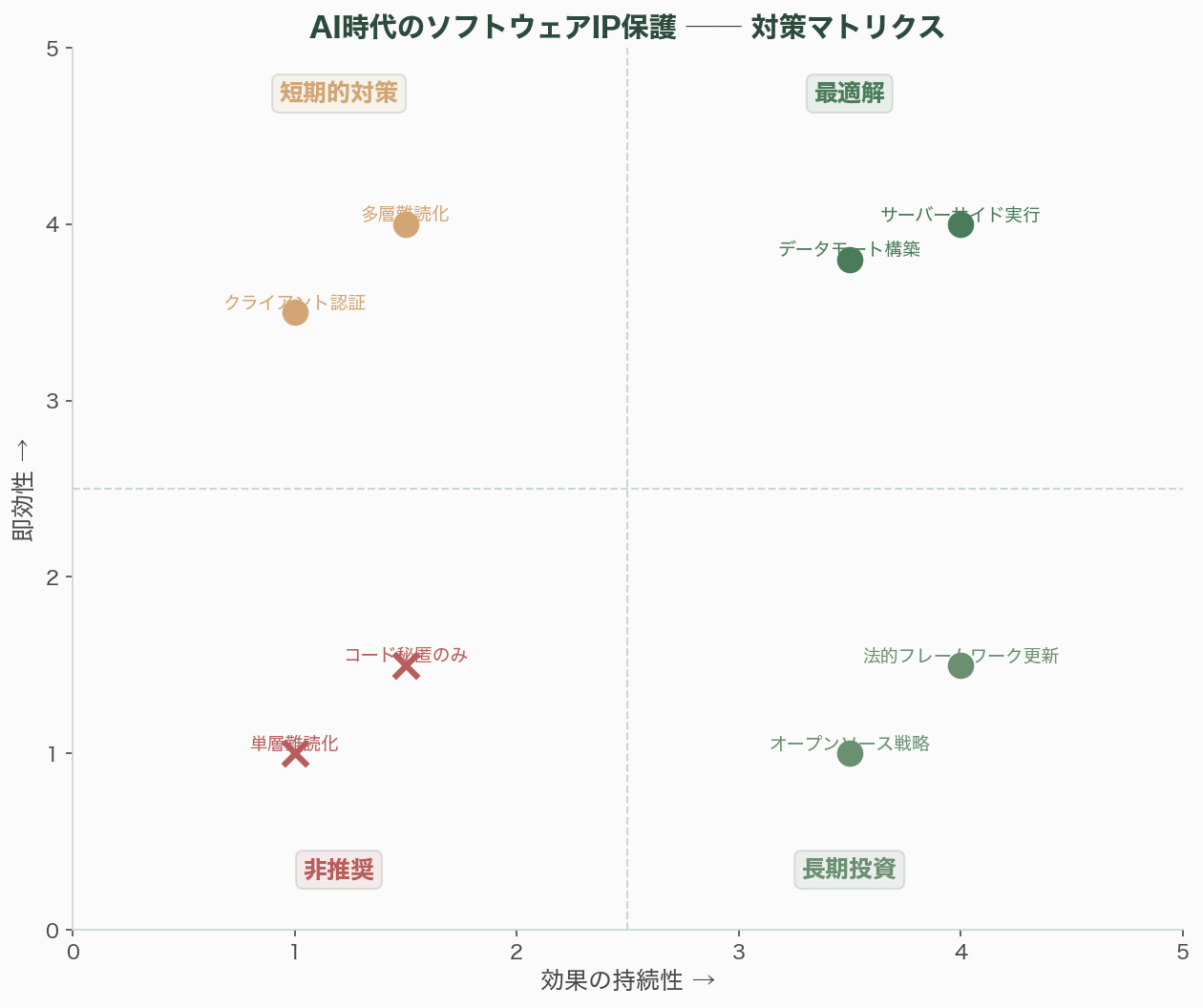
企業が取るべき対策——2026年のソフトウェアIP保護戦略
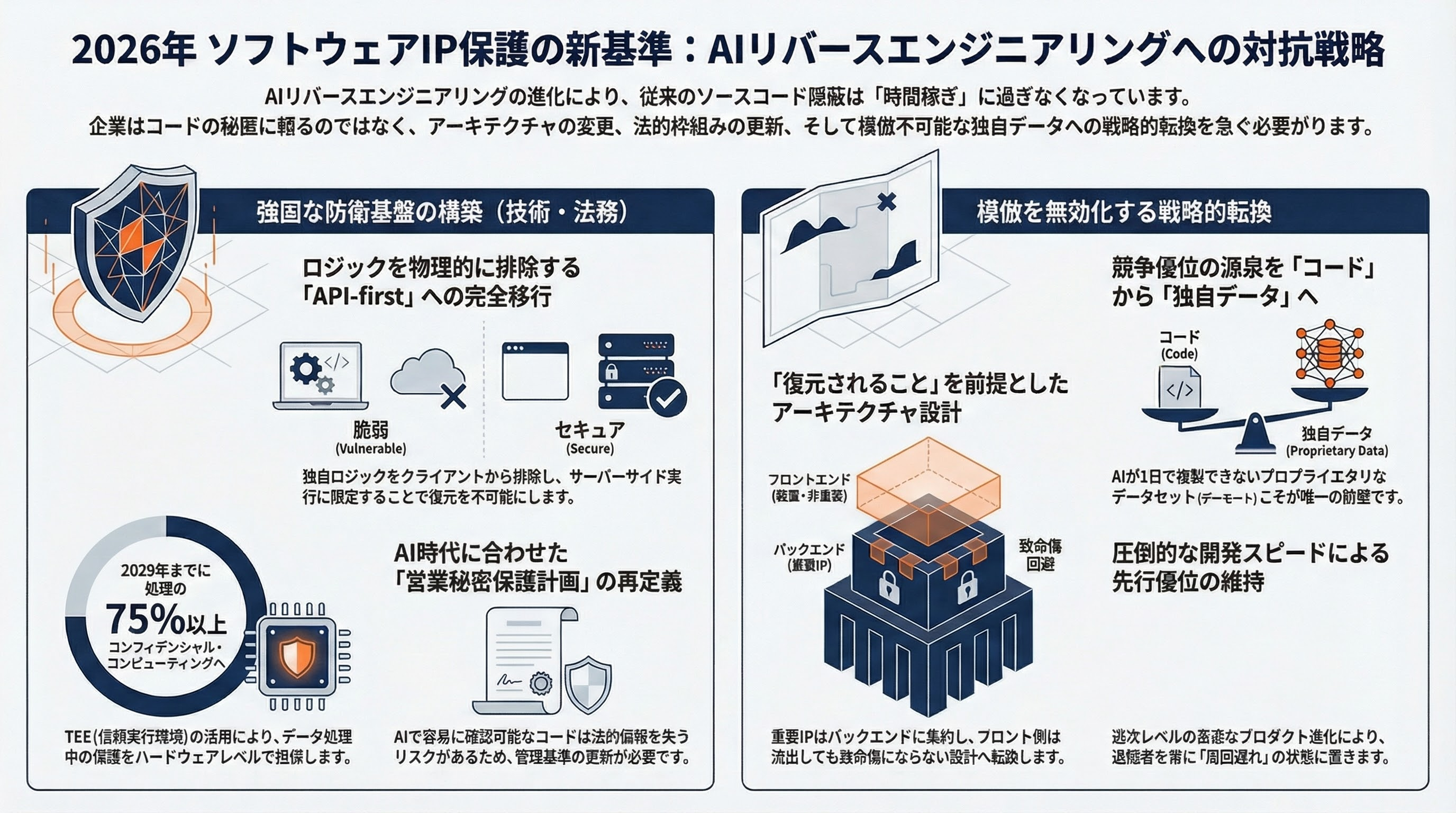
AIリバースエンジニアリングの進化に対して、企業はどのような対策を取るべきか。技術・法務・戦略の3軸で整理する。
技術的対策
1. サーバーサイド実行への全面移行。最も確実な対策は、独自ロジックをクライアントデバイスから完全に排除することだ。API-firstアーキテクチャにより、クライアントは薄いフロントエンドのみとなる。リバースエンジニアリングの対象が物理的に存在しなければ、復元のしようがない。皮肉にも、Claude Code自身がこのアーキテクチャだ——流出したのはフロントのCLIツール部分であり、AIモデルそのものはAnthropicのサーバー上にある。
2. コンフィデンシャル・コンピューティング。Gartnerは、2029年までに信頼されていないインフラ上での処理の75%以上がコンフィデンシャル・コンピューティングを使用すると予測している。AMD、Intelのハードウェアベースの信頼実行環境(TEE)は、データを保存中・転送中だけでなく、処理中も保護する。HPEは2026年3月にMorpheus SoftwareへのConfidential Computing統合を発表した。
3. 多層難読化の維持(時間稼ぎとして)。Promonのレポートが示すように、FLA+BCFの組み合わせは依然としてAIに対する有効なバリアだ。3重難読化ARMバイナリに対する平均成功率は8.5%。ただし、これは根本的な解決策ではなく時間稼ぎであり、毎年その有効期間は短縮する。
4. ネイティブクライアント認証とアテステーション。正規クライアントの認証をハードウェアレベルで行う。流出したClaude Code自身も、BunのZig HTTPスタックを用いたDRM的な認証システムを実装していた。ただし、これもソースコードが流出すれば回避される——認証そのものの実装も復元対象となるからだ。
法的対策
5. 営業秘密法の更新。米国のDefend Trade Secrets Act(DTSA)と各州のUniform Trade Secrets Act(UTSA)が主要な法的保護手段だが、AIによって「容易に確認可能(readily ascertainable)」の基準が根本的に変わりつつある。Greenberg Traurig法律事務所は次のように警告する。
「2023年以前に営業秘密保護計画を策定した企業は、AIを全く考慮していない可能性がある。」
かつて「容易に確認可能ではない」とされたソフトウェアの内部ロジックが、AIによって容易に確認可能になれば、営業秘密としての法的保護が失われるリスクがある。
6. 判例の活用。Motorola v. Hytera判決(2025年)は、「再設計」の抗弁を却下し7,000万ドルの追加ロイヤリティを命じた。AIで修正された不正取得コードに対しても、この先例が適用される可能性がある。裁判所はプロンプトインジェクションと合法的なリバースエンジニアリングを「不正手段」として区別し始めている。
7. カリフォルニア州AI透明性法(2026年1月施行)への対応。トレーニングデータの要約の開示義務。自社のコードがAIのトレーニングデータに含まれているかを監視する体制が必要となる。
戦略的対策
8. データモートの構築。VCが口を揃えて指摘する通り、コードが復元可能な世界では、独自データこそが唯一の持続可能な競争優位だ。プロプライエタリなデータセット、顧客との深い関係、ネットワーク効果——これらはAIが1日で複製できない。
9. スピードとイテレーション速度の優位性。コードが復元されても、週次でプロダクトを進化させる速度があれば、追随者は常に周回遅れとなる。Claude Code自身がその実証だ——ソースコードが流出しても、ARR 25億ドルの成長は止まらなかった。なぜなら価値はコードではなくバックエンドのAIモデルにあるからだ。
10. 「復元されることを前提とした設計」への転換。逆説的だが、最も堅牢な戦略は、ソースコードの流出を前提としてアーキテクチャを設計することだ。クライアントに配布するコードには独自の知的財産を含めず、差別化要素は全てサーバーサイドに置く。Red HatやHashiCorpのBSLモデルのように、コードをオープンにしながらサポート・ホスティング・エンタープライズ機能で収益化する道もある。
ポジティブな見通しとネガティブな見通し
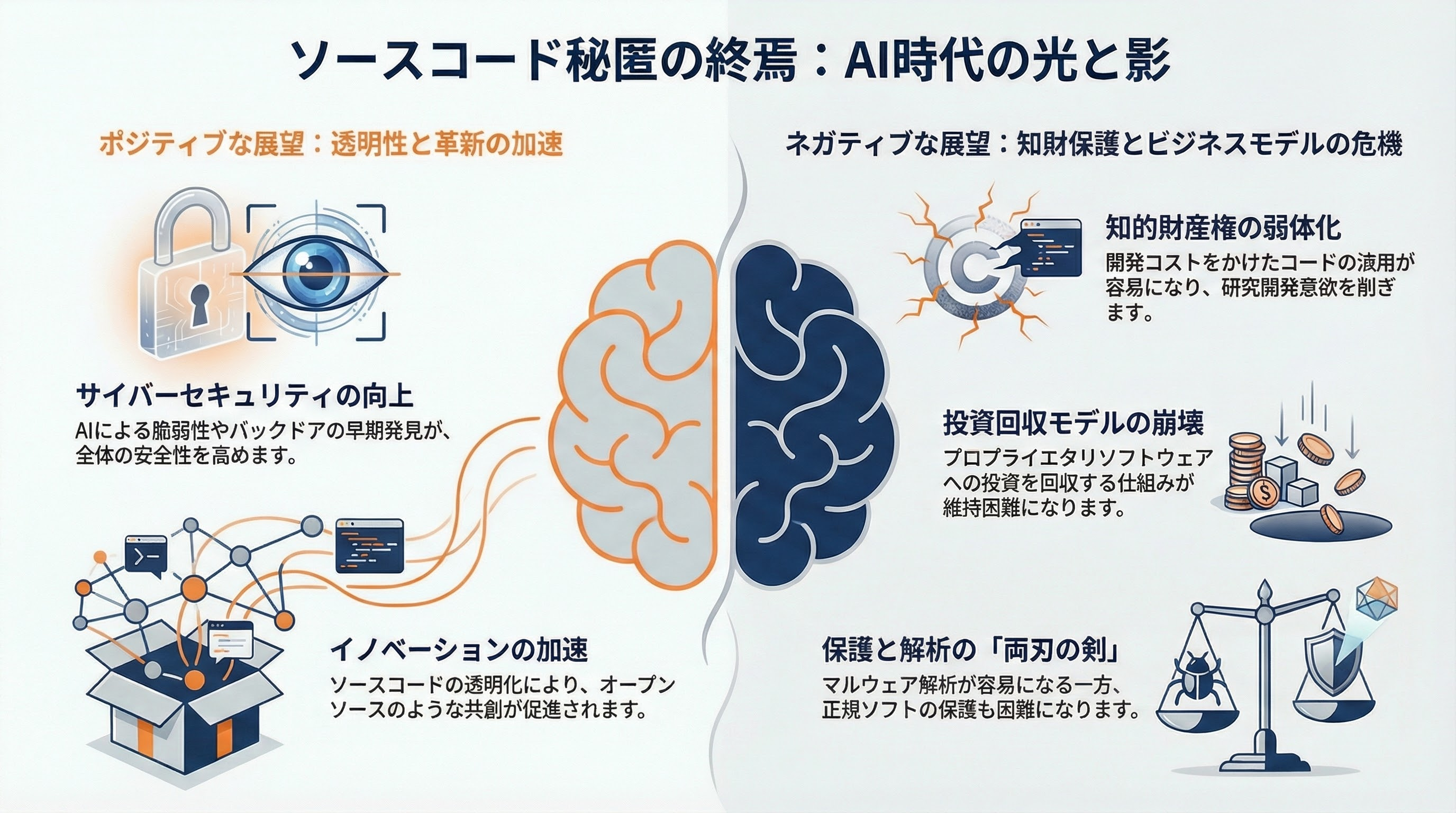
ポジティブな見方として、ソースコード秘匿の無意味化は、ソフトウェア産業全体の透明性とセキュリティを向上させる可能性がある。隠されたバックドアや脆弱性がAIで発見されやすくなることは、サイバーセキュリティにとっては正のフィードバックだ。オープンソース運動が示したように、透明性はイノベーションを加速する。
ネガティブな見方として、知的財産保護の弱体化は、特にスタートアップや中小企業のR&Dインセンティブを損なう可能性がある。巨額の開発費をかけたソフトウェアが容易に復元されるなら、プロプライエタリソフトウェアへの投資回収モデルが成り立たなくなる。また、マルウェア解析が容易になる反面、正規ソフトウェアの保護も困難になるという両刃の剣だ。
Claude Mythos(ミソス)——「神話」が示す未来

Claude Codeのソースコード流出のわずか5日前、Anthropicの次期モデルClaude Mythos(ミソス)の存在が情報漏洩で明らかになった。LayerX SecurityのRoy Pazとケンブリッジ大学のAlexandre Pauwelsが、CMSの設定ミスで公開検索可能となったデータベースから約3,000のファイルを発見した。
MythosはOpusの上位に位置する全く新しいクラスであり、バージョンアップではない。「神話」の名を冠するこのモデルについて、内部文書は次のように記述していた。
「現在、他のあらゆるAIモデルをサイバー能力において大幅に凌駕している。」
Mythosは、Linuxカーネルのヒープバッファオーバーフロー脆弱性を複数発見し、内部文書はこう記録していた。
「言語モデルが、自律的に、洗練されたスキャフォールディングなしで、非常に重要なソフトウェアのゼロデイ脆弱性を発見し悪用できる。」
Anthropicは政府高官に対し、Mythosが「2026年に大規模サイバー攻撃の可能性を大幅に高める」と非公式に警告した。
ここで立ち止まって考えてほしい。Linuxカーネルのゼロデイ脆弱性を自律的に発見するモデルにとって、難読化されたJavaScriptバンドルの解析は——あるいはO3最適化されたバイナリの逆コンパイルは——どの程度の「難易度」なのか。
Promonのベンチマークで、Claude Opus 4.5が3重難読化ARMバイナリに対して24%を達成した。Mythosはその上位クラスだ。LLM4Decompileの9Bモデルが64.94%の再実行可能率を達成しているなら、Mythos級のモデルが同タスクに挑んだとき、何パーセントに到達するのか。80%か、90%か、あるいはそれ以上か。
結論——そもそも我々のソースは隠されているのか
Claude Codeの51万2,000行のTypeScriptソースコードは、.npmignoreの設定漏れで流出した。しかし、流出しなかったとしても、問いの答えは同じだ。
LLM4Decompileは64.94%の再実行可能率に到達した。Mizuchiは88%の関数でバイト完全一致する逆コンパイルを実現した。Claude Opus 4.5は3重難読化ARMバイナリに対して24%——GPT-4oの12倍——の復元成功率を示した。そしてClaude Mythosが来る。Opusを超える、「神話」の名を冠する全く新しいクラスが。
ローカルに配布するモジュールのソースコードは、もはや隠されていない。
我々がコンパイルし、難読化し、ミニファイし、パッキングしたコードは、AIの前では薄い霧のようなものだ。その霧は年々薄くなり、やがて消える。
企業が取るべき行動は明確だ。独自ロジックはサーバーサイドに移し、クライアントに配布するものは復元されることを前提として設計する。競争優位は、コードの秘匿ではなく、データの独自性、顧客関係の深さ、イテレーションの速度に置く。
Anthropicが送った「メッセージ」が意図的だったかどうかは、もはや重要ではない。重要なのは、我々が自分に問いかけることだ——そもそも我々のソースは、隠されているのか、と。
業界への影響
第一に、ソフトウェアIP保護の経済学が不可逆的に変化しつつある。難読化やコード秘匿にコストをかけるよりも、サーバーサイド実行やデータモートの構築にリソースを投入する方が合理的な時代が到来した。Promonのレポートが示すように、多層難読化は依然として時間稼ぎとして有効だが、AIの進化速度を考えれば、その有効期間は年単位で短縮し続ける。
第二に、Anthropicの財務的成功がこの文脈で持つ意味は大きい。Claude Codeだけで25億ドルのARRを9ヶ月で達成し、ソースコードが流出しても成長は止まらなかった。これは「ソースコードを隠せない世界」での生存戦略の実証だ。価値はフロントのコードではなく、バックエンドのAIモデルとデータにある。
第三に、VCの投資判断が明確にシフトしている。独自データモートを持たないジェネリックなSaaSは投資対象外となりつつあり、a16zのStory Protocol(IP保護プラットフォーム)への8,000万ドル投資が示すように、「AI時代のIP保護」そのものが新たな投資テーマとなっている。
第四に、法的フレームワークの更新が急務だ。AIによって「容易に確認可能」の基準が変わり、営業秘密の法的保護が弱体化する恐れがある。Motorola v. Hytera判決は先例として重要だが、AI時代に特化した法整備はまだ始まったばかりだ。
第五に、Claude Mythosの存在は、この変化が加速することを示唆する。ゼロデイ脆弱性を自律発見するモデルが一般に普及すれば、あらゆるバイナリが事実上のオープンソースとなる世界が現実になる。その世界で生き残るのは、コードではなくデータとリレーションシップで差別化できる企業だ。
参考情報: Axios「Anthropic leaked its own Claude source code」(2026/3/31), VentureBeat「Claude Code's source code appears to have leaked」(2026/3/31), Fortune「Anthropic leaks source code in second major security breach」(2026/3/31), The Hacker News「Claude Code Source Leaked via npm」(2026/4), Bleeping Computer「Claude Code source accidentally leaked in npm package」(2026/4), Layer5「512,000 Lines and the Fastest-Growing Repo in GitHub History」(2026/4), Geoffrey Huntley「Claude Code deobfuscation tradecraft」(2025/3), Fortune「Anthropic Mythos revealed in data leak」(2026/3/26), Euronews「Mythos poses unprecedented cybersecurity risks」(2026/3/30), Futurism「Anthropic leaked model with unprecedented risks」(2026/3), CoinDesk「Anthropic massive Claude Mythos leak」(2026/3/27), GitHub: LLM4Decompile (albertan017/LLM4Decompile), BrightCoding「Mizuchi LLM Pipeline for Perfect Decompilation」(2026/3), arxiv: ReCopilot (2505.16366v1), RevEng.AI「Training an LLM to Decompile Assembly Code」, arxiv: LLM4Decompile paper (2403.05286v2), GitHub: humanify (jehna/humanify), GitHub: DAILA (mahaloz/DAILA), NDSS 2026「Decompiling the Synergy: An Empirical Study of Human-LLM Teaming in Software Reverse Engineering」, Secybers「Ghidra vs IDA Pro 2026」, Promon「App Threat Report 2026 Q1: The State of Code Obfuscation Against AI」, Promon「AI deobfuscators won't help hackers yet」, Google Cloud Blog「Scaling Up Malware Analysis with Gemini 1.5 Pro」, Google Cloud Blog「Gemini for Malware Analysis」, TechCrunch「Investors spill what they aren't looking for in AI SaaS」(2026/3), CNBC「Story raises funds from a16z to stop IP theft by AI」(2024/8), KoreaTechDesk「a16z $80M for IP Protection in Age of AI」, Greenberg Traurig「Reverse Engineering in the Age of AI: Are Your Trade Secrets Still Safe?」(2025/12), Intel Confidential Computing Whitepaper (2025), HPE Security Advancements (2026/3), JDSupra「2025 AI and Trade Secret Law Retrospective」, Anthropic「acquires Bun as Claude Code reaches $1B milestone」(2025/12), Yahoo Finance「Anthropic ARR surges to $19 billion」(2026), TechCrunch「Anthropic raises $30B Series G at $380B valuation」(2026/2)