創薬の構造的課題——なぜ新薬はこれほど高コストで遅いのか
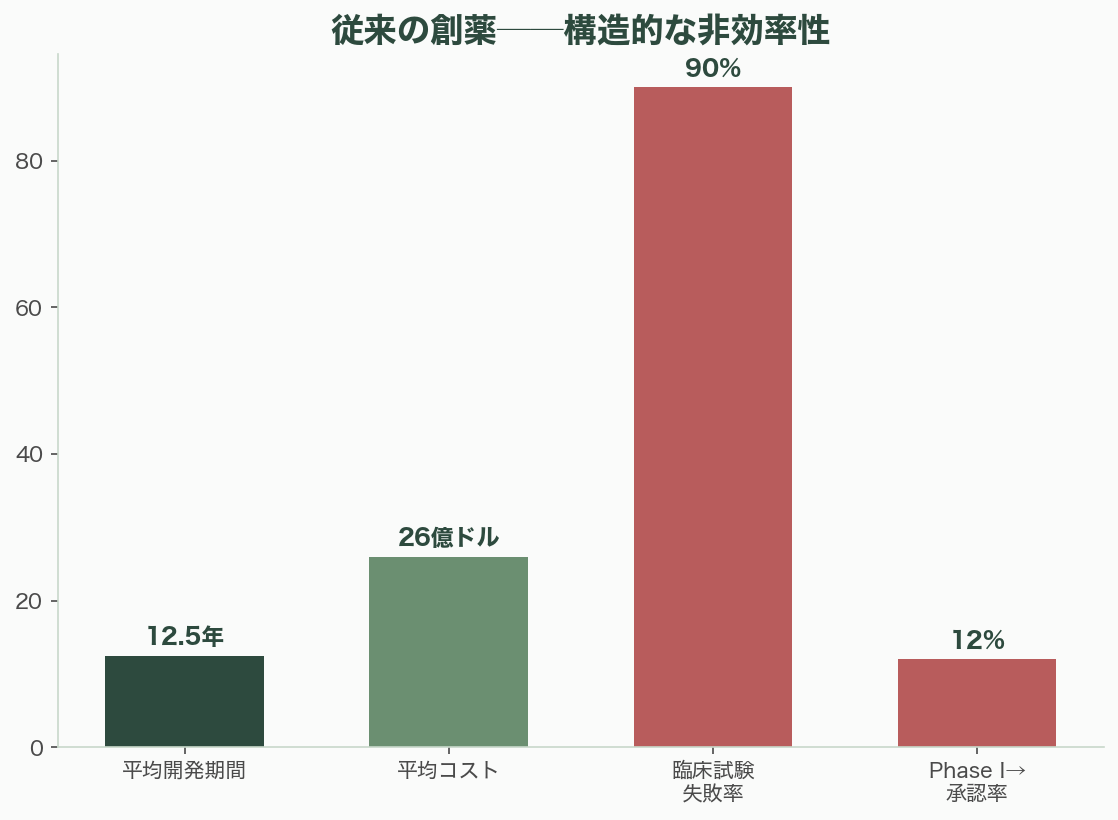
新薬開発の非効率性は、製薬産業の最も根深い課題だ。
Tufts大学医薬品開発研究センター(CSDD)の推計によれば、1つの承認薬を市場に送り出すまでの平均コストは26億ドル(約3,900億円)、平均所要期間は10〜15年だ。BIO/QLS Advisors/Informaの2021年分析では、フェーズIに入った薬剤が最終的にFDA承認を得る確率はわずか12%。臨床試験全体の失敗率は約90%に達する。がん領域に至っては、フェーズIから承認に至る確率はわずか5%だ。
この非効率性の根源は「イルームの法則(Eroom's Law)」——ムーアの法則の逆読み——で表現される。インフレ調整後の創薬生産性は1950年以降、約9年ごとに半減してきた。規制の厳格化、「低い果実」の枯渇(容易なターゲットは既に薬がある)、そして決定的に、質の高い多様な生物学的データの不足が原因だ。
グローバルの製薬R&D支出は2024年に2,650億ドル(約39兆7,500億円)を超えた(IQVIA推計)。しかしその大部分は失敗した試験のコストとして消えていく。このパラダイムを根本から変えようとしているのが、バイオバンク、合成データ、そしてAI/機械学習の三位一体だ。
バイオバンク——遺伝子型と表現型を結ぶ「地上の真実」
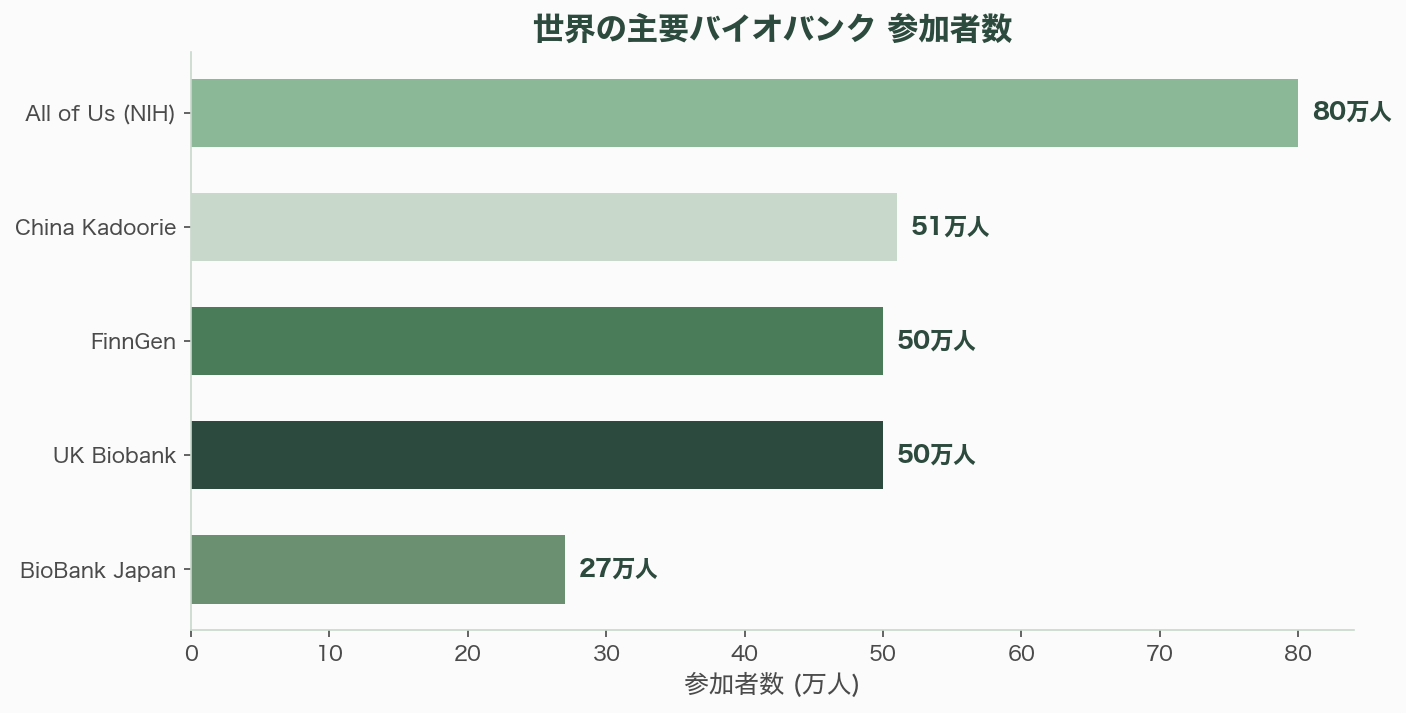
バイオバンクは、大規模な集団からゲノムデータ、血液・尿などの生体試料、健康記録を長期にわたって収集・保管する研究基盤だ。創薬においては、遺伝子と疾患の因果関係を集団レベルで検証する「地上の真実」を提供する。
UK Biobankは世界で最も有名なバイオバンクだ。2006〜2010年に50万人を募集し、全参加者の全ゲノムシーケンス(WGS)が2023年に完了した。Olink社との協力で約3,000のタンパク質を全50万人で測定したプロテオミクスデータも公開されている。3万人以上の登録研究者、1万件以上の承認プロジェクト、8,000件以上の査読付き論文を生み出した。予算は累計約2億6,000万ポンド(約500億円)。オープンアクセスモデルにより、世界中の研究者がデータにアクセスできる。
All of Us(NIH、米国立衛生研究所)は、米国の多様性を反映する100万人以上の参加者を目標とする。2025年時点で80万人以上が登録し、50万人以上が生体試料を提供。歴史的に研究から排除されてきた人種・民族的マイノリティが参加者の50%以上を占める点が画期的だ。予算は第一フェーズで14億ドル(約2,100億円)が計上されている。
BioBank Japan(BBJ)は約27万人の参加者と47の対象疾患を擁し、理化学研究所と東京大学が運営する。非ヨーロッパ系では世界最大級のバイオバンクの一つであり、東アジア集団の遺伝的構造の理解に不可欠だ。200以上の疾患関連遺伝子座の同定に貢献してきた。
FinnGen(フィンランド)は50万人以上の参加者を持ち、フィンランドの始祖効果を活用した稀少変異の発見に特に価値がある。13のバイオバンクと11社の製薬企業(AbbVie、AstraZeneca、Pfizer等)の官民パートナーシップだ。
deCODE Genetics(アイスランド)は19万人以上のアイスランド人(人口の半数以上)の遺伝子型を保有し、1,000年以上の系譜データと組み合わせる。2012年にAmgenが4億1,500万ドル(約622億5,000万円)で買収し、多数の創薬ターゲット同定に貢献している。
バイオバンクのデータが創薬にもたらす最大の価値は、遺伝的根拠のある創薬ターゲットは臨床試験の成功率が2倍であるという知見だ(Nelson et al., Nature Genetics, 2015)。King et al.(2019)の更新では、遺伝的支持のある薬剤はフェーズIから承認に至る確率が2.6倍高いことが示されている。
合成データ——プライバシーと希少性の壁を超える
合成データは、実際の患者データの統計的特性を模倣しながら、個人を特定できない人工データを生成する技術だ。HIPAA(米国)やGDPR(EU)のプライバシー規制を設計段階でクリアする。
創薬における合成データの価値は3つある。第一に、データ希少性の解消。希少疾患は世界で7,000種以上が知られるが、多くは患者数が数百人規模であり、従来の臨床試験設計が不可能だ。合成データは、この少数の実データから統計的に妥当な数千人規模のコホートを生成する。第二に、プライバシー保護付きデータ共有。複数の医療機関が実データを共有せずに、合成データの形で共同研究を行える。第三に、臨床試験シミュレーション(in silico試験)。Unlearn.AIは合成対照群(digital twin)を生成するFDA承認済みアプローチを持ち、対照群のサイズを20〜30%削減でき、試験あたり1,000万〜5,000万ドル(約15億〜75億円)のコスト削減が可能だ。
主要企業として、Syntegra(サンフランシスコ、合成EHRデータ、シリーズAで約1,700万ドル調達)、MDClone(イスラエル/米国、「ADAMS」プラットフォーム、Mayo Clinic等が採用、累計約6,300万ドル調達)、Gretel.ai(サンディエゴ、差分プライバシー保証、シリーズBで約6,800万ドル調達)、Mostly AI(ウィーン、GDPR特化、約3,100万ドル調達)、Datavant(サンフランシスコ、7万以上の病院を接続するデータネットワーク、1億1,000万ドル超調達)がある。
合成データのヘルスケア市場は2025年に約12〜15億ドル(約1,800億〜2,250億円)、2030年には40〜55億ドル(約6,000億〜8,250億円)に拡大する見通しだ(CAGR 25〜28%)。Gartnerは2030年までにAIモデルの訓練において合成データが実データを上回ると予測している。
AI創薬の主要企業——テクノロジーが切り開く新時代
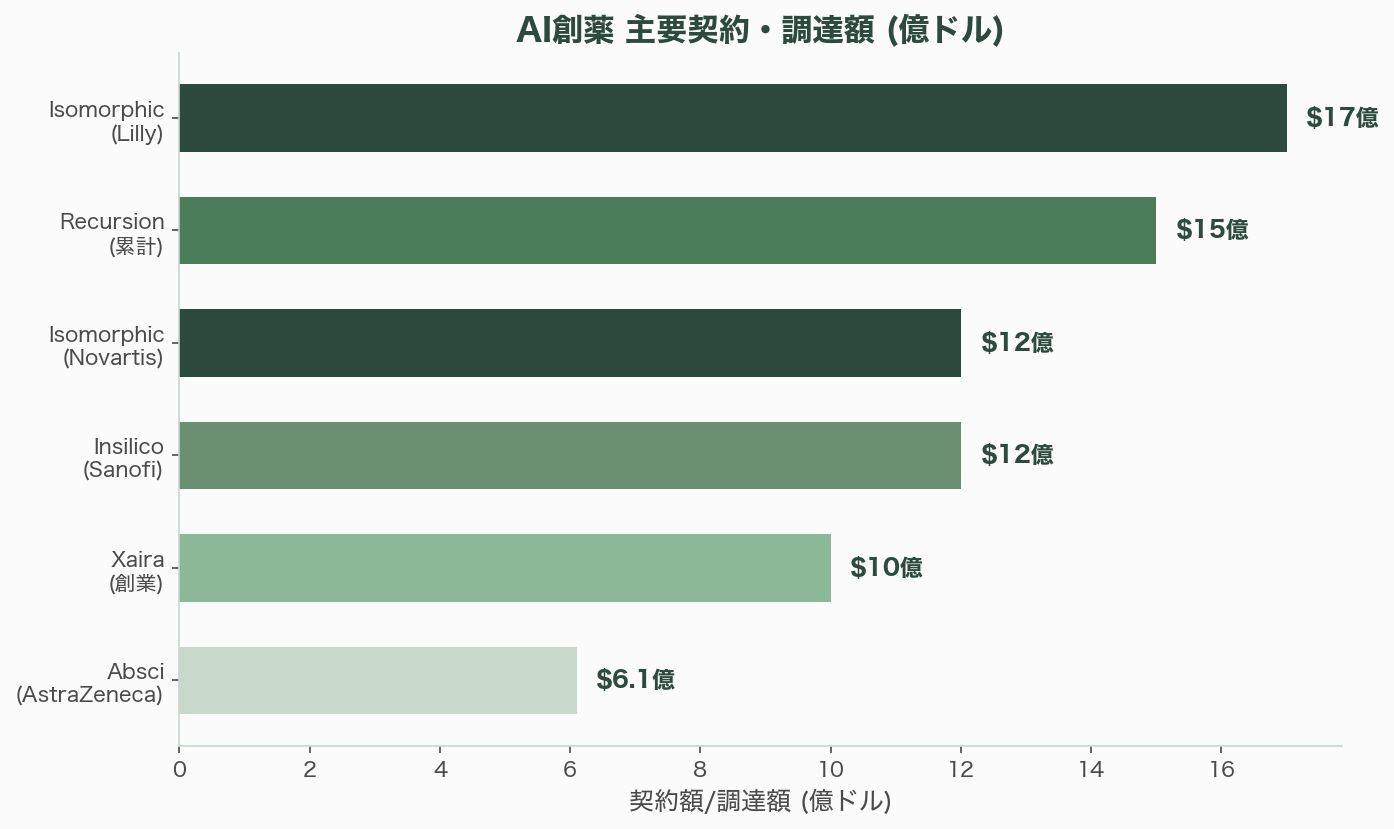
AI創薬分野では、数十億ドル規模の企業が林立し、製薬バリューチェーンの全段階を変革している。
Recursion Pharmaceuticals(ソルトレイクシティ、NASDAQ: RXRX)は累計15億ドル超を調達し、2024年8月にExscientiaとの合併(約6億8,800万ドル)を発表して世界最大級のAI創薬企業となった。「世界最大の独自生物学・化学データセット」——数兆のデータポイント——を保有し、NVIDIAとの複数年パートナーシップ(NVIDIAは5,000万ドルを出資)を結んでいる。8以上のプログラムが臨床段階にある。
Insilico Medicine(香港)はAI創薬の象徴的存在だ。INS018_055(レントセルチブ)は、ターゲットもAI(PandaOmics)が発見し、分子もAI(Chemistry42)が設計した史上初の完全AI発見・AI設計の薬剤としてフェーズII臨床試験に到達した。特発性肺線維症(IPF)を対象とし、フェーズIIaで許容可能な安全性と初期有効性シグナルが報告されている。Sanofiとは最大12億ドル(約1,800億円)の契約を締結した。
Isomorphic Labs(ロンドン、Alphabet/DeepMind)はDemis Hassabis CEOが率い、AlphaFoldの技術を創薬に応用する。2024年1月にEli Lillyと最大17億ドル(約2,550億円)、Novartisと最大12億ドル(約1,800億円)の契約を締結した。AlphaFold 3(2024年5月発表)はタンパク質-リガンド、タンパク質-DNA、タンパク質-RNA複合体の構造を予測でき、創薬に直結する能力を持つ。
Xaira Therapeutics(サンフランシスコ/シアトル)は2024年に10億ドル超の創業資金で設立された。ARCH Venture Partners、Foresite Capital、Sequoia Capital、Lightspeed Venture Partnersが出資。David Baker研究室(ワシントン大学タンパク質設計研究所)からIPをライセンスし、生物学のファウンデーションモデル構築を目指す。バイオテックスタートアップ史上最大の創業ラウンドの一つだ。
Generate Biomedicines(サマービル、MA)はModernaの生みの親であるFlagship Pioneeringが2020年に設立。5億7,300万ドル超を調達し、生成AIでゼロからタンパク質医薬品を設計する。Nature誌に掲載された拡散モデル「Chroma」は指定された特性を持つタンパク質を生成する。
Absci(バンクーバー、WA、NASDAQ: ABSI)は生成AIによる抗体設計に特化する。Nature Biotechnology(2023年)で、出発抗体なしにゼロショットでターゲットに結合する抗体を設計する初の実証を発表。AstraZenecaと最大6億1,000万ドル(約915億円)の契約を締結した。
日本では、武田薬品がRecursion、Schrödinger、Exscientia(合併前)とパートナーシップを結び、データ/デジタル変革に5億ドル超を投資。第一三共はPreferred Networks(PFN)と協力しADC(抗体薬物複合体)の最適化にAIを活用。住友ファーマはExscientiaと提携し、DSP-1181(OCD治療薬)を開発——AI設計分子としてフェーズI臨床試験に入った最初期の事例の一つだ。
要素技術——AlphaFoldから生物学ファウンデーションモデルまで
AI創薬を支える要素技術の進化は目覚ましい。
AlphaFold 2(2020年)はタンパク質構造予測という50年来の大問題を解決し、EMBL-EBIとの協力で2億以上のタンパク質の構造を予測・公開した。AlphaFold 3(2024年5月)は拡散アーキテクチャを採用し、タンパク質-リガンド、タンパク質-DNA/RNA複合体の構造を予測する。タンパク質-リガンド相互作用の精度は従来手法より50%以上向上した。Hassabis、Jumper、Bakerの2024年ノーベル化学賞受賞は、この分野の到達点を象徴する。
拡散モデルによる分子生成はAI創薬の最前線だ。RFdiffusion(David Baker研究室、Nature 2023年)は指定した特性を持つ新規タンパク質構造を生成する。DiffDock(MIT、2023年)は分子ドッキングに拡散モデルを適用し、従来のドッキングソフトウェアを上回った。Chroma(Generate Biomedicines)はタンパク質構造の生成モデルだ。
生物学のための大規模言語モデルが台頭している。ESM-2/ESMFold(Meta AI)は2億5,000万以上のタンパク質配列で訓練され、配列から構造を直接予測する。ProGen/ProGen2(Salesforce Research)は機能的なタンパク質配列を生成し、生成されたタンパク質が活性酵素として機能することを実証した。Evo(Arc Institute、Patrick Collison共同創設、2024年)は270万ゲノムで訓練されたゲノムファウンデーションモデルで、遺伝子・ゲノムスケールのDNA配列を生成できる。
デジタルツインによる臨床試験も進展している。Unlearn.AIは過去の試験データから患者のデジタルツインを生成し、FDAが承認した共変量調整手法で合成対照群を構築する。必要な対照群サイズを20〜30%削減し、時間とコストを節約する。
シリコンバレーVCの視点——「生物学は情報科学になった」
シリコンバレーのVCは、AI創薬を「世代に一度の投資機会」と位置づけている。
a16z Bio(Andreessen Horowitz)はVijay Pande(Folding@home発明者、元Stanford教授)が率い、2019〜2023年に15億ドル超のBioファンドを組成した。「ソフトウェアがバイオを食う」というテーゼの下、Insitro、Freenome等に投資。Pandeは「エンジニアリング・バイオロジー」について広範に発信している。
Flagship Pioneering(ケンブリッジ、MA)はModerna(時価総額ピーク1,500億ドル超)を生み出したベンチャー創造ファームだ。CEOのNoubar Afeyanが率い、100億ドル超の累計資本を運用。Generate Biomedicinesが旗艦のAI-バイオロジー投資だ。
ARCH Venture PartnersはRobert NelsenとKristina Burowが率い、Illumina(早期投資家)、Xaira Therapeutics(10億ドル超のラウンドをリード)に投資。「生物学は情報科学になった。AIとバイオの収束は世代に一度の最大の投資機会だ」と表明している。
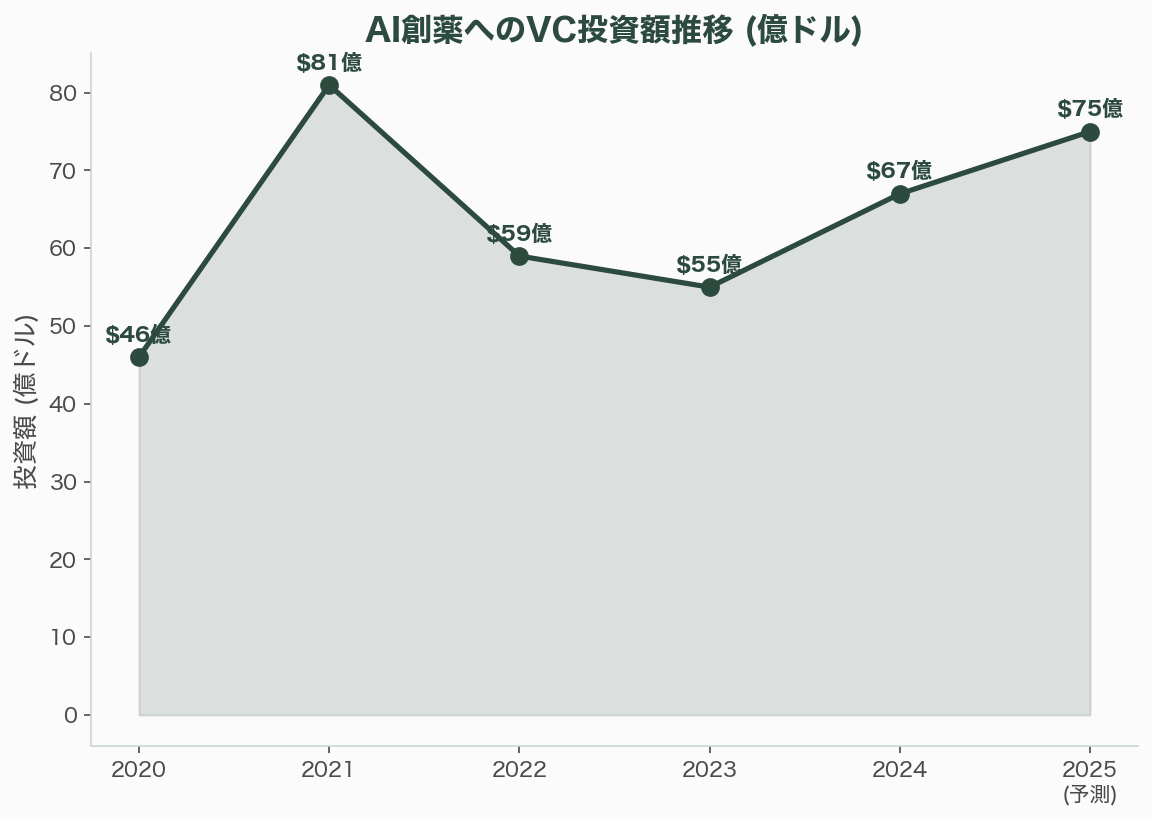
AI創薬へのVC投資総額は、2020年の46億ドルから2024年の67億ドルに拡大し(PitchBook、BioCentury)、2025年は70〜80億ドルに達する見通しだ。
Jensen Huang(NVIDIA CEO)は「次のコンピューティングプラットフォームは生物学だ。全ての製薬企業がテクノロジー企業になる」(GTC 2024基調講演)と宣言し、NVIDIAのBioNeMoプラットフォームとGPU(H100/B200)がAI創薬の「ツルハシとシャベル」として機能している。
著名人の見解——ノーベル賞受賞者からVC起業家まで
Demis Hassabis(Google DeepMind/Isomorphic Labs CEO、2024年ノーベル化学賞)は「AlphaFoldはこれまで取り組んだ中で最も重要な仕事だ。AIで最もインパクトのある応用だ」と述べ、「5年以内にAIが創薬の初期段階を大幅に加速し、10年以内にプロセス全体が根本的に変わる」と予測する。
David Baker(ワシントン大学、2024年ノーベル化学賞)は「自然の進化が探索しなかったことを行う分子をゼロから設計できる時代に入った。計算的設計とAIの組み合わせが医学で何が可能かを変革している」とノーベル講演で述べた。
Daphne Koller(Insitro CEO、Stanford教授)は「創薬が高コストな理由は、十分に良い予測モデルがないために人間で実験を行っているからだ。機械学習でより良い予測モデルを構築できれば、より速く、より安く、より早く失敗できる」と語る。
Eric Topol(Scripps Research翻訳研究所長)は「転換点にいる。バイオバンクの豊かなゲノムデータとAIの収束が、創薬の方法を変革する」と述べ、「2030年までに、AIを創薬パイプラインに持たないことは、オフィスにメールがないようなものになる。選択肢ではなくなる」と予測する。
数字で見るAI創薬——急拡大する市場と臨床成果
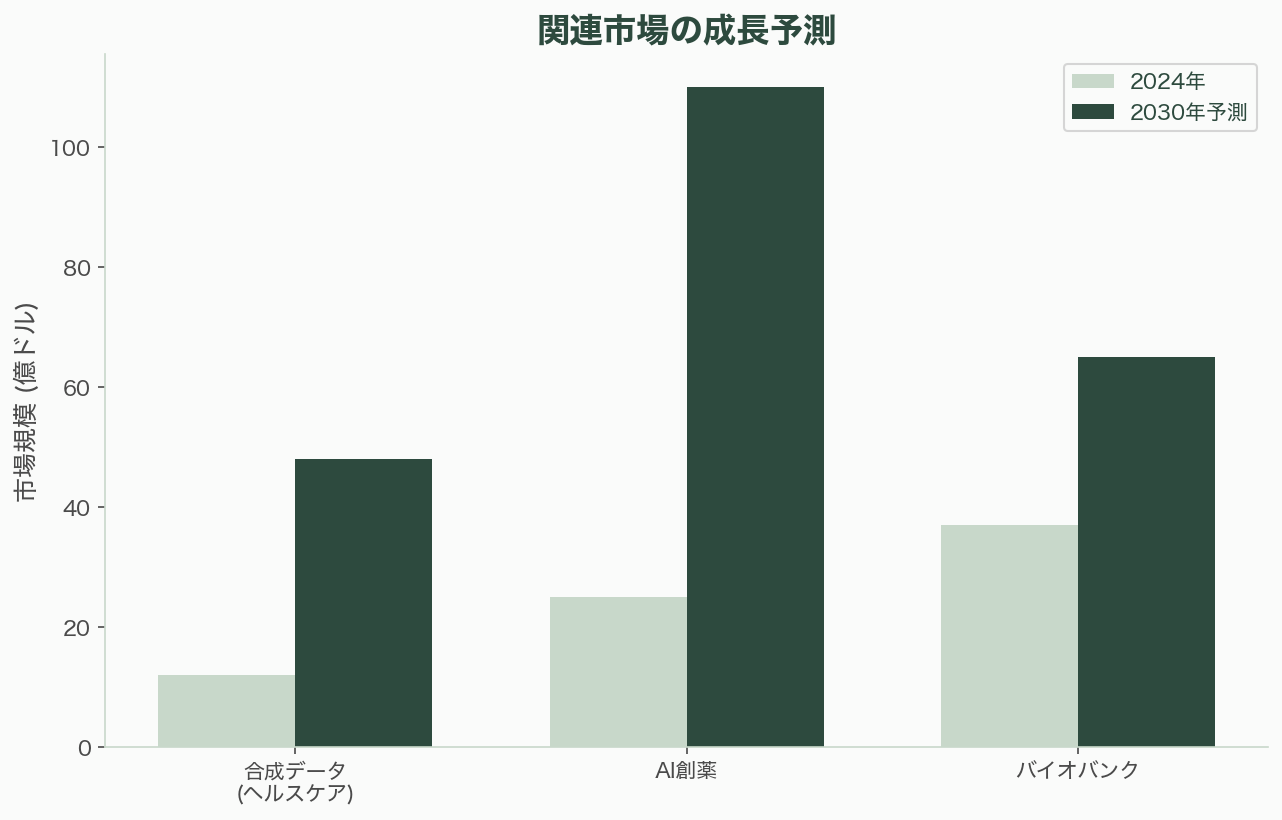
AI創薬の数字は、この分野の急拡大を物語っている。
AI創薬市場は2024年の約25億ドル(約3,750億円)から2030年に100〜120億ドル(約1兆5,000億〜1兆8,000億円)に成長する見通しだ(CAGR 24〜28%、Precedence Research)。より広義のAI in ファーマ市場は2032年に200億ドル超とも推計される(Grand View Research)。
AI発見分子の臨床進捗は加速している。2025年初頭時点で、フェーズI: 50件以上、フェーズII: 15〜20件、フェーズIII: 2〜3件のAI発見分子が臨床試験中だ。最初のFDA承認は2026〜2028年に期待されている。全ゲノムシーケンスのコストは約200ドルにまで低下した(ヒトゲノム計画の30億ドルから)。バイオバンク市場は2024年に約35〜40億ドル(約5,250億〜6,000億円)、2030年に60〜70億ドル(約9,000億〜1兆500億円)に拡大する。
日本の動向——バイオバンクと製薬AIの交差点
日本は、バイオバンクインフラとAI創薬の両面で重要なプレイヤーだ。
BioBank Japanは約27万人の参加者と47の対象疾患を擁し、東アジア集団の遺伝的構造の理解に不可欠な資源だ。UK BiobankやAll of Usとのトランスエスニック全ゲノム関連解析(GWAS)にも貢献している。
東北メディカル・メガバンク(ToMMo)は2011年の東日本大震災の復興プロジェクトとして設立され、約15万人の参加者を持つ。日本人参照ゲノムパネル(3.5KJPNv2/8.3KJPN)は日本人集団特有のゲノミクス研究に不可欠だ。
日本政府は「ゲノム医療実装戦略」(2019年策定、2023年更新)で10万以上のがんゲノムシーケンスを目標とし、AMED(日本医療研究開発機構)は年間約4,000億円の予算で創薬研究を支援している。
Preferred Networks(PFN)は第一三共やAMEDとAI創薬で提携し、分子シミュレーションの深層学習に強みを持つ。評価額は35億ドル超の日本最大級のAIスタートアップだ。
課題——楽観論の裏にあるハードル
AI創薬の将来は明るいが、重要な課題も残る。
データの偏りは最大の懸念だ。GWASの参加者の約78%がヨーロッパ系であり(2023年時点、改善中)、UK Biobankの参加者は英国平均よりも健康で裕福で白人が多い。合成データは訓練データに含まれるバイアスを伝播・増幅する可能性がある。
規制の不確実性もある。2026年初頭時点で、AI発見薬のFDA/EMA完全承認はまだない。FDAはフレームワークを公表しているが、AI発見薬に特化した規制パスウェイは確立されていない。
合成データの検証も課題だ。合成データが現実の生物学を正確に反映していることをどう証明するか。「幻覚的」パターン——統計的アーティファクト——が合成データに含まれるリスクがある。
伝統的製薬との統合も容易ではない。AIの予測はウェットラボでの検証が必要であり(「ラストマイル問題」)、「我々はいつもこうやってきた」という文化的抵抗も根強い。
今後の見通し——創薬の未来が変わる

AI創薬の今後について、業界リーダーは異例の一致した楽観を示している。
2026〜2028年: AI発見薬の最初のFDA承認が実現する見通し(最有力候補はINS018_055またはRecursion/Exscientiaプログラム)。AI創薬が大手製薬企業の標準的実践となる(McKinsey)。
2028〜2030年: 生物学のファウンデーションモデルが「GPT-3モーメント」に到達——汎用的な生物学AIが任意の創薬タスクにファインチューニング可能になる。バイオバンクの実世界データ、合成データ、AIモデルの統合が製薬R&Dの標準操作手順となる。
2032〜2035年: 創薬タイムラインが多くの適応症で3〜5年に圧縮され、コストが50〜70%削減される。希少疾患の薬剤が経済的に実現可能になる(現在、7,000以上の希少疾患の約95%に承認薬がない)。
Insilico MedicineのAlex Zhavoronkov CEOは「AIが薬を発見・設計できることは証明した。問題はもはや『可能か』ではなく『いかに速くスケールできるか』だ」と語る。その答えが出る日は、もはや遠い未来ではない。
業界への影響
第一に、バイオバンクと合成データの組み合わせが、創薬における「データの壁」を構造的に解消しつつある。UK Biobank(50万人、全WGS完了)、All of Us(80万人超、多様性50%超)、BioBank Japan(27万人)の実世界データが「地上の真実」を提供し、合成データがプライバシーと希少性の制約を超える。遺伝的根拠のある創薬ターゲットの臨床成功率が2〜2.6倍高いという知見は、この組み合わせの経済的合理性を裏付ける。
第二に、AI創薬はもはや「概念実証」の段階を超え、「臨床実証」の段階に入った。100以上のAI発見分子が臨床試験中であり、最初のFDA承認は2026〜2028年に期待される。Isomorphic Labsの合計29億ドルの大手製薬との契約、Xaira Therapeuticsの10億ドル超の創業ラウンドは、この分野への信認の深さを示す。
第三に、ノーベル化学賞のHassabis/Jumper/Baker受賞は、AIとバイオの収束が学術的に最高レベルで認められたことを意味する。AlphaFold 3の拡散アーキテクチャは創薬に直結する能力を持ち、RFdiffusion、Chroma等の生成モデルとともに、「分子をゼロから設計する」時代を現実にしている。
第四に、日本はBioBank Japan、ToMMo、AMED、PFNの存在により、東アジア集団のゲノミクスとAI創薬の交差点で独自のポジションを持つ。武田、第一三共、住友ファーマのAIパートナーシップは、日本の製薬産業がこの変革に積極的に参画していることを示す。
参考情報: Tufts CSDD Drug Development Cost Study (2020), BIO/QLS Advisors Clinical Trial Success Rates (2021), IQVIA Global R&D Spending Report (2024), Eroom's Law (Scannell et al., Nature Reviews Drug Discovery, 2012), UK Biobank Open Access Data, NIH All of Us Research Program, BioBank Japan/RIKEN, FinnGen Public-Private Partnership, deCODE Genetics/Amgen, Nelson et al. "The support of human genetic evidence for approved drug indications" (Nature Genetics, 2015), King et al. update (2019), Recursion-Exscientia Merger Announcement (Aug 2024), Insilico INS018_055 Phase II Results, Isomorphic Labs-Lilly-Novartis Deals (Jan 2024), Xaira Therapeutics $1B+ Launch, AlphaFold 3 Release (May 2024), Nobel Prize Chemistry 2024, Generate Biomedicines Chroma (Nature 2023), Absci Zero-Shot Antibody Design (Nature Biotechnology 2023), RFdiffusion (Nature 2023), Evo Model (Arc Institute 2024), Unlearn.AI FDA Guidance, Syntegra/MDClone/Gretel.ai/Datavant Company Data, a16z Bio Fund, Flagship Pioneering, ARCH Venture Partners, PitchBook/BioCentury AI Drug Discovery Funding Data, NVIDIA BioNeMo, Jensen Huang GTC 2024, Demis Hassabis Nobel Lecture, David Baker Nobel Lecture, Daphne Koller a16z Podcast (2023), Eric Topol "Ground Truths" Substack, Patrick Collison Arc Institute, Precedence Research AI Drug Discovery Market, Grand View Research, ToMMo Japanese Reference Genome, AMED Budget Data, Preferred Networks/Daiichi Sankyo Partnership, Takeda Digital Transformation, Sumitomo Pharma/Exscientia DSP-1181