Surya
1. サービス概要
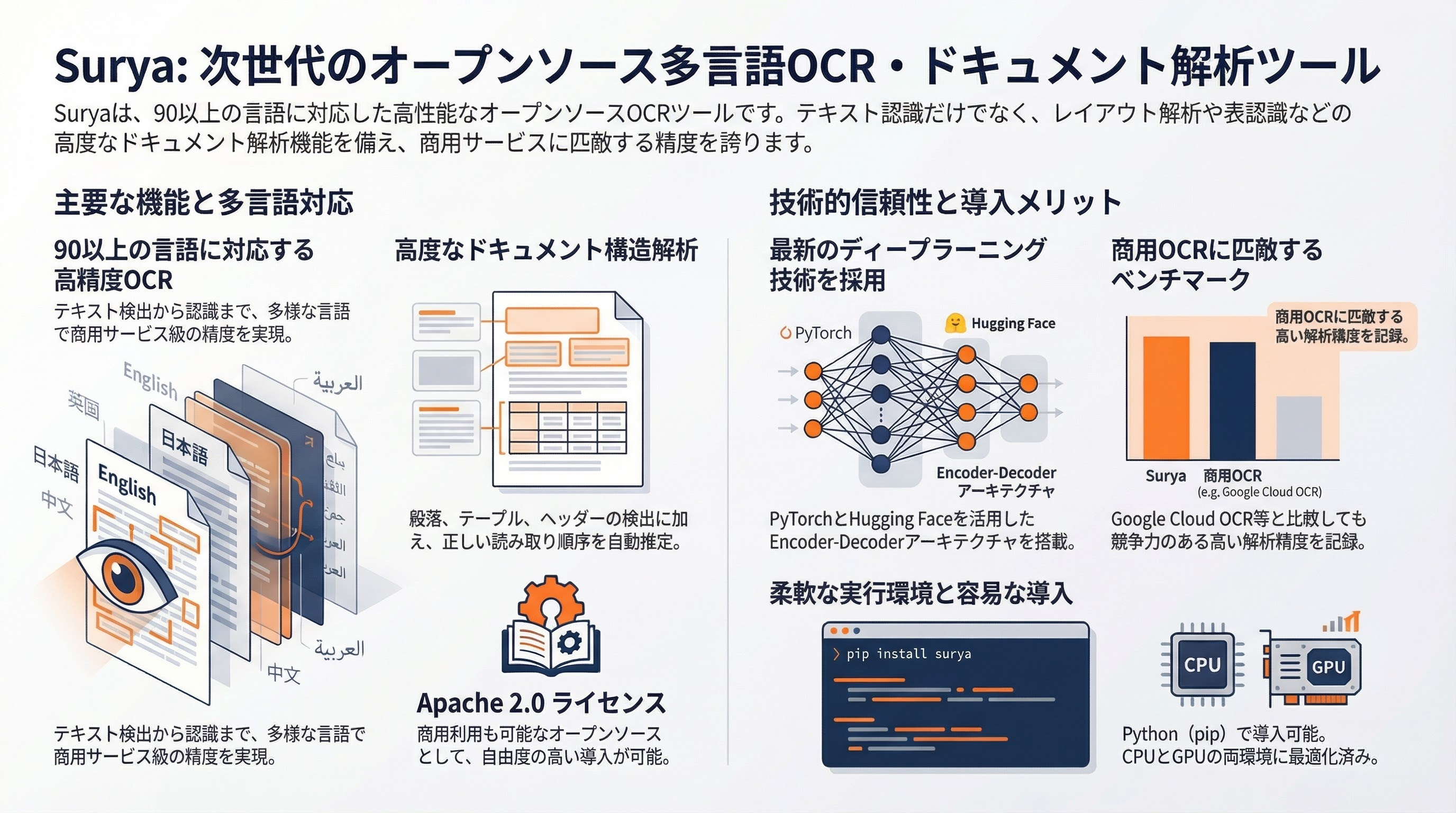
Suryaは、多言語対応のオープンソースOCR・ドキュメント解析ツールです。90以上の言語に対応し、テキスト検出・認識、レイアウト解析、行順序検出などの機能を備えています。
- 主な機能:
- テキスト検出(Text Detection): 画像・PDF内のテキスト領域を高精度に検出。
- テキスト認識(Text Recognition): 検出されたテキスト領域から文字を認識。90以上の言語に対応。
- レイアウト解析: ドキュメントの構造(段落、テーブル、ヘッダー、リスト等)を検出・分類。
- 行順序検出(Reading Order Detection): テキストブロックの読み取り順序を推定。
- テーブル認識: 表構造の検出と行・列の認識。
- ライセンス: Apache 2.0(オープンソース)。
- 対応プラットフォーム:
- Python パッケージ(pip install surya-ocr)
- CLI(コマンドラインインターフェース)
- GPU / CPU 両対応
2. 使用している技術スタック
- コア技術: ディープラーニングベースのOCRモデル。テキスト検出にはセグメンテーションモデル、テキスト認識にはEncoder-Decoderアーキテクチャ(Vision Encoder + Text Decoder)を採用。
- 言語/フレームワーク: Python。PyTorch、Hugging Face Transformersを利用。
- モデル: Hugging Face Hub上で事前学習済みモデルを公開。
- 特徴: Google CloudのOCR等の商用サービスと比較しても、多くのベンチマークで競争力のある精度を実現。特に多言語対応とレイアウト解析に強み。
3. 会社概要
- 開発者: Vik Paruchuri(個人開発者 / オープンソースプロジェクト)
- GitHub: VikParuchuri/surya
- 公開年: 2024年
- 開発拠点: 米国
4. 沿革、資本構成、国籍、役員情報
- 沿革:
- 2024年初頭:Vik ParuchuriによりGitHub上でオープンソースとして公開。
- 2024年:急速にスター数を獲得し、オープンソースOCRの有力な選択肢として認知される。
- 継続的にモデルの改善・多言語対応の拡充が行われている。
- 資本構成:
- 個人によるオープンソースプロジェクト。企業支援やVC資金は受けていない(公開情報ベース)。
- 国籍:
- 米国(開発者がUS拠点)。
- 開発者情報:
- Vik Paruchuri: データサイエンス・機械学習分野のエンジニア/起業家。OCR関連のオープンソースツール「Marker」の開発者でもある。Dataquestの創業者としても知られる。