いま「FDE」という職種に世界が殺到している

2026年のエンジニア採用市場で、もっとも注目を集めている肩書きのひとつがForward Deployed Engineer(FDE、フォワード・デプロイド・エンジニア)である。直訳すれば「前線に配置されたエンジニア」。顧客企業のオフィス・工場・物流拠点・店舗といった業務の最前線に自ら入り込み、現場の課題をその場でプロトタイプに落とし込みながら、ソフトウェアやAIを業務に定着させていく職種だ。SaaSベンダーがプロダクトを売って終わるのとは正反対に、FDEは「顧客の内側」で本番コードを書く。
この職種を発明したのはPalantir Technologiesである。同社はForward Deployed Software Engineer(FDSE)とDeployment Strategist(DS)という二系統の役割で、政府機関や大企業の現場に技術者を送り込み、データ統合基盤Foundry/Gothamを業務に食い込ませてきた。Pragmatic Engineerのニュースレター(Gergely Orosz)は、Palantirの慣行としてFDEが稼働時間のおよそ25%を顧客先のオンサイトで過ごすと報じている。a16z(Andreessen Horowitz)のMarc Andruskoは2026年に「The Palantirization of everything(あらゆるもののPalantir化)」と題し、このモデルがソフトウェア産業全体へ波及していると論じた。
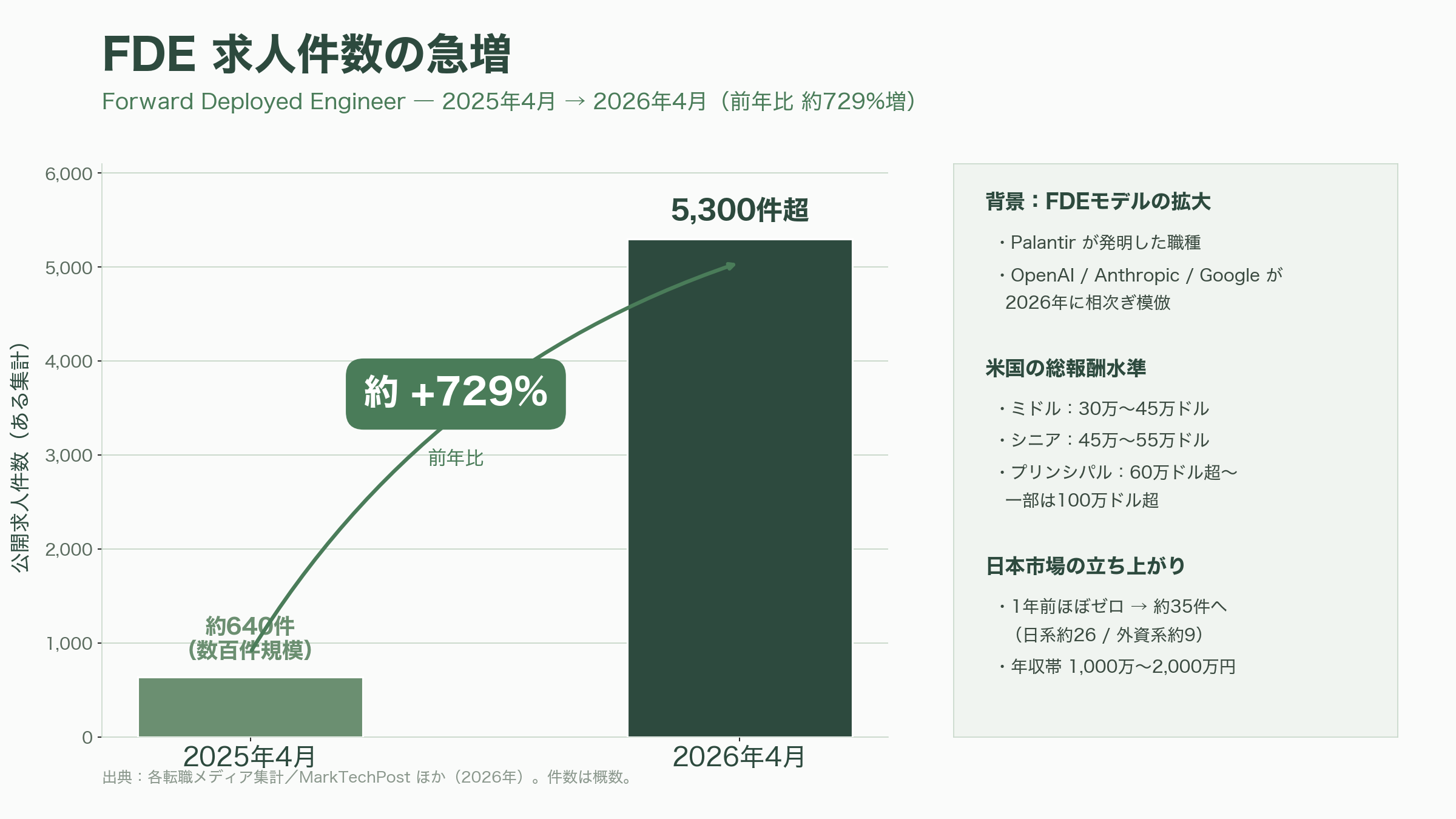
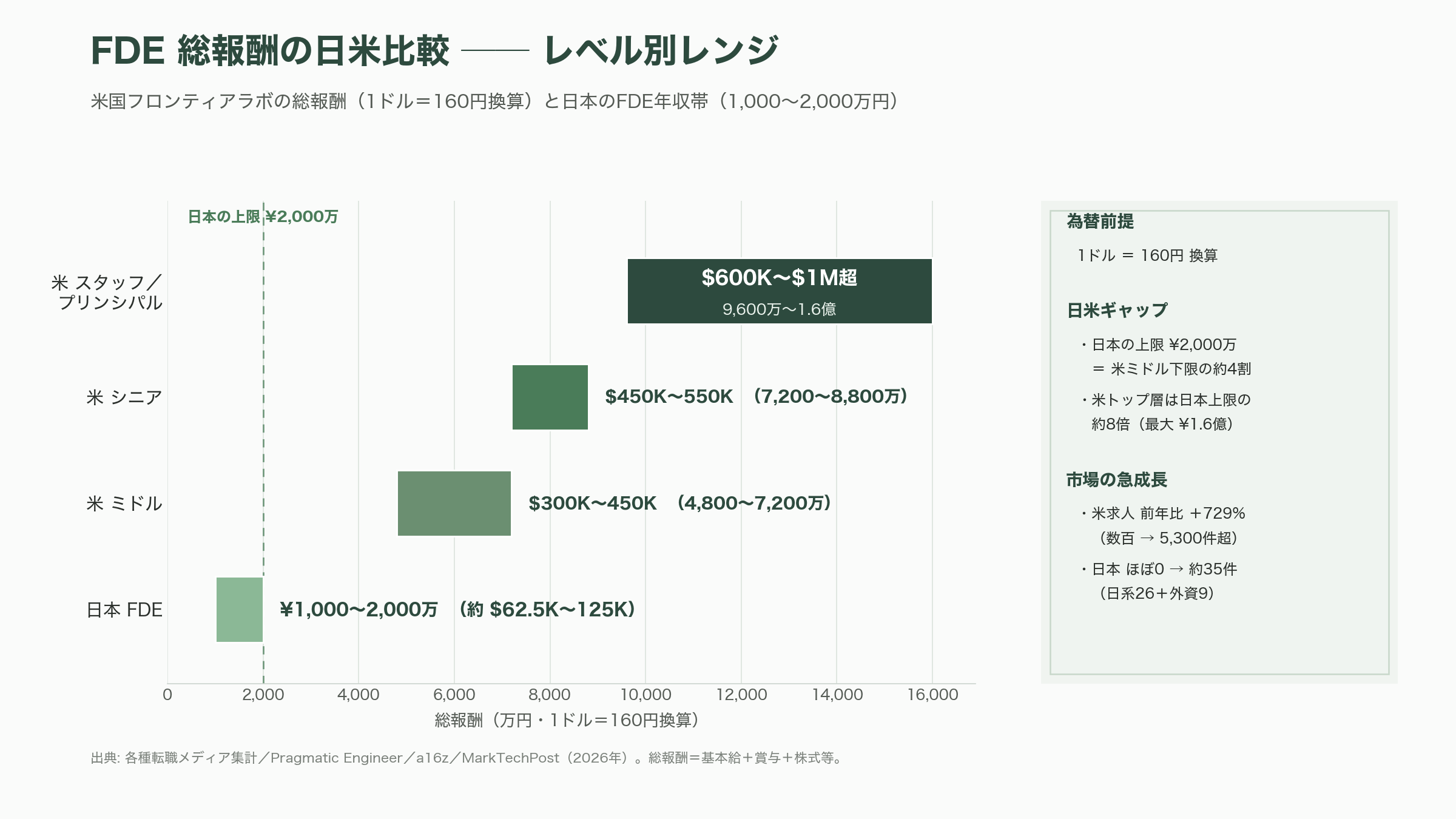
決定的だったのは、生成AIのフロンティアであるOpenAI・Anthropic・Googleが2026年にこのモデルを相次いで模倣し始めたことだ。MarkTechPostは2026年5月、これを「OpenAI・Anthropic・Googleが採用しているAI時代の職種」と特集している。Anthropicは自社のApplied AIチームの下にFDE機能を置き、戦略顧客に技術者を常駐させてClaudeの組織導入を推進している。報酬水準も突出している。複数の転職メディアの集計によれば、フロンティアラボ級の総報酬はミドルでおよそ30万〜45万ドル(約4,800万〜7,200万円)、シニアで45万〜55万ドル(約7,200万〜8,800万円)、スタッフ/プリンシパル級では60万ドル(約9,600万円)を超え、一部のプリンシパルでは100万ドル(約1.6億円)を上回るとされる。求人件数はある集計で2025年4月から2026年4月にかけて前年比でおよそ729%増え、数百件から5,300件超へと跳ね上がったと報じられている。
日本でも立ち上がりは急だ。日本語の転職メディアの集計では、2026年春時点で公開中のFDE求人は日系約26件・外資系約9件の合計35件前後で、1年前にはほぼゼロだった職種が30件超まで一気に育った。年収帯は1,000万〜2,000万円が形成されつつあり、米国の35万〜70万ドル(約5,600万〜1.1億円)超という水準には及ばないものの、国内エンジニアにとっても無視できない新しいキャリアパスになっている。Goodpatchやソフトバンクのビジネスブログ、TechLabsやムービンといった媒体が、こぞって「BTC(Business・Technology・Creativity)をバランスよく備えた人材」としてFDE像を解説している。
では、AIがコードを量産する時代に、なぜ人間のFDEがこれほど求められるのか。その答えの核心にあるのが、本稿の主題であるデータモデリングだ。
データモデリングとは何か——現実をデータ構造へ翻訳する営み
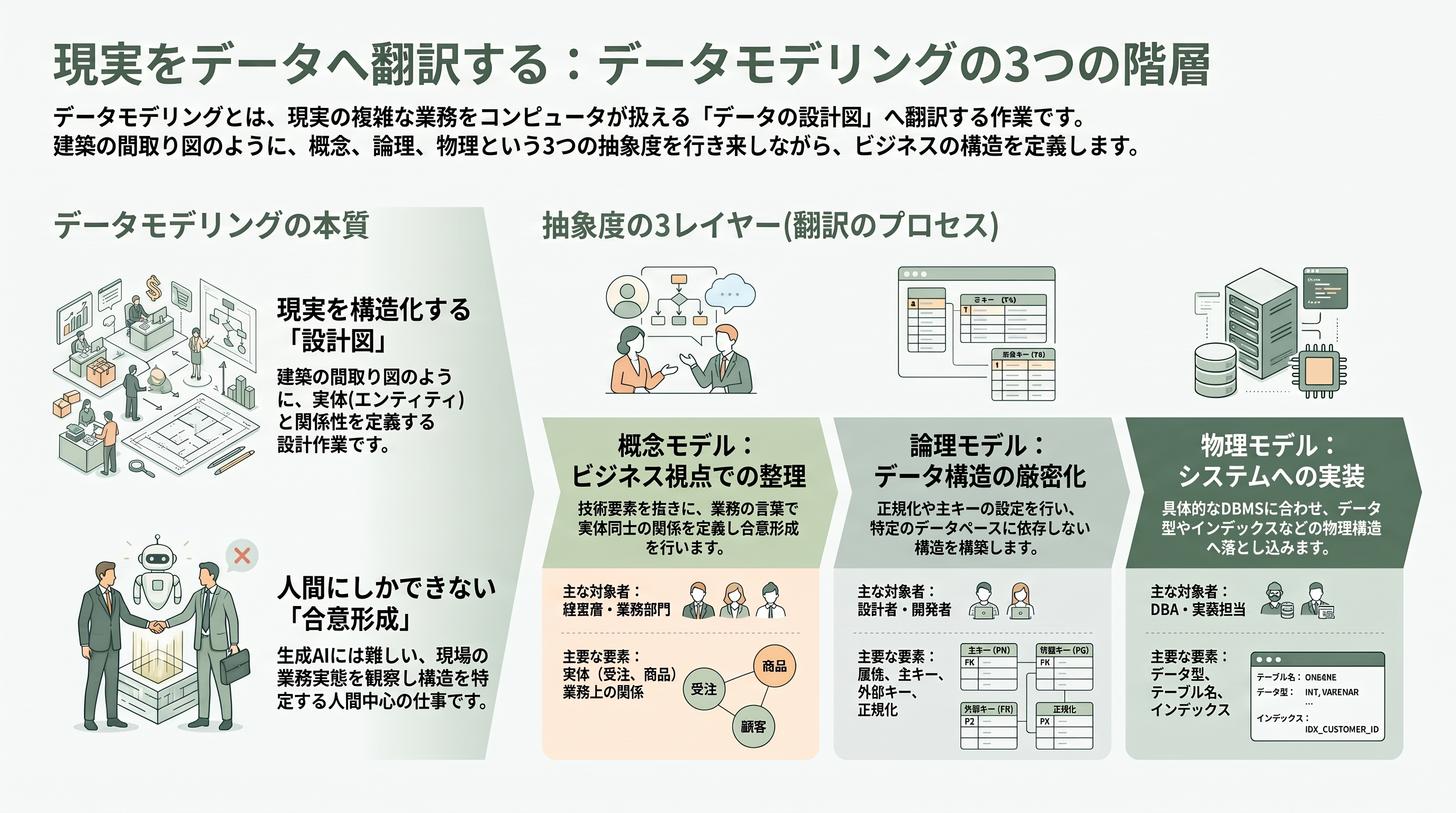
データモデリングとは、ひとことで言えば「現実世界の業務を、コンピュータが扱えるデータの構造へ翻訳する設計作業」である。ここで言う構造とは、どんなデータ(実体)が存在し、それぞれがどんな属性を持ち、互いにどう関係しているかを規定した青写真のことだ。家を建てる前に建築士が間取り図を描くように、システムを作る前にデータモデラーがデータの間取り図を描く。間取りを間違えれば、後からどれだけ立派な内装(アプリケーション)を作っても住みにくい家にしかならない。
具体的に考えてみよう。たとえば「受注業務」をシステム化するとする。現実には、得意先から注文が入り、一回の注文で複数の商品が、それぞれ異なる数量で頼まれ、その注文に営業担当者がひもづく。この現実を観察して、「受注」「受注明細」「得意先」「商品」「社員」といった実体(エンティティ)を切り出し、「一件の受注は複数の受注明細を持つ」「受注明細は一つの商品を指す」「受注は一人の得意先と一人の担当社員にひもづく」といった関係(リレーション)を定義していく。これがデータモデリングの最初の一歩だ。
重要なのは、データモデリングが三つの抽象度の層を行き来する点である。もっとも上位にあるのが概念モデルで、業務の言葉で「受注」「得意先」「商品」がどう関係するかを、技術の細部を抜きにして描く。経営層や業務部門と合意を取るための図であり、ここに「VARCHAR」や「インデックス」は登場しない。次が論理モデルで、各実体にどんな属性があるか、主キー(その行を一意に識別する鍵)と外部キー(他の実体を参照する鍵)は何か、までを正規化の理論にもとづいて厳密に詰める。ここはまだ特定のデータベース製品に依存しない。最後が物理モデルで、論理モデルをOracleやPostgreSQL、SQL Serverといった実在のDBMS上のテーブル・列・データ型・制約・インデックスへ落とし込む。日本のSI現場では、論理名(社員、受注日)と物理名(EMP、ORDER_DATE)を一枚のER図上で併記し、論理と物理を行き来できるようにするのが定石だ。
この「概念→論理→物理」の翻訳こそ、FDEが顧客の現場で最初に直面する仕事である。顧客の頭の中にある業務(概念)を引き出し、整合した構造(論理)に整え、動くシステム(物理)へ落とす。生成AIはSQLやコードを驚くほど速く書けるが、目の前の会社の業務が本当はどういう構造をしているのかを当てる仕事は、現場で人間が観察し、合意を取りながら詰めるしかない。
なぜFDEにこそデータモデリングが必要なのか
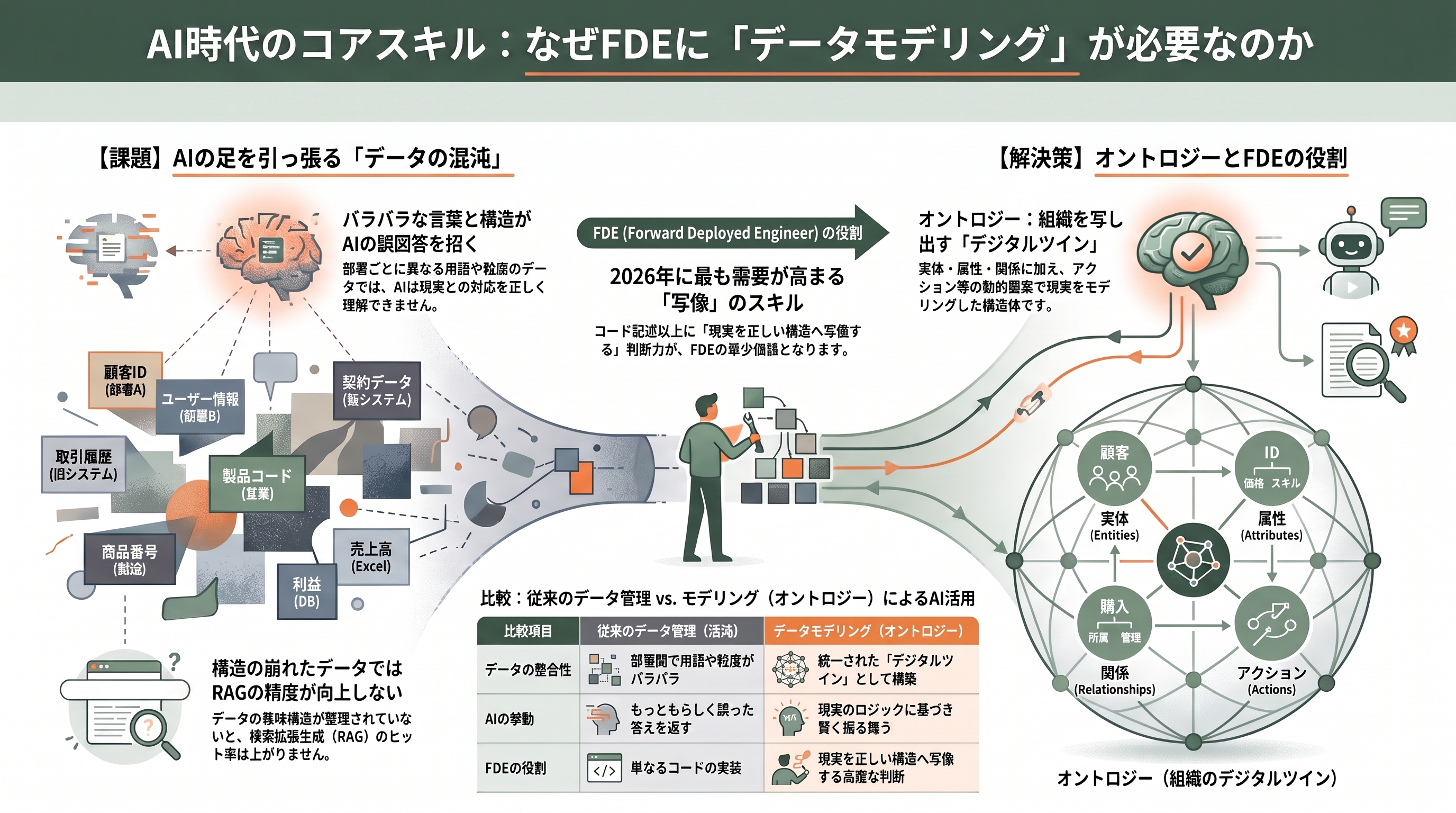
FDEが入っていく現場の実態は、たいてい「データの混沌」である。基幹システムのテーブル、Excelの台帳、SaaSのAPI、紙の帳票が、それぞれ別の言葉で同じ実体を指している。営業部の「顧客」、経理部の「取引先」、物流部の「納品先」が、実は同じ会社を指しているのに、コード体系も粒度もバラバラだ。この状態のまま生成AIやエージェントを載せても、AIは「どのテーブルのどの列が、現実の何に対応するのか」を知らないため、もっともらしく誤った答えを返す。RAG(検索拡張生成)でドキュメントを食わせても、データの意味構造が崩れていれば検索のヒット率は上がらない。
ここでデータモデリングが効いてくる。Palantirがこの問題に与えた答えがOntology(オントロジー)だ。Palantirの公式ドキュメントによれば、Ontologyとは組織の現実世界の実体・関係・ロジックを写し取った「組織のデジタルツイン」であり、オブジェクト型(実体)・プロパティ(属性)・リンク型(関係)という意味要素に加えて、アクションやファンクションといった「動かす」要素を備える。Palantir AIP(AI Platform)は、このOntologyを介してAIモデルを組織のデータと業務につなぐ。要するに、AIに賢く振る舞わせる前提として、まず現実を正しくモデリングしておく必要があるという思想だ。Palantirの現場で本番投入される成果物が「データパイプライン、オントロジーモデリング、AIエージェント設計」だと各所で報じられているのは、この順序を象徴している。
だからこそ、FDEの求人要件にはデータモデリングが明示的に並ぶ。Spark・Airflow・dbtを使ったデータエンジニアリング、オントロジーモデリング、課題の分解(decomposition)、そしてRAGパイプライン・評価フレームワーク・エージェント開発・本番運用の可観測性——これらが2026年のエンタープライズAIでもっとも需要が高く、もっとも供給が薄いスキルセットだと指摘されている。コードを書くだけならAIで代替が進むが、「顧客の現実を正しい構造へ写像する」判断は、いまだ人間のFDEの中核能力なのである。本稿が以降で再考するER図・正規化・非正規化・履歴設計は、まさにその写像の精度を決める基礎技術にほかならない。
データモデリングツールの地図——タイプ別と主要製品

データモデリングに使う道具は、目的と組織規模によっていくつかの系統に分かれる。最初に押さえたいのが、エンタープライズ向けの専用モデリングツールだ。この領域の二強がerwin Data ModelerとER/Studioである。erwinはニュージャージーのLogic Worksが生んだ老舗で、その後Computer Associates(CA)の傘下に入り、2016年に投資ファンドParallax Capital Partnersへ売却されてerwin, Inc.として独立、そして2021年初頭(クローズは2020年12月31日)にQuest Softwareが買収して現在に至る。一方のER/StudioはEmbarcadero系の製品で、現在はIDERAが擁する。両者はリバースエンジニアリング(既存DBからER図を起こす)、論理・物理モデルの双方向管理、大規模チームでの共有リポジトリ、データリネージュやビジネス用語集の統合といった重量級の機能を競っている。第三の柱としてSAPのPowerDesignerも、エンタープライズアーキテクチャ寄りの強力な選択肢として広く使われている。これらはライセンスが高価で、金融・製造・官公庁といった大規模システムのデータガバナンスを担う層が中心顧客だ。
次が、DBMSベンダーが無償で配る純正ツール群である。OracleのSQL Developer Data Modeler、Oracleが擁するMySQL Workbench、PostgreSQL向けのオープンソースpgModelerなどがこれにあたる。特定の製品に最適化されている代わりに無償で手に入り、個人やチームが日常的に物理モデルを描き、DDL(CREATE TABLE文)を生成するのに十分な機能を持つ。
日本の現場で根強い人気を誇るのが、松原正和氏が無償で公開するA5:SQL Mk-2だ。軽量なSQL開発環境にER図エディタを内蔵し、テーブル定義からDDLを出力したり、既存データベースを解析してER図を自動生成したりできる。フューチャーやImpress Watchなど技術系メディアでも「無料とは思えない神ツール」として繰り返し紹介されている。商用では、システムインテグレータ社のSI Object Browser ERが、論理名・物理名の併記やリバースエンジニアリングを日本語環境で手厚くサポートし、SI案件で採用されてきた。
加えて、純粋な作図に寄ったツールとして、draw.io(diagrams.net)、Lucidchart、Nulabのcacoo、ブラウザで手軽に書けるdbdiagram.ioなどが、軽量なER図の共有に広く使われる。そして近年は、ELT時代の「分析エンジニアリング」を担うdbtが、SQLによる変換ロジックそのものをモデルとして版管理し、セマンティックレイヤーで指標定義を一元化するという、新しい意味でのデータモデリングを牽引している。最後に、前章で触れたPalantirのOntologyは、図を描いて終わりではなく、本番業務とAIエージェントが実際に駆動する「生きたモデル」を保持する点で、従来の作図ツールとは一線を画す存在として位置づけられる。FDEは案件の性質に応じて、これらの系統を使い分けることになる。
論理モデリング・物理モデリング・ER図
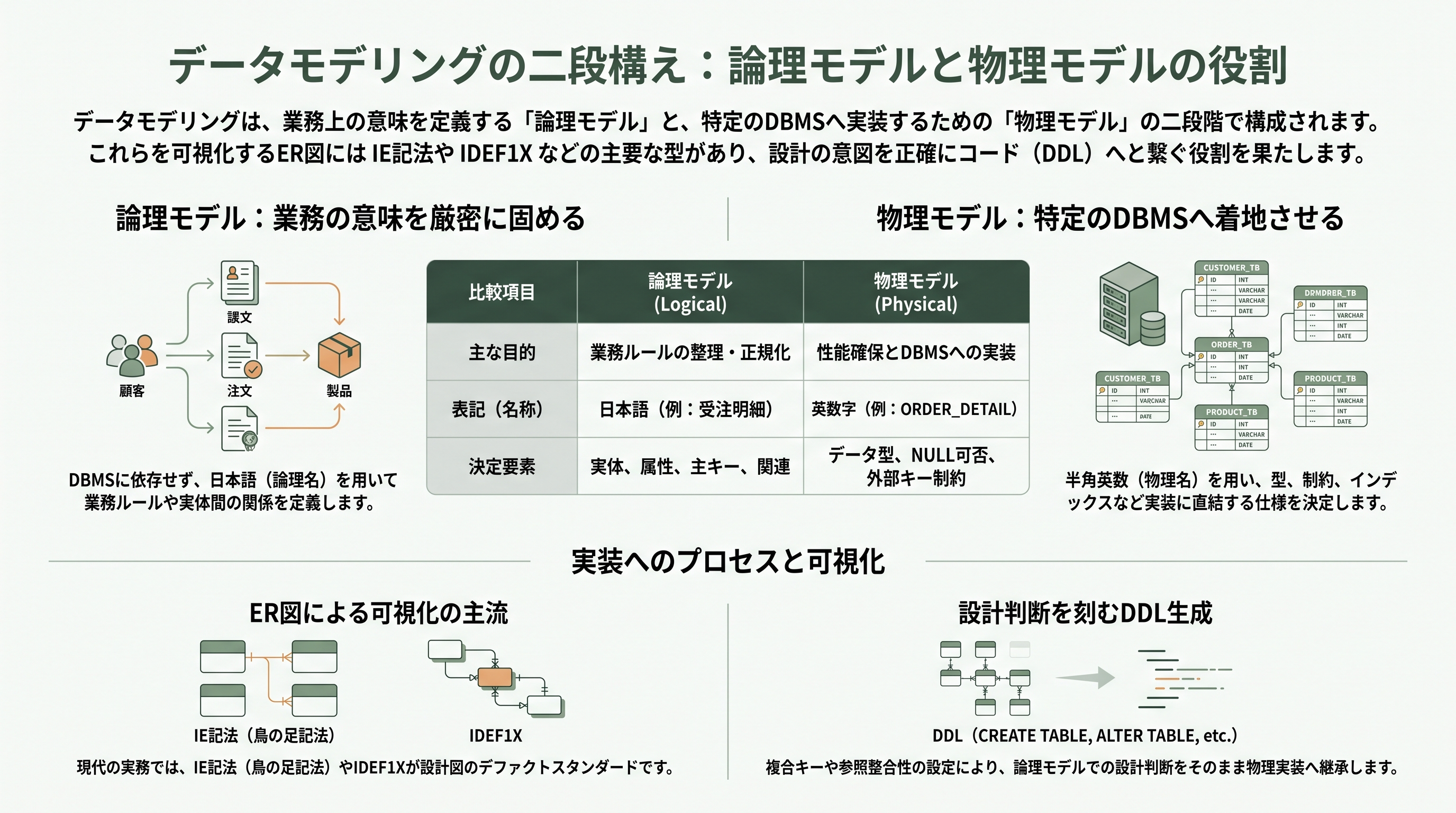
ここから各論に入る。データモデリングの背骨をなすのが、論理モデル・物理モデルの二段構えと、それを可視化するER図(Entity-Relationship Diagram、実体関連図)である。ER図の理論的な原型は、1976年にPeter Chenが発表した論文「The Entity-Relationship Model」にさかのぼる。Chenの記法では実体を長方形、関連を菱形、属性を楕円で描く。ただし現代の実務でこの原典記法を見かけることは少なく、主流は二つに収束している。ひとつがJames Martinに連なるIE記法(Information Engineering、いわゆる鳥の足/クロウズフット記法)で、線の端を鳥の足のように三又に分けて「多」を、丸で「ゼロも可(任意)」を、縦棒で「一」を表す。もうひとつが米国政府標準に由来するIDEF1Xで、erwinが既定で採用していることもあり、堅い業務システムで根強い。
論理モデリングとは、これらの記法を使って「業務の意味」を厳密に固める作業だ。ここでは具体的なDBMSをまだ想定しない。たとえば受注業務なら、社員・部門・得意先・商品・受注・受注明細という実体を置き、それぞれに属性(受注なら受注番号・受注日・得意先番号・担当社員番号)と主キーを与え、後述する正規化の理論で重複や矛盾を排除する。論理名は日本語で「受注明細」「受注時単価」のように書くのが日本の慣習だ。
物理モデリングは、その論理モデルを実在のDBMSへ着地させる。テーブル名・列名を物理名(半角英数、たとえばORDER_DETAIL、UNIT_PRICE)にし、列ごとにデータ型(NUMBER(10)、VARCHAR2(40)、DATE)と桁、NULL可否、主キー・外部キー制約、検索性能のためのインデックスを決める。ここで初めて「この列はBIGINTか、それともUUIDか」「この履歴テーブルにはどんな複合インデックスを張るか」といった、製品固有の判断が入る。
ハンズオンのイメージを掴むために、受注明細の物理モデルをDDLで書いてみよう。論理モデルで「受注明細は受注と商品にひもづき、数量と受注時単価を持つ」と決めたものを、PostgreSQLの物理モデルへ落とすと次のようになる。
CREATE TABLE order_detail (
order_no BIGINT NOT NULL, -- 受注番号(受注への外部キー)
line_no INTEGER NOT NULL, -- 明細行番号
product_no BIGINT NOT NULL, -- 商品番号(商品への外部キー)
quantity INTEGER NOT NULL CHECK (quantity > 0), -- 数量
unit_price NUMERIC(10) NOT NULL, -- 受注時単価(あえて明細に持つ=後述)
PRIMARY KEY (order_no, line_no), -- 受注番号+行番号で一意
FOREIGN KEY (order_no) REFERENCES "order"(order_no),
FOREIGN KEY (product_no) REFERENCES product(product_no)
);
このDDLには、論理モデルでの設計判断がそのまま刻まれている。主キーが(order_no, line_no)の複合キーであること、商品への外部キーで参照整合性を担保していること、そしてunit_priceを商品マスタではなく明細側に持たせていること——この最後の一点は、次章以降で「非正規化」と「履歴設計」を理解する伏線になる。
リレーションの実例——1対多から多対多まで
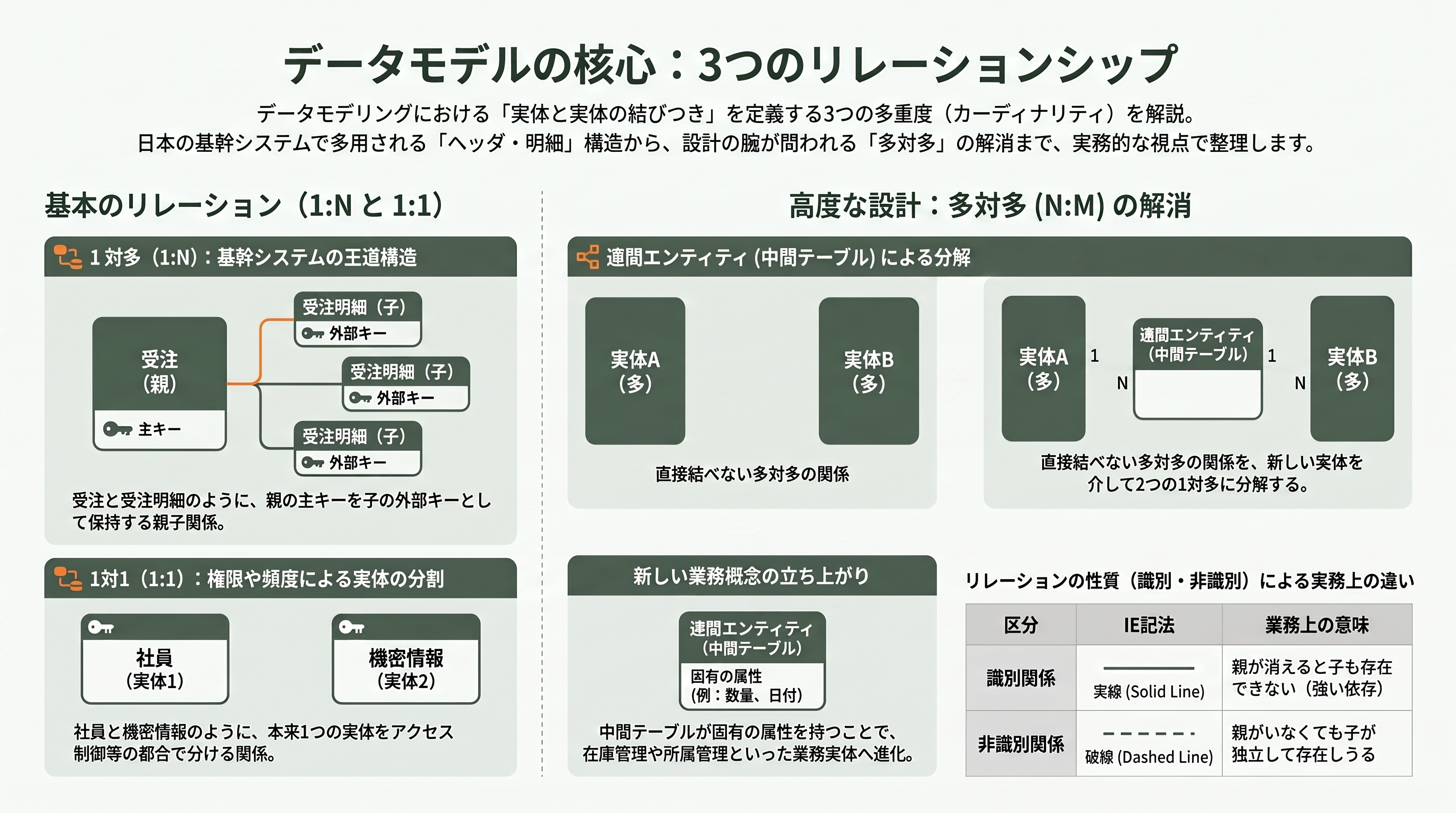
データモデリングの面白さの大半は、実体と実体をどう結ぶか、すなわちリレーションの設計に宿る。基本となるのが三つの多重度(カーディナリティ)だ。
もっとも頻出するのが1対多(1:N)である。受注業務でいえば「一件の受注は、複数の受注明細を持つ」がこれにあたる。逆から見れば「一行の受注明細は、必ず一件の受注に属する」。実装上は、多側のテーブル(受注明細)に一側の主キー(受注番号)を外部キーとして持たせることで表現する。日本の基幹システムは、この「ヘッダ(受注)+明細(受注明細)」という1対多の組がいたるところに現れる。請求書と請求明細、出荷と出荷明細、仕訳ヘッダと仕訳明細——構造はすべて同じ親子関係だ。
次に1対1(1:1)。これは「社員」と「社員の機密人事情報」のように、本来は一つの実体だが、アクセス権限や更新頻度の都合で別テーブルに切り出したいときに使う。主キーを共有し、片方が他方を補完する関係になる。
そして設計者の腕が問われるのが多対多(N:M)だ。たとえば「商品は複数の倉庫に在庫され、倉庫は複数の商品を保管する」。この関係はそのままでは一本の外部キーで表せない。そこで、両者の間に連関エンティティ(中間テーブル、associative entity)を置く。具体的には「在庫」という実体を新設し、商品番号と倉庫番号の両方を外部キーとして持たせ、その組み合わせを主キーにする。
CREATE TABLE inventory (
warehouse_no BIGINT NOT NULL, -- 倉庫番号
product_no BIGINT NOT NULL, -- 商品番号
stock_qty INTEGER NOT NULL DEFAULT 0, -- 在庫数
PRIMARY KEY (warehouse_no, product_no), -- 倉庫×商品の組で一意
FOREIGN KEY (warehouse_no) REFERENCES warehouse(warehouse_no),
FOREIGN KEY (product_no) REFERENCES product(product_no)
);
このとき重要なのは、連関エンティティはたいてい「ただの橋渡し」では終わらないことだ。在庫テーブルは在庫数という固有の属性を持ち、やがてロット番号や棚番、最終入庫日といった属性が育っていく。多対多を中間テーブルに分解した瞬間、そこには新しい業務概念(在庫管理)が立ち上がる。社員と部門の関係も同じだ。「社員は複数の部門に所属しうる(兼務)し、部門は複数の社員を抱える」という多対多は、「所属」という連関エンティティへ分解され、そこに所属開始日・所属終了日・主務/兼務区分といった属性がぶら下がる。この「所属」こそ、本稿の後半で人事システムの核心として再登場する実体である。
リレーションにはもう一段、識別関係(identifying)と非識別関係(non-identifying)という区別もある。受注明細の主キーが(受注番号, 行番号)のように親の主キーを含むなら識別関係、外部キーは持つが主キーには含めないなら非識別関係だ。IE記法では前者を実線、後者を破線で描き分ける。この区別は、親が消えたとき子も論理的に存在しえないか(識別)、それとも独立して存在しうるか(非識別)という、業務上の意味を反映している。
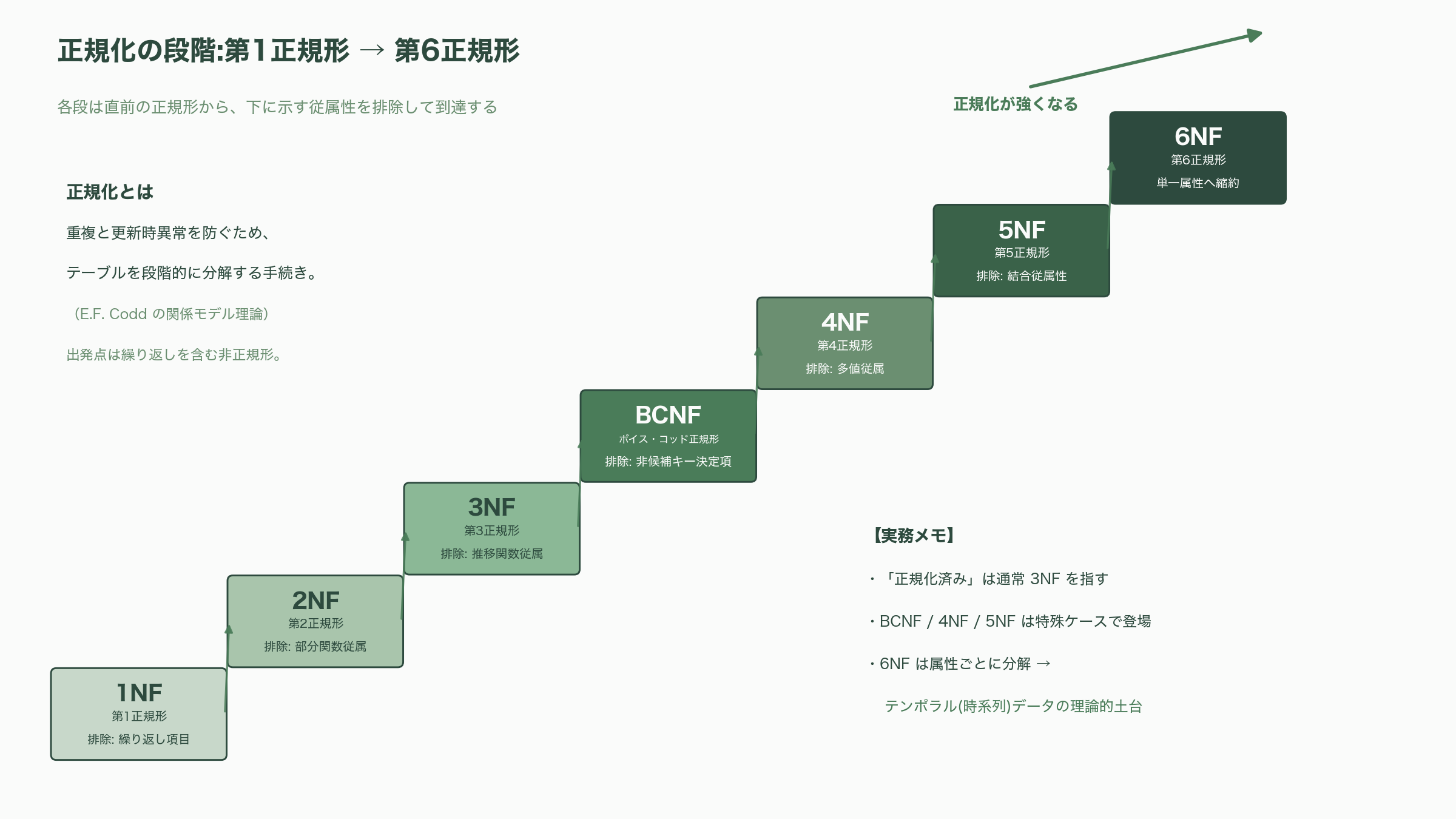
正規化の種類——第1正規形から第6正規形へ
リレーションを正しく引けるようになったら、次は正規化(normalization)だ。正規化とは、E.F. Coddが提唱した関係モデルの理論にもとづき、データの重複と更新時異常(更新・挿入・削除のたびに矛盾が生じる現象)を排除するために、テーブルを段階的に分解していく手続きである。段階は「正規形」と呼ばれ、低い方から積み上がる。
出発点として、わざと崩した受注台帳を考えよう。一行に受注番号・受注日・得意先番号・得意先名・得意先住所・商品番号・商品名・単価・数量がすべて詰め込まれ、しかも一件の受注で複数商品を頼むと商品の列が横に繰り返される——そんなExcel的な台帳だ。これを正規化していく。
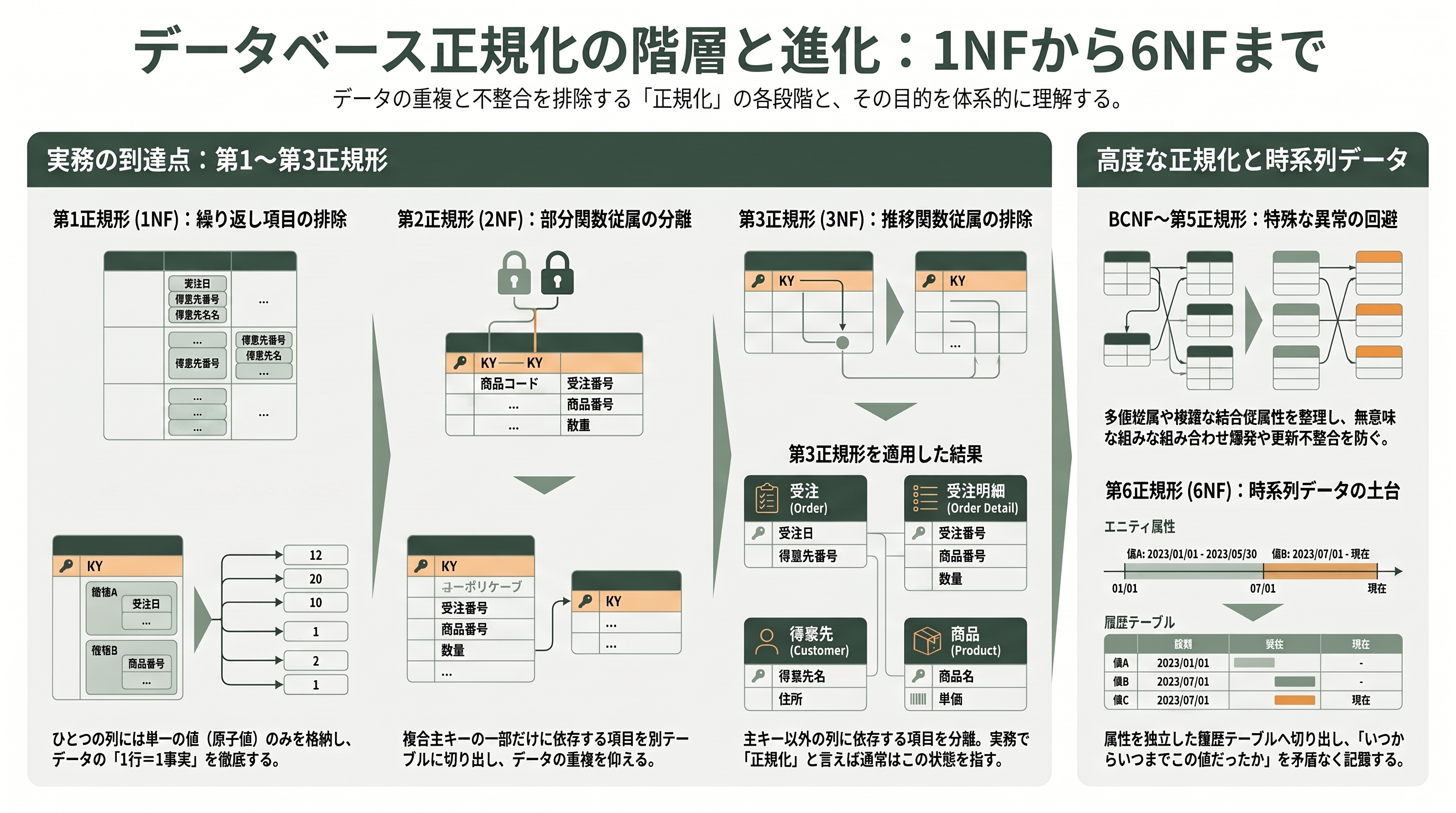
第1正規形(1NF)は、繰り返し項目をなくし、各列が単一の値(原子値)を持つようにする。横に繰り返していた商品群を縦の行に展開し、主キーを(受注番号, 商品番号)とする。これで「一行=一つの注文明細」になった。
第2正規形(2NF)は、複合主キーの一部だけに依存する属性(部分関数従属)を追い出す。(受注番号, 商品番号)が主キーのとき、受注日・得意先番号・得意先名・得意先住所は受注番号だけで決まり、商品名・単価は商品番号だけで決まる。前者を「受注」テーブルへ、後者を「商品」テーブルへ分離し、明細には主キー全体に依存する数量だけを残す。
第3正規形(3NF)は、主キー以外の列に依存する属性(推移関数従属)を追い出す。分離した「受注」テーブルには得意先番号・得意先名・得意先住所が残っているが、得意先名と得意先住所は得意先番号で決まる(主キーである受注番号を経由した間接的な依存だ)。これを「得意先」テーブルへ切り出す。結果として、受注・受注明細・得意先・商品という、それぞれが単一の主題だけを語るきれいな四つの実体に落ち着く。実務で「正規化されている」と言うとき、ふつうはこの第3正規形を指す。
ここから先は登場頻度こそ下がるが、知っておくと事故を防げる。ボイス・コッド正規形(BCNF)は3NFをさらに厳格にしたもので、テーブル内のあらゆる決定項(他の列を決める列)が候補キーであることを要求する。候補キーが複数あって一部が重なるような特殊なケースで3NFをすり抜ける異常を、BCNFは塞ぐ。第4正規形(4NF)は、独立した多値従属を分離する。たとえば一人の社員が複数のスキルと複数の保有資格を持ち、両者が互いに無関係なら、スキルと資格を一つのテーブルに同居させると無意味な組み合わせ爆発が起きる。これを二つの履歴テーブルに割る。第5正規形(5NF、結合従属性正規形)は、三項以上の関係を分解しても情報が失われないようにする、さらに稀な段階だ。
そして温故知新の文脈で近年あらためて注目されるのが第6正規形(6NF)である。6NFは、各テーブルを「主キー+たかだか一つの非キー属性」という、これ以上分解できない極限まで縮約する。一見やりすぎに思えるが、これは時間とともに値が変わる属性を扱うテンポラル(時系列)データの理論的な土台になる。C.J. Date、Hugh Darwen、Nikos Lorentzosらが『Temporal Data and the Relational Model』で論じたように、各属性を独立した履歴テーブルへ切り出せば、「いつからいつまでこの値だった」を属性ごとに矛盾なく記録できる。本稿の最終章で扱う人事の発令・所属履歴の設計は、まさにこの6NF的な発想と地続きである。
非正規化こそ、データモデリングの真髄
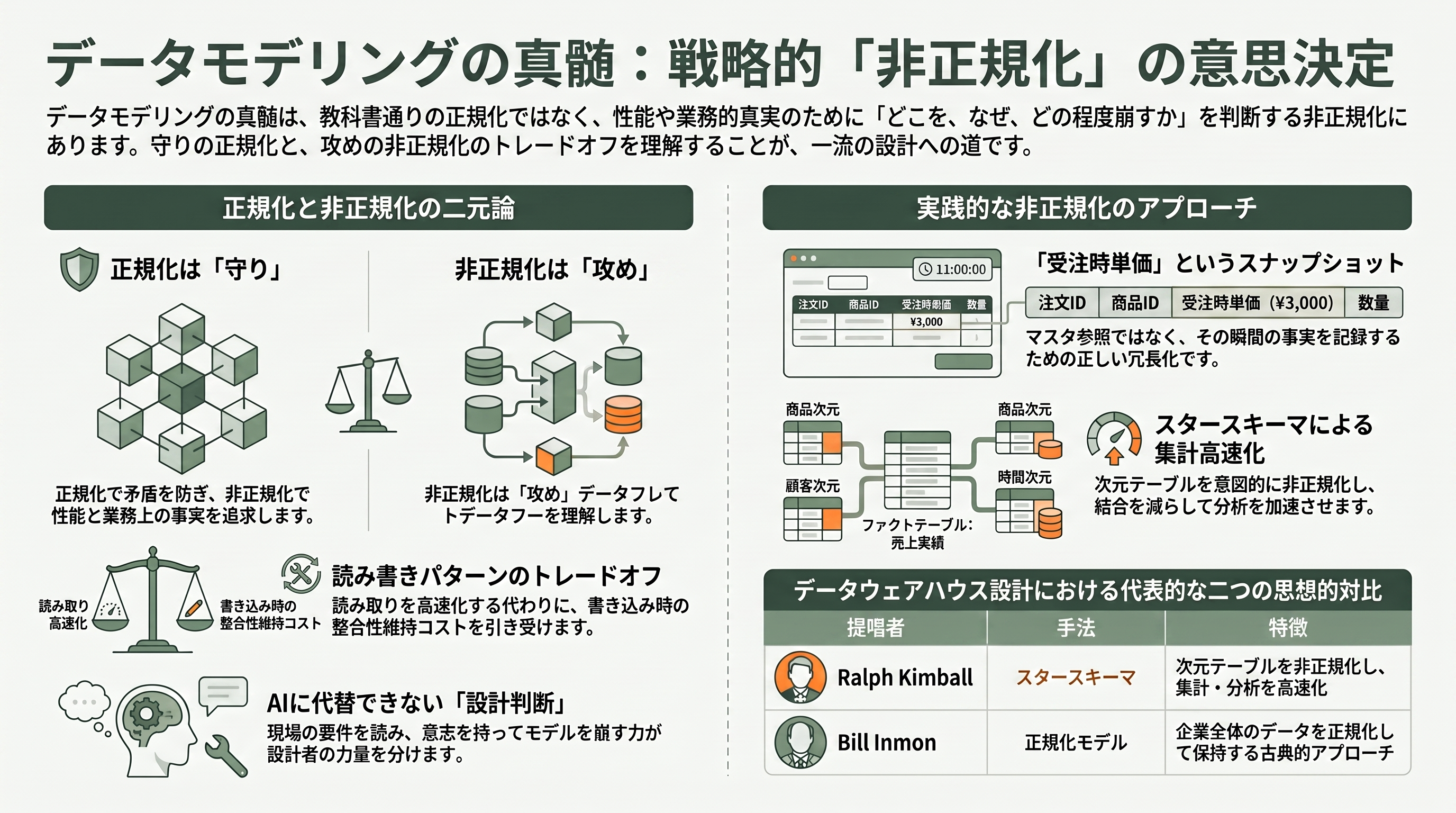
正規化を一通り学ぶと、誰もが一度は「では常に第3正規形まで割れば正解なのか」と考える。そして現実のシステムを覗いて愕然とする——一流の設計ほど、意図的に正規化を崩しているのだ。ここにデータモデリングの真髄がある。教科書通りに割るのは作業であり、どこを、なぜ、どの程度崩すかを判断するのが設計である。
非正規化(denormalization)とは、性能や業務要件のために、あえて冗長性を持ち込む設計判断だ。代表例が、第5章のDDLでさりげなく仕込んだunit_price(受注時単価)である。正規化の理屈だけで言えば、単価は商品マスタにあるのだから、受注明細に単価を持つのは重複であり3NF違反に見える。しかし商品の価格は時とともに改定される。もし明細が商品マスタの単価を参照するだけなら、来月価格を上げた瞬間、先月の受注金額まで遡って書き換わってしまう。これは業務上の大事故だ。だから受注時点の単価を明細に焼き付ける(スナップショットする)。これは冗長化ではなく、「受注した瞬間の事実」という、商品マスタとは別の真実を記録する正しいモデリングなのである。「冗長に見えるが実は別概念」を見抜けるかどうかが、設計者の力量を分ける。
性能のための非正規化も多い。集計レポートで毎回何百万行を結合して合計を出すのが重いなら、受注ヘッダに合計金額を冗長に持たせ、明細更新時に同期する。あるいは部門名を所属テーブルにコピーして、画面表示のたびに部門マスタを結合せずに済ませる。これらはいずれも「読み取りを速くする代わりに、書き込み時の整合性維持を引き受ける」というトレードオフだ。
この発想を体系化したのが、Ralph Kimballのディメンショナルモデリング(次元モデリング)である。分析・レポーティングを担うデータウェアハウスでは、業務系の正規化されたモデルとは逆に、事実テーブル(売上などの数値)を中心に、顧客・商品・期間といった次元テーブルを放射状に配置するスタースキーマを採る。次元テーブルは意図的に非正規化され、顧客の地域・業種・ランクといった属性がフラットに並ぶ。結合を減らし、集計を高速化するための、計算ずくの冗長化だ。一方でBill Inmonは、企業全体のデータウェアハウスはむしろ正規化して作るべきだと説き、KimballとInmonの対比はデータ基盤設計の古典的論争として今も語られる。さらにDan LinstedtのData Vaultや、Lars RönnbäckのAnchor Modelingといった、変化と履歴に強い専用の方法論も実務に根を張っている。
要点はこうだ。正規化は重複と矛盾を防ぐ守りの理論、非正規化は性能と業務的真実を取りに行く攻めの判断。優れたFDEやデータモデラーは、正規化を完璧に理解したうえで、現場の読み書きパターンと業務要件を読み、どこを崩すかを意志をもって決める。この判断力こそ、AIに丸投げできない設計の核心である。
人事システムで見る実際のデータモデリング
抽象論をここまで積み上げてきたので、日本のSI現場でもとりわけ難物とされる人事システムを題材に、実際のデータモデリングを通しで見てみよう。人事は「人」という単純そうな実体を扱うのに、時間と組織が絡んだ瞬間に、データモデリングのほぼ全論点が噴き出す領域だ。
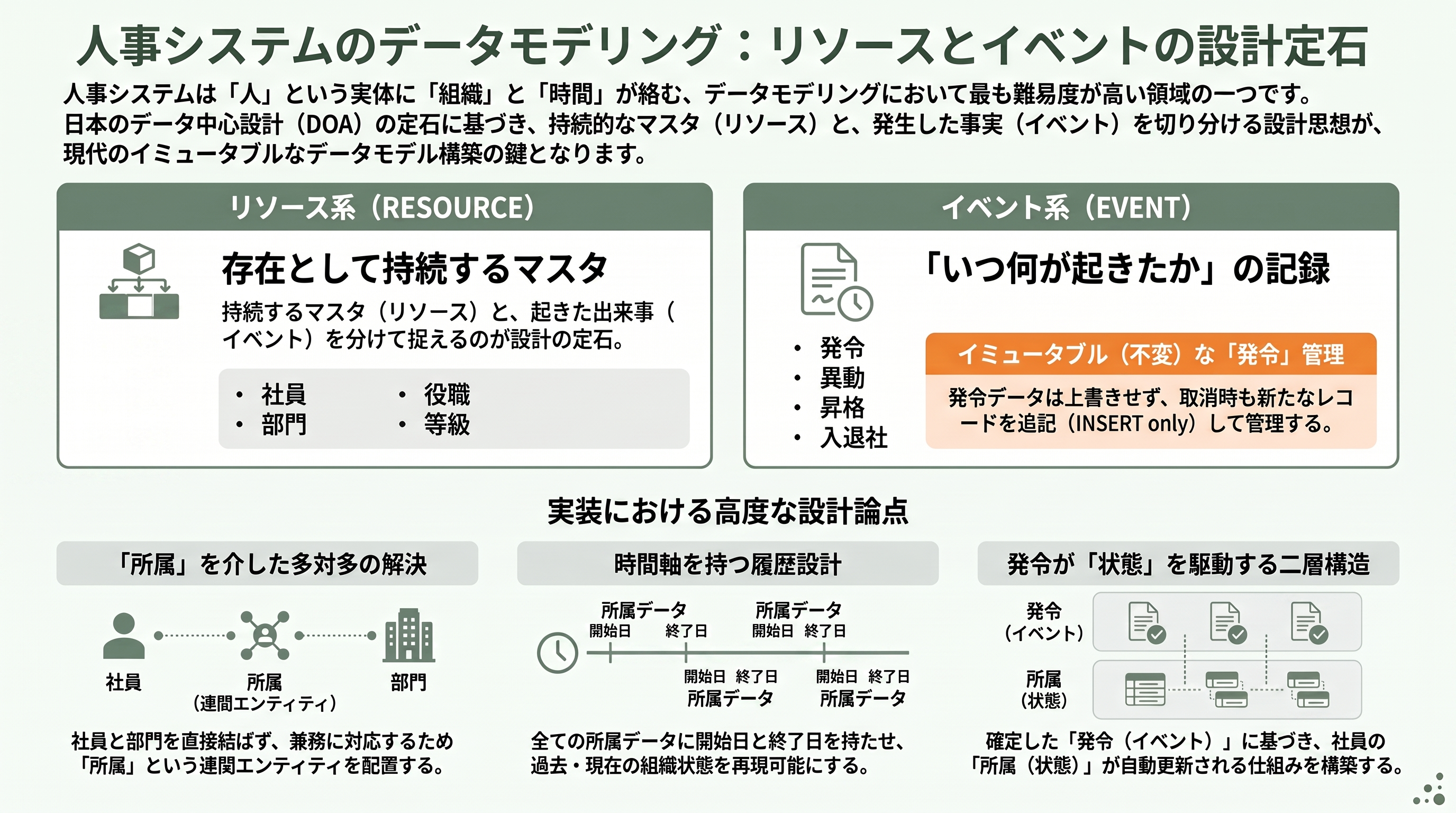
まず実体を、二つの性格に分けて捉えるのが日本のデータ中心設計(DOA)の伝統的な定石である。ひとつがリソース系、すなわちそれ自体が存在として持続するマスタ的な実体だ。社員、部門、役職、等級などがこれにあたる。もうひとつがイベント系、すなわち「いつ何が起きたか」という出来事を記録する実体で、人事における代表格が発令である。Zennやスライド共有サービスで活発に議論されている「イミュータブルデータモデル」も、まさにこのリソース/イベントの切り分けを出発点に置き、イベントは更新せず追記(INSERT only)で積む設計を推奨している。発令は起きてしまえば取り消されることはあっても書き換えられない——後から「あの異動は無かったことに」とレコードを上書きするのではなく、「取消」という新たな発令を積む。これがイベントを正しく扱う作法だ。
リソース系のマスタ設計にも罠がある。「社員」と「部門」を単純な1対多(社員は一つの部門に属する)で結んでしまうと、兼務に対応できず、組織改編の前後で過去の所属が再現できなくなる。第6章で見たとおり、社員と部門は本質的に多対多であり、間に「所属」という連関エンティティを置く必要がある。そしてこの所属は、ただの中間テーブルではなく、開始日と終了日という時間軸を持った履歴として設計しなければならない。
ここで国産の人事システムを覗くと、設計思想の厚みが見えてくる。Works Applicationsの「COMPANY 人事管理」は、雇用・異動・兼務・転籍・昇格・登用・出向・休職・退職・再雇用といった多様な発令業務を標準で扱い、発令申請を電子承認ワークフローで集め、発令にもとづいて辞令文や人事通達を自動生成する。さらに「玉突き異動案」、すなわち一人を動かすと玉突きで連鎖する後任配置までシステムで設計できると謳う。DreamArtsの「SmartDB」も、入退社・異動・組織改変を発令として管理し、確定したユーザーへ異動辞令を自動作成する連携を備える。これらの製品が共通して苦心しているのが、次章で述べる「発令というイベントが、所属という状態を駆動する」二層構造の正しい実装である。
発令と所属履歴の2層構造
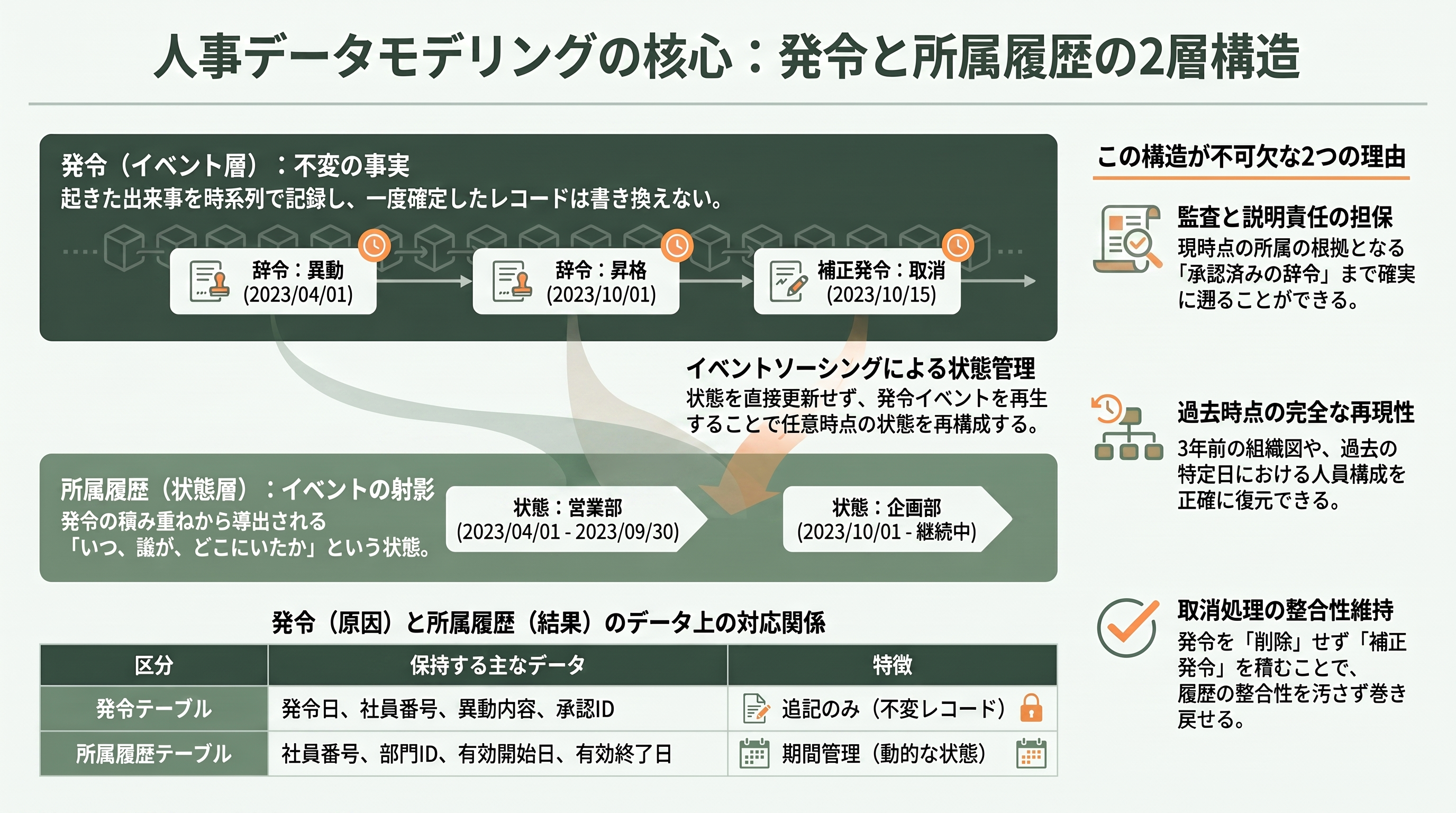
人事データモデリングの心臓部が、発令(イベント層)と所属履歴(状態層)の二層構造だ。この二つを混同すると、人事システムは必ず破綻する。逆に、この分離をきれいに設計できれば、人事の複雑さの大半は御せる。
発令は、起きた出来事そのものを記録するイベント層である。「2026年7月1日付で、社員番号10023の山田太郎を、営業第二部から経営企画部へ異動させる」——この一枚の辞令に対応する不変の事実が、発令レコードだ。発令は追記のみで、過去の発令は書き換えない。一方の所属履歴は、その発令の積み重ねが帰結としてもたらす「いつ、誰が、どの部門に所属していたか」という状態の時系列である。所属履歴は、発令というイベントから導出される射影(プロジェクション)にほかならない。ソフトウェア工学の言葉で言えば、これはイベントソーシングそのものだ。発令というイベントストリームを再生すると、任意時点の所属という状態が再構成できる。
なぜ状態を直接持たず、わざわざイベントから導くのか。第一に、監査と説明責任のためだ。「なぜこの人は今この部門にいるのか」を問われたとき、根拠となる発令(誰がいつ承認した、どの辞令か)まで遡れなければ、人事は説明責任を果たせない。第二に、時間を遡った再現のためだ。三年前の組織図を正確に復元する、過去の特定日付で在籍部門別の人員構成を集計する、といった要求に応えるには、状態の履歴が必要になる。Works Applicationsの製品が「過去に遡った帳票でも、その時点の所属・役職を再現できる」と訴求しているのは、まさにこの二層構造を実装しているからだ。
実装イメージを示そう。発令テーブルはイベントを追記で積み、所属履歴テーブルは期間(有効開始日・有効終了日)を持った状態として、発令の確定に連動して更新される。
-- イベント層:発令(追記のみ。過去行は書き換えない)
CREATE TABLE personnel_order (
order_id BIGINT PRIMARY KEY, -- 発令ID
employee_no BIGINT NOT NULL, -- 対象社員
order_type VARCHAR(20) NOT NULL, -- 異動/昇格/休職/取消…
to_department BIGINT, -- 異動先部門(異動時)
issue_date DATE NOT NULL, -- 発令日(辞令の日付)
effective_date DATE NOT NULL, -- 発効日(実際に効力が生じる日)
registered_at TIMESTAMP NOT NULL -- 登録日時(システムに入れた瞬間)
);
-- 状態層:所属履歴(発効日を境に期間で持つ)
CREATE TABLE department_assignment (
employee_no BIGINT NOT NULL,
department_no BIGINT NOT NULL,
valid_from DATE NOT NULL, -- この所属の有効開始(=発効日)
valid_to DATE, -- 有効終了(次の異動の前日/無期限はNULL)
source_order_id BIGINT NOT NULL, -- どの発令に由来するか
PRIMARY KEY (employee_no, valid_from)
);
異動の発令が確定すると、システムは一つのトランザクションの中で、既存の所属履歴行のvalid_toを発効日の前日で閉じ、新しい所属履歴行を発効日から開始する。発令が「取消」されれば、対応する所属履歴を巻き戻す補正発令が積まれる。状態を直接UPDATEで上書きするのではなく、あくまでイベントの帰結として状態を更新する——この規律が、人事システムの一貫性を支えている。
発令日・発令発効日・発令登録日が分かれる理由
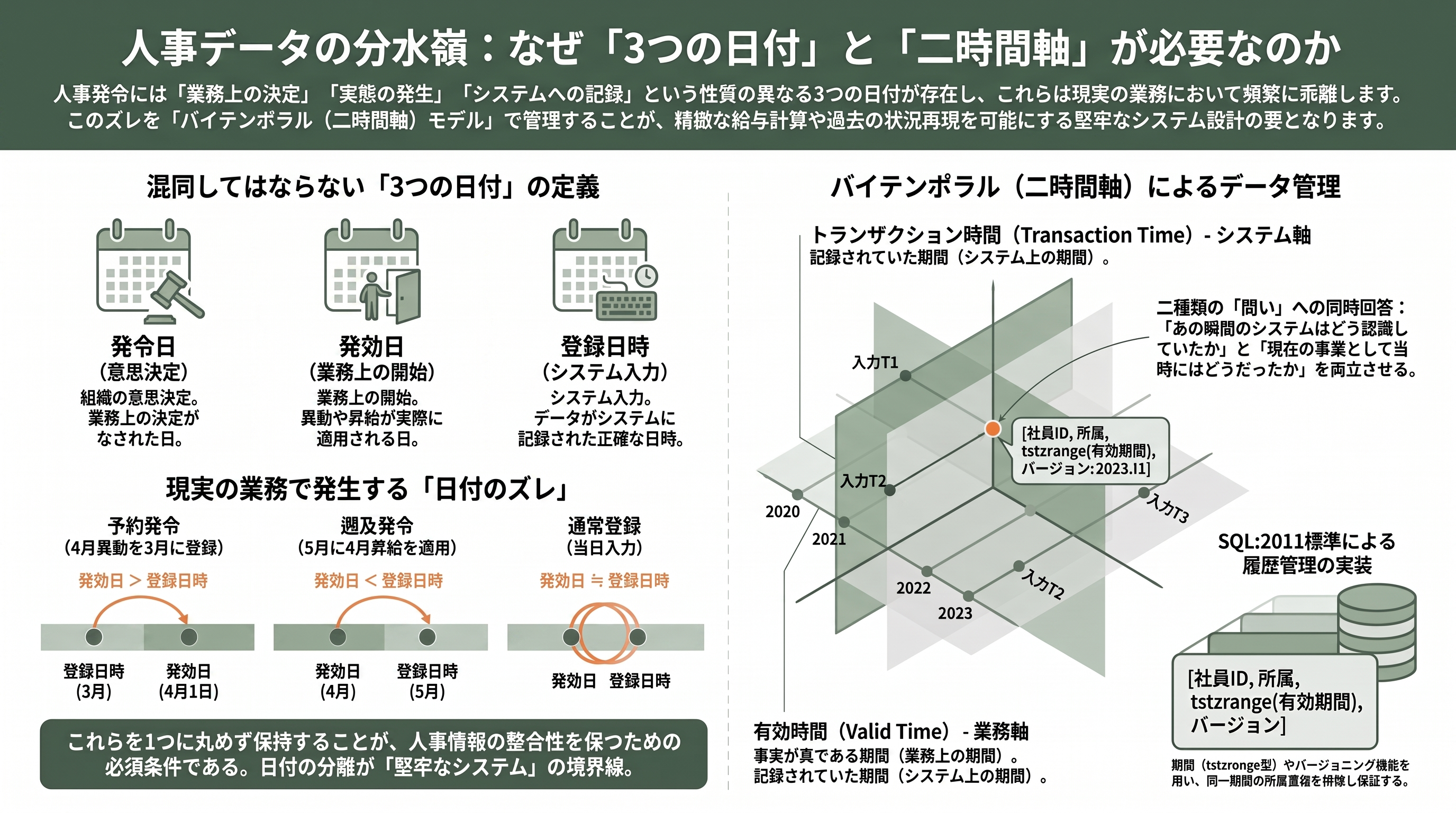
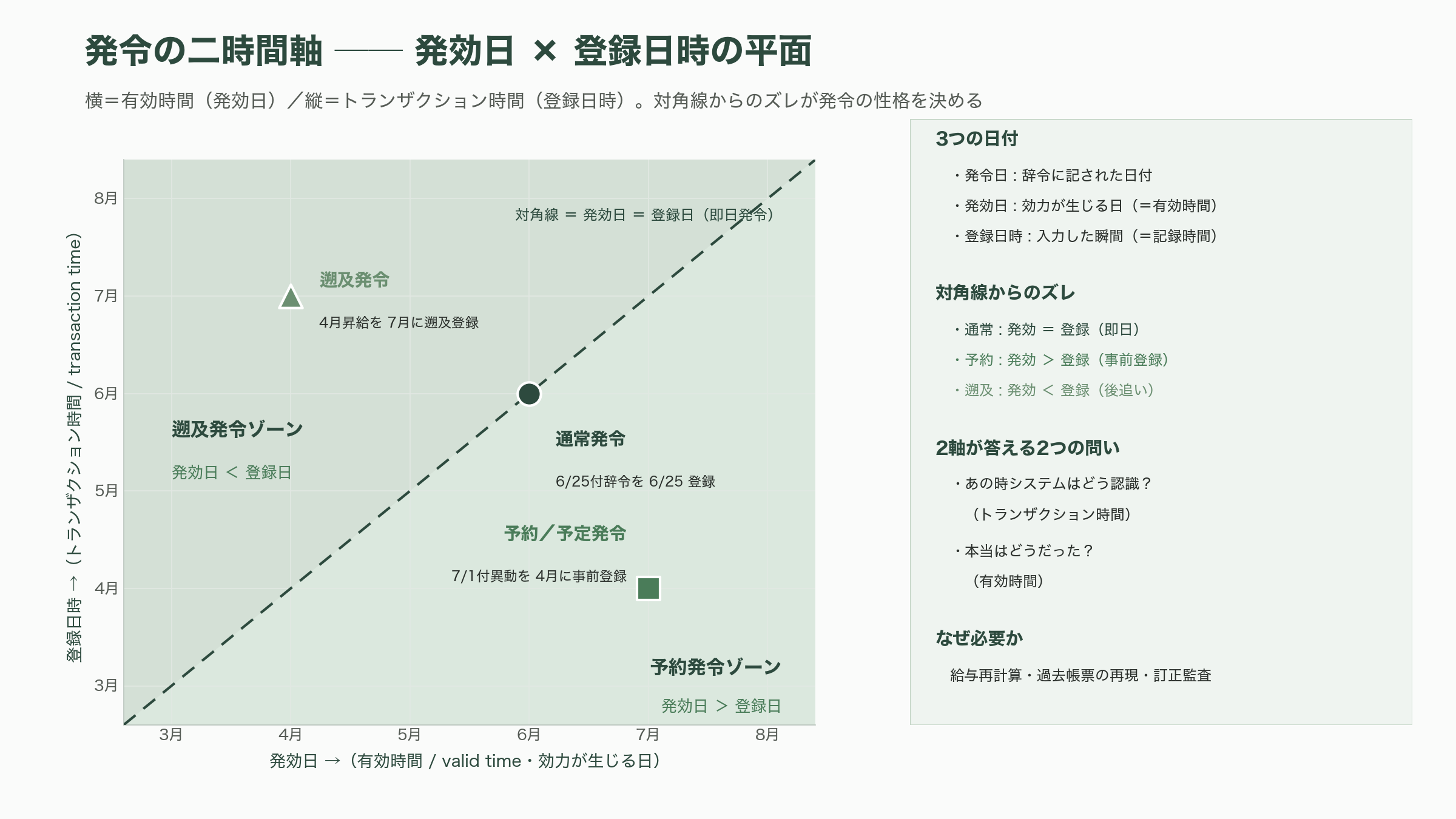
最後に、二層構造をさらに一段深く掘る。人事の発令には、よく見ると三つの異なる日付がまとわりつく。発令日、発令発効日(発効日)、そして発令登録日(登録日時)だ。初学者はこれらをひとつの「日付」に丸めてしまいがちだが、三つを分けて持つことこそ、堅牢な人事システムの分水嶺である。
発令日は、辞令という文書に記された日付だ。「2026年6月25日付辞令」のように、組織が正式に発令という意思決定を行った業務上の日付を指す。発効日は、その発令が実際に効力を生じる日、すなわち本人が実際に新しい部門で働き始める日だ。「7月1日付で異動」の7月1日がこれにあたる。そして登録日時は、その発令情報を人事担当者がシステムへ入力した瞬間のタイムスタンプである。
この三つがなぜ一致しないのか。現実の人事はほとんど常にズレるからだ。四月一日付の大規模異動は、三月のうちに辞令が発令され、システムにも事前登録される(発効日>登録日のケース、予約/予定発令)。逆に、承認が遅れて辞令が後追いになり、すでに過ぎた日付に遡って効力を持たせることもある(発効日<登録日のケース、遡及発令)。昇給を四月に遡って適用する、出向の開始を実態に合わせて先月付にする——人事ではこうした遡及がごく日常的に起きる。
ここで効いてくるのが、第7章で触れたバイテンポラル(二時間軸)モデルだ。データベース理論では、事実が現実世界で真であった期間を有効時間(valid time、業務時間)、その事実がシステムに記録されていた期間をトランザクション時間(transaction time、システム時間)と呼び分ける。発効日は有効時間の起点であり、登録日時はトランザクション時間の起点である。この二軸を分けて持つと、二種類のまったく異なる問いに同時に答えられるようになる。ひとつは「2026年6月25日に給与計算を回した“あの瞬間”、システムはこの社員をどの部門だと認識していたか」というトランザクション時間の問い。もうひとつは「いま分かっている事実として、2026年6月25日時点で彼は本当はどの部門だったのか」という有効時間の問いだ。遡及発令が一本入ると、この二つの答えは食い違う。給与の再計算、過去レポートの再現、訂正の監査——人事のもっとも厄介な要求は、すべてこの食い違いを正しく扱えるかにかかっている。
エンジニアコミュニティでも、この設計は活発に共有されている。たとえばPostgreSQLで人事のバイテンポラルモデルを実装する事例では、所属テーブルに業務上の有効期間(effective)とシステム記録期間(assertive)の二軸を持たせ、tstzrange型で[2024-04-01, infinity)のように期間を表現し、EXCLUDE USING gist制約で「同一社員・同一期間の所属が重複しない」ことをデータベース自身に保証させる手法が紹介されている。予約登録なら発効日を未来に置きつつ登録時点から記録を有効にし、遡及登録なら実際の異動日から業務期間を開始しつつ登録日から記録を有効にする。理論的には、第6正規形が説いた「属性ごとに独立した履歴」へ縮約する発想や、SQL:2011(ISO 9075:2011)が標準化したシステムバージョニング・テンポラルテーブルの機能が、この実装を下支えしている。IBM Db2をはじめ主要DBMSがこの標準に追随したことで、二軸の履歴管理はもはや特殊技ではなく、設計者が当然知っておくべき基礎教養になった。
こうして人事という一見地味な題材を掘り下げると、本稿が辿ってきた論点——実体とリレーション、正規化と非正規化、リソースとイベントの分離、そして時間の二軸——がすべて一点に収束することが分かる。FDEがAI時代の花形職種でありながら、なおコードではなくデータモデリングを必須スキルとして問われる理由も、ここにある。発令日と発効日と登録日を分けて持てるか。所属を状態ではなくイベントの射影として設計できるか。冗長に見える受注時単価が実は別の真実だと見抜けるか。これらは生成AIが現場を観察して勝手に決めてくれることではなく、顧客の現実に分け入り、業務の意味を写像する人間の判断である。データモデリングの基礎を徹底的に再考することは、AIがコードを書く時代に人間のエンジニアが立つべき場所を、もう一度確かめる作業にほかならない。