まず全体像 — 「多数のAIを束ねて1つのAPIとして使う」とは何か
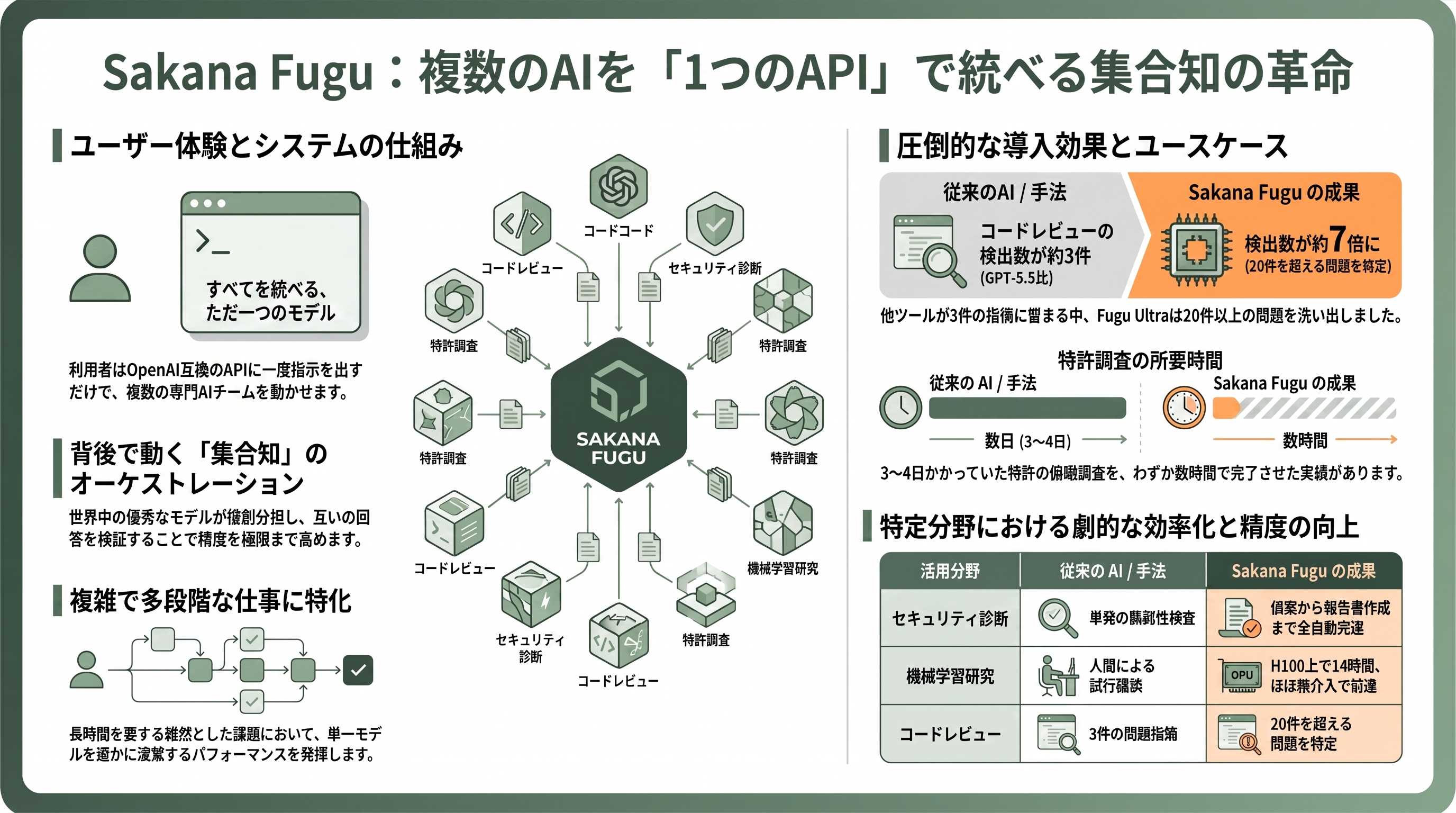
新しいサービスを理解する一番の近道は、利用者が実際に何を体験するのかを具体的に思い描くことだ。Sakana Fuguの場合、開発者の体験は拍子抜けするほど単純である。OpenAI互換のAPIに対して、いつものように「このコードをレビューして」「この論文を再現して」といった指示を一度投げるだけ。返ってくるのは1つの回答で、利用者から見ればChatGPTやClaudeに話しかけるのと何ら変わらない。ところがその回答が生成されるまでの裏側では、世界中の優秀なAIモデルが何体も呼び出され、役割を分担し、互いの答えを検証し合っている。Sakana AIが掲げるキャッチコピー「One Model to Command Them All(すべてを統べる、ただ一つのモデル)」は、この体験を端的に言い表している。利用者は複数のAIを使い分ける手間から解放され、単一モデルを叩くのと同じ手軽さで「集合知」にアクセスできる、という設計思想だ。
具体例で考えると分かりやすい。あるソフトウェアエンジニアはコードレビューにFugu Ultraを使い、「他のツールが3件ほどの問題しか指摘しないところで、Fuguは20件を超える問題を洗い出した。今ではすべてのレビューをこれに通している」と公式サイトの利用者証言で語っている(GPT-5.5との比較)。別のセキュリティ技術者は、たった一つの指示を与えただけで「偵察からXSS/SQLインジェクションの検査、認証レビュー、そして証拠と再検証手順を添えた報告書の作成まで、診断を最後までやり切った。しかも検査範囲を逸脱せず、破壊的な操作も避けた」と述べる。さらにある研究者は、Fuguをほぼ全自動の研究モードで走らせ、1台のNVIDIA H100上で約14時間にわたり機械学習研究を人間の介入ほぼなしで前進させたという。3〜4日かかっていた特許の俯瞰調査が数時間で終わった、という例も公式に紹介されている。
これらに共通するのは、「単一のAIへの一回の問い合わせでは解きにくい、長くて面倒で多段階の仕事」である。Sakana AI自身、マルチエージェント・オーケストレーションが最も効くのは「課題が雑然としていて、長時間を要し、単一モデルの一回の呼び出しでは難しいとき」だと位置づけている。逆に言えば、短い雑談や単発の質問にはオーバースペックであり、そこは後述する軽量版の役割になる。まずはこの「1つのAPIの裏に専門家チームが控えている」というイメージを掴んでおけば、以降の各論はすべてその延長線上に理解できる。
Sakana AIとは — Transformer共著者が東京で築く「集合知」の会社
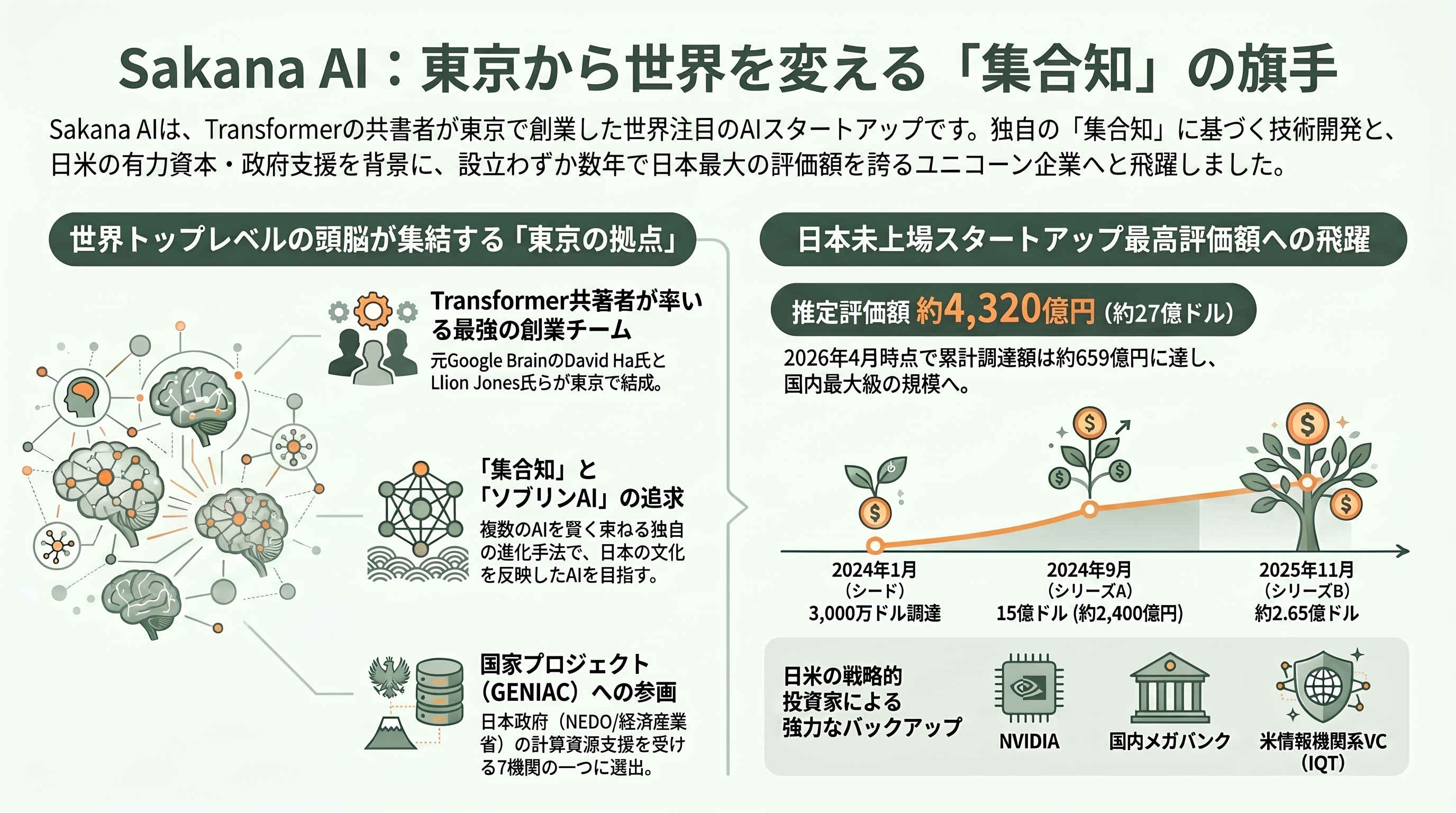
Sakana AIは2023年7月設立、東京・麻布台ヒルズに本拠を置くAI研究スタートアップである。共同創業者は3人。CEOのDavid Ha(デイビッド・ハ)は元Google Brainの研究者で、Google Brain Tokyoを率いた後、画像生成のStability AIで研究責任者を務めた人物だ。CTOのLlion Jones(リオン・ジョーンズ)は、現代の生成AIすべての土台となった2017年の論文「Attention Is All You Need」の共著者8人の一人で、2023年8月にGoogleを離れて創業に加わった。会長のRen Ito(伊藤錬)が経営を支える。Transformerの生みの親の一人が、米国の巨大ラボではなく東京で次の一手を打っている――この一点だけでも、Sakana AIが世界のAI地図上で特異な座標にいることが分かる。
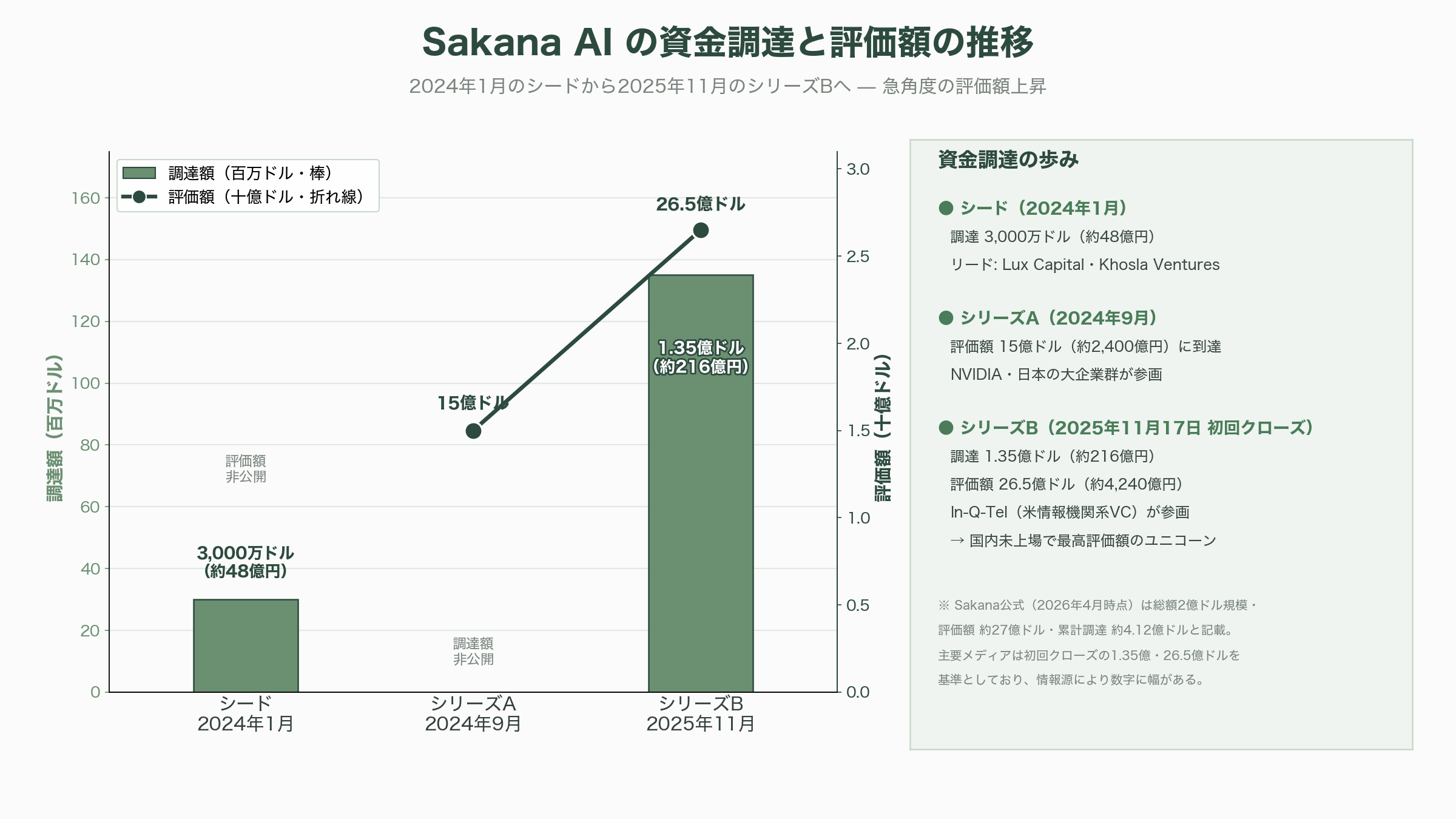
同社の資金調達の歩みは急角度だ。2024年1月にLux CapitalとKhosla Venturesが主導するシードで3,000万ドル(約48億円)を調達すると、同年9月のシリーズAではNEA・Khosla・Luxを筆頭にNVIDIAや日本の大企業群が参画し、評価額15億ドル(約2,400億円)に到達した。2025年11月17日に公表されたシリーズBの初回クローズでは1.35億ドル(約216億円)を調達し、評価額は約26.5億ドル(約4,240億円)――日本の未上場スタートアップとして最高評価額の「ユニコーン」となった。Sakana AIの公式サイトはその後(2026年4月9日更新時点で)このラウンドを総額2億ドル規模・評価額約27億ドル(約4,320億円)・累計調達約4.12億ドル(約659億円)へと上積みされたものとして記載しているが、主要メディアの報道は依然として初回クローズの1.35億ドル・26.5億ドルを基準に伝えており、ここは情報源によって数字に幅がある。シリーズBで目を引くのは、米国の情報機関系ベンチャーキャピタルIn-Q-Tel(IQT)が名を連ねた点だ。MUFG・SMBC・みずほ・KDDI・伊藤忠・野村といった日本の金融・事業会社が初期から厚く支える「日の丸」色の濃い株主構成に、米国の安全保障コミュニティが接続した格好になる。
技術面でも、Sakana AIはFuguに至るまでの一貫した系譜を持つ。2024年3月の「Evolutionary Model Merge(進化的モデルマージ)」は、進化的アルゴリズムで既存の公開モデルを自動的に「掛け合わせ」て新しい強いモデルを作る研究で、Nature Machine Intelligenceに掲載された。仮説立案から実験、論文執筆までを自律的にこなす「The AI Scientist」、推論時に重みを自己調整する「Transformer²」、自らのコードを書き換えて進化する「Darwin Gödel Machine」と続く。そしてFuguの直接の技術的祖先と言えるのが、2025年7月公表の「AB-MCTS(Adaptive Branching Monte Carlo Tree Search)」だ。これは推論時に複数のフロンティアモデルを協調させ、「同じ方針を深掘りするか(深さ)」「別の方針を試すか(幅)」を適応的に選ぶ手法で、Gemini 2.5 Proやo4-mini、DeepSeek-R1を組み合わせてARC-AGI-2で単体モデルを上回る成績を出した。複数のAIを賢く束ねれば単体を超えられる――この発想を製品化した到達点がFuguなのである。Sakana AIが日本政府(NEDO/経済産業省のGENIACプログラム)の計算資源支援に選ばれた7機関の一つであったことも、同社が「国家の文化や価値観を反映するソブリンAI」を掲げる文脈とつながっている。
マルチエージェントシステムとは — 「指揮者」が専門家を束ねる仕組み
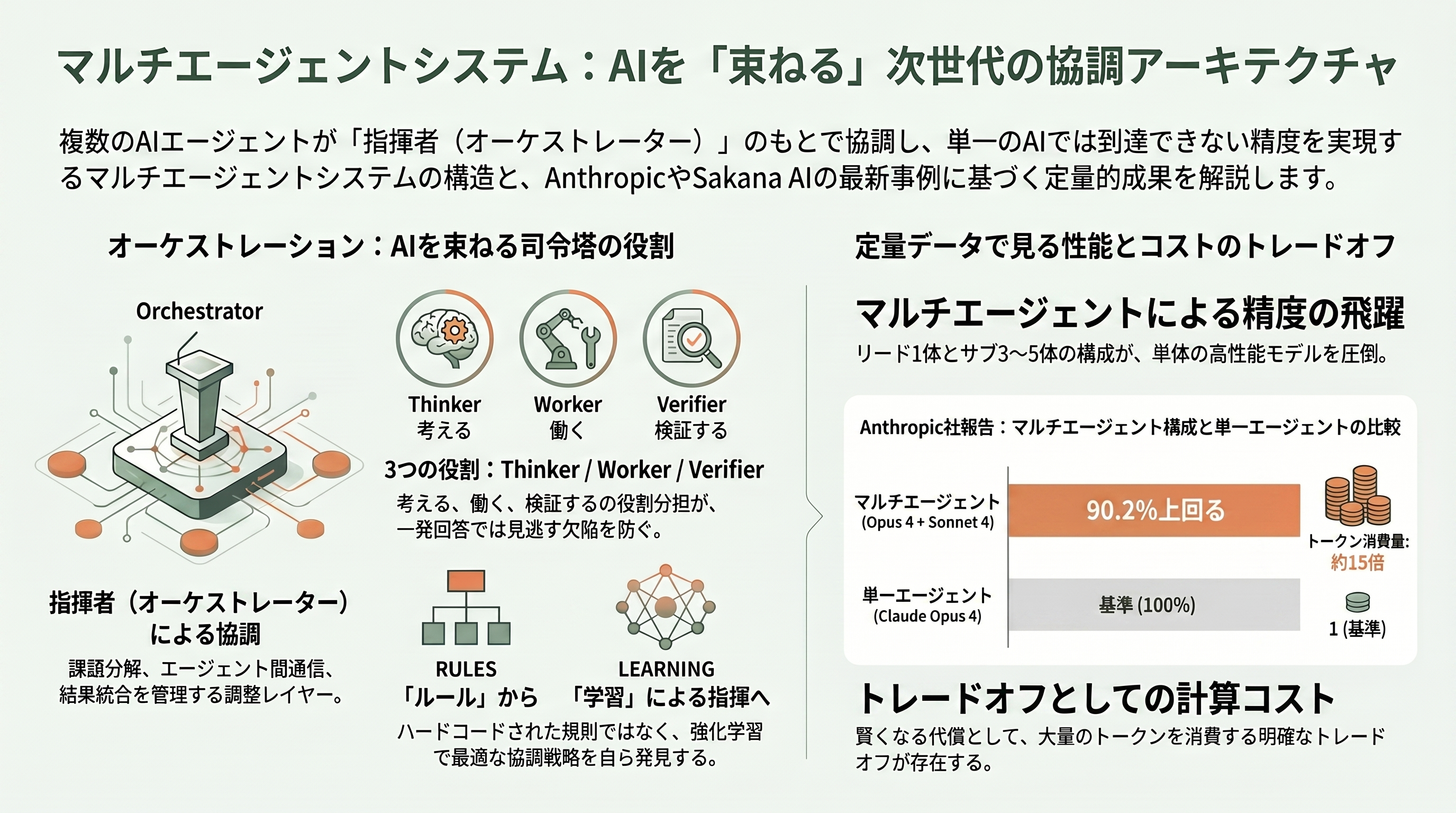
ここで「マルチエージェントシステム」という言葉そのものを整理しておきたい。現代のLLM文脈でこれは、役割・プロンプト・モデル・道具立てがそれぞれ異なる2体以上のAIエージェントが協調し、単一のエージェントが一人でやるよりも速く・正確に課題を解くアーキテクチャを指す。そしてそれらを束ねる司令塔の働きが「オーケストレーション(orchestration、指揮)」だ。課題の分解、エージェント間の通信、状態管理、結果の統合――この調整レイヤーがオーケストレーションの本体である。
最も普及している実装パターンは「オーケストレーター・ワーカー型(supervisor型、ハブ&スポーク型とも)」である。リード役が課題を小分けにして専門ワーカーへ配り、戻ってきた結果を束ねる。ワーカー同士は直接話さず、調整はすべて指揮者を経由する。Sakana AIのTRINITY論文が使う「Thinker(考える)/Worker(働く)/Verifier(検証する)」という役割分担は、まさにこの系統だ。とりわけVerifier(検証役)の存在は重要で、先のコードレビューで「3件対20件」という差が生まれた一因は、単一モデルの一発回答では見逃される欠陥を、独立した検証エージェントが拾い直すからだと理解できる。
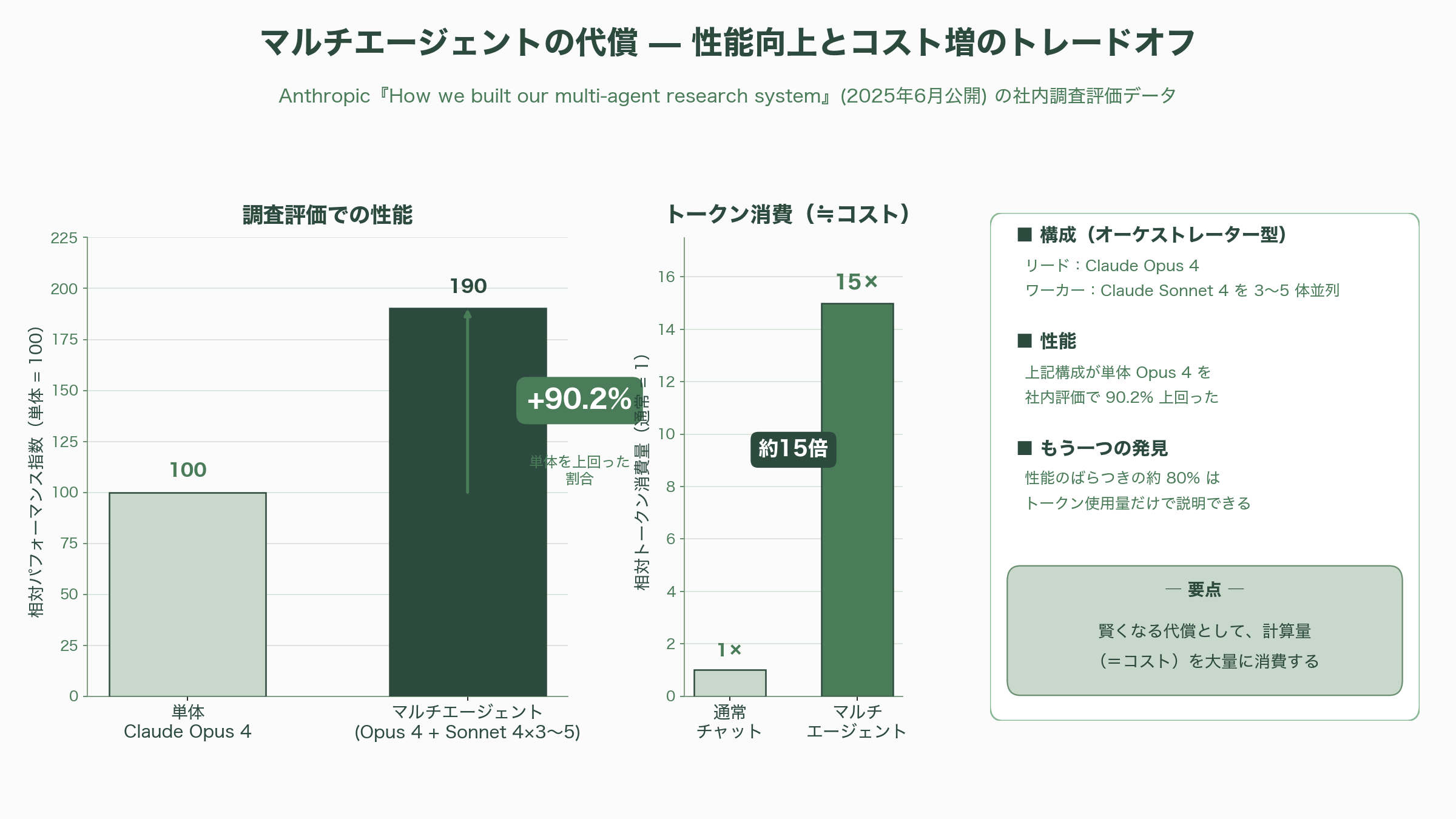
この「束ねると本当に強くなるのか」という問いには、実は業界最大手の定量データがある。Anthropicは2025年6月に公開したエンジニアリング記事「How we built our multi-agent research system」で、リードエージェント(Claude Opus 4)が複数のサブエージェント(Claude Sonnet 4)を3〜5体並列で起動するオーケストレーター・ワーカー構成が、単体のOpus 4を社内の調査評価で90.2%上回ったと報告している。同時に、マルチエージェント構成は通常のチャットの約15倍ものトークンを消費し、性能のばらつきの約80%はトークン使用量だけで説明できるとも明かしている。つまり「賢くなる代わりに、計算量(=コスト)を大量に食う」という、後述するFuguの死角にも直結するトレードオフが、ここで数字として裏付けられているわけだ。
Sakana FuguはこのオーケストレーションをICLR 2026採択の2本の論文の上に構築したと説明している。一つは「TRINITY: An Evolved LLM Coordinator」(arXiv:2512.04695)で、進化的に獲得した軽量な調整役が複数のLLMにThinker/Worker/Verifierの役割を割り当てる。もう一つは「The Conductor」(arXiv:2512.04388)で、強化学習によって自然言語での協調戦略を自ら発見する――ハードコードされたルールではなく、どう連携すれば良いかをモデル自身が学ぶ点が肝だ。Fugu自身が「エージェントプールの中の様々なLLMを、必要なら自分自身の複製も含めて再帰的に呼び出すよう訓練された言語モデル」であり、モデル選択・委任・検証・統合をすべて内部で管理する。この「ルールで振り分ける」のではなく「学習した指揮者がチームを編成する」という違いこそが、Fuguを単なるモデルルーターから分かつ核心だと、Sakana AIは主張している。
FuguとFugu Ultraの中身 — 2つのモデル、ベンチマーク、価格

製品は2つの変種で提供される。無印のFuguは性能と低レイテンシのバランスを取ったモデルで、日常のコーディングやコードレビュー、チャットボットなど応答性が要る用途の「既定値」として位置づけられる。上位のFugu Ultraは、より深い専門エージェント群を編成して回答の質を最大化するモデルで、Kaggleコンペ、論文の再現、サイバーセキュリティ診断、文献・特許調査といった重い多段階タスク向けだ。なお一部メディアは指揮役を約70億パラメータの小型モデルと報じているが、この数字はSakana AIの公式ページには明記されておらず、確証はない。
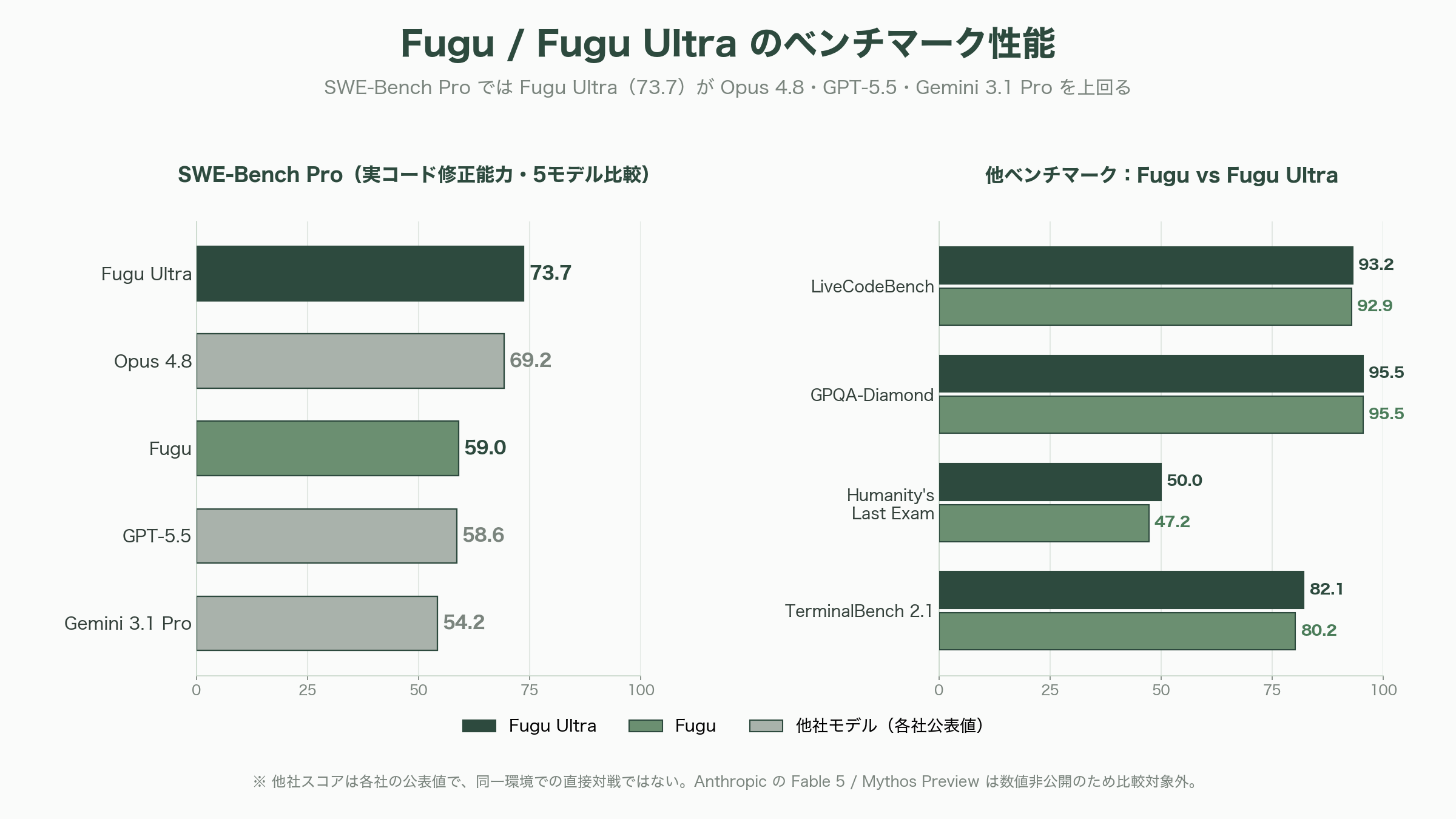
ベンチマークでは、Sakana AIの公式比較表が強気の数字を並べる。実コードの修正能力を測るSWE-Bench ProでFuguとFugu Ultraがそれぞれ59.0/73.7。Fugu Ultraの73.7という値は、同表に並ぶOpus 4.8の69.2、GPT-5.5の58.6、Gemini 3.1 Proの54.2を上回る。汚染耐性のあるコーディング評価LiveCodeBenchは92.9/93.2、大学院レベルの理科の難問を問うGPQA-Diamondは両者とも95.5、人類最難関の学術試験Humanity's Last Examは47.2/50.0、ターミナル操作のTerminalBench 2.1は80.2/82.1といった具合だ。総じてFugu Ultraは、Opus 4.8・GPT-5.5・Gemini 3.1 Proという公開フロンティアモデルを多くの項目で上回る、というのが同社の自己申告である。
ただしここには二つの留保が要る。第一に、これらの比較表の対戦相手のスコアは各モデル提供元の公表値であって、同一環境での直接対戦の結果ではない。第二に、Sakana AIが「肩を並べる(shoulder-to-shoulder)」と表現するAnthropicのFable 5とMythos Previewには、そもそも表に数値の列が与えられていない――この2モデルは公開停止中でFuguのエージェントプールにもFugu自身の比較対象としても数値が示せないため、パリティ(同等)主張はあくまで定性的なものにとどまる。実際、暗号メディアのCrypto Briefingは、Fable 5がSWE-Bench Proで80.0を記録しFugu Ultraの73.7を上回るとする数字を伝えており(単一ソース)、もし規制対象モデルを土俵に乗せれば序列は変わり得ることを示唆している。
価格は二本立てだ。月額サブスクリプションはStandardが20ドル(約3,200円)、Proが100ドル(約1万6,000円、Standardの10倍の利用枠)、Maxが200ドル(約3万2,000円、20倍)で、いずれもFuguとFugu Ultraの両方を含む。2026年7月31日までに加入すると2か月目が無料になる導入キャンペーンも用意された。従量課金(API)ではFugu Ultraが入力100万トークンあたり5ドル(約800円)、出力30ドル(約4,800円)、キャッシュ入力0.50ドル(約80円)で、272Kトークンを超える長文脈では入力10ドル(約1,600円)・出力45ドル(約7,200円)に上がる。無印Fuguには固定の単価が設定されておらず、その時に呼び出された下位モデルの標準レートで、エージェントを跨いだ課金の積み増しなしに請求される設計だという。提供形態はconsole.sakana.aiのOpenAI互換APIで世界中から使えるが、GDPRなどEU規制への対応を進めている最中のため、EU/EEA域内では現時点で提供されていない。
なぜ「今」なのか — 6月12日の輸出規制が空けた穴
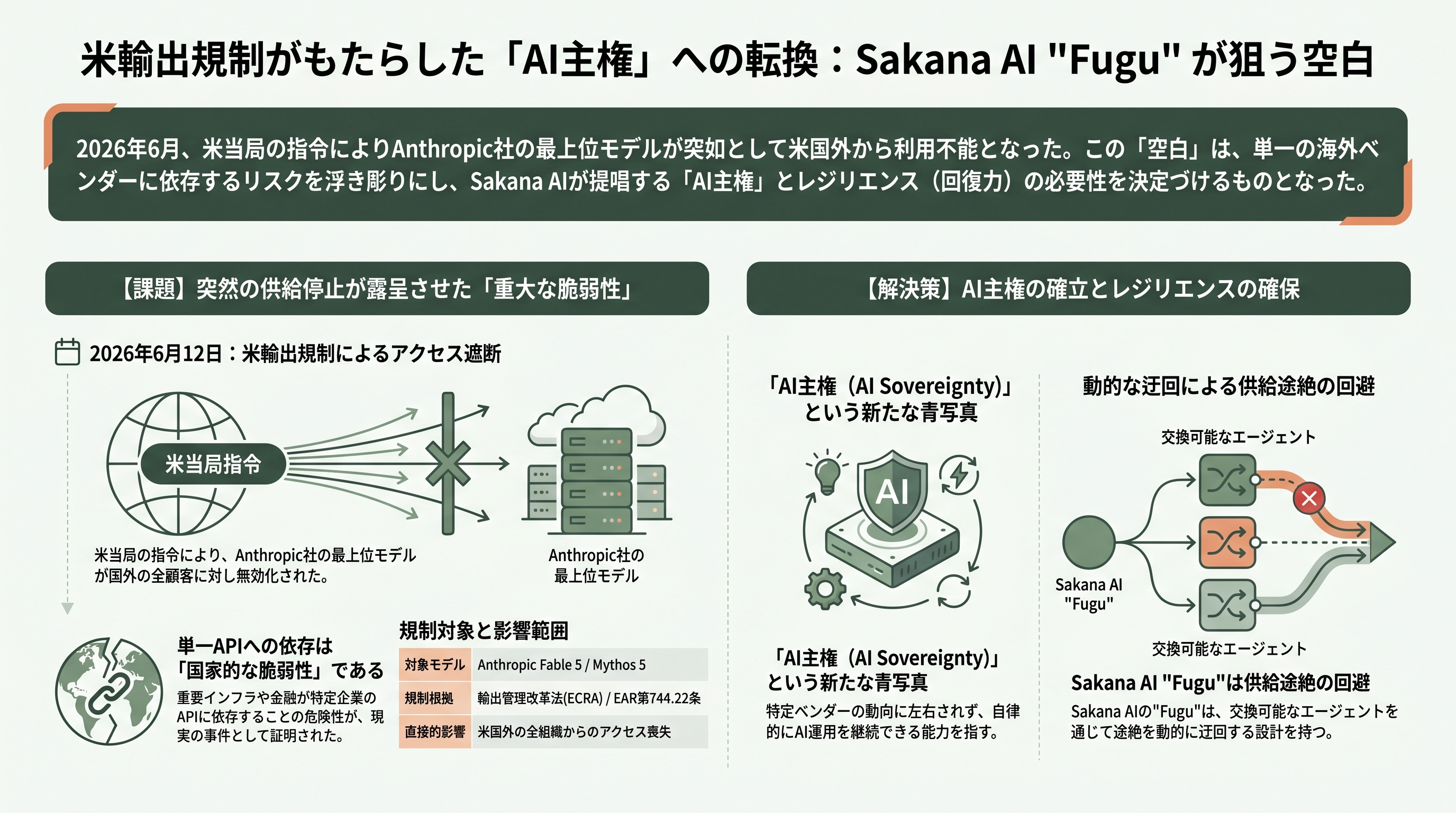
Fuguのリリース時期は偶然ではない。2026年6月12日(米東部時間午後5時21分)、米商務省の産業安全保障局(BIS)はAnthropicに対し、フロンティアモデルのFable 5とMythos 5への「あらゆる外国籍者(米国内外を問わず、同社の外国籍従業員を含む)」のアクセスを停止せよとする輸出管理上の指令を出した。利用者の国籍を確実に選別できなかったAnthropicは、両モデルを全顧客向けに丸ごと無効化する対応を取り、6月13日に公表した。Fortune、Nextgov、Al Jazeera、CSIS、Tech Policy Pressなど複数の報道とAnthropic自身の声明が一致して伝えており、Anthropicは「国家安全保障の権限を理由に、Fable 5とMythos 5へのあらゆる外国籍者のアクセスを停止する輸出管理指令を受けた」「これは誤解だと考えており、一刻も早くアクセスを復旧すべく取り組んでいる」と表明した。法的根拠は公式には明らかにされていないが、CSISは輸出管理改革法(ECRA)とEAR第744.22条(軍事インテリジェンス用途)の組み合わせとみており、Lawfareも「おそらくこれらに依拠している」と慎重に表現している。発端は第三者がMythos 5の安全機構を「脱獄(jailbreak)」できると主張したことだとされるが、Anthropicは「同種の能力はGPT-5.5を含む他の実用モデルからも広く入手可能だ」と反論している。
ここで言葉の整理をしておくと、Sakana AIがFugu Ultraの比較対象として挙げる「Mythos Preview」は、より早い段階の限定公開プレビューであり、6月12日の指令で名指しされた「Mythos 5」とは同じMythos系列の別の段階にあたる。いずれにせよ、世界最高峰とされたAnthropicの最上位モデル群が、ある金曜の夕方を境に米国外のほとんどの組織から忽然と消えた、という事実が要点だ。
この空白こそ、Fuguの売り口上の核心である。Sakana AIは公式リリースで「組織や国家にとって、重要インフラ・金融・統治を単一企業のAPIに依存することは重大な脆弱性(material vulnerability)である」と述べ(この一文は同社の声明として記載され、特定個人の発言としては帰属されていない)、ある提供元がアクセスを断ってもFuguは「交換可能なエージェントによって、その途絶を動的に迂回する」と謳う。同社はこれを「AI主権(sovereignty)のための現実的でレジリエントな青写真」と位置づけ、輸出規制という生々しい事件を、ベンダーロックインの危険性を示す格好の論拠へと転化させた。「Fable 5がなくても問題ない(No Claude Fable 5? No problem)」というVentureBeatの見出しは、この物語を端的に捉えている。
どんな用途に向くか — コードレビューからセキュリティ診断、自動研究まで
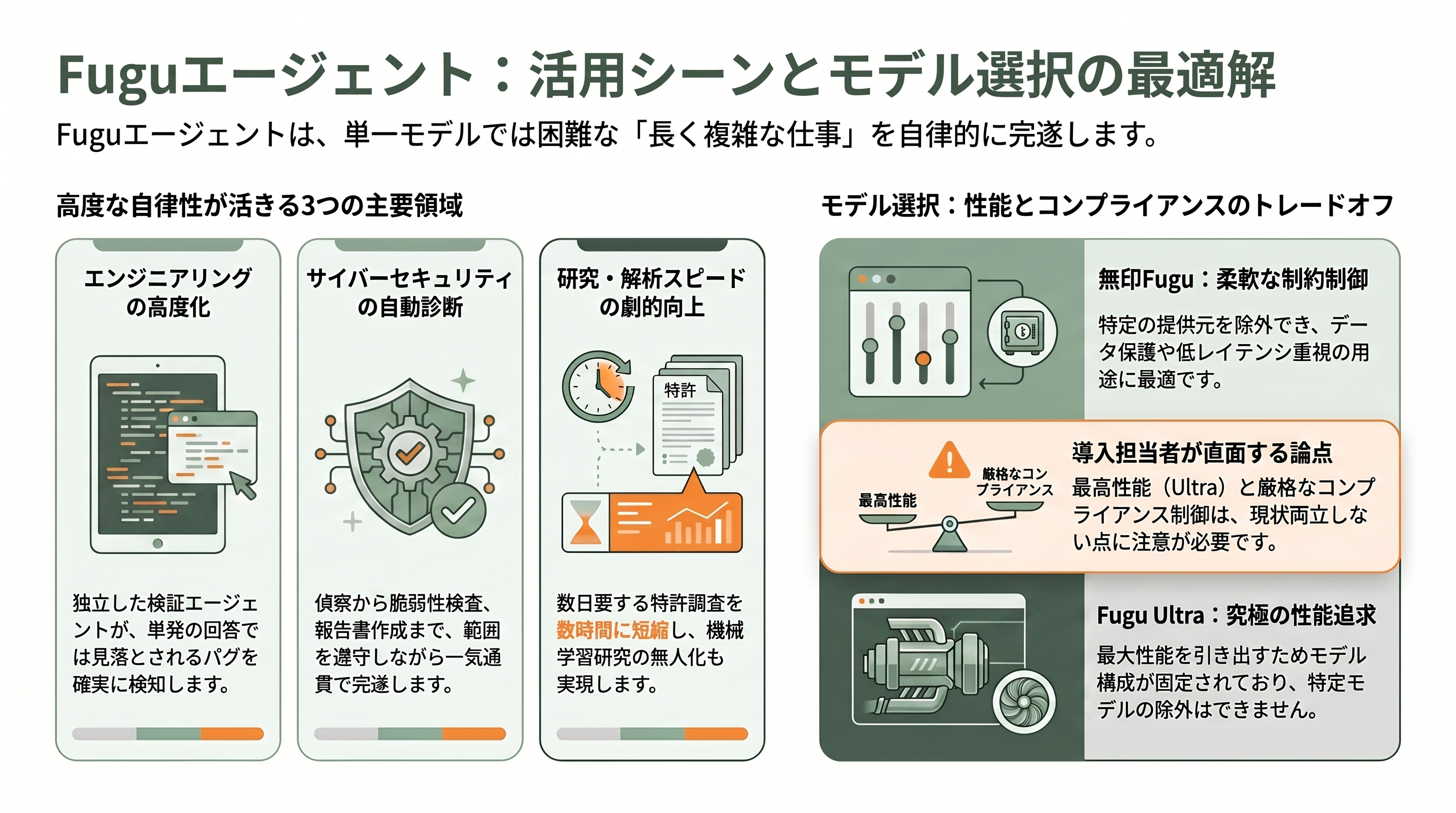
適したユースケースは、これまで挙げた具体例が示す通り「単一モデルでは荷が重い、長く複雑な仕事」に集中する。コーディングとコードレビューはその筆頭だ。検証エージェントが独立して欠陥を洗い直すため、前述の「3件対20件」のように、単発の回答では見落とされるバグを拾い上げやすい。サイバーセキュリティ診断では、一つの指示から偵察・脆弱性検査・認証レビュー・報告書作成までを範囲を守りながら完遂した実例がある。科学研究の領域では、論文の再現やKaggleコンペに加え、H100一台で約14時間、ほぼ無人で機械学習研究を進める「AutoResearch」的な使い方が紹介され、数日かかる特許調査を並列エージェントで数時間に短縮した例もある。ルービックキューブを19手で解く、機械設計、日本語の手書き解析、一手詰めならぬ一発指しのチェス、金融時系列予測といった多彩なタスクがベンチマーク対象として並ぶのも、汎用オーケストレーションの幅広さを示す狙いだろう。
企業利用で見逃せないのが、データ保護・プライバシー・コンプライアンス要件に応じて、特定の提供元やモデルをプールから除外できる機能だ。たとえば「この提供元のモデルには社内データを渡さない」といった制御がコンソールから設定できる。ただし重要な注意点として、この除外機能が効くのは無印Fuguだけで、Fugu Ultraは「最大性能を出すために全エージェントプールに依存するため、そのプールは固定」とされる。つまりデータ所在地やコンプライアンスのために特定モデルを外したい組織は、同時に最高性能のUltraを使うことが現状できない――この「コンプライアンス制御」と「最高性能」が両立しないトレードオフは、規制産業の導入担当者が真っ先に直面する論点になる。一方、無印Fuguはチャットボットや対話型サービスのような低レイテンシ用途の定番として位置づけられており、重いUltraと軽いFuguを使い分ける二層構造が製品設計の骨格になっている。
オーケストレーション競争 — ルーターから「学習する指揮者」へ
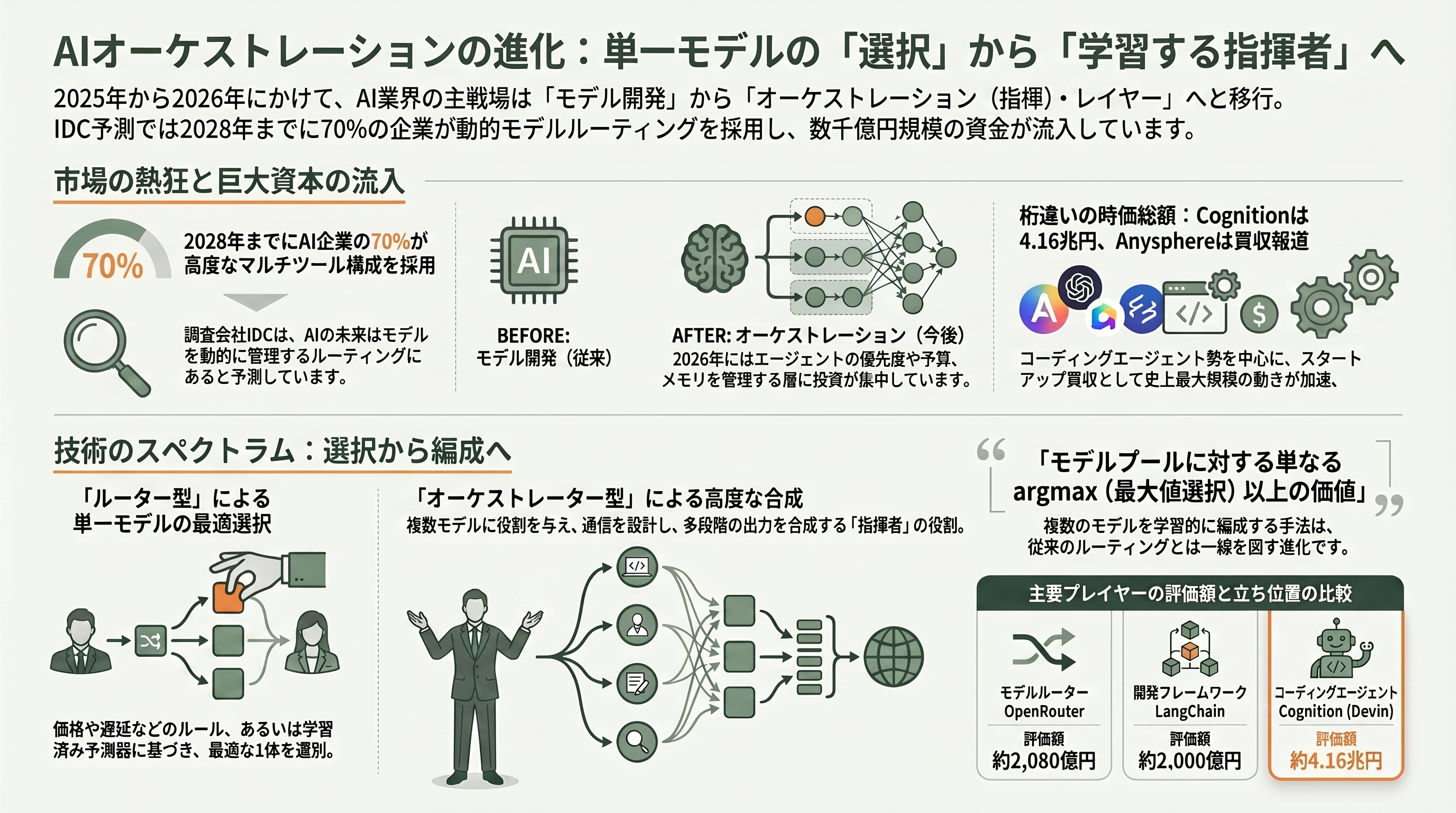
シリコンバレーの技術者の視点で見ると、Fuguは「オーケストレーション(指揮)・レイヤーを製品にする」という2025〜2026年の大きな潮流の最前線に立つ。モデルが乱立しコモディティ化するほど、価値は「どのモデルを使うか」から「すべてのモデルをいかに賢く束ねるか」へ移る、という考え方だ。調査会社IDCは「AIの未来はモデルルーティングにある」とし、2028年までに先進的なAI企業の70%が、モデルルーティングを動的に管理する高度なマルチツール構成を採用すると予測する。Theory VenturesのTomasz Tunguzも、2026年の投資機会として「エージェント・オーケストレーション・レイヤー(ルーティング、優先度、予算、メモリ、評価、承認)」を名指ししている。
この層には既に多くのプレイヤーがいる。最もFuguに近い「多数のモデルの前に立つ単一API」系では、400以上のモデルを束ねるOpenRouterが2026年5月にCapitalG(Alphabet系)主導で1.13億ドル(約181億円)を調達し評価額約13億ドル(約2,080億円)に達した。学習済みのルーターで「どのモデルが最適か」を予測するMartian(2024年9月にNEA主導で900万ドル=約14億円)やNot Diamond、EU志向のゲートウェイRequesty、オープンソースのLiteLLMなどが続く。エージェント開発フレームワークの側では、LangGraphを擁するLangChainが2025年10月にIVP主導で1.25億ドル(約200億円)を調達し評価額12.5億ドル(約2,000億円)、役割演技型のクルーを組むCrewAIが累計1,800万ドル(約29億円)を集めている。巨大プラットフォーマーも、MicrosoftがAutoGenとSemantic Kernelを統合した「Microsoft Agent Framework」を2026年4月にGAし、OpenAIはSwarmを実用版の「Agents SDK」に進化させ、Googleはエージェント間連携プロトコルA2Aを1年前(2025年6月23日)にLinux Foundationへ寄贈している。
自律的にコードを書き、内部でモデルを使い分けるコーディングエージェント勢の資金力はさらに桁違いだ。Devinを擁するCognitionは2026年5月に10億ドル(約1,600億円)を調達し評価額260億ドル(約4.16兆円)に達した。これは2025年9月の102億ドル=約1.6兆円からの急騰である。エディタCursorを開発するAnysphereに至っては、2026年6月16日にSpaceXが600億ドル(約9.6兆円)の全株式交換で買収すると報じられ、ベンチャー発スタートアップの買収として史上最大規模となった。Khoslaが主導したFactoryは2026年4月に評価額15億ドル(約2,400億円)へ。一方で独自モデルを掲げたPoolsideは120〜140億ドル(約1.9兆〜2.2兆円)規模とされたシリーズCが2026年4月に頓挫し、確認できる直近の評価額は2024年10月の約30億ドル(約4,800億円)にとどまる――オーケストレーション周辺の熱狂と淘汰が同時進行していることを示す好例だ。
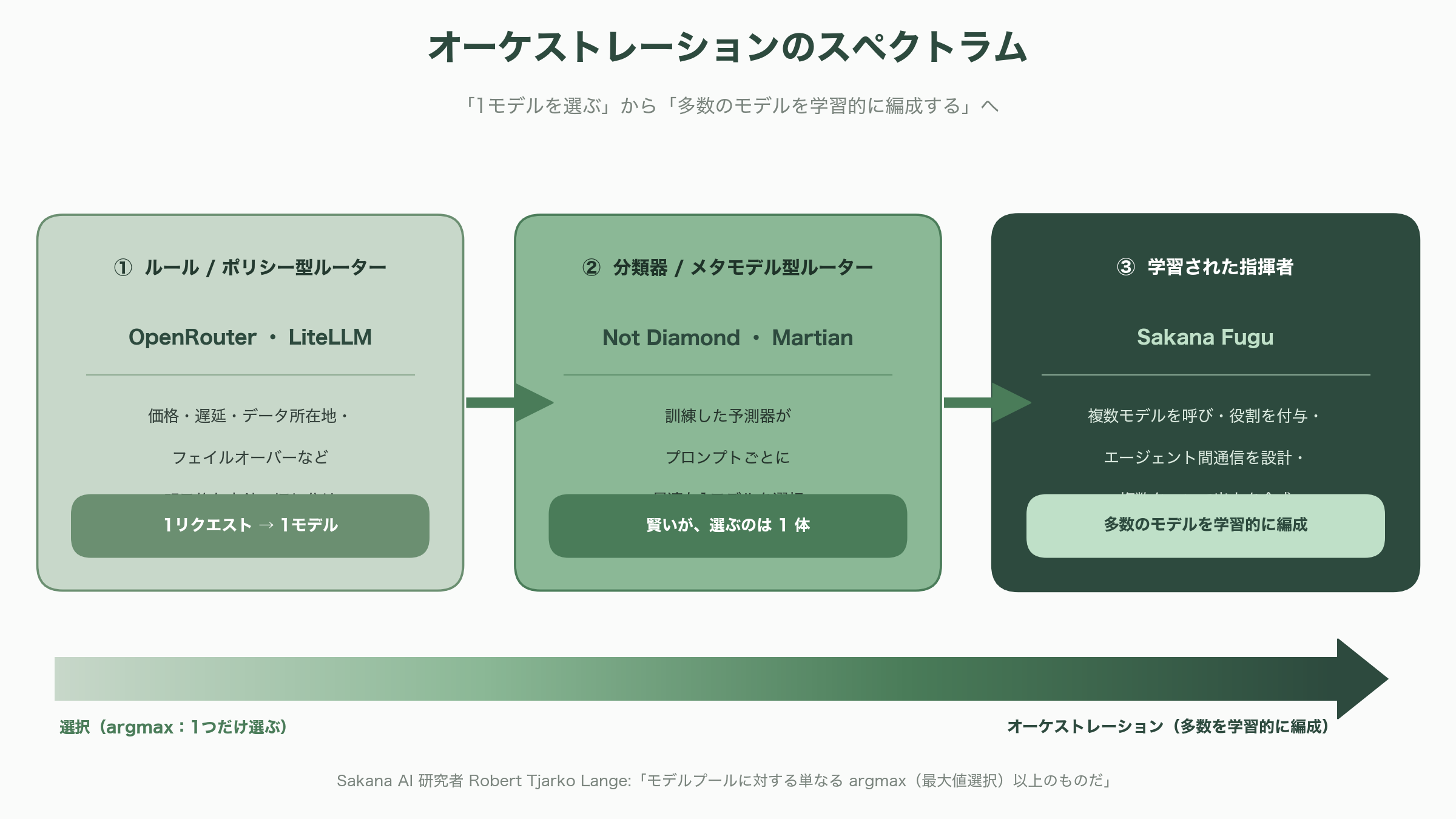
この地図の中でFuguはどこに座るのか。技術者の目で整理すると、束ね方には明確なスペクトラムがある。OpenRouterやLiteLLMのような「ルール/ポリシー型ルーター」は、価格・遅延・データ所在地・フェイルオーバーといった明示的な方針で1リクエストを1モデルに振り分ける。Not DiamondやMartianのような「分類器/メタモデル型ルーター」は、訓練した予測器がプロンプトごとに最適な1モデルを選ぶ――賢いが、選ぶのは依然として1体だ。そしてFuguは「訓練された指揮者」として、複数のモデルを呼び・役割を与え・エージェント間の通信を設計し・複数ターンにわたって出力を合成する。要は「選択(一つ選ぶ)」と「オーケストレーション(多数を学習的に編成する)」の違いであり、Sakana AIの研究者Robert Tjarko Langeはこれを「モデルプールに対する単なるargmax(最大値選択)以上のものだ」と表現している(同氏は社員のため、独立した第三者評価ではない)。
VC・各紙はどう報じたか
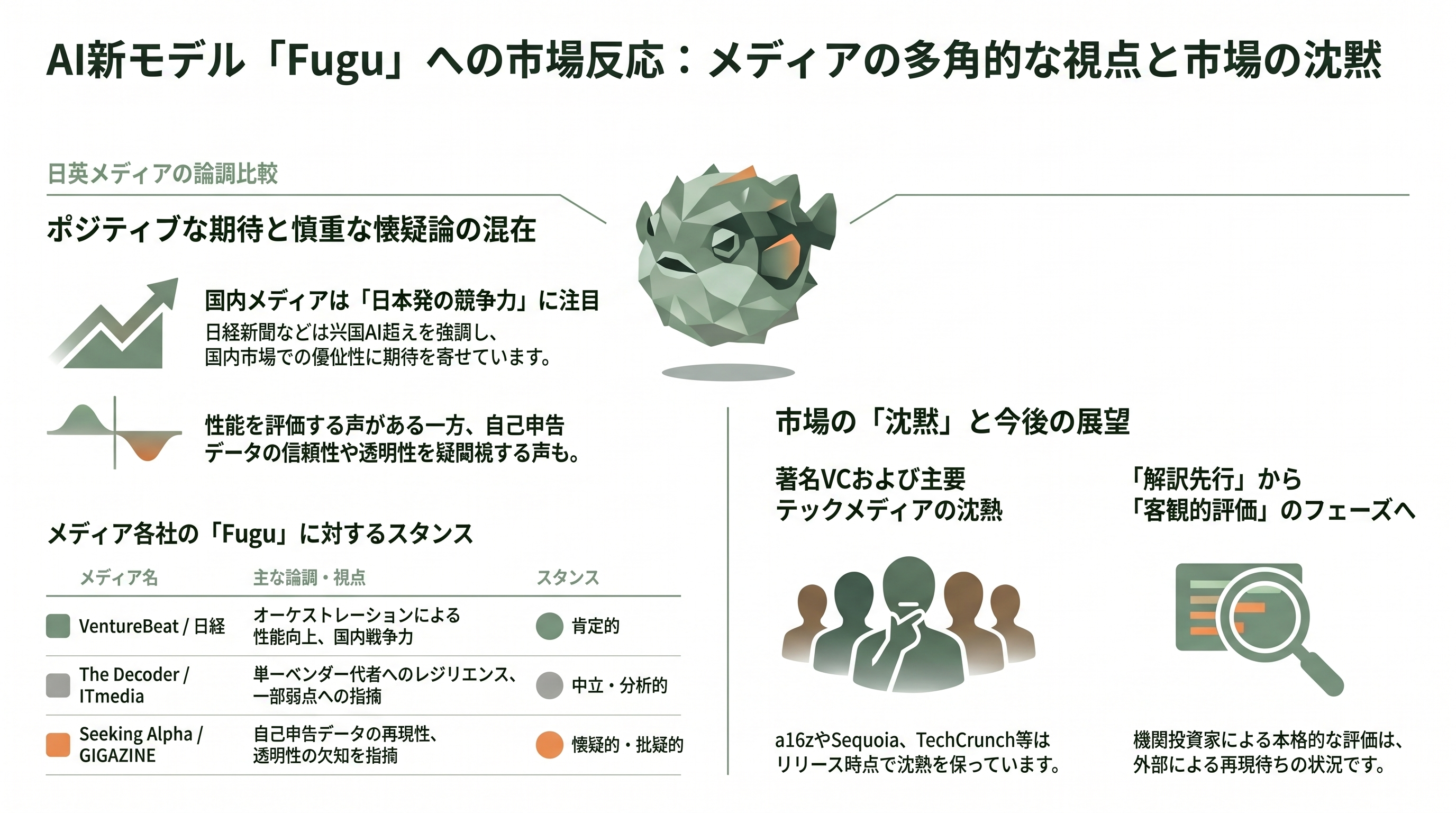
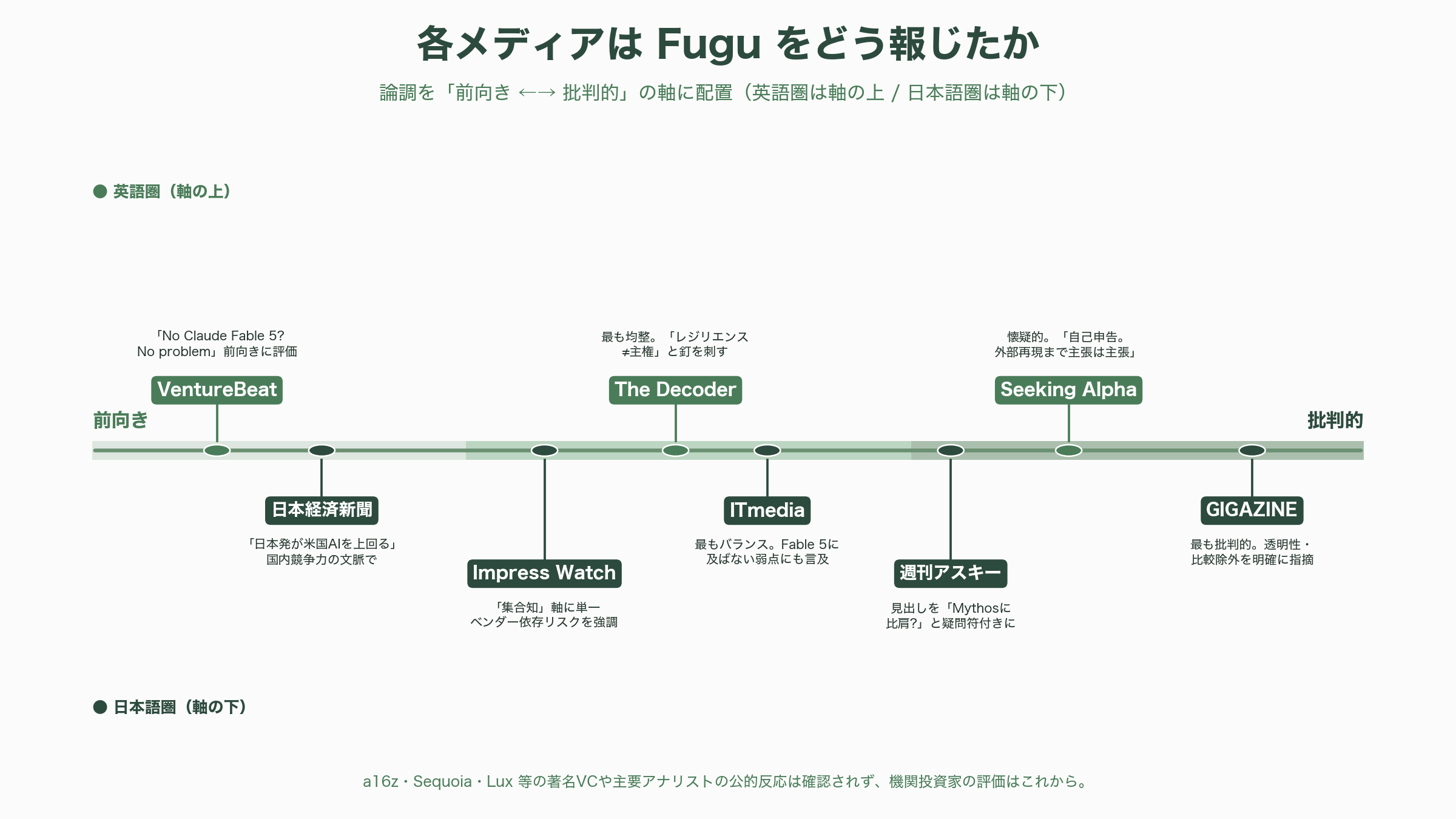
報道の論調は媒体の性格を映して割れている。英語圏ではVentureBeatが「No Claude Fable 5? No problem」とオーケストレーションをフロンティア性能の代替として前向きに描き、The Decoderは最も均整の取れた記事で「単一企業のAPIへの依存は重大な脆弱性」というSakanaの言葉を引きつつ、「レジリエンス(回復力)は真の主権とは違う」と釘を刺した。金融系のSeeking Alphaはより懐疑的で、Fable 5/Mythosに対する「同等」とGemini・Opus・GPTに対する「凌駕」を慎重に区別し、「すべての数字はSakana自身の環境での自己申告。外部が再現するまでは主張は主張として扱え」と論じている。なお主要テックメディアのうちTechCrunch、The Verge、Ars Technicaにはリリース当日時点でFugu発表の記事が見当たらなかった。
日本語圏では、日本経済新聞が「日本発スタートアップが米国AIを上回る」という国内競争力の文脈で報じ、価格を「月3,200円(20ドル)から」と紹介した。Impress Watchは「集合知」をキーワードに単一ベンダー依存リスクを強調。ITmediaは最もバランスの取れた記事で、Sakanaの具体的発言を引きつつ「Humanity's Last Examのような広範な知識を問う課題ではFable 5に及ばなかった」という弱点にも触れた。最も批判的だったのはGIGAZINEで、「どのAIモデルが各出力に使われたかを利用者が確認できない」という透明性の問題と、比較からFable 5/Mythosが除外されている点を明確に指摘した。週刊アスキーは見出しを「Mythosに比肩?」と疑問符付きにし、慎重な距離を保った。
注目すべきは「沈黙」の方かもしれない。a16z、Sequoia、Lux Capital、Khosla、NEAといった著名VCや、SemiAnalysisのようなアナリストがFuguのリリースに公に反応した形跡は、調べた範囲では見当たらなかった。Sakana AIの株主であるLux Capitalも、出資時(2024年)に「自然に着想を得たAI基盤モデルを作る日本のSakana AIへの投資」と題した論考を出してはいるが、Fuguへの直接言及はない。世界が固唾を呑んで見守る発表、というより、当事者の発信とテックメディアの解釈が先行し、機関投資家の評価はこれから、という段階にある。
死角と論点 — シリコンバレーの技術者はどう見るか
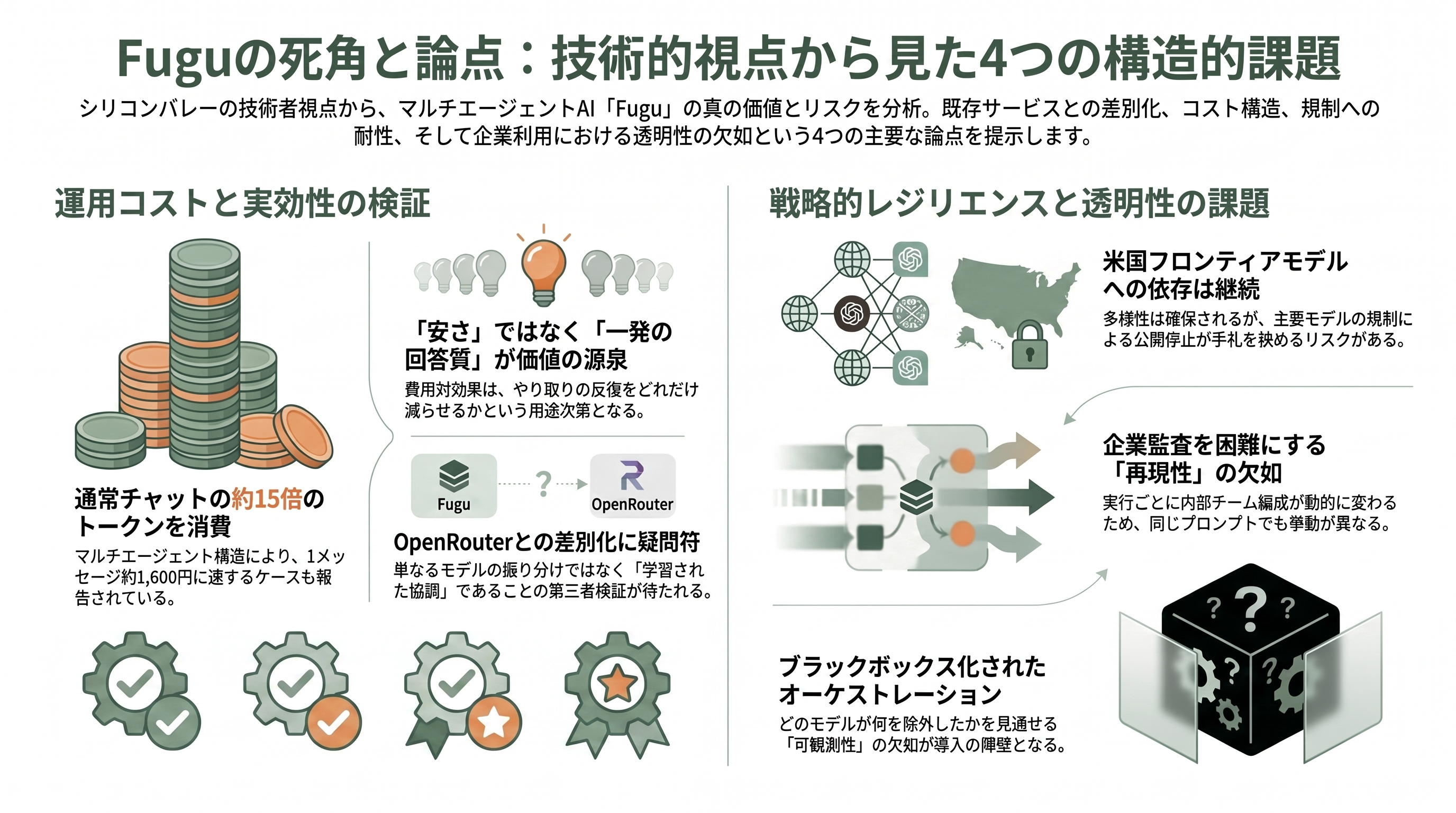
技術者の冷めた目で見れば、Fuguには無視できない論点がいくつもある。第一の、そして最も率直な疑問は「これは結局OpenRouterではないのか」だ。Hacker Newsには「要するにopenrouter?」という反応が並び、あるニュースレターは「皮肉な見方をすれば、非常に優れたマーケティングを纏ったプレミアム・モデルルーターだ」と評した。Sakana側の反論は「学習された多ターンの協調であって単なる振り分けではない」という点に尽きるが、それを裏づけるのが自社ベンチマークである以上、第三者の再現を待つほかない。
第二はコストとレイテンシだ。前述のAnthropicのデータが示すように、マルチエージェントは通常チャットの約15倍のトークンを食う。Fuguは下位モデルに各社の正規API料金を支払った上で自社のオーケストレーション・マージンを乗せる構造のため、「トークンが安くなる」わけではない。実際、重いUltraタスクでは1メッセージあたり約10ドル(約1,600円)に達するとの指摘や、有料利用者から「動作が遅く感じる」「5時間の利用上限が驚くほど早く尽きる」という声がある。価値の源泉は安いトークンではなく「やり取りの反復が減り、一発でより良い答えが返ること」に置かれており、その費用対効果が成立するかは用途次第だ。
第三は、皮肉なことに看板の「輸出規制を迂回する」という主張そのものにある。Fuguが束ねるのは第三者のモデル群だが、その肝心のFable 5やMythosは規制で公開停止中ゆえプールに入っていない。そしてThe Decoderが指摘するように、複数の有力提供元が同時にアクセスを制限すれば、Fuguが選べる手札も縮む。レジリエンスは「多様性」から来るのであって「独立性」から来るのではない――一社依存を避けられても、米国フロンティアモデル全体への依存からは自由になっていない。第四に透明性。どの出力にどのモデルが使われたかを利用者が追えないこと、課題ごとに内部のチーム編成が動的に変わるため「同じプロンプトの2回の実行が同じ内部チームを使うとは限らない」再現性の難しさは、評価やデバッグ、監査を要する企業にとって現実的な頭痛の種になる。隠れたオーケストレーション層は、コスト・出所・故障モード・ツールの境界を覆い隠しかねず、導入には「どのエージェントが走り、何を根拠に、何を除外したか」を見通せる優れた可観測性が要る、という論調だ。
今後の展望 — 次に何が、いつ来るか
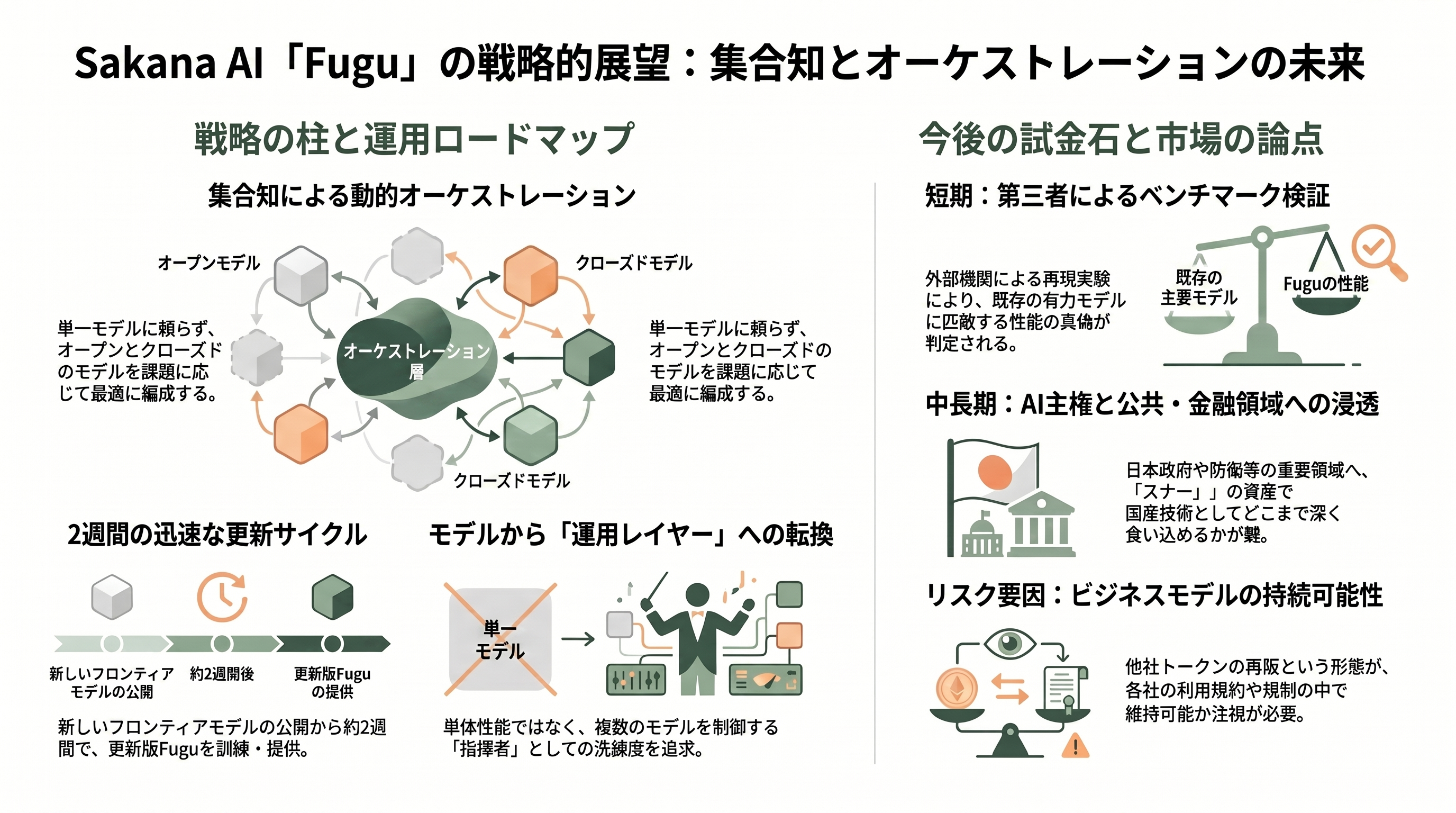
公式に表明されたロードマップは具体的だ。Sakana AIはエージェントプールをオープンモデルや自社モデルへと拡張し、長時間・エージェント的タスクでの協調を強化すると述べる。運用面では、「新しいフロンティアモデルが公開されるたびに、更新版のFuguを訓練・評価してロールアウトするまでにおよそ2週間を見込む」という更新サイクルを公言しており、これが守られればFuguは下位エコシステムの進化に2週間遅れで追従し続けることになる。利用者側の制御も今後さらに拡げるとし、EU/EEAについてはGDPR等への対応後の提供を目指すが時期は明示されていない。一方で、オンプレミス提供、利用者によるファインチューニングやカスタムプール、正式なSLAといった項目は公式には約束されておらず、二次報道で「未解決の論点」として挙がるにとどまる。
戦略の旗印は明快だ。David HaはLinkedInの投稿で「単一のモデルに頼るのではなく、あらゆる課題に対してオープンとクローズドのモデルの最適な組み合わせを動的に編成する。AIの未来は集合知(collective intelligence)だ」と述べている。一企業の巨大モデルを際限なく訓練する路線へのアンチテーゼとして、「小さく賢い指揮者が大きな専門家たちを協調させる」というSakanaの自然着想型の思想は、Transformerの共著者が東京から放つ問題提起として象徴的でもある。
では、いつ頃どんな動きが観測されるのか。最も近い試金石は、第三者による独立ベンチマークの再現だ。Seeking AlphaやGIGAZINEが促す通り、外部の検証が出そろえば「Fable 5に肩を並べる」という主張の真偽が定量的に判定される。次に、商務省の輸出規制の行方――Anthropicが「誤解」として復旧を働きかけており、Fable 5/Mythosが市場に戻れば、Fuguの「規制を迂回する唯一の選択肢」という物語の前提が揺らぐ。あるニュースレターが「モデルは製品ではない。オペレーティング・レイヤーこそが製品だ」と論じたように、2026年後半から2027年にかけての競争は、個々のモデル性能ではなくオーケストレーションの洗練度を軸に進むという見立てが有力だ。In-Q-Telを株主に迎え「AI主権」を掲げるSakana AIが、日本政府や防衛・金融・統治の領域へどこまで食い込むか、そして「他社のトークンを再販してマージンを乗せる」というビジネスモデルが、各社の利用規約というグレーゾーンの中で持続可能なのか――Fuguの真価は、リリース当日の華やかなベンチマークではなく、これらの問いへの答えが出そろう数か月先に明らかになる。