LLMOpsとは何か——「動くか」ではなく「良い答えを出し続けているか」を測る運用
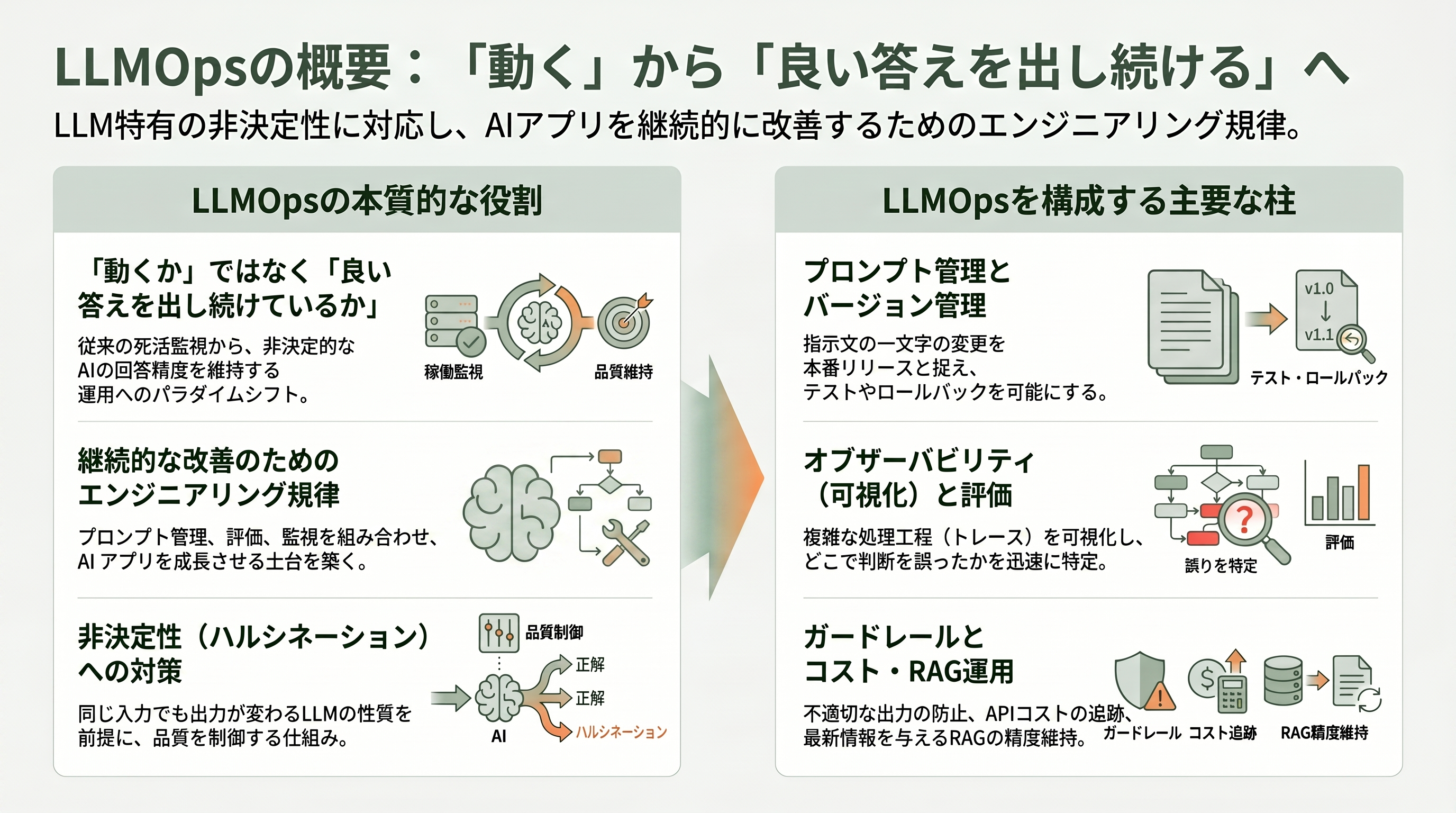
LLMOps(Large Language Model Operations、大規模言語モデル運用)とは、ChatGPTやClaude、Geminiのような大規模言語モデルを組み込んだアプリケーションを、本番環境で開発・デプロイ・監視・保守・改善していくための一連の実践・ツール・ワークフローの総称である。基盤モデル(foundation model)を中核に据え、その周囲にプロンプトのバージョン管理、推論API、品質評価、本番監視といった仕組みを組み合わせて、AIアプリを「作って終わり」ではなく「継続的に良くしていく」ためのエンジニアリング規律だと考えるとわかりやすい。
なぜ専用の運用規律がわざわざ必要になるのか。鍵は、LLMが従来のソフトウェアと根本的に性質が異なる点にある。通常のプログラムは「同じ入力なら必ず同じ出力」を返す決定的な存在だが、LLMは同じ質問を投げても毎回少しずつ違う答えを返す非決定的な存在である。しかも「正解」が一意に決まらない。たとえば顧客対応チャットボットに「返品したい」と打ち込んだとき、丁寧で正確な回答もあれば、もっともらしいが事実と異なる回答(ハルシネーション)が混じることもある。だからLLMOpsの問いは、従来の運用監視のように「システムは動いているか(落ちていないか)」ではなく、「良い答えを出し続けているか」へと変わる。この一点が、LLMOpsという分野が独立して立ち上がった最大の理由である。
具体的な構成要素を、身近な例で見ていこう。第一にプロンプト管理である。LLMアプリでは、モデルに与える指示文(プロンプト)を一文字変えるだけで出力が大きく変わる。そこで「プロンプトの変更はすべて本番リリースであり、バージョン管理・テスト・ロールバックの対象であるべき」という考え方が標準になった。たとえばECサイトの問い合わせボットで応対トーンをv1からv2に変えた途端にクレームが増えたなら、ボタン一つでv1へ戻せる仕組みが要る。第二に評価(Eval)である。品質を合否ではなく連続的なスコアで採点するために、模範解答を集めた「ゴールデンデータセット」を用意し、別のLLMに出力を採点させる「LLM-as-a-Judge(審査員としてのLLM)」という手法が主流化した。第三にオブザーバビリティ/トレーシングで、ユーザーの一回の操作が、モデル呼び出し・外部ツール実行・検索・再試行といった一連の処理(トレース)としてどう流れたかを可視化する。エージェントが誤動作したとき、トレースを見れば「どこで判断を誤ったか」を数分で特定できるが、計測していないチームは推測と再実行に頼るしかない。
これらに加えて、トークン消費とAPI料金を追跡するコスト管理、不適切な出力や情報漏洩を防ぐガードレール、社内文書や最新情報をモデルに与えるRAG(検索拡張生成)の運用、複数ステップを自律的にこなすエージェントを監視・改善するエージェント運用(AgentOps)、そして複数バージョンを本番で比較するA/Bテストと継続監視が、LLMOpsの主要な柱として並ぶ。要するにLLMOpsとは、「非決定的で壊れ方の見えにくいAI」を、安心して顧客に届け続けるための地味だが不可欠な土台なのである。
MLOpsからLLMOpsへ——なぜ新しい運用パラダイムが必要になったのか

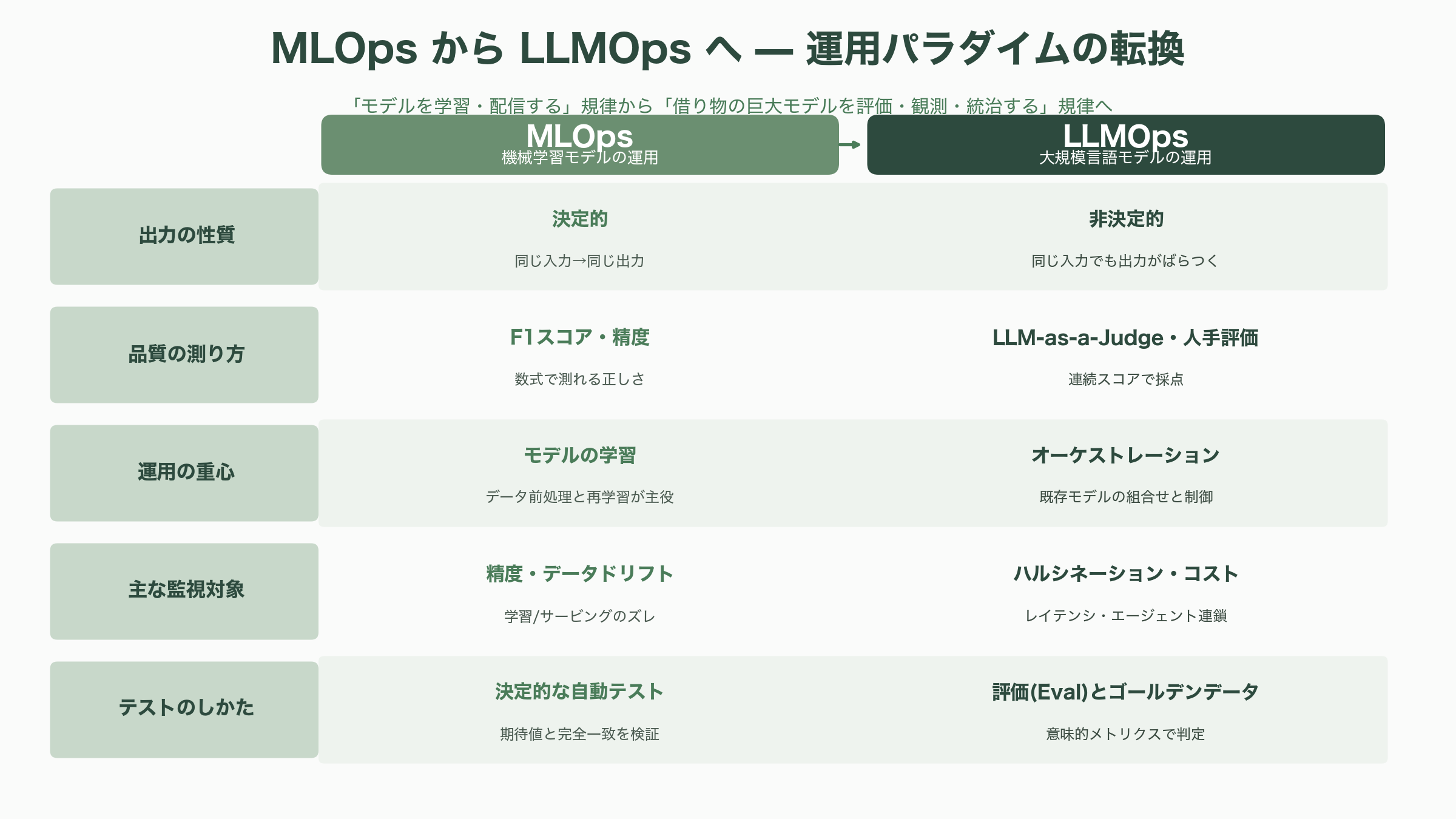
LLMOpsは突然現れたわけではなく、機械学習モデルの運用規律であるMLOps(Machine Learning Operations)からの進化として理解するのが正確である。従来のMLOpsは、自社データを集めてモデルをゼロから学習させ、デプロイし、精度やF1スコアといった定量指標で監視する営みが中心だった。出力は基本的に決定的で、「正しさ」は数式で測れた。学習パイプラインこそが主役であり、データの前処理とモデルの再学習が運用の大半を占めていた。
ところがLLM時代になると、多くの企業は自前でモデルを学習しない。OpenAIやAnthropic、Googleが提供する巨大な基盤モデルをAPI経由で借り、プロンプト設計やRAG、必要に応じたファインチューニングで「使いこなす」側に回る。すると運用の重心が、モデルの「学習」から、既存モデルの「オーケストレーション(組み合わせと制御)」へと移る。ここで前章で述べた非決定性が効いてくる。同じ入力でも出力がばらつくため、決定的なテストが書けない。だから人間による評価や、別のLLMによる自動採点が不可欠になる。さらに、自信満々に虚偽を述べるハルシネーションという固有の信頼性課題、トークン単位で積み上がるコスト、応答までのレイテンシ、そして複数ステップで自律動作するエージェント化——これらすべてが、従来のMLOpsの道具立てでは捉えきれない新しい監視対象になった。
象徴的なのは「失敗の見え方」の違いである。エージェントが普及した世界では、不具合は単一のAPI呼び出しではなく、複数の判断が連鎖したマルチステップの因果の中で起きる。会話型AIは従来システムとは異なる壊れ方をする——誤った出力をユーザーが正しいと信じてしまう「信頼の罠」、意図から少しずつ逸れていく「ドリフト」、もっともらしいのに実は間違っている「サイレント・ミスマッチ」といった具合だ。米VCのBessemer Venture Partnersは2026年5月公開のレポート「AI Infrastructure Roadmap: Five Frontiers for 2026」で、AIの失敗の78%は従来の監視やユーザーからは見えない「不可視(invisible)」なものであり、失敗パターンの93%はモデルの能力差ではなく相互作用のダイナミクスに由来する——つまりモデルを強くしても残る——と指摘している。だからこそ、意味的なメトリクス、LLM-as-a-Judge、リアルタイムの本番監視を束ねる新しい層が要るというわけだ。
こうした流れの中で、「GenAIOps」「AgentOps(エージェント運用)」といった派生語も生まれた。とりわけAgentOpsは2026年に独立した規律として認知されつつあり、その標準化の中核に位置づけられているのが、観測データの記述様式を統一するOpenTelemetryのGenAI/agenticセマンティック規約である。LLMやツール、エージェントがメトリクス・ログ・トレースを共通スキーマで吐き出せるようにすることで、特定ベンダーに縛られない可観測性の土台を作ろうという動きだ。MLOpsが「モデルを正しく学習・配信する」規律だったとすれば、LLMOpsは「借り物の巨大モデルを正しく評価・観測・統治する」規律へと重心を移した——これが進化の本質である。
LangfuseとLangSmith——オープンソースとフレームワークnativeの二大潮流

LLMOpsの可観測性ツールを語るとき、最初に名前が挙がるのがLangfuseとLangSmithだ。両者は出自が対照的で、この分野の二大潮流をよく表している。
Langfuseは、オープンソースのLLMエンジニアリング/オブザーバビリティ・プラットフォームである。LLM呼び出しや埋め込み、ツール使用、再試行、レイテンシをトレースとして可視化し、プロンプトをバージョン管理し、LLM-as-a-Judgeや人手ラベリングで評価し、データセット上で実験する——という一連の流れを、試作から本番スケールまで一気通貫で提供する。OpenTelemetryやLangChain、OpenAI SDK、LiteLLMなどとネイティブに連携する点も実務での採用を後押しした。運営はドイツ・ベルリン発のスタートアップで、Marc Klingen、Maximilian Deichmann、Clemens Rawertの3名が創業し、Y CombinatorのWinter 2023バッチを経て、2023年11月にLightspeed Venture Partnersらから約400万ドル(約6億円)のシードを調達している。コア機能はMITライセンスで公開され、Fortune 500のうち63社、Fortune 50のうち19社に採用され、SDKは月間2,600万回を超えてインストールされるまでになった。TwilioやIntuit、Khan Academy、Merckなどが利用企業として名を連ねる。
そのLangfuseに、2026年に入って大きな転機が訪れた。データ分析データベースで知られるClickHouseが、2026年1月16日にLangfuseを買収したのである。買収額は非開示だが、ClickHouseは同じ日にDragoneer主導で約4億ドル(約600億円)のシリーズDを調達し、評価額が約150億ドル(約2.3兆円)に達したことも発表した。LangfuseはもともとバックエンドにClickHouseを使っており、両社は「LLMの可観測性と評価は本質的にデータ問題である」という認識で一致していた。買収後もLangfuseのコアはMITライセンスのオープンソースとして維持され、Langfuse Cloudも独立サービスとして継続される方針が示されている。独立系OSSが、AIの「フィードバックループ」を自社に取り込みたいデータ基盤大手に吸収された——この構図は本稿後半で論じる業界再編の典型例である。
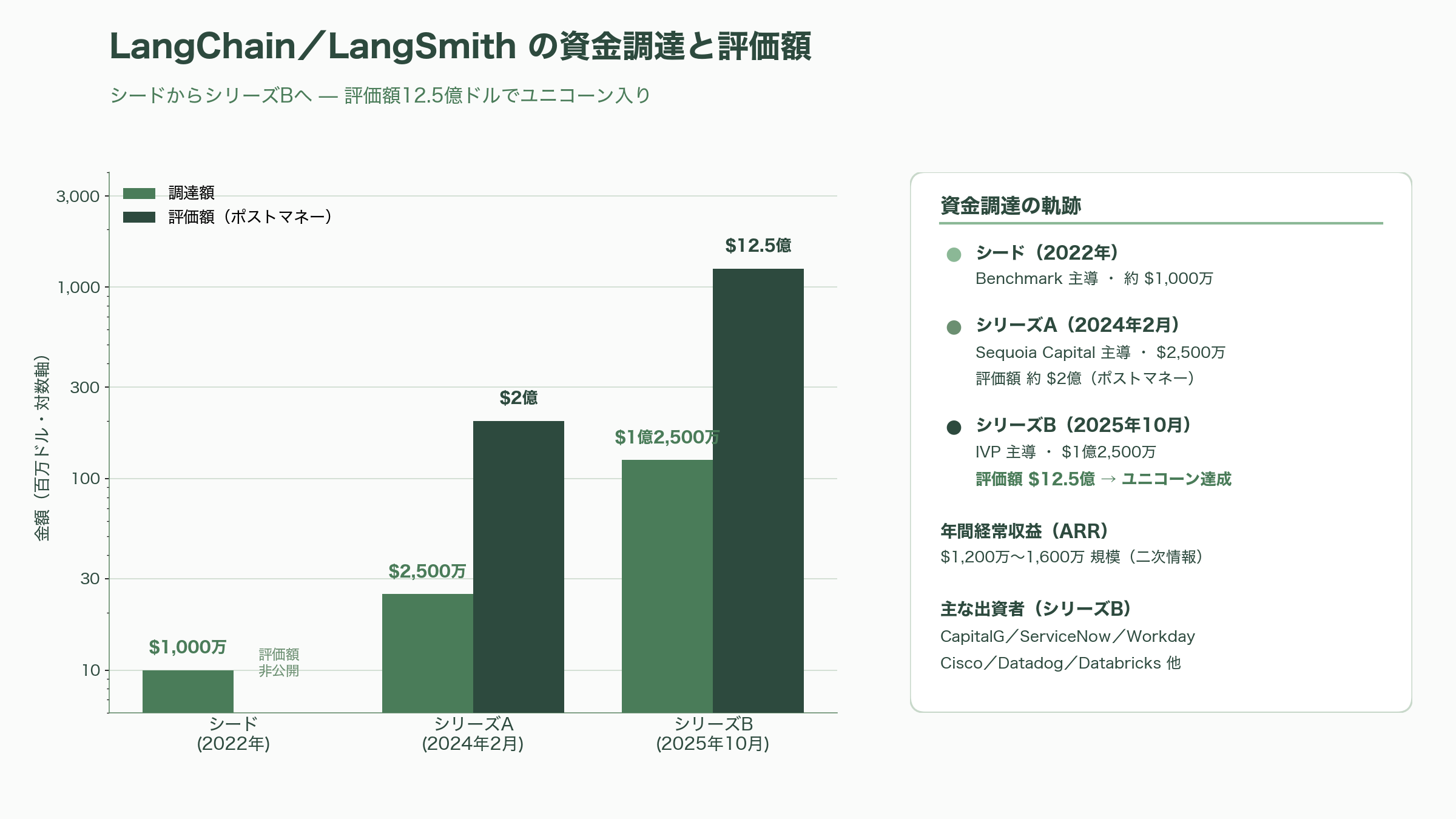
一方のLangSmithは、LLMアプリ構築フレームワークとして爆発的に普及したLangChainを母体に持つ。ここで三つのプロダクトの関係を整理しておきたい。LangChainはLLMをアプリに組み込むためのオープンソースのフレームワーク(MITライセンス)であり、LangGraphはエージェントやマルチエージェントのオーケストレーションと状態管理を担うフレームワーク、そしてLangSmithはデバッグ・テスト・評価・本番監視を提供するクローズドソースのSaaSで、同社の収益化の中核を担う。創業者はHarrison ChaseとAnkush Golaで、本社はサンフランシスコ。オープンソースの発端は2022年10月で、そこからの成長は凄まじい。Benchmark主導のシード(約1,000万ドル、約15億円)、2024年2月にSequoia Capital主導のシリーズA(2,500万ドル、約38億円、ポストマネー評価額約2億ドル=約300億円)を経て、2025年10月20日にIVP主導のシリーズBで1億2,500万ドル(約190億円)を調達し、評価額12.5億ドル(約1,900億円)でユニコーンの仲間入りを果たした。このラウンドにはAlphabet傘下のCapitalG、ServiceNow Ventures、Workday Ventures、Cisco Investments、Datadog、Databricksらが名を連ねる。年間経常収益(ARR)は1,200万〜1,600万ドル規模と複数の二次情報が伝える。2025年10月22日にはLangChain 1.0とLangGraph 1.0を同時に正式リリースし、create_agentという抽象化やhuman-in-the-loop承認などのミドルウェアを整え、エージェント開発の事実上の標準を狙う構えだ。Langfuseが「OSSが基盤大手に統合される」道を歩んだのに対し、LangChainは「OSSフレームワーク発のスタートアップが自社SaaSで独立ユニコーン化する」道を進んだ。同じLLMOpsの可観測性でも、出口戦略は鮮やかに分かれている。
Helicone、Portkey、Laminar——軽量プロキシからAIゲートウェイ、エージェント観測へ
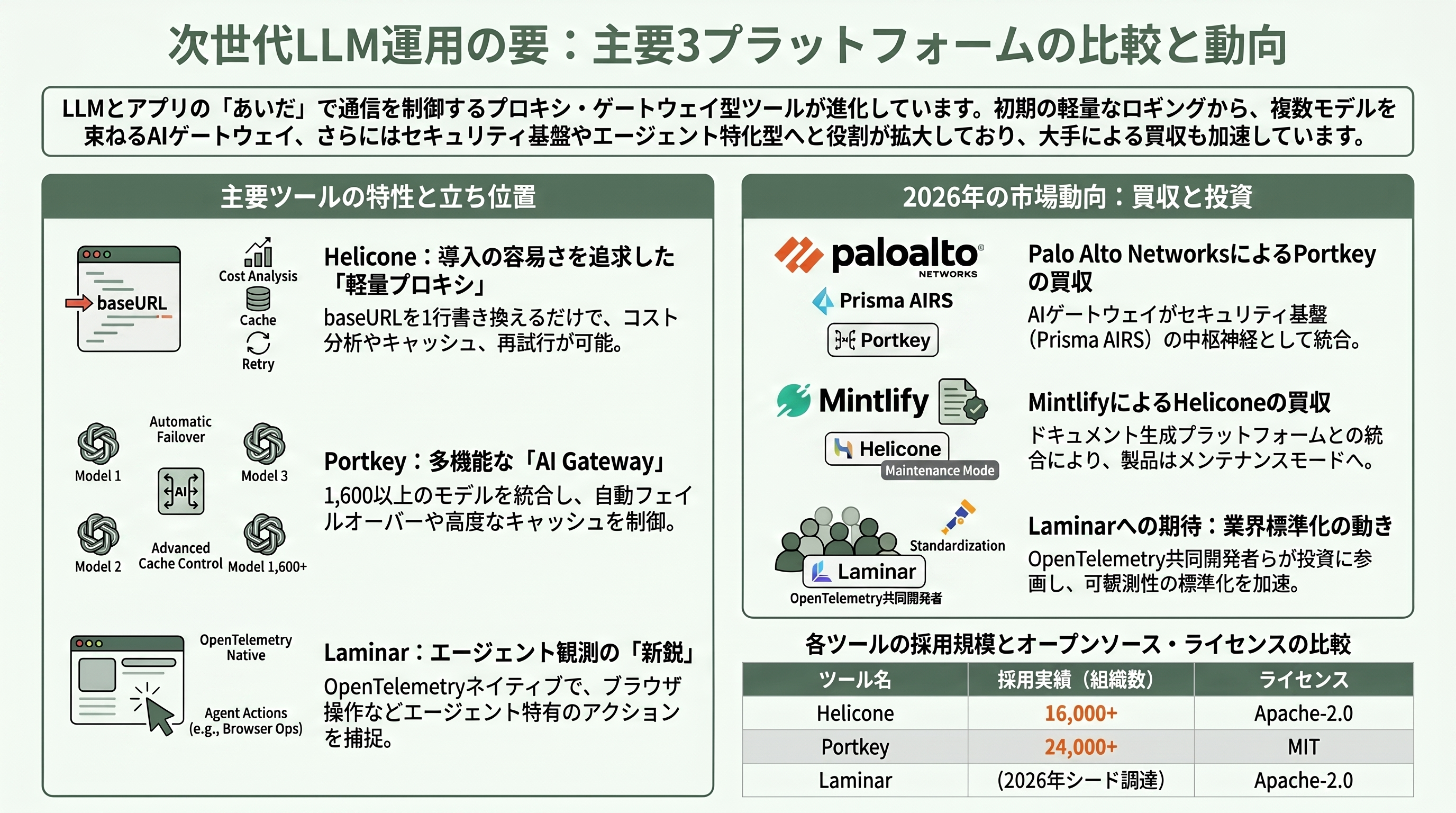
可観測性のもう一つの系譜が、アプリとLLMの「あいだ」に立って通信を捌くツール群である。Heliconeはその代表で、オープンソース(Apache-2.0)のLLM可観測性プラットフォームだ。最大の特徴は導入の手軽さで、OpenAIなどのクライアントの接続先URL(baseURL)を1行書き換えるだけで、リクエストの自動ロギング、コストとレイテンシの分析、レスポンスのキャッシュ、レート制限、再試行、アラートが有効になる。プロキシ型と呼ばれるこの方式は、既存コードへの変更を最小にできるため、まず観測を始めたいチームに重宝された。創業はJustin TorreとCole Gottdankを中心とするチームで、こちらもY CombinatorのWinter 2023バッチ出身、本社はサンフランシスコにある。累計で1万6,000以上の組織に使われ、14兆トークン超を処理した実績を持つ(なお調達額については公開情報が錯綜しており、本稿では特定の金額を断定しない)。
そのHeliconeもまた2026年に買収された。ドキュメント生成プラットフォームのMintlifyが2026年3月3日にHeliconeを買収したのである(買収額は非開示)。創業者らはMintlifyに合流し、Helicone製品は当面メンテナンスモードで存続しつつ、他プラットフォームへの移行を支援するとされる。
Portkeyは、同じく「あいだ」に立つツールだが、立ち位置はより野心的で、自らを「AI Gateway(統合コントロールプレーン)」と位置づける。1,600以上のモデルと45以上のプロバイダーを単一のAPIで束ね、可観測性・ガードレール・プロンプト管理・ガバナンスを一体で提供する。具体的な挙動が分かりやすい。フェイルオーバー設定をすれば、OpenAIが失敗したらAnthropic、それも駄目ならGoogleへと成功するまで自動で切り替える。ロードバランシングでは重み付けに従ってOpenAIへ70%、Azureへ30%とトラフィックを振り分けられる。セマンティックキャッシュを使えば、「Who is the US president?」と「Tell me who is the president of the US.」のように文面は違うが意味が近い質問もキャッシュヒットさせ、応答を高速化できる。創業はRohit AgarwalとAyush Gargで2023年1月、本社はサンフランシスコにベンガルールを加えた二拠点体制だ。中核のAI GatewayはMITライセンスで公開され、GitHubで約1万2,000のスターを集め、2万4,000を超える組織に採用された。資金調達はLightspeed主導のシード(300万ドル、約4.5億円、2023年8月)に続き、2026年2月にElevation Capital主導のシリーズAで1,500万ドル(約23億円)を調達している。
そのPortkeyの行き先も、Langfuse・Heliconeと並ぶ象徴的なものだった。サイバーセキュリティ大手のPalo Alto Networksが、2026年4月30日にPortkey買収の意向を発表し、5月29日に買収を完了したのである。買収額は公式には非開示で、一部メディア(The New Stack)が「7億ドル規模」と見出しで推計したものの、これはあくまでメディア推計であり当事者の開示ではない点に注意が必要だ。PortkeyのAI Gatewayは、Palo Alto Networksのランタイム保護プラットフォーム「Prisma AIRS(Prisma AI Runtime Security)」の中核として統合され、企業内のあらゆるAIトランザクションを監視・ルーティング・防御する「中枢神経系」になると位置づけられた。可観測性ツールが「セキュリティ」の文脈で買われた点に、AIエージェント時代の運用とセキュリティの融合が見て取れる。
新興勢のLaminarも押さえておきたい。lmnr.aiで知られるオープンソース(Apache-2.0)のAIエージェント向け可観測性プラットフォームで、OpenTelemetryネイティブに設計され、1行のコードでVercel AI SDKやBrowser Use、LangChain、各社モデルを自動トレースする。長時間稼働するエージェントを前提に、会話とそれを生んだスパンを中心に整理し、ブラウザを操作するエージェントの全アクションまで捕捉できるのが特徴だ。コードベースはTypeScriptが主体(約73%)でRustも約23%を占める。創業者のRobert KimとDinmukhamed MailibayはそれぞれPalantir/BloombergとAWSでインフラを築いた経歴を持ち、Y CombinatorのSummer 2024バッチを経て、2026年3月にAtlantic.vc主導で300万ドル(約4.5億円)のシードを調達した。このラウンドにはOpenTelemetryの共同開発者Ben SigelmanやSupabase CTOのAnt Wilsonらがエンジェルとして参加しており、可観測性の標準化に賭ける顔ぶれが揃っている点が興味深い。
Braintrustの「評価ファースト」とLatitudeの軌跡

可観測性が「起きたことを観る」アプローチだとすれば、Braintrustは「出す前に良し悪しを測る」評価(Eval)を起点に据えたプラットフォームである。LLMアプリを本番投入するチーム向けに、評価・実験・オブザーバビリティ・プロンプトプレイグラウンドを一体で提供する。事実性や関連性、安全性などを測る組み込みスコアラー群(AutoEvals)を備え、本番トレースから「ゴールデンデータセット」を作って回帰テストに使い、ブラウザ上でコードを書かずにプロンプトを試して複数モデルを横並びで比較できる。さらに「Loop」というAIエージェントが、自然言語の指示からプロンプト・スコアラー・データセットを自動生成し、本番ログを解析して失敗パターンを洗い出す——エンジニア以外の職種でも評価設計に参加できるようにするのが狙いだ。
創業者でCEOのAnkur Goyalは、MemSQL(現SingleStore)の創業チームからImpira(後にFigmaが買収)を起業し、FigmaでAIチームを率いた人物。2023年創業、本社はサンフランシスコ。資金面では2024年10月にAndreessen Horowitz(a16z)のMartin Casado主導でシリーズA・3,600万ドル(約54億円)を調達し、2026年2月17日にはICONIQ主導のシリーズBで8,000万ドル(約120億円)を調達、ポストマネー評価額は約8億ドル(約1,200億円)に達した。a16z、Greylock、basecase capital、Elad Gilらが参加している。NotionやStripe、Vercel、Airtable、Instacart、Zapier、Replit、Cloudflare、Ramp、Dropboxといった、いわゆる「AIネイティブ」企業が顧客として名を連ねるのも特徴だ。後述するように、Menlo VenturesやBessemerのレポートがAI技術スタックの観測・評価層でBraintrustを名指ししており、VCの注目度は突出して高い。
対照的に小規模ながら、ピボット(事業転換)の軌跡が示唆に富むのがLatitudeだ。スペイン・バルセロナのLatitude Data社(latitude.so)が運営するオープンソース(LGPL-3.0)のプラットフォームで、César MigueláñezとGerard Closが創業した。注意したいのは、同社が当初データ分析ワークスペースとして始まり、2024年10月にオープンソースのプロンプトエンジニアリング基盤へ、そして2025〜2026年にはAIエージェントの可観測性へと、同じ会社のままプロダクトを転換してきた点である。資金は欧州系VC(Moonfire、K Fund、Sur Ventures、Itnig)から少額のシードを得たのみで(金額については情報が割れており断定は避ける)、巨額調達組とは規模が異なる。2026年時点では自らを「Sentry, but for agents and LLMs.(エージェントとLLMのためのSentry)」と位置づけ、課題のクラスタリング、人間の判断に整合させた評価、エージェント特化のトレース、MCPサーバー提供などへ軸足を移した。2026年5月にはClaude Code向けの連携も投入している。純粋なプロンプト管理ツールが、エージェント観測へと生き残りをかけて進化する——Latitudeはその縮図と言える。
プラットフォーマーの参入——DatabricksとGoogle Cloud Vertex AI
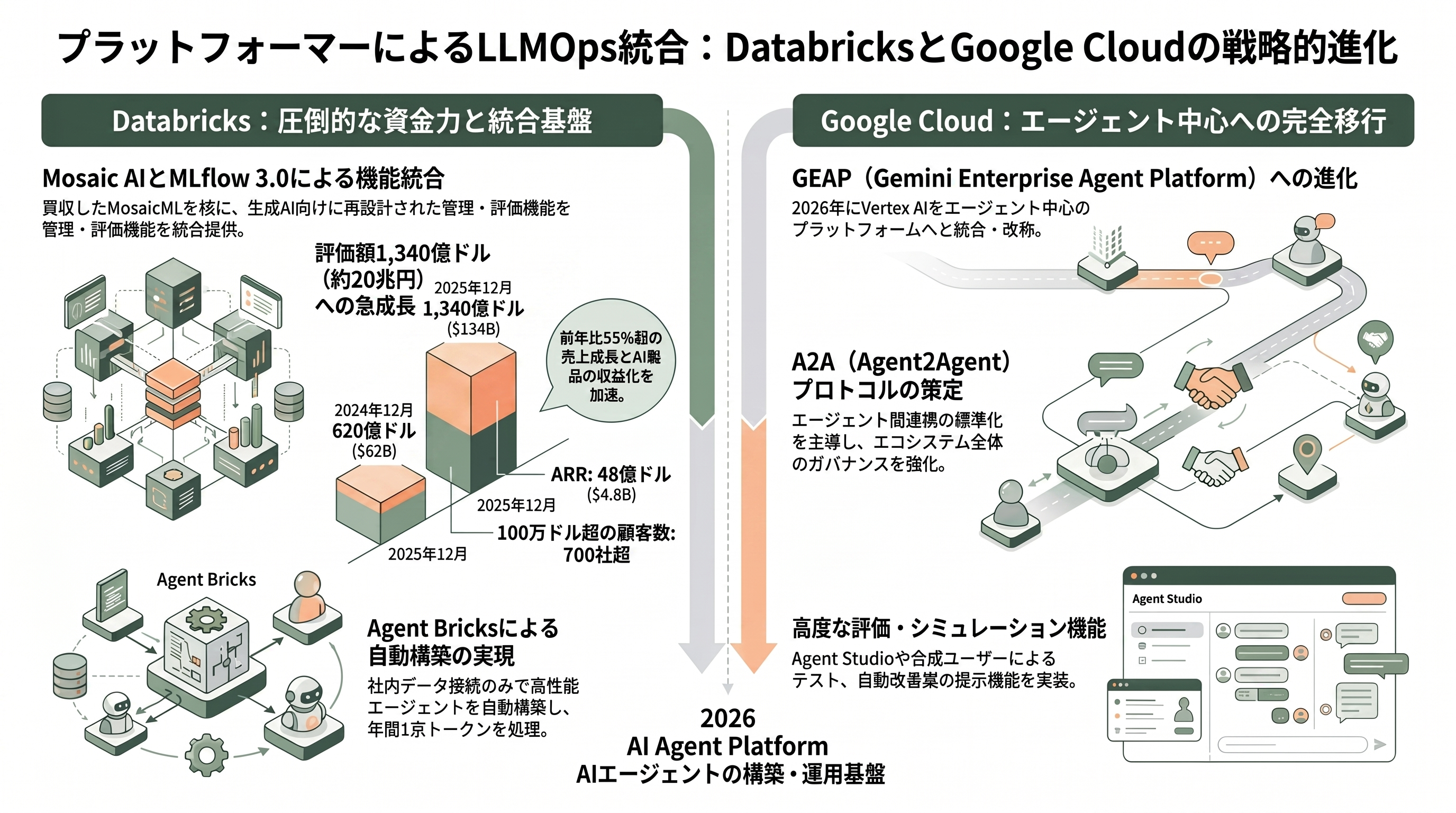
ここまで見てきた専業スタートアップ群の頭上には、データ/クラウドのプラットフォーマーが「LLMOpsを丸ごと取り込む」動きを進めている。その筆頭がDatabricksだ。2013年創業、Ali GhodsiをCEOとし、Apache SparkやMLflowの生みの親Matei Zahariaを含むUC Berkeley AMPLab出身の7名が立ち上げた同社は、2023年6月に生成AI基盤のMosaicMLを約13億ドル(約1,950億円)で買収し、これを「Mosaic AI」ブランドの中核に据えた。
DatabricksのLLMOpsは大きく二つの柱からなる。一つはMLflow 3.xで、2025年のData + AI Summitで3.0が正式リリースされ、生成AI向けにゼロから再設計された。OpenTelemetryベースのトレーシングで入出力・レイテンシ・コストをプロンプトやコードのバージョンに紐づけ、研究に基づくLLM-as-a-Judgeで品質を採点し、Gitスタイルでプロンプトをバージョン管理して即時ロールバックや差分比較ができる。ドメイン専門家がノーコードで出力をレビューする仕組みも備える。もう一つの柱がMosaic AIで、エージェントの構築・評価・デプロイ・監視を担うAgent Framework、品質を測るAgent Evaluation、推論を配信するModel Serving、ガバナンスを効かせるAI Gateway、検索を支えるVector Search、データとAI資産を統合管理するUnity Catalogなどが揃う。2025年に発表されたAgent Bricksは、タスクの記述と社内データの接続だけで高性能エージェントを自動構築する仕組みで、2026年6月のData + AI Summit 2026で正式提供(GA)に至った。ローンチ以降10万を超えるエージェントが構築され、年間1京(quadrillion)トークンを処理したという。
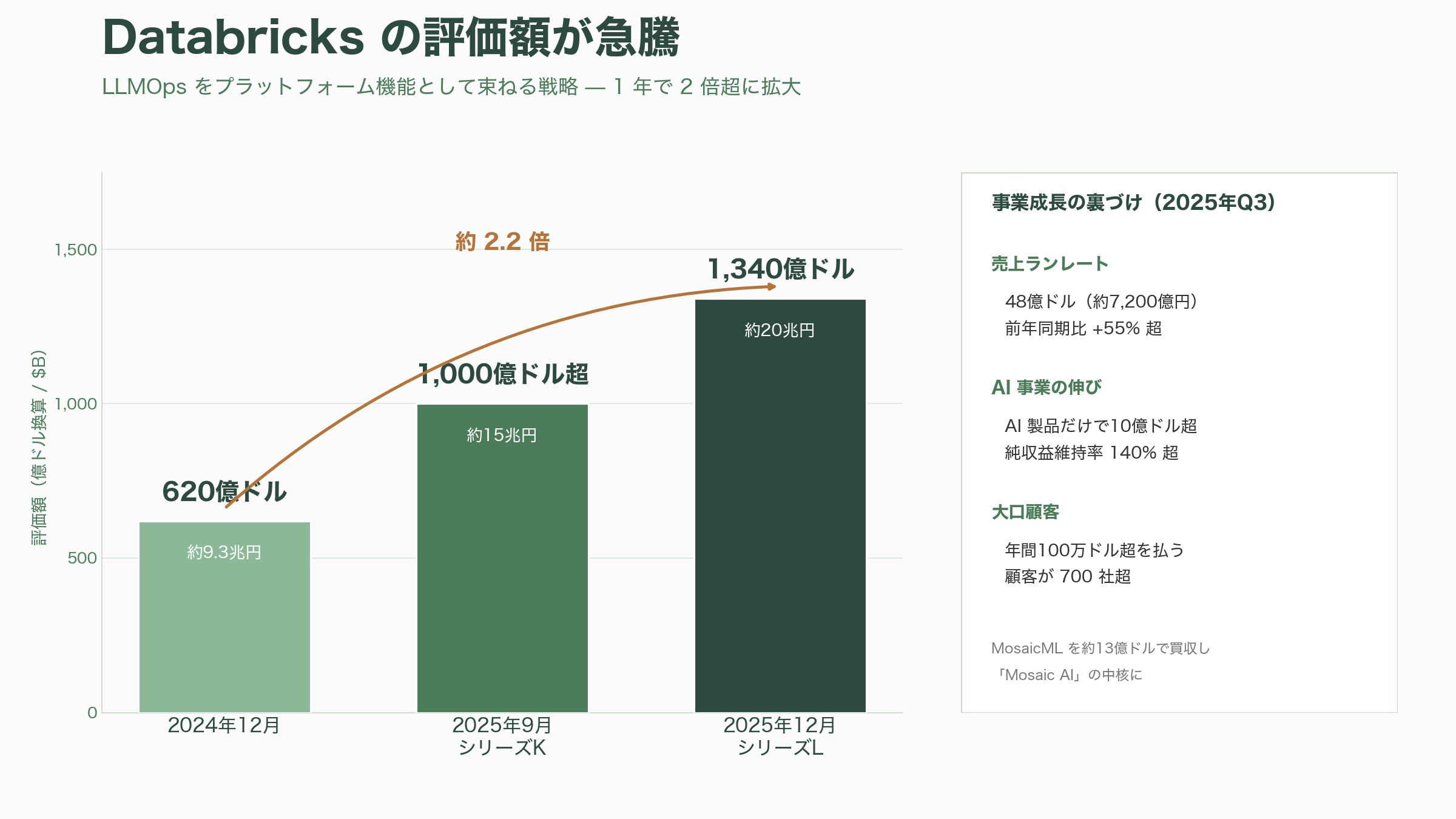
その事業の伸びは資金調達にも表れている。Databricksは2025年9月にシリーズKで10億ドル(約1,500億円)を調達し評価額1,000億ドル超(約15兆円)に乗せ、わずか3か月後の2025年12月16日にはシリーズLで40億ドル超(約6,000億円)を調達、評価額1,340億ドル(約20兆円)へと駆け上がった。2024年12月の620億ドル(約9.3兆円)からの急騰である。売上は2025年第3四半期に年換算ランレートで48億ドル(約7,200億円)を突破し、前年同期比55%超の成長、AI製品だけで10億ドル超のランレート、純収益維持率140%超、年間100万ドル超を支払う顧客が700社超——と、LLMOpsを「プラットフォームの一機能」として束ねる戦略が数字で裏打ちされている。
もう一方の雄、Google Cloud Vertex AIも2026年に大きく姿を変えた。Vertex AIはもともと、200を超える基盤モデルへのアクセスから評価・監視・デプロイまでをカバーするフルマネージドのAI開発プラットフォームであり、生成出力を採点するGen AI Evaluation Service(既定の審査モデルはgemini-2.5-flashで、Model Garden経由ならAnthropicのClaudeやMetaのLlamaも評価できる)、学習とサービングのズレやドリフトを検出するModel Monitoring、プロンプトを資産として管理するPrompt Managementと自動最適化のPrompt Optimizer、出力を検証可能な情報源に紐づけてハルシネーションを抑えるGrounding、エージェント構築のためのAgent BuilderとAgent Engine、マネージドRAGのRAG Engineといった、LLMOpsの主要機能を網羅していた。さらにエージェント間連携の標準プロトコルA2A(Agent2Agent)を策定し、2025年6月にLinux Foundationへ寄贈している。
そのVertex AIは、2026年4月22日のGoogle Cloud Next 2026で「Gemini Enterprise Agent Platform(GEAP)」へと進化・改称された。公式ブログは「今後Vertex AIの全サービスとロードマップは単独サービスとしてではなく、このAgent Platform経由で提供される」と明言しており、Vertex AIは廃止ではなくエージェント中心のプラットフォームへ統合される(既存のAPIやSDKは引き続き有効)。新たにビジュアルUIのAgent Studio、合成ユーザーでテストするAgent Simulation、ライブトラフィックをマルチターンのオートレイターで継続採点するAgent Evaluation、複雑な推論を視覚的に追うトレース機能、実障害を自動でクラスタリングして改善案を提示するAgent Optimizerなどが加わった。AWSのAmazon BedrockやSageMaker、MicrosoftのAzure AI Foundryも同様にマルチモデルとエージェント基盤を競っており、ハイパースケーラー各社が「LLMOpsの主要機能を自社プラットフォームに内蔵する」流れは2026年に決定的になった。
シリコンバレーVCはLLMOpsをどう見ているか
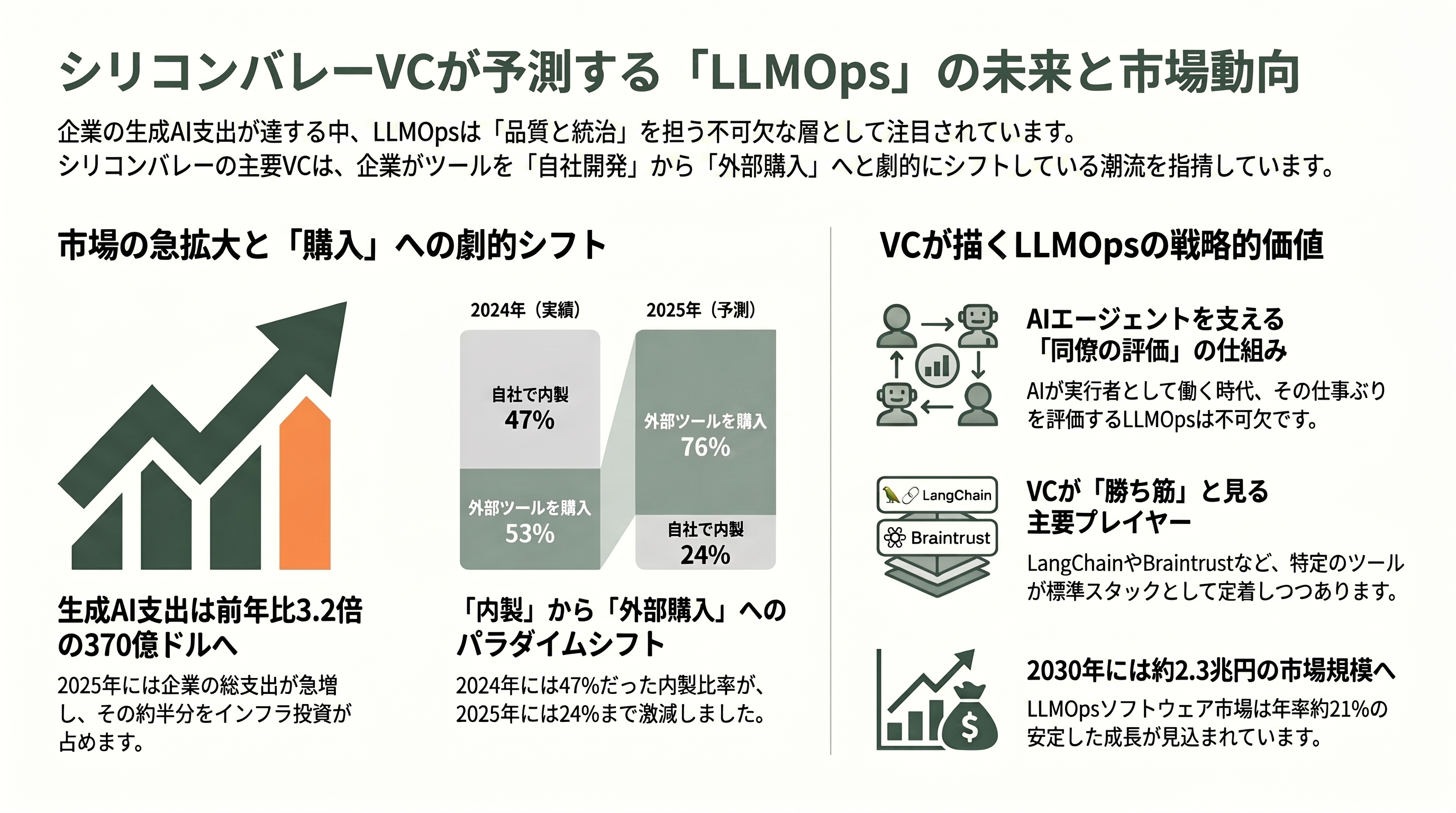
では、これらのツール群を投資家はどう捉えているのか。最も参照される一次データが、Menlo Venturesの年次レポート「2025: The State of Generative AI in the Enterprise」(2025年12月公開、米企業の意思決定者約500名への調査)である。同レポートによれば、企業の生成AI総支出は2025年に370億ドル(約5.6兆円)に達し、前年の115億ドル(約1.7兆円)から3.2倍に拡大した。内訳はアプリケーションが190億ドル(約2.9兆円、51%)、インフラが180億ドル(約2.7兆円、49%)で、インフラのうち基盤モデルAPIへの支出が125億ドル(約1.9兆円)と最大を占める。LLMOpsはまさにこの「インフラ」層に位置し、API支出の急増がコスト管理や可観測性の需要を直接押し上げている。
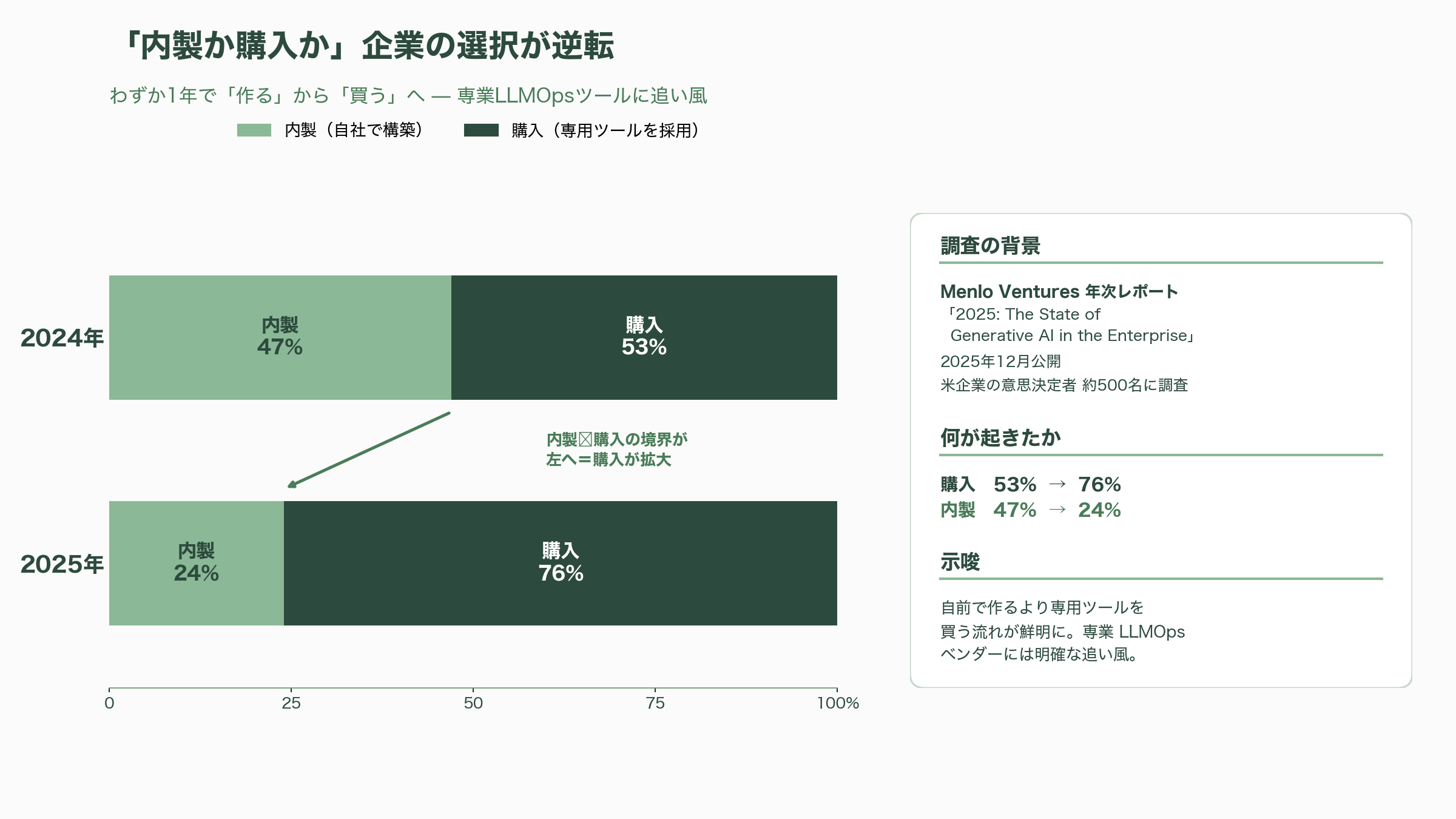
このレポートにはLLMOpsの追い風を示す数字が並ぶ。まず「内製か購入か」が劇的に逆転した。2024年は内製47%・購入53%だったのが、2025年には購入76%・内製24%となり、企業は自前で作るより専用ツールを買う方向へ大きく舵を切った。これは専業LLMOpsベンダーにとって追い風そのものだ。モデルの企業内シェアではAnthropicが40%(前年24%)でOpenAIの27%、Googleの21%を上回り、コーディング用途に限ればAnthropicが54%とさらに優勢だった。一方で、本番で「真のエージェント」を動かしている企業はまだ16%(スタートアップでも27%)にとどまり、多くは固定的なワークフローの段階にある——つまりエージェント運用の本格的な需要はこれから立ち上がる、という読みになる。注目すべきは、同レポートがAI技術スタックの観測・評価層でLangChainとBraintrustを、推論層でFireworksやBaseten、Modal、Togetherを名指ししている点だ。VCが「勝ち筋」と見る具体名が、本稿で扱ってきた企業群と重なっている。
VC各社の発信も、この領域への確信を裏づける。a16zは「Emerging Architectures for LLM Applications」でLLMアプリの事実上の標準アーキテクチャ図を公開し、可観測性やオーケストレーションを含むスタックの全体像を早くから示してきた。前述のBessemerは「Five Frontiers for 2026」で、コンテキスト管理やオーケストレーションを担う「Harness」層を最重要フロンティアの一つに挙げ、その具体例としてBigspin.ai、Braintrust、Judgment Labsを名指しした。Sequoia Capitalは2026年1月の「2026: This Is AGI」で、長時間稼働するエージェントは機能的にはAGIに等しく、2026〜2027年のAIは「同僚のように働くdoer(実行者)」になると論じる。エージェントが同僚のように働くなら、その仕事ぶりを評価し観測する仕組み——すなわちLLMOps——は不可欠だ、という含意である。
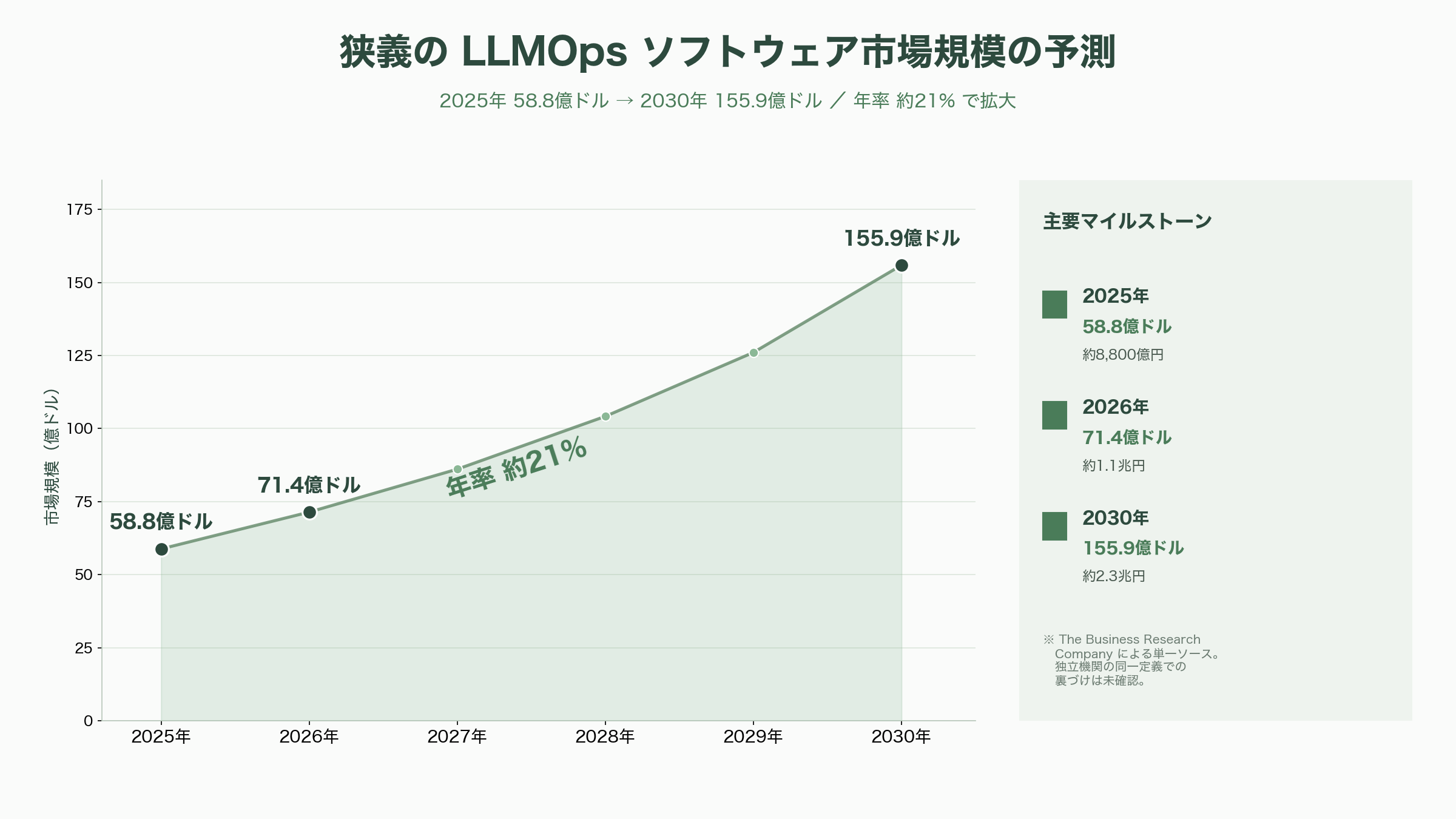
市場規模の見立ては、スコープによって幅がある点に留意が要る。調査会社The Business Research Companyによれば、狭義のLLMOpsソフトウェア市場は2025年の58.8億ドル(約8,800億円)から2026年に71.4億ドル(約1.1兆円)、2030年には155.9億ドル(約2.3兆円)へ、年率約21%で拡大する見通しだ(ただしこの数値は同一調査会社による単一ソースであり、独立した別機関による同一定義の裏づけは確認できていない)。隣接するLLMオブザーバビリティ市場は2030年に92.6億ドル規模・年率36.2%との予測もある(Research and Markets)。マクロでは、Gartnerが2026年の世界AI支出を約2.5兆ドル(約375兆円、前年比+44%)、IDCが2026年のAIインフラ支出を4,870億ドル(約73兆円、前年比+53%)と見込んでおり、LLMOpsはこの巨大な投資フローの「品質と統治を担う薄いが不可欠な層」として位置づけられている。
2026年は「統合の年」——買収ラッシュが映すLLMOpsの構造変化
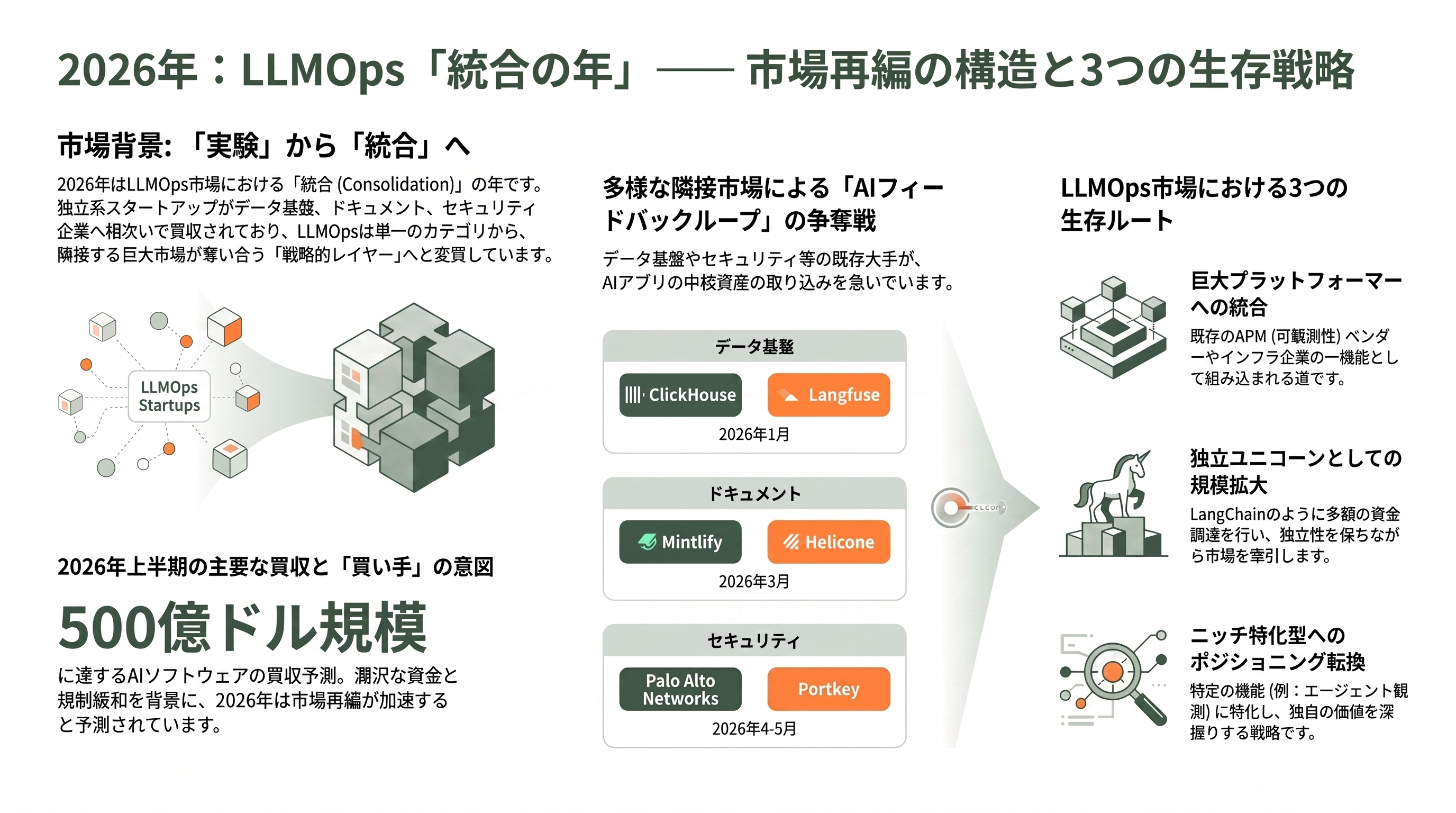
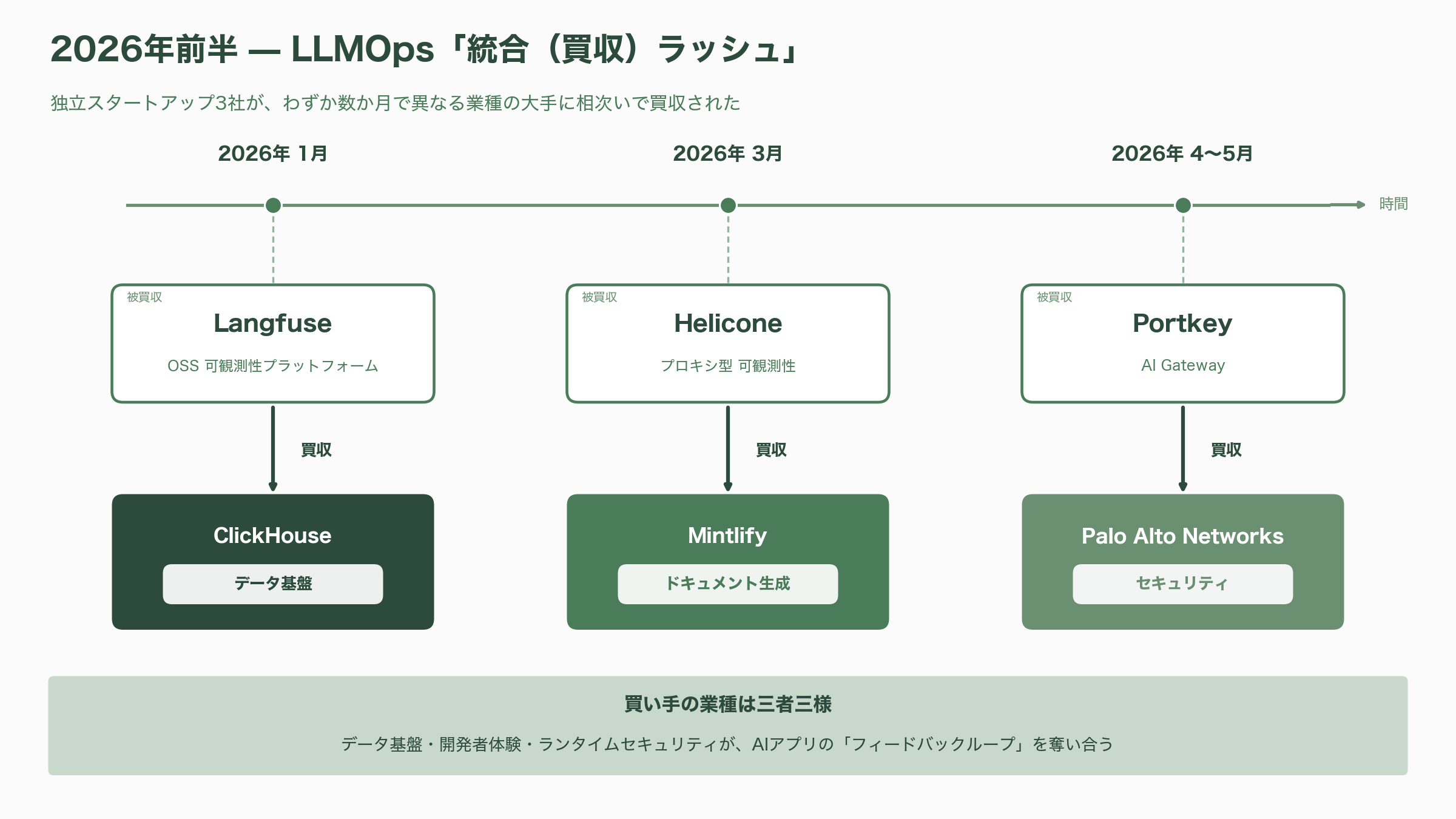
ここまでの事実を並べると、他のどのサイトもまだ正面から論じていない、シリコンバレーVC視点の統合的な構図が浮かび上がる。2025年が「実験の年」だったとすれば、2026年は明確に「統合(consolidation)の年」である。本稿が扱った主要ツールのうち、独立スタートアップだった三社が、2026年前半のわずか数か月で立て続けに買収された。1月にLangfuseがClickHouseへ、3月にHeliconeがMintlifyへ、そして4〜5月にPortkeyがPalo Alto Networksへ——である。
重要なのは、それぞれの「買い手の業種」が異なることだ。Langfuseを買ったのはデータ基盤企業(ClickHouse)、Heliconeを買ったのはドキュメント企業(Mintlify)、Portkeyを買ったのはセキュリティ企業(Palo Alto Networks)だった。これは偶然ではない。LLMの可観測性・評価データは、突き詰めれば「AIアプリのフィードバックループ」そのものであり、データ分析・開発者体験・ランタイムセキュリティという異なる事業から見て、いずれも自社の中核に取り込む価値がある資産になった、ということだ。InfoWorldが「データ基盤各社がAIのフィードバックループの所有権を争っている」と評したように、LLMOpsは独立カテゴリであると同時に、隣接する巨大市場が奪い合う戦略的レイヤーへと変質した。
一方で、買収されなかった企業の動きも示唆的だ。LangChainはLangSmithの課金で評価額12.5億ドル(約1,900億円)のユニコーンへ、Braintrustは評価額約8億ドル(約1,200億円)へと、独立路線で資金を厚くした。Latitudeのような小規模プレイヤーは、純粋なプロンプト管理から「エージェント観測」へとポジションを移して生き残りを図る。つまり2026年のLLMOps地図は、「巨大プラットフォーマーに統合される」「独立ユニコーンとして規模を追う」「ニッチに特化して進化する」という三つの道に分かれつつある。
この再編は、VCの予測とも符合する。Sapphire Venturesは「2026 Outlook: 10 AI Predictions」で、2026年には500億ドル(約7.5兆円)を超えるAIソフトウェアの買収が市場を再編すると予測し、その背景に既存大手の潤沢な資金と良好な規制環境を挙げた。LLMOps領域で起きた一連の買収は、まさにこの予測を地で行く動きだと位置づけられる。可観測性の汎用市場ではCiscoによるSplunk買収(約280億ドル)がすでに戦略的価値を実証しており、DatadogやNew Relicといった既存APMベンダーが「LLMタブ」を追加して機能を取り込む流れも続いている。専業ツールにとっては、独立を貫くか、より大きなプラットフォームの一機能になるかの選択が、いよいよ現実の経営判断として迫っているのである。
今後の展望——エージェント評価の標準化と「観測なき本番」の解消

最後に、今後いつ頃どのような動きが計測されるかを、できる限り具体的に見立てておきたい。第一の論点は評価(Eval)の標準化である。LLM-as-a-Judgeはすでに自動評価の標準メカニズムになりつつあり、Braintrustが評価ファーストの哲学で約8億ドル(約1,200億円)の評価額を得たことは、この方向への市場の確信を象徴する。AIの第一人者Andrew Ngは「効果的なエージェントを作れるかどうかの最大の予測因子は、規律ある評価とエラー分析のプロセスを回せるかどうかだ」と繰り返し説き、Arize AIと共同で「Evaluating AI Agents」の教育コースまで提供している。評価をどう自動化・標準化するかは、2026年後半から2027年にかけてLLMOpsの中心テーマであり続けるだろう。
第二に、エージェント評価とAgentOpsの主流化である。前述のとおりAgentOpsは2026年に独立した規律として立ち上がり、その共通言語としてOpenTelemetryのGenAI/agenticセマンティック規約の採用が広がる。Laminarのシードに、OpenTelemetry共同開発者のBen Sigelmanがエンジェルとして名を連ねたのは象徴的だ。ルールベースの検証と小型モデルによる審査を組み合わせ、安価に本番トラフィックの100%をカバーする——といった実装パターンが推奨として定着しつつある。GoogleがGEAPで継続的なオンライン評価やAgent Optimizerを標準搭載し、DatabricksがAgent Bricksで評価とガバナンスを束ねたように、エージェントの「働きぶりの計測」はプラットフォームの標準機能へと組み込まれていく。
第三に、需要側の最大の伸びしろは「観測なき本番」の解消にある。エージェントが本番に出る一方で、適切な評価まで実装しているチームはまだ一部にとどまり、Bessemerが指摘する「失敗の78%が不可視」というギャップは大きい。裏を返せば、いまきちんと計測するチームは不当なほどの優位を得られる局面であり、この需要が専業ツールとプラットフォーマー双方の成長を支える。
統合の流れは2026年後半以降も続くと見るのが自然だ。Sapphireの予測する大型買収、Datadog型APMによる機能取り込み、ハイパースケーラーの内蔵化——これらが重なり、独立系LLMOpsベンダーには「特定の評価・エージェント観測領域で唯一無二の深さを持つ」か「より大きなスタックに統合される」かの二択がいっそう鮮明になるだろう。LLMOpsはもはやニッチな運用ツールではなく、生成AIという2.5兆ドル(約375兆円)規模の投資フロー全体の信頼性を担保する基幹レイヤーへと位置づけを変えた。Langfuse、LangSmith、Helicone、Databricksといった名前が示すのは、その基幹レイヤーをめぐる主導権争いが、2026年にいよいよ本格化したという事実である。