ローカルLLMとは何か——クラウドに頼らないAI推論
ローカルLLM(Local Large Language Model)とは、クラウドサーバーに依存せず、手元のPC、サーバー、またはエッジデバイス上でLLM(大規模言語モデル)を直接実行する技術・運用形態を指す。
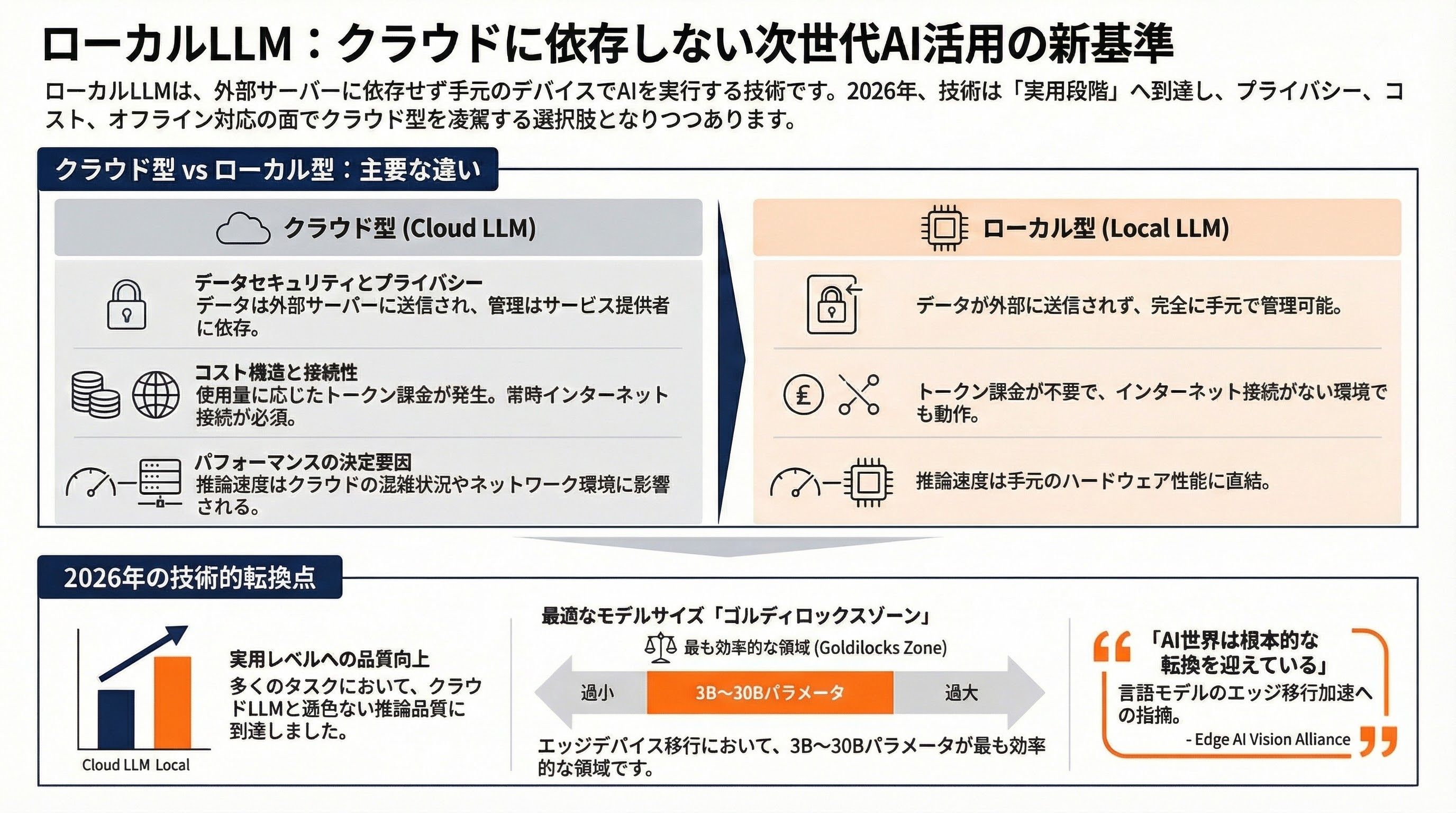
クラウドAPI経由のLLM利用(OpenAI GPT、Anthropic Claude、Google Gemini等)は、モデルの能力を最大限に引き出せる反面、データが外部サーバーに送信される、トークンごとに課金される、インターネット接続が必須、レイテンシが発生するといった制約がある。ローカルLLMはこれらの制約を全て解消する。データは手元のマシンから出ず、トークン課金は発生せず、オフラインでも動作し、推論速度はハードウェアの性能に直結する。
2026年に入り、ローカルLLMは「技術的に可能だが実用には遠い」段階から「多くのタスクでクラウドLLMと遜色ない品質で動作する」段階へと到達した。Edge AI Vision Allianceは2026年4月のレポートで次のように述べている。
「AI世界は根本的な転換を経験している。言語モデルのエッジデバイスへの移行が加速しており、3B〜30Bパラメータが『ゴルディロックスゾーン』だ。」
実行環境の全体像——Ollama、LM Studio、vLLM、llama.cpp、MLX
ローカルLLMを実行するためのツールは、用途と技術レベルに応じて複数の選択肢がある。
Ollama——ローカルLLMの「Docker」
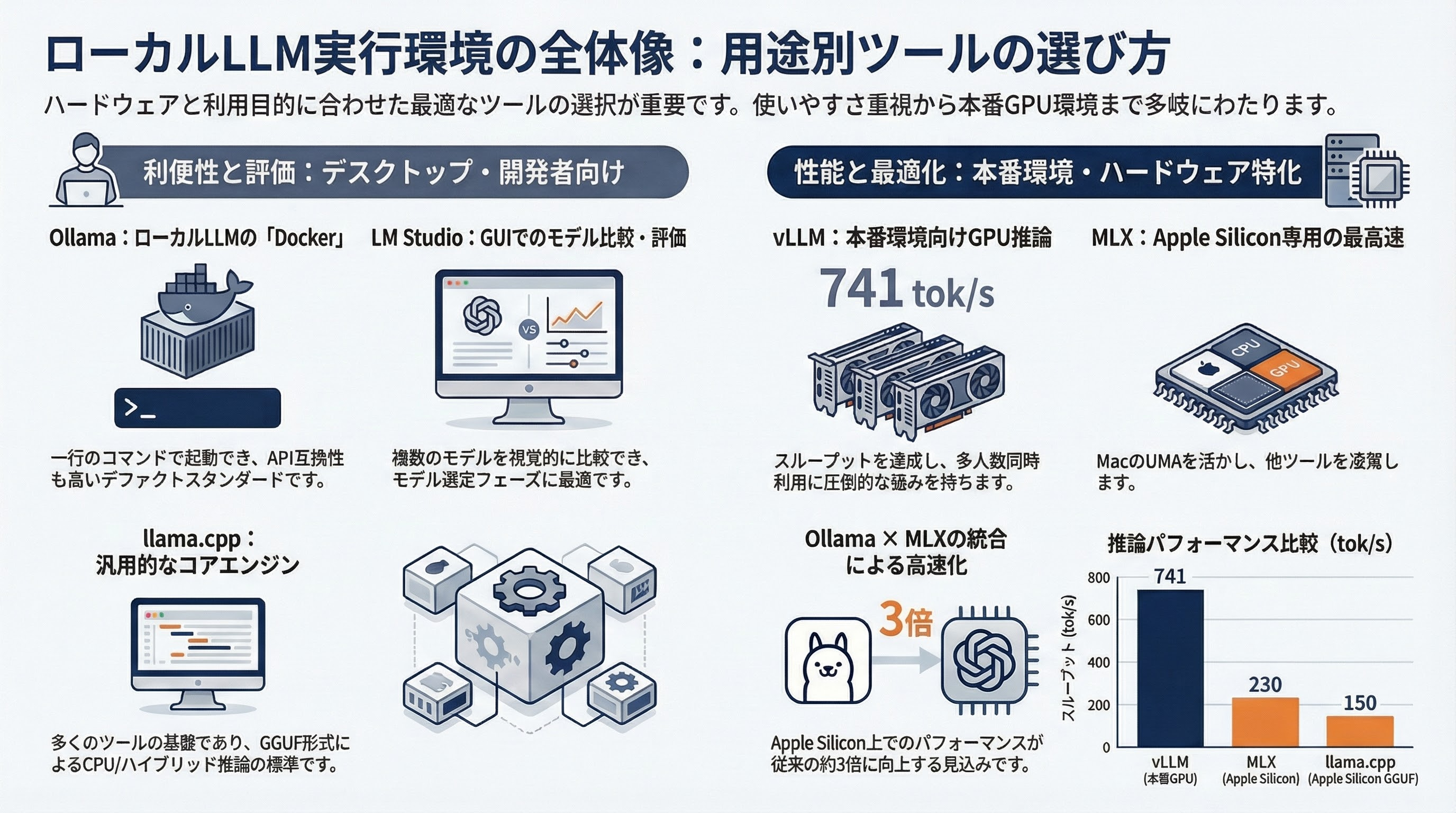
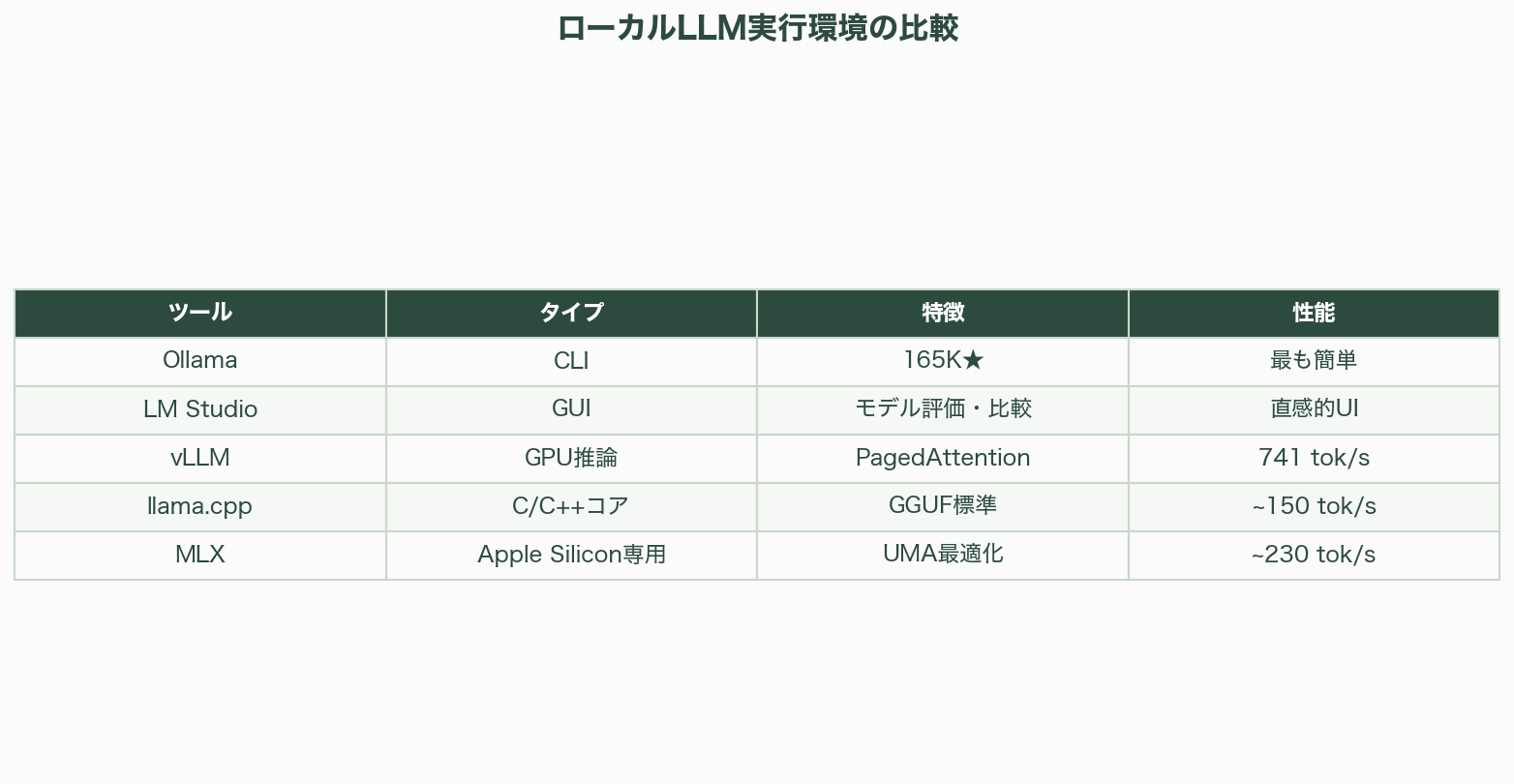
Ollama(GitHub 16.5万スター超)は、ローカルLLMのデファクトスタンダードだ。ollama run gemma4:31bの一行で最新モデルを起動でき、OpenAI互換のREST APIを提供する。内部ではllama.cppをラップし、ストリーミング、ツールコール、Thinkingモードに対応する。
2026年3月、OllamaはApple SiliconでのバックエンドにMLXフレームワークを統合する計画を発表した。これにより、Mac上の推論パフォーマンスが従来の約3倍に向上する見込みだ(Qwen3-Coder-30BでMLX 130 tok/s vs Ollama 43 tok/s)。Y Combinator出身で、Sunflower Capital、Essence VCから50万ドルを調達している。
LM Studio——GUIでモデルを比較・評価
LM StudioはGUIベースのモデル評価プラットフォームだ。モデルのブラウズ、ダウンロード、サイドバイサイド比較が視覚的に行える。v0.3.5では「Local LLM Service」ヘッドレスモードが追加され、GUIなしのバックグラウンドサーバーとしても動作する。複数モデルの評価・選定フェーズに最適だ。
vLLM——本番環境のGPU推論エンジン
vLLM(v0.16.0)は、GPUベースの本番環境向け推論エンジンだ。PagedAttentionによるメモリ効率の高いKVキャッシュ管理、連続バッチング、投機的デコーディングを実装する。NVIDIA、AMD ROCm、Intel XPU、TPUのマルチプラットフォームに対応し、AWQ + Marlinカーネルで741 tok/sのスループットを達成する。同時5ユーザー以上の環境でOllamaを圧倒する。
llama.cpp——C/C++のコア推論エンジン
llama.cppは、Ollamaをはじめ多くのローカルLLMツールの基盤となるC/C++推論エンジンだ。GGUFフォーマットはCPU/ハイブリッド推論のデファクトスタンダードとなり、Apple Siliconで約150 tok/sを達成する。2026年にはAMD GPUアクセラレーションも実用レベルに達した。
MLX——Apple Silicon専用フレームワーク
Appleが開発したオープンソースの配列フレームワークMLXは、Apple Siliconのユニファイドメモリアーキテクチャ(UMA)に最適化されている。CPUとGPUが同一アドレス空間を共有するため、データ転送のオーバーヘッドがゼロだ。Apple Silicon上の推論で約230 tok/sを達成し、llama.cpp(約150 tok/s)やOllama(20〜40 tok/s)を大きく上回る。M5 Neural AcceleratorsではM4比で最初のトークン生成までの時間(TTFT)が4.06倍高速化された。
量子化——巨大モデルを手元のマシンに収める技術

ローカルLLMを実用的にする鍵が量子化(Quantization)だ。モデルの重みを32ビット/16ビット浮動小数点から4ビット/8ビット整数に圧縮し、メモリ使用量と推論速度を劇的に改善する。
主要な量子化フォーマット
GGUFはCPU/ハイブリッド推論のデファクトスタンダードだ。7Bモデルを4ビット量子化すると約3.5GB(75%削減)に圧縮され、元のモデルの92〜95%の品質を保持する。Q4_K_M量子化はMMLUベンチマークで1〜3ポイント以内の精度低下に収まり、多段階数学推論など特殊なタスクでのみ5%以上の劣化が見られる。
AWQ(Activation-aware Weight Quantization、MIT発)は、全重みの1%未満が「顕著(salient)」であるという発見に基づく。顕著な重みを保護しながら圧縮することで、95%の品質を保持しつつ、Marlinカーネルで基準比1.6倍の高速化を実現する。
GPTQはHessian行列を用いた最初の4ビット圧縮手法で、CUDAでの生スループットに優れる。
2026年時点の品質保持率は AWQ 95% > GGUF 92% > GPTQ 90% だ。
Gemma QAT——訓練時量子化の革新
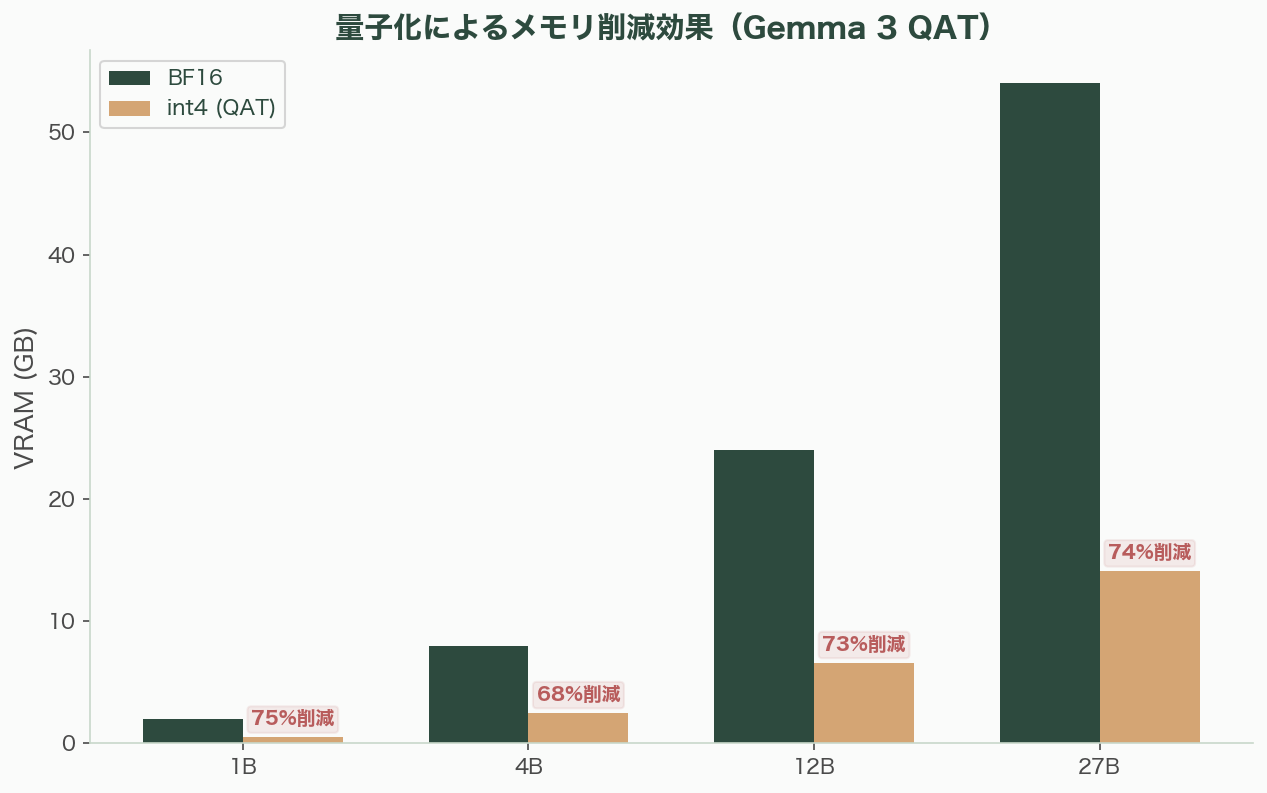
Google DeepMindが導入したQuantization-Aware Training(QAT)は、従来のPost-Training Quantization(PTQ)とは根本的に異なるアプローチだ。量子化をモデル訓練の過程に組み込み、約5,000ステップのファインチューニングで量子化誤差を学習させる。結果、Q4_0量子化でのパープレキシティ低下をPTQ比で54%削減した。
具体的なメモリ効果は劇的だ。Gemma 3 27BのVRAMは、BF16で54GBだったものがint4で14.1GBに圧縮される。12Bは24GBから6.6GBへ、4Bは8GBから2.6GBへ、1Bは2GBから0.5GBへ。これにより、27BクラスのモデルがコンシューマーグレードのGPU(RTX 4070程度)で動作可能になった。
Gemma 4——オープンモデルの新たな頂点

2026年4月2日、Google DeepMindのClement Farabetが執筆した公式ブログでGemma 4が発表された。Gemmaファミリーの第3世代は、アーキテクチャ、性能、ライセンスの全てにおいて跳躍的な進化を遂げた。
4つのモデルバリアント
Gemma 4は4つのバリアントで構成される。
E2Bはエッジデバイス向けの最小モデルだ。2.3Bのアクティブパラメータ(総パラメータ5.1B)で、128Kコンテキストウィンドウを持つ。テキスト、画像、音声のマルチモーダル入力に対応し、4ビット量子化で1.5GB以下に収まる。Per-Layer Embeddings(PLE)技術により、2.3Bのアクティブパラメータが5.1B相当の表現深度を持つ。
E4Bは4.5Bアクティブパラメータ(総パラメータ8B)で、128Kコンテキスト。テキスト、画像、音声に対応する。
26B A4B(MoE)はMixture-of-Experts(MoE)アーキテクチャを採用し、総パラメータ26Bのうち3.8Bのみがアクティブ化される。256Kコンテキストウィンドウを持ち、LMArenaでオープンモデル世界第6位(スコア1441)を記録した。フルモデルの1/7以下の計算量で動作する。
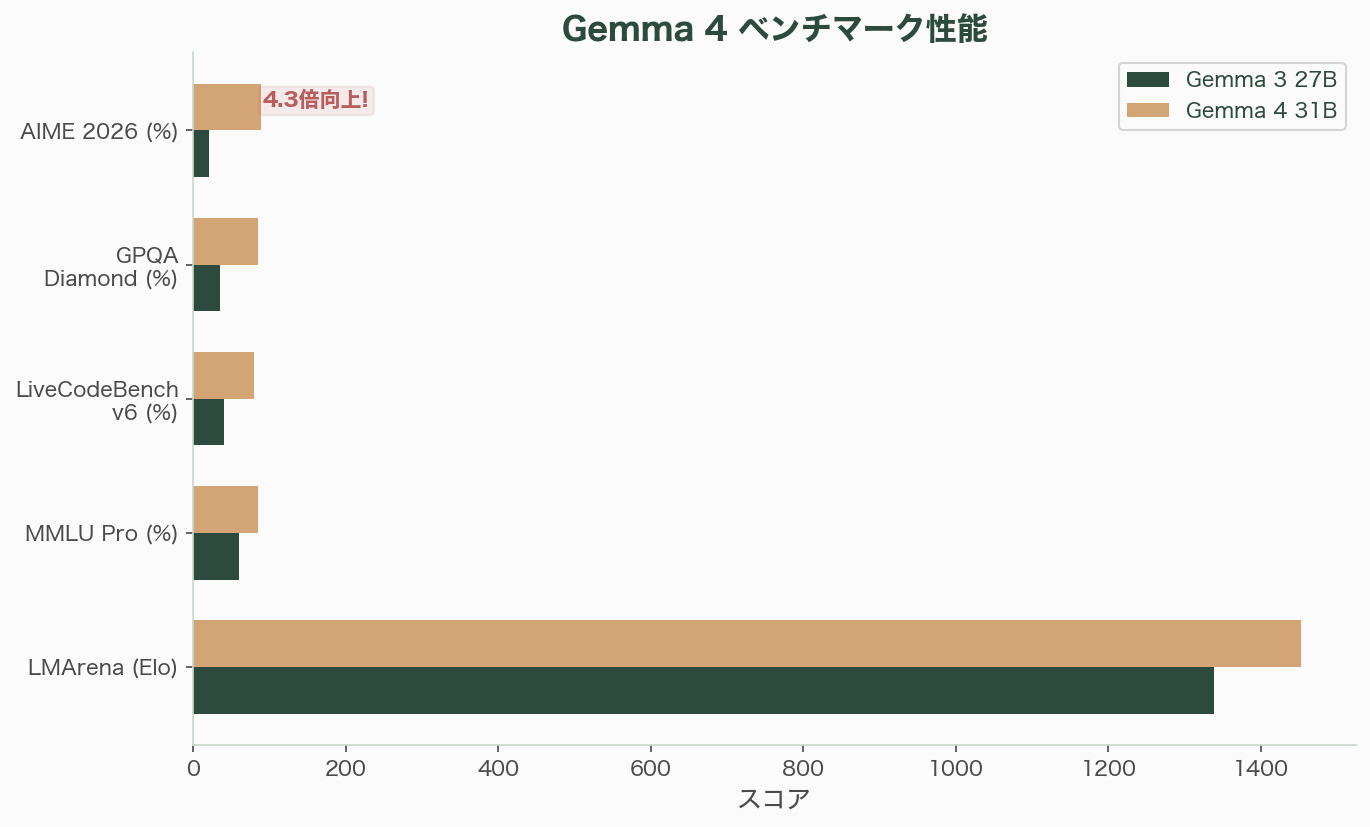
31B(Dense)は高密度モデルで、31Bの全パラメータが推論に使用される。256Kコンテキストウィンドウ。LMArenaでオープンモデル世界第3位(スコア1452)を記録し、AIME 2026で89.2%、GPQA Diamondで84.3%、LiveCodeBench v6で80.0%、Codeforces ELOで2150を達成した。
Gemma 3からの進化
Gemma 4の進化は数字で語る方がわかりやすい。AIME(数学推論)のスコアは、Gemma 3 27Bの20.8%からGemma 4 31Bの89.2%へ——4.3倍の改善だ。これは量的改善ではなく質的変化である。
マルチモーダル対応もテキスト+画像(Gemma 3)からテキスト+画像+音声(Gemma 4 E2B/E4B)へと拡張された。コンテキストウィンドウは128Kから256K(26B/31B)に倍増。ネイティブの関数呼び出しとExtended Thinking(拡張思考)モードも追加された。
そして最大の変更はライセンスだ。Gemmaファミリーは従来独自のカスタムライセンスを使用していたが、Gemma 4で初めてApache 2.0に移行した。Hugging Face CEOのClement Delangueはこれを「巨大なマイルストーン」と評し、「ローカルAIの時代が来た。これはAI産業の未来だ」と宣言した。
アーキテクチャの革新
Per-Layer Embeddings(PLE)は、Gemma 4で導入された新技術だ。各層に専用のエンベディングを持たせることで、E2B(2.3Bアクティブ)が5.1B総パラメータの表現深度を維持しながら、推論時の計算量は2.3B相当に抑えられる。これにより、4ビット量子化で1.5GB以下という超軽量性と、同サイズモデルを超える性能の両立が実現した。
ハイブリッドアテンションは、ローカルスライディングウィンドウ(512/1024トークン)とグローバルフルコンテキストアテンションを交互に配置する。短いコンテキストでの高速推論と、256Kの長大なコンテキストでの情報保持を両立する。共有KVキャッシュによりメモリ効率をさらに最適化する。
主要オープンモデルとの比較——Gemma 4はどこに立つのか
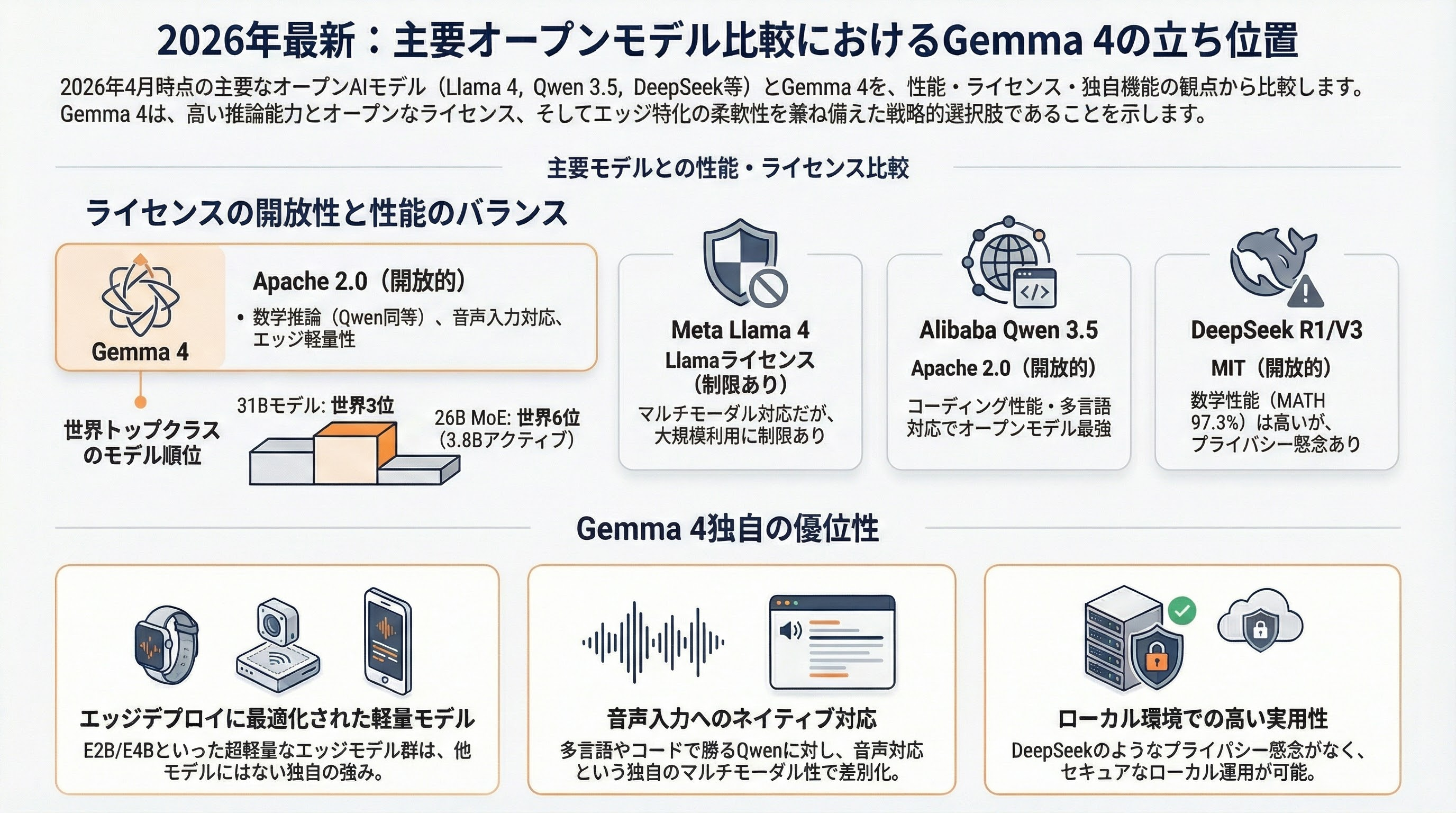
2026年4月時点で、ローカルデプロイ可能な主要オープンモデルを比較する。
Meta Llama 4はScout(17Bアクティブ/109B総、16エキスパートMoE、1,000万トークンコンテキスト)とMaverick(17Bアクティブ/400B総、128エキスパート、100万コンテキスト)を提供する。テキスト+画像のマルチモーダルに対応するが、ライセンスはLlamaライセンス(月間7億アクティブユーザー超の場合は特別ライセンスが必要)であり、Apache 2.0のGemma 4より制約が多い。
Alibaba Qwen 3/3.5は0.6Bのエッジモデルから235B MoEのフラッグシップまでを提供し、Apache 2.0ライセンスだ。250Kの語彙サイズと201言語対応で多言語性能に優れ、GPQA Diamond 77.2%、AIME'24 85.7%を達成。コーディング性能ではオープンモデル最強だ。
DeepSeek R1/V3はMATH-500で97.3%を達成し、MITライセンスで最もオープンだ。ただし、API利用時のデータが中国のサーバーを経由するプライバシー懸念があり、ローカルデプロイが特に推奨される。
Microsoft Phi-4はMATHベンチマークで80.4%を達成し、小フットプリントに特化する。
MistralはMinistral 3シリーズ(3B/8B/14B、Apache 2.0)、Mistral Small 4(119B総/6Bアクティブ、MoE)、Devstral Small 2(24B、SWE-bench Verified 68.0%)を提供する。
Gemma 4の競争ポジションは明確だ。31Bはオープンモデル世界第3位、26B MoEはわずか3.8Bアクティブパラメータで第6位。数学推論はQwen 3.5と同水準。ライセンスはApache 2.0でQwenと同等、Llamaより開放的。コーディングと多言語ではQwen 3.5に劣るが、エッジモデル(E2B/E4B)の軽量性と音声入力対応はGemma 4のユニークな強みだ。

具体的な活用シーンと実証事例

プライバシーとデータ主権
ローカルLLMの最大の価値は、データが手元から出ないことだ。GDPRの越境データ移転問題を根本的に解消し、完全な監査証跡管理を実現する。欧州企業にとっては、米国CLOUD法のリスクを排除する手段でもある。エアギャップ環境での展開は、防衛、エネルギー、航空の各分野で不可欠だ。
コスト効率
オープンウェイトモデルのローカル実行は、クラウドAPIと比較して最大18倍のコスト効率を実現する。あるFinTechの事例では、月額AI支出が47,000ドルから8,000ドルに削減された(83%削減)。損益分岐点は約200万トークン/日で、4ヶ月でROIを回収する。
Googleは「トークン税」という概念を提示した——「常時稼働のバックグラウンドエージェントが生成する全トークンに対してクラウドプロバイダーに課金されることは、財務的に持続不可能だ。」ローカルLLMはこのトークン税を完全に排除する。
エンタープライズ導入の現状
エンタープライズのAI推論の55%が既にオンプレミス/エッジで実行されている(2023年の12%から急増)。2026年までに80%以上の企業が生成AIを統合する見通しだ。ローカル実行の平均レスポンス時間は、クラウドの1.5秒から40ms未満に短縮される。
コーディングアシスタント
Continue(GitHub 2万スター超)、Tabby(セルフホスト型)、OpenCode CLIなど、Ollamaやローカルモデルをバックエンドとするコーディングアシスタントが急増している。Simon Willisonは「2026年はLLM生成コードの品質が『否定しようがない』レベルになる年だ。手書きのコードは自分の出力のうちごくわずかになった」と述べている。
ヘルスケア
三重大学病院ではNTT西日本と共同で、NTTのtsuzumiを用いた看護・医師記録の要約化を実施している。HIPAA準拠のオフラインLLMが患者との対話を分析し、プライバシーを完全に保護する。
金融
みずほフィナンシャルグループとSB Intuitionsは金融特化LLMを共同開発中。MUFGとSakana AIは進化的モデルマージ技術で金融AI連携を進める。アルゴリズミックトレーディングでは、インターネットレイテンシを排除するローカル推論が不可欠だ。
ハードウェア——何でどのモデルが動くか

NVIDIA RTX 5090
21,760 CUDAコア、32GB GDDR7、1,792 GB/s帯域幅。MSRP 1,999ドル。バッチサイズ8で5,841 tok/sを達成し、A100を2.6倍上回る。量子化済み70Bモデルを快適に実行し、デュアルRTX 5090ではH100相当の性能を発揮する。
NVIDIA DGX Spark
GB10 Grace Blackwell Superchip搭載、128GBユニファイドメモリ。Gemma 4 31BをBF16で量子化なしに実行可能。
Apple Silicon M4 Max
546 GB/sメモリ帯域幅。128GB構成でQwen3.5-35B-A3Bを130 tok/s(MLX経由)で実行。M5 Neural AcceleratorsではTTFTが4.06倍高速化。
Gemma 4のハードウェア要件
E2Bは4ビット量子化で4GB、E4Bは5GB、26B MoEは18GB(4ビット)/28GB(8ビット)、31Bは20GB(4ビット)/34GB(8ビット)。E2BとE4Bはスマートフォンでも動作可能な軽量性だ。
日本の動向——デジタル庁と国産LLM
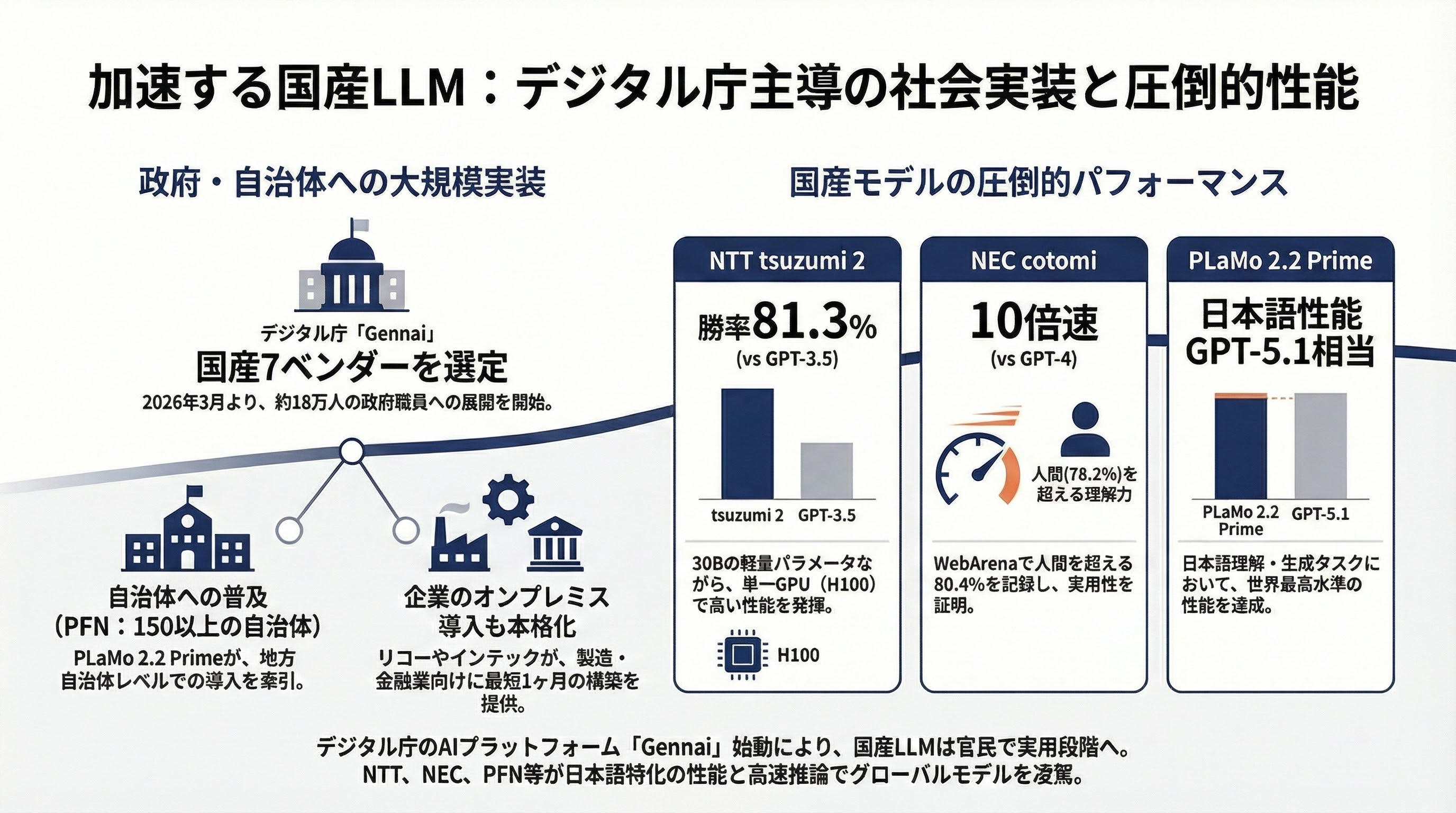
日本のローカルLLM展開は、政府主導で急速に進んでいる。
デジタル庁は2026年3月、政府職員向けAIプラットフォーム「Gennai」に7つの国産LLMベンダーを選定した。tsuzumi 2(NTT)、ELYZA Llama-3.1-JP-70B(KDDI)、PLaMo 2.0 Prime(PFN)、cotomi v3(NEC)などが約18万人の政府職員への展開を開始する。
NTT tsuzumi 2は30Bパラメータで単一H100で動作し、GPT-3.5に対して81.3%の勝率を記録。NEC cotomiはGPT-4比10倍の高速推論を実現し、WebArena 80.4%で人間の78.2%を超えた。PFN PLaMo 2.2 Prime 31BはJFBenchでGPT-5.1相当の日本語性能を達成し、150以上の自治体で導入されている。
企業では、リコーの「RICOH オンプレLLMスターターキット」が2025年日経優秀製品・サービス賞最優秀賞を受賞。インテックは2026年1月からオンプレミスLLM導入支援を開始し、製造業・金融業向けに最短1ヶ月での構築を提供する。
Gemma 4の日本語性能も注目に値する。東京科学大学のGemma-2-Llama Swallowは同サイズLLMで日本語理解・生成タスク最高性能を達成している。Gemma 4の140言語以上のサポートとCJKトークナイザーの大幅改善により、日本語ローカルLLMの実用性はさらに向上する。
残る課題と制約
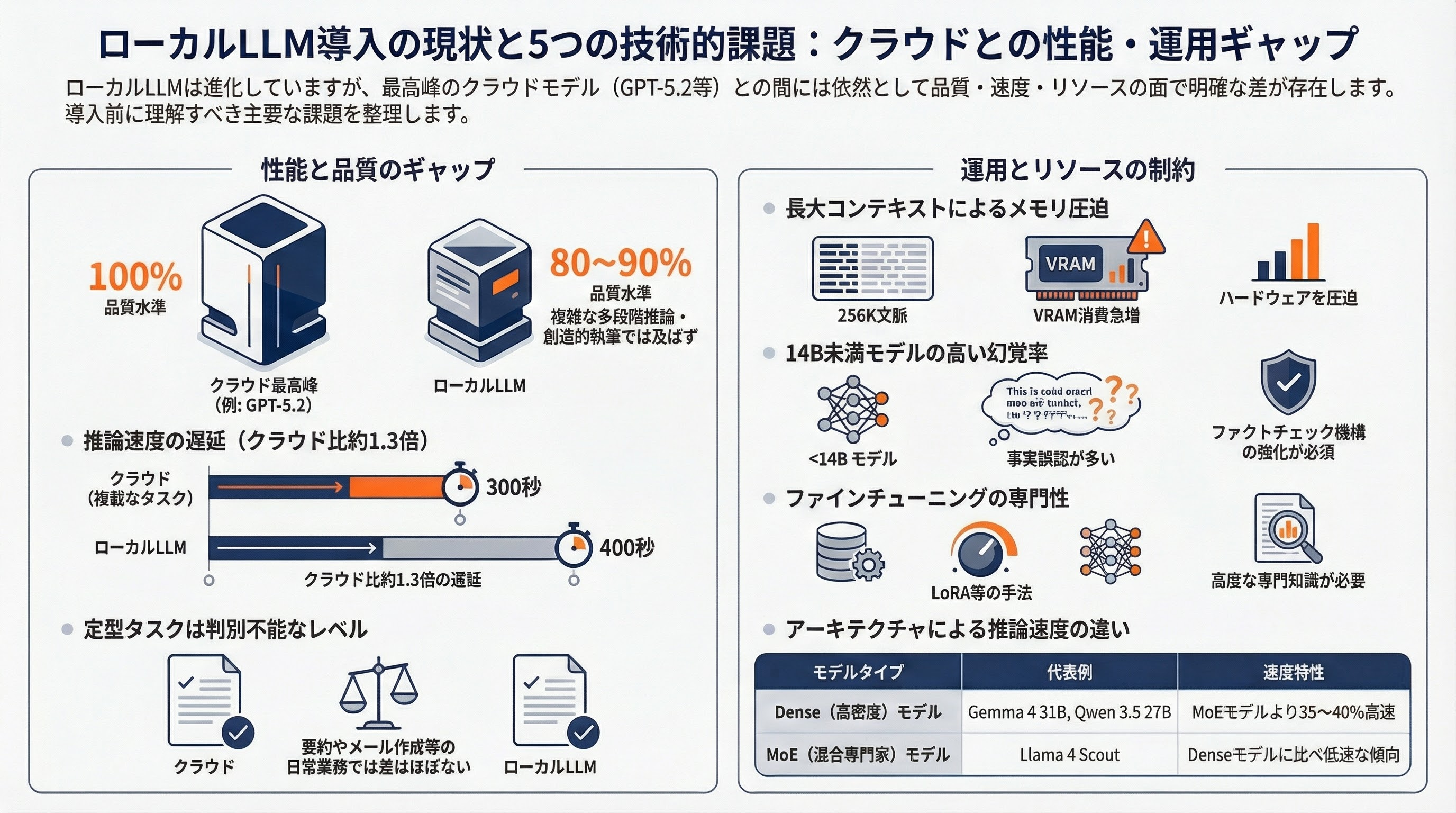
ローカルLLMの進歩は目覚ましいが、課題も残る。
品質ギャップは縮小しているが存在する。最良の14Bモデルでも、GPT-5.2やClaude Opus 4.6の80〜90%の品質に留まる。ギャップが最も顕著なのは複雑な多段階推論と創造的ライティングだ。ただし、日常的なタスク(コード補完、要約、メール作成、Q&A)では「ブラインドテストでほとんどのユーザーが違いを判別できない」レベルに達している。
推論速度はクラウドLLMに及ばない。複雑なタスクでクラウドLLMが約300秒、ローカルSLMが約400秒。Dense模型(Gemma 4 31B、Qwen 3.5 27B)はMoEモデル(Llama 4 Scout)より35〜40%高速だ。
コンテキストウィンドウのメモリスケーリングは長大なコンテキストで問題となる。31B Gemma 4を256Kコンテキストで使用すると、大量のVRAMを消費する。
ファインチューニングは依然として専門知識と計算リソースを要する。LoRA/QLoRAにより敷居は下がっているが、最適なハイパーパラメータの選定やデータ準備は非自明だ。
幻覚(ハルシネーション)率は小型モデルほど高い傾向がある。特にサブ14Bモデルではファクトチェック機構の強化が必要だ。
VCの視点——エッジAIに賭ける投資マネー
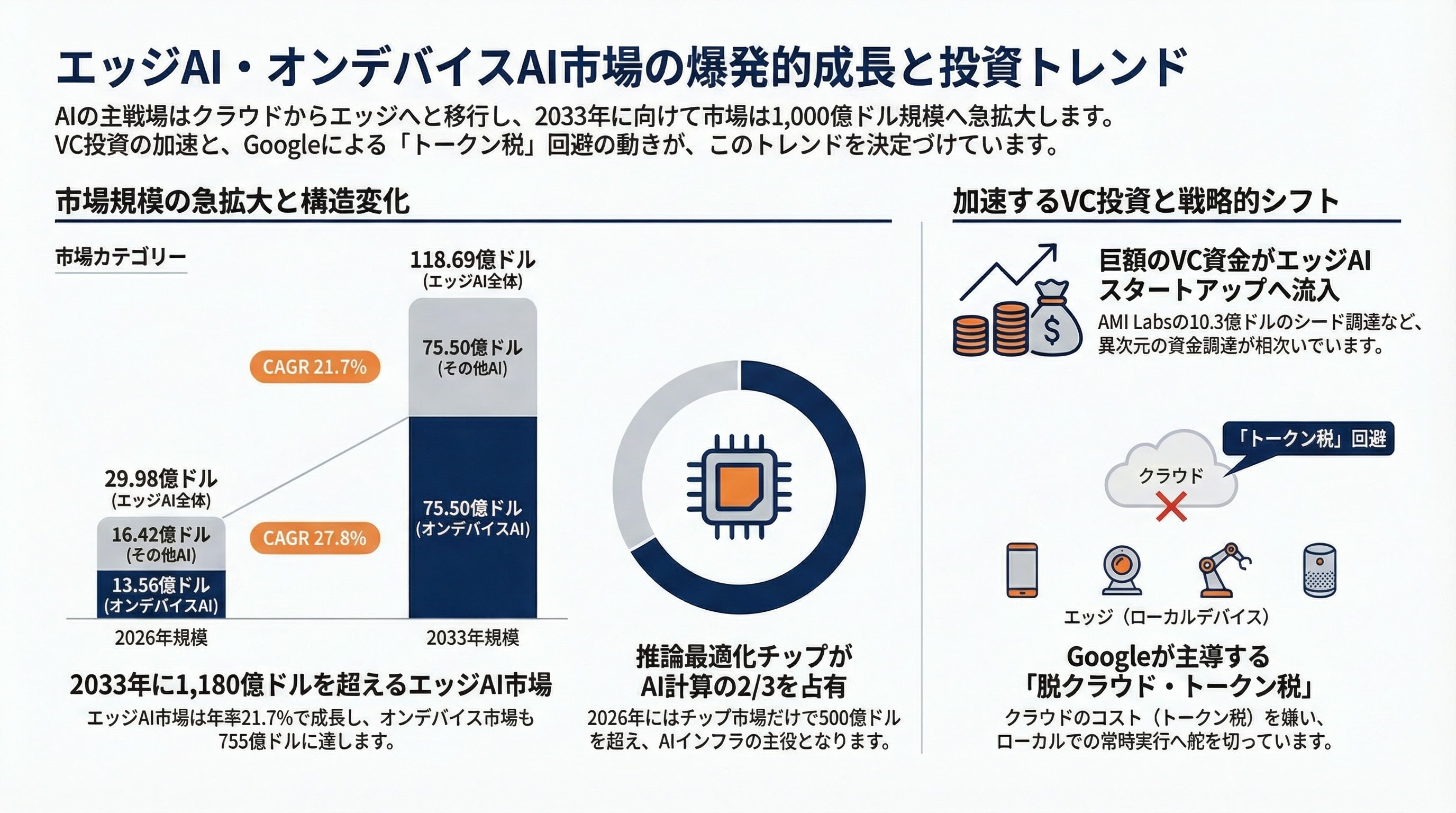
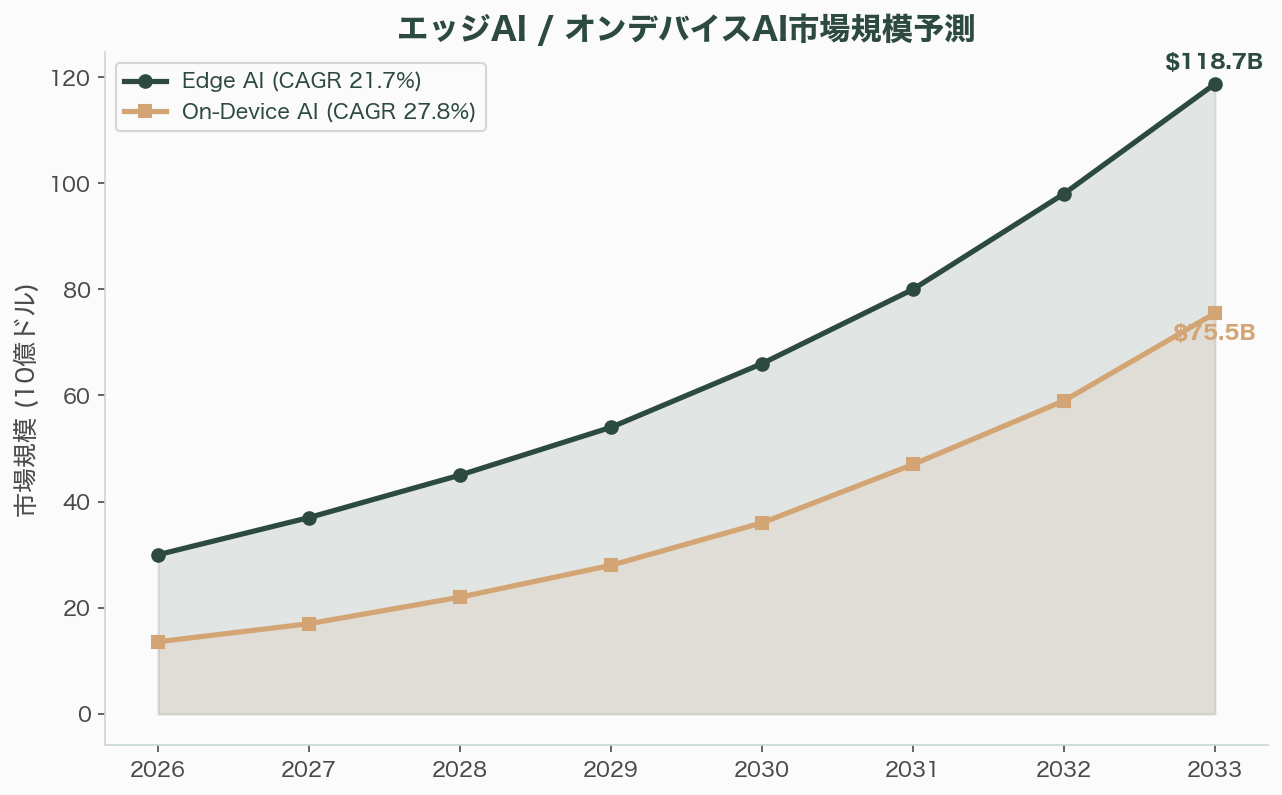
オンデバイスAI市場は2026年の135.6億ドルから、年率27.8%で2033年に755億ドルに成長する見通しだ。エッジAI市場は2026年の299.8億ドルから年率21.7%で2033年に1,186.9億ドルに達する。推論最適化チップだけで2026年に500億ドル以上の市場を形成し、全AIコンピュートの約2/3を占める。
VC投資も加速している。d-Matrix(インメモリコンピューティング)がシリーズCで2.75億ドル、Mythic(アナログ処理ユニット)が1.25億ドル、Yann LeCunのAMI Labsが10.3億ドルのシードラウンドを獲得。2025年にはAIスタートアップ全体で894億ドルのVC資金が流入し、2026年のAIファウンデーションモデルへの投資はQ1だけで前年比2倍に達した。
Googleが「トークン税」を問題提起し、エッジデバイス上でのAIエージェント常時実行を推進していることは、クラウドAIの覇者であるGoogle自身がローカルAIの未来を認めている証左だ。
将来の見通し——2026年はローカルLLM元年になるか
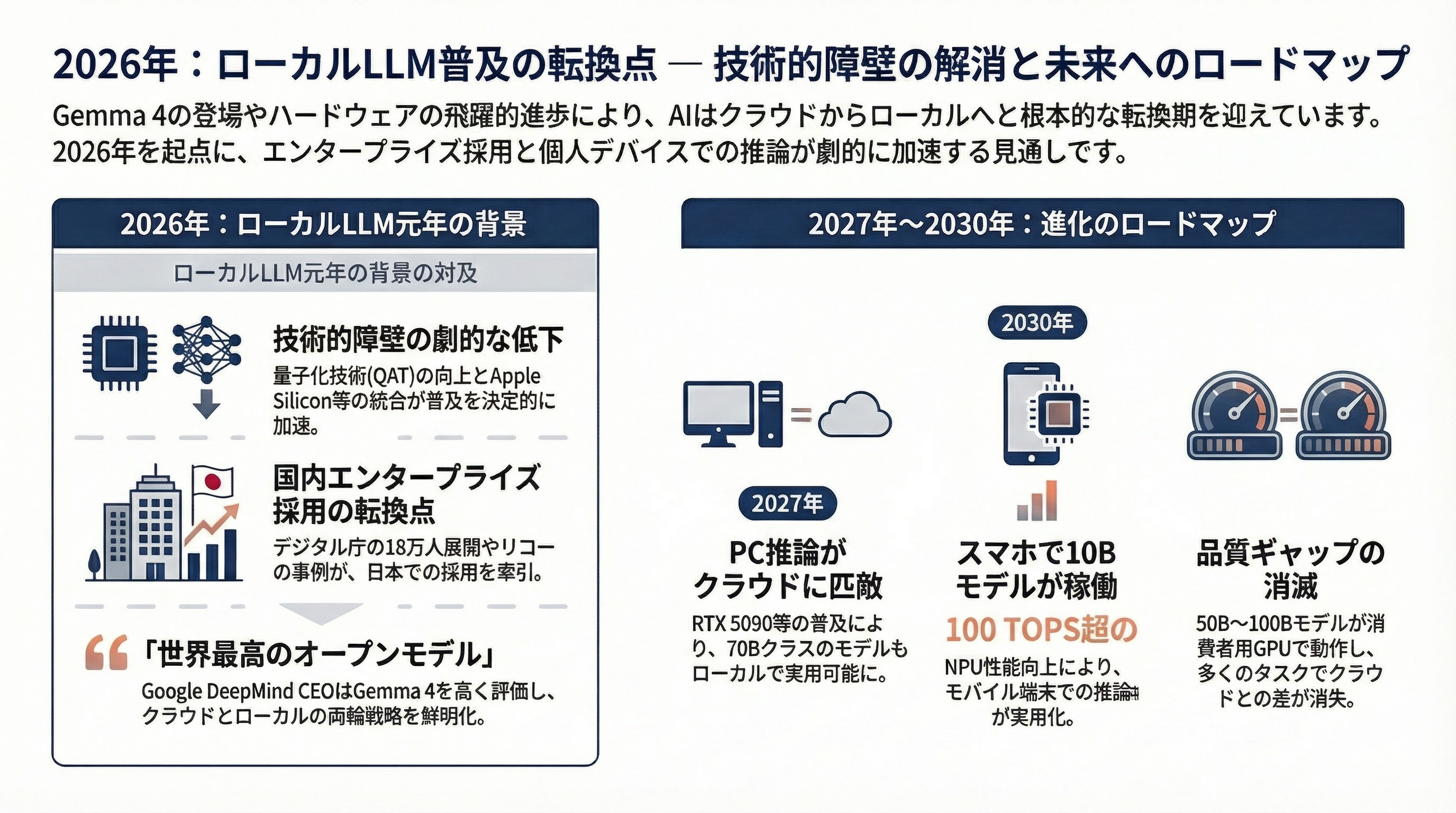
ポジティブな見通しとして、Gemma 4のApache 2.0化とE2Bの超軽量性は、ローカルLLMの普及を決定的に加速する。QATによる量子化品質の向上、MLXとApple Siliconの統合、vLLMの本番環境対応は、技術的障壁を大幅に引き下げた。デジタル庁の18万人展開とリコーの受賞は、日本におけるエンタープライズ採用の転換点だ。
Google DeepMind CEOのDemis Hassabisは、Gemma 4を「それぞれのサイズで世界最高のオープンモデル」と評した。この発言は、Googleがクラウドサービス(Gemini API)とローカルモデル(Gemma)の両輪戦略を本格化させていることを示す。
2026年後半〜2027年: Gemma 4の31BとE2Bが広く普及し、Ollama + MLXの統合によりMacでの推論パフォーマンスがクラウドAPIに迫る。NVIDIA RTX 5090とDGX Sparkの普及により、70Bクラスのモデルもローカルで実用的に。
2028年〜2030年: 50B〜100Bのモデルが4ビット量子化でコンシューマーGPU上で動作するようになり、品質ギャップは多くのタスクで消滅。NPUの性能向上(100 TOPS超)により、スマートフォン上での10B級モデル推論が実用化。
Edge AI Vision Allianceの言葉を借りれば、「AIの世界は根本的な転換を経験している」。2026年が「ローカルLLM元年」として記憶されるかどうかは、Gemma 4の普及速度、Apple SiliconとNVIDIAの推論パフォーマンス競争、そしてエンタープライズ採用の加速度にかかっている。しかし、技術的にはその条件は既に整った。
業界への影響
第一に、Gemma 4のApache 2.0化は、オープンモデルのライセンス競争を新たなフェーズに押し上げた。Qwen(Apache 2.0)、Gemma 4(Apache 2.0)、DeepSeek(MIT)に対し、Llama(独自ライセンス)は制約の多さで不利に立つ。商用利用の自由度がモデル選択の決定的な要因となりつつある。
第二に、ローカルLLMの品質がクラウドLLMの80〜90%に達したことで、「全てのAI推論をクラウドで行う」というデフォルトの前提が崩れている。特にプライバシー要件の高い金融・医療・政府機関では、ローカルデプロイがファーストチョイスになりつつある。
第三に、Googleの「トークン税」問題提起は、AIエージェントの常時実行コストに関する業界全体の議論を喚起した。クラウドAPI課金モデルは、散発的なクエリには合理的だが、24時間365日稼働するエージェントには経済的に成り立たない。この認識は、ローカルLLMの採用を加速させる。
第四に、日本のデジタル庁による国産LLM7ベンダー選定と18万人展開は、政府機関のAI採用として世界的にも先進的だ。リコーのオンプレLLMスターターキットの受賞は、エンタープライズ市場での実装が商業的に成功し得ることを証明した。
第五に、Apple Silicon + MLXの組み合わせは、Macを「AIワークステーション」に変える可能性を持つ。M4 Max 128GBで30Bクラスのモデルを130 tok/sで実行できるという事実は、開発者のワークフローを根本的に変え得る。NVIDIAのRTX 5090やDGX Sparkとの推論パフォーマンス競争は、ハードウェア市場にも新たな競争軸をもたらす。
参考情報: Google Blog「Gemma 4」(2026/4/2), Google DeepMind「Gemma 4 Models」, Hugging Face Blog「Welcome Gemma 4」, The Decoder「Gemma 4 Apache 2.0」, 9to5Google「Gemma 4」, NVIDIA Blog「RTX AI Garage - Gemma 4」, Demis Hassabis「best open models in the world」, Clement Delangue (Hugging Face CEO)「Local AI is having its moment / future of the AI industry」, Edge AI Vision Alliance「On-Device LLM Revolution: 3B-30B Models Moving to Edge」(2026/4), Ollama Blog (v0.18.0, MLX Integration, 165K+ GitHub Stars), LM Studio v0.3.5 Local LLM Service, vLLM v0.16.0 (PagedAttention, AWQ + Marlin 741 tok/s), llama.cpp GGUF Format, Apple MLX Framework (230 tok/s Apple Silicon), Apple Machine Learning Research「Exploring LLMs on M5」, macgpu.com「Mac Inference Framework Benchmark 2026」, Google Developers Blog「Gemma 3 QAT」, Prem.ai「LLM Quantization Guide 2026: GGUF vs AWQ vs GPTQ」, LocalLLM.in「Quantization Explained」, Unsloth「Gemma 4 31B GGUF」, Grand View Research「On-Device AI Market」($13.56B 2026 → $75.5B 2033), Crunchbase「AI Funding Q1 2026」, Accrets「On-Premise LLM ROI」(18x cheaper, 4-month ROI), MarkTechPost「Defeating the Token Tax: Gemma 4 + NVIDIA」(2026/4/2), ai.meta.com「Llama 4」, Mistral「Mistral Small 4」, SitePoint「Best Local LLMs 2026」, ai.rs「Gemma 4 vs Qwen 3.5 vs Llama 4」, Simon Willison「LLM Predictions 2026」, RunPod「RTX 5090 LLM Benchmarks」, localaimaster「NPU Comparison 2026」, CraftRigs「Gemma 4 Hardware Requirements」, d-Matrix $275M Series C, Mythic $125M, デジタル庁「Gennai」国産LLM 7ベンダー選定 (Impress Watch, 2026/3), リコー「RICOH オンプレLLMスターターキット」日経優秀製品・サービス賞最優秀賞 (2025), インテック ローカルLLM導入支援 (2026/1), NTT tsuzumi 2 (30B, 単一H100, GPT-3.5比81.3%勝率), NEC cotomi (GPT-4比10倍高速, WebArena 80.4%), PFN PLaMo 2.2 Prime 31B (JFBench GPT-5.1相当, 150+自治体導入), Google DeepMind「Gemma-2-Llama Swallow」(東京科学大学), みずほ + SB Intuitions 金融特化LLM, MUFG + Sakana AI モデルマージ, DevelopersIO「2026年のローカルLLM事情」, Label Your Data「LLM Model Size」, Enclave AI「Quantization Explained GGUF Guide」