GPUの起源——ゲーミングからAIの支配者へ
NVIDIAのGPUがAI半導体の代名詞となるまでの道のりは、一人の起業家の先見性と、いくつかの歴史的転換点によって形作られた。
1993年、Jensen Huang、Chris Malachowsky、Curtis Priemがカリフォルニア州サンタクララでNVIDIAを創業した。当初の事業はPCゲーム向けのグラフィックスチップだった。1999年にGeForce 256を発売し、「GPU(Graphics Processing Unit)」という用語を生み出したのもNVIDIAだ。2000年代前半はATI(後のAMD)とゲーミングGPU市場で激しいシェア争いを繰り広げていた。
最初の転換点は2006年、CUDA(Compute Unified Device Architecture)のリリースだ。CUDAは、本来グラフィックス描画に特化していたGPUの数千コアを、汎用的な並列計算に使えるプログラミングモデルとして提供した。C言語ライクなコードでGPUの並列性を活用できるようになり、科学計算や物理シミュレーションの研究者が飛びついた。この時点では、誰もCUDAがAI産業の「堀(moat)」になるとは想像していなかった。
第二の転換点は2012年、「AlexNetの衝撃」だ。Alex Krizhevsky、Ilya Sutskever、Geoffrey HintonがImageNetコンペティションで、2枚のGTX 580 GPUを使って訓練した畳み込みニューラルネットワーク「AlexNet」で圧勝した。画像認識のエラー率を26%から16%に劇的に改善したこの成果は、「ディープラーニング革命」の起点となった。Jensen Huangは後にこの瞬間を「ビッグバン」と表現し、AIをNVIDIAの将来の中核事業にすると決断した。
以降、NVIDIAはデータセンター向けGPUを急速に進化させた。2017年のVolta世代Tesla V100ではAI演算に特化したTensor Coreを初搭載し、混合精度演算(FP16/FP32)で大幅な高速化を実現。2020年のAmpere世代A100は312 TFLOPS(TF32)を達成し、コロナ禍のAI需要急増と相まってデータセンター売上を急伸させた。2022年のHopper世代H100はTransformer Engineを搭載してFP8演算に対応し、GPT系大規模モデル訓練の「標準」となった。2024年にはBlackwell世代B200/GB200を発表。2つのダイを1パッケージに統合した2,080億トランジスタのチップで、FP4対応で20 PFLOPSを達成。GB200 NVL72(72 GPU液冷ラック)は前世代比30倍の推論性能向上を謳う。
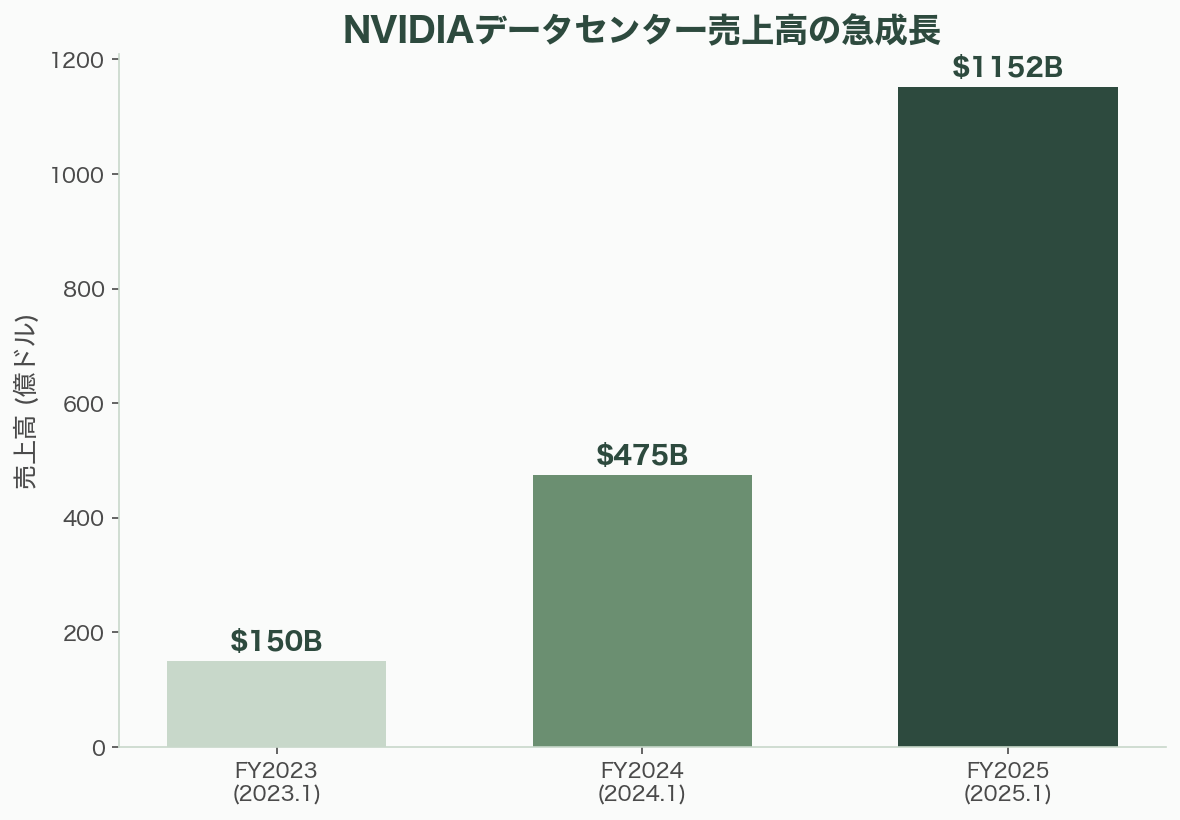
2025年度(2025年1月期)のNVIDIAの売上高は1,305億ドル(約19兆5,750億円)、前年比114%増。そのうちデータセンター事業は1,152億ドル(約17兆2,800億円)で全売上の88%を占めた。時価総額は3兆ドル(約450兆円)を超え、世界で最も価値のある企業の一角となった。
TPUの起源——Googleが自前チップを作った理由
GoogleがTPUを開発した動機は、純粋な技術的野心ではなく、経済的な必然だった。
2010年代前半、Google内部でディープラーニングの利用が急拡大した。音声認識、Google翻訳、検索ランキング、YouTube推薦——あらゆるサービスにニューラルネットワークが組み込まれていった。Googleの試算では、「もし全ユーザーが1日3分だけ音声検索を使えば、当時のデータセンター容量を倍増する必要がある」とされた。NVIDIAのGPUを大量購入し続けることは、コスト的にも供給的にも持続可能ではなかった。
この課題に対するGoogleの回答が、ドメイン特化アーキテクチャ(DSA)——ニューラルネットワーク計算に特化した自社設計チップだった。Jeff Dean(当時Google Brain責任者)とDavid Patterson(UCバークレー名誉教授、RISC発明者、2016年からGoogle Distinguished Engineer)らが中心となり、TPU v1が2015年に社内で稼働を開始した。
TPU v1は推論専用の8ビット整数演算チップで、92 TOPS(INT8)の性能を持っていた。2016年3月、DeepMindのAlphaGoが李世ドルに勝利した際、推論にTPU v1が使用され、その名が世界に知れ渡った。
TPUの設計哲学は、GPUとは根本的に異なる。GPUが汎用的な並列計算を志向するのに対し、TPUはシストリックアレイ(Systolic Array)構造を採用し、行列乗算(GEMM)に特化している。データの再利用を最大化することで、ワット当たりの演算効率を高める。また、Googleが業界に先駆けて導入したBFloat16(Brain Float 16)フォーマットにより、精度をわずかに犠牲にしつつスループットを大幅に向上させた。BFloat16は後にNVIDIA GPU(V100以降)やIntel CPUにも採用され、業界標準となった。
TPUは着実に世代を重ねた。2017年のv2で訓練対応とHBM搭載を実現し、Google Cloudでの公開を開始。2018年のv3で液冷を導入。2021年のv4ではSparseCore搭載と光回路スイッチ(OCS)による4,096チップPod構成で1 EXAFLOPS超を達成した。2023年にはv5e(コスト効率重視)とv5p(性能重視、8,960チップPod)を投入。そして2024年、第6世代「Trillium」が発表され、v5e比で訓練性能4.7倍、エネルギー効率67%向上を実現した。
技術的な得手不得手——汎用性 vs 特化効率
GPUとTPUの技術的特性を整理すると、両者の設計思想の違いが鮮明になる。
NVIDIAGPUの強みは、第一に汎用性だ。AI訓練・推論だけでなく、科学計算、レンダリング、シミュレーション、暗号通貨マイニングまで、あらゆる並列計算ワークロードに対応できる。第二に、CUDAエコシステムの規模だ。推定400万人以上のCUDA開発者、cuDNN、TensorRT、NCCL、Tritonなどの最適化ライブラリ群、PyTorch・TensorFlow・JAXすべてのフレームワークがCUDA最適化をファーストクラスでサポートしている。この15年以上かけて構築されたソフトウェア基盤は、「一朝一夕には複製できない」(Jensen Huang)。第三に、NVLink/NVSwitchによるGPU間の高帯域通信(H100で双方向900 GB/s)と、Mellanox買収(2019年、69億ドル=約1兆350億円)によるInfiniBandネットワークの統合で、チップからクラスタまでのend-to-end最適化を実現している。
一方、GPUの弱点も明確だ。消費電力はH100で700W、B200で1,000W以上に達し、データセンターの電力・冷却コストが膨大になる。H100の価格は1枚約25,000〜40,000ドル(約375万〜600万円)、DGX H100システム(8 GPU)は20万ドル(約3,000万円)以上。2023〜2024年は深刻な供給不足に陥り、リードタイムは6〜12ヶ月に及んだ。そして、CUDAへの依存は「堀」であると同時に「ロックイン」でもある。他のハードウェアへの移行コストは極めて高く、AMDのROCmはCUDAの成熟度に追いついていない。
TPUの強みは、何よりコスト性能比にある(次章で詳述)。行列演算特化設計により、ワット当たり性能が高い。Trilliumはv5e比で67%のエネルギー効率改善を達成した。ICI(Inter-Chip Interconnect)によるチップ間直接接続はNVLinkに匹敵する低レイテンシ・高帯域を実現し、数千チップのPod構成が実証済みだ。Google開発のJAXフレームワークとの親和性は極めて高く、Geminiの訓練はJAX+TPUの組み合わせで実施されている。
TPUの弱点は、Google Cloud限定であること(オンプレミス購入不可)、CUDAに比べてエコシステムが小さいこと(PyTorchのTPUサポートはCUDA版より遅れがち)、TPU特有の最適化(データパイプライン設計、シャーディング戦略)の学習曲線が存在することだ。
MLPerfベンチマーク(MLCommons主催、AI性能の業界標準)では、NVIDIAがBlackwellでほぼ全カテゴリで最高性能を記録する一方、Google TPU v5pも複数カテゴリでトップクラスの結果を出している。ただし、MLPerfは「最高性能」を競うベンチマークであり、コスト効率は測定しない。TPUの最大の強みであるコスト性能比は、MLPerfには反映されない構造になっている。
TPUのコスト性能比——特筆すべき構造的優位性
GPU vs TPUの議論において、最も見落とされがちで、しかし最も重要な論点がコスト性能比だ。
Googleは各世代のTPU発表時に、一貫してコスト優位性を強調してきた。TPU v5e発表時(2023年8月)には「v4比で訓練コスト半減、推論コスト約3分の1」、v5p発表時(2023年12月)には「大規模モデル訓練でH100対比で優れたコスト性能比」、Trillium発表時(2024年)には「v5e比で1ドル当たり性能4.7倍向上」と発表した。
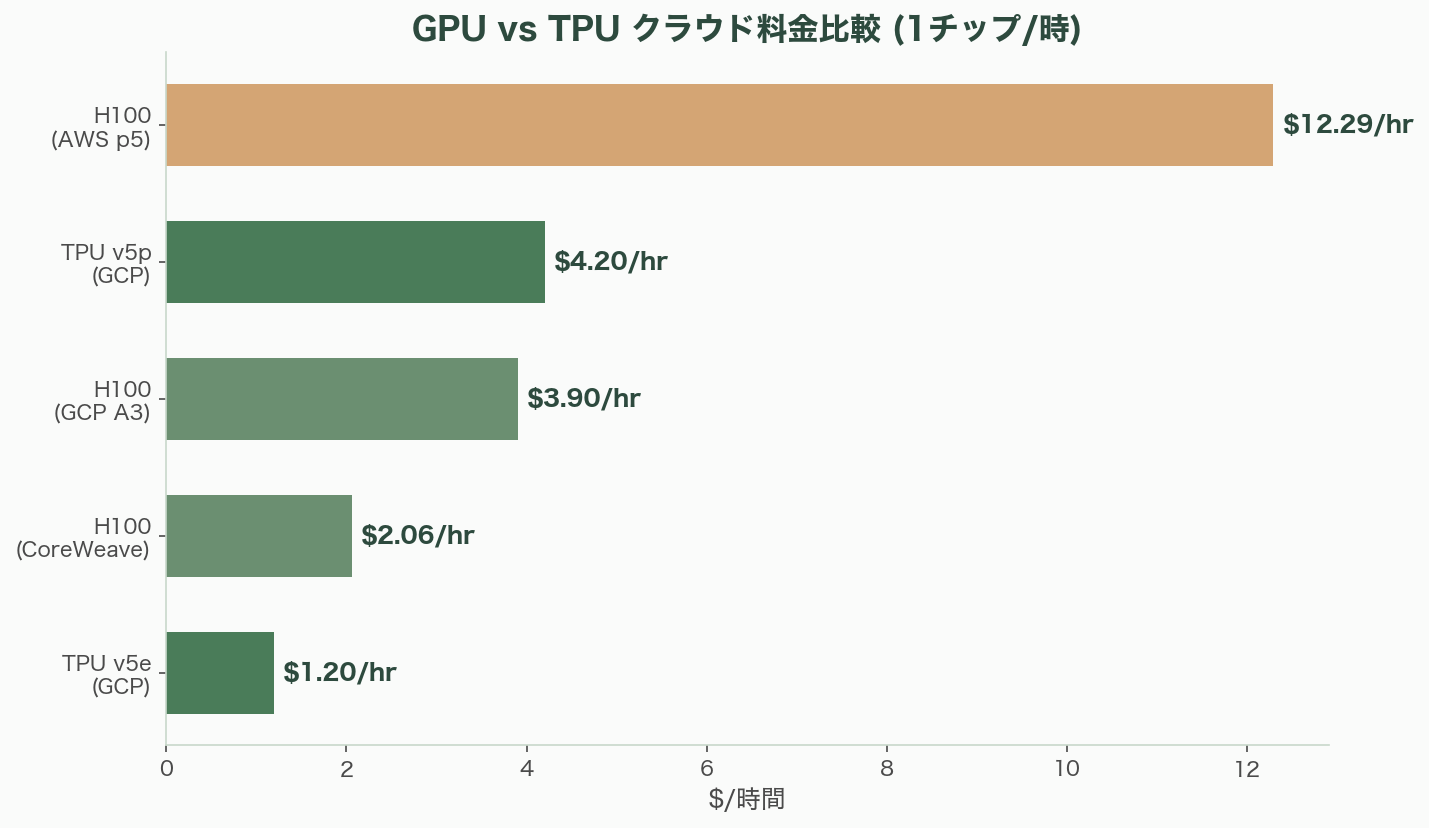
クラウド料金の直接比較は、構成やリージョンにより変動するものの、概算では以下の構図が浮かび上がる。Google Cloud上でTPU v5eは1チップあたり約1.20ドル/時(オンデマンド)、3年コミットメントで約0.50ドル/時にまで下がる。一方、同じGoogle Cloud上のH100(A3インスタンス)は1 GPU あたり約3.90ドル/時。AWSのH100(p5インスタンス)は1 GPUあたり約12.29ドル/時、CoreWeaveやLambdaなどのGPUクラウドでも約2.00〜2.50ドル/時だ。
LLM訓練コストの比較では、LLaMA 2 70B規模のモデル訓練が、H100 2,048基構成(AWS/Azure想定)で約200〜300万ドル(約3億〜4億5,000万円)のところ、TPU v5pの同等規模構成ではGoogleの主張で30〜50%のコスト削減、すなわち100〜200万ドル(約1億5,000万〜3億円)相当になるとされる。推論のトークン当たりコストでは、TPU v5eがH100比で最大2.5倍のコスト効率改善をGoogleは主張している。
このコスト優位性が生まれる構造的な理由は3つある。第一に、TPUはドメイン特化設計により、行列演算のワット当たり効率がGPUを上回る。汎用性を犠牲にした分の効率がコストに反映される。第二に、GoogleはTPUの設計・製造(TSMCに委託)・運用を垂直統合しており、NVIDIAのGPUを第三者として購入する場合に発生するマージンが存在しない。Google内部でのTPU利用コストは、外部顧客向け料金よりさらに低い可能性が高い。第三に、GoogleのデータセンターはPUE(Power Usage Effectiveness)1.1程度の世界最高水準のエネルギー効率を実現しており、電力・冷却コストが低く抑えられている。
ただし、コスト比較には重要な留意点がある。直接比較の困難さ(クラウド料金体系の違い)、最適化度合いの影響(TPU/GPU各々に最適化されたコードでないと公平な比較にならない)、隠れコスト(データ転送費、エンジニアリング時間、TPU移行の学習コスト)を考慮する必要がある。また、TPUはGoogle Cloud限定であるため、マルチクラウド戦略やオンプレミス運用を志向する企業にとっては選択肢にならない。
AI訓練コストの急騰——GPT-3(推定460万ドル、2020年)→ GPT-4(推定1億ドル超、2023年)→ 次世代モデル(推定5〜10億ドル)——を考えると、コスト性能比の差は数千万ドル単位のインパクトになる。これは、特に資金効率を重視するスタートアップにとって、TPUを選択する強力な経済的動機となっている。
企業のインフラ選択——なぜ分かれるのか
AI開発のインフラ選択は、企業の戦略・パートナーシップ・技術的背景によって大きく分かれている。
OpenAIはMicrosoft Azureと戦略的パートナーシップを結んでおり、GPT-4/oの訓練はAzure上のNVIDIA GPU(推定数万〜10万基のH100)で実施されている。Sam Altman CEOは「長期的にはAIに最適化された多様なチップが必要」と発言しつつも、2024年初頭には独自AIチップ製造のために5〜7兆ドルの資金調達を構想したと報じられた(Bloomberg)。この構想自体が実現しなかったものの、GPU供給への深い危機感を示している。
MetaはNVIDIA GPU一択の戦略を鮮明にしている。Mark ZuckerbergはMeta が2024年末までに約35万基のH100を確保すると発表し、LLaMA 3.1 405Bは推定16,000基以上のH100で訓練された。推論用のカスタムチップMTIA(v2で推論性能3倍改善)を開発中だが、訓練はNVIDIA GPUが中心だ。オープンソース主義を掲げるMetaにとって、CUDAエコシステムとPyTorchとの親和性がGPU選択の最大の理由だ。
xAI(Elon Musk)はさらに極端だ。テネシー州メンフィスに世界最大級の単一GPUクラスタ「Colossus」を建設し、10万基のH100を稼働させている。Muskは「GPUは新しい金」「GPUを十分確保できない企業はAI競争に参加できない」と公言する。Teslaで独自AIチップDojo(D1)を開発したが、結局NVIDIA GPUへの投資を大幅に増加させ、2024年にDojo計画を事実上縮小した。自社チップ開発の困難さを示す象徴的な事例だ。
一方、TPUを選択するスタートアップも確実に増えている。AnthropicはGoogleからの20億ドル超の投資(2023年)を背景にGoogle Cloud TPUでClaudeの訓練を実施しつつ、Amazonからの40億ドル投資によりAWS上のGPU/Trainiumも併用するハイブリッド戦略を取る。Character.AI(Google Brain出身のNoam Shazeer、Daniel De Freitasが創業)は、日次数百万ユーザーの対話処理をTPU v4/v5eで運用し、大規模推論のコスト効率を主要因として選択した。CohereはTPUとGPUの両方を使用し、マルチクラウド対応を図る。MidJourneyは初期にGoogle Cloud TPUを利用して画像生成モデルを訓練した。
Google/DeepMind自体は当然ながらTPU中心だ。Geminiの訓練はTPU v5p上で、PaLM 2はTPU v4 Podで、AlphaFoldもTPU上で実施された。ただし、Google CloudはNVIDIA H100/A100も顧客向けに提供しており、「選択肢を提供する」姿勢を示している。Google内部のAI推論ワークロードの大部分——検索、YouTube、Gmail、Google翻訳、Gemini——はTPU上で稼働しているとされる。
シリコンバレーVCの視点——NVIDIA支配の持続性と代替シナリオ
シリコンバレーのVCは、GPU vs TPUの議論を「チップの性能比較」ではなく、「AI産業の構造的リスク」として捉えている。
Sequoia Capitalは2024年前半に発表したレポート「AI's $600B Question」で、NVIDIAのGPU売上500億ドル超に対し、AI企業の実際の収益が大きく下回っている現実を指摘した。GPU/コンピュート投資が過剰である可能性を示唆し、代替手段(TPU、カスタムチップ)によるコスト最適化の重要性を浮き彫りにした。
a16z(Andreessen Horowitz)のMartin CasadoとMatt Bornsteinは、AI企業のコスト構造を分析した「Who Owns the Generative AI Platform?」(2023年)で、「AIスタートアップの粗利率はGPUコストにより伝統的SaaS企業より低い」と指摘した。a16zはAIインフラ層(GPU/TPU)をNVIDIA/Googleが支配する「税」と見なし、VC投資の最大機会はアプリケーション層にあるとする一方、「NVIDIA依存のリスク」とカスタムシリコンの台頭に注目している。Matt Bornsteinは「2026年はAIエージェントの年」と予測するが、その基盤コストの最適化がスタートアップの生死を分けるとも指摘する。
VCの投資行動はこの認識を反映している。NVIDIAの支配に対する「代替」として、大型投資が以下のAIチップスタートアップに向かっている。Cerebras Systems(累計調達約7億ドル=約1,050億円、ウエハースケールチップWSE-3)、Groq(累計調達約6.4億ドル=約960億円、推論特化LPU)、SambaNova Systems(累計調達約11億ドル=約1,650億円、RDU)、Tenstorrent(累計調達約3億ドル=約450億円、Jim Keller主導のRISC-Vベース)、Etched(累計調達約1.2億ドル=約180億円、Transformer特化ASIC「Sohu」)。
VC界隈の共通認識は3つの時間軸で整理される。短期(1〜3年)ではNVIDIAの支配は揺るがない——CUDAの堀が強固で、Blackwell/Rubinの世代更新が速い。中期(3〜5年)ではカスタムシリコン(TPU含む)のシェアが拡大し、特に推論市場で顕著になる。長期(5年超)ではヘテロジニアス(GPU+TPU+カスタムASIC混在)環境が標準になると見られている。
Goldman Sachsは「AI Infrastructure: The Next $1 Trillion Opportunity」レポート(2024年)で、NVIDIAを短期勝者としつつも、Google TPUとAWS Trainiumを「最も有力な代替」と位置づけた。Morgan Stanleyは「NVIDIAの堀はハードウェアではなくCUDAエコシステム」と分析し、Bernstein ResearchのStacy Rasgon(NVIDIAの最も著名なアナリスト)は「NVIDIAの競争力は今後数年持続する」としながらも、長期的にはASIC/カスタムチップの台頭で粗利率が圧迫される可能性を指摘している。
著名人の主張——GPU派 vs TPU派
GPU vs TPUの議論は、シリコンバレーの著名な人物たちの間でも見解が分かれている。
Jensen Huang(NVIDIA CEO)は、GPUの汎用性が長期的な優位をもたらすと一貫して主張する。「特定ワークロードに特化したチップは一時的に効率が良くても、AIモデルは急速に進化する。汎用性のあるGPUプラットフォームの方が長期的に有利だ」。CUDAについては「数百万のインストールベースは15年以上かけて構築したエコシステムであり、一朝一夕には複製できない」と、GTC 2024では「次のインダストリアル・レボリューションが始まった」と宣言した。NVIDIAのロードマップは1年サイクルの世代更新(Blackwell→Rubin→Vera)を宣言し、従来の2年サイクルから加速している。
David Patterson(UCバークレー名誉教授、Google Distinguished Engineer)は、TPU側の最も強力な論客だ。RISCとRAID の発明者として半導体設計の歴史に名を刻む彼は、2020年の論文「A Domain-Specific Supercomputer for Training Deep Neural Networks」でTPUの優位性を論証し、2023年にはJeff Deanとの共著ISCAペーパーでTPU v4のアーキテクチャ詳細を公開した。「ドメイン特化アーキテクチャは汎用プロセッサより桁違いに効率的だ」と主張する。
Jeff Dean(Google Chief Scientist)はTPUの開発を統括的に推進した立役者だ。「TPUの設計哲学は、ニューラルネットワーク計算の本質的な性質を活用すること。精度をある程度犠牲にしても、スループットを最大化する」と語る。スケーリング則の信奉者として、「計算量の増加がAI性能向上の鍵。TPUはそのスケーリングを経済的に実現するためのツール」と位置づけている。
Yann LeCun(Meta Chief AI Scientist、NYU教授)はGPU支持派だが、独自の視点を持つ。Metaの大規模AI研究(LLaMAシリーズ等)は全てNVIDIA GPU上で実施されている。「汎用GPUの進化速度が速すぎて、ASICが追いつくのは難しい」としつつも、長期的にはドメイン特化チップの重要性も認めている。オープンソース主義者として、特定ベンダーへの過度な依存を懸念する立場だ。
Jim Keller(Tenstorrent CEO、AMD Zen/Apple Aシリーズ/Tesla Dojo設計者)は、NVIDIAに正面から挑戦する。「NVIDIAの堀は思われているほど深くない。良い代替が出れば移行は起きる」。RISC-Vベースのオープンなアーキテクチャを推進し、「GPU+CUDAのモデルは最適ではない」と断言する。
Elon Muskは実践面で結論を出した。Teslaで独自AIチップDojoを開発しながら、結局xAIでは10万基のNVIDIA H100を購入した。「GPUは新しい金」との言葉は、NVIDIA支配の現実を最も端的に表現している。
Andrew Ng(Stanford教授、Coursera共同創業者)は実務的な中間派だ。初期のGPUベースディープラーニング研究の先駆者として、「どのチップを使うかより、何を作るかが重要。ただし現時点ではGPU+CUDAのエコシステムが最も生産性が高い」と述べる。
数字で見るGPU vs TPU——市場データと投資動向
AI半導体市場の数字は、NVIDIAの圧倒的支配と、それに挑戦する勢力の台頭の両方を映し出している。
NVIDIAのデータセンター売上は2023年度(2023年1月期)の150億ドル(約2兆2,500億円)から、2024年度に475億ドル(約7兆1,250億円)、2025年度に1,152億ドル(約17兆2,800億円)と、わずか2年で約8倍に膨張した。AI訓練用アクセラレータ市場で推定70〜95%のシェアを握る。この売上規模をa16zは「AI産業の税」と形容する。
AMDはMI300Xで追撃し、2024年のAIアクセラレータ売上目標を50億ドル(約7,500億円)前後に設定した。ただしNVIDIAの10分の1以下の規模であり、シェアは5〜15%程度にとどまる。
Google Cloud TPUの直接的な売上数値は非公開だ。AlphabetはGoogle Cloud全体として2024年通期で約430億ドル(約6兆4,500億円、前年比+28%)を報告し、営業利益の黒字化を達成している。TPU利用企業数は数百社以上とされるが、Google内部での利用が圧倒的に大きい。検索、YouTube、Gmail、Google翻訳、Geminiの推論ワークロードの大部分がTPU上で稼働している。
AI半導体市場全体は、2024年に約700〜800億ドル(約10兆5,000億〜12兆円)、2030年には3,000〜4,000億ドル(約45兆〜60兆円)に達すると複数の調査会社が予測している。年率20〜30%の成長だ。
クラウドプロバイダーの設備投資も急膨張している。Sundar Pichai(Google/Alphabet CEO)は年間750億ドル(約11兆2,500億円)規模の設備投資計画を発表。MicrosoftとAmazonも同規模の投資を計画している。この「AIインフラ軍拡競争」の最大の受益者がNVIDIAだが、各社のカスタムチップ開発投資も加速している。
AI訓練コストの急騰は、コスト効率の重要性を一層高めている。GPT-3の訓練コスト推定460万ドル(2020年)から、GPT-4は推定1億ドル超(2023年)、次世代モデルは5〜10億ドルと推定される。このスケールでは、TPUのコスト優位性がもたらす30〜50%の削減は、1億5,000万〜5億ドルの差になる。
カスタムシリコンの潮流——GPU・TPU以外の第三の道
GPU vs TPUの二項対立に加え、「カスタムシリコン」という第三の潮流が勢いを増している。
Amazon/AWSはTrainium 2(2024年)を投入し、NVIDIAへの依存低減を図る。Anthropicの次期モデル訓練用に大規模Trainiumクラスタ「Project Rainier」を構築中だ。推論特化のInferentia 2も展開している。
Microsoftは初のAI特化チップMaia 100を2023年11月に発表。ArmベースCPU Cobaltとの組み合わせでAzure向けに展開するが、規模はまだ限定的で、NVIDIAとの協力関係が当面の主軸だ。
MetaはMTIA v2で推論性能3倍改善を達成。ただし訓練はNVIDIA GPU中心で、MTIAは推論のコスト最適化に特化している。
AppleはApple Silicon(M-series)でオンデバイスAI推論を独自チップで実行するが、データセンター訓練にはNVIDIA GPUを使用している。
これらの動きに加え、スタートアップによる挑戦も続く。Cerebras(ウエハースケールチップ)、Groq(推論特化LPU、超低レイテンシ)、Tenstorrent(RISC-Vベース、Jim Keller主導)、Etched(Transformer特化ASIC)など、それぞれ異なるアプローチでNVIDIAの牙城に挑んでいる。
Stanford HAI(Human-Centered AI Institute)のAI Index Report 2024は、コンピュートコストがAI研究のボトルネックになっており、GPU/TPUアクセスの格差が「AI研究の民主化」を阻害していると警鐘を鳴らしている。
今後のトレンド——ヘテロジニアスな未来へ
GPU vs TPUの競争は、最終的には「どちらかが勝つ」のではなく、ヘテロジニアス(多様なチップ混在)環境への収束が最も有力なシナリオだ。
NVIDIAのロードマップは加速している。Blackwell(2024〜2025年)→ Rubin(2026年、HBM4、新型NVLink)→ Vera(2028年)と、従来の2年サイクルから1年サイクルへの移行を宣言した。チップ単体の性能向上だけでなく、NVLink、NVSwitch、Spectrum-X Ethernet、ソフトウェア(NIM、NEMO)を含む統合プラットフォーム化が進む。
Googleも世代更新を続ける。Trillium(v6)の次の世代は18〜24ヶ月サイクルで投入される見通しだ。独自CPU「Axion」(Armベース、2024年発表)との統合も進み、TPU+GPU+CPUの「AIハイパーコンピュータ」構想が描かれている。推論の最適化がGeminiの大規模デプロイにとって特に重要なテーマだ。
ソフトウェア側では、チップ間のポータビリティを高める動きが加速している。MLIR、OpenXLA等のMLコンパイラの標準化が進み、Triton(OpenAI/Meta開発)もGPU以外のバックエンドへの拡張を模索している。これらの技術が成熟すれば、CUDAロックインの障壁は徐々に低下する。
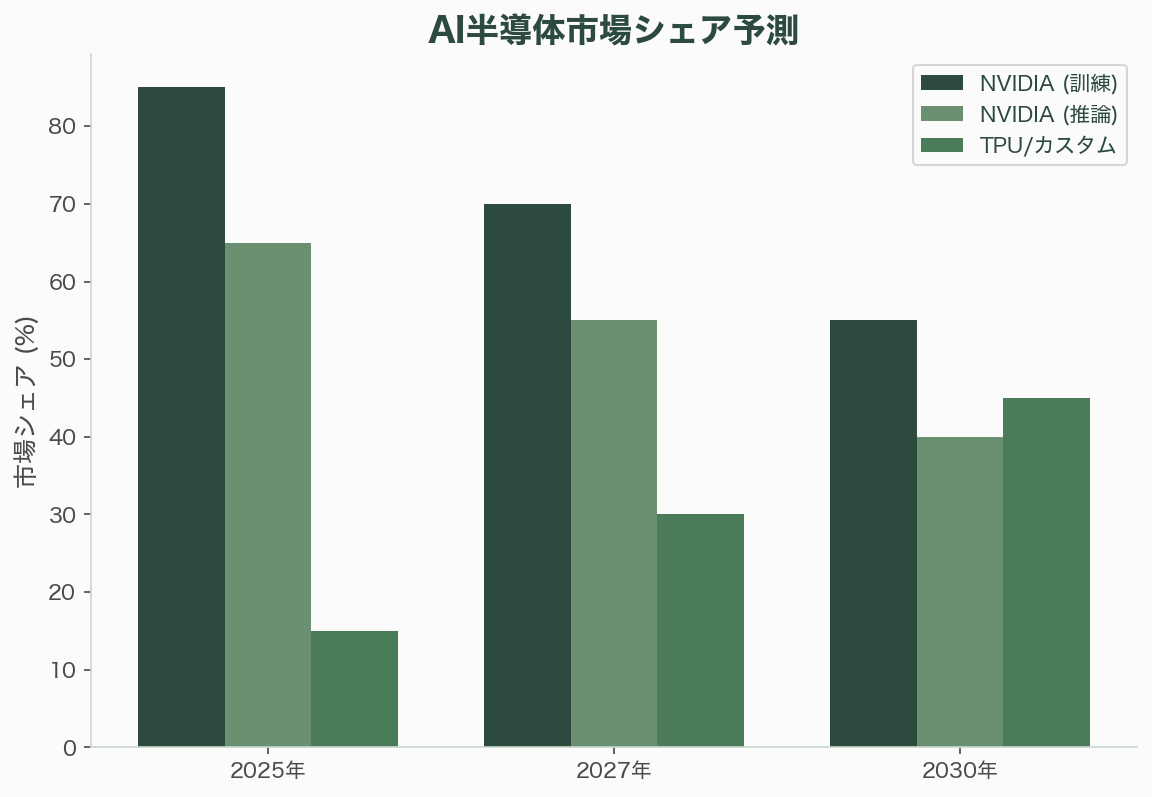
アナリストの予測を総合すると、2025〜2027年にはNVIDIAが訓練市場で60〜80%のシェアを維持するが、推論市場では50〜60%に低下する。2028〜2030年にはカスタムチップ(TPU、Trainium、各社ASIC)が訓練市場で30〜40%に到達する可能性がある。推論市場はコスト感度が高いため、TPU/カスタムチップの浸透が最も速く進む領域だ。
Jensen Huangの「あらゆる企業がAIファクトリーになる」というビジョンが実現するとすれば、そのファクトリーの設備はNVIDIA GPUだけでなく、Google TPU、AWS Trainium、各社カスタムASICが混在する多様な構成になるだろう。問題は「GPU vs TPU」の勝敗ではなく、各企業がワークロード・スケール・コスト構造に応じて最適なチップを選択する時代が到来していることだ。
業界への影響
第一に、NVIDIAのGPU支配は短期的に揺るがないが、「NVIDIA税」というコスト構造がAI産業全体の成長を制約する可能性がある。データセンター売上1,152億ドル(FY2025)という数字は、AI産業が「計算の工場」に支払うコストの大きさを示している。Sequoia Capitalが指摘した「GPU投資と収益のギャップ」は、コスト最適化の代替手段——TPU、Trainium、カスタムASIC——への構造的なシフト圧力を生んでいる。
第二に、TPUのコスト性能比は、特に資金効率を重視するAIスタートアップにとって看過できない優位性だ。訓練コスト30〜50%削減は、次世代モデル(推定訓練コスト5〜10億ドル)のスケールでは数億ドルの差になる。Anthropic、Character.AI、Cohereといった企業がTPUを選択している事実は、コスト優位性が「理論」ではなく「実践」のフェーズに入ったことを示している。
第三に、CUDAエコシステムはNVIDIAの最大の強みであると同時に、AI産業全体のボトルネックでもある。400万人以上の開発者基盤は移行コストを極めて高くしているが、MLIR/OpenXLA/Tritonといったチップ横断コンパイラ技術の進化により、この障壁は中期的に低下する見通しだ。Jim Kellerの「NVIDIAの堀は思われているほど深くない」という指摘が現実になるかどうかは、これらのソフトウェア技術の成熟度にかかっている。
第四に、AI半導体市場はGPU vs TPUの二項対立から、ヘテロジニアス(多様なチップ混在)環境へと移行しつつある。Amazon Trainium、Microsoft Maia、Meta MTIA、さらにCerebras、Groq、Tenstorrent、Etchedといったスタートアップの挑戦が加わり、企業はワークロード・スケール・コスト構造に応じたチップ選択を迫られている。訓練市場ではNVIDIA GPU優位が当面続くが、推論市場ではTPU/カスタムチップの浸透が最も速く進む。
参考情報: NVIDIA FY2025 Annual Report & Earnings (Jan 2025), NVIDIA GTC 2024 Keynote (Jensen Huang), Google Cloud Next 2024 (Trillium/TPU v6 発表), Google ISCA 2023 TPU v4 Paper (Jeff Dean, David Patterson et al.), Sequoia Capital「AI's $600B Question」(2024), a16z「Who Owns the Generative AI Platform?」(Martin Casado, Matt Bornstein, 2023), Goldman Sachs「AI Infrastructure: The Next $1 Trillion Opportunity」(2024), Morgan Stanley NVIDIA Coverage Reports, Bernstein Research (Stacy Rasgon) Semiconductor Analysis, Stanford HAI AI Index Report 2024, MLCommons MLPerf Training v4.0 Results (2024), Google Cloud TPU Pricing & Documentation, AWS P5/Trainium Pricing, Azure ND H100 Pricing, David Patterson「A Domain-Specific Supercomputer for Training Deep Neural Networks」(Communications of the ACM, 2020), Anthropic-Google Cloud Partnership Announcement (2023), Character.AI TPU Infrastructure Reports, Elon Musk xAI Colossus Announcements, Sam Altman AI Chip Fundraising Reports (Bloomberg, 2024), Jim Keller Tenstorrent Interviews & RISC-V Vision, Yann LeCun AI Hardware Commentary, Andrew Ng GPU-based DL Research, Cerebras/Groq/SambaNova/Etched Funding Rounds (TechCrunch, The Information), Google Axion CPU Announcement (2024), NVIDIA Rubin/Vera Roadmap (GTC 2024), The Information「NVIDIA Tax」Coverage, IEEE Spectrum TPU Architecture Analysis, 日経クロステック NVIDIA/AI半導体特集