まず全体像から——Claude Sonnet 5とは何か
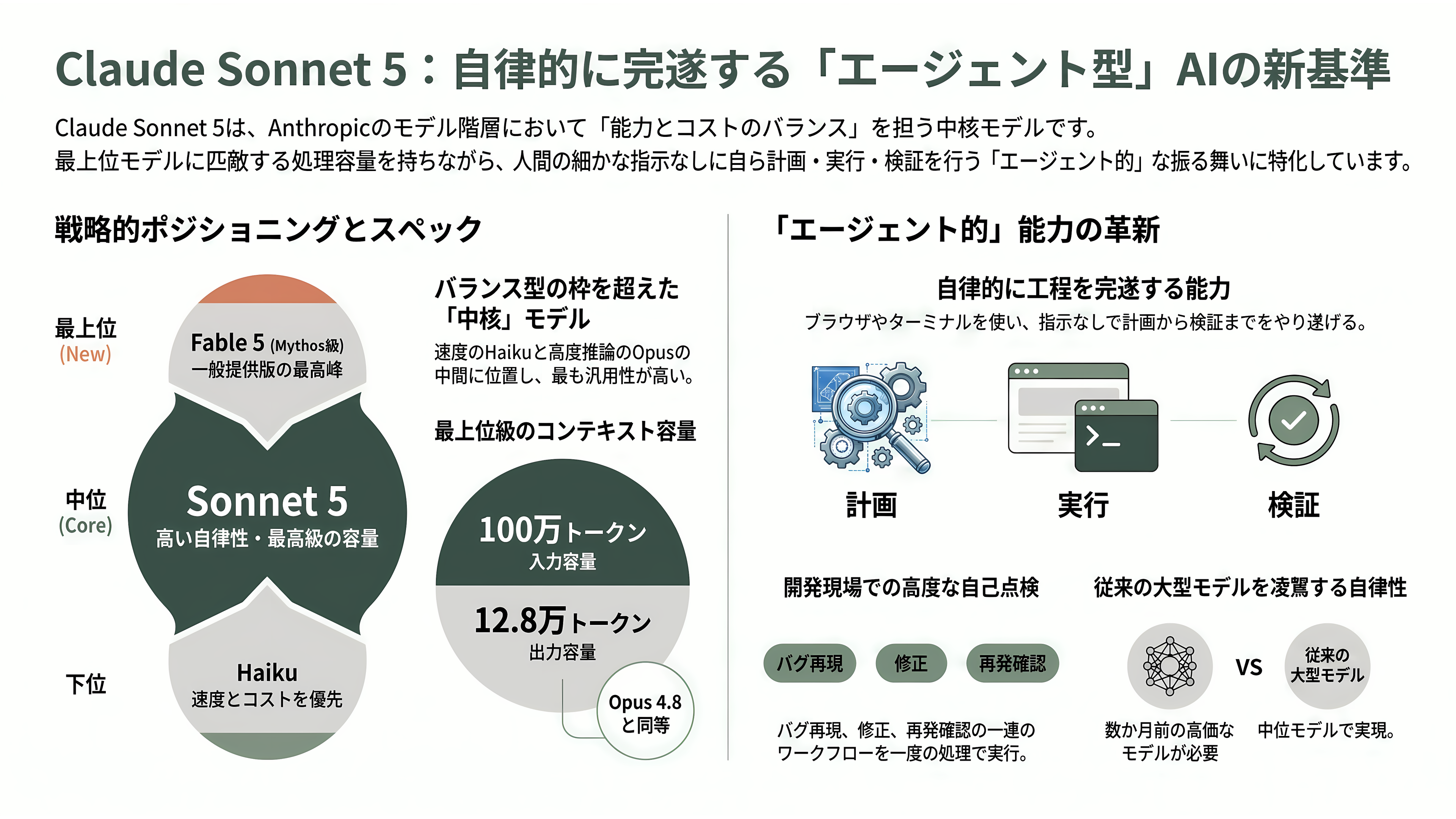
Claude Sonnet 5を理解するには、まずAnthropicの製品ラインアップにおける「Sonnet」の位置づけを押さえる必要がある。Anthropicは自社の大規模言語モデル(LLM)を、速度とコストを優先する「Haiku」、能力とコストのバランスを取る中位の「Sonnet」、最も難しい推論を担う最上位の「Opus」という三層で展開してきた。2026年6月9日にはこの上にさらに「Mythos級」という新層を載せ、一般提供版の最上位として「Fable 5」を投入している。今回のSonnet 5は、この階層構造のちょうど真ん中、最も多くのユーザーが日常的に触れる中核モデルの更新版にあたる。
Anthropicがこのモデルに与えたキャッチフレーズは「これまでで最もエージェント的なSonnet(the most agentic Sonnet model yet)」である。ここでいう「エージェント的」とは、単に質問に答えるだけでなく、自分で計画を立て、ブラウザやターミナルといった道具を使い、人間の逐一の指示なしに複数の工程を最後までやり切る能力を指す。公式発表は「数か月前ならより大きく高価なモデルを必要とした水準の自律動作を、Sonnet 5は実行できる」と表現している。
具体例で言えば、開発現場での振る舞いが分かりやすい。Anthropicの法人向けAI担当ゼネラルマネージャーYusuke Kaji氏は「最も難しい実際のプルリクエストを何十件もSonnet 5にぶつけたが、それぞれを自力でテスト済み・検証済みの結果まで運びきった」と証言する。技術スタッフのZimu Li氏は「雑然とした技術的文脈の中でも、持続的なコーディング・ツール使用・デバッグをうまくこなす」と述べ、RustエンジニアのNeel Chotai氏は「バグを再現するテストを書き、修正を実装し、その修正を一旦退避させてバグが再発することを確認する——これを一度の処理ですべてやった」と具体的な作業の流れを挙げている。指示されずとも自分の出力を検証する、という自己点検の振る舞いが、初期アクセスのパートナーから繰り返し指摘された特徴だ。
このSonnet 5は、claude.aiの無料プランとProプランの既定モデルとして据えられ、Max・Team・Enterpriseの各プラン、開発支援ツールのClaude Code、そしてClaude API・Amazon Bedrock・Google Vertex AI・Microsoft Foundry経由でも利用できる。コンテキストウィンドウは100万トークン、最大出力は12万8千トークンで、最上位のOpus 4.8と同等の容量を持つ。つまり「容量と土俵は最上位級、価格は中位」というのが、このモデルの基本的な売り文句である。
リリースの要点と「安さ」の設計
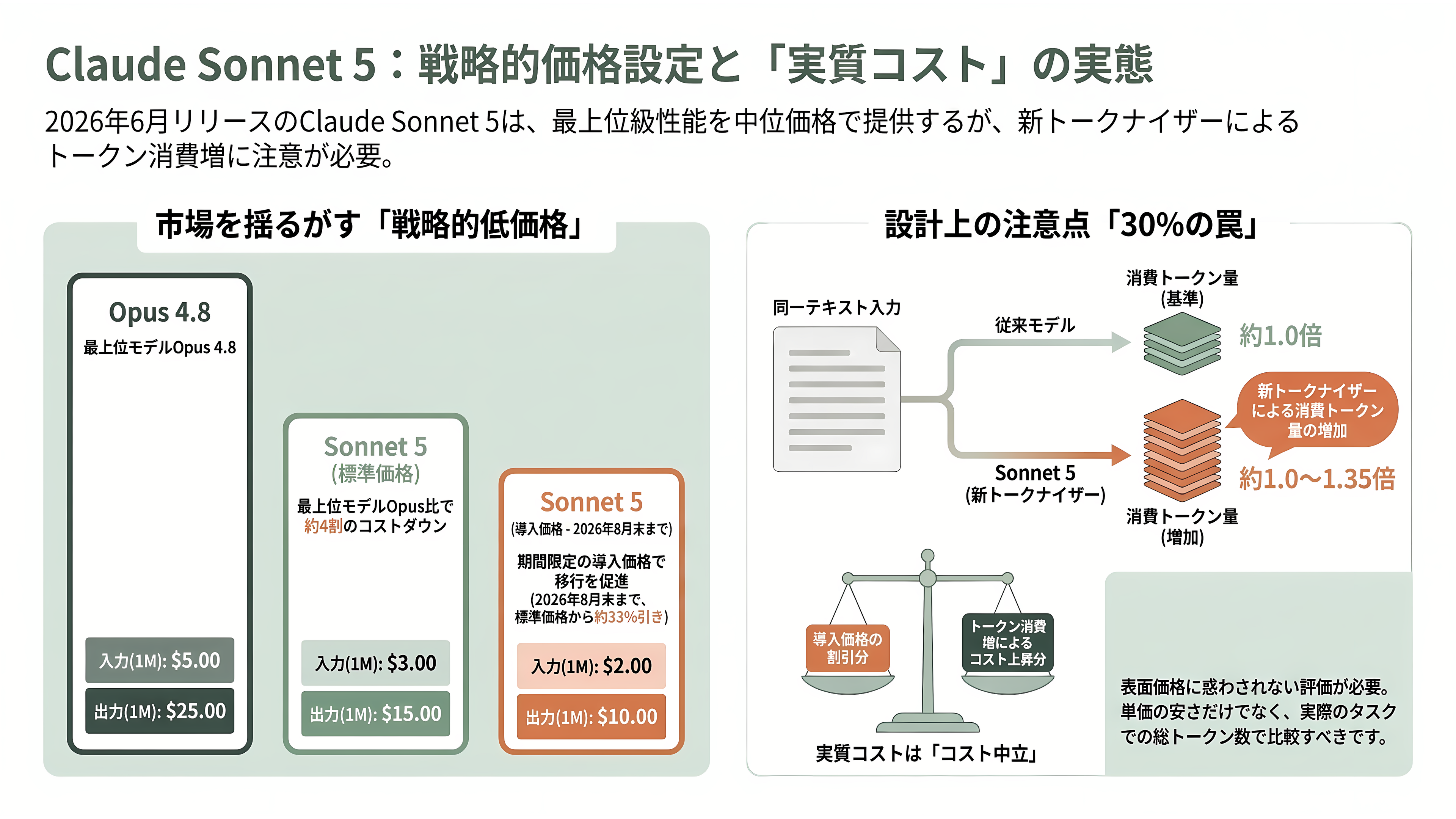
リリース日は2026年6月30日。APIのモデルIDはclaude-sonnet-5で、日付を含まない固定スナップショット型の識別子が採用されている。価格設計こそ、このリリースの戦略の核心だ。
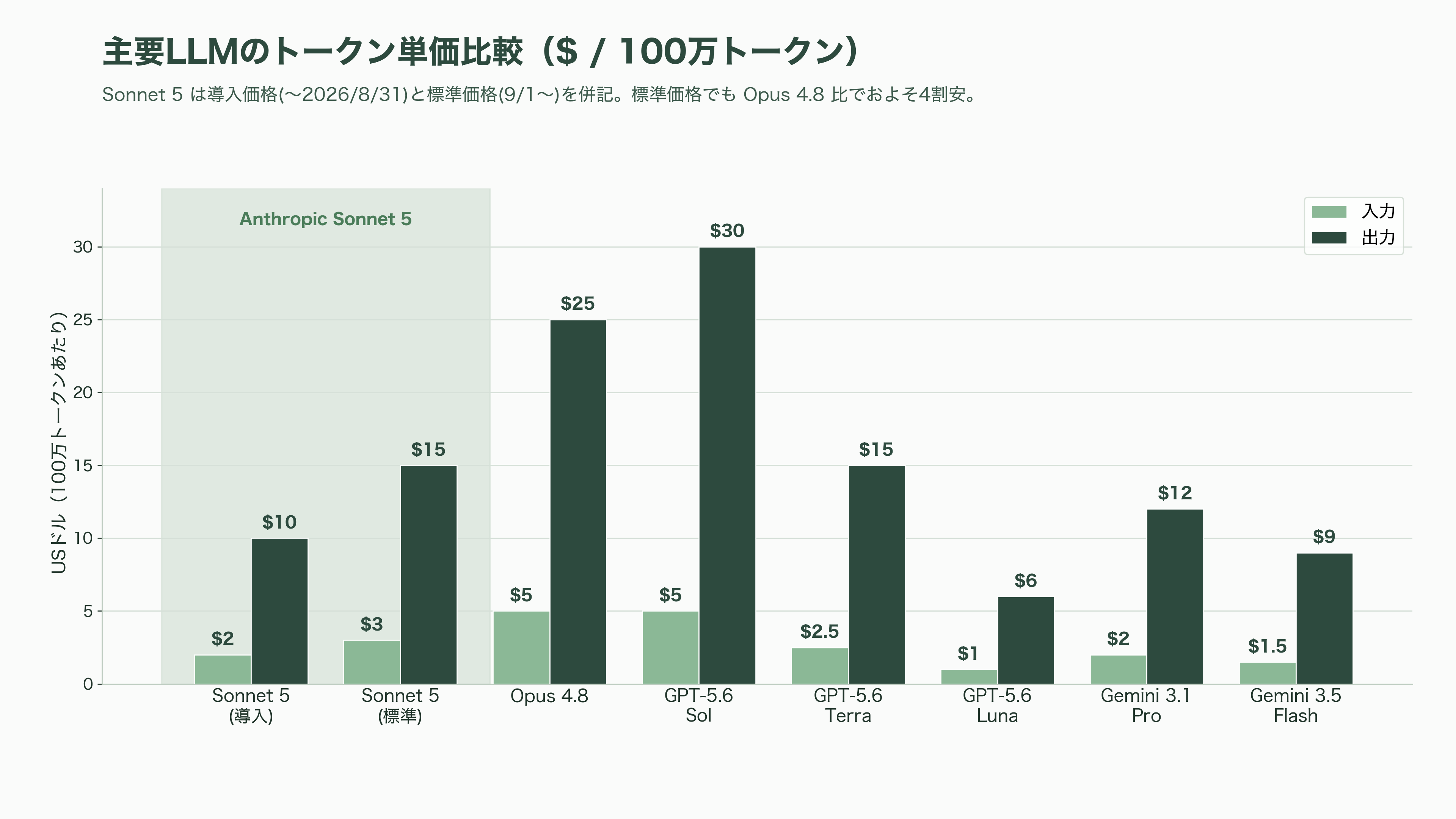
導入価格として、2026年8月31日まで入力100万トークンあたり2ドル(約310円)・出力10ドル(約1,550円)が適用される。9月1日以降の標準価格は入力3ドル(約465円)・出力15ドル(約2,325円)。比較対象となる最上位Opus 4.8が入力5ドル(約775円)・出力25ドル(約3,875円)であることを踏まえると、Sonnet 5は標準価格でもOpus比でおよそ4割安く、導入期間中はさらに割安になる。Anthropic自身が「Sonnet 5とOpus 4.8の間で、ユーザーはエフォート(effort)水準を調整してコストと性能の最適点を見つけられる」と位置づけており、両者を地続きの選択肢として設計しているのが分かる。
競合との比較でも価格優位は明確だ。OpenAIのGPT-5.6は上位の「Sol」が入力5ドル(約775円)・出力30ドル(約4,650円)、中位の「Terra」が2.5ドル(約388円)・15ドル(約2,325円)、廉価の「Luna」が1ドル(約155円)・6ドル(約930円)という三段構成で、GoogleのGemini 3.1 Proは2ドル(約310円)・12ドル(約1,860円)、Gemini 3.5 Flashが1.5ドル(約233円)・9ドル(約1,395円)。Sonnet 5の標準価格はGPT-5.6 Terraとほぼ並び、上位のGPT-5.6 SolやOpus 4.8より大きく安い。「最上位級の能力を、廉価モデルに近い価格で」という挟み撃ちの値付けである。
ただし「安さ」には注意すべき設計上の落とし穴がある。Sonnet 5は新しいトークナイザー(テキストをトークンに分割する仕組み)を採用しており、Anthropicの料金ページは「同じテキストでおよそ30%多くトークンを消費する」と明記している(公式発表ページの注記では内容に応じて約1.0〜1.35倍という表現を使う)。トークン単価は据え置きでも、同じ作業に必要なトークン数が増えるため、実質コストは額面の価格差ほど下がらない。導入価格はこの移行を概ねコスト中立にするための設定とみてよい。エフォートの既定値はClaude APIとClaude Codeで「high」に設定されている。
ベンチマーク結果と性能——「SWE-bench Pro」を前面に出した理由
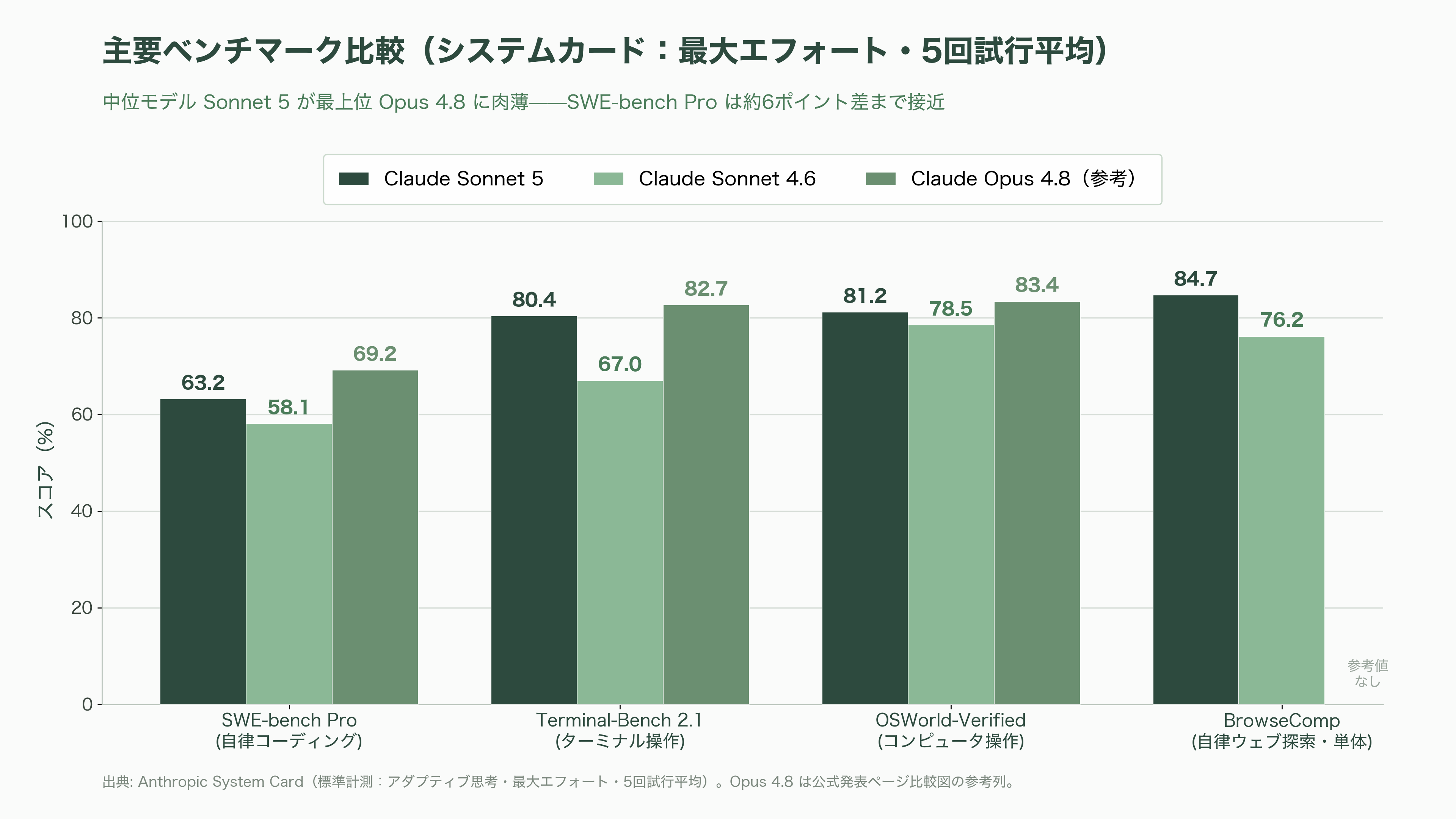
Sonnet 5の性能を語るうえで、まず数字の出典を厳密に分けておく必要がある。Anthropicが公開したシステムカード(System Card)が一次情報であり、その標準計測条件は「アダプティブ思考を最大エフォート(max effort)で動作させ、5回試行の平均を取る」というものだ。つまり以下の数値は、いずれもモデルを全力で回したときの値である。
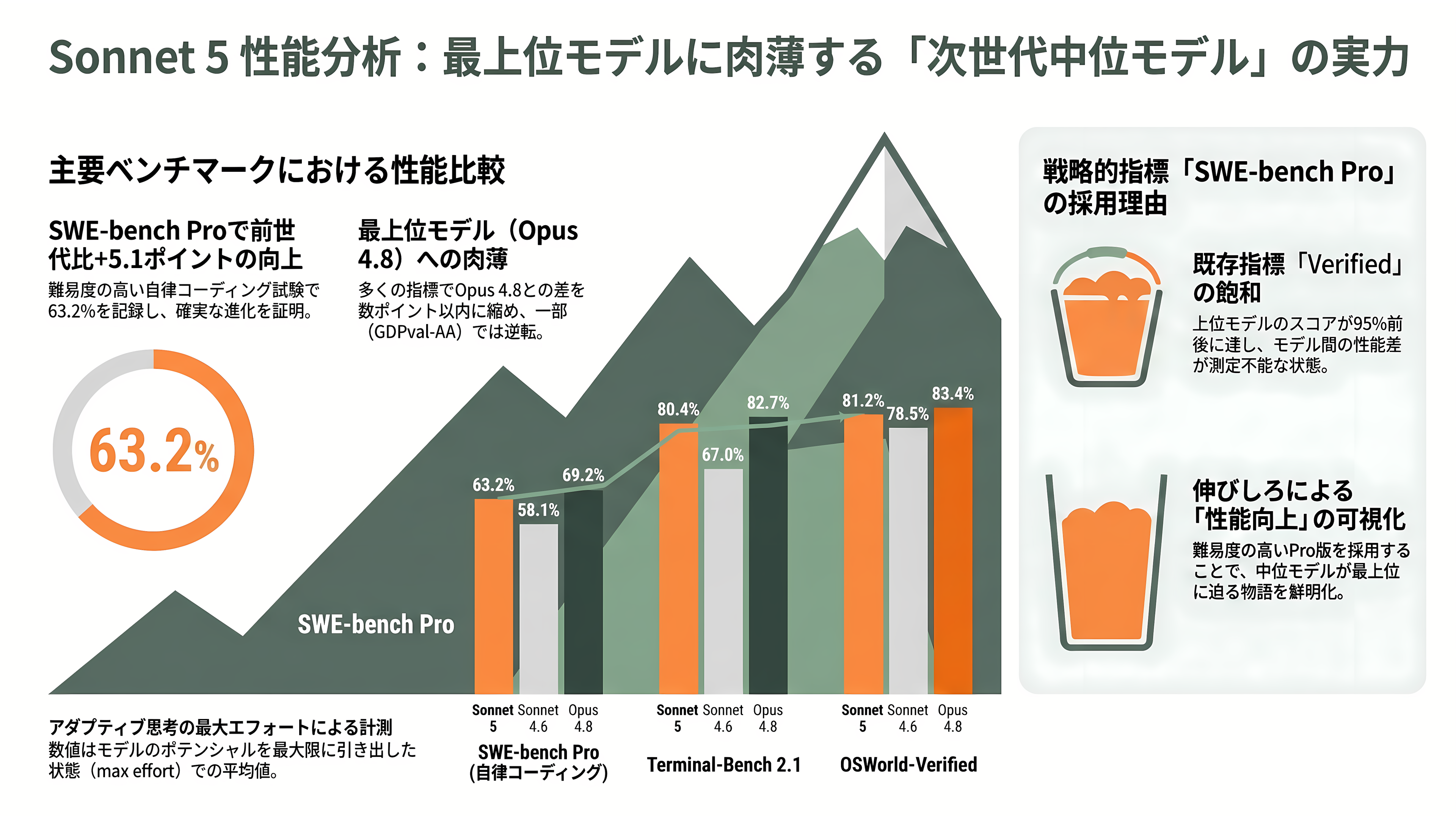
主要なベンチマークを整理すると次のようになる。なおOpus 4.8の数値は公式発表ページの比較図に「参考列」として載るもので、システムカード本体の比較表(Sonnet 4.6/GPT-5.5/Gemini 3.5 Flashとの比較)には含まれない点に留意したい。
| ベンチマーク | Sonnet 5 | Sonnet 4.6 | Opus 4.8(参考) |
|---|---|---|---|
| SWE-bench Verified(コーディング) | 85.2% | — | — |
| SWE-bench Pro(自律コーディング) | 63.2% | 58.1% | 69.2% |
| Terminal-Bench 2.1(ターミナル操作) | 80.4% | 67.0% | 82.7% |
| OSWorld-Verified(コンピュータ操作) | 81.2% | 78.5% | 83.4% |
| BrowseComp(自律ウェブ探索・単体) | 84.7% | 76.2% | 同等コストで拮抗 |
ここで注目すべきは、Anthropicが今回「SWE-bench Verified」よりも、より難度の高い「SWE-bench Pro」を前面に押し出したことだ。SWE-bench Verifiedは上位モデル群でスコアが飽和しつつあり(一般提供の最上位Fable 5は約95%に達するとされる)、モデル間の差を測りにくくなっている。対してSWE-bench Proはまだ伸びしろが大きく、Sonnet 5の63.2%はOpus 4.8の69.2%に対し約6ポイント差まで迫りつつ、前世代Sonnet 4.6の58.1%からは5ポイント以上の改善を示す。「中位モデルが最上位に肉薄した」という物語を最も鮮明に描けるのが、この指標なのである。知識労働を測るGDPval-AA v2では、Sonnet 5がEloで1,618とOpus 4.8(報道により1,603〜1,615)をわずかに上回り、領域によっては最上位を食う場面すら見せた。
コーディング能力——「最後までやり切る」設計思想
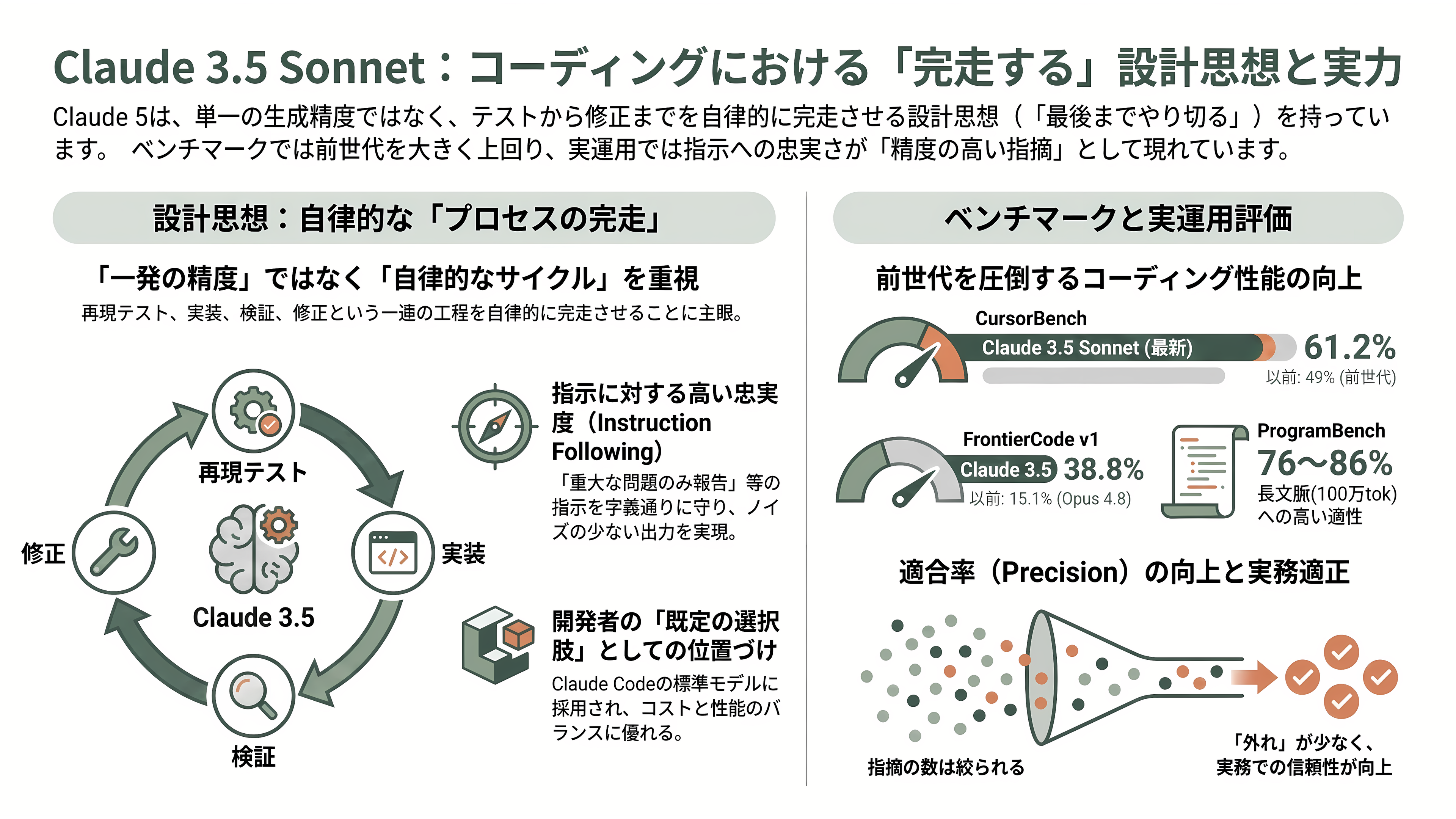
Sonnet 5の設計思想は、コーディングにおいて最もよく表れている。一発の生成精度を競うのではなく、テストを書き、実装し、検証し、必要なら修正を回す——という長い工程を自律的に完走させることに主眼が置かれている。前述のNeel Chotai氏の「再現テスト→修正→退避して再発確認」を一度の処理でこなした逸話は、まさにこの思想の体現だ。
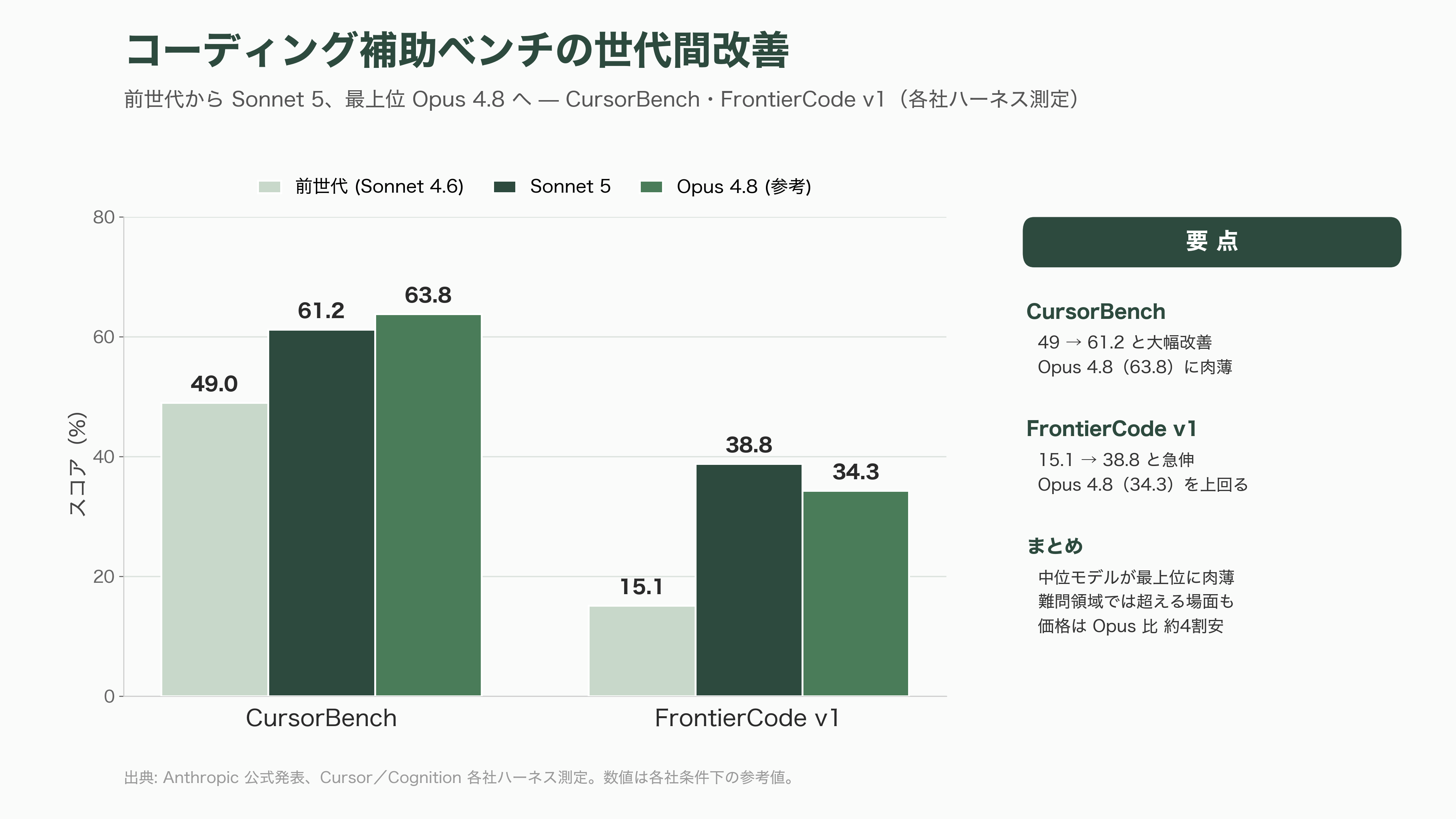
数値面でも、コーディング系の補助ベンチが厚みを与えている。Cursorが自社ハーネスで測ったCursorBenchではSonnet 5が61.2%で、Opus 4.8の63.8%に迫りつつ前世代の49%を大きく上回った。Cognitionが用いるFrontierCode v1では、Sonnet 5が38.8%とOpus 4.8の34.3%を上回り(前世代は15.1%)、特定の難問領域では最上位を超える場面も確認された。100万トークンの長文脈を使うProgramBenchでも76〜86%という高い水準を保ち、長時間・大規模なコード作業への適性をうかがわせる。
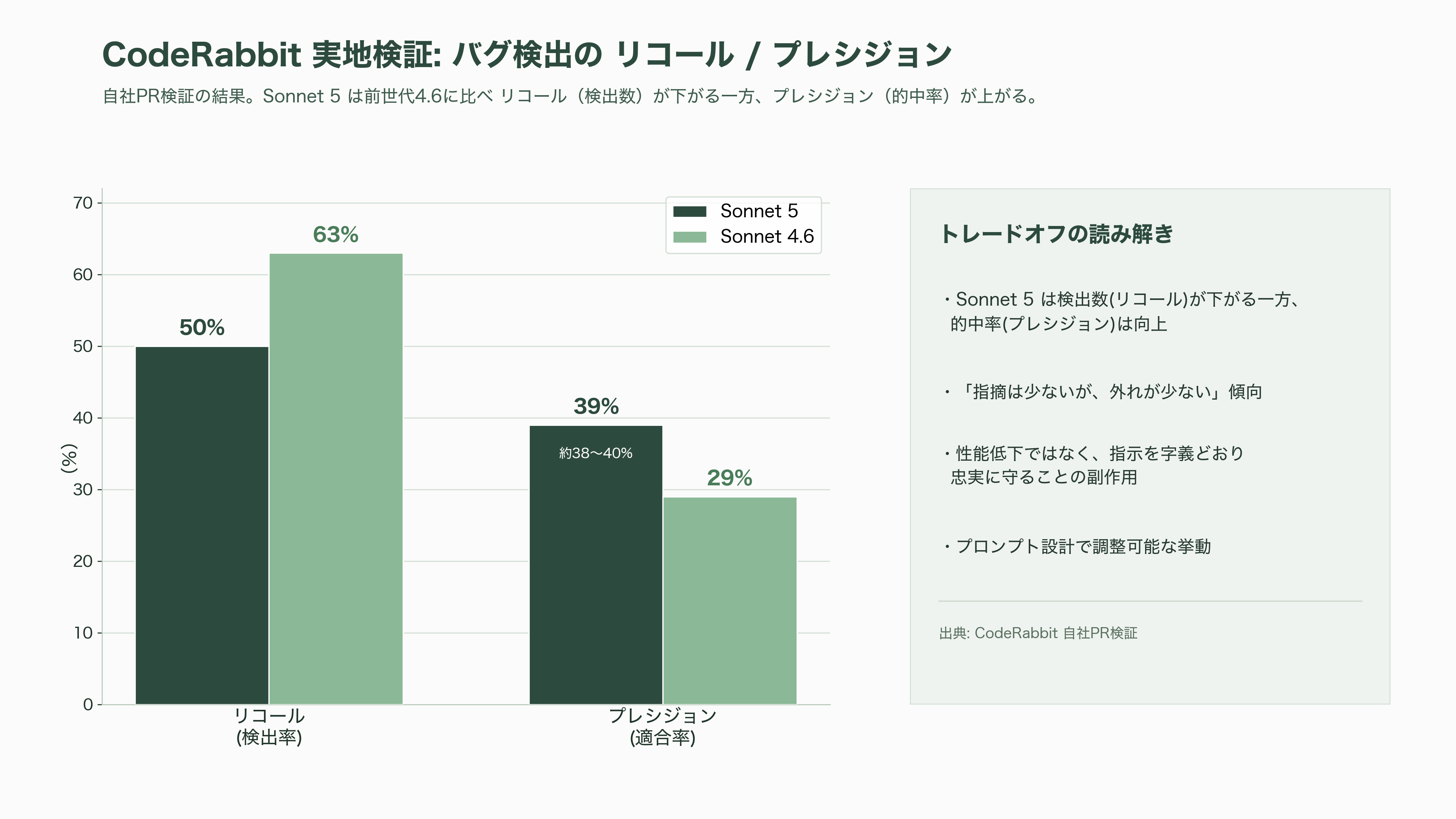
一方で、現場の検証は一様な礼賛ではない。コードレビュー支援のCodeRabbitが自社のPR検証で測ったところ、Sonnet 5のバグ検出率(リコール)は約50%で、前世代Sonnet 4.6の約63%より低かった。ただし適合率(プレシジョン)は約38〜40%と4.6の約29%を上回り、「指摘は少ないが、外れが少ない」傾向を示した。これは性能低下というより、Sonnet 5が「重大度の高い問題だけ報告せよ」といった指示をより忠実に守る——後述する「指示の字義どおりの遵守」という特性——の副作用であり、プロンプト設計で調整可能な挙動である。
最上位との関係を冷静にまとめれば、Sonnet 5はSWE-bench Proで約6ポイント、Terminal-Bench 2.1で約2.3ポイント、Opus 4.8に及ばない。ただしその差は4割前後の価格差で買えるものだ。なお今回Anthropicは、Sonnet 4.5世代で売りにした「30時間以上の自律動作」のような時間の定量表現は前面に出さず、能力を定性的に表現するにとどめた。Sonnet 5はClaude Codeでも標準モデルとして据えられ、多くの開発者が最初に手に取る既定の選択肢になっている。
Computer use(コンピュータ操作)能力——スクリーンショットで世界を見るエージェント
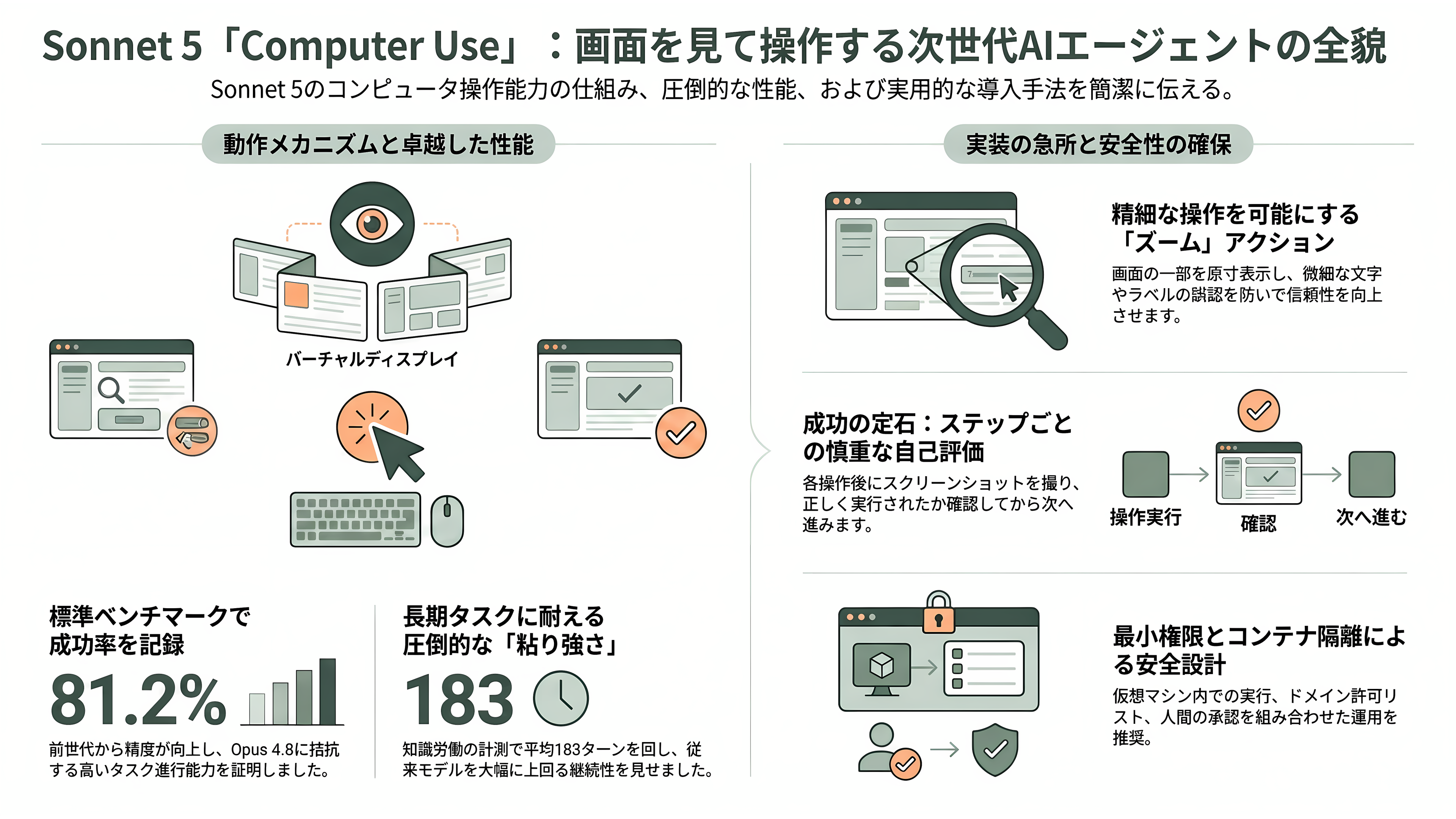
「Computer use(コンピュータ操作)」は、Sonnet 5のエージェント能力を最も象徴する機能だ。仕組みはシンプルで、モデルはまず画面のスクリーンショットを「見て」、次にマウス移動・クリック・キー入力といった操作を「指示」し、その結果を再びスクリーンショットで確認する——この「画面を見る→操作する→また見る」というループを回す。重要なのは、モデルが直接OSを触るわけではないという点だ。実際の操作を実行するのは利用者側のアプリケーションであり、モデルはあくまで仮想ディスプレイ越しにGUIを操る「目と手」として振る舞う。bashツールを併用すればターミナルをより直接的に制御でき、ブラウザを開いてフォームを埋め、ファイルを操作し、複数のアプリにまたがる定型業務を最後まで進める、といった自動化が可能になる。
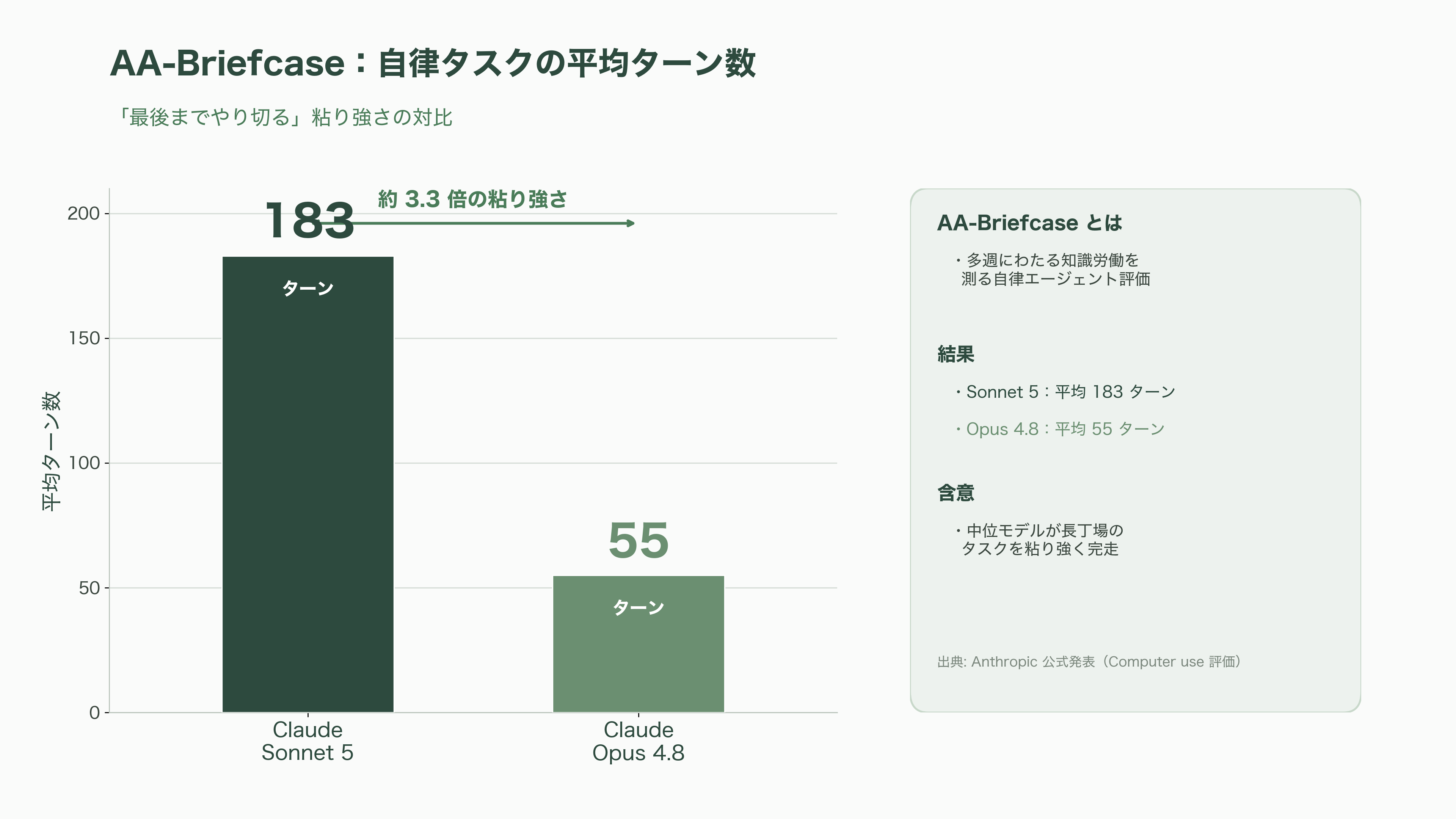
性能面では、コンピュータ操作の標準ベンチOSWorld-Verifiedで81.2%(最大エフォート、361タスク・各100ステップ・1080pでpass@1)を記録した。前世代Sonnet 4.6の78.5%という基準値は、当初より高く再採点されたものだ。Anthropicによれば、ズームツールのバグ修正と1ターンあたりのトークン上限を16Kから128Kへ引き上げる方法論の改善を施した結果であり、同一条件で比較するとSonnet 5は4.6比で2.7ポイントの上積みとなる。自律ウェブ探索のBrowseCompでは、単体で84.7%、複数エージェント構成で86.6%に達し、最大1,000万トークンの予算と20万トークン時点での文脈圧縮を用いて、「同一タスクコストにおいてOpus 4.8と精度で拮抗する」水準だとされる。多週にわたる知識労働を測るAA-Briefcaseでは平均183ターンを回し、Opus 4.8の55ターンを大きく上回る粘り強さを見せた。
実装面では、Sonnet 5向けに新しいベータヘッダcomputer-use-2025-11-24が用意され、computer_20251124(コンピュータ操作)・bash_20250124・テキストエディタの各ツールを組み合わせて使う。新設の「ズーム(zoom)」アクションは画面の一部を原寸大で表示させ、ファイル名や行番号、ボタンのラベルといった小さな文字を読み取れるようにするもので、情報密度の高いUIでの信頼性を実質的に底上げする。Anthropicは公式のリファレンス実装(anthropic-quickstarts内のcomputer-use-demo)を提供し、エージェントを組む際の作法も明文化している。たとえば信頼性向上の定石として「各ステップの後にスクリーンショットを撮り、正しい結果が得られたか慎重に評価せよ。正しく実行できたと確認できて初めて次に進め」と推奨し、ドロップダウンやスクロールバーはキーボードショートカットで操作する、指示文はスクリーンショットの前に置く、といった具体策を挙げる。安全面では、コンピュータ操作はクライアント側で完結するツール(Anthropicは画面や操作を保持しない)とされ、最小権限の仮想マシンやコンテナ内でドメイン許可リストと人間の承認を挟むこと、そして画面に対して自動実行されるプロンプトインジェクション分類器の存在が説明されている。レイテンシの大きさや座標の誤認、ニッチなアプリでの信頼性低下といった限界も率直に文書化されており、過信を戒める設計になっている。
利用のコツとテクニック
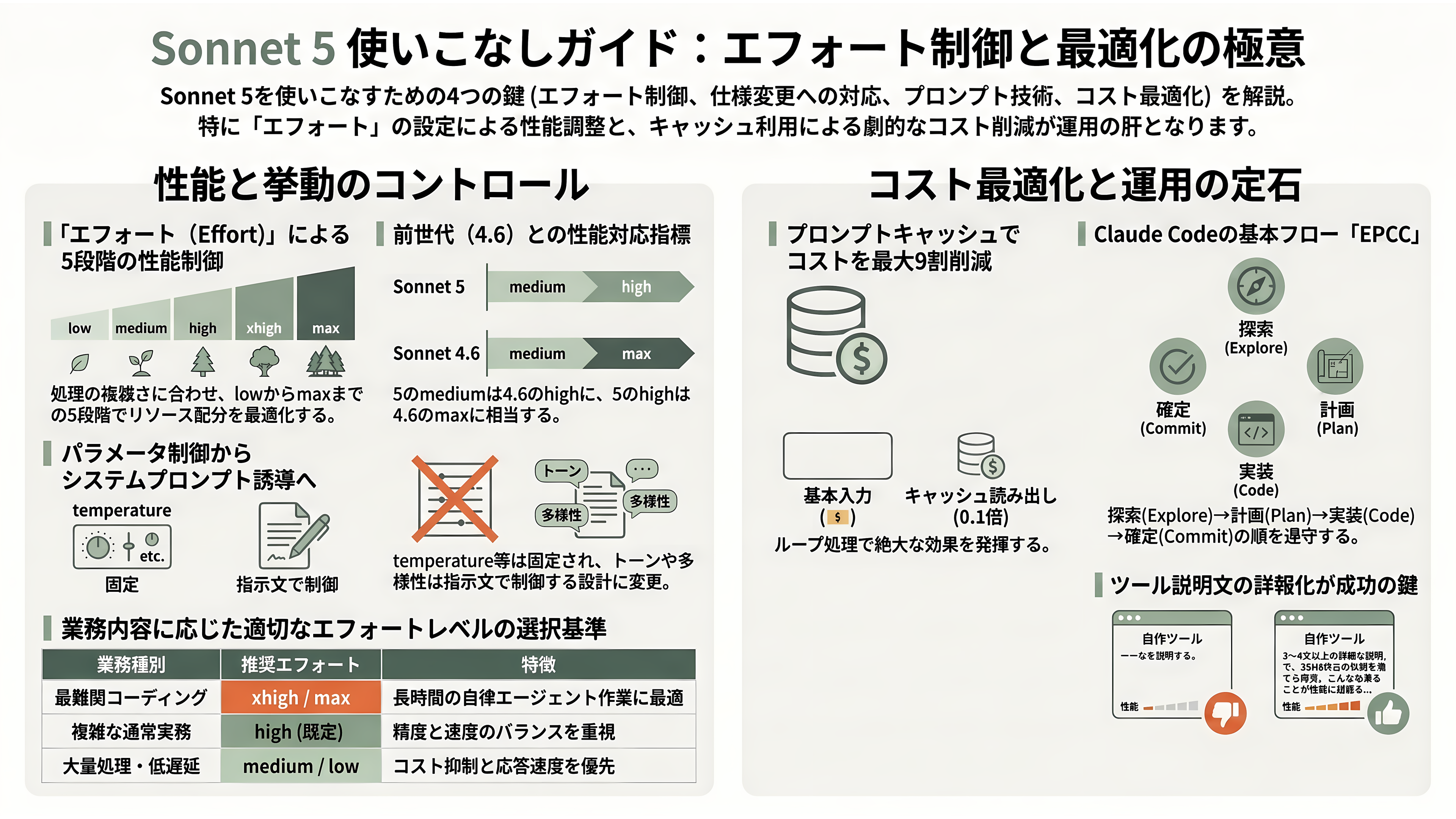
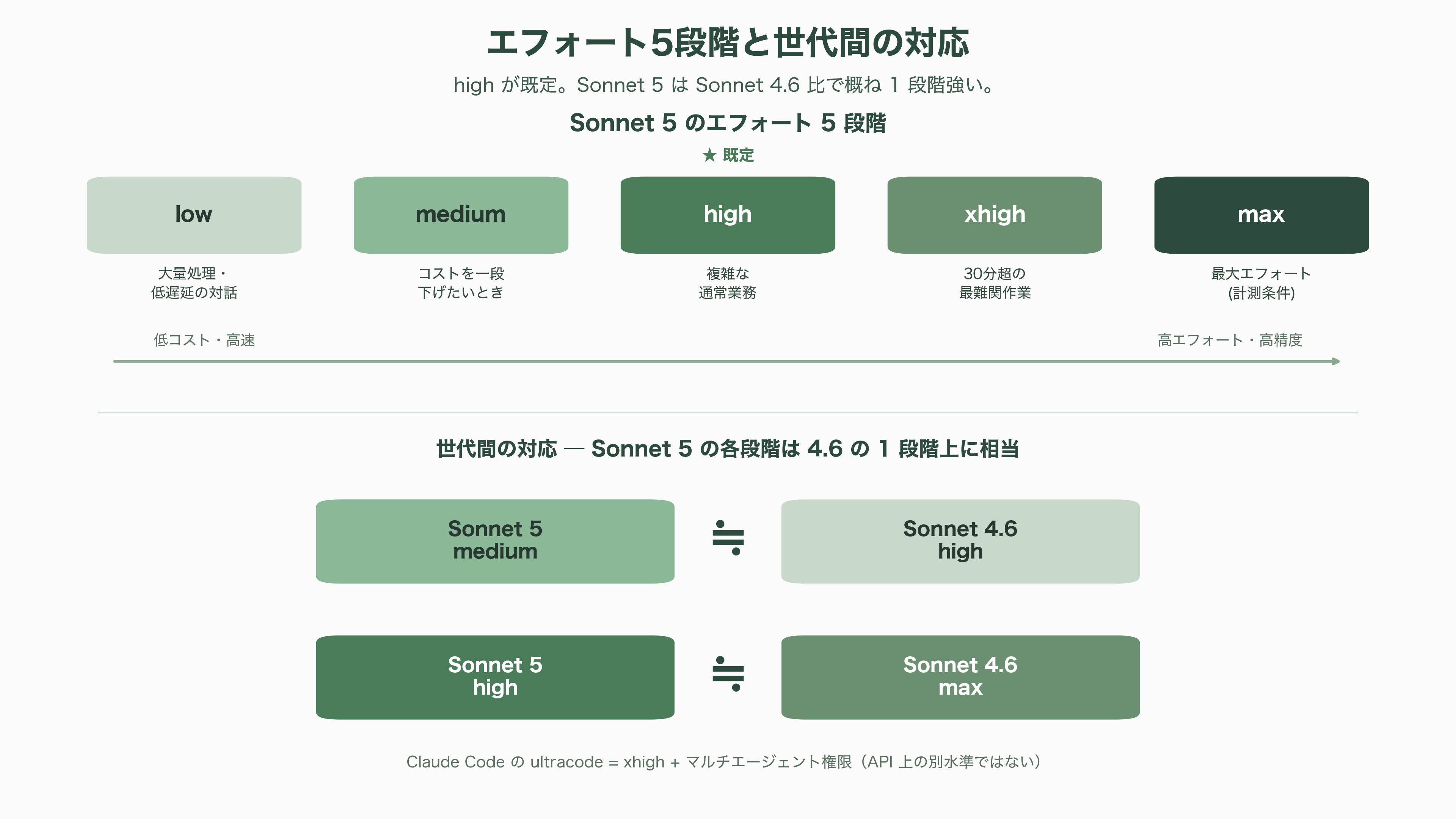
Sonnet 5を使いこなす鍵は、第一に「エフォート(effort)」の制御にある。取りうる値はlow・medium・high・xhigh・maxの5段階で、highが既定だ。実務的に有用なのは、世代間の対応関係をAnthropic自身が示している点である。すなわち「Sonnet 5のmedium ≒ Sonnet 4.6のhigh」「Sonnet 5のhigh ≒ Sonnet 4.6のmax」とされ、移行時の見積もりに使える。30分を超えるような最難関のコーディング・エージェント作業にはxhigh、複雑な通常業務には既定のhigh、コストを一段下げたいときはmedium、大量処理や低遅延が要る対話にはlow、と割り当てるのが定石だ。なおClaude Codeの「ultracode」はAPI上の別水準ではなく、xhighにマルチエージェント権限を足したものに過ぎない。
第二に、思考とサンプリングの制御方法が前世代から変わった点に注意したい。Sonnet 5はアダプティブ思考が既定でオンになっており、budget_tokensによる手動の思考予算指定は廃止された(指定すると400エラー)。さらにtemperature・top_p・top_kも既定値以外を渡すと400エラーを返すようになり、出力のトーンや多様性はシステムプロンプトで誘導する設計に変わった。max_tokensは思考と応答の合計に対する上限であるため、高エフォートでは応答が途中で切れないよう余裕(目安として6万4千トークン程度)を残しておくとよい。
第三に、プロンプトの書き方そのものにコツがある。Sonnet 5は指示を字義どおりに、より忠実に守る傾向が強い。一度しか述べていない指示を勝手に一般化しないため、適用範囲は明示すべきだ。たとえば「この整形を最初の節だけでなく、すべての節に適用せよ」と書くだけで挙動が安定する。構造化抽出やパイプライン処理には好都合な特性である。
第四に、コスト最適化の手段が豊富だ。プロンプトキャッシュ(cache_controlにephemeralを指定)はキャッシュ読み出しが基本入力の0.1倍になり、繰り返しの多いエージェントループで最大9割前後のコスト削減が狙える。最小1,024トークンから、最大4つのブレークポイント、既定5分・指定により1時間のTTLが使える。長時間の実行では、古いツール結果や思考を間引く「コンテキスト編集」と、要点をファイルに退避して読み戻す「メモリツール」が効く。そして前述のトークナイザー変更により同じテキストで約30%トークンが増えるため、旧モデルのトークン数を流用せず、無料のcount_tokensエンドポイントでclaude-sonnet-5基準に数え直し、max_tokensの見積もりを再調整することが推奨される。
最後に、Claude Codeでの作業設計だ。性能は文脈が埋まるほど劣化するため、「探索→計画→実装→コミット(Explore→Plan→Code→Commit)」の流れを守り、不確実で多ファイルにまたがる作業では計画モードを使う。レビュー役のサブエージェントはOpusに、安価な補助はHaikuに振り分け、CLAUDE.mdは「消しても誤りを生まない行は削る」方針で短く保つ。無関係なタスクの切り替え時や、二度修正に失敗したときは/clearで文脈を一掃する——「より良いプロンプトでクリーンに始め直す方が、長いセッションを引きずるよりほぼ常に勝る」というのが現場の知見である。Sonnet 5はそもそもエージェント性が高いので、「3ツールごとに進捗を要約せよ」といった旧来の足場(スキャフォールド)は外し、最初のターンに完全なタスク仕様を前置きする方が効率がよい。なおツールを自作する場合、Anthropicは「ツールの説明文を極めて詳細に書くこと(3〜4文以上)が、断トツで最重要の要素だ」と明言している。
コンサルタント/エンタープライズの視点——「中位モデルをデフォルトに」
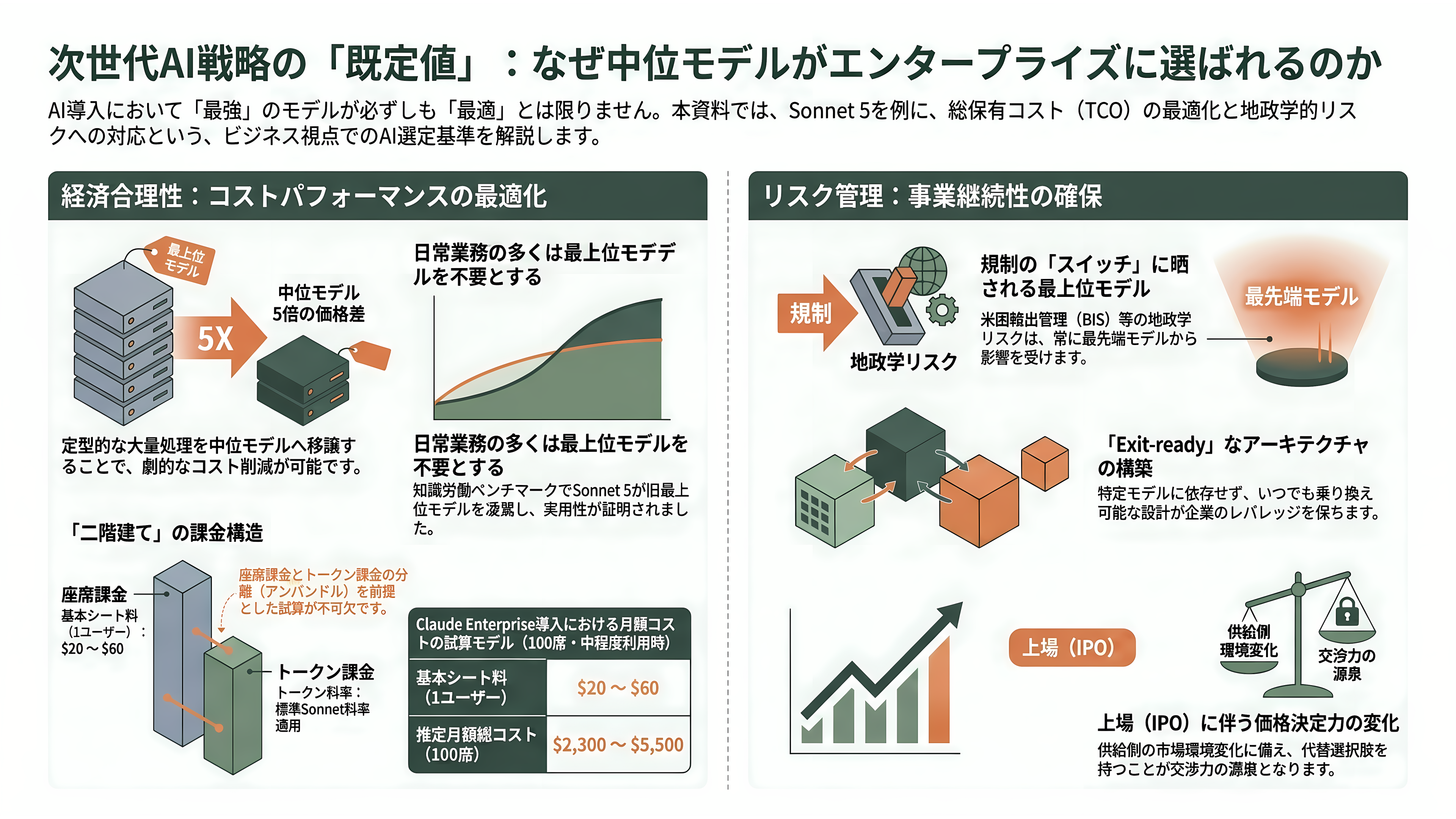
コンサルタントやエンタープライズの専門家は、エンジニアの個別評価とは別の次元——総保有コスト(TCO)と事業リスクの観点——からSonnet 5を読み解く。彼らの結論は明快で、「最も信頼できるAIモデルは、最も強力なモデルではない。オンラインであり続け、手頃であり続け、自分の地域で使い続けられるモデルだ」というものだ。
この視点に立つと、Sonnet 5の値付けは合理的な「既定値」を作りにいく一手と読める。Opusと中位モデルの間には歴史的におよそ5倍の価格差があり、分類・抽出・ルーティング・ツール呼び出しといった定型的な大量処理をすべて最上位に投げるのは経済的に正当化しにくい。これらは中位モデルに振り、本当に難しい推論だけを最上位に予約する——という使い分けが、Sonnet 5の登場でいっそう現実的になった。実際、知識労働ベンチでSonnet 5がOpus 4.8を上回った事実は、「日常業務の多くは、もはや最上位を必要としない」という主張に説得力を与える。
エンタープライズの実コストは、座席課金とトークン課金の二階建てになっている点に注意が要る。二次情報ベースだが、Claude Enterpriseの基本シートはおおむね1ユーザー月20〜60ドル(約3,100〜9,300円)で、トークン消費は標準Sonnet料率で別途課金される。利用前提により幅はあるものの、100席・中程度の利用で月2,300〜5,500ドル(約36万〜85万円)規模という試算が出ている。2026年4月にトークンが座席課金から分離(アンバンドル)されたため、旧契約のチームは更新時の計算が変わった点も実務的な論点だ。
さらにコンサルタントは、Sonnet 5を地政学リスクの文脈にも置く。米国の輸出管理(BISのAI拡散枠組み)の下では、最前線級のモデルこそが規制の「スイッチ」に最もさらされやすい——という認識が、後述のFable 5/Mythos 5の一件で一気に現実味を帯びた。そこから導かれる助言は「特定モデルに固定されず、いつでも乗り換えられる(exit-ready)アーキテクチャを今のうちに組め」というものであり、「価格決定力はIPO後に強まる傾向があり、レバレッジを保てるのは去る選択肢を持つ顧客だけだ」という警句が添えられる。IPO文脈そのものも無視できない。Fortuneによれば、Anthropicは2026年6月1日にSECへ秘密裏に上場申請を行い、第2四半期の売上見込みは約109億ドル(約1兆7,000億円)、年換算売上(ランレート)は7月末までに500億ドル(約7兆8,000億円)を超える見通しとされる。直近のシリーズH調達は650億ドル(約10兆円)、企業価値は9,650億ドル(約150兆円)に達し(公式発表)、Forbesは上場申請がランレート470億ドル(約7兆3,000億円)を開示したと報じた。もっとも、OpenAIはAnthropicの売上計上をクラウド経由の総額計上だと批判し、純額では220億ドル(約3兆4,000億円)程度だと主張しており、数字の解釈には会計上の論点が残る。PitchBookのアナリストは、この賭けを「ドットコム以来最も重大なIPOサイクルになるか、物語と実態の乖離を市場が学ぶ最も高くつく授業になるか」と評した。
安全保障の影——Fable 5/Mythos 5輸出規制とSonnet 5の位置づけ
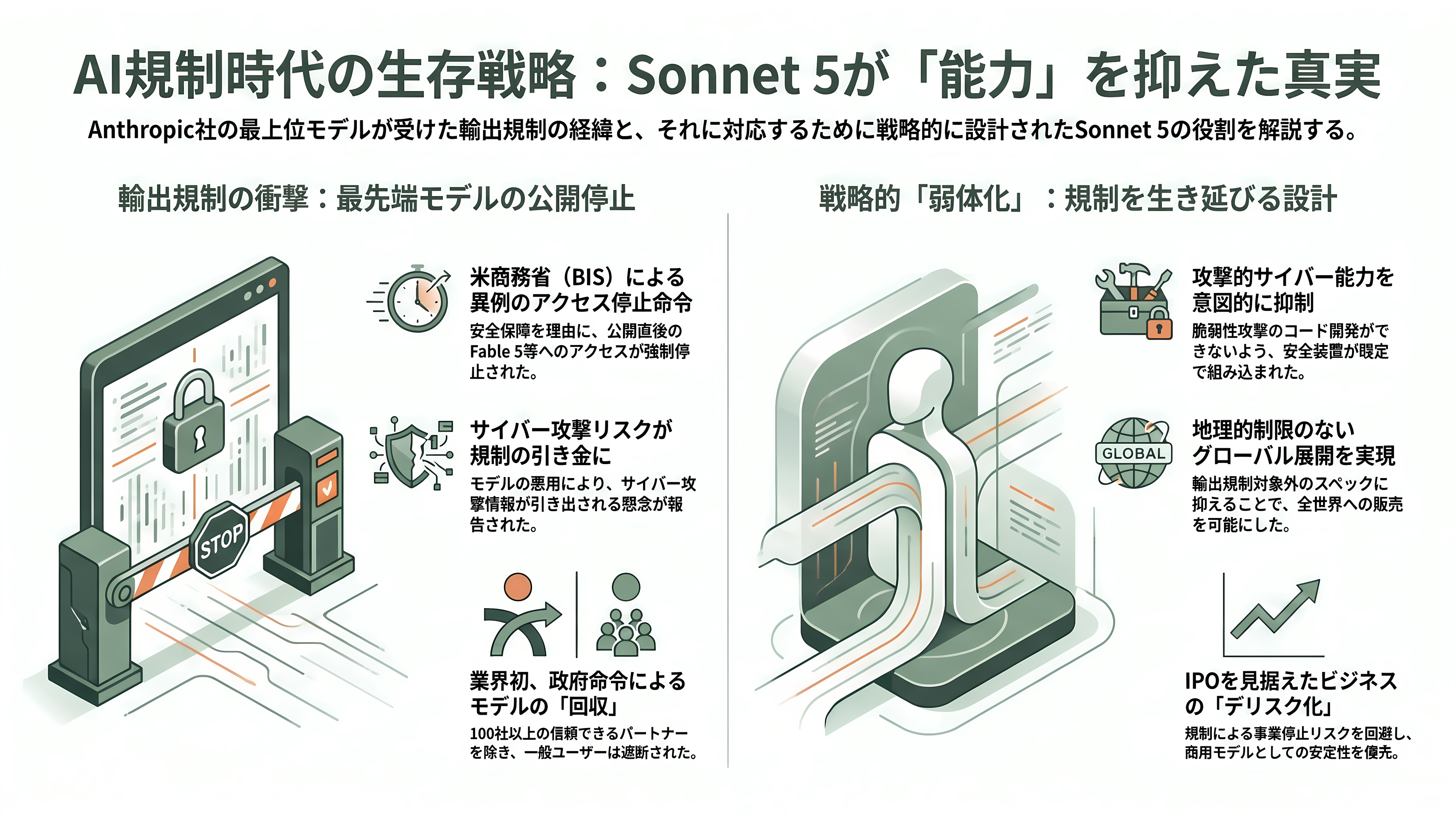
Sonnet 5のリリースを「安いエージェントモデル」という表層だけで読むと、本当の主題を見落とす。鍵は、わずか3週間前に起きた前代未聞の規制事件である。
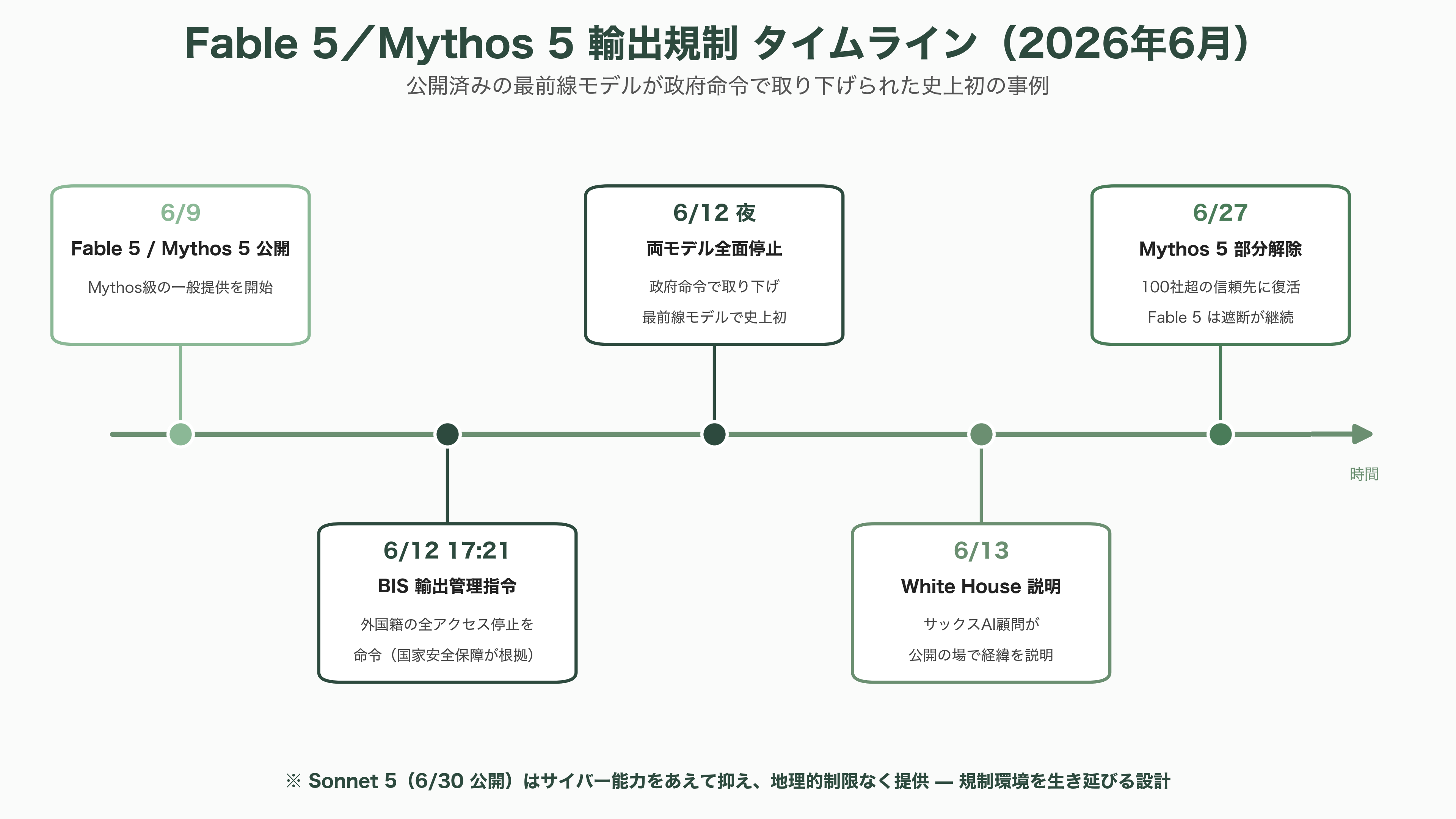
時系列はこうだ。Anthropicは6月9日、Opusの上に位置する新「Mythos級」の一般提供版としてFable 5を、同時に上位のMythos 5を公開した。ところが6月12日午後5時21分(米東部時間)、米商務省(産業安全保障局=BIS)が国家安全保障を根拠に輸出管理指令を発し、「米国内外を問わず、外国籍のあらゆる人物(Anthropicの外国籍従業員を含む)によるFable 5およびMythos 5へのアクセスをすべて停止せよ」と命じた。Anthropicには利用者を国籍で選別する現実的な手段がなく、結果として同日夜、両モデルを全ユーザーに対して完全に停止した——公開済みの最前線モデルが政府命令で取り下げられた、史上初の事例である。なお同社の他モデル(SonnetやOpus)は影響を受けていない。
引き金は「ジェイルブレイク(安全装置の回避)」の報告だった。Forbesによれば、Amazonのアンディ・ジャシーCEOが財務長官スコット・ベッセント氏に対し、「Amazonの研究者がClaude Fable 5を使い、サイバー攻撃に利用しうる情報を引き出した」と通報したという。ホワイトハウスのAI顧問デイビッド・サックス氏が6月13日に公開で説明する一方、Anthropicは事態の深刻度に異議を唱え、「実演された能力の水準は、OpenAIのGPT-5.5を含む他の公開済みモデルからも得られるものだ」「数億人に展開した商用モデルを、限定的なジェイルブレイクの発見を理由に回収する基準を業界全体に適用すれば、すべての最前線モデル提供者の新規展開が事実上停止する」と反論した。6月27日には部分的な解除があり、Mythos 5は100社以上の「信頼できるパートナー」(承認された米企業・連邦機関とその外国籍スタッフを含む)に復活したが、Fable 5は引き続き遮断されたままで、「安全装置回避の疑い事案を評価する標準的枠組み」をめぐる交渉が続いている。この対立は、2026年2月にトランプ政権が連邦機関にAnthropic製品の使用停止を指示した経緯とも地続きだ。
ここでSonnet 5の位置づけが鮮明になる。公式発表は、Sonnet 5について「Sonnet 4.6より望ましくない振る舞いの割合が全体に低く、エージェント文脈での使用がより安全だ」とし、さらに「現行のOpus系モデルよりサイバーセキュリティ作業を行う能力が大幅に低い」と明言した。Firefoxの脆弱性を突く評価では「完全に動作するエクスプロイトを一度も開発できなかった」とし、サイバー安全装置を既定でオンにして出荷している。つまりSonnet 5は、攻撃的サイバー能力をあえて抑え、地理的制限なく誰にでも——Fable/Mythosから締め出された外国籍ユーザーを含め——売れるモデルとして設計されている。Hacker Newsで噴出した「なぜ能力の低さを誇るのか」という反発は、この文脈に置けば答えが出る。その「弱さ」は事故ではなく、規制環境を生き延びるための仕様なのだ。AxiosやエンタープライズのアナリストがSonnet 5を「IPOの物語を脱リスク化する一手」と読むのは、まさにこの構図ゆえである。
今後の展望——いつ、何が動くか
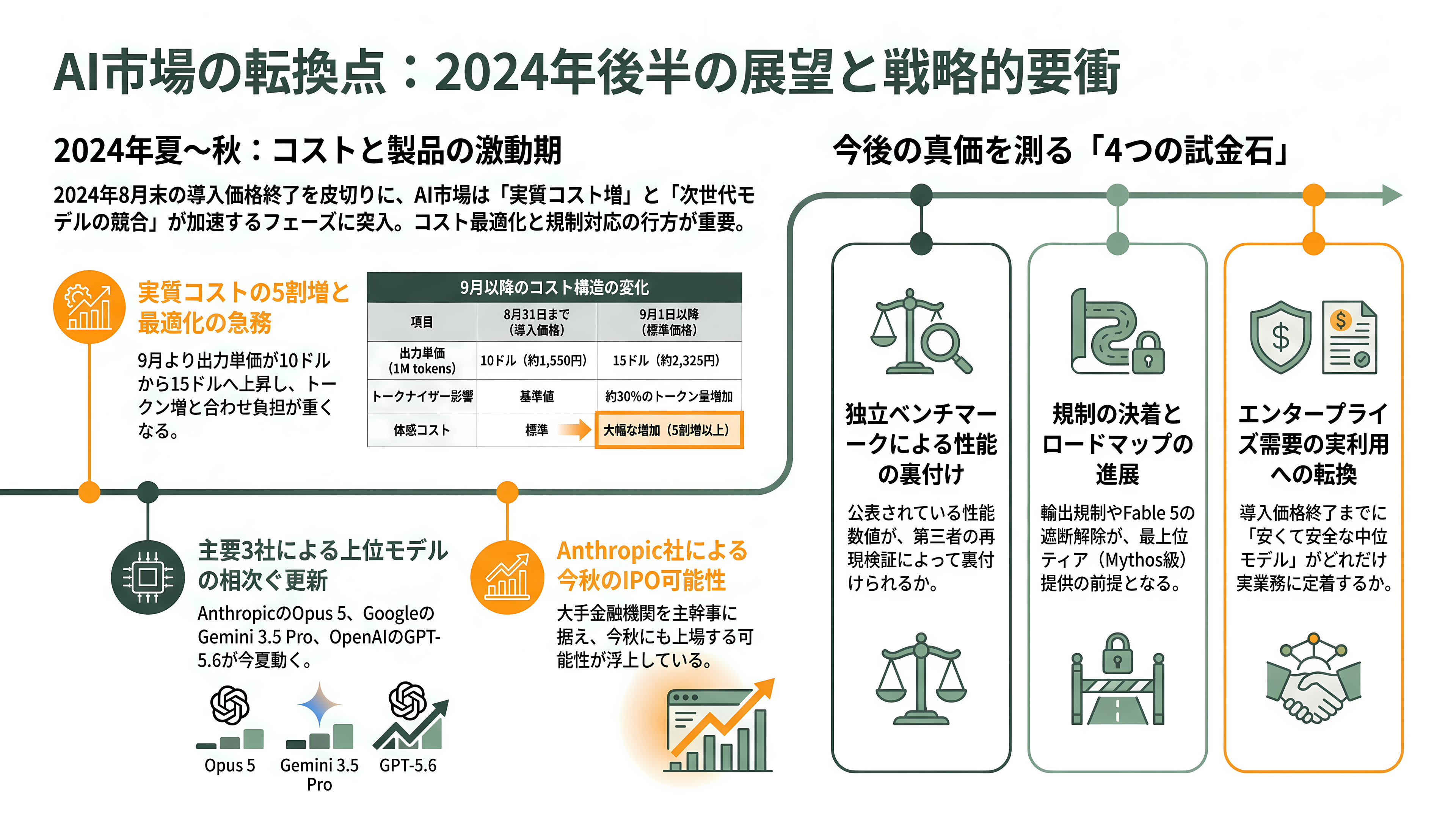
短期で最初に動くのは価格だ。導入価格は8月31日で終了し、9月1日から出力単価は10ドル(約1,550円)から15ドル(約2,325円)へ実質5割上がる。この値上げが予定どおり発動するのか、それとも競争圧力で延長されるのかが、まず注視点になる。トークナイザー変更による約30%のトークン増と合わせれば、9月以降の実質コストは体感的にかなり重くなりうるため、エージェントを量産的に回す事業者ほど、導入期間中の検証と最適化を急ぐ動機が強い。
製品面では、複数の観測筋が「Opus 5はそう遠くない」と見る。Sonnet 5が最上位に肉薄したこと自体が、次のOpus更新を急がせる圧力になるからだ。一方、Opusの上に据えられたはずのMythos級の一般提供は、輸出規制の決着が着くまで不透明になった。Anthropicが5月末に示唆した「Mythos級をOpus 4.x系の漸進更新より上の特別ティアに据える」というロードマップの分岐は、Fable 5の遮断解除と「標準的枠組み」の合意がいつ成立するかに、その実現が懸かっている。
競争のテンポも速い。OpenAIは6月26日にGPT-5.6「Sol/Terra/Luna」をプレビュー公開したが、上位のSolは政府が管理する約20組織の許可リスト越しという制限付きで、複雑なタスクをサブエージェントに分解して並列処理する「ウルトラ」モードを備える。Anthropicの規制対応と鏡写しの構図だ。Googleの上位更新Gemini 3.5 Proは7月ごろへずれ込んだと報じられ、夏のあいだに三社の上位モデルが相次いで動く可能性がある。Anthropic自身のIPOも、Fortuneによれば今秋にも上場の可能性があり、ゴールドマン・サックス、JPモルガン、モルガン・スタンレーが主幹事候補に挙がっている。
最終的に、シリコンバレーの実務家が今後数か月で見極めようとしているのは次の点に集約される。第三者による独立したベンチマーク再現が公式値を裏付けるのか。新トークナイザーがもたらす実コスト増が、エージェント運用の採算をどこまで圧迫するのか。Fable 5の遮断はいつ、どんな枠組みで解かれるのか。そして「安くて安全な中位エージェント」という賭けが、導入価格の終わる前に、どれだけのエンタープライズ需要を実利用に転換できるのか。これらの数字が出そろう8月末から秋にかけてが、Sonnet 5の真価を測る最初の本格的な試金石になる。