Gemini Omni とは何か ―― I/O 2026 が示した「Veo の次」
まず全体像から押さえたい。Gemini Omni は、2026年5月19日に開幕した Google I/O 2026 の基調講演で、Sundar Pichai CEO と Google DeepMind が中核トピックとして披露した動画生成・編集モデルである。Google の公式発表は一文でこう表現している ――「あらゆる入力から、あらゆるものを作り出せるモデル。まずは動画から(create anything from any input — starting with video)」。最初に一般提供が始まったのは軽量・高速版の「Gemini Omni Flash」で、同日からグローバルに展開された。
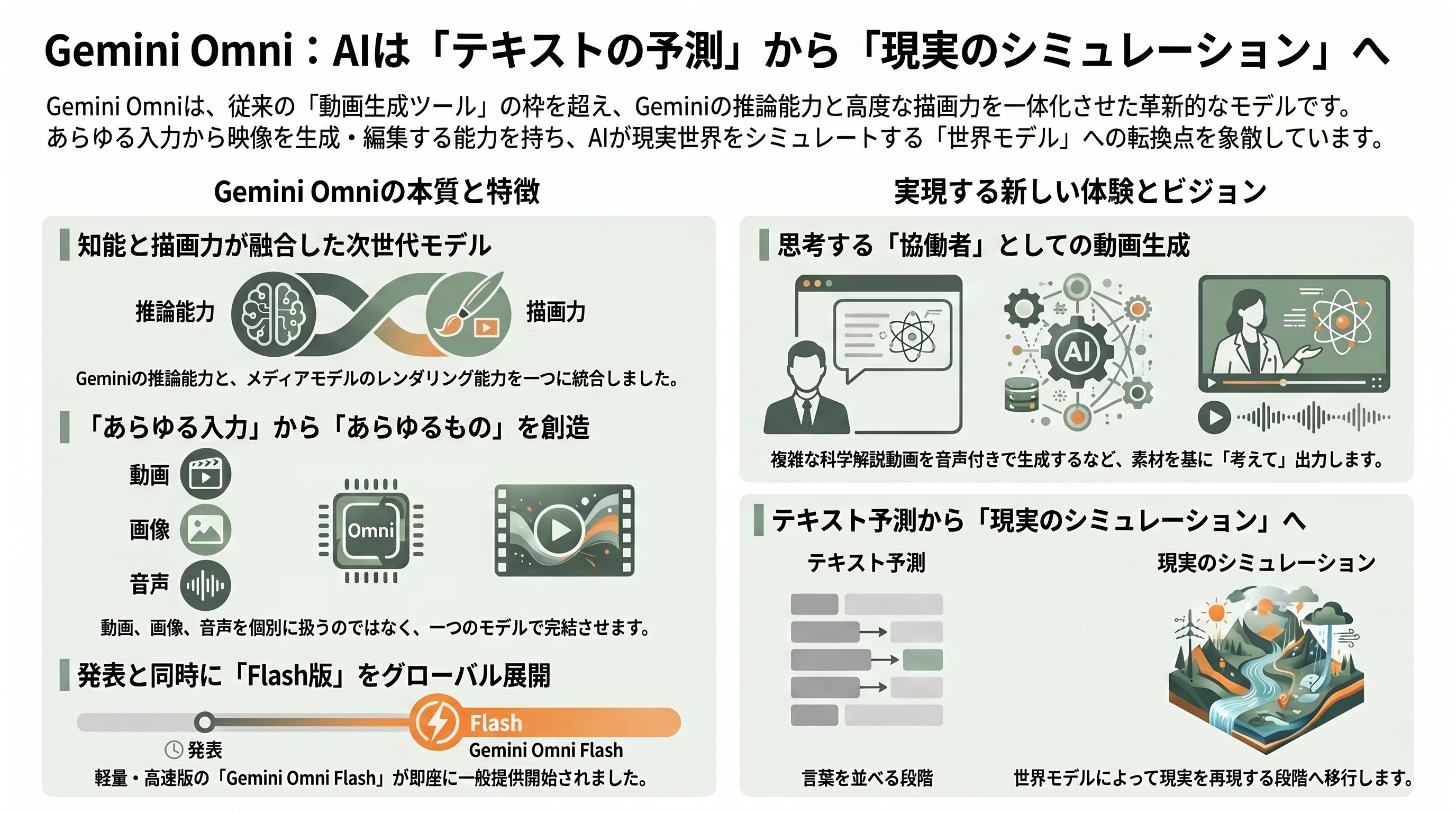
ここで重要なのは、Omni が単なる「動画生成ツールの新バージョン」ではない、という点だ。これまで Google の生成メディアは、動画は Veo、画像は Imagen、音声は別系統、というように機能ごとにレーンが分かれていた。Omni はこれらを一つのモデルに畳み込み、Gemini 本体の「知能(推論・世界知識)」と、メディアモデルの「描画力(レンダリング)」を一体化させた。DeepMind のプロダクト管理ディレクター Nicole Brichtova は TechCrunch に対し、これを「Gemini の知能と、私たちのメディアモデルのレンダリング能力を組み合わせる進歩の、次の一歩」と説明している。公式ブログを執筆したのは DeepMind の CTO 兼 Google チーフ AI アーキテクトである Koray Kavukcuoglu 氏だ。
具体例を挙げると分かりやすい。Kavukcuoglu 氏が示したデモでは、「タンパク質の折りたたみをクレイアニメ(粘土アニメ)で解説して」と指示するだけで、正確なナレーション音声付きのストップモーション動画が一本生成された。手元に一枚の写真があれば、それを起点に動画化することもできるし、テキストで写真を編集する ―― これは Google の画像編集モデル「Nano Banana」に近い体験 ―― ことも可能だ。つまり Omni は、「素材を put-in すると、考えてから一本の映像を返してくる」協働者のように振る舞う。
Pichai はこの方向性を、AI の歴史的な転換点として位置づけた。彼の言葉を借りれば、「世界モデルによって、AI はテキストを予測する段階から、現実をシミュレーションする段階へと移りつつある」。この一文が、Omni を理解する上での背骨になる。以下、クリエイターが知っておくべき五つの論点を順に掘り下げていく。
双方向・同時マルチモーダル推論 ―― 「貼り付けたものすべて」を一度に考える
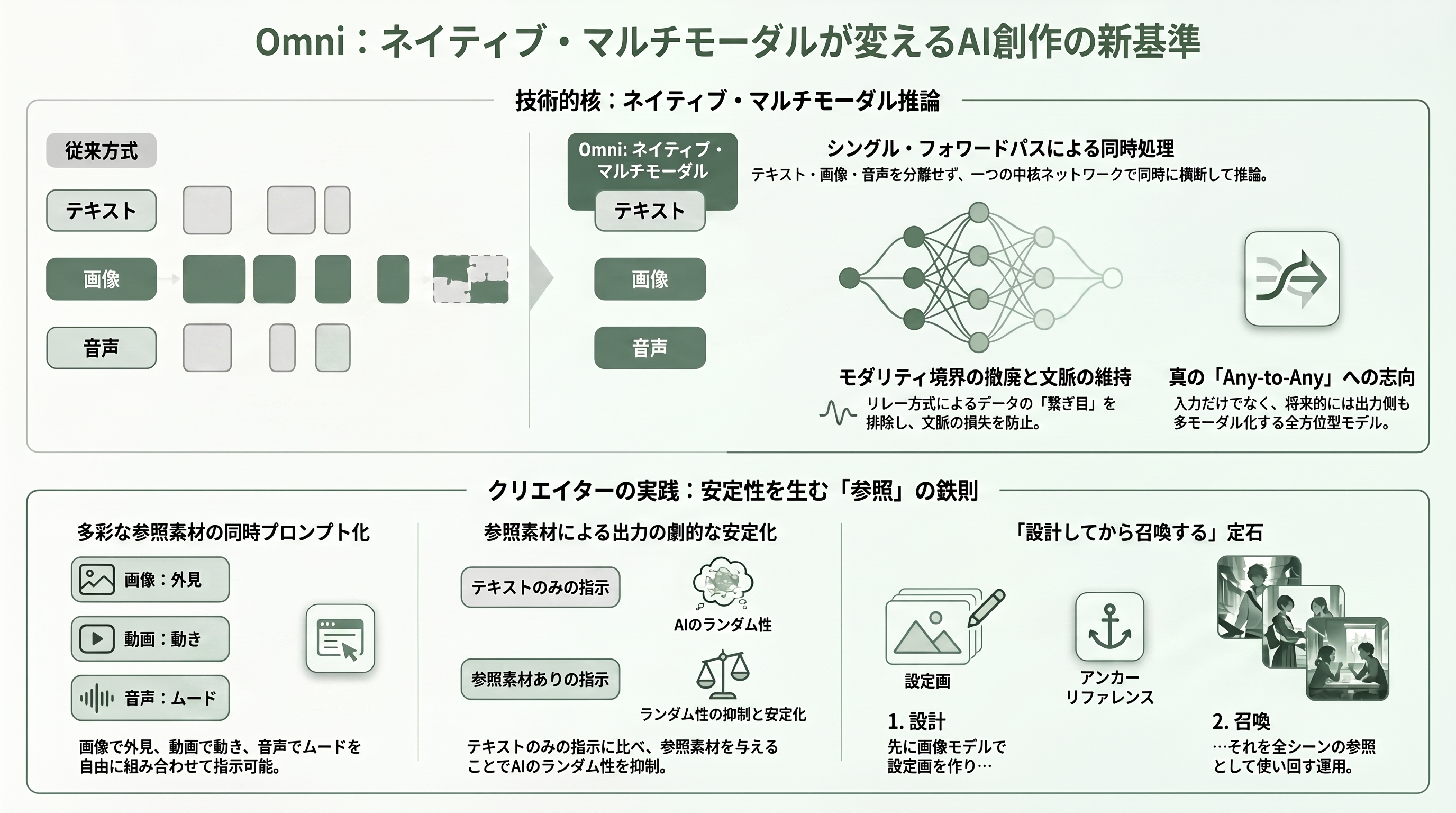
Omni の技術的な核心は、「ネイティブ・マルチモーダル」であることだ。テキスト・画像・音声・動画という異なる種類のデータを、別々のステップに振り分けてから繋ぎ合わせる(stitch する)のではなく、一つの中核ニューラルネットワークが同じ forward pass(推論の一回の流れ)の中で同時に横断して考える。従来のように「テキストモデルの出力をメディアモデルに渡す」リレー方式では、モダリティの境界で文脈が失われ、つなぎ目にアーティファクト(破綻)が出やすかった。Omni はこの境界そのものを取り払った。
クリエイターにとっての実利は「リファレンス(参照素材)の自由度」に直結する。Google の表現では、「Omni は、画像・テキスト・動画・音声のどんな参照でも、一つのまとまった出力へと変換する」。一枚の静止画でキャラクターの見た目を、別の動画クリップで動きのニュアンスを、音声サンプルでムードを、テキストで指示を ―― これらを一つのプロンプトに混ぜて投げ込める。モデルはそのすべてを突き合わせて推論し、全要素を反映した一本の動画を返す。これが「双方向・同時」の実体である。入力が多モーダルであるだけでなく、出力側も将来的に多モーダル化していく(後述)という意味で、文字どおり any-to-any を志向している。
ただし現時点(2026年6月初旬)では、音声入力は「ボイス・リファレンス(声の参照)」のみのスタートで、その他の音声入力タイプは順次展開、と公式に明記されている。ここは誇張せずに押さえておきたい。
クリエイター視点の TIPS: 公式・各メディアのプロンプト検証が口を揃えるのは、「参照素材は可能な限り添付せよ」という鉄則だ。テキストだけのプロンプトは、モデルにビジュアル・アイデンティティをゼロから発明させることになり、複数ターンの編集を重ねるほどランダム性が累積していく。逆に、参照画像・モーション用クリップ・音声トラックを一つでも与えると、出力の安定性が劇的に上がる。キャラクターを固定したいなら、Nano Banana(画像モデル)で先に「設定画」を一枚作っておき、それを参照として全シーンに使い回すのが定石になりつつある。一度デザインした人物を、以後どのシーンにも呼び出せる ―― この「設計してから召喚する」発想が、Omni 時代のキャラクター運用の基本だ。
物理エンジン・インテリジェンス ―― 「世界モデル」が映像の常識を変える
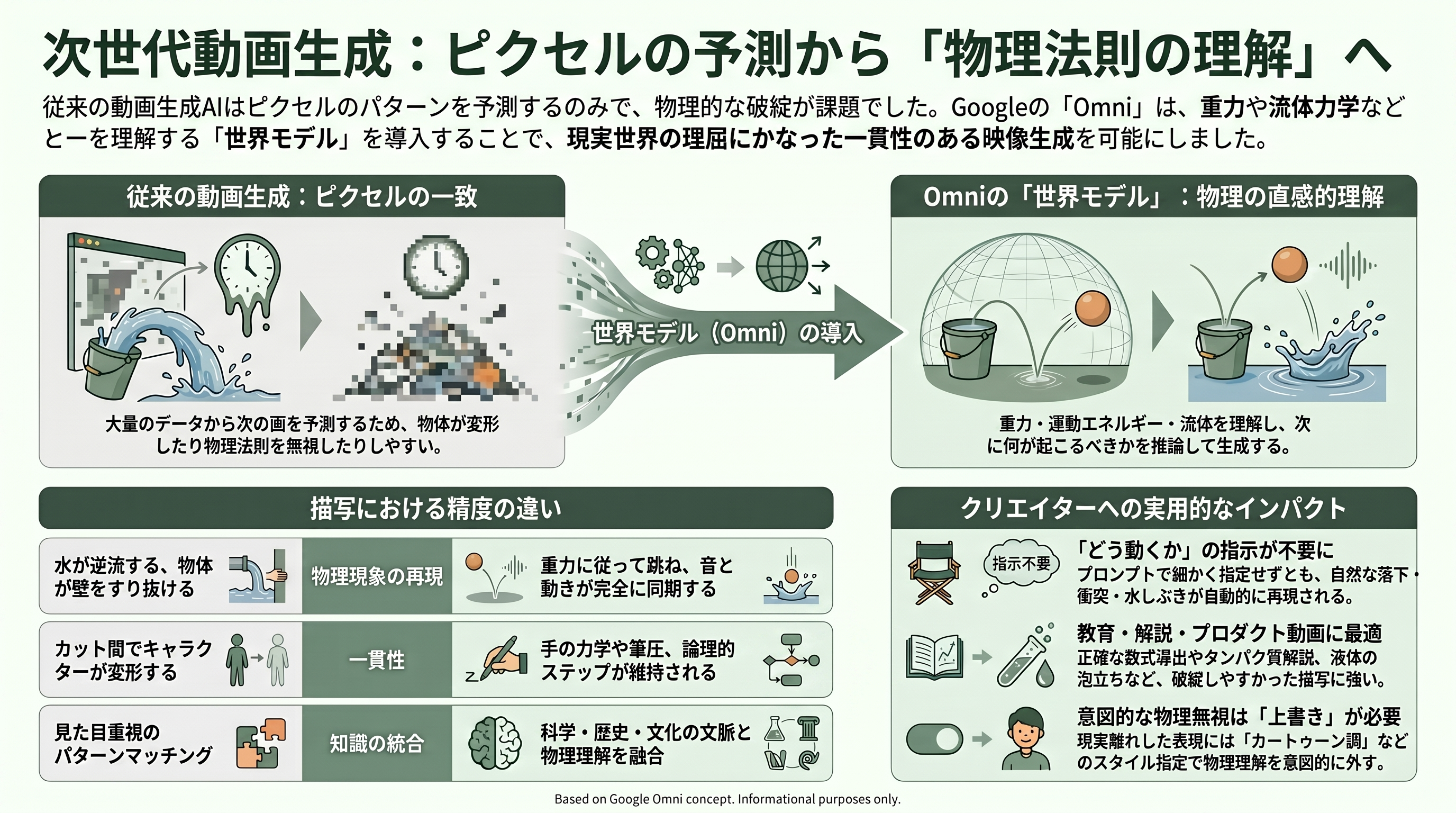
Omni が「Veo の延長」ではなく世代交代だと言われる最大の理由が、物理法則の理解にある。Google の公式記述は、Omni が「重力・運動エネルギー・流体力学といった力に対する、改善された直感的な理解」を備え、「物理の直感的理解と、歴史・科学・文化の文脈に関する Gemini の知識を組み合わせる」と述べる。DeepMind CEO の Demis Hassabis は基調講演で、Omni を「世界モデル(world model)」 ―― 現実の内的な理解を構築し、あるシーンの中で次に何が起こるべきかを推論するシステム ―― として紹介した。
なぜこれが効くのか。従来の動画生成は、大量のピクセルをパターンマッチングして「次のフレーム」を予測する方式が主流だった。見た目はそれらしくても、振る舞いが一貫しない。キャラクターがカットの間でモーフィング(変形)し、影が光源を無視し、水が物質ではなくテクスチャのように流れる ―― 初期の Sora で噴水の水が上向きに流れたり、物体が壁をすり抜けたりした例が象徴的だ。Omni は「次のピクセル」を当てるのではなく、力がどう働くかという物理の枠組みを生成プロセスに直接組み込んだ、と説明される。
具体的なデモが説得力を持つ。各メディアが取り上げた代表例は「ガラス玉(マーブル)」のクリップで、複雑なピタゴラ装置のようなトラックをビー玉が転がり落ち、跳ねるたび・鈴が鳴るたびに同期した効果音が鳴る。あるレビューは「ボールの物理が信じられる出来」と評した。Kavukcuoglu 氏のクレイアニメ・タンパク質解説も、ナレーションの正確さという意味で「科学的知識に裏打ちされた生成」の好例だ。黒板に数学的に正しい三角関数の導出を書いていく教授のデモも報じられており、これは手の力学・チョークの筆圧・論理的なステップの順序まで一貫してモデル化されていることを示す。
クリエイター視点の TIPS: 物理理解が強いということは、プロンプトで「どう動くか」を細かく指示しなくても、自然な落下・衝突・水しぶき・髪や布のなびきが返ってくる、ということだ。これは作り手の負担を下げる一方で、教育系・解説系コンテンツに強い追い風になる。プロダクト動画なら「液体が容器に注がれて泡立つ」「金属球が水面に落ちて波紋が広がる」といった、これまで破綻しやすかった物理描写を狙って使う価値がある。逆に、現実の物理を意図的に破りたい(漫画的な誇張表現など)場合は、スタイル指定(「カートゥーン調」「重力を無視した」など)を明示的に足して、世界モデルの「真面目さ」を上書きしてやる必要がある。
Google Flow 統合 ―― プロ編集ツールが「会話」になった
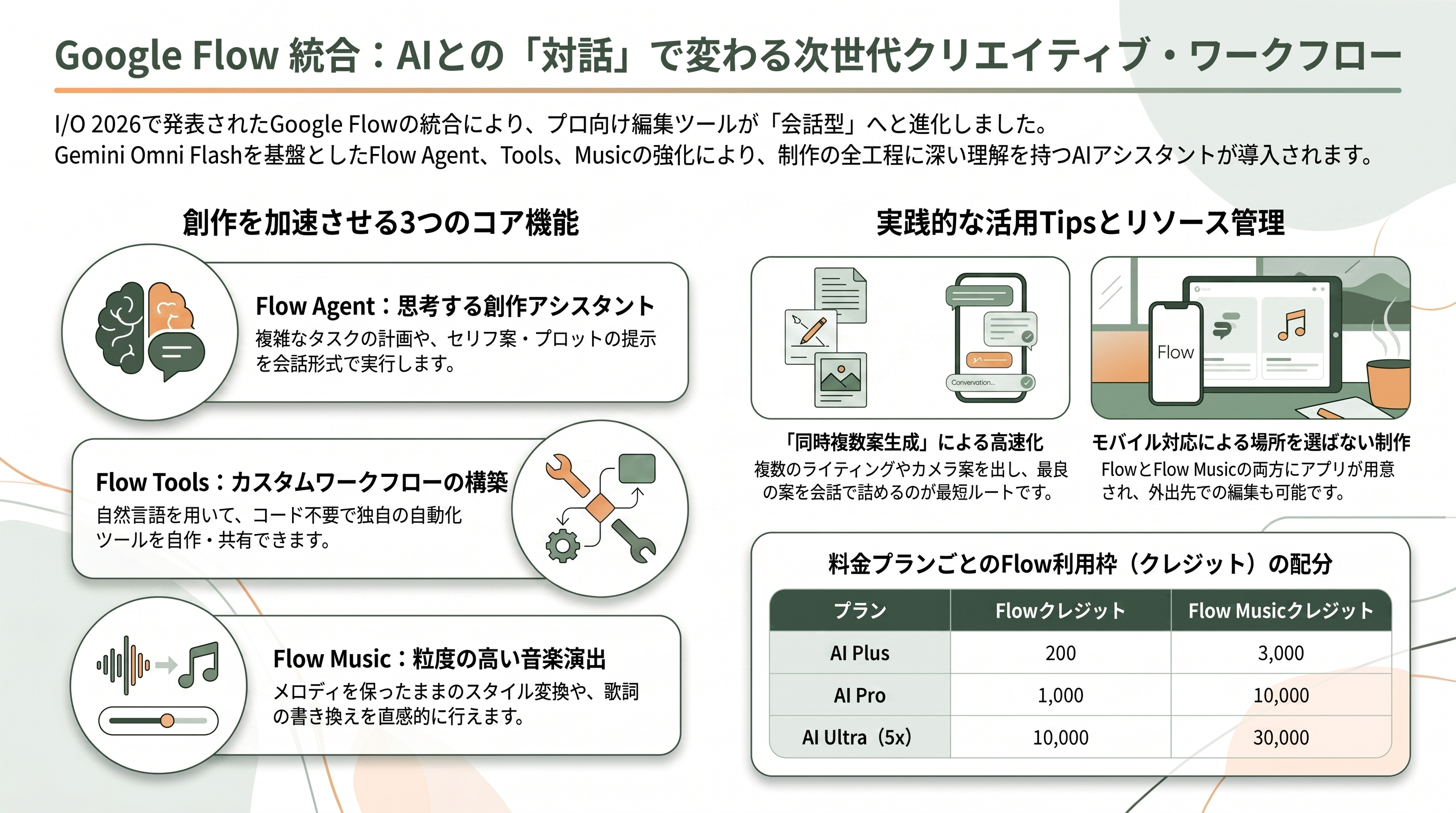
Omni のプロ向けの顔が、Google の生成映像制作スタジオ「Google Flow」への統合だ。I/O 2026 で Flow は、Gemini Omni Flash の搭載に加えて、Flow Agent・Flow Tools・Flow Music の大幅強化・モバイルアプリという四点でアップグレードされた。ここはクリエイターのワークフローが最も変わる領域なので、丁寧に見ていきたい。
中心にいるのが Flow Agent だ。これは Gemini モデルで構築された「創作アシスタント」で、Google の表現では「あなたの入力をもとに、あなたのコントロール下で、複雑なタスクを計画し、推論する」。具体的には、セリフ案の提示、プロットの提案、複数バリエーションの同時生成、アセットの一括(バッチ)編集、コレクションの直感的なリネームと整理までをこなす。ブレインストーミングから制作・編集までの各工程に「プロジェクトへの深い理解」を持ち込む相棒、という位置づけだ。
Flow Tools は、コードを書かずに自然言語でカスタム・ワークフローを組み立てる仕組みで、自作のツールを他のユーザーと共有し、リミックスし合える。Flow Music 側も強力で、Omni によって音楽ビデオを会話で演出できるようになり、歌詞の書き換え、特定セクションの作り直し、メロディや構成を保ったままトラック全体のスタイル変換(スタイル・カバー)といった粒度の細かい編集が可能になった。そして Flow と Flow Music の両方にモバイルアプリが用意され、外出先での制作にも対応した。
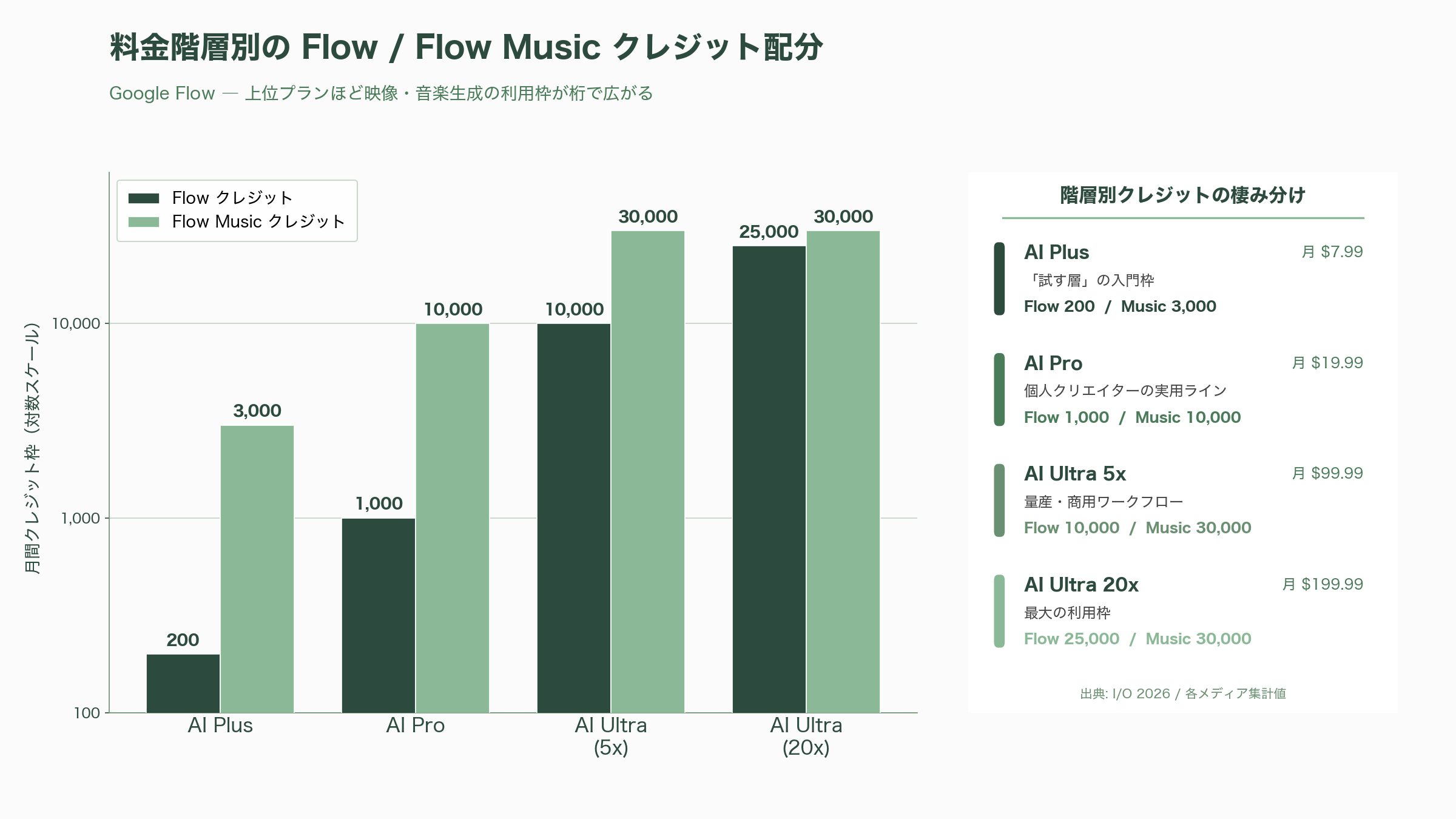
Flow の利用枠は料金階層に紐づく「Flow クレジット」で管理される。各メディアがまとめた数値では、AI Plus が Flow 200/Flow Music 3,000、AI Pro が 1,000/10,000、AI Ultra(5x)が 10,000/30,000、AI Ultra(20x)が 25,000/30,000 という配分になっている(料金は次章)。
クリエイター視点の TIPS: Flow Agent の真価は「同時に複数案を出させて選ぶ」使い方にある。1カットを1案だけ詰めるのではなく、ライティングやカメラ違いのバリエーションをまとめて生成させ、当たりを引いてから会話で詰める方が、結果的に速い。Flow Tools は「自分の定番処理(縦型 9:16 への切り出し+ブランドカラーのテロップ、など)」を一度ツール化しておくと、チームやコミュニティで再利用でき、量産系の案件で効いてくる。Flow Music の「メロディを保ったままスタイル変換」は、同じ楽曲をターゲット層別に作り分けるマーケ用途と相性が良い。
ライブ・ストリーミング・エディット ―― 会話で映像を彫る新しい編集ループ
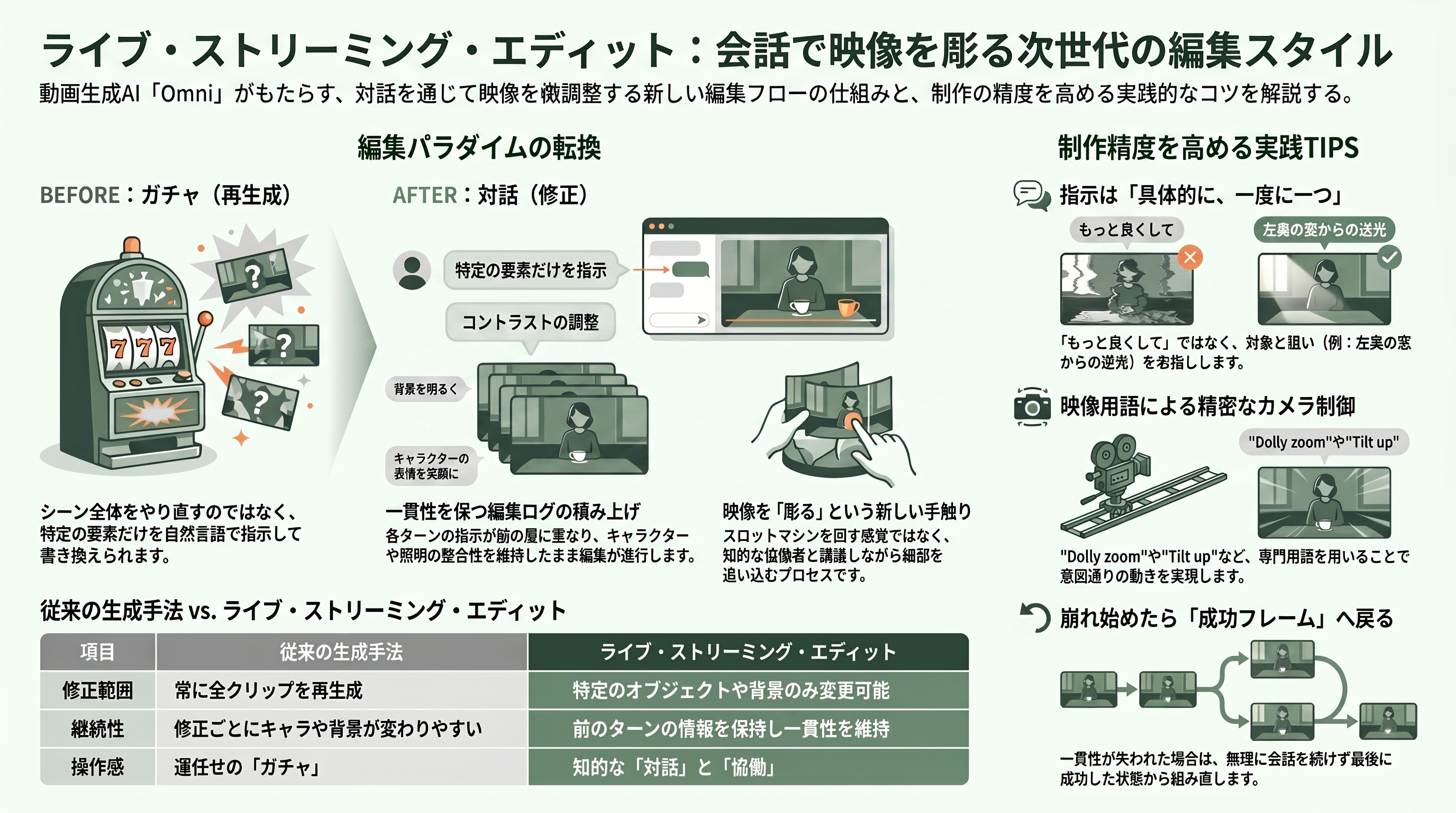
Omni がクリエイターに与えた最も大きな体験的インパクトは、「動画編集が、会話と同じくらい簡単になった」ことだ。Google は Omni の紹介ページのタイトルそのものを「会話するように動画を作り、編集する」と掲げている。これが本稿でいう「ライブ・ストリーミング・エディット」 ―― リアルタイムに、対話を往復させながら映像を彫っていく編集ループ ―― の正体である。
従来の生成動画は、プロンプトを投げては全クリップを生成し直す「ガチャ(スロットマシン)」だった。Omni では、シーンの一部だけを自然言語で指示して直せる。公式プロンプトガイドは「背景の変更や新しいキャプションの追加のように、特定のアップデートだけを Omni に頼めばよく、シーン全体を再びプロンプトする必要はない」「複数回の修正をまたいで動画を保持し、うまくいっている部分は残す」と説明する。各ターンの指示が前のターンの上に積み上がり、キャラクター・ライティング・オブジェクトの一貫性を保ったまま編集が進む。あるレビューが「洗練されたスロットマシンを操作するのではなく、知的な協働者と話している感覚」と評したのは、この往復の手触りを指している。
CineD が紹介した実例が分かりやすい。「人物が鏡に触れたら、鏡を液体のように美しく波打たせて」と話しかけるだけで、キャラクターの連続性とシーンの論理を保ったまま、その一点だけが書き換わる。映像を「撮り直す」のではなく「会話で直していく」 ―― この感覚が編集の前提を変えつつある。
ただし冷静な留保も必要だ。複数ターンの編集をまたいだキャラクター一貫性は、このカテゴリーで歴史的に弱点だった領域で、CineD も「本番案件で頼る前に検証すべき」と釘を刺している。また、編集プロンプトが曖昧だと意図しない箇所まで変わってしまう ―― これは Nano Banana ユーザーが既に知っている落とし穴で、TechCrunch も同じ注意を挙げている。
クリエイター視点の TIPS: 編集指示は「具体的に、一度に一つ」が鉄則だ。「もっと良くして」ではなく「左奥の窓からの逆光を足して、人物の輪郭を強調して」のように対象と狙いを名指しする。カメラワークは映像用語が効く ―― 公式ガイドは「push in(寄り)」「dolly zoom」「locked off(固定)」「natural smartphone zoom」「webcam style」などの語彙を推奨し、「靴のクローズアップから素早くティルトアップしてミディアムショット、そこからワイドに」のような連続したカメラ指示の例を挙げている。一貫性が崩れ始めたら、無理に会話で粘らず、最後に成功したフレームや参照画像に戻って組み直す方が早い。
Project Astra ―― 常駐型の視覚アシスタントへ
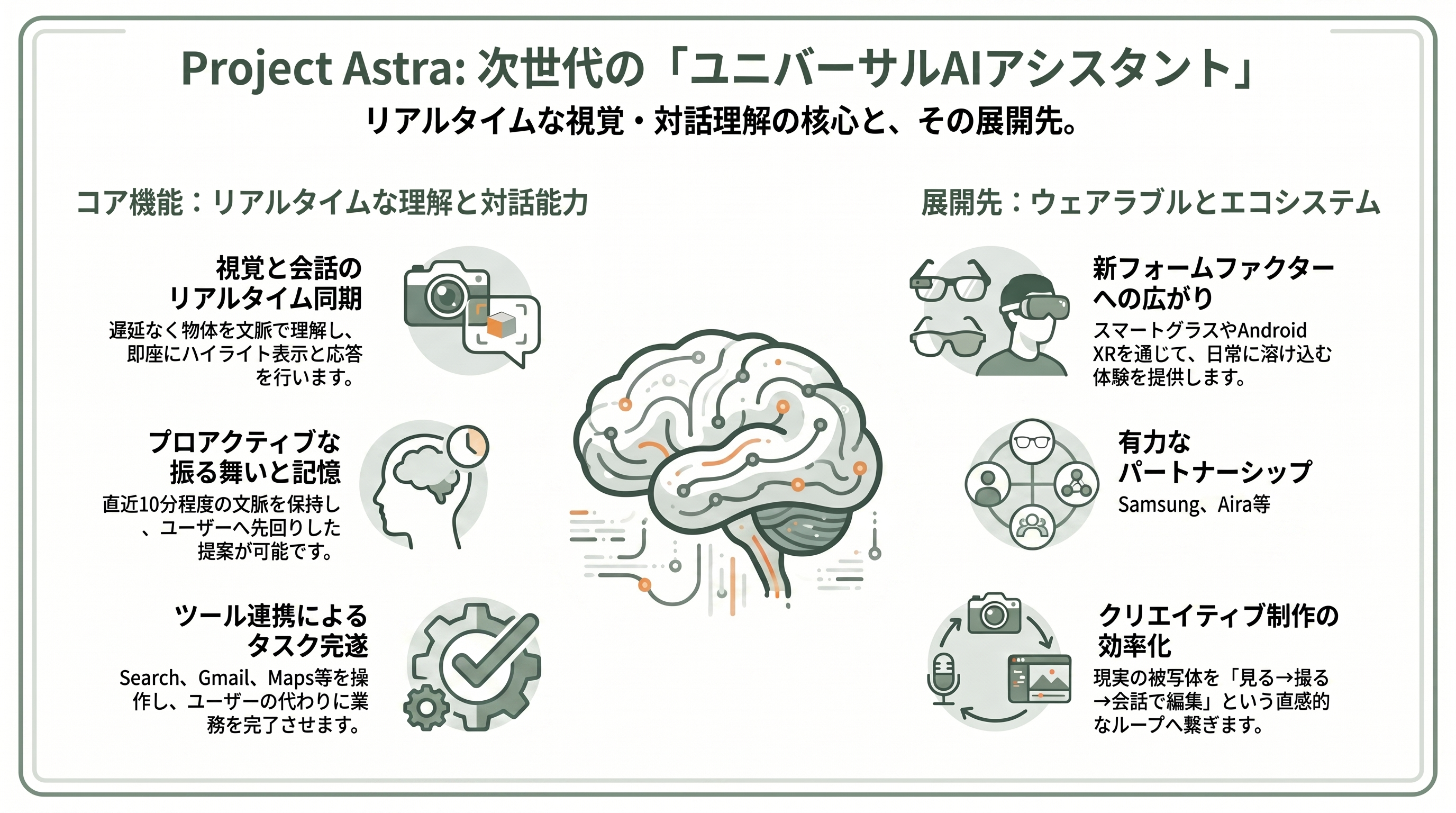
五つ目の軸は、Omni 本体とは別系統だが密接に連動する「Project Astra」だ。これは Google DeepMind が「ユニバーサル AI アシスタント」へ向けて開発するリサーチ・プロトタイプで、カメラが捉える世界をリアルタイムに理解し、会話と視覚を同時に処理する常駐型アシスタントを目指す。なお、一部の海外メディアやブログはこれを「Project Astra 2.0」と呼ぶが、Google DeepMind の公式ページ上の名称はあくまで「Project Astra」であり、「2.0」は公式の製品ブランドというより、世代が進んだ能力を指す通称として流通している点に注意したい。本稿では便宜上この通称も併記する。
能力面では、画面上のハイライトで「いま注目すべき対象」を示しながら物体を文脈で理解し、時間差や割り込みなしにその場で応答する。会話を自分から切り出す「プロアクティブ(先回り)」な振る舞いも特徴だ。記憶については、セッション内で直近の映像フレーム・過去のクエリ・デバイスをまたいだ文脈を保持し、過去の会話を呼び出して個別最適化する。初期のデモ以来語られてきた「セッション内およそ10分の記憶」という水準が、より洗練された形で受け継がれている。ツール連携も実装され、Search・Gmail・Calendar・Maps の操作やインターフェース制御まで、ユーザーに代わってタスクを完了させる。
展開先として Google は、Project Astra の能力を Gemini Live、Search の新体験、そしてメガネという新フォームファクターへ広げると明言している。実際、Gemini Live の最新機能のいくつかは Project Astra で最初に探索されたものだ。アイウェアでは Warby Parker や Gentle Monster といった眼鏡ブランド、XR ハードウェアでは Samsung(Android XR)がパートナーとして報じられており、Android XR のオーディオ・グラスは「この秋」に登場予定とされる。視覚障害・弱視のユーザー向けには、視覚支援サービス Aira と提携した特化版も開発されている。
クリエイター視点の TIPS: Astra は、映像制作の「入口」を変える可能性を秘めている。グラスやスマホのカメラで現実をライブに捉え、その場の被写体・ロケーション・モーションを「参照素材」として Omni に橋渡しする ―― 「見る → 撮る → 会話で編集する」というループが一本につながると、ロケハンやリファレンス収集の手間が大きく縮む。現時点では Astra と Omni は別レイヤーだが、Gemini Live を起点にこの連携が立ち上がる方向性は意識しておく価値がある。
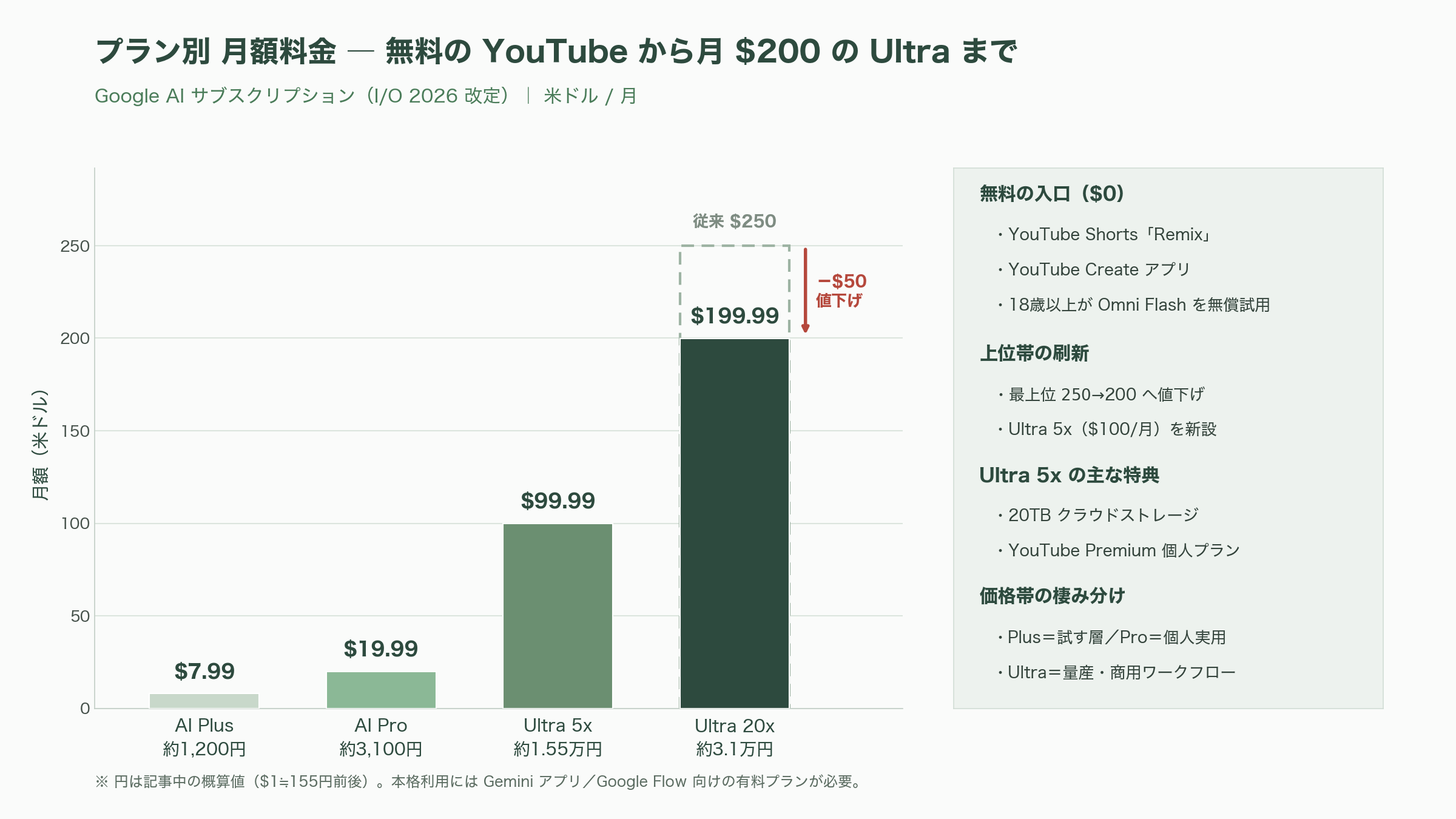
料金とアクセス ―― 無料の YouTube から月200ドルの Ultra まで

Omni をどこで・いくらで使えるかは、I/O 2026 で刷新された Google AI のサブスクリプション体系に沿う。まず無料の入口として、YouTube Shorts の「Remix」機能と YouTube Create アプリで、18歳以上のユーザーが Omni Flash を無償で試せる。本格的に Gemini アプリと Google Flow で使うには、Google AI のいずれかの有料プランが必要だ。
価格は、AI Plus が月7.99ドル(約1,200円)、AI Pro が月19.99ドル(約3,100円)、上位の AI Ultra は二段構成で、5倍の利用枠を持つ「Ultra 5x」が月99.99ドル(約1万5,500円)、20倍の「Ultra 20x」が月199.99ドル(約3万1,000円)となる。Ultra の最上位は従来の月250ドル(約3万8,800円)から月200ドル(約3万1,000円)へと値下げされ、5倍枠の月100ドル(約1万5,500円)の新設と合わせて、上位帯の選択肢が広がった。Ultra 5x には 20TB のクラウドストレージと YouTube Premium 個人プランが含まれる。前章で触れた Flow クレジットの配分と合わせて読むと、Plus は「試す層」、Pro は「個人クリエイターの実用ライン」、Ultra は「量産・商用ワークフロー」という棲み分けが見えてくる。
商用利用で要注意なのが、出力に必ず付く電子透かしだ。Omni が生成したすべての動画には、Google の不可視の電子透かし「SynthID」が埋め込まれ、Gemini アプリ・Chrome の Gemini・Search で検証できる。これはオプトアウト(無効化)できない仕様で、後述する API では C2PA の Content Credentials と合わせて「許可」ではなく「必須」になるとみられる。AI 生成物の識別という社会的要請には沿うが、クリーンな出力を前提とする一部の商用ワークフローには制約となり得る点を、見積もり段階で織り込んでおきたい。
シリコンバレーはどう報じたか ―― Seedance・Sora との立ち位置
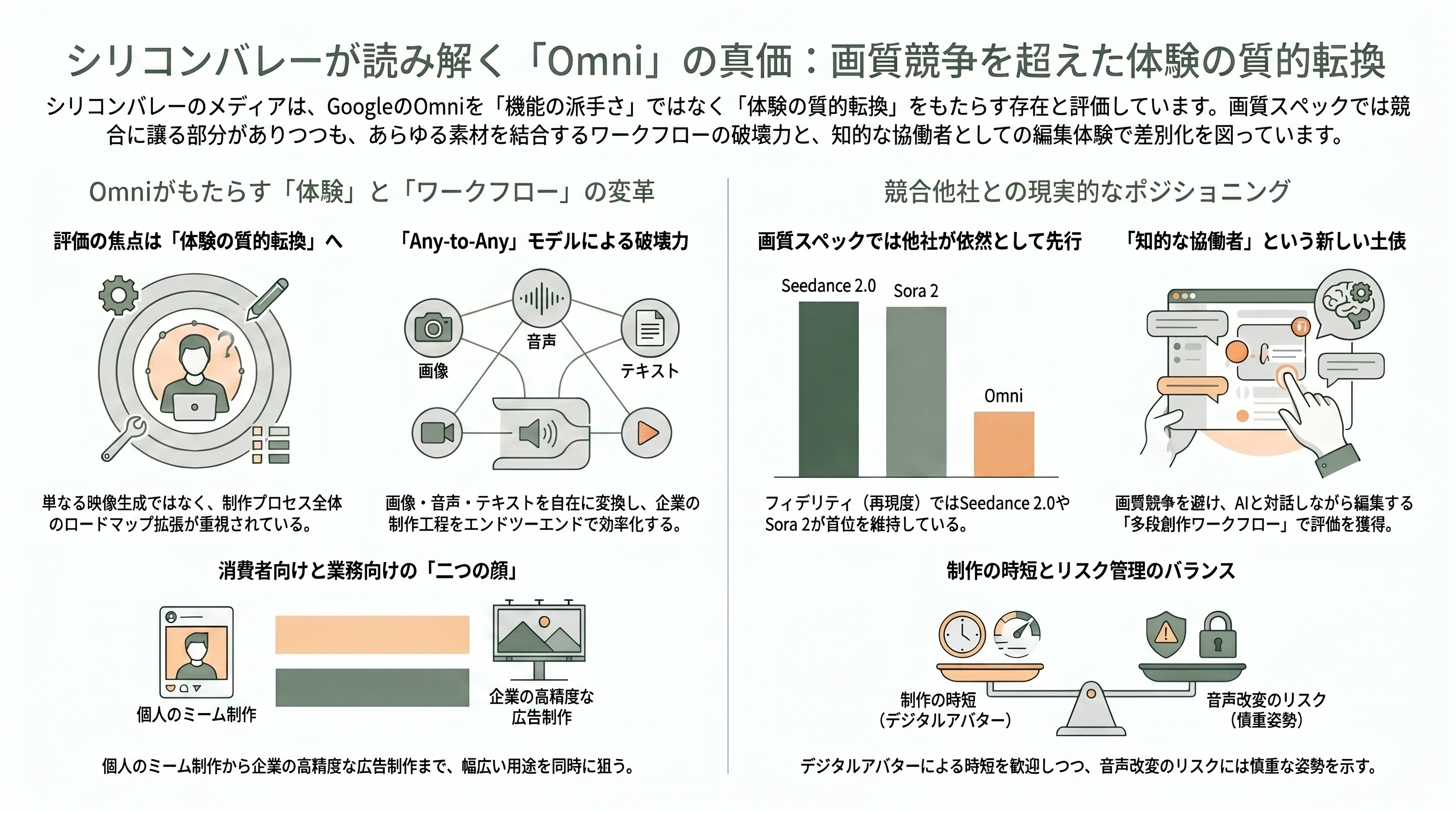
シリコンバレーの受け止めは、「機能の派手さ」よりも「体験の質的転換」に焦点が当たっている。TechCrunch は見出しからして「画像・音声・テキストを動画に変える ―― そしてこれはまだ序章だ」と、ロードマップの広がりを強調した。The Verge は Omni を、これまでの動画生成の狭い制約から離れ「あらゆるものを作る」ことを狙う新しいモデル群として紹介。VentureBeat は「any-to-any」モデルとして、エンタープライズ(広告主・制作会社)にとっての end-to-end ワークフローの破壊力を論じた。映像制作者向けの CineD は、自分自身のデジタル・アバターを自分の声で動かせる機能を「制作の時短」として歓迎しつつ、音声編集の広い解放を Google が意図的に保留している点 ―― セリフ改変のリスクへの配慮 ―― を冷静に記録している。
競合との立ち位置についても、各メディアは過度な煽りを避けつつ現実的だ。発売初日時点で「最高画質のモデルではない」という評価は共通しており、フィデリティのリーダーボードでは Seedance 2.0 が依然首位、特定の物理ケースでは Sora 2 が依然強い、と複数の比較記事が指摘する。それでも Omni が評価されるのは、画質競争ではなく「知的な協働者と話す」編集体験という新しい土俵を切り開いた点にある。TechCrunch は、エージェント的な多段創作ワークフローを構築するスタートアップとして Luma AI(製品ブリーフから広告キャンペーンを生成)を比較対象に挙げ、Omni を「Google による消費者向けの本気の一手」と位置づけた。
消費者向けと業務向けの「二つの顔」の緊張関係も論点だ。Google はアバターを、月旅行や受賞シーンを自作する「パーソナライズされたミーム」として消費者に訴求する一方、Brichtova は広告での文字表示精度(text-rendering)の価値を強調するなど、エンタープライズの本気度もにじませる。なお、競合の一部サービスの稼働状況を巡る一次情報の確認が取れない報道も流通しているが、本稿では裏取りできた範囲の事実関係に留める。
クリエイター必携 ―― プロンプト設計と一貫性の作り方

ここまでの各論を、実制作で効く「型」として束ね直しておきたい。Google DeepMind の公式プロンプトガイドが繰り返すのは、「Omni には過剰に指示しすぎなくてよい」という思想だ。公式の言い回しでは、「何を作りたいかを伝え、モデルの推論と世界知識がディテールを立ち上げるのを見守る」。良いプロンプトは「法律の契約書ではなく、優秀な協働者への明快なブリーフのように読める」ものだ、と。
その上で公式ガイドは、コントロールしたいときの軸として、ショットのフレーミングと動き(ワイド/ミディアム/クローズアップ)、スタイル(リアル/シネマティック、地に足のついた/荘厳な)、ライティング(くっきり/暖かい/エセリアル)、ロケーション、アクション、を挙げる。コミュニティ側の検証では、「何を作るか/どの入力を使わせるか/何を一貫させたいか/最終的に何に使う動画か」の四つを答えるプロンプトが安定し、Google 社内でも「六つの次元を押さえたユーザーほど劇的に良い出力を得た」と共有されているという。これは提案というより、「モデルを使う」のと「モデルを使いこなす」の差を分ける実務知だ。
一貫性の作り方は、本稿で繰り返してきた通り「参照を添付し、キャラクターは設計してから召喚する」に尽きる。実在の素材でも Nano Banana で作ったものでも、参照を一枚与えればシーンをまたいで使い回せる。アバターを使う場合は、ディープフェイク防止のための専用オンボーディングがあり、ユーザーは一連の数字を読み上げる自己録画を求められる ―― この一手間自体が、商用での「本人性の担保」につながる安全設計だと捉えるとよい。仕上げの編集では「具体的に、一度に一つ」、カメラは映像用語で、崩れたら直近の成功フレームに戻る ―― この三点を守るだけで、量産時の歩留まりは大きく変わる。
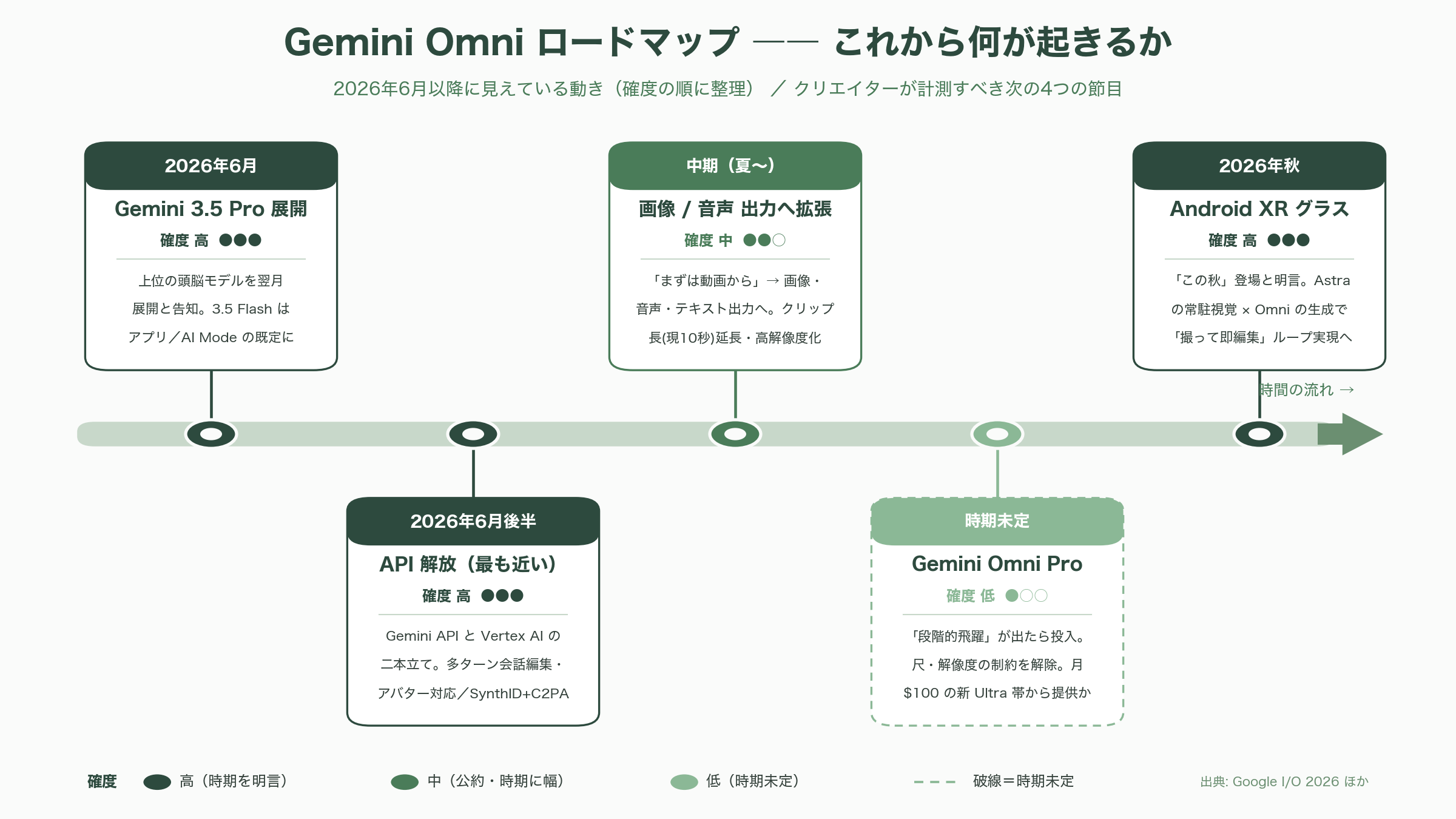
これから何が起きるか ―― API・Omni Pro・画像/音声出力・グラス
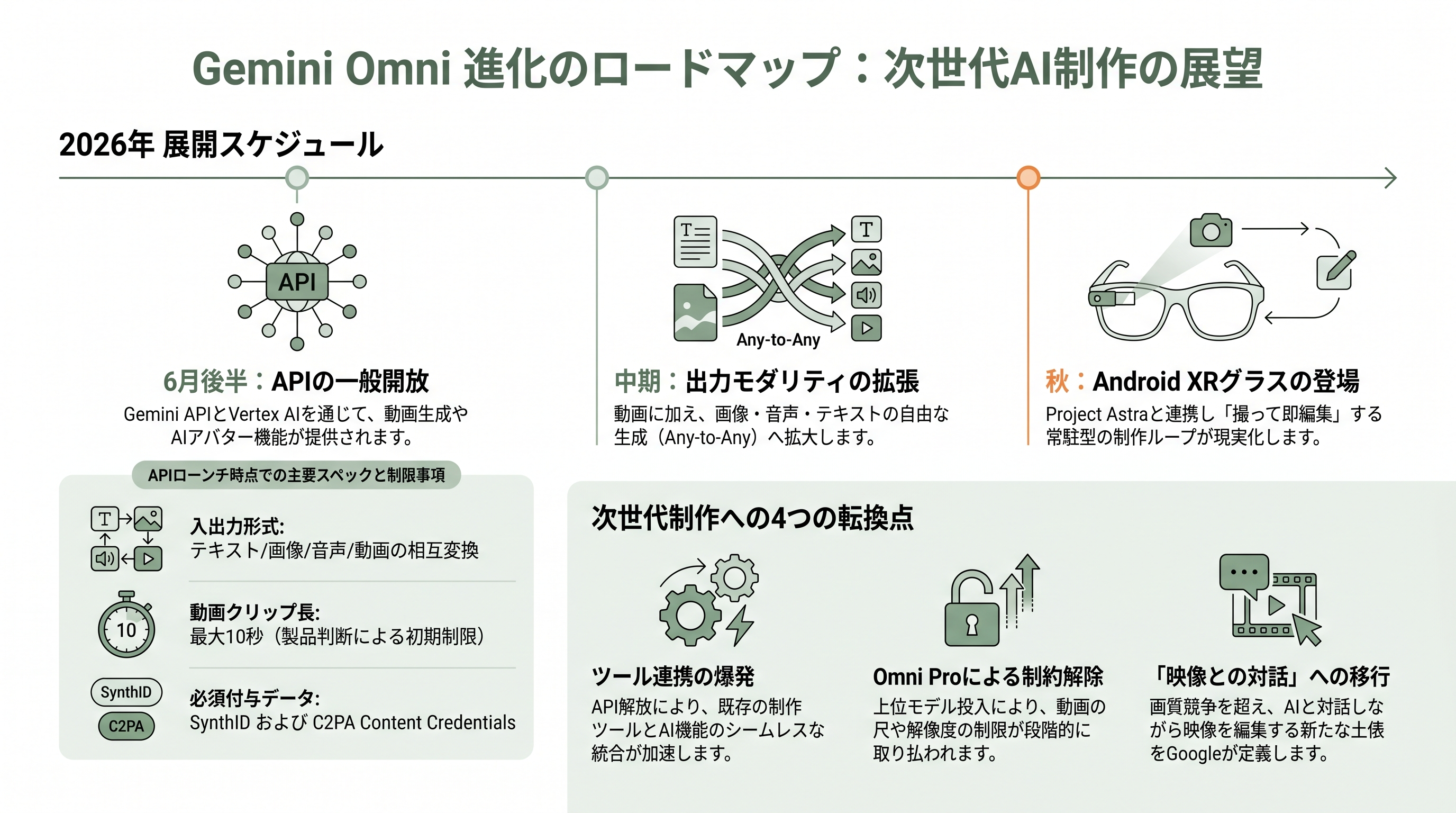
最後に、2026年6月初旬時点で見えている今後の動きを、確度の順に整理する。最も近いのが開発者・企業向けの API 提供で、Google は「数週間以内」と告知しており、各メディアは6月中旬〜下旬の提供開始を見込む。経路は個人開発者向けの Gemini API と、企業向けの Vertex AI の二本立てになる見通しだ。ローンチ時点の API は、テキスト/画像/音声/動画の入力から動画出力、多ターンの会話編集、AI アバターをサポートし、出力には SynthID と C2PA Content Credentials が必須で付与されると報じられている。
中期では、出力モダリティの拡張が公約されている。Omni は「まずは動画から」だが、Google は時間をかけて画像・テキスト(さらには音声)の出力にも広げると明言しており、TechCrunch は「音声から画像を、動画から音声を生成する」将来像を伝えた。クリップ長(現状の上限10秒)の延長や解像度の引き上げも開発中とされる。なお10秒という上限は、アーキテクチャ上の限界ではなく「より多くの人の手に早く届けるため」の製品判断だと明言されている点は、誇張せず正確に押さえたい。
その先に控えるのが、上位モデル Gemini Omni Pro だ。Flash に対して「ステップ・チェンジ(段階的な飛躍)」と呼べる差が出たときに投入する、とされ、明確な時期は示されていない。各メディアは、クリップ長の延長・解像度向上を伴い、まず月100ドルの新 AI Ultra 帯から提供される可能性が高いと見る。並行して、Omni の頭脳側にあたる Gemini 3.5 系も進化が続く。I/O で投入された Gemini 3.5 Flash はアプリと AI Mode の既定モデルとなり、上位の Gemini 3.5 Pro は翌月(2026年6月)に展開予定と告知されている。フォームファクター面では、前述の Android XR オーディオ・グラスが「この秋」に登場予定で、Project Astra の常駐視覚と Omni の生成・編集がどう橋渡しされていくかが、次の注目点になる。
総じて、シリコンバレーのクリエイターが計測すべき次の節目は、(1) 6月後半の API 解放によるツール連携の爆発、(2) 画像/音声出力への拡張で any-to-any が完成へ近づく瞬間、(3) Omni Pro による尺・解像度の制約解除、(4) 秋のグラス展開で「撮って即編集」のループが現実化するか、の四つに集約される。Omni は初日に画質王者だったわけではない。だがそれは、画質ではなく「映像とどう対話するか」という土俵を Google が先に押さえにいった、という戦略の現れでもある。