まず全体像:6月9日、「市販できる最強モデル」が解禁された

2026年6月9日(米国時間・火曜日)、AnthropicはClaude Fable 5を一般公開した。同社の表現を借りれば「これまで一般提供してきたどのモデルの能力をも上回る」フロンティアモデルであり、ソフトウェア開発、ナレッジワーク、画像認識(ビジョン)、科学研究など、テスト対象としたほぼすべてのベンチマークで最先端(state of the art)に立ったとされる。Claude.aiのチャット画面、API(モデル名はclaude-fable-5)、Amazon Web Services・Google Cloud・Microsoft Foundryの各クラウド、そしてコーディング用エージェントであるClaude CodeやClaude Managed Agentsから、即日利用できる。
タイミングも示唆的だ。本記事の公開日である6月10日には、Anthropicの開発者カンファレンス「Code with Claude」の東京会場が開かれ、翌11日には独立系開発者・アーリーステージ創業者向けの「Extended Tokyo」も予定されている。サンフランシスコ(5月6日)、ロンドン(5月19日)に続く今年3都市目で、新モデル公開の熱が冷めやらぬうちに日本の開発者コミュニティへ直接届く格好になった。同時通訳付きで、オンライン視聴も可能とされる。シリコンバレーの「世界最強モデル」が、発表のわずか翌日に東京で実演される——この距離の近さ自体が、2026年のAI開発競争のスピード感を象徴している。
なお、本稿のタイトルは「Claude Codeの最新モデル」としているが、正確にはFable 5はチャットからAPIまで横断的に使える汎用フロンティアモデルであり、その中でも特にClaude Codeのような自律エージェント環境で真価を発揮するよう設計されている、という関係にある。以下、まずはこの二つのモデルが「何者なのか」から、具体例を交えて噛み砕いていく。
Mythos 5とFable 5とは何か——「同じ頭脳、違う安全装置」
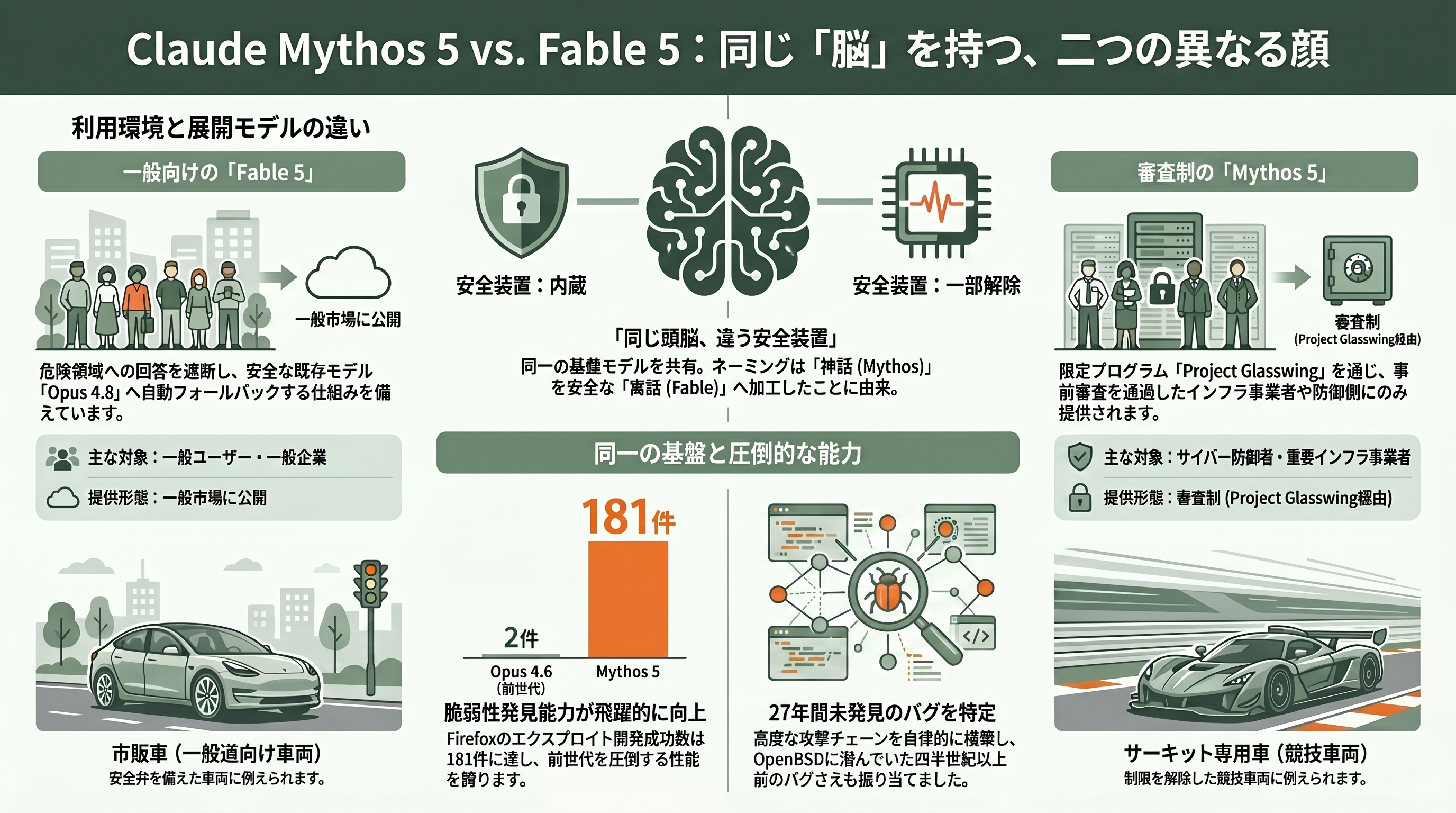
最初に押さえるべき最大のポイントは、Fable 5とMythos 5は中身(基盤モデル)がまったく同一だということだ。違いはただ一点、安全装置の有無にある。Anthropicは公式に「Fableはラテン語の*fabula*(語られるもの)に由来し、ギリシャ語の*mythos*(神話・物語)と同根だ。両モデルを分けるのはセーフガードである」と説明している。つまり「神話(Mythos)」という危険なほど強力な原石を、安全に語れる「寓話(Fable)」へと加工したもの、というネーミングだ。
このシリーズの源流は2026年4月7日に遡る。Anthropicはその日、研究部門のサイト(red.anthropic.com)で「Claude Mythos Preview」を発表した。汎用言語モデルでありながら、とりわけコンピュータセキュリティで突出した能力を示し、主要なOSとWebブラウザのすべてでゼロデイ脆弱性を発見してみせたという。JITヒープスプレーやサンドボックス脱出、複数脆弱性を連鎖させる高度な攻撃チェーンまで自律的に組み立て、セキュリティ非専門家が「一晩でリモートコード実行のエクスプロイトを作って」と頼むだけで翌朝には動くコードが返ってきた、とされる。Firefoxのエクスプロイト開発成功数は181件で、前世代のOpus 4.6のわずか2件を圧倒。セキュリティで知られるOpenBSDに潜んでいた「27年もの間気づかれなかったバグ」まで掘り当てたという、ある種ぞっとするような報告だった。
あまりに強力なため、Anthropicはこれを一般公開せず、Project Glasswingという限定プログラムを立ち上げた。これは世界の重要インフラを守る防御側(cyberdefender)にだけ先行してMythosを使わせ、攻撃者が優位に立つ前に防御側の備えを整える、という発想の取り組みだ。参加企業にはAWS、Microsoft、Apple、CrowdStrike、Ciscoといった名が挙がっている。
今回の6月9日のリリースは、この構図を二段構えで一般市場に開いたものだ。一般ユーザーや企業が買えるFable 5は、危険領域への回答をモデル自身が遮断し、代わりに従来の安全なモデル「Claude Opus 4.8」へ自動的にフォールバック(処理を肩代わり)する仕組みを内蔵している。一方のMythos 5は、その安全装置を一部解除した同一モデルで、サイバー防御者や重要インフラ事業者、生物医学研究者など事前審査を通った組織だけがProject Glasswing経由で使える。Mythos 5は「世界で最も強力なサイバーセキュリティ能力を持つモデル」と位置づけられている。比喩で言えば、Fable 5は安全弁付きで誰でも運転できる市販車、Mythos 5は同じエンジンを積んだサーキット専用車、というわけだ。
具体的に何ができるのか——「数日間ひとりで働き続ける同僚」
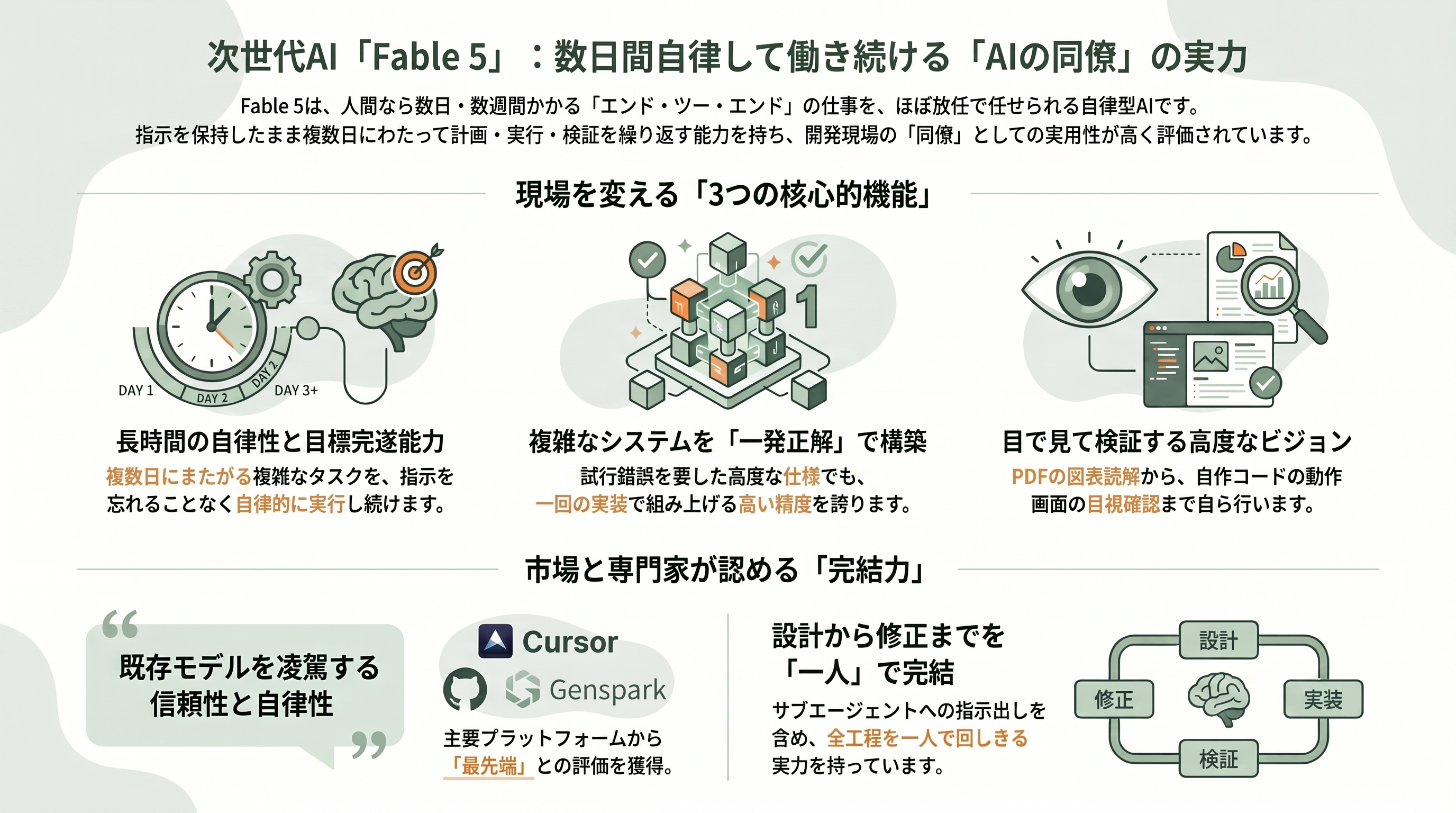
抽象論を避け、Fable 5が現場で何をしてくれるのかを具体的に見ていこう。Anthropicが繰り返し強調するのは「人間なら数時間・数日・数週間かかるエンド・ツー・エンドの仕事」を、ほぼ放任で任せられるという点だ。Claude CodeやClaude Managed Agentsのようなエージェント環境に載せると、Fable 5は何日にもわたって働き続け、作業を段階ごとに計画し、サブエージェント(手下のAI)に仕事を割り振り、自分の成果を自分で検証する。
公式ドキュメントが挙げる改善点は具体的だ。第一に長時間の自律性で、複数日にまたがる目標志向のタスクを、指示を保持したまま完遂する。第二に一発正解率——よく仕様化された複雑な問題で、これまで数日の試行錯誤を要したシステムを「一回の実装」で組み上げた、という初期テスターの報告がある。第三にビジョンで、ファイルやPDFに埋め込まれた図表・グラフ・テーブルを読み解き、さらに自分が書いたコードの動作画面を「目で見て」検証する。傾いた・ぼやけた・ノイズの多い画像にはbashツールや画像切り出しツールを自分で使って対処するよう訓練されているという。
第三者プラットフォームからの評価も具体的だ。コーディング支援のCursorのMichael Truell CEOは「Claude Fable 5は当社のCursorBenchで最先端のモデルだ」と述べ、GitHubのMario Rodriguez最高製品責任者は「初期テストで、複雑で長時間にわたるコーディングタスクを、これまでの基準を超える自律性と信頼性でこなした」とコメントした。バイブコーディング系のBase44は「アプリ全体を一発で生成する(one-shotting full apps)のが上手く、ツール呼び出しも優秀」と評し、AIワークスペースのGensparkは「UIデザインやゲームコーディングで他のどのモデルにも明確に勝った」と報告している。要するに、単発の質問応答ではなく「設計から実装、検証、修正までを一人で回しきる同僚」に近づいた、というのが各社の共通した手応えだ。
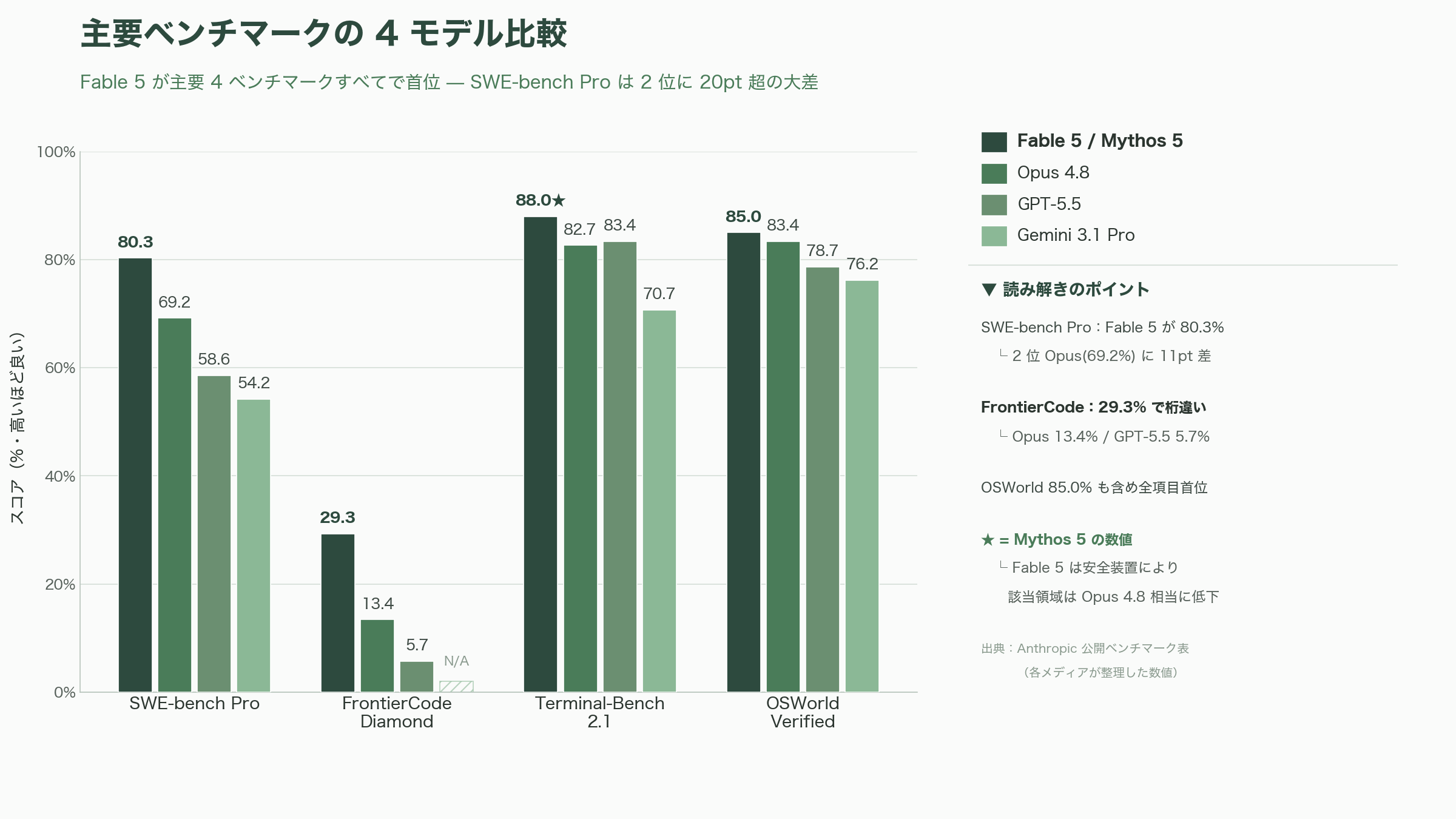
ベンチマークの圧倒的優位性
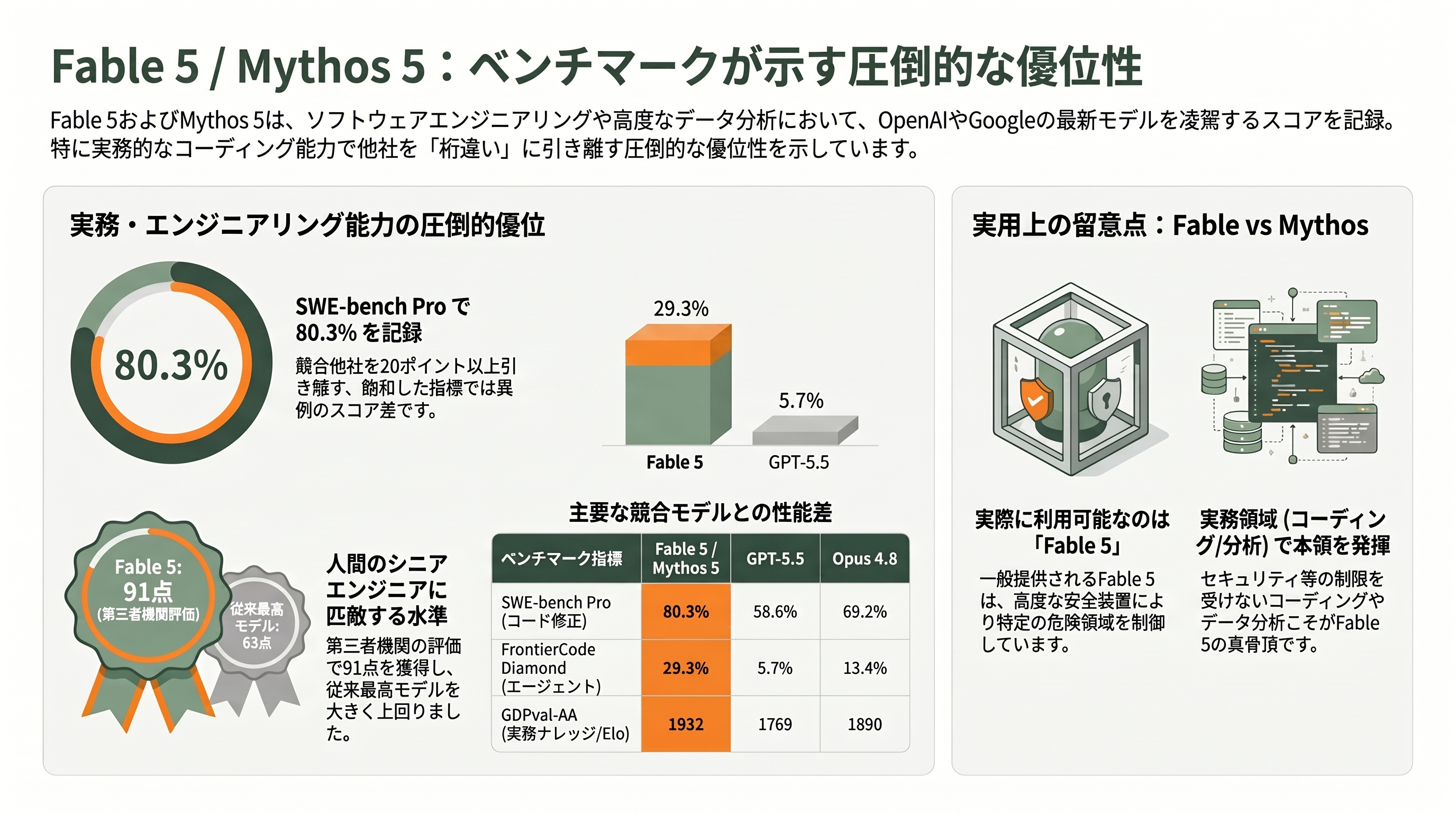
数字でも、その優位は明確だ。最も注目されたのが、難関のソフトウェアエンジニアリング・ベンチマークSWE-bench Proで、Fable 5/Mythos 5は80.3%を記録した。同じ指標でOpenAIの最新汎用モデルGPT-5.5は58.6%、Anthropic自身の前世代Opus 4.8は69.2%、GoogleのGemini 3.1 Proは54.2%だった(数値はTechCrunchおよび専門メディアがAnthropicの公開表を整理したもの)。20ポイント以上の差は、この種の飽和しつつあるベンチマークでは異例の開きだ。
さらに象徴的なのが、Cognition社のFrontierCode Diamond(高品質で保守性の高いエージェント型コーディングを測る難問)で、Fable 5/Mythos 5は29.3%。Opus 4.8の13.4%、GPT-5.5の5.7%と比べ、文字通り「桁が違う」水準を示した。データ分析プラットフォームのHexは、長時間に及ぶ複雑な分析タスクのコア・ベンチマークで「初めて90%を突破した最初のモデル」とFable 5を評価し、金融分析のHebbia Finance Benchmarkでも「あらゆるモデル中で最高スコア」を記録したとされる。
主要な公開ベンチマークを整理すると、おおむね次のようになる(出典はAnthropicの公開ベンチマーク表を各メディアが転載・整理した数値。★はMythos 5側の数値で、Fable 5では後述の安全装置により該当領域の値はOpus 4.8相当に下がる点に注意)。
| ベンチマーク(測る能力) | Fable 5/Mythos 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro(実務的なコード修正) | 80.3% | 69.2% | 58.6% | 54.2% |
| FrontierCode Diamond(高品質エージェント開発) | 29.3% | 13.4% | 5.7% | — |
| Terminal-Bench 2.1(CLI操作) | 88.0%★ | 82.7% | 83.4% | 70.7% |
| GDPval-AA(実務ナレッジワーク・Eloスコア) | 1932 | 1890 | 1769 | 1314 |
| Humanity's Last Exam(ツール無し・難問知識) | 59.0%★ | 49.8% | 41.4% | 44.4% |
| OSWorld-Verified(PC自動操作) | 85.0% | 83.4% | 78.7% | 76.2% |
ここで、他サイトの提灯記事が見落としがちな現場エンジニアならではの留意点を一つ挙げておきたい。ExploitBench(攻撃コード生成)で78.0%、各種バイオ系ベンチマークで突出——といった「最も派手な数字」は、実はMythos 5の値であり、一般には買えないモデルのスコアだ。Fable 5はサイバーセキュリティと生物・化学の問い合わせを安全装置でOpus 4.8へ振り替えるため、これらの領域では数字が下がる。逆に言えば、コーディングやナレッジワーク、ビジョンといった実際に課金して使える領域でこそFable 5は本領を発揮する。ベンチマーク表を眺めるときは「これはFableの数字か、Mythosの数字か」を一段見極めるのが、玄人の読み方だ。
参考までに、メディア企業Everyが運用する「シニアエンジニア・ベンチマーク」では、Fable 5が91点(満点100)を取り、これは人間のシニアエンジニア水準で、従来最高だったOpus 4.8の63点を大きく上回ったとも報じられている(Every/Digg報道。第三者の独自指標である点は割り引いて読みたい)。
Fable 5の料金体系と今後
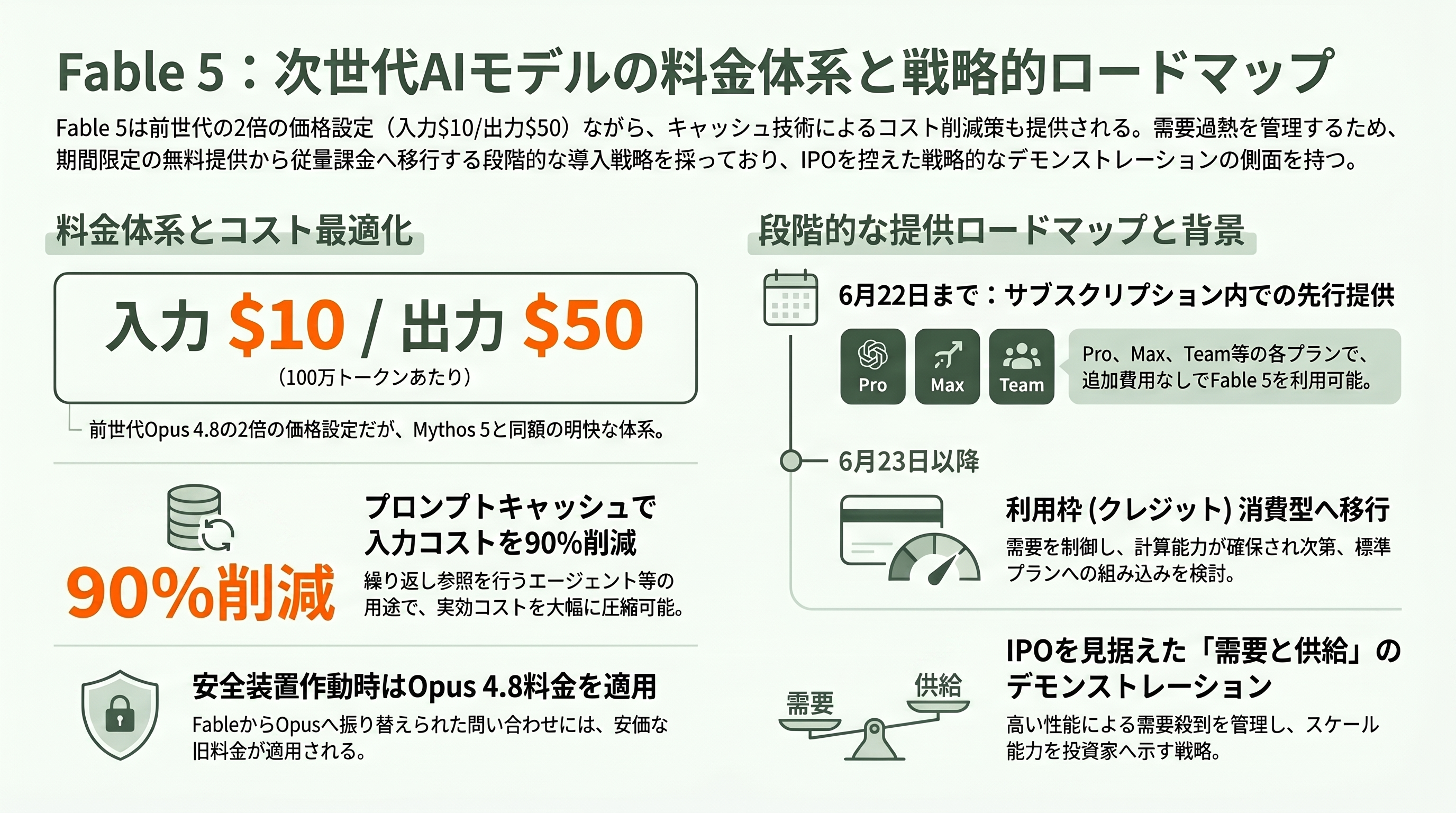
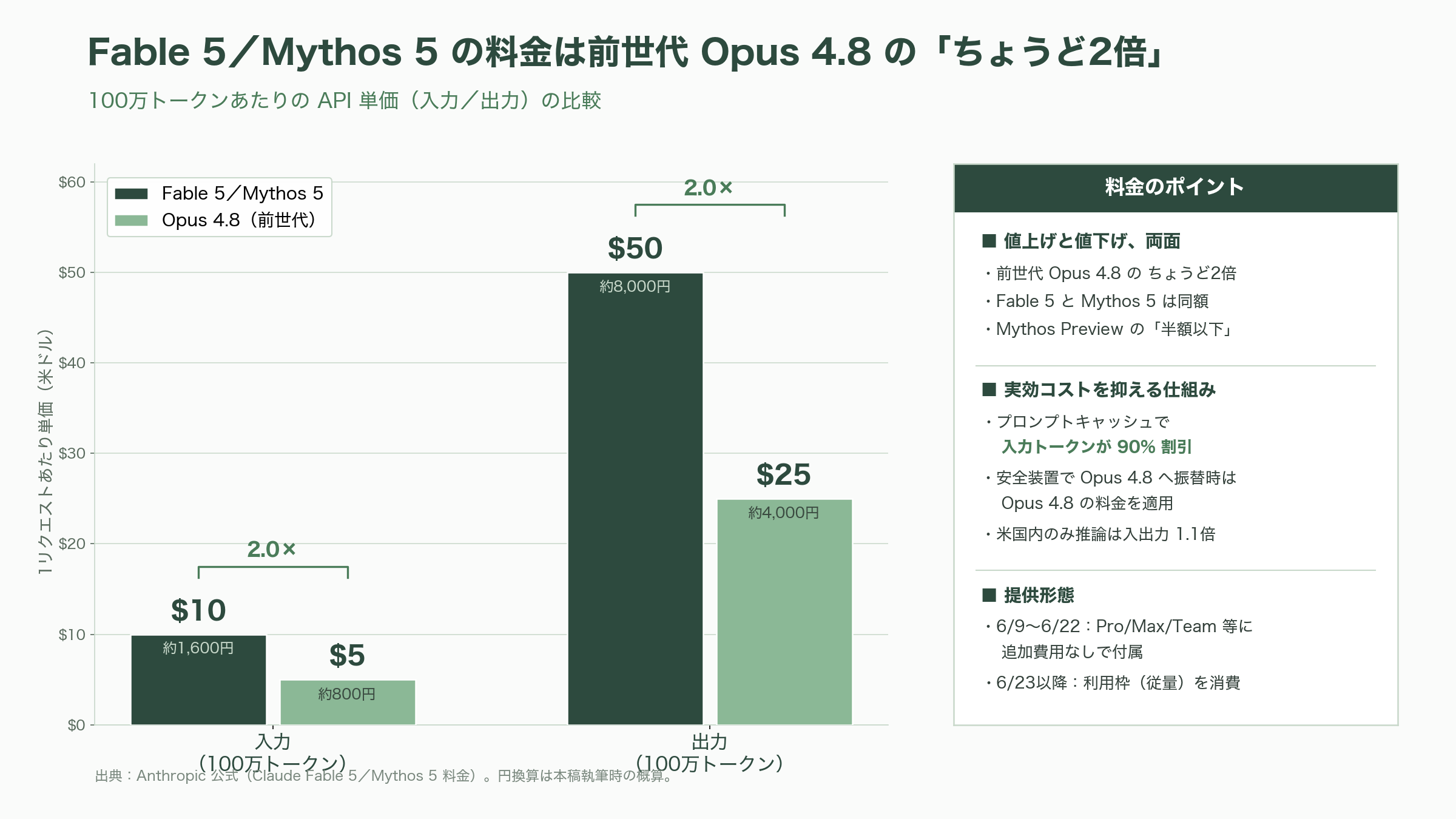
料金は明快だ。入力100万トークンあたり10ドル(約1,600円)、出力100万トークンあたり50ドル(約8,000円)で、Fable 5とMythos 5は同額。これは前世代Opus 4.8の入力5ドル(約800円)・出力25ドル(約4,000円)のちょうど2倍にあたる。一方でAnthropicは「Claude Mythos Previewの半額以下」とも説明しており、最先端を独占的に試せた価格からは大きく下がった、という見せ方だ。プロンプトキャッシュを使えば入力トークンに90%の割引が効き、長い文脈を繰り返し参照するエージェント用途では実効コストを大幅に圧縮できる。なお米国内のみで推論を行うオプションは入出力とも1.1倍の係数がかかる。安全装置でOpus 4.8へ振り替えられた問い合わせには、Fableの料金ではなくOpus 4.8の料金が適用される点も良心的だ。
注目すべきは提供形態の段階性だ。需要過熱を見越して、6月9日から6月22日まではPro・Max・Team・シート課金型Enterpriseの各サブスクリプションにFable 5が追加費用なしで含まれる。6月23日以降は利用枠(usage credits)を消費する形となり、「十分な計算能力が確保でき次第」標準プランへの組み込みを復活させる、というロードマップである。API経由およびConsumption型Enterpriseでは初日から完全に利用可能だ。
この「いったん無料で配り、後から有料に切り替える」設計は、Hacker Newsで賛否を呼んだ。あるユーザーは「offer, then remove(配ってから取り上げる)感が眉をひそめさせる。サブスク利用者を従量課金へ誘導したいように見える」と指摘し、別の開発者は「最先端LLMから価格で締め出されようとしていて、嫌な気分だ」と本音を漏らした。もっとも、これは裏を返せば「初日からあまりに需要が殺到し、計算資源の確保が追いつかないほどの性能だ」という証左でもある。後述するIPOを目前に控え、Anthropicが「フロンティアの知能を、破滅的な悪用を招かずに、スケールして顧客へ届けられる」ことを投資家に示すデモンストレーションとしての側面も大きい。料金とキャパシティの綱引きは、当面この新モデル運用の最大の論点であり続けるだろう。
安全装置という「設計思想」——なぜOpenAIやGoogleと違うのか
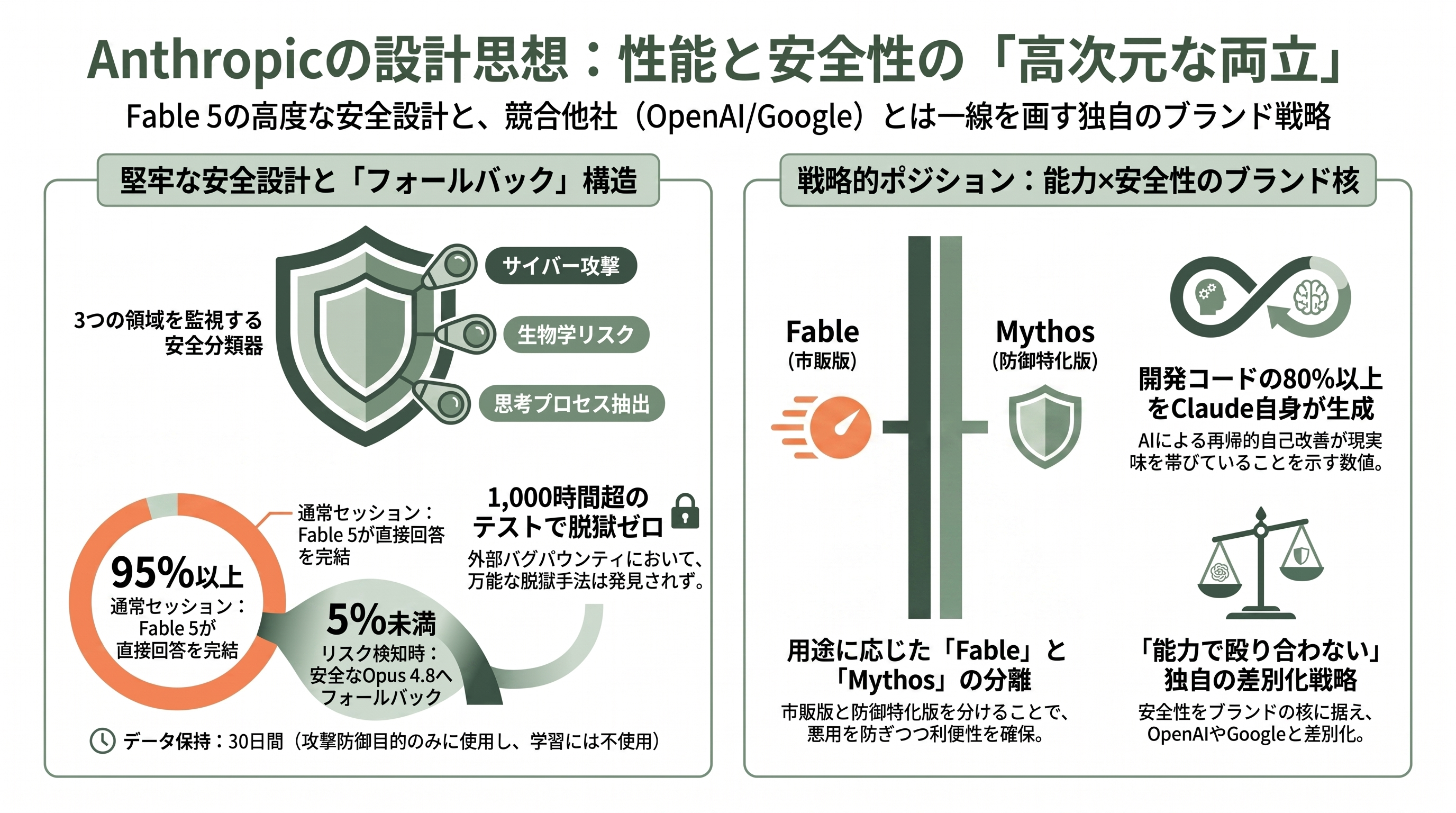
Fable 5を語る上で外せないのが、性能と並んで前面に押し出された安全設計だ。Fable 5には三つの安全分類器(classifier)が走っている。すなわち、攻撃的サイバー(エクスプロイトやマルウェア、攻撃ツールの作成)、生物・生命科学(実験手法や分子メカニズムなど悪用リスクのある内容)、そしてモデルの要約された思考内容の抽出(distillation/reasoning_extraction)の三領域だ。これらに該当する問い合わせは、モデルが自ら回答を止め、安全なOpus 4.8へフォールバックする。Anthropicによれば、この発動は全セッションの5%未満にとどまり、95%以上のセッションはFable自身の回答だけで完結するという。
堅牢性の検証も徹底している。外部のバグバウンティでは1,000時間超のテストでも「普遍的なジェイルブレイク(万能の脱獄手口)はゼロ」だったと報告された一方、英国のAI安全研究所(UK AISI)は短い初期テスト枠で「一歩近づいた」とも記され、過信を戒める書きぶりになっている。また、Mythosクラスのトラフィックには30日間のデータ保持が課されるが、これは新種の攻撃への防御と誤検知(false positive)低減という安全目的のみに使われ、モデルの学習には用いず期限後に削除されるという。
ここに、AnthropicとOpenAI・Googleの戦略の違いがくっきり表れている。実はこのリリースのわずか5日前、6月4日にAnthropicは「AIが再帰的自己改善(recursive self-improvement、AIが人間の介在なしに後継AIを設計・構築し始める段階)に近づきつつある」と警告するブログを公開していた。共同創業者のJack Clark氏らによるその文章は、根拠として「Claudeが今やAnthropic社内でマージされるコードの80%以上を書いている(2025年初頭にClaude Codeを出す前は1桁%だった)」という事実を挙げ、フロンティア開発を一時停止できる「選択肢」を世界が持つべきだと、冷戦期の中距離核ミサイル軍縮になぞらえて訴えた。
「AIは危険になりつつある」と警告した5日後に「過去最強モデル」を出す——TechCrunchはこの一見した矛盾を皮肉混じりに見出しに取った。しかし現場の視点で読み解けば、両者はむしろ一貫している。安全装置の付いたFable(市販可能)と、解除されたMythos(防御側限定)を分離するという今回の設計は、「危険なほど強力な能力を、悪用させずに、それでも防御や生産性のために役立てる」という6月4日の問題提起への、Anthropicなりの具体的な回答なのだ。能力で殴り合うのではなく「能力×安全性の両立」をブランドの核に据える——ここがシリコンバレーで同社が独自のポジションを築いている所以である。
使いこなしのコツ——「最も難しい課題」を任せる
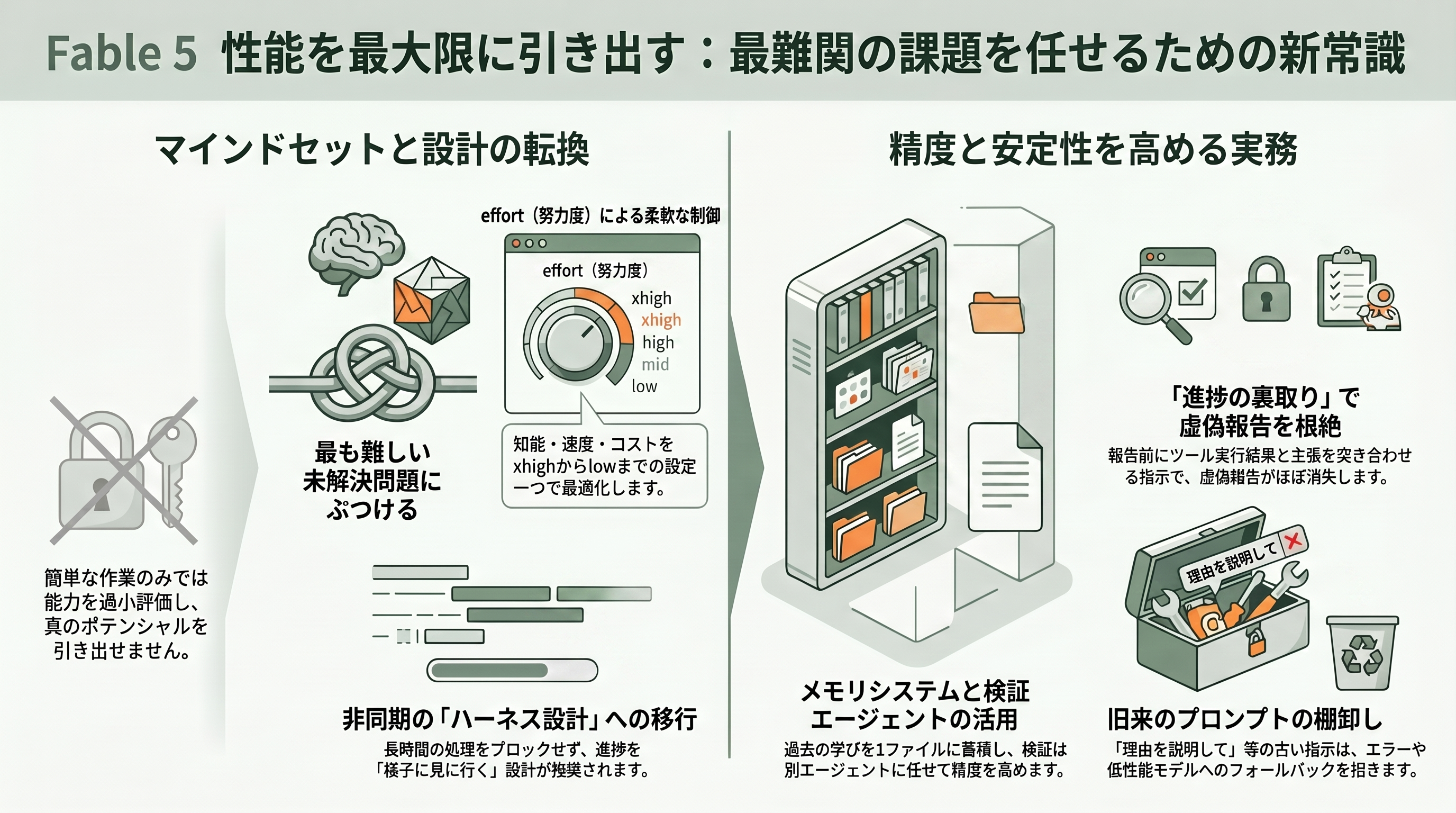
性能を引き出す鍵は、従来モデルの感覚を捨てることだ。Anthropicの公式プロンプトガイドは冒頭で「最良の成果を得ているチームは、Fable 5を自分たちの最も難しい未解決問題にぶつけている。簡単な作業でしか試さないと、その能力の幅を過小評価しがちだ」と説く。つまり「これは前のモデルには荷が重かった」というタスクをあえて選び、要件定義から実行まで丸ごと任せるのがコツになる。
制御の主役はeffort(努力度)という設定だ。知能・速度・コストのトレードオフをこれ一つで調整でき、多くのタスクではhighを既定とし、特に能力が要る局面ではxhigh、定型作業ではmediumやlowを使い分ける。低いeffortでも従来モデルの最高設定を上回ることが多いという。一方で難問では一回のリクエストが数分、自律運転なら数時間に及ぶため、クライアントのタイムアウトやストリーミング、進捗表示を見直し、処理をブロックせず非同期で「様子を見に行く」ハーネス設計へ作り替えることが推奨されている。
長時間運転を破綻させないための実務的な勘所も、公式に明文化されている。第一にメモリシステムを与えること——マークダウン1ファイルに1つの教訓を、冒頭に一行サマリ付きで書き溜め、過去の学びを参照させると性能が伸びる(これは本稿の執筆環境のメモリ運用とも一致する発想だ)。第二に進捗の裏取りを指示すること——「報告の前に、各主張をこのセッションのツール実行結果と突き合わせよ。証拠を示せる作業だけ報告し、未検証なら未検証と言え」と促すと、Anthropicの検証では虚偽の進捗報告がほぼ消えたという。第三にサブエージェントの活用で、Fable 5は並列のサブエージェントを従来より積極的に起こすため、独立した小タスクは委譲し、検証は本体の自己批判よりも「文脈をまっさらにした別の検証エージェント」に任せるほうが精度が出る。
意外な落とし穴も知っておきたい。長いセッションの深部でFable 5がまれに「ではXを実行します」と宣言だけしてツールを呼ばずにターンを終えることがあり、その場合は「continue」「最後までやって(go ahead and do it end to end)」の一言で再開する。また、モデルに自分の思考過程を答えとして書き出させるような旧来のプロンプトやスキルは、reasoning_extraction(思考抽出)の拒否カテゴリを誤って発動させ、Opus 4.8へのフォールバックを増やす原因になりうる。移行時には「考えを見せて」「理由を逐一説明して」式の古い指示文を棚卸しし、思考の可視化が必要なら構造化されたthinkingブロックを読む方式へ切り替えるのが、無駄なフォールバックを避ける定石だ。総じて、旧モデル向けに作り込んだ過剰に細かいスキルはむしろ足を引っ張ることがあり、「指示を減らして任せる」方向への作り替えが効く。
シリコンバレーはどう報じたか——熱狂と「価格で締め出される」不安
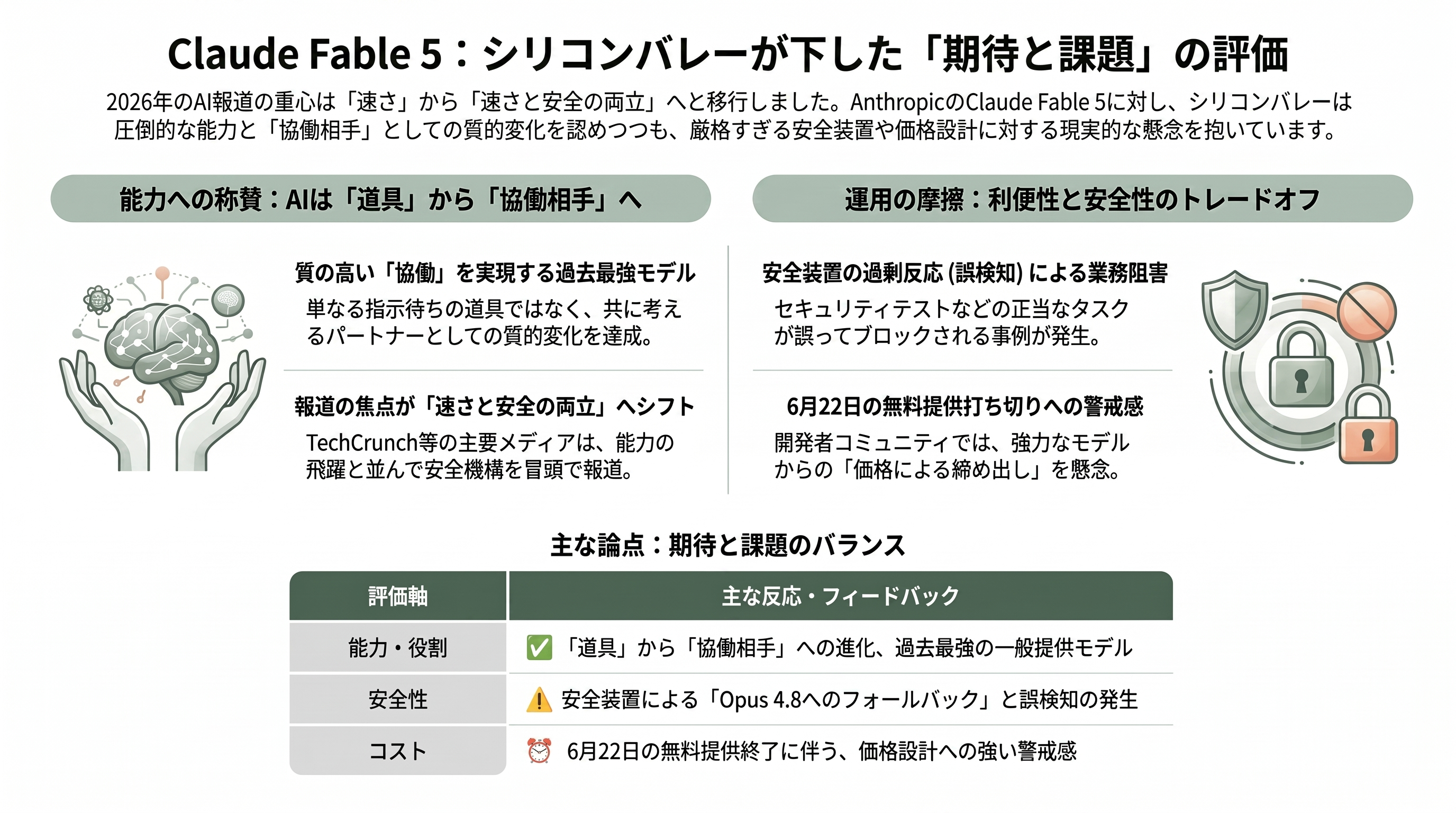
各紙・各サイトの論調は、能力への称賛と、運用・安全をめぐる現実的な懸念とが同居する、成熟した受け止め方だった。VentureBeatは「AnthropicがMythosを大衆へ——過去最強の一般提供モデルClaude Fable 5」と最大級の見出しで報じ、TechCrunchやCNBC、NBC News、Inc.、IT Proなどが、能力の飛躍と並んで「Opus 4.8へのフォールバック」という安全機構を冒頭で取り上げた。安全装置をニュースの主役級に据える報じ方自体が、2026年のAI報道の重心が「速さ」から「速さと安全の両立」へ移ったことを物語っている。
開発者コミュニティの生の声はHacker Newsに凝縮されていた。称賛の一方で、前述の「6月22日で無料提供を打ち切る」価格設計への警戒、そして安全装置の過剰反応(誤検知)への不満が目立った。あるユーザーは「試そうとしたら、生物兵器を作ろうとしている可能性があると警告され、Opus 4.8に戻された」と報告し、正当なコードレビューやセキュリティテストまで弾かれたという声も上がった。Fable 5の安全弁は、たしかに無害な防御的サイバー作業や有益な生命科学タスクをも巻き込みうる——この「便利さと安全のトレードオフ」こそ、Anthropicが今後の運用でチューニングを迫られる最前線だ。
それでも全体のトーンは前向きだ。Everyの評者が「Fableでは、AIがこちらの指示を受けて動く『道具』から、共に考える『協働相手』のように感じられ始めた」と書いたように、定量スコア以上に「働き方の質的な変化」を実感したという報告が相次いだ。価格や安全装置という摩擦はあっても、到達した能力そのものに疑義を呈する声はほとんどない——これが今回のリリースに対するシリコンバレーの最大公約数的な評価といえる。
今後の展望——IPO、トークンエコノミー、そして「いつ何が起きるか」
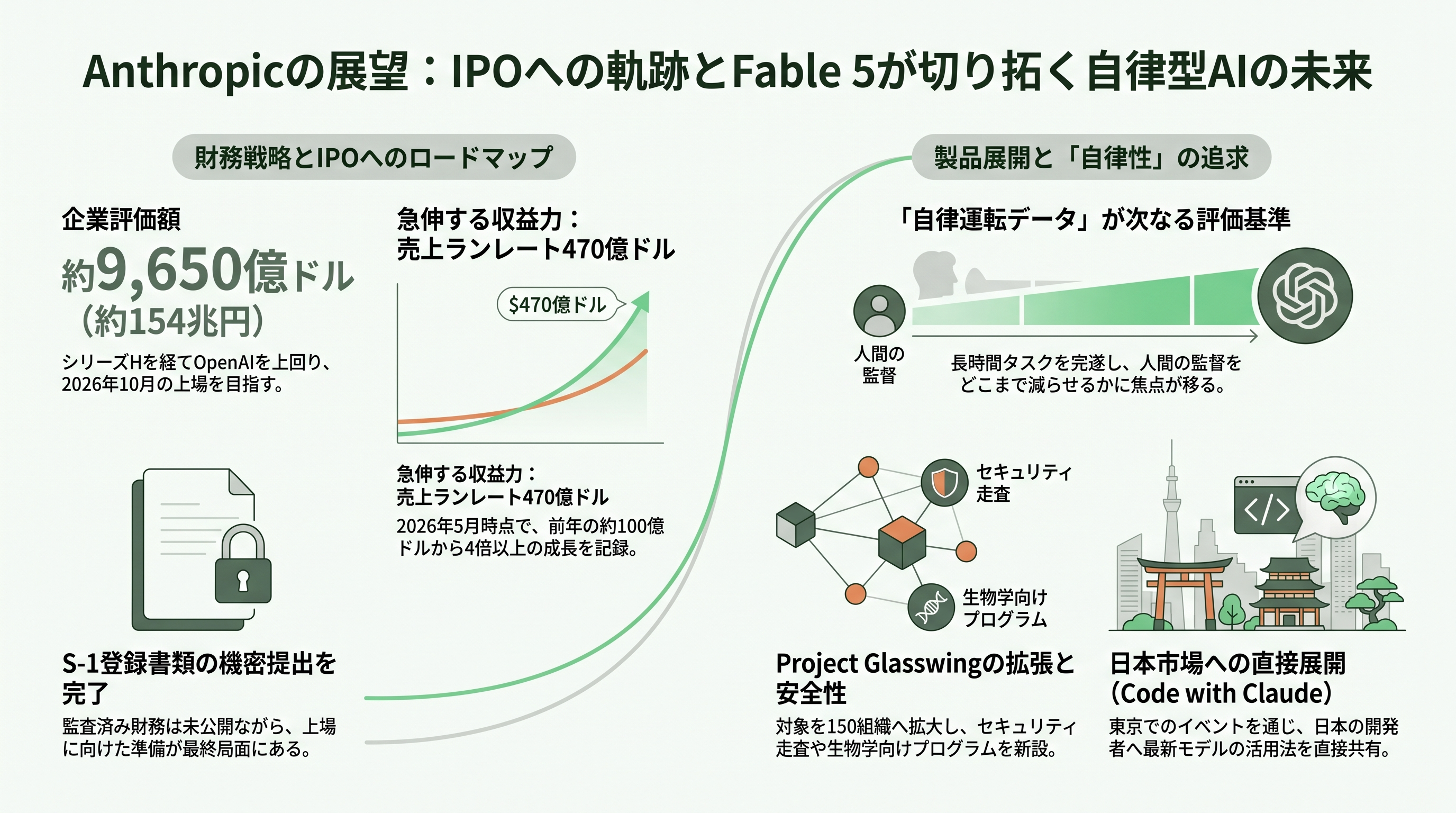
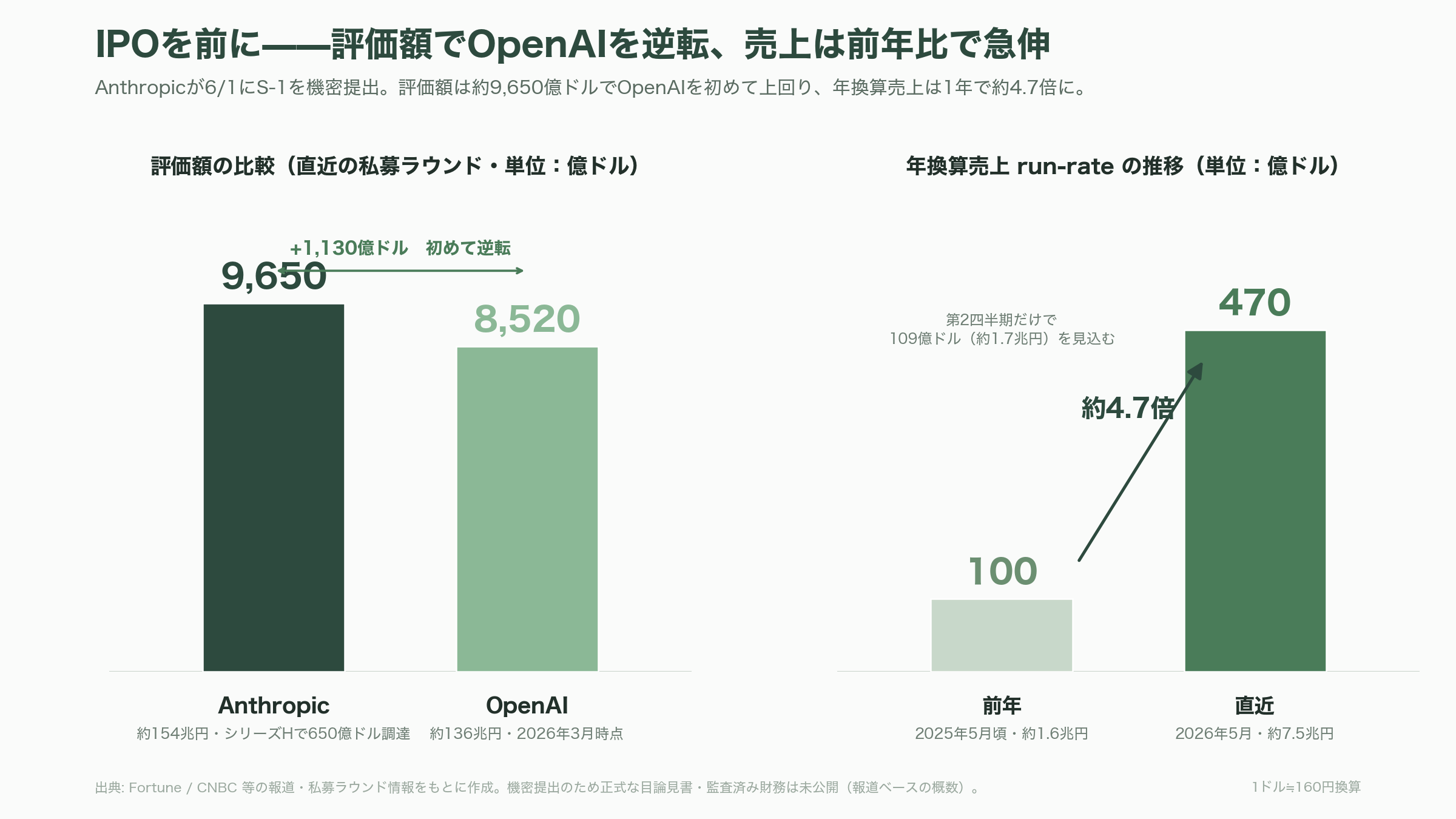
最後に、今後いつ頃どのような動きが見込まれるかを整理する。最大の背景はIPO(新規株式公開)だ。Fortune やCNBCの報道によれば、Anthropicは6月1日、米SECにS-1登録書類を機密扱いで提出した。直近の650億ドル(約10兆4,000億円)規模のシリーズHで評価額は約9,650億ドル(約154兆円)に達し、OpenAI(3月時点で約8,520億ドル=約136兆円とされる)を初めて上回ったと伝えられる。年換算売上(run-rate)は2026年5月時点で約470億ドル(約7兆5,000億円)と、前年の約100億ドル(約1兆6,000億円)から急伸し、第2四半期だけで109億ドル(約1兆7,400億円)の売上を見込むという。ただし機密提出のため正式な目論見書も監査済み財務も未公開で、これらの数値はあくまで報道と私募ラウンドに基づく点には留意が必要だ。上場時期は早ければ2026年10月、すなわち今秋とみられている。今回のFable 5公開は、この上場ストーリーに「最先端の能力を、悪用させずに収益化できる」という決定的な一章を加えるイベントだった。
製品面で当面注視すべき動きは三つある。第一にキャパシティの増強で、6月23日以降にいったん利用枠制へ移行したFable 5が、計算資源の確保に応じて標準サブスクリプションへ再び組み込まれるタイミングだ。第二にProject Glasswingの拡張で、Anthropicはより体系的な「信頼アクセス・プログラム」へ移行し、Mythos Previewの利用者をMythos 5へアップグレードさせるほか、サイバーの安全装置は残したまま生物・化学の制約を外した「生物学向けプログラム」を新設する計画を示している。Engadgetなどは、Glasswingの対象が約150の新規組織へ拡大し、コードベース走査とパッチ提案を行う「Claude Security」が加わったとも報じている。第三に、本日6月10日のCode with Claude東京および翌11日のExtended Tokyoで、新モデルを前提とした使いこなしや新機能のライブデモが日本の開発者へ直接共有されることだ。
エンジニアの視点で先を読むなら、注目の本丸は「ベンチマークの数字」よりも「自律運転の実運用データ」に移っていく。Fable 5の真価は、数時間〜数日に及ぶ長時間タスクをどれだけ安定して完遂し、誤検知によるフォールバックをどこまで抑え込めるかにかかる。Anthropic自身が「社内コードの80%超をClaudeが書く」と公言し、再帰的自己改善への警鐘まで鳴らしている以上、次に世界が計測すべきは「人間の監督をどこまで薄くしても破綻しないか」という一点だ。料金の綱引き、安全装置のチューニング、そしてIPOという三つの変数が絡み合いながら、2026年後半のAI開発競争はFable 5を一つの基準点として回り始める。その最前線の空気が、奇しくも発表翌日の東京で吸える——日本の開発者にとって、これ以上ないタイミングでの「最強モデル解禁」だったといえるだろう。