Fish Speech
1. サービス概要
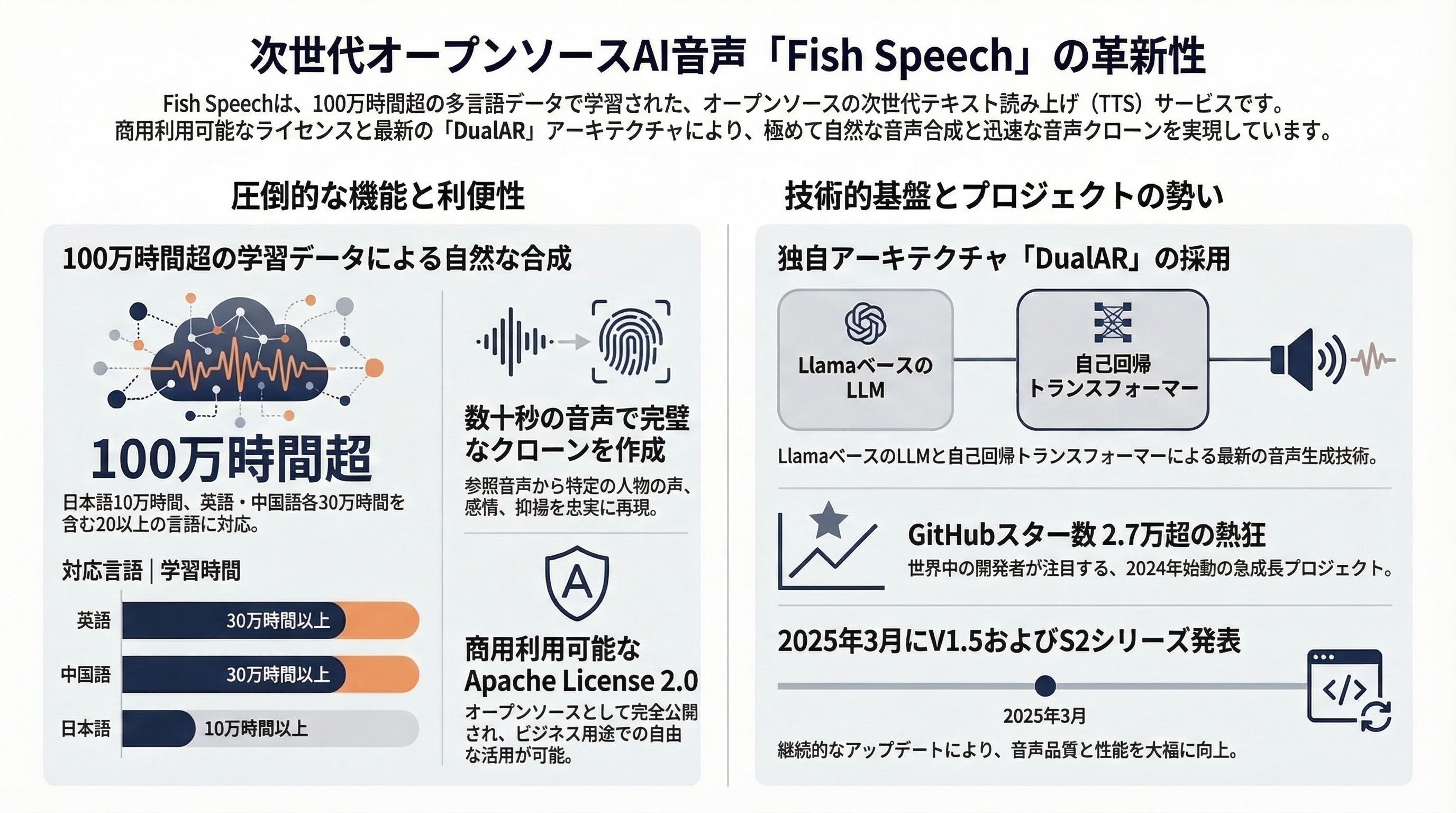
Fish Speech は、最先端の生成AIを活用した、次世代型のオープンソース・テキスト読み上げ(TTS)および音声クローンサービスです。
- 主な機能:
- テキスト読み上げ (TTS): 100万時間を超える多言語音声データで学習された、極めて自然な音声合成。
- 音声クローン (Voice Cloning): 数十秒程度の参照音声から、特定の人物の声、感情、抑揚を忠実に再現。
- 多言語対応: 日本語(10万時間以上)、英語(30万時間以上)、中国語(30万時間以上)を含む、20以上の言語に対応。
- WebUI / API 提供: ブラウザ上で操作できるインターフェースのほか、開発者向けのAPIも提供。
- ユーザー数: 公開されている GitHub のスター数は 2.7万(2025年3月時点)を超えており、世界中の開発者やクリエイターに利用されています。具体的な総登録ユーザー数は非公開。
- 対応プラットフォーム: Webブラウザ(クラウド版)、Windows / Linux / macOS(ローカル環境、Docker対応)、Python SDK、API。
2. 使用している技術スタック
Fish Speech は、従来の VITS 等のモデルとは異なる「DualAR(デュアル自己回帰)」アーキテクチャを採用しているのが特徴です。
- アーキテクチャ:
- LLM (Large Language Model): Llama アーキテクチャに基づいた自己回帰型モデル。
- DualAR (Dual Auto-Regressive): テキストから音響トークンへの変換にデュアル自己回帰トランスフォーマーを使用。
- VITS / VQGAN / EnCodec: 音声の離散化および高品質なデコードに使用。
- 開発言語・フレームワーク: Python, PyTorch (torch.compile による高速化に対応).
- 環境構築: Docker, NVIDIA CUDA, Triton(高速化プラグイン), UV(パッケージ管理).
- モデル配布: Hugging Face にてチェックポイント(重みファイル)を公開。
3. 会社概要
運営実体は、米国のデラウェア州に登記されているスタートアップ企業です。
- 運営会社名: Hanabi AI Inc.(サービスブランド名は Fish Audio)
- 設立年: 2024年(ドメイン取得およびプロジェクトの本格始動時期より)
- 本社所在地: 131 Continental Dr, Suite 305, Newark, DE 19713, United States
- 従業員数: 不明(GitHub の主要なコントリビューターおよびコアメンバーは数名〜10名程度と推測される)
4. 沿革、資本構成、国籍、役員情報
- 沿革:
- 2024年5月:Fish Speech V1.0 を発表。当初は商用利用不可のライセンス(CC BY-NC-SA 4.0)であった。
- 2024年12月:ライセンスを Apache License 2.0 に変更し、完全なオープンソース化と商用利用を解禁。
- 2025年3月:性能を大幅に向上させた Fish Speech V1.5 および最新の S2 モデルシリーズを発表。
- 資本構成: 外部からの大規模な資金調達(Series A等)の詳細は公表されておらず、現状は「Unfunded(自己資金またはエンジェル投資家等)」の段階とされている。
- 国籍: 会社登記は米国(デラウェア州)であるが、主要開発者および研究チームの多くが中国出身のエンジニアである。
- 役員情報:
- Songting Liu (CEO/Founder): 代表的な論文『Fish Audio S2 Technical Report』の筆頭著者であり、主要な開発を主導。
- 主要メンバー: Yifan Cheng, Ruoyi Zhang, Yisheng Zheng 等、AI・音声合成分野の研究者が名を連ねている。役員の詳細なキャリアパスについては、学術研究およびオープンソース開発を基盤としており、特定の国籍(中国系・米国籍等)や詳しい経歴の詳細は公式には非公開。