CosyVoice 2
1. サービス概要
CosyVoice 2は、Alibaba(アリババグループ)のAI研究部門である「Tongyi Speech Lab」が開発・公開している、大規模言語モデル(LLM)ベースのオープンソースなストリーミング音声合成(TTS:Text-to-Speech)モデルです。
- 主な機能:
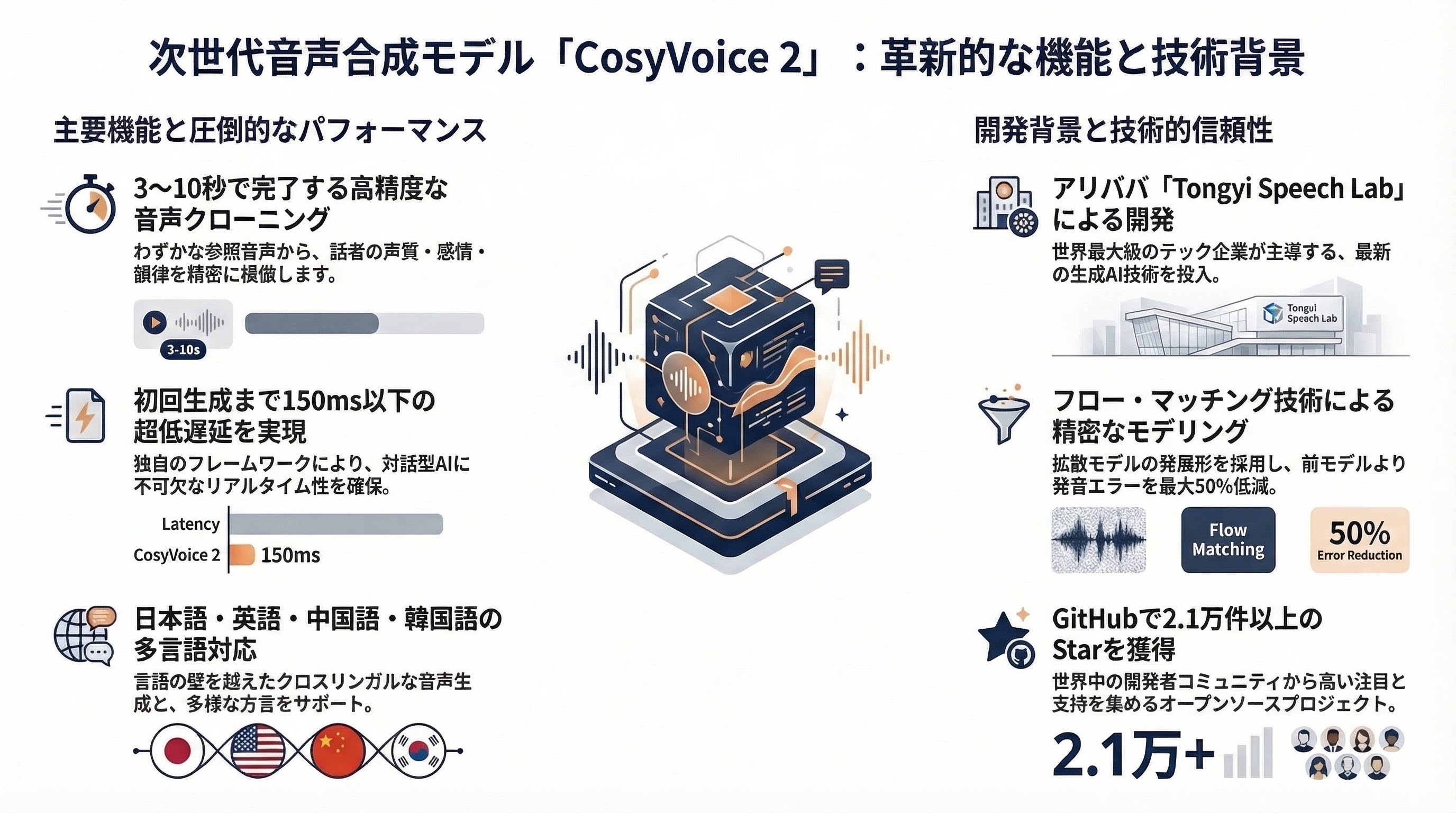
- ゼロショット音声クローニング: わずか3秒から10秒程度の短い音声サンプル(参照音声)から、その話者の特徴(声質、感情、韻律)を模倣した音声を生成可能。
- 多言語・クロスリンガル対応: 日本語、中国語、英語、韓国語、および複数の中国語方言(広東語、四川語、上海語等)をサポート。
- 超低遅延ストリーミング: 独自の統合フレームワークにより、非ストリーミングと同等の品質を維持しつつ、初回パケット生成まで150ms以下の低遅延を実現。
- 精密な感情・韻律制御: 発音エラーが前モデル(CosyVoice 1.0)より30〜50%低減し、自然な感情表現やきめ細かな音声制御が可能。
- ユーザー数: オープンソースプロジェクトのため正確な総ユーザー数は不明ですが、GitHubでのStar数は2.1万(2025年3月時点、リポジトリ全体)を超えており、開発者コミュニティで広く利用されています。
- 対応プラットフォーム: Python環境(Linux/Windows/macOS)、Docker、およびWebUI(Gradio等)。ModelScopeやHugging Faceを通じてモデルが提供されています。
2. 使用している技術スタック
CosyVoice 2は、高度な生成AI技術を組み合わせたアーキテクチャを採用しています。
- 基盤モデル: 大規模言語モデル(LLM)ベースの生成フレームワーク。
- 音声トークナイザー: 音声信号を離散的なユニットに変換する技術。
- フロー・マッチング(Flow Matching): 拡散モデル(Diffusion)の発展形であるフロー・マッチングを導入し、音韻情報の精密なモデリングを実現。
- ストリーミング・インフラ: ストリーミングと非ストリーミングを統合したトレーニング・推論フレームワーク。
- フレームワーク: PyTorchをベースに構築。
- 推論最適化: ONNX、TensorRTなどへの対応(コミュニティによる実装を含む)。
3. 会社概要
CosyVoice 2は、アリババグループ(Alibaba Group Holding Limited)内の音声AI専門組織「Tongyi Speech Lab(通義音声ラボ)」によって開発されています。
- 運営会社名: Alibaba Group Holding Limited(アリババグループ)
- 設立年: 1999年
- 本社所在地: 中国 浙江省 杭州市 余杭区 文一西路969号
- 従業員数: 約204,000人(2024年グループ全体連結)
4. 沿革、資本構成、国籍、役員情報
- 沿革:
- 1999年:ジャック・マー(馬雲)ら18人により杭州で設立。
- 2014年:ニューヨーク証券取引所(NYSE)に上場。
- 2024年:AIモデル「通義千問(Tongyi Qianwen)」シリーズの一環として、音声合成モデル「CosyVoice」を発表。
- 2024年末〜2025年:大幅に性能を向上させた「CosyVoice 2」をリリース。
- 資本構成: ニューヨーク証券取引所(BABA)および香港証券取引所(9988)の上場企業。主要株主にはソフトバンクグループ(かつての筆頭株主、現在は大部分を解消済み)、BlackRock、Vanguardなどの国際的な機関投資家が含まれます。
- 国籍: 中華人民共和国(ケイマン諸島登記の持株会社)
- 役員情報:
- 蔡崇信 (Joseph Tsai): 会長(Chairman)。台湾出身、カナダ国籍。アリババ創設メンバーの一人。
- 呉泳銘 (Eddie Wu): 最高経営責任者(CEO)。中国国籍。アリババ創設メンバーの一人。
- 周暢 (Zhou Chang): Tongyi Speech Labを含むAIモデル開発を主導するシニア技術者・研究員(Alibaba Cloud所属)。